Ближайшее будущее AI в рентгенологии. Мои комментарии к статьи на RSNA
В конце октября вышла статья «The Future of AI and Informatics in Radiology» под авторством Кёртиса Ланглотца, профессора радиологии и биомедицинского data science в Стэнфорде. Она содержит 10 предсказаний о будущем ИИ в нашей индустрии. Хочу по ним пробежаться и поделиться своим видением текущей ситуации.
Ещё несколько лет назад ни один эксперт не мог даже предположить, что сегодня технологии искусственного интеллекта смогут проникнуть в такую сложную и ответственную область как медицина. Но динамика развития цифровых помощников просто поражает. На 2023 год насчитывается более 100 компаний, разрабатывающих продукты на основе ИИ. Кроме того, только официально зарегистрированных Управлением по контролю за продуктами питания и лекарствами США (FDA), алгоритмов на основе ИИ для радиологии насчитывается более 400. И это только в США, но не менее крупных достижений добиваются в России, Евросоюзе, странах СНГ.

Радиология останется главным плацдармом развития искусственного интеллекта в сфере здравоохранения
Рентгенологи являются основным потребителем продуктов на основе медицинского ИИ. По статистике, 75% из более чем 500 зарегистрированных решений приходятся именно на радиологию. Такая динамика объясняется несколькими пунктами:
Данные рентгенографии, маммографии, КТ и МРТ на протяжении десятилетий являются цифровыми и хранятся в таком же виде. Медицинские учреждения накопили эксабайты таких данных и готовы делиться ими с разработчиками решений на основе ИИ.
Медицинские изображения (РГ, КТ, МРТ) и записи сочетаются с текстовым описаниями, заключениями и наблюдения реальных врачей, что делает их идеальными для создания точных алгоритмов машинного обучения.
Анализ изображений рентгенографии в некоторых случаях сложен для человеческого глаза. Минимальные отклонения, еле заметные детали на снимках, определение размеров — это проблемы для рентгенологов, приводящий к клинически значимым ошибках. Сейчас показатель ошибок в интерпретации составляет 4% и это достаточно высокий показатель для медицинской сферы.
Для определения патологий и поиска несоответствий врачи вынуждены обрабатывать огромное количество информации, сравнивать снимки, что занимает огромную часть рабочего времени, а ИИ может делать это за секунды.
Мой комментарий
Говорим «ИИ в медицине», держим «ИИ в рентгенологии» в уме. Во многом это правда — медицинские изображения продолжают генерировать внушительное количество статей, выступлений, обсуждений, датасетов. При этом больше половины российских регионов в этом году закупили системы не рентгенологические ИИ-системы, а предиктивную аналитику по электронным медицинским картам (предсказание вероятности возникновения сердечно-сосудистых заболеваний). В этом году также сильно перетянули на себя внимание медицинские LLMки — их хватило уже аж на целый обзор.

Но, пожалуй, с точки зрения стадии взросления, количества преодолённых проблем, ожидаемого экономического эффекта, понятных сценариев применения, картиночные системы продолжают быть в авангарде продуктового медицинского ИИ. Всё-таки задача поиска определённых паттернов на 2D и 3D-изображениях очень хорошо приспособлена для решения с помощью ML. К тому же, ИИ отлично закрывает частые причины ошибок врачей — усталость и большая нагрузка, «слепые пятна» на исследованиях, когнитивные искажения. При этом ИИ всё ещё порядочно уступает врачу в плане способностей агрегировать всю информацию о пациенте и выдавать хорошие рекомендации лечащему врачу.
В общем, AI in medical imaging уже не на волне хайпа, но точно с нами надолго.
2. ИИ сможет формировать радиологические отчёты, снижая нагрузку врачей
Дальнейшее развитие технологии искусственного интеллекта в медицине скажется и на производительности врачей, взяв на себя рутинные задачи. Одной из таких является составление радиологических отчетов на основе выявленных признаков на снимке. Сейчас этим занимаются либо ординаторы, либо сами врачи. Но в скором будущем решения на основе ИИ, способные не только изучать и сравнивать изображения, но и генерировать естественный текст радиологических заключений, тем самым облегчая работу врачей.
Врачам останется лишь проверять готовые отчёты и ставить подписи (сначала по заключениям с описанием «нормы», а потом по случаям с патологиям, где ИИ имеет высокую «степень уверенности»).
При этом постоянное обучение моделей на основе уже готовых радиологических отчетов позволит постоянно повышать уровень качества ИИ. А врачи при этом смогут сфокусироваться на главном, что и повысит производительность, находиться постоянно в фокусе, так как в их потоке исследований для анализа не будет присутствовать простых случаев, тем самым ожидается существенное повышение уровня диагностических и скрининговых процедур, и также большие подвижки в решении проблемы нехватки квалифицированного персонала.

На диаграмме показана архитектура виртуального ассистента рентгенолога , включающая в себя две области применения искусственного интеллекта: компьютерное зрение, которое распознает рентгенологические признаки на изображениях (например доброкачественные и злокачественные образования), и генерацию естественного языка, которая генерирует текстовое заключение для врача на основе найденных находок.
Мой комментарий
В этом году мы очень постарались сделать наши текстовые отчёты максимально стандартизированными и более удобными для врача. Для этого понадобилось большое количество доработок — добавление новых классов, дополнительных функций, а ещё мы перенесли генерацию текста на сторону ML для гибкости и скорости разработки и более полного тестирования.

Пример протокола по ММГ
В статье предполагается, что текстовые отчёты будут генерироваться с помощью LLM на основе предиктов картиночных нейронок. С этим мне пока согласиться сложно. Я не очень понимаю, какие преимущества LLM дают по сравнению с детерминированным алгоритмом генерации, а вот потенциальные проблемы лежат на поверхности (галлюцинации и всё такое). В теории можно предположить вариант с суммаризацией текстового отчёта, истории болезни и направления терапевта на исследование, но и тут я пока не готов сделать ставку исключительно на LLM.
3. Единая интеллектуальная система интерпретации изображений решит проблему разрозненных инструментов
Технологии, с которыми работают радиологи в настоящее время, развивались независимо друг от друга, что создало барьер для удобной работы в рамках одного интерфейса. Мы говорим про отдельные системы распознавания речи, архивирования изображений, связи, бумажные истории болезни и медицинские карты. Огромное количество сервисов и инструментов, в каждый из которых требуется вносить информацию «с нуля».
Но технологии постепенно меняют мир, в особенности облачные решения, позволяющие собрать множество инструментов в одном интерфейсе.
Единая система для рентгенологов — это важный шаг к повышению как качества услуг, так и удобства работы врачей.
В ближайшем будущем радиологи смогут видеть открытые задачи, историю болезни, результаты рентгенографии и отчеты в одном интерфейсе.
Мой комментарий
В этом предсказании описан красивый пайплайн работы рентгенолога. Всё развёрнуто в облаке, к моменту начала работы врача уже всё сегментировано, описано, измерено и сгенерирован первый вариант отчёта. Все эти измерения можно на лету отредактировать голосом или парой кликов.
В принципе в некотором виде этот процесс работы уже существует, но куда же без сложностей:
До сих пор существуют большие непонятки со стандартизацией формата хранения результатов работы ML-сервисов. На данный момент у нас 100% интеграций сделано через комбинацию Secondary Capture (SC) + Structured Report (SR). Проблема SC в том, что это отдельное RGB-изображение — полная копия исходного исследования с нанесённой на него разметкой. Это позволяет генерировать красивые картинки, но значительно утяжеляет коммуникацию между медицинском учреждением и ИИ-сервисом и требует больших затрат на хранение. В DICOM-формате существуют другие, очень лёгкие способы хранения различных видов разметки (классификация, сегментация, детекция), и даже есть питоновские библиотеки, которые позволяют удобно с ними работать. Увы, пока с этим никто особо не хочет запариваться, но, думаю, всё впереди. Ещё одна альтернатива — использование платформ типа deepc, которые берут интеграцию между больницами и ИИ-вендорами на себя. В этом случае разработчику достаточно предоставить результаты работы в формате JSON, а генерацию всех репортов в нужном формате берёт на себя платформа.
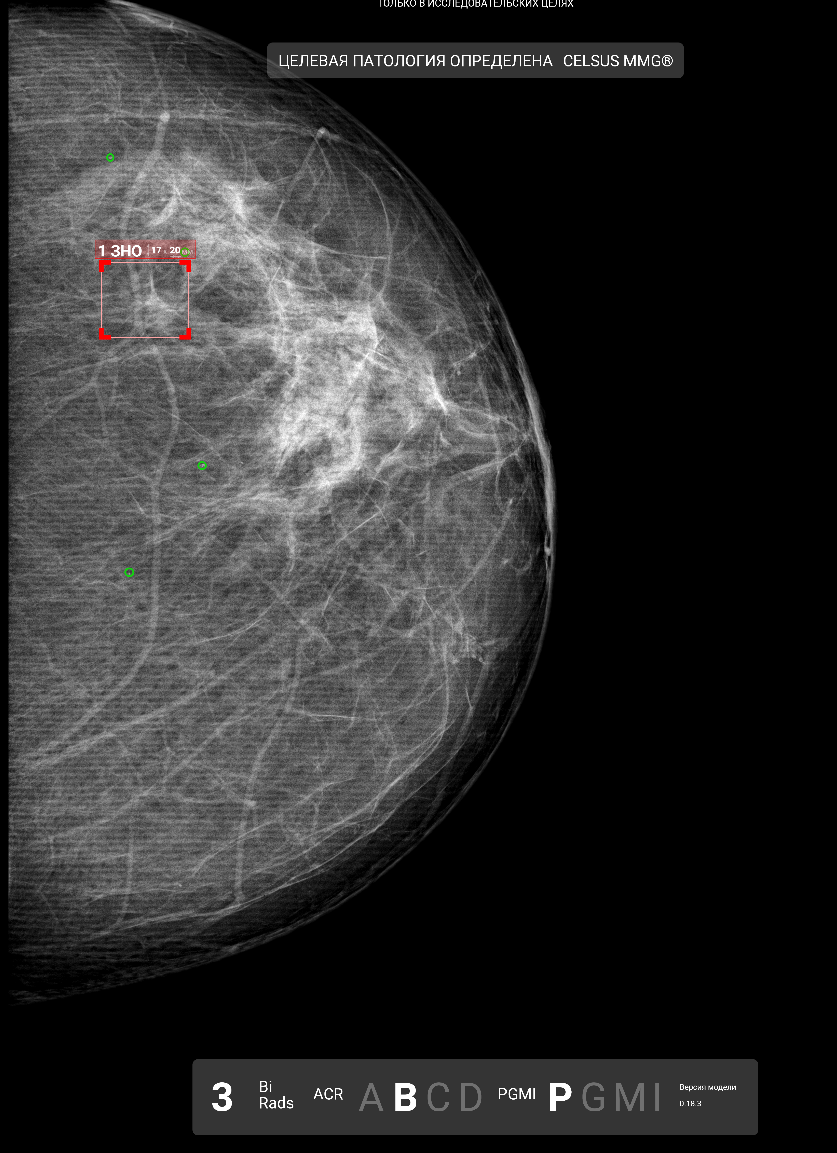
Пример SC-файла
Популярной схемой в регионах остаётся локальное развёртывание на физической машине в контуре клиента. Это даёт определённые преимущества (например, скорость обмена данными и инфобез), но при этом и затрудняет всякие модные облачные сценарии взаимодействия, а также мониторинг качества работы ИИ-систем.
4. Точные ИИ-модели полностью исключат потребность в интерпретации человеком.
Человечество пока не научилось полностью доверять машинам, особенно в сфере медицины, где слишком высока цена ошибки. Но статистика показывает, что 63% скрининговых маммограмм могут не проверяться человеком. ИИ уже сейчас способен достаточно точно описывать часть потока исследований.
В любом случае, технологии скоро достигнут уровня, когда участие человека в некоторых процессах просто не будет требоваться.
Но стоит отметить, что автоматизация процесса скрининга не вытеснит радиологов, а наоборот откроет новые грани профессии и позволит раскрыть потенциал.
Мой комментарий
Идея этого сценария работы проста — часть исследований может обрабатываться автоматически, без какого-либо участия врача. Особенно это актуально для сценариев массового скрининга, где подавляющее количество исследований не содержит патологию и не представляет большой сложности в плане интерпретации.
По итогам 3 квартала этого года наш сервис по флюорографии обработал в сценарии «highly sensitive AI» более 60к исследований. Чувствительность сервиса составила 99.93% при автоматической генерации заключения «без патологии» для 67% исследований. При этом пересмотр врача-эксперта подтвердил расхождение только для 40% из этих 0.07% расхождений. Иными словами, сервис автоматически присвоил категорию «норма» более 40к исследованиям, при этом было допущено около 15–20 ошибок.
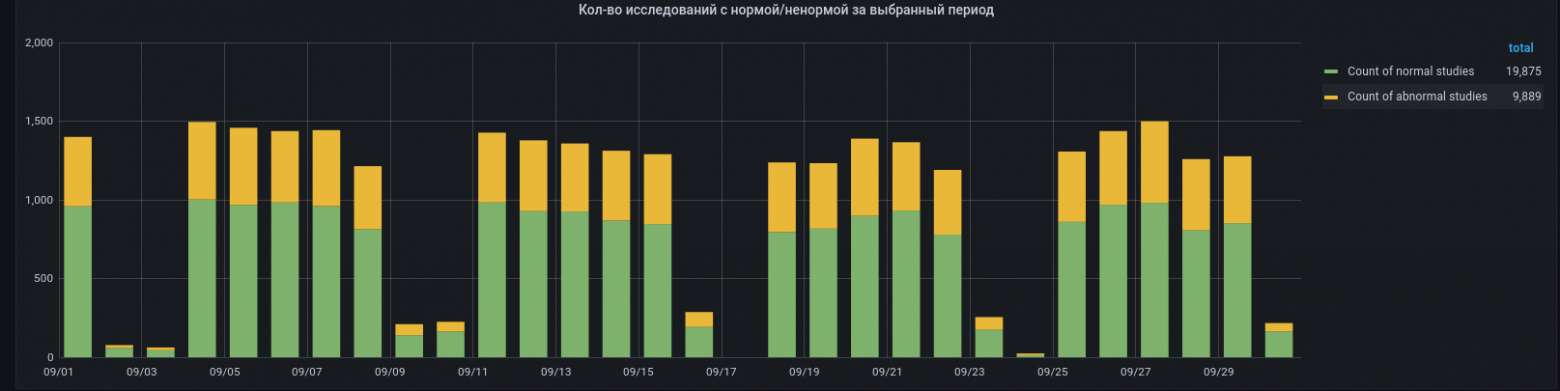
Статистика за сентябрь
Барьеров для полноценного внедрения ещё немало — нужно ещё сильнее улучшать чувствительность (в основном решать проблемы со всякими сложными случаями и редкими патологиями) и понять, что делать с точки зрения ответственности разработчиков в случае ошибки, но перспективы реального применения автономных сценариев явно вышли из области фантастики.
5. Языковые модели помогут пациентам понять радиологию
Тут стоит рассмотреть сразу 2 стороны больших языковых моделей в медицине:
Языковые модели пришлись по вкусу в сфере медицины, составляя отчеты, объясняя рекомендации и даже сдавая экзамены. Но количество ошибок, в том числе ложные сведения, проблемы с математикой и даже опасные заявления пока сдерживают прогресс. В будущем разработчикам предстоит бороться с этими проблемами.
Радиологи, согласно общепринятым правилам, должны обеспечивать пациентам свободный доступ к информации и они делают это. Но профессиональный сленг врачей вводит пациентов в ступор из-за сложных терминов, а объяснений ждать не приходится. Зато языковые модели могут в режиме реального времени объяснять сложные заключения врачей простым языком, понятным для масс.
Вот пример ответа с просьбой объяснить медицинский термин «Круг Уиллиса» на уровне ученика начальной школы от языковой модели ChatGPT:
«Круг Уиллиса — это группа кровеносных сосудов в вашем мозге, которые помогают снабжать кровью ваш мозг и поддерживать его здоровым. Она имеет форму круга и состоит из нескольких крупных кровеносных сосудов, которые соединены друг с другом. Эти кровеносные сосуды называются артериями, и они доставляют кровь от вашего сердца к мозгу. Уиллисов круг помогает убедиться, что ваш мозг получает достаточное количество крови, даже если одна из артерий закупоривается или сужается».
Данная технология может стать буфером для понимания данных своей медицинской карты пациентом и лучшее знание истинного состояния своего здоровья и ограничений.
Мой комментарий
Пожалуй, единственное применение LLM в рентгенологии, которое мне на данный момент видится реальным. Когда я делал МРТ колена, голеностопа и поясницы, мне каждый раз приходилось гуглить, что же у меня там такое нашлось, и что с этим делать. В идеале это, конечно, должен пояснять врач, но не всегда это возможно, к тому же любопытным пациентам часто хочется перепроверить всё самим. В общем, «перевод» с медицинского на русский — направление перспективное.
6. Мультимодальный искусственный интеллект превзойдёт человека в определении новых закономерностей
Искусственный интеллект в радиологии сможет не только заменить врачей в простых и рутинных задачах, требующих обработки массивов информации, но и исключить «человеческий фактор», а также превзойти человека в точных вычислениях.
На данный момент ИИ в редких случаях находит закономерности, ранее не обнаруженные человеком. Однако, его развитие приведет к тому, что модели машинного обучения смогут соотносить результаты исследования с конкретными геномными сигнатурами и лабораторными показателями, а также использовать больше категорий при определении патологий.
Это позволит повысить эффективность диагностирования сложных заболеваний и, соответственно, помочь в их лечение.
Эксперты журнала приводят в пример гораздо большие объёмы информации и количество категорий при диагностировании рака, что позволит оценить течение болезни и дать более точные прогнозы заболевания.
Используя данные каждого пациента, система персонифицированной медицины, предоставит оптимальные рекомендации для конкретного пациента по профилактике, диагностике и лечению заболеваний.
Мой комментарий
Искренне верю и давно хочу поработать с мультимодальными данными (простой пример приводил выше — агрегация текстового отчёта об исследовании, истории болезни пациента и заметок с приёма пациента), но всё упирается в их фактическое отсутствие у разработчиков. Самое похожее, что у нас реально есть на руках в адекатных объёмах — это пары «картинка — заключение врача», но с этим особо каши не сваришь. Есть мнение, что на самом деле даже и неплохо, что ИИ описывает только визуальную информацию, не ориентируясь на априорные данные. Но всё-таки верится, что мультимодальность позволит совершить рентгенологическому ИИ следующий большой скачок.
7. Онлайн-обмен изображениями значительно сократит расходы
Электронный обмен медицинскими исследованиями внутри облачных систем в скором будущем поможет ещё и избежать задержек при оказании медицинских услуг, а также снизить затраты на передачу изображений.
Дело в том, что при необходимости оказания неотложной медицинской помощи данные визуализации часто приходится запрашивать у других медицинских организаций, либо делать заново. Лишь единицы из пациентов имеют при себе изображения на компакт-дисках или DVD-дисках.
Создание единой сети обмена информации только в США позволит экономить до 218 миллионов долларов в год за счет экономии на расходных материалах при повторных исследованиям и до 11 миллиардов долларов на процедуры медицинскую визуализацию.
Мой комментарий
Звучит правдоподобно. Экспертом здесь не являюсь, так что и комментировать не буду.
8. Реформы правового регулирования значительно ускорят внедрение и повышение качества применения технологий
Искусственный интеллект в сфере медицины пока ещё сталкивается с проблемой отсутствия правовой базы регулирования. Модели нуждаются в обучении на больших объёмах данных, которые желательно собирать на месте развёртывания систем. Но на данный момент идеальный сценарий разбивается о правила регулирования, отношение к конфиденциальности и общую закрытость данных.
В ближайшие годы требуются реформы регулирования, создание новых структур местного управления и простые формы для сбора обратной связи от пациентов, касательно конфиденциальности данных.
В США и России уже на данном этапе наблюдаются шаги в правильном направлении.
Мой комментарий
На данный момент обновление регистрационного удостоверения на медицинское изделие занимает не менее полугода. То есть, каждое обновление нейронки — от переобучения до изменения формата отчёта, в теории должно сопровождаться долгим и муторным процессом обновления сертификации. Все в индустрии понимают, что нужно что-то менять. FDA предложило документ, посвящённый этой проблеме, российский набор ГОСТов по ИИ в медицине тоже затрагивает эту проблему. Дело за малым — имплементировать возможность быстрого обновления версии на практике. Тем более, что есть хороший опыт Московского эксперимента.
Отдельно хотел бы отметить важность прозрачности в этом процессе. Наличие подробной документации, описывающей сами ИИ-системы, процесс и результаты их тестирования, процедуру переобучения и использованные набора данных значительно снижает риск появления критических ошибок при обновлении версии алгоритма. В рамках процедуры подготовки к получению ISO 13485 мы пересмотрели процесс документирования тестирования новых версий систем. Все релизы делятся на minor и major. Minor-версии (без изменения метрик качества) сопровождаются релизным чек-листом, а к major-версиям прилагается обязательный отчёт по тестированию и техническое задание.
9. Крупнейшая база данных поможет использовать все возможности искусственного интеллекта
На сегодняшний день уже существует несколько крупных баз данных, содержащих изображения для обучения искусственного интеллекта. Это и эталон в области компьютерного зрения ImageNet, и база данных MIDRC, насчитывающая более 100 тысяч исследований изображений с открытых сайтов, и National COVID Cohort Collaborative, собравшая данные визуализации 130 000 пациентов, прошедших КТ, МРТ и УЗИ.
Появление новых законов, позволит медицинским и научным организациям открыто обмениваться данными и улучшать качество работы решений на основе ИИ.
Ожидается, что в ближайшие годы появится новая крупнейшая база данных, которая будет содержать изображения рентгенографии единого формата и постоянно пополняться новыми исследованиями.
Мой комментарий
За время существования компании мы накопили уже четверть петабайта данных. Прямо сейчас находимся в размышлениях, что со всем этим делать, нужны ли нам все данные, и какие политики хранения внедрить, чтобы не тратить каждый месяц мешок денег. Разговоры о каком-нибудь безумном претрейне то и дело возобновляются (прямо сейчас я пробую обучить свой DINO на всём объёме неразмеченных маммографических данных), но по факту обычно не хватает ни времени, ни вычислительных ресурсов. Время от времени в опенсорсе появляются всякие штуки типа MedSAM, но обычно (кажется) выгоднее вложиться в создание качественных датасетов под свои нужды и их улучшение. Рано или поздно ситуация, наверное, изменится, но пока претрейны в опенсорсе не являются панацеей от всех проблем.
10. У руля инноваций окажутся гибкие и сотрудничающие академические организации
Для развития искусственного интеллекта, особенно для медицинской сферы, нужны разноплановые специалисты. Сейчас за решения на базе ИИ в медицинских организация могут отвечать практикующие врачи с минимальной подготовкой в области машинного обучения.
Но тренд идёт к тому, что будут создаваться команды, включающие практикующих врачей, IT-специалистов, экономистов, философов, специалистов по этике, которые смогут обеспечить стабильное развитие медицинского ИИ, оценивать риски и применять новейшие решения на практике.
У руля исследований и разработок при этом останутся академические институты, именующие доступ ко всем необходимым ресурсам.
Мой комментарий
Пункт про важность интердисциплинарных команд поддерживаю обеими руками. В каждой ML-команде сейчас есть врач, который активно участвует в работе: отвечает на вопросы команды, мониторит поток, генерирует гипотезы, выстраивает процесс разметки.
При этом слабо себе могу представить, чтобы на данный момент эти команды возглавлялись врачами, и чтобы в них в обязательном порядке присутствовали специалисты по этике, экономисты и философы. Эти специалисты нужны для изменения регуляторики, сопровождения внедрения и других подобных задач, но непосредственно разработка сейчас базируется на ML-компетенциях с консультативной поддержкой со стороны медицины.
Что касается главенства университетов в развитии области — не знаю. Безусловно, есть пример моего родного NYU, у которого есть куча данных, специалистов, вычислительных мощностей и возможностей для партнёрства с медицинскими организациями, но я уверен, что коммерческие компании играют и продолжат играть очень важную роль в реальном прониковении ИИ в сферу рентгенологии.
Вывод
Прогресс искусственного интеллекта, особенно в медицинской сфере, поражает своими масштабами. Делать прогнозы даже на несколько лет не берутся даже эксперты.
Однозначно понятно, что ближайшие 5–10 лет принесут множество сюрпризов, упрощающих работу врачей, повышающих качество и скорость оказания медицинских услуг и улучшающих пользовательский опыт пациентов.
Радиологи точно смогут сфокусироваться на интеллектуальной деятельности и полезной работе, из-за которой люди и выбирают данную сложную, но очень интересную профессию.
