Безопасность CI/CD. Часть 2. Давайте рассмотрим как защитить ваши пайплайны
Безопасность CI/CD. Часть 2.
Читатели! Всем добра и веселых новогодних! Меня зовут Моисеев Андрей, в ИБэшечке я уже более 5 лет. Сейчас работаю DevSecOps в компании Bimeister. Опыт подсказывает, что часто R&D не понимает что от них хотят безопасники и зачем все это нужно делать. Поэтому я надеюсь данная статья поможет разобраться хотя-бы в проблемах CI/CD и станет чуть более понятно с чем приходится иметь дело DevSecOps в вашей компании — ну либо подскажет им что можно прикрутить, чтобы стало еще секъюрнее.
Зачем вы здесь
Эта статья написана по мотивам выступления на конференции Saint Highload 2023 (link) c моим коллегой Алексеем Федулаевым. Видео выступления доступно по ссылке: link.
Если вы наткнулись на эту статью, то предполагаю что вы неравнодушны к инфосеку, ну или просто захотели прочитать продолжение первой части, написанной моим коллегой Артёмом Пузанковым (link).
Ну, а если вы зашли случайно, то, ознакомится не помешает — так вы сможете понять и простить принять боль ваших коллег со стороны инфосека.
Данная статья обзорная, а ее цель — познакомить вас с лучшими практиками по построению безопасных пайплайнов. Если вы DevOps, DevSecOps, специалист служб It, разработчик или четырехрукий шива-эникейщик — вы по адресу. Каких-то особых подробностей или невероятных открытий в рамках этой статьи не предвидится, так что сложных вещей будет по минимому. Так совпало, что в начале года вышла новенькая top 10 от OWASP — на нее мы и будем опираться в этой статье.
P.S. это вторая часть и тут вы найдете только 6–10 пункты. Полный список найдете тут https://owasp.org/www-project-top-10-ci-cd-security-risks/.
О чем пойдет речь
Задавались ли вы вопросом безопасности при написании кода? Может быть используете статический анализ кода (SAST), или динамический анализ (DAST), а может уделяете пристальное внимание зависимостям ПО (SCA)? Хорошо если так. Кстати, если вы не знакомы с этими терминами — почитать можно вот здесь https://www.clouddefense.ai/the-differences-between-sca-sast-and-dast/.
Ладно про код понятно, а задумывались ли вы, что технологии применяемые для сборки и доставки ПО это по сути такой же, кем-то написанный код, а что мы всегда можем найти в коде? Правильно! Баги. Но некоторые баги более опасны чем другие и могут влиять на вашу безопасность — приводить к утечкам критичной информации или же просто превратить ваш продукт в кирпич (это кстати уязвимости). При этом, даже те самые сканеры безопасности, которые должны искать уязвимости и разрабатываются людьми с высоким уровнем компетенций в инфобезе не защищены от наличия уязвимостей в своем коде. Но это не удивительно, ведь новые уязвимости и вектора атак появляются намного быстрее, чем разрабатывается защита от них. Кстати за примерами далеко ходить не надо, вот к примеру уязвимость, обнаруженная в Snyk Kubernetes Monitor — анализатор безопасности кластера и образов контейнеров:

Информация с nvd.nist
Возвращаясь к нашей теме CI/CD, если мы обратимся к https://owasp.org/www-project-top-ten/ то увидим, что из 10 самых распространенных уязвимостей в 2021 году, к проблемам CI/CD так или иначе можно отнести более половины:
A01_2021-Broken_Access_Control
A03_2021-Injection
A05_2021-Security_Misconfiguration
A07_2021-Identification_and_Authentication_Failures
A08_2021-Software_and_Data_Integrity_Failures
A09_2021-Security_Logging_and_Monitoring_Failures/
Этот список уже не раз рассмотрен, почитать про них можно в интернете. Вместо этого я просто оставлю интересную bingo like картинку, которую мы подготовили с моим коллегой Алексеем Федулаевым про антипаттерны, которые можно часто встретить у себя.
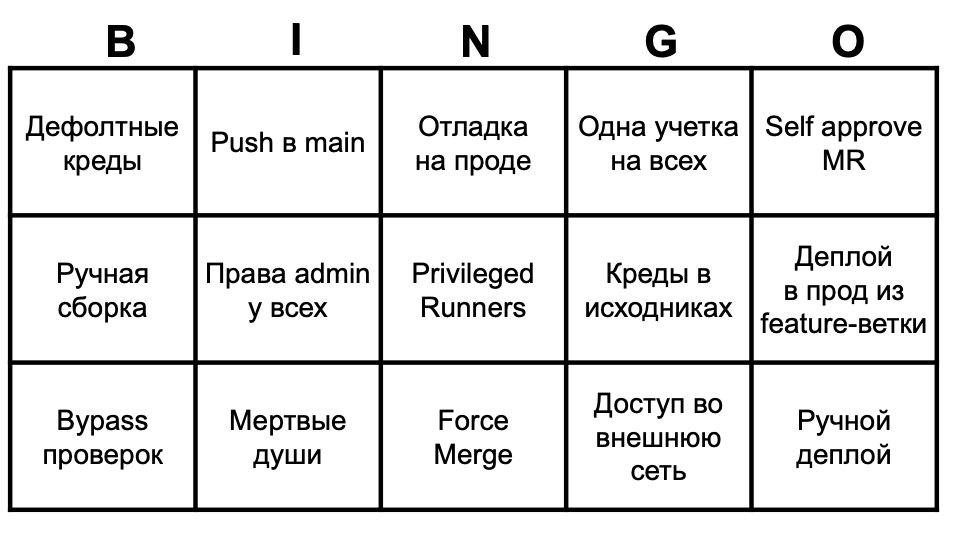
Антипаттерны безопасности
Ну и последнее — безопасность это всегда вопрос компромисса ресурсов — не существует серебряной пули, которая исправит все проблемы, но даже небольшое улучшение, может снизить вероятность успешной атаки. Важно понимать, что злоумышленник — это такой же человек, который действует ради выгоды, а любые сложности снижают эту самую выгоду, ведь ему нужно тратить время и вскрывать дополнительные замки. Поставьте себя на его место — если выбор стоит между открытой дверью и дверью за семью замками очевидно какую стоит открыть первой.
Давайте наконец перейдем к ключевым моментам на которые следует обратить внимание для построения безопасных пайплайнов.
Недостаточная «гигиена» секретов
CICD-SEC-06-Insufficient-Credential-Hygiene
Секреты используются везде, API-интеграции, yaml-манифесты IAC, .txt в репозиториях. Найти их можно где угодно. Чаще всего проблема возникает в момент настройки сервисов или разворачивания новых экземпляров продукта. К примеру после настройки легко забыть обновить пароль. Или разработчик для удобства может хранить учетные данные в своем репозитории. И такая халатность может привести к тому, что разработчик (или кто-то под его учеткой) может получить доступ к внутренней инфраструктуре компании и использовать ее мощности себе на благо. Например поднять свой личный nginx или помочь вашим админам пофармить крипту. Так что же стоит принять во внимание?
Секреты везде
Часто разработчики могут забыть, куда сохранили ключи от репозитория или указывать креды напрямую в коде, если в первом случае вы можете использовать локальный репозиторий в компании и в принципе с этим можно жить дальше, то во втором, любой простенький реверс приведет к получению учетных данных злоумышленником. Вот пара примеров, где вы можете встретить ваши секреты.
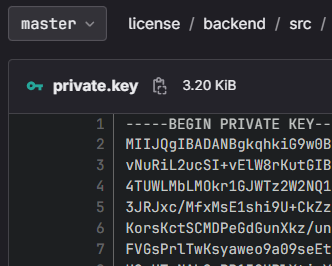
Пример 1. Секреты в репозитории

Пример 2. Секреты в cfg
Небезопасная передача секретов
Секреты, которые используются в процессах сборки и развертывания, для доступа к репозиториям кода, взаимодействия с артефактами, в том числе на стороне заказчика могут передаваться небезопасным способом. Учитывая большое количество целевых систем и сервисов, к которым необходим доступ, необходимо осознавать фактическую картину -, а именно как реализовано управление вашими секретами. Может ли не проверенный код получить доступ к секретам? А может вы просто передаете свои креды в slack или teams? Можете ли вы гарантировать, что доступ к этим чатам есть только у проверенных сотрудников или доверяете ли вы на 100% этому вендору?
Учетные данные в ваших IaC
В Dockerfile могут остаться учетные данные привилегированного пользователя, учетная запись которого использовалась при создании и настройке сервиса. Или могут быть дефолтные креды для различных API, получение которых позволит взаимодействовать с этими API, а если еще и используются привилегированные учетки — можно вообще перенастроить ваши сервисы на свой лад. Кстати если вы используете кубер, чарты, вот это вот все — не стоит забывать про values.
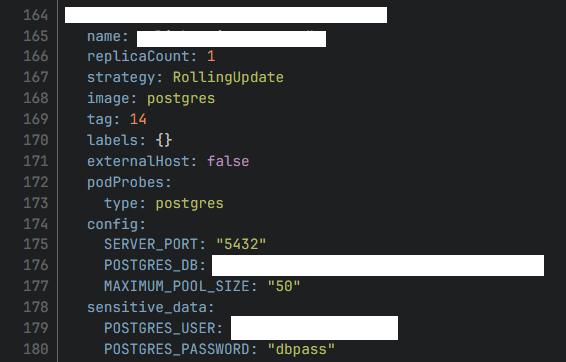
Секреты в values.yaml
Как организовать работу с секретами правильно
Первое — проводим генеральную уборку.
Чтобы подчистить ваши конфигурационные файлы и проверить репозитории, стоит воспользоваться решениями типа secret detection — например из open-source с такими задачами отлично справится https://github.com/gitleaks/gitleaks.
Можно использовать его в вашем пайплайне. При каждом merge-request будет запускаться проверка, на основе результатов которой можно будет блокировать сборку или разрешать.
Вот так выглядит лог работы сканера, на котором видно, что он обнаружил 4 потенциальные утечки секретов в анализируемом репозитории

Лог анализатора
А вот так выглядит отчет — указывается что и где было обнаружено, в нашем случае приватный ключ в репозитории, добавленный в конкретном коммите.
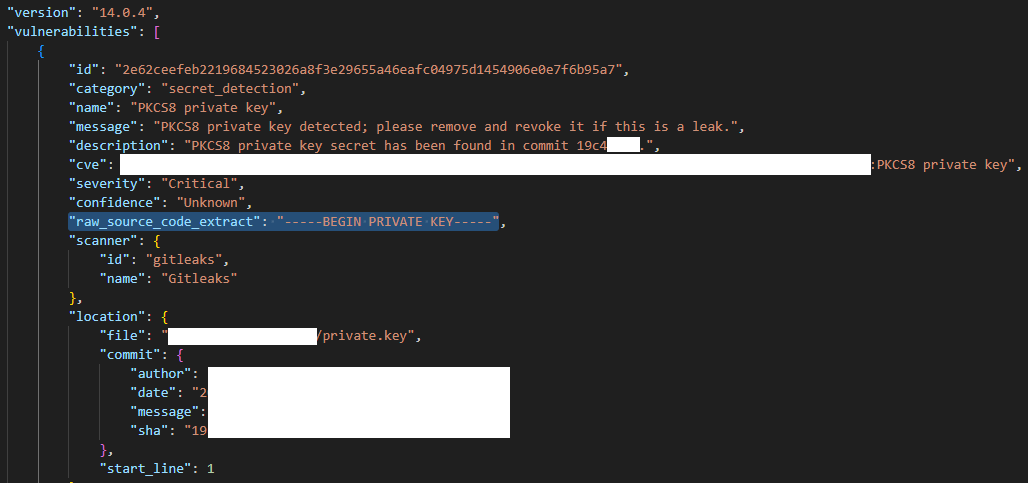
Результат работы анализатора
Далее мы просто исправляем то, что нашли и секретики уже не так заметны.
Второе — грамотно выстраиваем процессы
Все что связано с управлением секретами внутри компании и передачей сборок продукта вовне, должно быть заранее определено и протестировано. К примеру должны быть организованы процедуры выдачи и отзыва сертификатов (с проверкой их валидности и срока их жизни). Доступ к секретам должен контролироваться, а хранение секретов должно быть безопасным, тут может помочь использование хранилища секретов. Не стоит забывать и про процедуры ротации секретов — учетки (креды) сотрудников должны быть удалены после их увольнения или изменения уровня доступа (при переходе в другую команду или отдел).
Небезопасная конфигурация
CICD-SEC-07-Insecure-System-Configuration
Что такое CI/CD? Набор скриптов, утилит, сервисов, систем контроля версий, систем мониторинга, сборки, развертывания… В общем — много разных, сильно связанных (а может быть и нет) сервисов, которые к тому же имеют разные API, общаются по различным протоколам и т.д. Всех их объединяет одно: они должны быть настроены и уметь взаимодействовать между собой. Из-за такого разношерстного зоопарка возникает ситуация, когда предусмотреть все — просто невозможно, в некоторых ситуациях настройки могут быть безопасны прямо из коробки (крайне редко), но как только мы добавляем другие сервисы или настраиваем очередную интеграцию — нарушается консистентность системы и могут появляться новые вектора атаки на продукт. Поэтому важно всегда следить за тем, что вы используете и понимать как оно работает, как минимум круто, когда есть архитектурная схема к которой всегда можно обратиться.
Если вы защищаете свой код, фиксите уязвимости, постоянно сканируете SAST’ами — вы молодцы! Честно — это круто, но обеспечение безопасности это всеобъемлющий процесс, и наличие одной маленькой незапатченной проблемы приведет к обесцениванию вашего труда. Всегда стоит держать в уме, что ваш код выполняется на какой-то инфраструктуре, а уязвимости в ней намного проще и быстрее найти, нежели 0-day в проприетарном коде. Зачем злоумышленнику исследовать ваш код и искать сложно эксплуатируемые уязвимости, если можно просто загуглить эксплойт на https://www.exploit-db.com/ и сломать вас?
Теперь давайте представим ситуацию: приходит менеджер и говорит «нужно поднять сервис Х в кратчайшие сроки». Обычное дело — да? Ну без проблем, подняли сервис, сдали задачу. Внезапно нужно поднять какой-то другой сервис, а 5 минут назад что-то сломалось и надо починить, а завтра уже релиз — все должно быть готово, а тут еще приходит какой-то DevSecOps и говорит, что все нужно переделать. Нет ничего более постоянного, чем временное — важнейшая проблема при разворачивании новых систем.
Многие считают, что пока проблема не стреляет — тратить время на нее бессмысленно. Кто при настройке задумывается, о том, что учетки admin-admin потом надо бы переделать? А закрыть дефолтные порты? А стоит! Хотя бы обеспечить безопасность всех настроек, реализовать аутентификацию, авторизацию уже покроет 80% всех проблем.
Настройки по умолчанию небезопасны
При использовании каких-либо сервисов или утилит из коробки без допиливания напильником, они не будут безопасными в 99% случаев. Следовательно нужно улучшить состояние безопасности, отключив например не используемые протоколы, или небезопасные методы. Существует термин — hardening — укрепление или усиление защищенности вашего приложения/сервиса/сервера с целью минимизации возможности атаки. Есть руководства, которые достаточно полно описывают что нужно сделать к примеру одно из них https://www.cisecurity.org/cis-benchmarks. С моей точки зрения наиболее распространенная проблема это избыточные привилегии. Наличие прав на выполнение или запись на конечном устройстве может привести к наличию возможности у злоумышленника редактировать ваши файлы конфигурации или подменять их на вредоносные скрипты, которые будут выполнены при подгрузке этих самых файлов. Ведь для запуска скриптов (эксплойтов) нужны права на этот самый запуск, иногда достаточно просто положить файл в нужную папку, чтобы он получил права на выполнение.
Dependency confusion
Отдельно решил выделить данный пункт, т.к. напрямую относится к конфигурации продукта — данная атака известна также как dependency hijacking. В базовом варианте реализации возможна за счет проблемы с именованием компонентов и приоритетами в менеджерах пакетов. Например злоумышленник может создать пакет с таким же именем как и используемый в вашем продукте, но старшей версии. При этом добавить этот пакет с вредоносным ПО в общедоступный репозиторий, когда менеджер пакетов попытается подгрузить зависимость, он подгрузит уязвимый пакет старшей версии (pip по умолчанию устанавливает более высокие номера версии).
Подробнее можно ознакомиться здесь https://www.websecuritylens.org/how-dependency-confusion-attack-works-and-how-to-prevent-it/
Избежать таких проблем можно с помощью кеширующих репозиториев, но стоит подумать про верификацию зависимостей при скачивании — об этом чуть позже.
Отсутствие гигиены секретов
Выше мы уже обсуждали эту проблему, единственное, что стоит отдельно упомянуть — стоит избегать наличия секретов в файлах конфигурации (как локальных, так и тех, что передаются заказчикам). Многие приложения содержат пароли по умолчанию — их стоит изменить после первоначальной настройки. Например PSQL содержит креды postgress/postgress. А zabbix Admin/zabbix. Наличие возможности аутентифицироваться в вашей базе с помощью дефолтных паролей открывает целый спектр возможностей для нарушителя — от банального drop всей базы, до внедрения снифферов, эксплойтов и прочих «приятностей» которые вы можете и не заметить вовремя.
Отсутствие важных исправлений безопасности
Очевидно что первое что будет делать хакер — сканировать вас и искать компоненты с известными уязвимостями, для которых как правило есть эксплойты на том же гитхабе. Не стоит думать, что хакеру важнее взломать ваш собственный код — все, что ему нужно — это взломать вас., а как — очевидно чем проще — тем лучше.
Возможность доступа к внутренним сервисам компании
К наличию такой возможности приводит некорректно настроенная сеть, отсутствие firewall, изоляции, избыточные маршруты. Например у вас может быть разрешен доступ в интернет на раннере, в таком случае возможна ситуация, когда запуская очередной пайплайн, раннер сходит на ресурс нарушителя и загрузит оттуда малварь, а если раннер еще и в общей сети предприятия это может привести к получению нарушителем доступа к хостам корпоративной сети. Вообще хорошей практикой считается отключение избыточных доступов, которые не нужны для работы, или которых можно избежать, этому даже посвящен отдельный принцип минимальных привилегий, о котором поговорим чуть позже.
Как добиться безопасной конфигурации
Проверить и улучшить текущее состояние вашей конфигурации.
Стоит использовать автоматизированные проверки. Найти проблемы связанные с контейнерами довольно просто — есть опенсорс инструмент https://github.com/goodwithtech/dockle.
Результат выглядит так:
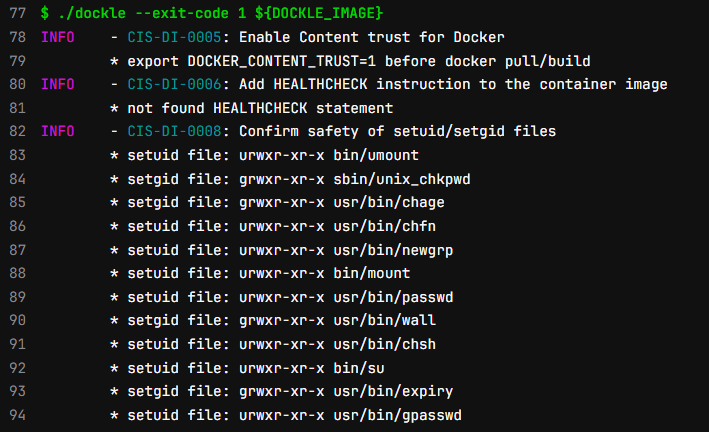
Результат анализатора Dockle
Очень полезная штука в вашем CI/CD — подсвечивает то, что было упущено при настройке микросервиса — в примере у файлов имеются опасные разрешения, setuid — позволяет запускать исполняемый файл с правами владельца, а setgid — примерно тоже самое, только от имени группы. Если вы используете веб сервисы — можно попробовать запустить опенсорсный https://github.com/sullo/nikto для точечного анализа
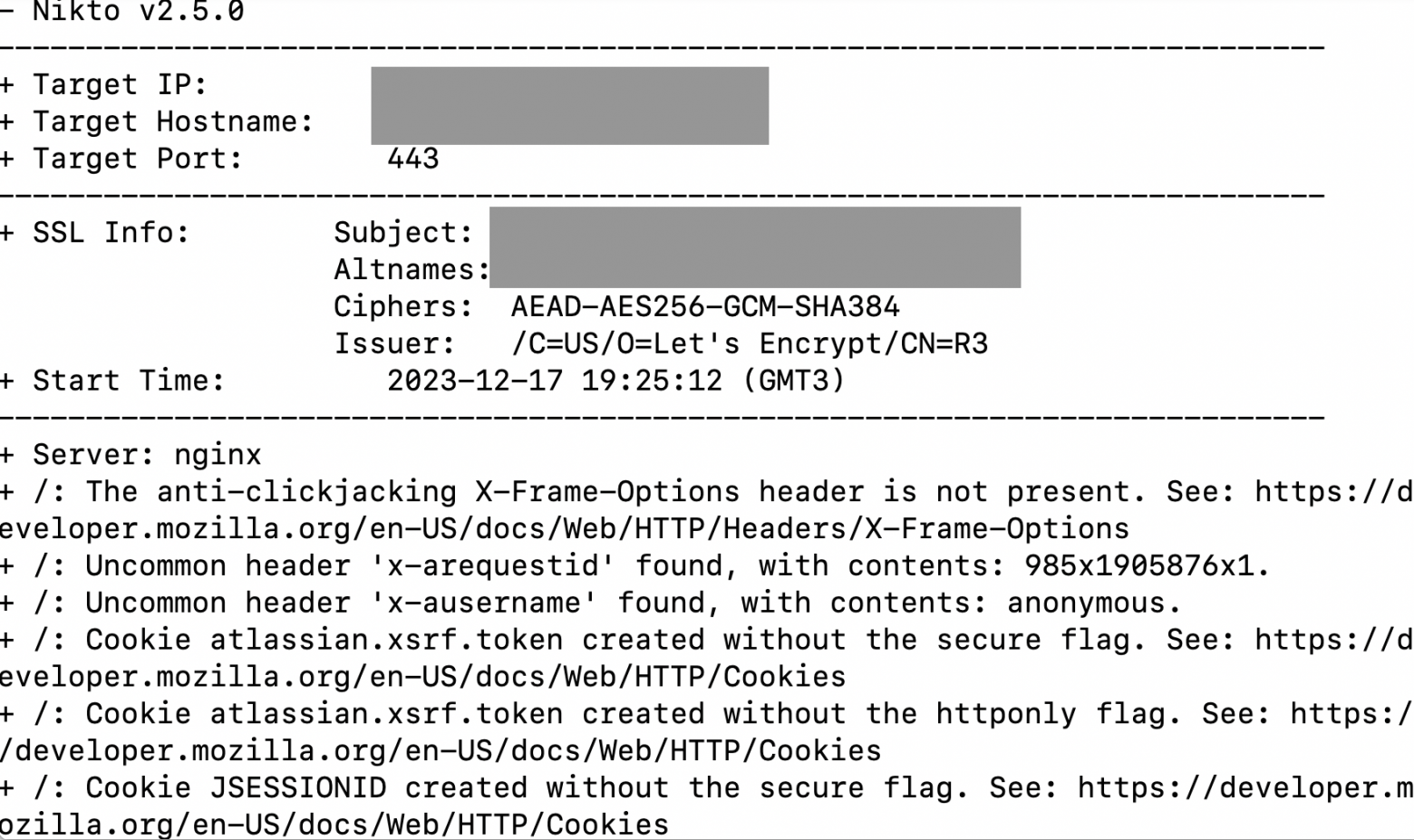
Или https://www.tenable.com/products/nessus для анализа сети.
Разработать самостоятельный процесс ревью конфигурации
Создание процесса ревью файлов конфигурации отдельно или в составе код-ревью, с дополнительным аппрувером, позволит проверять ваши MR на корректность параметров конфигурации до влития в основную ветку.
За основу чеклиста можно взять https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/02-Configuration_and_Deployment_Management_Testing/README:
Соответствие security by default
В целом данный пункт можно перефразировать как «следите за вашими настройками и используйте эталонные параметры». При этом недостаточно проработать только базовый список безопасных настроек, которые будут применены автоматически при деплое приложения или при установке из пакета. Стоит помнить, что администратор всегда может поменять эти настройки, если запретить ему нельзя — нужно хотя бы предупредить — например всплывающим окошком или сообщением в консоли по типу «вносимые изменения снижают общий уровень безопасности продукта, будьте внимательны». Также помимо этого у вас могут использоваться различные API безопасность взаимодействия которых тоже нужно обеспечивать, в качестве гигиенической меры можно выполнить рекомендации https://github.com/shieldfy/API-Security-Checklist или https://owasp.org/API-Security/editions/2023/en/0xa8-security-misconfiguration/
Своевременный security patch managment
Самый простой вариант быстренько проверить ваши зависимости на наличие уязвимостей — перейти на https://www.cvedetails.com/ (vpn required) и найти ваши компоненты.
Как правило вендоры периодически выпускают исправления уязвимостей своего ПО. Такие обновления могут быть как в составе новых версий ПО, так и выпускаться в рамках своего релизного цикла. Крайне важно отслеживать эти обновления или workaround, которые публикуют вендоры и своевременно их применять. На одну уязвимость меньше — на одну головную боль для хакера больше. Неплохой вариант подписаться и мониторить рассылки безопасности — как правило у известных вендоров существует отдельный ресурс посвященный исправлениям безопасности к примеру Debian и AWS публикуют на сайте:
Это просто и необходимо на старте, но для полноценного обеспечения безопасности, потребуется использовать SCA решения, которые будут проводить анализ автоматизировано в рамках вашего цикла разработки. Достаточно просто встроить сканер в ваш пайплайн отдельным stage или job, запускать на каждый MR в main. Можно также блокировать сборку при приросте уязвимостей, если не боитесь релиз-менеджеров.
Опенсорсные решения:
dependency check
dependency track
gemnasium
Проприетарные решения:
Сетевая изоляция или минимальный сетевой доступ
Важно всегда знать какие у вас есть сетевые ресурсы и куда теоретически может попасть злоумышленник. Плохо, когда рабочие места, тестовые окружения, деплой сервера, сборочные агенты, etc находятся в одной подсети и не ограничены в сетевом доступе, в таком случае, если нарушитель сможет получить доступ на произвольное устройство, перед ним откроется вся инфраструктура как на ладони. Поэтому, чтобы этого избежать следует реализовать сегментацию вашей сети, если не на физическом, то хотя бы на виртуальном уровне, использовать виртуальные свичи, firewall, настроить правила фильтрации (https://opnsense.org/). Также, важно регулярно следить за вашей инфраструктурой, ведь ее состояние меняется где-то добавили новый хост, где-то увеличили количество раннеров или вышли новые сотрудники с новыми хостами. Для отслеживания изменений состояния инфраструктуры я рекомендую использовать такие решения как Rapid7 или Nessus Pro.
Неконтролируемое использование сторонних сервисов
CICD-SEC-08-Ungoverned-Usage-of-3rd-Party-Services
Как правило в любой организации есть системы и сервисы используемые для упрощения ее жизнедеятельности, а SAAS решения в последнее время особенно популярны. Обычно использование интеграций включает в себя несколько методов — это могут быть приложения с использованием протоколов OAuth, интеграции на основе токенов (JWT), использующие SSH, или вебхуки. Метод не столь важен. Важно то, что за этим всем нужно следить и вовремя отключать.
Потеря контроля над используемыми интеграциями
Давайте представим ситуацию — мы подключили чат-бота, который имеет доступ к нашему репозиторию и пушит уведомления на каждый merge-request. Мы добавили вебхук, выпустили токен, все настроили, все работает. Потом приняли решение перейти в другой мессенджер или заморозили работу в репозитории. В общем оказалось что интеграция нам не особо нужна сейчас, но удалять не стали. Что же произойдет если нарушитель получит токен? Как минимум все будет зависеть от разрешений учетной записи, к которой привязан этот токен, самое плохое — когда учетная запись имеет доступ ко всем вашим репозиториям (а теперь представьте что вы еще не удалили приватные ключи из репозиториев).
А если вы используете SAAS решения? Что будет, например, если провайдера услуг взломают? Это не редкость. Нужно всегда держать в голове мысль «что будет если атакуют? как нарушитель может это использовать?» и выстраивать политику работы с такими решениями исходя в том числе из этого.
Отсутствие процессов управления токенами доступа
Многопользовательский доступ сотрудников к каким либо ресурсам, или множество различных интеграций, в том числе с внешними сервисами очевидно могут быть опасны, если за ними не следить должным образом. При этом, даже если вы как security специалист пойдете и отключите все подозрительное, кто-то обязательно вернет все обратно или выпустит новый токен — чтобы работало или банально сами забудете что выпускали n месяцев назад. Поэтому бесполезно в одиночку что-то блокировать или удалять — стоит подойти системно и осознанно.
Отзыв прав без отзыва самих интеграций
Также важно помнить, что утилизировать нужно в том числе сами токены или ключи, а не только забирать отдельные права. Ведь
Как обеспечить безопасное использование сторонних сервисов
Парадигма минимальных привилегий
Как и многие решения в области кибербезопасности, соответствие принципу минимальных привилегий лишь снижает вероятность успешной атаки. А сам принцип заключается в исключении прироста поверхности атаки в течении жизненных циклов ваших процессов R&D. Упрощенно можно сформулировать как — всегда выдавать любые доступы только тем, кому они нужны и только нужного уровня. Следование такому правилу позволит значительно обезопасить ваши системы.
Также можно ознакомиться со статьей, где более подробно рассказывается про минимальные привилегии: https://www.cloudflare.com/learning/access-management/principle-of-least-privilege/
Реализация процессов предоставления, удаления и аудита прав для интегрируемых сервисов
Сколько у вас в компании сервисов? Есть ли свои чат-боты? Настроены вебхуки для получения данных из репозитория? Может быть нотификации? Или вы используете сторонние услуги для анализа качества кода? Просто задумайтесь сколько всего у вас уже есть и сколько еще может быть подключено — разработка не стоит на месте. За этим просто так не уследить, а еще надо понимать какой доступ сервисам нужен и куда, а если решили прекратить использование или заменить часть сервисов, это ведь тоже надо сделать правильно.
Централизованный процесс позволит предотвратить множество проблем, связанных с некорректным отзывом или выдачей полномочий для сервисов, при этом стоит в процессе рассмотреть не только процедуры, но и ответственных на каждом из этапов вашего жизненного цикла — это обеспечит прозрачность и контролируемость, а также позволит не допустить внезапный выпуск токенов или произвольное повышение уровня привилегий на каком-либо. А наличие контрольных точек на каждом из этапов жизненного цикла интеграций позволит снизить трудозатраты на восстановление интеграций или трабшутинг проблем.
Некорректная валидация артефактов
CICD-SEC-09-Improper-Artifact-Integrity-Validation
При разработке кода, может произойти множество непредвиденных ситуаций — это может быть подмена артефактов в хранилище, загрузка с рабочего места разработчика или вообще загрузка в процессе сборки версии продукта в билд конвейере. Чтобы избежать этого можно использовать механизм валидации — или контроль целостности сборочных артефактов. При этом важно определить места в процессе разработки, где контрольные суммы (подписи) будут формироваться и места проверки, где они будут проверяться. Для того, чтобы избежать подмены артефактов необходимо проработать прозрачный процесс их валидации. Что же именно стоит учесть?
Проверка целостности артефактов
Реализация механизмов проверки целостности критичных артефактов сборки, в момент их получения заказчиками или дочерними организациями позволит обеспечить прозрачность процесса доставки. Если в пути будет изменен хотя бы один файл, контрольная сумма изменится и при контроле целостности это будет обнаружено, а значит использовать полученный дистрибутив или файл может быть опасно.
Подпись кода и артефактов
Подпись кода и артефактов в момент их создания в вашей доверенной сред позволит избежать подмены при передаче и
Нужно обеспечить ваш CI/CD механизмом подписи и в управляемом вами потоке подписывать артефакты сборок, естественно доступ к ключам подписи необходимо ограничить. Например можно назначить пару ответственных за подпись артефактов — реализовать отдельную manual job, запускать которую будет ответственный человек со своим ключом.
Проверка подписи на всех этапах
Важно не только сформировать подпись для файлов или дистрибутивов, но и вовремя ее проверить. Например можно реализовать отдельную job, которая будет проверять подпись полученных артефактов перед их использованием в пайплайне. Также необходимо реализовать блокировки при отрицательных результатах валидации и соответствующие оповещения.
Подпись всех сторонних артефактов в локальном хранилище
Хорошей практикой также является использование проксирующих репозиториев, в которые попадают только проверенные вами компоненты ПО. Если требуется добавить или обновить какой-либо компонент, он должен пройти через 7 кругов ада ряд проверок безопасности, только после которых будет разрешено его использование. Но, это не исключает возможность загрузки зависимостей на локальные машины разработчиков из произвольных общедоступных источников, или USB. Я считаю верно использовать единый источник правды в виде вашего кэширующего репозитория с реализованным механизмом подписи проверенных артефактов. А разрешать использование различных компонентов только при проверке подписи, таким образом мы можем избежать подмены артефактов или использование не разрешенных компонентов.
Недостаточное логирование и мониторинг
CICD-SEC-10-Insufficient-Logging-And-Visibility
Изобилие систем и сервисов может упростить жизнь разработчикам и тестировщикам, но как правило это приводит к головной боли у безопасников, ведь за каждым из них необходимо следить. Да и в общем-то без мониторинга довольно сложно проводить анализ ошибок, так что пусть будет. При реализации мониторинга или логирования стоит задуматься какие метрики нужно собирать, какие логи стоит сохранять, а какие бесполезны, как долго хранить логи и как их передавать, какие данные там должны находиться и прочее. Поэтому важно подойти ответственно к данному процессу, как минимум стоит начать с вопроса «А как добавление этих метрик поможет решить мне мою проблему?». Ну да ладно, давайте перейдем к рекомендациям.
Отсутствие регистрации критичных событий
Давайте представим ситуацию: ночью (а хакеры любят работать по ночам) нарушитель смог получить доступ к вашей базе данных, отправить команду, что-то типа DROP DATABASE DatabaseName. Утром вы обнаруживаете, что ничего не работает, все пользователи пропали, данные утеряны. Да бекапирование спасет от этого, но что, если хакер будет ломать вашу базу раз в час? Как же найти этот вектор, если у вас не настроено логирование и мониторинг? Какие события следует регистрировать? А для других сервисов? Дальше мы рассмотрим как от этого защититься
Отсутствие карты инструментов
Современная IT компания, как правило использует огромное количество различных инструментов и сервисов, которые должны упростить работу разработчиков, тестировщиков, да вообще всех сотрудников. Только взгляните на схему популярных инструментов.

Конечно можно отслеживать их по отдельности или выбрать только часть для мониторинга -, но это только на старте. В ситуации когда даже наличие одной маленькой уязвимости в одной из них может предоставить возможность хакеру влиять на вашу инфраструктуру стоит задуматься о том, как понять что у вас произошел инцидент, как вовремя на него среагировать. Логичнее реализовать мониторинг всех систем и сервисов, а для этого необходимо провести инвентаризацию вашей инфраструктуры- построить карту инструментов. Только после этого стоит обдуманно «навешивать» мониторинг.
Отсутствие анализа событий и оповещений
С точки зрения анализа логов легко пропустить какие-либо события, для которых логирование не включено или события-исключения из принятых паттернов анализа. Очевидно, что недостаточно просто собирать логи, необходимо их анализировать, хотя бы вручную, а лучше автоматизировано. При этом разовая реализация может вам помочь на какое-то время, но с каждым днем актуальность анализа будет снижаться, ведь хакер всегда на шаг впереди и никогда не спит. Анализ событий также поможет при траблшутинге проблем, а своевременные оповещения о подозрительной активности могут помочь вовремя обнаружить атаку и избежать продвижение нарушителя по вашей сети.
Как обеспечить достаточный мониторинг
Логирование событий для всех систем
Важно определить перечень событий, которые требуется отслеживать, все события все равно невозможно отследить, да и слишком это сложно при анализе. Как потом проводить анализ инцидентов, если не понятно кто, что и когда сделал? Я предлагаю в базовом варианте регистрировать как минимум эти события:
аутентификацию пользователей
добавление или удаление пользователей
доступ (чтение, создание, изменение) к файлам и каталогам администратора
доступ (чтение, создание, изменение) к файлам и каталогам пользователей
создание и изменение файлов конфигурации
инициация сборки
скачивание артефактов
изменение разрешений файлов и каталогов
Конечно полный список для каждой организации свой и зависит от тех сервисов которые вы используете.
Централизованный анализ логов (SIEM)
Учитывая, что количество используемых сервисов только растет, количество собираемых логов увеличивается еще быстрее, в один момент станет невозможно анализировать их вручную или самописными скриптами. Уже давно существуют специализированные решения для данной проблемы — SIEM (Security information and event management), которые как раз и призваны выполнять анализ логов 24/7 и искать потенциальные проблемы в них и даже предсказывать возможные атаки.
Процедуры нотификации об аномалиях
Но даже если вы будете использовать SIEM, недостаточно просто поднять и настроить — все же это автоматизированное средство и его необходимо администрировать и регулярно проверять оповещения о событиях. На старте можно назначить пару человек, которые будут по очереди выполнять анализ инцидентов, или обратиться к аутсорс-компаниям, которые предоставляют такие услуги. Ну, а в идеале следует собрать особую группу, которая будет заниматься анализом инцидентов и оперативным реагированием на них.
Блокирование систем при подтверждении инцидентов
Естественно обнаруживать потенциальные проблемы это круто, но надо и предусмотреть алгоритмы блокировки. Блокировать можно определенные порты, систему целиком, отдельные сервисы, сетевой трафик — развернуться можно и нужно. На самом деле мониторинг, без активных блокировок бесполезен, нужно вовремя пресекать возможные атаки на вас. Но и не стоит блокировать все и сразу, инцидент может быть и ложным, а простой будет уже проблемой для бизнеса — важно заранее определить SLA на который будут согласны все.
Ну вот и все!
Спасибо всем кто дочитал до конца, надеюсь было интересно. Буду признателен за обратную связь, особенно если вы извлекли что-то полезное для себя и попробовали это применить на практике. Оставляйте обратную связь в комментариях — это поможет выпускать более качественный контент в будущем.
