Битва за портфель: Python против финконсультантов
В продолжение статьи о вреде избыточной диверсификации создадим полезный инструментарий по подбору акций. После этого сделаем простую ребалансировку и добавим уникальные условия технических индикаторов, которых так часто не хватает в популярных сервисах. А затем сравним доходность отдельных активов и различных портфелей.
Во всём этом задействуем Pandas и минимизируем количество циклов. Погруппируем времянные ряды и порисуем графиков. Познакомимся с мультииндексами и их поведением. И всё это в Jupyter на Python 3.6.
Если хочешь сделать что-то хорошо, сделай это сам.
Фердинанд Порше
Описанный инструмент позволит подобрать оптимальные активы для портфеля и исключить инструменты, навязываемые консультантами. Но мы увидим лишь общую картину — без учёта ликвидности, времени набора позиций, комиссий брокера и стоимости одной акции. В целом, при ежемесячной или ежегодной ребалансировке у крупных брокеров это будут незначительные затраты. Однако перед применением выбранную стратегию всё же стоит проверить в event-driven бэктестере, например, Quantopian (QP), дабы исключить потенциальные ошибки.
Почему не сразу в QP? Время. Там самый простой тест длится около 5 минут. А текущее решение позволит вам за минуту проверить сотни разных стратегий с уникальными условиями.
Загрузка сырых данных
Для загрузки данных возьмем метод, описанный в этой статье. Для хранения дневных цен я использую PostgreSQL, но сейчас полно бесплатных источников, из которых можно сформировать необходимый DataFrame.
Код загрузки истории цен из БД доступен в репозитории. Ссылка будет в конце статьи.
Структура DataFrame
При работе с историей цен, для удобной группировки и доступа ко всем данным, лучшим решением является использование мильтииндекса (MultiIndex) с датой и тикерами.
df = df.set_index(['dt', 'symbol'], drop=False).sort_index()
df.tail(len(df.index.levels[1]) * 2)
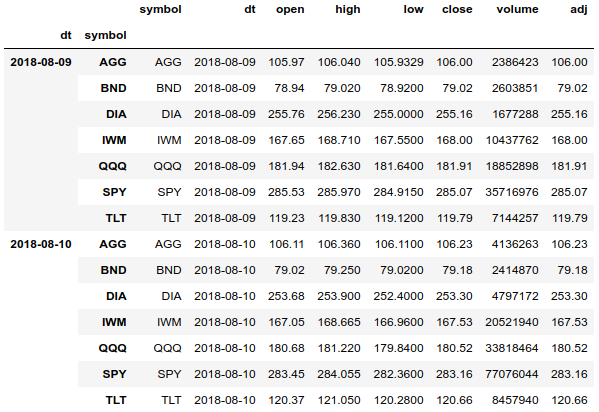
Используя мультииндекс, мы можем легко получить доступ ко всей истории цен для всех активов и можем группировать массив отдельно по датам и активам. Также можем получить историю цен для одного актива.
Вот пример, как можно легко группировать историю по неделям, месяцам и годам. И всё это показать на графиках силами Pandas:
# Правила обработки колонок при группировке
agg_rules = {
'dt': 'last', 'symbol': 'last',
'open': 'first', 'high': 'max', 'low': 'min', 'close': 'last',
'volume': 'sum', 'adj': 'last'
}
level_values = df.index.get_level_values
# Графики
fig = plt.figure(figsize=(15, 3), facecolor='white')
df.groupby([pd.Grouper(freq='W', level=0)] + [level_values(i) for i in [1]]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False
).close.unstack(1).plot(ax=fig.add_subplot(131), title="Weekly")
df.groupby([pd.Grouper(freq='M', level=0)] + [level_values(i) for i in [1]]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False
).close.unstack(1).plot(ax=fig.add_subplot(132), title="Monthly")
df.groupby([pd.Grouper(freq='Y', level=0)] + [level_values(i) for i in [1]]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False
).close.unstack(1).plot(ax=fig.add_subplot(133), title="Yearly")
plt.show()
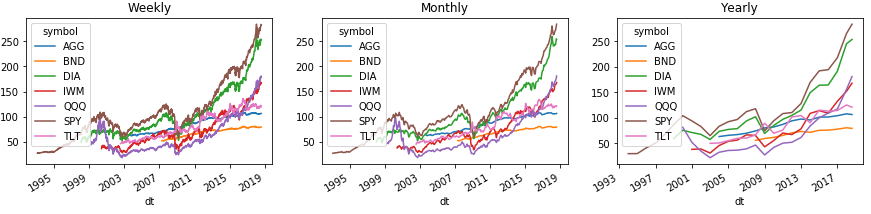
Для корректного отображения области с легендой графика мы переносим уровень индекса с тикерами на второй уровень над колонками, используя команду Series ().unstack (1). С DataFrame () такой номер не пройдёт, но решение есть ниже.
При группировке по стандартным периодам Pandas использует в индексе последнюю календарную дату группы, которая часто отличается от фактических дат. Для того чтобы это исправить, обновим индекс.
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(agg_rules) \
.set_index(['dt', 'symbol'], drop=False)
Пример получения истории цен определённого актива (берём все даты, тикер QQQ и все колонки):
monthly.loc[(slice(None), ['QQQ']), :] # история одно актива
Ежемесячная волатильность активов
Теперь мы в несколько строк можем посмотреть на графике изменение цены каждого актива за интересующий нас период. Для этого получим процент изменения цены, группируя dataframe по уровню мультииндекса с тикером актива.
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False)
# Ежемесячные изменения цены в процентах. Первое значение обнулим.
monthly['pct_close'] = monthly.groupby(level=1)['close'].pct_change().fillna(0)
# График
ax = monthly.pct_close.unstack(1).plot(title="Monthly", figsize=(15, 4))
ax.axhline(0, color='k', linestyle='--', lw=0.5)
plt.show()
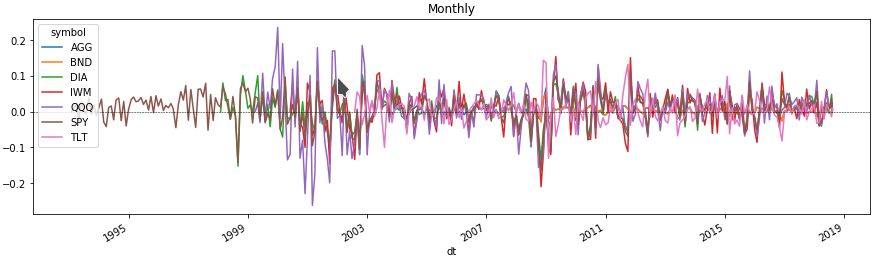
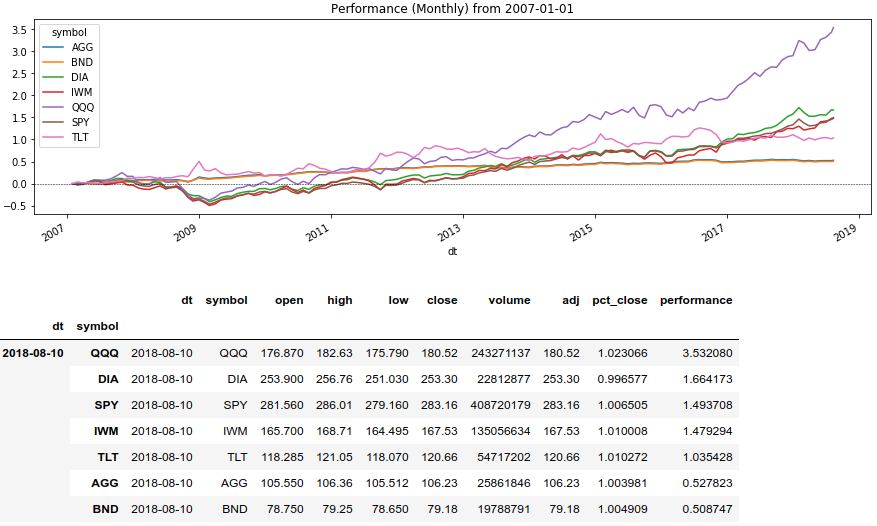
Сравним доходность активов
Теперь воспользуемся оконным методом Series ().rolling () и выведем доходность активов за определённый период:
rolling_prod = lambda x: x.rolling(len(x), min_periods=1).apply(np.prod) # кумулятивный доход
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False)
# Ежемесячные изменения цены в процентах. Первое значение обнулим. И прибавим 1.
monthly['pct_close'] = monthly.groupby(level=1)['close'].pct_change().fillna(0) + 1
# Новый DataFrame без данных старше 2007 года
fltr = monthly.dt >= '2007-01-01'
test = monthly[fltr].copy().set_index(['dt', 'symbol'], drop=False) # обрежем dataframe и обновим индекс
test.loc[test.index.levels[0][0], 'pct_close'] = 1 # устанавливаем первое значение 1
# Получаем кумулятивный доход
test['performance'] = test.groupby(level=1)['pct_close'].transform(rolling_prod) - 1
# График
ax = test.performance.unstack(1).plot(title="Performance (Monthly) from 2007-01-01", figsize=(15, 4))
ax.axhline(0, color='k', linestyle='--', lw=0.5)
plt.show()
# Доходность каждого инструмента в последний момент
test.tail(len(test.index.levels[1])).sort_values('performance', ascending=False)
Методы ребалансировки портфелей
Вот мы и подобрались к самому вкусному. В примерах мы посмотрим результаты портфлеля при распределении капитала по заранее определённым долям между несколькими активами. А также добавим уникальные условия, по которым будем отказываться от некоторых активов в момент распределения капитала. Если подходящих активов не будет, то будем считать, что капитал лежит у брокера в кэше.
Для того чтобы при ребалансировке использовать методы Pandas, нам необходимо хранить доли распределения и условия ребалансировки в DataFrame с группированными данными. Теперь рассмотрим функции ребалансировок, которые будем передавать в метод DataFrame ().apply ():
def rebalance_simple(x):
# Простая ребалансировка по долям
data = x.unstack(1)
return (data.pct_close * data['size']).sum() / data['size'].sum()
def rebalance_sma(x):
# Ребалансировка по активам, у которых SMA50 > SMA200
data = x.unstack(1)
fltr = data['sma50'] > data['sma200']
if not data[fltr]['size'].sum():
return 1 # Баланс без изменений, если нет подходящих
return (data[fltr].pct_close * data[fltr]['size']).sum() / data[fltr]['size'].sum()
def rebalance_rsi(x):
# Ребалансировка по активам, у которых RSI100 > 50
data = x.unstack(1)
fltr = data['rsi100'] > 50
if not data[fltr]['size'].sum():
return 1 # Баланс без изменений, если нет подходящих
return (data[fltr].pct_close * data[fltr]['size']).sum() / data[fltr]['size'].sum()
def rebalance_custom(x, df=None):
# Медленная ребалансировка с уникальными условиями и внешними данными
data = x.unstack(1)
for s in data.index:
if data['dt'][s]:
fltr_dt = df['dt'] < data['rebalance_dt'][s] # исключим будущее
values = df[fltr_dt].loc[(slice(None), [s]), 'close'].values
data.loc[s, 'custom'] = 0 # обнулим значение фильтра
if len(values) > len(values[np.isnan(values)]):
# Получим RSI за 100 дней
data.loc[s, 'custom'] = talib.RSI(values, timeperiod=100)[-1]
fltr = data['custom'] > 50
if not data[fltr]['size'].sum():
return 1 # Баланс без изменений, если нет подходящих
return (data[fltr].pct_close * data[fltr]['size']).sum() / data[fltr]['size'].sum()
def drawdown(chg, is_max=False):
# Максимальная просадка доходности
total = len(chg.index)
rolling_max = chg.rolling(total, min_periods=1).max()
daily_drawdown = chg/rolling_max - 1.0
if is_max:
return daily_drawdown.rolling(total, min_periods=1).min()
return daily_drawdown
По порядку:
- rebalance_simple — самая простая функция, которая будет распределять доходность каждого актива по долям.
- rebalance_sma — функция, распределяющая капитал по активам, у которых скользящая средняя за 50 дней выше значения за 200 дней на момент ребалансировки.
- rebalance_rsi — функция, распределяющая капитал по активам, у которых значение индикатора RSI за 100 дней выше 50.
- rebalance_custom — самая медленная и самая универсальная функция, где мы будем высчитывать значения индикатора из дневной истории цен актива на момент ребалансировки. Здесь можно использовать любые условия и данные. Даже загружать каждый раз из внешних источников. Но без цикла уже не обойтись.
- drawdown — вспомогательная фукция, показывающая максимальную просадку по портфелю.
В функциях ребалансировки нам необходим массив всех данных на дату в разрезе активов. Метод DataFrame ().apply (), которым мы будем рассчитывать результаты портфелей, передаст в нашу функцию массив, где колонки станут индексом строк. А если мы сделаем мультииндекс, где нулевым уровнем будут тикеры, то к нам придёт мультииндекс. Этот мультииндекс мы сможем развернуть в двумерный массив и получить на каждой строке данные соответствующего актива.

Ребалансировка портфелей
Теперь достаточно подготовить необходимые условия и сделать в цикле расчёт для каждого портфеля. Первым делом рассчитаем индикаторы на дневной истории цен:
# Смещаем данные на 1 день вперед, чтобы не заглядывать в будущее
df['sma50'] = df.groupby(level=1)['close'].transform(lambda x: talib.SMA(x.values, timeperiod=50)).shift(1)
df['sma200'] = df.groupby(level=1)['close'].transform(lambda x: talib.SMA(x.values, timeperiod=200)).shift(1)
df['rsi100'] = df.groupby(level=1)['close'].transform(lambda x: talib.RSI(x.values, timeperiod=100)).shift(1)
Теперь сгруппируем историю под нужный период ребалансировки, используя методы, описанные выше. Будем брать при этом значения индикаторов в начале периода, чтобы исключить заглядывание в будущее.
Опишем структуру портфелей и укажем нужную ребалансировку. Портфели рассчитаем в цикле, так как нам необходимо указывать уникальные доли и условия:
# Условия портфелей: доли активов, функция ребалансировки, название
portfolios = [
{'symbols': [('SPY', 0.8), ('AGG', 0.2)], 'func': rebalance_sma, 'name': 'Portfolio 80/20 SMA50x200'},
{'symbols': [('SPY', 0.8), ('AGG', 0.2)], 'func': rebalance_rsi, 'name': 'Portfolio 80/20 RSI100>50'},
{'symbols': [('SPY', 0.8), ('AGG', 0.2)], 'func': partial(rebalance_custom, df=df), 'name': 'Portfolio 80/20 Custom'},
{'symbols': [('SPY', 0.8), ('AGG', 0.2)], 'func': rebalance_simple, 'name': 'Portfolio 80/20'},
{'symbols': [('SPY', 0.4), ('AGG', 0.6)], 'func': rebalance_simple, 'name': 'Portfolio 40/60'},
{'symbols': [('SPY', 0.2), ('AGG', 0.8)], 'func': rebalance_simple, 'name': 'Portfolio 20/80'},
{'symbols': [('DIA', 0.2), ('QQQ', 0.3), ('SPY', 0.2), ('IWM', 0.2), ('AGG', 0.1)],
'func': rebalance_simple, 'name': 'Portfolio DIA & QQQ & SPY & IWM & AGG'},
]
for p in portfolios:
# Обнуляем размер долей
rebalance['size'] = 0.
for s, pct in p['symbols']:
# Устанавливаем свои доли для каждого актива
rebalance.loc[(slice(None), [s]), 'size'] = pct
# Подготовим индекс для корректной ребалансировки и получим доходность за каждый период
rebalance_perf = rebalance.stack().unstack([1, 2]).apply(p['func'], axis=1)
# Кумулятивная доходность портфеля
p['performance'] = (rebalance_perf.rolling(len(rebalance_perf), min_periods=1).apply(np.prod) - 1)
# Максимальная просадка портфеля
p['drawdown'] = drawdown(p['performance'] + 1, is_max=True)
В этот раз нам потребуется провернуть хитрость с индексами колонок и строк, чтобы получить нужный мультииндекс в функции ребалансировки. Добьёмся этого, вызвав последовательно методы DataFrame ().stack ().unstack ([1, 2]). Данный код перенесет колонки в строчный мультииндекс, а затем вернет обратно мультииндекс с тикерами и колонками в нужном порядке.
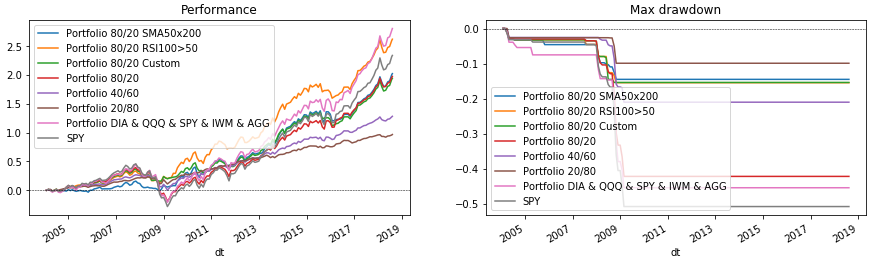
Готовые портфели на графики
Теперь осталось всё нарисовать. Для этого ещё раз запустим цикл по портфелям, который выведет данные на графики. В конце нарисуем SPY в качестве бенчмарка для сравнения.
fig = plt.figure(figsize=(15, 4), facecolor='white')
ax_perf = fig.add_subplot(121)
ax_dd = fig.add_subplot(122)
for p in portfolios:
p['performance'].rename(p['name']).plot(ax=ax_perf, legend=True, title='Performance')
p['drawdown'].rename(p['name']).plot(ax=ax_dd, legend=True, title='Max drawdown')
# Вывод доходности и просадки перед графиками
print(f"{p['name']}: {p['performance'][-1]*100:.2f}% / {p['drawdown'][-1]*100:.2f}%")
# SPY, как бенчмарк
rebalance.loc[(slice(None), ['SPY']), :].set_index('dt', drop=False).performance. \
rename('SPY').plot(ax=ax_perf, legend=True)
drawdown(rebalance.loc[(slice(None), ['SPY']), :].set_index('dt', drop=False).performance + 1,
is_max=True).rename('SPY').plot(ax=ax_dd, legend=True)
ax_perf.axhline(0, color='k', linestyle='--', lw=0.5)
ax_dd.axhline(0, color='k', linestyle='--', lw=0.5)
plt.show()
Заключение
Рассмотренный код позволяет подбирать различные структуры портфелей и условия ребалансировок. С его помощью можно быстро проверить, стоит ли, например, держать в портфеле золото (GLD) или развивающиеся рынки (EEM). Попробуйте его сами, добавьте свои условия индикаторов или подберите параметры уже описанных. (Но помните об ошибке выжившего и о том, что подгонка под прошлые данные, может не оправдать ожидания в будущем.) А после этого решите, кому вы доверите свой портфель — Python-у или финкосультантy?
Репозиторий: rebalance.portfolio
