Библиотека быстрого поиска путей на графе
Привет, Друзья!
Я написал библиотеку поисков путей на произвольных графах, и хотел бы поделиться ей с вами: http://github.com/anvaka/ngraph.path
Пример использования на огромном графе:
Поиграться с демо можно здесь: https://anvaka.github.io/ngraph.path.demo/
В библиотеке используется мало-известный вариант A* поиска, который называется NBA*. Это двунаправленный поиск, с расслабленными требованиями к функции-эвристике, и очень агрессивным критерием завершения. Не смотря на свою малоизвестность у алгоритма отличная скорость сходимости к оптимальному решению.
Описание разных вариантов A* уже не раз встречалось на хабре. Мне очень понравилось вот это, потому повторяться в этой статье я не буду. Под катом расскажу подробнее почему библиотека работает быстро и о том, как было сделано демо.
Почему библиотека работает быстро?
«Как-то не верится что так быстро. Ты точно ниче не считаешь предварительно?»
Реакция друга, который первый раз увидел библиотеку.
Сразу должен признаться, я не верю что моя реализация — самая быстрая из возможных. Она работает достаточно быстро учитывая окружение в котором находится (браузер, javascript). Ее скорость сильно будет зависеть от размера графа. И, конечно же, то, что сейчас есть в репозитории можно ускорить и улучшить.
Статистика
Для замера производительности я взял граф дорог из Нью-Йорка (~730 000 ребер, 260 000 узлов). Таблица ниже показывает статистику времени, необходимого для решения одной задачи поиска пути из 250 случайно выбранных:
| Среднее | Медиана | Min | Max | p90 | p99 | |
|---|---|---|---|---|---|---|
| A* ленивый (локальный) | 32ms | 24ms | 0ms | 179ms | 73ms | 136ms |
| NBA* | 44ms | 34ms | 0ms | 222ms | 107ms | 172ms |
| A*, однонаправленный | 55ms | 38ms | 0ms | 356ms | 123ms | 287ms |
| Дейкстра | 264ms | 258ms | 0ms | 782ms | 483ms | 631ms |
Каждый алгоритм решал одну и ту же задачу. A* ленивый самый быстрый, но его решение не всегда оптимально. По-сути, это двунаправленный A* который сразу же выходит как только оба поиска встретились. NBA* двунаправленный, сходится к оптимальному решению. В 99% ему понадобилось меньше чем 172 миллисекунды, чтобы найти кратчайший путь (p99).
Оптимизации
Библиотека работает относительно быстро по нескольким причинам.
Во-первых, я изменил структуру данных в приоритетной очереди таким образом, что обновление приоритета любого элемента очереди занимает O(lg n) времени. Это достигается тем, что каждый элемент отслеживает свою позицию в куче во время перестройки очереди.
Во-вторых, во время нагрузочных тестов я заметил, что уборка мусора занимает значительное время. Это не удивительно, поскольку алгоритм создает много маленьких объектов когда он ходит по графу. Решается проблема со сборщиком мусора при помощи пула объектов. Это структура данных которая позволяет повторно использовать объекты, когда они уже не нужны.
Ну и наконец, алгоритм поиска NBA* имеет очень красивый и жесткий критерий посещения узлов.
Признаться, я думаю что это не предел совершенства. Вполне вероятно, если использовать иерархический подход, описанный Борисом удастся ускорить время для еще больших графов.
Как работает демо?
Создание библиотеки это, конечно, очень интересно. Но мне кажется демо-проект заслуживает отдельного описания. Я усвоил несколько уроков, и хотел бы поделиться с вами, в надежде, что это окажется полезным.
Прежде чем начнем. Кто-то меня спросил: «Но ведь это же граф? Как можно карту представить в виде графа?». Легче всего представить каждый перекресток узлом графа. У каждого перекрестка есть позиция (x, y). Каждый прямой участок дороги сделаем ребром графа. Изгибы дороги можно моделировать как частный случай перекрестков.
Готовим данные
Конечно, я слышал об https://www.openstreetmap.org, но их внешний вид меня не сильно привлекал. Когда же я обнаружил API и инструменты типа http://overpass-turbo.eu/ — это как новый мир открылся перед глазами :). Данные они отдают под лицензией ODbL, которая требует чтобы их упомянули (чем больше людей знают о сервисе — тем лучше становится сервис).
API позволяет делать очень сложные запросы, и дает потрясающие объемы информации.
Например, такой запрос даст все велодороги в Москве:
[out:json];
// Сохранить область в переменную `a`
(area["name"="Москва"])->.a;
// Скачать все дороги внутри a у которых аттрибут `highway == cycleway`
way["highway"="cycleway"](area.a);
// и объединить дороги с узлами графа (узлы содержат геопозицию)
node(w);
// Наконец, вернуть результаты
out meta;API очень хорошо описано здесь: http://wiki.openstreetmap.org/wiki/Overpass_API
Я написал три маленьких скрипта, чтобы автоматизировать получение дорог для городов, и сохранять их в мой формат графа.
Сохраняем граф
Данные OSM отдает в виде XML или JSON. К сожалению оба форматы слишком объемные — карта Москвы со всеми дорогами занимает около 47MB. Моя же задача была сделать загрузку сайта как можно быстрее (даже на мобильном соединении).
Можно было бы попробовать сжать gzip'ом — карта Москвы из 47МБ превращается в 7.1МБ. Но при таком подходе у меня не было бы контроля над скоростью распаковки данных — их бы пришлось парсить javascript’ом на клиенте, что тоже повлияло бы на скорость инициализации.
Я решил написать свой формат для графа. Граф разбивается на два бинарных файла. Один с координатами всех вершин, а второй с описанием всех ребер.
Файл с координатами — это просто последовательность из x, y пар (int32, 4 байта на координату). Смещение по которому находится пара координат я рассматриваю как иденификатор вершины (nodeId).

Ребра графа превращаются в обычную последовательность пар fromNodeId, toNodeId.

Последовательность на картинке означает, что первый узел ссылается на второй, а второй ссылается на третий, и так далее.
Общий размер для графа с V узлами и E ребрами можно подсчитать как:
storage_size = V * 4 * 2 + # 4 байта на пару координат на узел
E * 4 * 2 = # 4 байта на пару идентификаторов вершин
(V + E) * 8 # суммарно, в байтахЭто не самый эффективный способ сжатия, но его очень легко реализовать и можно очень быстро восстановить начальный граф на клиенте. Типизированные массивы в javascript’e работают быстрее, чем парсинг JSON’a.
Сначала я хотел добавить также вес ребер, но остановил себя, ибо загрузка на слабом мобильном соединении даже для маленьких графах станет еще медленнее.
В первую очередь мобильные телефоны
Когда я писал демо, я думал, что напишу о нем в Твиттер. Твиттер большинство людей читают с мобилок, а потому и демо должно быть в первую очередь рассчитано на мобильные телефоны. Если оно не будет загружаться быстро, или не будет поддерживать touch — пиши пропало.
Спустя пару дней после анонса, можно признать логику выше оправданной. Твит с анонсом демо стал самым популярным твитом в жизни моего твиттера.
Я тестировал демо в первую очередь на платформах iPhone и Андроид. Для тестов на Андроиде я нашел самый дешевый телефон и использовал его. Это очень сильно помогло с отладкой производительности и удобства использования на маленьком экране.
Асинхронность
Самая медленная часть в демо была начальная загрузка сайта. Код, который инициализировал граф выглядел как-то так:
for (let i = 0; i < points.length; i += 2) {
let nodeId = Math.floor(i / 2);
let x = points[i + 0];
let y = points[i + 1];
// graph это https://github.com/anvaka/ngraph.graph
graph.addNode(nodeId, { x, y })
}На первый взгляд — ничего плохого. Но если запустить это на слабеньком процессоре и на большом графе — страничка становится мертвой, пока основной поток занят итерацией.
Выход? Я знаю, некоторые используют Web Workers. Это прекрасное решение, учитывая что все сейчас многоядерное. Но в моем случае, использование web workers значительно бы продлило время, необходимое для создания демо. Нужно было бы продумать как передавать данные между потоками, как синхронизировать, как сохранить жизнь батарее, как быть когда web workers не доступны и т.д.
Поскольку мне не хотелось тратить больше времени, нужно было более ленивое решение. Я решил просто разбить цикл. Просто запускаем его на некоторое время, смотрим сколько времени прошло, и потом вызываем setTimeout() чтобы продолжить на следующей итерации цикла событий. Все это сделано в библиотеке rafor.
С таким решением у браузера появляется возможность постоянно информировать пользователя о том, что происходит внутри:

Отрисовка
Теперь, когда у нас загружен граф, нужно показать его на экране. Конечно, использовать SVG для отрисовки миллиона элементов не годится — скорость начнет проседать после первого десятка тысяч. Можно было бы нарезать граф на тайлы, и использовать Leaflet или OpenSeadragon чтоб нарисовать большую картинку.
Мне же хотелось иметь больше контроля на кодом (и подучить WebGL), поэтому я написал свой WebGL отрисовщик с нуля. Там я использую подход «scene graph». В таком подходе мы строим сцену из иерархии элементов, которые можно нарисовать. Во время отрисовки кадра, мы проходим по графу, и даем возможность каждому узлу накопить трансформации или вывести себя на экран. Если вы знакомы с three.js или даже обычным DOM’ом — подход будет не в новинку.
Отрисовщик доступен здесь, но я намеренно не документировал его сильно. Это проект для моего собственного обучения, и я не хочу создавать впечатление, что им можно пользоваться :)
Батарейка

Изначально, я перерисовывал сцену на каждом кадре. Очень быстро я понял, что это сильно греет телефон и батарея уходит в ноль с примечательной скоростью.
Писать код при таких условиях было так же неудобно. Для работы над проектом, я обычно заседал в кофейне в свободное время, где не всегда были розетки. Поэтому мне нужно было либо научиться думать быстрее, либо найти способ не сажать ноутбук так быстро.
Я до сих пор не нашел способ как думать быстрее, потому я выбрал второй вариант. Решение оказалось по-наивному простым:
Не рисуй сцену на каждом кадре. Рисуй только когда попросили, или когда знаешь, что она поменялась.
Может, это покажется слишком очевидным сейчас, но это было вовсе не так сначала. Ведь в основном все примеры использования WebGL описывают простой цикл:
function frame() {
requestAnimationFrame(frame); // Планируем следующий кадр
renderScene(); // рисуем текущий кадр.
// Ничего плохого в этом нет, но батарею мы можем так быстро посадить
}С «консервативным» подходом, мне нужно было вынести requestAnimationFrame() наружу из функции frame():
let frameToken = 0;
function renderFrame() {
if (!frameToken) frameToken = requestAnimationFrame(frame);
}
function frame() {
frameToken = 0;
renderScene();
}Такой подход позволяет кому угодно затребовать нарисовать следующий кадр. Например, когда пользователь перетащил карту и изменил матрицу преобразования, мы вызываем renderFrame().
Переменная frameToken помогает избежать повторного вызова requestAnimationFrame между кадрами.
Да, код становится немного сложнее писать, но жизнь батарее для меня была важнее.
Текст и линии
WebGL не самый простой в мире API. Особенно сложно в нем работать с текстом и толстыми линиями (у которых ширина больше одного пикселя).
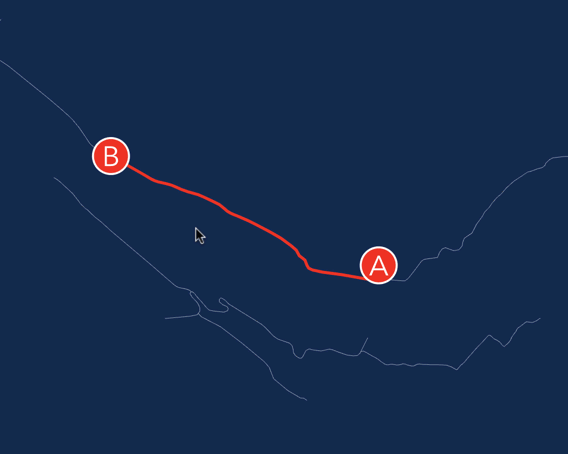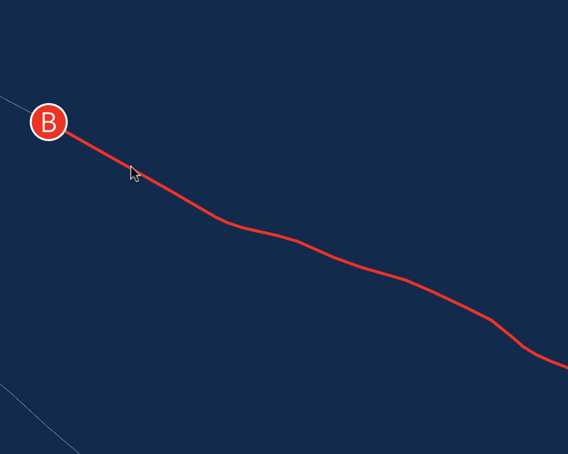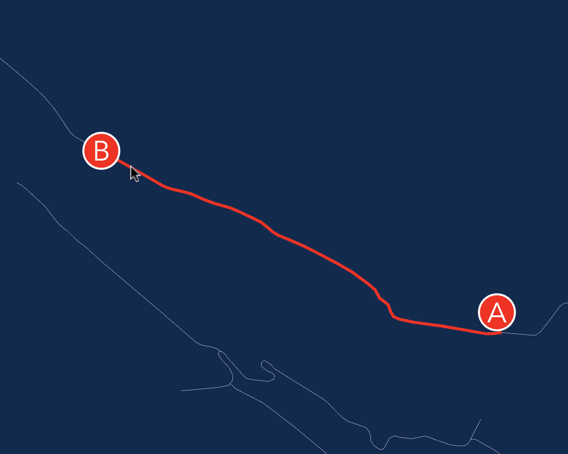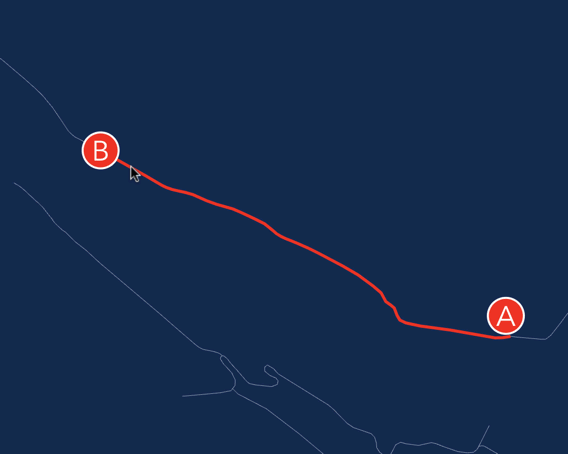
Учитывая что я совсем новичок в этом деле, я быстро понял, что добавить поддержку текста/линий займет у меня очень много времени.
С другой стороны, из текста мне нужно было нарисовать только пару меток A и B. А из толстых линий — только путь который соединяет две вершины. Задача вполне по силам для DOM’a.
Как вы помните, наш отрисовщик использует граф сцены. Почему бы не добавить в сцену еще один элемент, задачей которого будет применять текущую трансформацию к… SVG элементу? Этот SVG элемент сделаем прозрачным, и положим его сверху на canvas. Чтобы убрать все события от мышки — ставим ему pointer-events: none;.

Получилось очень быстро и сердито.
Перемещаемся по карте
Мне хотелось сделать так, чтобы навигация была похожа на типичное поведение карты (как в Google Maps, например).
У меня уже была написана библиотека навигации для SVG: anvaka/panzoom. Она поддерживала touch и кинетическое затухание (когда карта продолжает двигаться по инерции). Для того чтобы поддерживать WebGL мне пришлось чуть-чуть подправить библиотеку.
panzoom слушает события от пользователя (mousedown, touchstart, и т.п.), применяет плавные трансформации к матрице преобразования, и потом, вместо того чтобы напрямую работать с SVG, она отдает матрицу «контроллеру». Задача контроллера — применить трансформацию. Контролер может быть для SVG, для DOM или даже мой собственный контроллер, который применяет трансформацию к WebGL сцене.
Как понять что кликнуто?
Мы обсудили как загрузить граф, как его нарисовать, и как двигаться по нему. Но как же понять что было нажато, когда пользователь касается графа? Откуда прокладывать путь и куда?
Когда пользователь кликнул на карту, мы могли бы самым простым способом обойти все точки в графе, посмотреть на их позиции и найти ближайшую. На самом деле, это отличный способ для пары тысяч точек. Если же число точек превышает десятки/сотни тысяч — производительность будет не приемлема.
Я использовал квад дерево чтобы проиндексировать точки. После того как дерево создано — скорость поиска ближайшего соседа становится логарифмической.
Кстати, если термин «квад дерево» звучит устрашающе — не стоит огорчаться! На самом деле квад-деревья, очень-очень похожи на обычные двоичные деревья. Их легко усвоить, легко реализовать и легко применять.
В частности, я использовал собственную реализацию, библиотека yaqt, потому что она неприхотлива по памяти для моего формата данных. Существуют лучшие альтернативы, с хорошей документацией и сообществом (например, d3-quadtree).
Ищем путь
Теперь все части на своих местах. У нас есть граф, мы знаем как его нарисовать, знаем что было на нем нажато. Осталось только найти кратчайший путь:
// pathfinder это объект https://github.com/anvaka/ngraph.path
let path = pathFinder.find(fromId, toId);Теперь у нас есть и массив вершин, которые лежат на найденном пути.
Заключение
Надеюсь, вам понравилось это маленькое путешествие в мир графов и коротких путей. Пожалуйста, дайте знать если библиотека пригодилась, или если есть советы как сделать ее лучше.
Искренне желаю вам добра!
Андрей.
