Биржевой зодиак: Какие алгоритмы и инструменты применяются для прогнозирования движения цен акций

Сегодня мы поговорим об инструментах технического анализа, которые используют для предсказания поведения биржевых индексов. В наши задачи не входило собрать в одну кучу и подробно описать все технологические способы прогнозирования цен на фондовых рынках. По каждому из них можно найти достаточно подробную информацию в нашем блоге. Но небольшая шпаргалка была бы весьма полезна.
По-настоящему эффективную биржевую стратегию можно создать, лишь используя большинство инструментов в комплексе. Тем более что сама стратегия подразумевает несколько этапов, включая сбор и обработку данных, построение алгоритма, отладку и проверку в реальном времени. И для каждого из них можно применять разные методы и математические модели.
Математические модели предсказания цены
Оборот алгоритмической торговли на крупных фондовых площадках сегодня достигает, по некоторым данным, 70%. При этом речь уже идет не просто о том, чтобы опередить конкурентов в совершении транзакции, но и суметь предсказать движение цены. Сделать это можно, к примеру, при помощи математической формулы, учитывающей скрытую ликвидность рынка при данной ликвидности заявок на покупку и продажу. «Истощение» очереди заявок на покупку или продажу может свидетельствовать о скором движении цены.
Изменение возникает, когда на одном из уровней цены исчезают все заявки на покупку или продажу, и существует следующий уровень цен бид и аск.
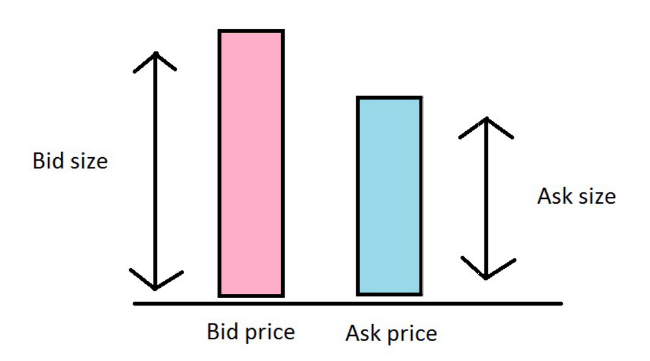
В одном из наших предыдущих материалов мы рассматривали формулу, позволяющую высчитать вероятность того, что очередь заявок аск истощится ранее, чем очередь заявок бид.
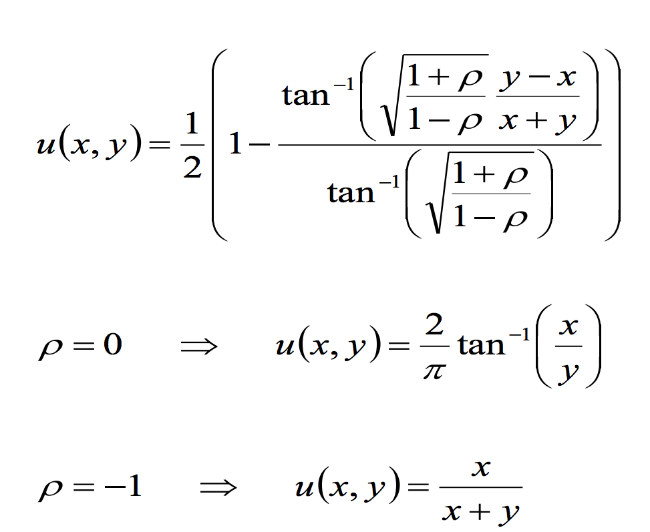
Формула для расчета вероятности повышения цены выглядела так:
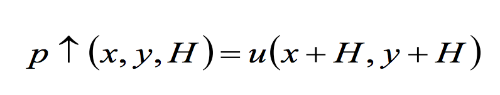
, где H — скрытая ликвидность рынка, то есть сделки, которые неизвестны широкой общественности (например, сделки крупных финансовых организаций, которые заключаются за пределами бирж).
Сама процедура анализа выглядит следующим образом:
- Для начала собранные данные разделяются по биржам, за один раз анализируется один торговый день.
- Котировки значений бид и аск компонуются по децилям (). Для каждого такого набора вычисляется частота повышения цены.
- Подсчитывается число появлений каждой величины.
- Производится анализ соответствия модели с помощью метода наименьших квадратов.
Нужно четко осознавать, что на фондовые индексы, помимо чисто экономических факторов, влияет масса посторонних вещей. Поэтому математическая модель для таких нелинейных, непредсказуемых рядов будет крайне сложно создать. Но использовать ее как основу для более сложных стратегий вполне возможно.
Машинное обучение и Big Data
Машинное обучение — самое, пожалуй, востребованное и многообещающее направление сложных финансовых расчетов. В нашем блоге ему, также как и, вообще, работе с большими данными, посвящена серия материалов (мы писали об этом, например, здесь и здесь).
Сам процесс машинного обучения состоит из нескольких шагов: от выбора математических и программных инструментов, сбора входных данных, до выработки предсказаний и тестирования. Самый простой способ — это создание с помощью машинного обучения модели на основе исторических данных, ее тестирование и дальнейшее применение для генерирования прогнозов будущего движения цен.
Проще всего понять работу этой модели на конкретном примере. Вот в этой статье довольно подробно, пошагово описывается успешный опыт применения стратегии машинного обучения.
Модель подразумевает создание фреймворка, симулирующего торги, который должен максимально точно воссоздать поведение реального рынка. В него закладывается тренировочный набор данных, позволяющий системе обучаться на них. Затем создается или подбирается алгоритм, отвечающий за предсказание движения цен и организацию торгов. Можно интегрировать уже готовые алгоритмы. Например, скрытые Марковские Модели, искусственные нейронные сети, алгоритм бустинга, наивный байесовский классификатор, метод опорных векторов, дерева решений, дисперсионный анализ и множество других.
Дальнейшие действия будут зависеть от используемого алгоритма (конкретные примеры можно посмотреть по ссылкам выше). Обычно за этим следует выбор, создание и оптимизация индикаторов, которые будут участвовать в прогнозе. Они, по большому счету, привязаны к повышению или понижению цены. На основе кривых изменения индикаторов можно создать формулу для более точного предсказания цены. Протестировать получившийся алгоритм можно на исторических данных.
Еще один интересный подход к использованию машинного обучения для прогнозирования цен акций — это его применение к прогнозам финансовых аналитиков. Подобный механизм работает примерно так:
На вход системы подаются мнения экспертов рынка акций (просто их мнение, которое необязательно оказывается верным), а затем на основе их прогнозов раз за разом делаются предсказания возможного движения цены. На каждой итерации вес эксперта, чье предсказание оказалось верно, повышается, а у тех, кто ошибся — наоборот снижается.

Такую технику взвешивания на основе экспертных мнений можно рассматривать в качестве гибридного подхода, комбинирующего в себе фундаментальный и технический анализ — эксперты делают прогнозы на основе фундаментального анализа, а алгоритм впоследствии использует их для генерирования собственных прогнозов с помощью методов технического анализа.
Алгоритм адаптивной фильтрации
Алгоритм адаптивной фильтрации широко применяется в радиоэлектронике в качестве системы цифровой обработки данных. Если не вдаваться в подробности, адаптивный фильтр — это самообучающаяся система, нацеленная на достижение максимального соответствия анализируемых данных на выходе реальному положению дел.
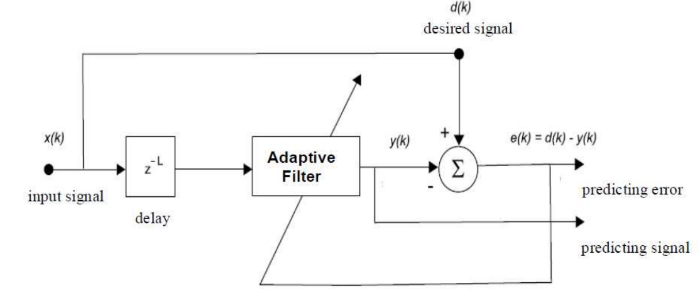
Блок-диаграмма адаптивного фильтра для предсказания сигналов
Суть метода в том, что мы можем быстро и четко реагировать на изменения входных данных для получения точных прогнозов. На практике адаптивные алгоритмы реализуются двумя классическими методами — методом градиента и наименьших квадратов (LMS и RLS).
В свое время LMS-фильтр успешно применялся для предсказания трафика в беспроводных сетях. Бразильским ученым пришла в голову идея опробовать этот алгоритм в биржевой торговле. Они создали модуль для предсказания движения цены одной из компаний. Для этого использовался адаптивный цифровой FIR-фильтр со 100 реальными коэффициентами. В качестве алгоритма адаптации был использован RLS с коэффициентом забывания 0,98. Симуляция производилась на платформе MATLAB.
Испытания с различными параметрами показали, что применение адаптивного фильтра позволяет добиться прибыли в среднем 7% от вложенных средств.
Генетические алгоритмы
Еще один свежий тренд в области алгоритмической торговли — это генетические алгоритмы. Это поисковые алгоритмы, применяющиеся в системах, где точные взаимоотношения элементов неизвестны или вовсе отсутствуют.
Как это работает: ставится задача, формализованная таким образом, чтобы на выходе возникло решение, закодированное в виде вектора генов («генотип»). Гены — это любые объекты, числа, биты. Далее случайным образом создается множество генотипов начальной «популяции», которые оцениваются с помощью специальной функции приспособленности. В итоге каждому генотипу присваивается значение «приспособленности» — именно оно определяет, насколько хорошо он решает задачу.
В своем блоге мы писали о работе ученых из исламского университета Азад, в которой речь идет о прогнозировании поведения фондовых индексов через сочетание методов генетического алгоритма, нейронных сетей и data mining с использованием опорных векторов.
При этом data mining отвечает за сбор информации и упорядочивание данных в модели классификации. Генетический алгоритм настраивает систему. Для того чтобы ее оптимизировать, каждый ген рассматривается в виде вектора, а соответствующий алгоритм оптимизации применяет к нему механизм промежуточной рекомбинации. Генерируются предсказания через метод опорных векторов (частный случая машинного обучения). Точность предсказаний для NASDAQ, сгенерированных системой, составила 74.4%.
Анализ новостей
Тем, что новости могут серьезно влиять на фондовый рынок, сегодня никого не удивишь. Примеры того, как то или иное событие (иногда фейковое) «обрушило» рынок появляются с завидной регулярностью — иногда создатели таких фейков затем испытывают проблемы с законом. Но немногие оказались способны превратить манипуляции экономическими новостями в настоящее искусство.

В 2015 году 62-летний шотландец Алан Крейг создал два поддельных твиттер-аккаунта аналитических компаний и разместил в них новости о проблемах торгующихся на бирже компаний. На графике показан рост цен одной из таких компаний после публикации фейковой новости и их падение после ее опровержения
На рынке появляются системы анализа, использующие публикации в СМИ и социальных сетях для совершения транзакций. Ведутся работы по созданию систем, которые будут способны самостоятельно создавать статьи, основываясь на данных новостных лент, с их последующей выкладкой в сеть для провоцирования тех, кто не обладает полнотой информации, на покупку или продажу активов.
Еще в 2013 году исследователи из бизнес-школы Уорика (Warwick Business School) опубликовали результаты эксперимента, в ходе которого в качестве инструмента для прогнозирования трендов фондового рынка использовался поисковик Google, и в частности, сервис Google Trends.
Он позволяет работать с информацией о поисковых запросах, ранжированных по популярности. Исследователи предположили, что существует корреляция между увеличением числа поисковых запросов по тем или иным политическими и экономическими темам и значимыми событиями на фондовых рынках.
Очевидно, что перед тем, как принять решение, люди пытаются через поисковик узнать как можно больше. Информация о поисковых запросах о темах, которые могут влиять на цены акций, может свидетельствовать о скором развороте рыночного тренда — раз уже простые люди, а не профессиональные аналитики, интересуются делами на бирже, то это верный признак того, что назревает разворот тренда.
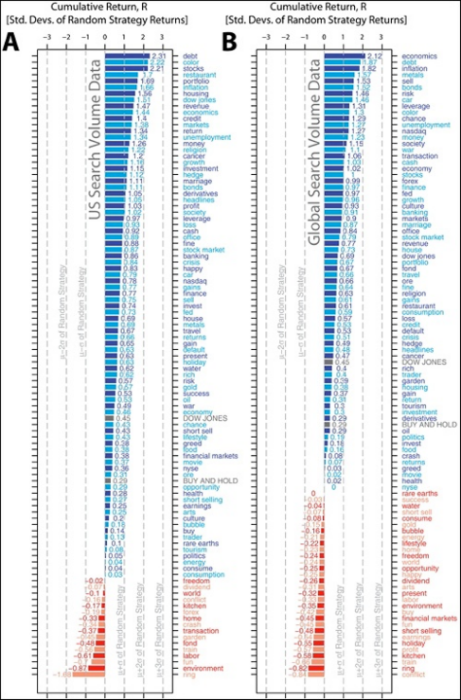
Созданный в рамках эксперимента ученых симулятор инвестиционной игры показал впечатляющие результаты. Например, самым надежным для США оказалось слово «долг». Отслеживая рынки только по нему, ученые увеличили свой гипотетический портфель ценных бумаг на 326% за семь лет. При моделировании стандартной стратегии торгов, которая не учитывала частоту поисковых запросов, им удалось добиться прироста лишь в 16%.
Другие материалы по теме онлайн-трейдинга в блоге ITinvest:
