Безболезненный Fallback Cache на Scala
В крупных или микросервисных архитектурах самый важный сервис не всегда самый производительный и бывает не предназначен для хайлоада. Мы говорим о бэкенде. Он работает медленно — теряет время на обработке данных и ожидании ответа между ним и СУБД, и не масштабируется. Даже если само приложение масштабируется легко, это узкое место не масштабируется совсем. Как эту проблему решить и обеспечить высокую производительность? Как обеспечить ответ системы, когда важные источники информации молчат?

Если ваша архитектура полностью соответствует Reactive-манифесту, составные части приложения неограниченно масштабируются с возрастанием нагрузки независимо друг от друга, и выдерживают падение любого узла, — вы знаете ответ. Но если нет, то Олег Нижников (Odomontois) расскажет, как проблему масштабируемости решили в Тинькофф, построив свой безболезненный Fallback Cache на Scala, не переписывая приложение.
Примечание. В статье будет минимум кода на Scala и максимум общих принципов и идей.
Нестабильный или медленный бэкенд
Cреднее приложение при взаимодействии с бэкендом работает быстро. Но бэкенд выполняет основную часть работы и внутри себя перемалывает большую часть данных — на это тратится больше времени. Дополнительное время теряется на ожидание ответа бэкенда и СУБД. Даже если само приложение масштабируется легко, это узкое место не масштабируется совсем. Как ослабить нагрузку на бэкенд и решить проблему?
Embedded Cache
Первая идея — взять данные для чтения, запросы, которые получают данные, и настроить кэш на уровне каждой ноды in-memory.
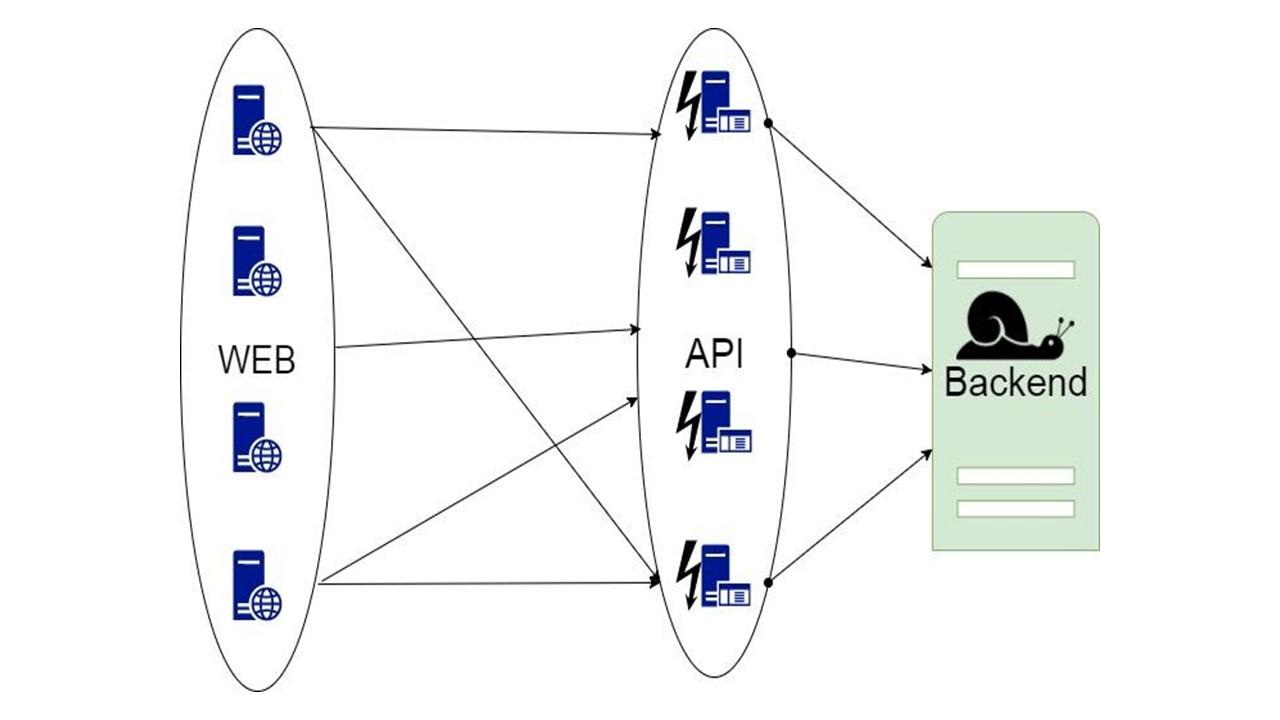
Кэш живет, пока нода не перезапустится, и хранит только последнюю часть данных. Если приложение отказывает и заходят новые пользователи, которых не было последний час, день или неделю, приложение не может ничего с этим сделать.
Proxy
Второй вариант — proxy, который берет на себя часть запросов или модифицирует работу приложения.
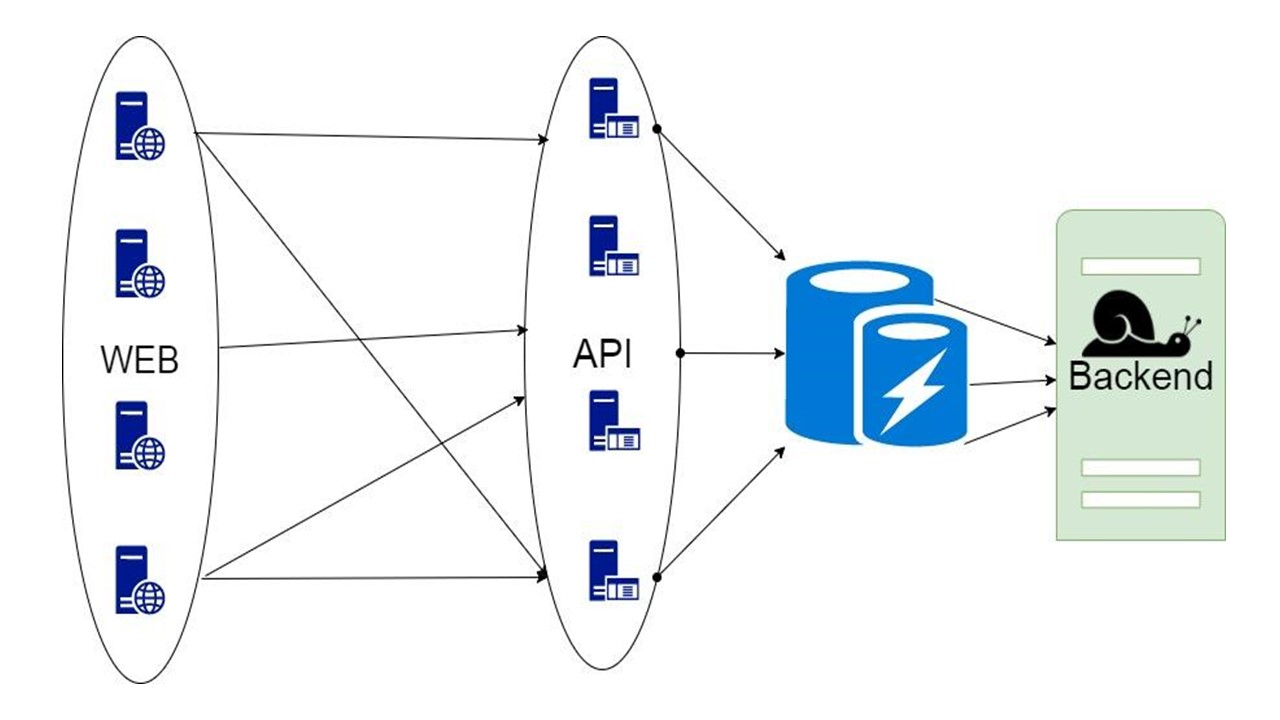
Но в proxy вы не можете выполнять всю работу за само приложение.
Caching Database
Третий вариант — хитрый, когда часть данных, которую возвращает бэкенд, можно надолго поместить в хранилище. Когда они понадобятся — показываем клиенту, даже если они уже не актуальны. Это лучше, чем ничего.
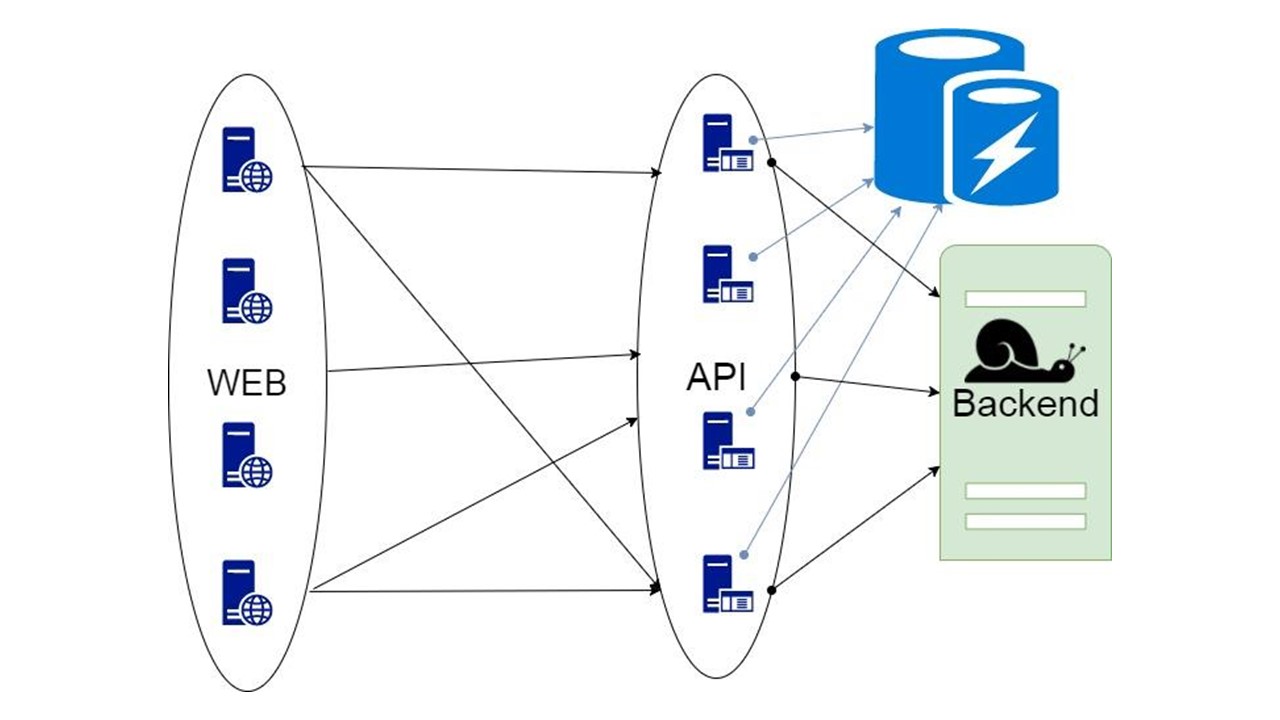
Про такое решение и пойдет речь.
Fallback cache
Это наша библиотека. Она встраивается в приложение и общается с бэкендом. При минимальной доработке анализирует структуру данных, генерирует форматы сериализации и с помощью алгоритма Circuit Breaker повышает отказоустойчивость. Эффективная сериализация может быть реализована в любом языке, где можно заранее проанализировать типы, если они определены достаточно строго.
Компоненты
Наша библиотека выглядит приблизительно так.

Левая часть посвящена взаимодействию с этим хранилищем, которая включает две важные компоненты:
- компонента, которая отвечает за процесс инициализации — предварительных действий с СУБД перед тем, как пользоваться Fallback Cache;
- модуль генерации автоматических сериализаторов.
Правая часть — общая функциональность, которая касается Fallback.
Как все это работает? Для хранения состояния есть запросы в середине приложения и промежуточные типы. В этой форме выражаются данные, которые мы получили с бэкенда за один или несколько запросов. Параметры отправляем в свой метод, и получаем оттуда данные. Эти данные требуется как-то сериализовывать, чтобы поместить в хранилище, поэтому мы оборачиваем их в код. За это отвечает отдельный модуль. Мы воспользовались паттерном Circuit Breaker.
Требования к хранилищу
Длительный срок хранения — 30–500 дней. Какие-то действия могли происходить давно, и все это время требуется хранить данные. Поэтому мы хотим хранилище, которое может долго хранить данные. In-memory для этого не подходят.
Большой объём данных — 100 ГБ-20 ТБ. Мы хотим хранить в кэше десятки терабайт данных, а в связи с ростом — даже больше. Все это держать в памяти неэффективно — большая часть данных не запрашивается постоянно. Они долго лежат, ждут своего юзера, который зайдет и спросит. Под эти требования не подпадает In-memory.
Высокая доступность данных. С сервисом может происходить что угодно, но мы хотим, чтобы СУБД оставалась доступна постоянно.
Низкие расходы на сохранение. Мы отправляем в кэш дополнительные данные. Как следствие возникает overhead. При внедрении нашего решения мы хотим свести его к минимуму.
Поддержка запросов с интервалами. В нашей БД должна была возможность вытаскивать кусок данных не только целиком, а интервалами: список действий, историю пользователя за определенный период. Поэтому чистый key value не подходит.
Допущения
Требования сужают список кандидатов. Мы предполагаем, что реализовали все остальное, и делаем следующие допущения, зная, зачем конкретно нам нужен Fallback Cache.
Целостность данных между двумя разными GET-запросами не требуется. Поэтому, если они отображают два разных не консистентных друг с другом состояния, мы смиримся с этим.
Актуальность и инвалидации данных не требуется. В момент запроса предполагается, что у нас есть последняя версия, которую мы показываем.
Мы отправляем и получаем из бэкенда данные. Структура этих данных заранее известна.
Выбор хранилища
В качестве альтернатив мы рассматривали три основных варианта.
Первый — Cassandra. Достоинства: высокая доступность, легкая масштабируемость и встроенный механизм сериализации с коллекцией UDT.
UDT или User Defined Types, означает некоторый тип. Они позволяют эффективно складывать структурированные типы. Поля типов заранее известны. Эти поля для сериализации помечаются отдельными тэгами как в Protocol Buffers. Прочитав эту структуру, можно на основании тэгов понять, какие там поля. Достаточно метаданных, чтобы узнать их название и тип.
Еще один плюс Cassandra, что кроме partition key она имеет дополнительный clustering key. Это специальный ключ, благодаря которому данные упорядочиваются на одной ноде. Это позволяет реализовывать такую опцию, как интервальные запросы.
Cassandra относительно долго существует на рынке, для нее есть много решений мониторинга, и один минус — JVM. Это не самый производительный вариант для платформ, на которых можно написать СУБД. У JVM есть проблемы со сборкой мусора и overhead.
Второй вариант — CouchBase. Достоинства: доступность данных, масштабируемость и Schemaless.
С CouchBase о сериализации надо думать еще меньше. Это и плюс, и минус — нам не нужно контролировать схему данных. Есть глобальные индексы, которые позволяют запускать интервальные запросы глобально по кластеру.
CouchBase — это гибрид, где к обычной СУБД добавлен Memcache — быстрый кэш. Он позволяет автоматически кэшировать все данные на ноде — самые горячие, с очень высокой доступностью. Благодаря своему кэшу CouchBase может быть быстрой, если одни и те же данные запрашиваются очень часто.
Schemaless и JSON могут быть также и минусом. Данные могут храниться так долго, что приложение успеет измениться. В этом случае также изменится структура данных, которую CouchBase собирается сохранять и читать. Предыдущая версия, возможно, будет несовместима. Об этом вы узнаете только при чтении, а не при разработке данных, когда они лежат где-то на продакшн. Над правильной миграцией приходится думать, а это именно то, что мы не хотим делать.
Третий вариант — Tarantool. Славится своей супер-скоростью. У него есть замечательный движок LUA, который позволяет написать кучу логики, которая будет исполняться прямо на сервере на LuaJit.
С другой стороны, это модифицированный key value. Данные хранятся в кортежах (tuple). Нам нужно думать самим над правильной сериализацией, это не всегда очевидная задача. Также у Tarantool специфический подход к масштабируемости. Что с ним не так, обсудим дальше.
Sharding/Replication
Возможно, в нашем приложении потребуется Sharding/Replication. Три хранилища реализуют их по-разному.
Cassandra предполагает структуру, которая обычно называется «кольцом».
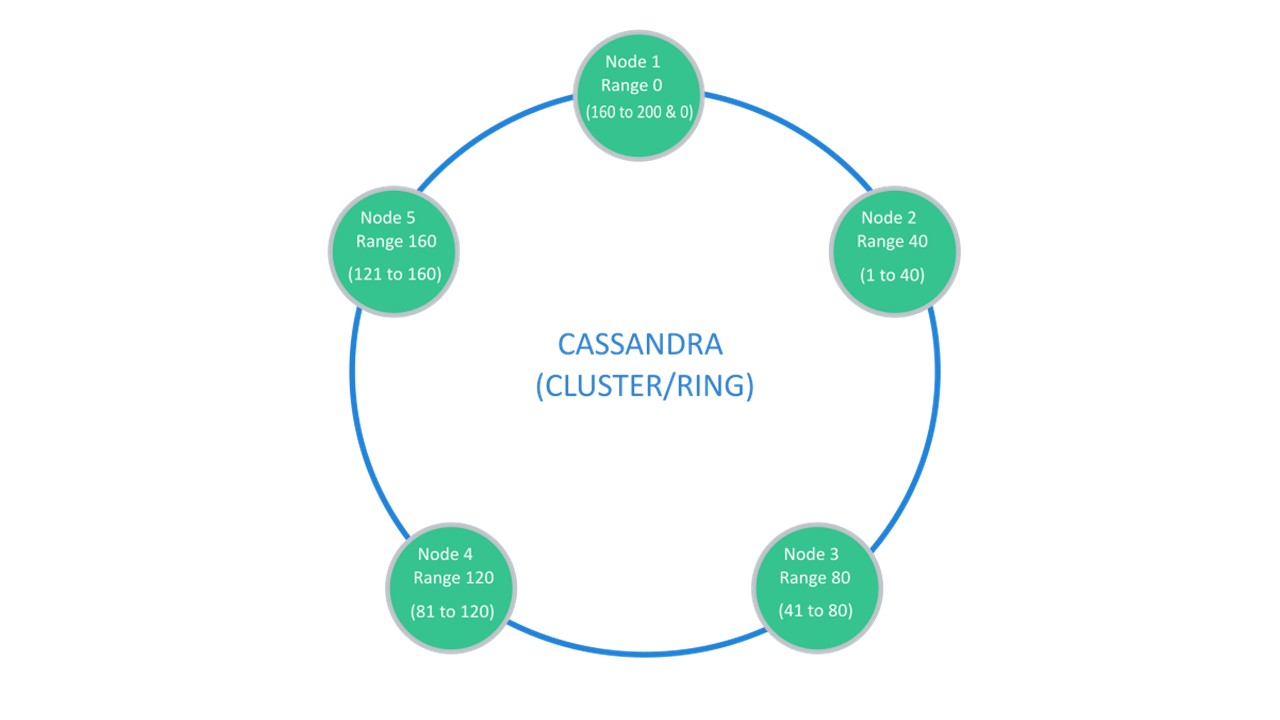
В наличии много нод. Каждая из них хранит свои данные и данные с ближайших нод как реплики. Если одна выбывает, ноды рядом с ней могут обслуживать часть ее данных, пока выбывшая не поднимется.
За Sharding\Replication отвечает одна и та же структура. Для расшардирования на 10 кусков и Replication factor 3, достаточно 10 нод. Каждая из нод будет хранить 2 реплики из соседних.
В CouchBase структура взаимодействия между нодами устроена похожим образом:
- есть данные, которые помечены как active, за которые отвечает сама нода;
- есть реплики соседних нод, которые CouchBase хранит у себя.
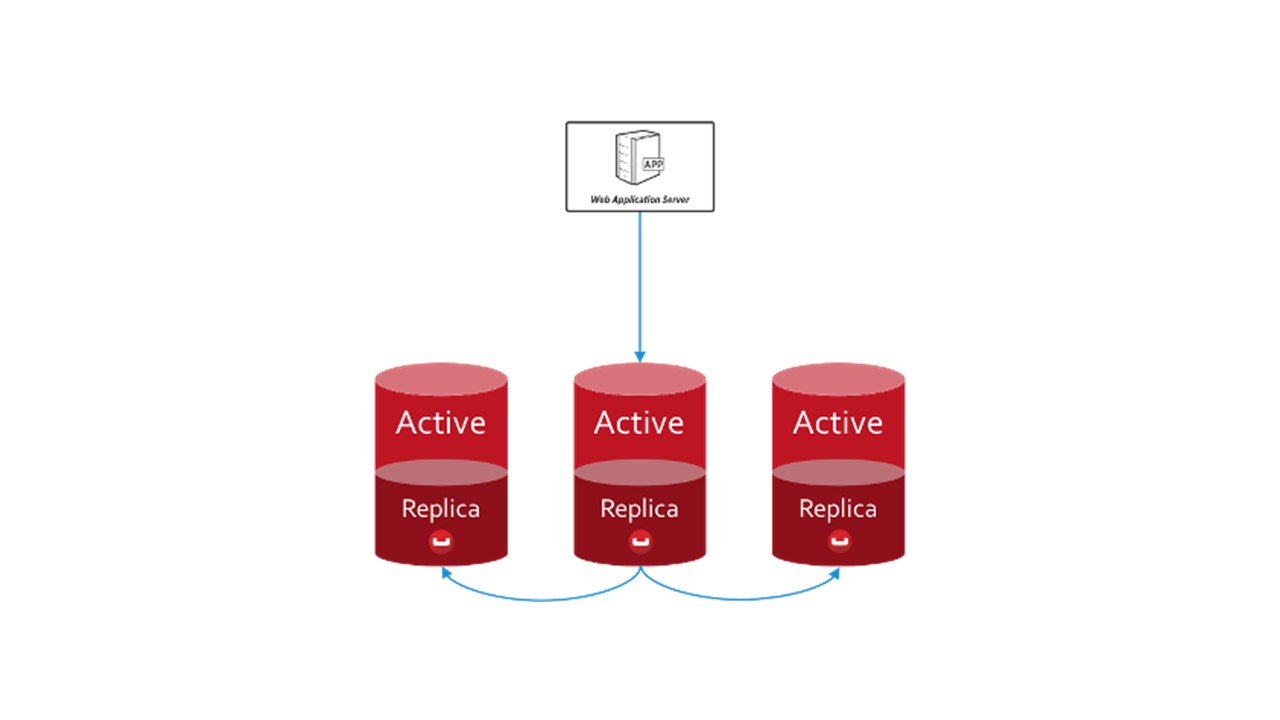
Если одну ноду выбывает, соседние, расшарденные, берут на себя ответственность за обслуживание этой части ключей.
В Tarantool архитектура похожа на MongoDB. Но с нюансом: есть шардинг-группы, которые друг с другом реплицируются.
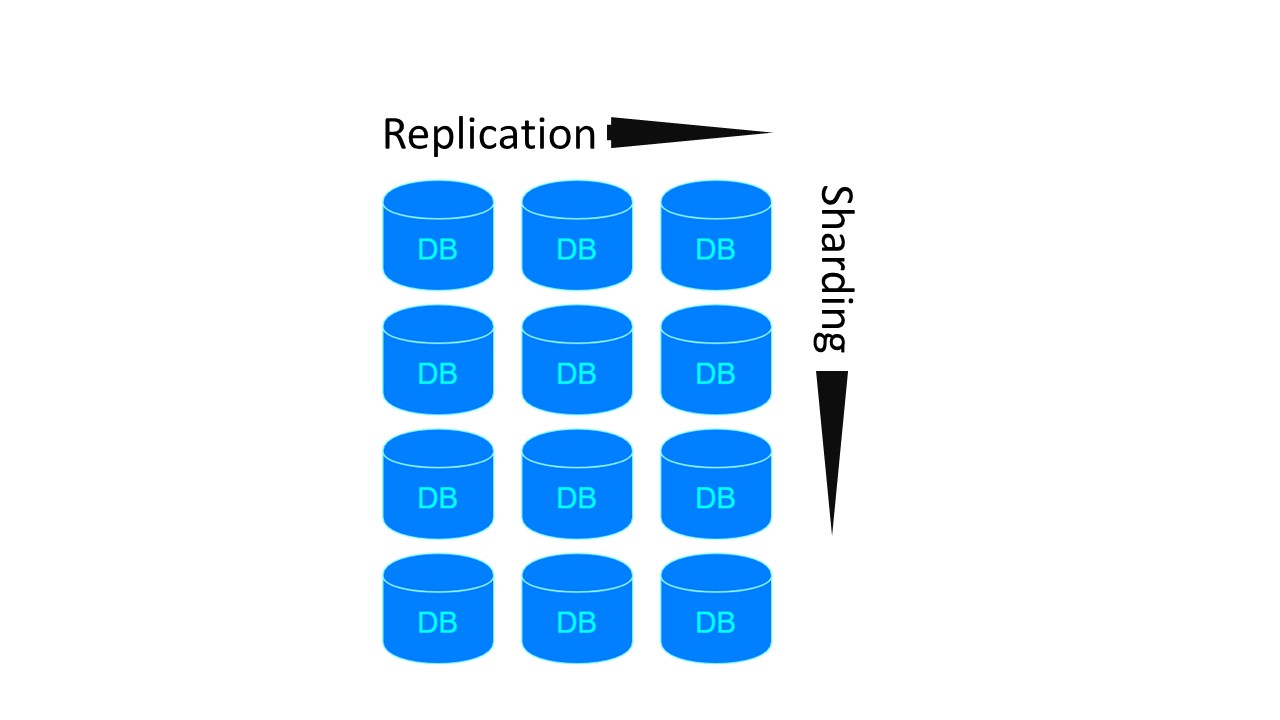
Для предыдущих двух архитектур, если нам захочется сделать 4 шарда и Replication factor 3, потребуется 4 ноды. Для Tarantool — 12! Но недостаток компенсируется скоростью работы, которую Tarantool гарантирует.
Cassandra
Опциональные модули для шардинга в Tarantool появились только недавно. Поэтому основным кандидатом мы выбрали СУБД Cassandra. Вспомним, что мы говорили о ее специфической сериализации.
Авто-сериализация
Протокол SQL предполагает, что вы достаточно свободно определяете схему данных.
Можно использовать это как преимущество. Например, сериализовать данные так, чтобы длинные имена полей наших развесистых структур не хранились каждый раз в наших значениях. В этом случае у нас будут некие метаданные, которые описывают устройство данных. Также сами UDT рассказывают каким полям соответствуют метки и тэги.
Поэтому автоматически генерируемая сериализация проходит приблизительно по такой схеме. Если у нас есть один из базовых типов, которому можно один в один поставить в соответствие тип из базы данных, мы так и делаем. Набор типов Int, Long, String, Double есть и в Cassandra.
Если в какой-то структуре встречается опциональное поле — ничего дополнительно не делаем. Указываем для него тип, в который должно это поле превращаться. В структуре будет храниться null. Если найдем null в структуре на уровне десериализации, мы предполагаем, что это отсутствие значения.
Все типы коллекций из набора в Scala превращаем в тип list. Это упорядоченные коллекции, у которых есть элемент соответствия с индексом.
Неупорядоченные коллекции Set гарантируют наличие ровно одного элемента с каждым значением. Для них в Cassandra тоже существует специальный тип set.
Скорее всего, у нас будет много mapping (), особенно со string-ключами. Для них в Cassandra есть специальный тип map. Он также типизирован и имеет два параметра типа. Так что мы можем для любого ключа создать соответствующий тип
Есть типы данных, которые мы определяем сами в нашем приложении. Во многих языках их называют алгебраическими типами данных. Они определяются с помощью определения именованного произведения типов, то есть структуры. Такую структуру мы ставим в соответствие User Defined Type. Каждое поле структуры будет соответствовать одному полю в UDT.
Второй тип — алгебраическая сумма типов. В этом случае типу соответствует несколько заранее известных подтипов или подразновидностей. Также определенным образом ставим ему в соответствие структуру.
Abstract Data Type переводим в UDT
У нас есть структура, и мы отображаем ее один в один — для каждого поля определяем поле в создаваемом UDT в Cassandra:
case class Account (
id: Long,
tags: List[String],
user: User,
finData: Option[FinData]
)
create type account (
id bigint,
tags: frozen>,
user frozen,
fin_data frozen
)
Примитивные типы превращаются в примитивные типы. Ссылка на заранее определенный до этого тип переходит во frozen. Это специальная обертка в Cassandra, которая означает, что нельзя читать из этого поля по кусочкам. Обертка «вморожена» в это состояние. Мы можем только целиком прочитать или сохранить туда user, или список, как в случае с тэгами.
Если мы встречаем опциональное поле, то отбрасываем эту характеристику. Берем только тип данных, соответствующий тому типу поля, который будет. Если встретим здесь non — отсутствие значения, — запишем в соответствующее поле null. При чтении также будем брать соответствие non-null.
Если встречаем тип, который имеет несколько заранее известных альтернатив, то определяем также и новый тип данных в Cassandra. Для каждой альтернативы — поле в нашем типе данных в UDT.
В результате в этой структуре только одно из полей в каждый момент времени будет не null. Если встретили какой-то тип user, и он в runtime оказался instance модератора — поле moderator будет содержать какое-то значение, остальные будут null. Для админа — admin, остальные — null.
Это позволяет закодировать структуру так: у нас есть 4 опциональных поля, мы сами гарантируем, что записано из них будет только одно. Cassandra использует всего лишь один тэг, чтобы идентифицировать наличие конкретного поля в структуре. Благодаря этому мы получаем структуру хранения без overhead.
Фактически, чтобы сохранить тип user, если это модератор, потребуется то же количество байт, которое требуется для хранения модератора. Плюс один байт, чтобы показать, какая именно альтернатива здесь присутствует.
Инициализация
Инициализация — предварительная процедура, которую нужно выполнить до того, как мы можем пользоваться нашим fallback.
Как устроен этот процесс.
- На каждой ноде генерируем определения таблиц, типов и тексты запросов на основании типов, которые представлены.
- Читаем из СУБД текущую схему. В Cassandra это легко сделать, просто подключившись к ней. При подключении, практически во всех драйверах, сам объект «сессия» выкачивает метаданные key space, к которому он подключен. Дальше можно смотреть, что в них есть.
- Проходим по метаданным, сравниваем и проверяем, что разрешено все, что мы хотим создать и возможна инкрементальная миграция.
- Если все нормально и инициализация возможна — выполняем миграцию.
- Готовим запросы.
sealed trait User
case class Anonymous extends User
case class Registered extends User
case class Moderator extends User
case class Admin extends User
create type user (
anonymous frozen,
registered frozen,
moderator frozen,
admin frozen
)
Происходит это так. У нас есть типы, таблицы и запросы. Типы зависят от других типов, те — от других. Таблицы зависят от этих типов. Запросы зависят уже от таблиц, из которых они читают данные. Инициализация проверит все эти зависимости и создаст в СУБД все, что может создать, по определенным правилам.
Миграция типов
Как определить, что можно инкрементально мигрировать тип?
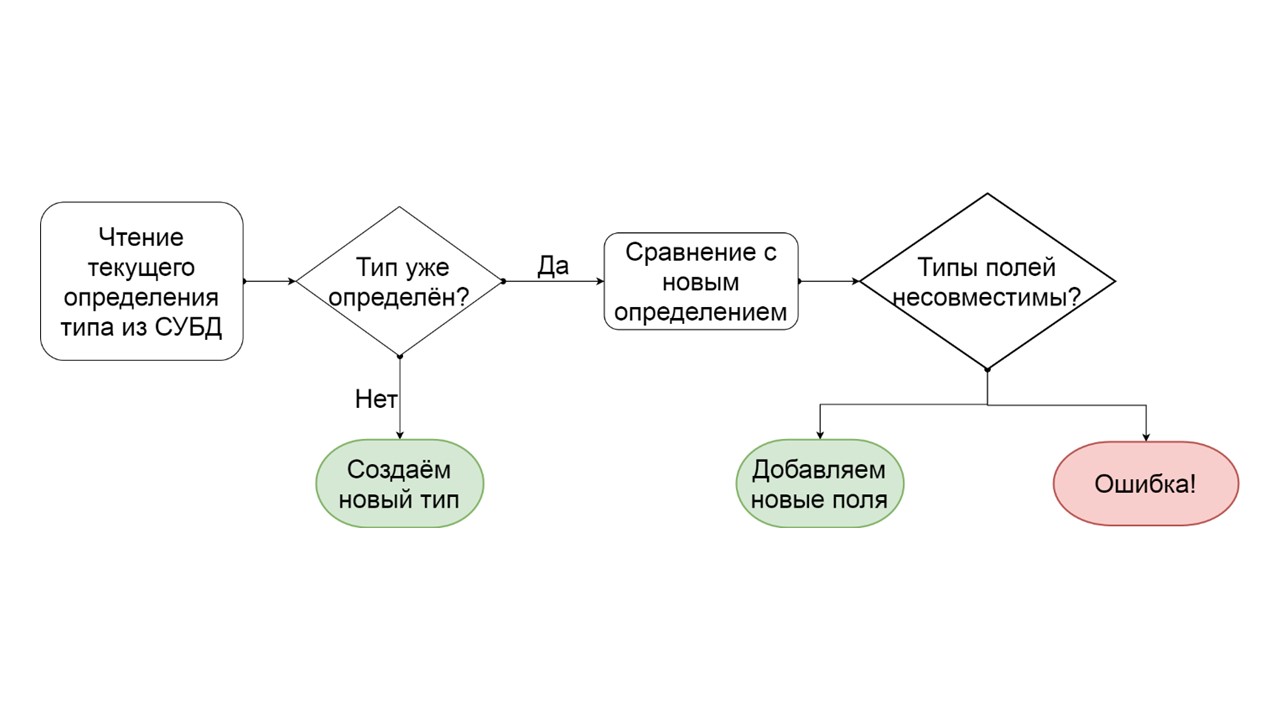
- Читаем, как этот тип определен в СУБД.
- Если такого типа нет, то есть мы придумали новый — создаем его.
- Если такой тип уже есть — пытаемся сопоставить поле за полем существующее определение с тем, которое мы хотим этому типу дать.
- Если выясняется, что мы хотим добавить просто несколько полей, которых уже не существует, мы так и делаем. Создаем список мутирующих операций ALTER TYPE, и запускаем их.
- Если получается, что у нас есть какое-то поле, которое было, другого типа — генерируем ошибку. Например, был list — стал map, или была ссылка на один user-defined type, а мы пытаемся сделать его другим.
Эту ошибку разработчик может увидеть еще до того, как запустит функционал на продакшн. Предполагаю, что точно такая же схема данных есть в его среде разработки. Он видит, что как-то создал немигрируемую схему данных, и чтобы избежать этих ошибок, может переопределить автоматически сгенерированную сериализацию, добавить опции, переименовать поля или все типы и таблицы целиком.
Инициализация: типы
Представим, что есть определения нескольких типов:
case class Product (id: Long, name: ctring, price: BigDecimal)
case class UserOffers (valiDate: LocalDate, offers: Seq[Products])
case class UserProducts (user User, products: Map[Date, Product])
case class UserInfo: UserOffers, products: UserProducts)
Сase class — класс, который содержит набор полей. Это аналог struct в Rust.
Сгенерируем приблизительно такие определения данных для каждого из 4 типов — то, что хотим в итоге провернуть:
CREATE TYPE product (id bigint, name text, price decimal);
CREATE TYPE user_offers (valid_date date, offers frozen>>);
CREATE TYPE user_products (user frozen, products frozen>);
CREATE TYPE user_jnfo (offers: frozen, products: frozen);
Тип user_offers зависит от типа offer, user_products зависит от типа product, user_info — от второго и третьего типов.

У нас такая зависимость между типами, и мы хотим правильно ее инициализировать. На схеме показано, что мы будем инициализировать user_offers и user_products параллельно. Это не значит, что мы запустим две параллельные операции. Нет, все утверждения, все анализы запускаем последовательно, чтобы случайно не создать один и тот же тип в двух параллельных потоках.
Но есть некая параллельность на уровне устранения ошибок. Если произошла ошибка в типе, всё, что от него зависит, потянет за собой исходную ошибку.
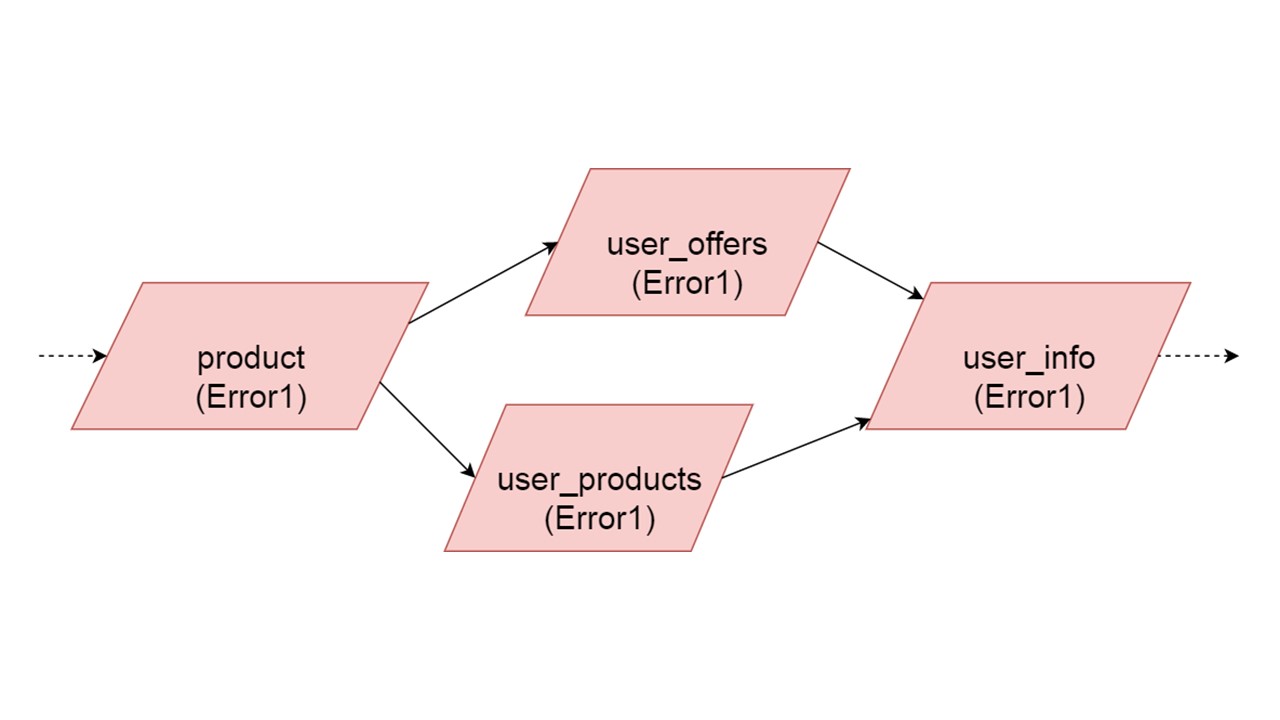
Если ошибку генерирует какая-то из параллельных ветвей, всё, что зависит от нормально мигрируемых данных, будет сгенерировано без ошибки. Если дальше будут определения таблиц, prepared statements от них, мы сможем спокойно инициализировать эту часть нашего Fallback Сache. Связь будет потеряна только с какой-то частью бэкендов или с какой-то функциональностью. Остатки доинициализируем.
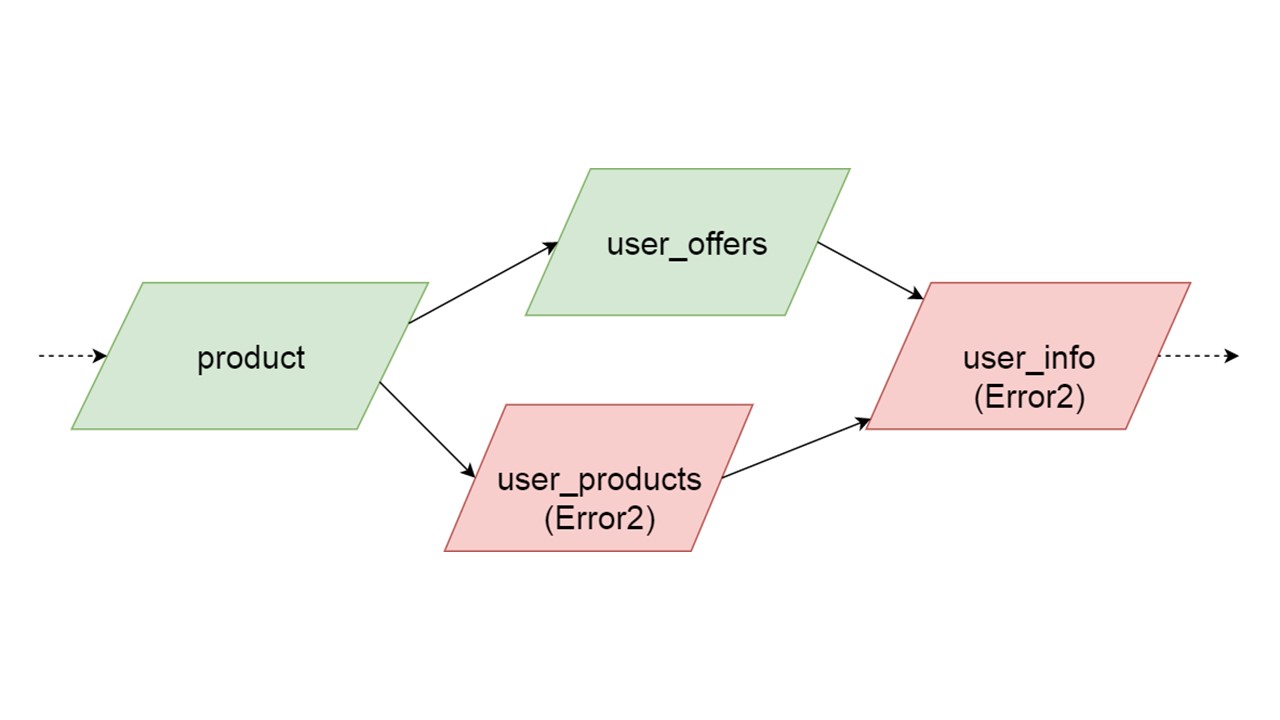
Может получится так, что два параллельно инициализируемых типа сгенерируют разные ошибки. В этом случае функциональность, которая зависит от обоих типов, даст суммирующий тип ошибок. Разработчик, инициализируя свой Fallback в среде разработки, получит полный список данных с ошибками. Естественно, он может исправить здесь и получить ошибку дальше. Но не будет такого, что одна совершенно не зависящая ветка закроет ошибки, которые мы могли бы получить, независимо от этой ветки.
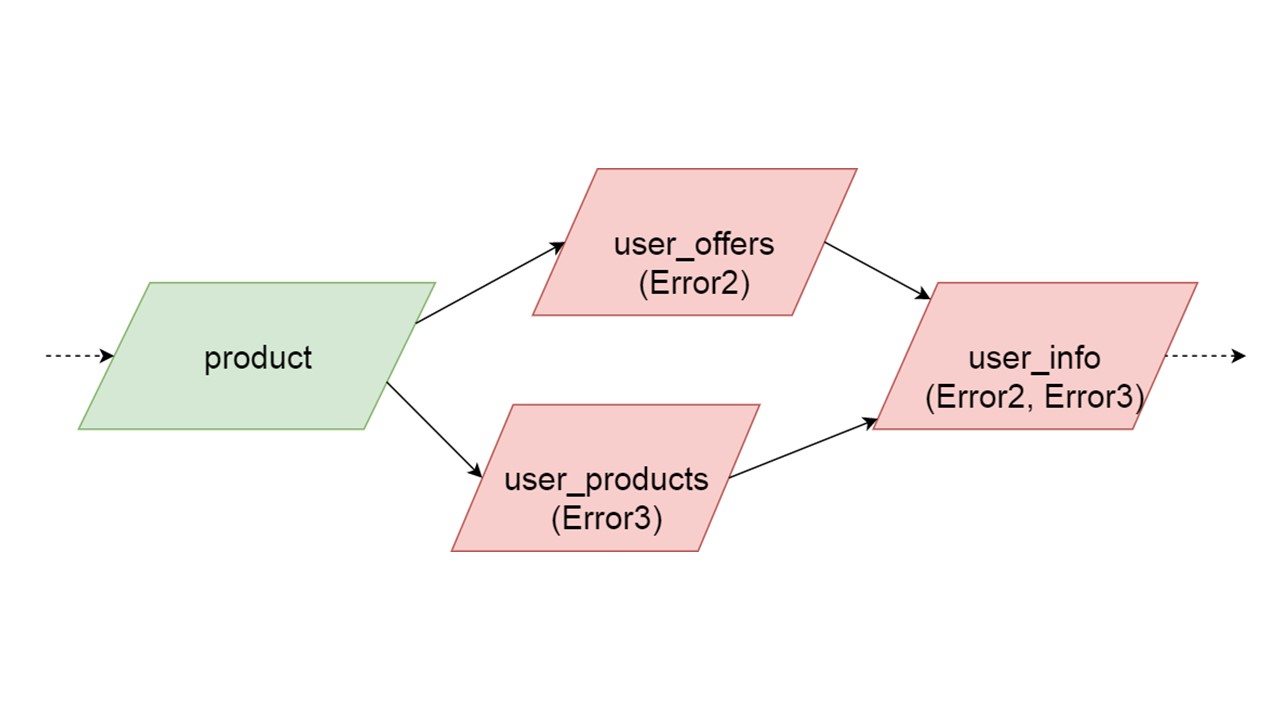
Инициализация: таблицы
Дальше мы создаем таблицы.
def getOffer (user: User, number: Long): Future[OfferData]
create table get_offer(
key frozen, bigint>>PRIMARY KEY,
value frozen
)
Такой запрос может прямо сразу запускать REST или SOAP-запрос, создавать внутри дополнительные операции, или даже запускать несколько запросов. Все зависит от вашего кода — как вы организовали код, так и будет. Fallback совершенно не анализирует, что происходит внутри метода, на который вы вешаете такую заглушку.
Метод обязательно должен быть асинхронным, потому что Fallback такой же. В Scala это помечается специальным типом Future. Это значит, что результат вернется когда-нибудь. Когда точно — неизвестно: может сразу, а может нет.
Для метода создаем таблицу. В качестве ключа в таблице выступает кортеж (tuple) из всех типов, которые соответствуют параметрам этого метода. В качестве неключевого значения выступает результат, который возвращаем асинхронно. Для каждой такой таблицы заранее готовим два параметрических запроса: вставить данные и прочитать данные.
insert into get_offer(key, value) values (?key, ?value);
select value from get_offer where key = ?key;
Для взаимодействия с СУБД все готово. Осталось выяснить, как мы будем читать данные из Fallback.
Circuit Breaker
Здесь ответственность переходит в зону известного паттерна Circuit Breaker.
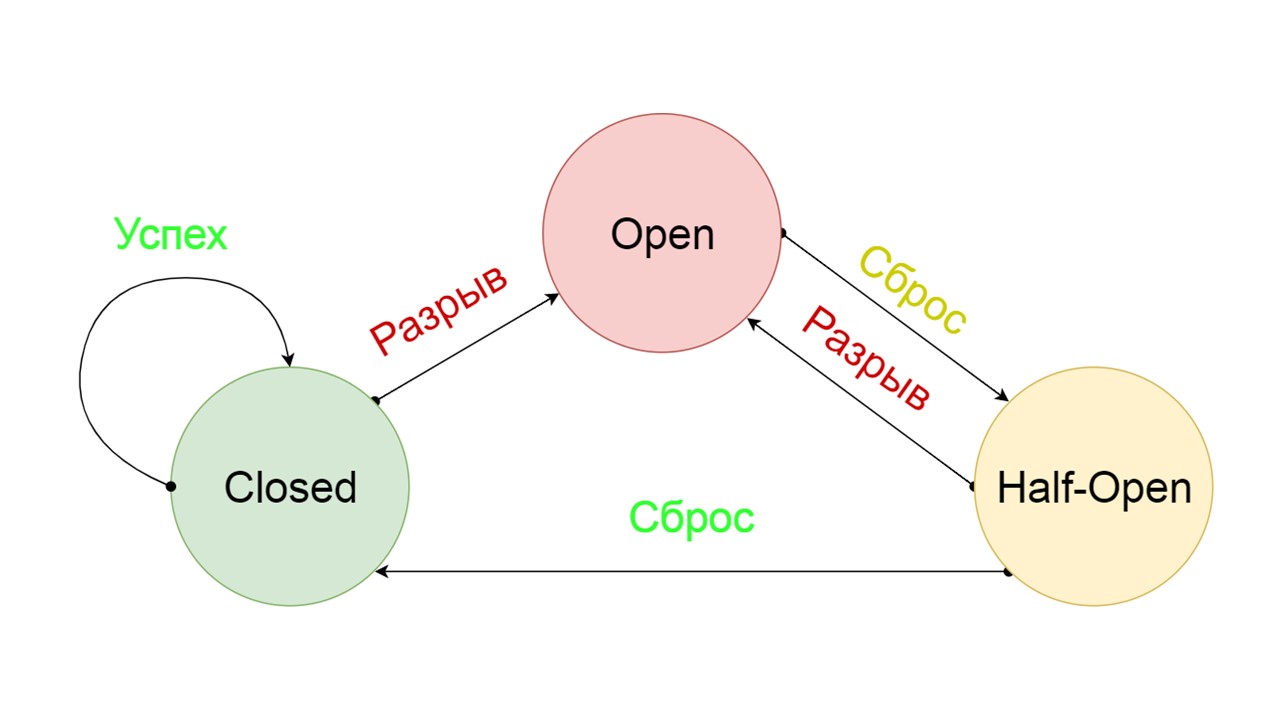
Типичный Circuit Breaker включает три состояния.
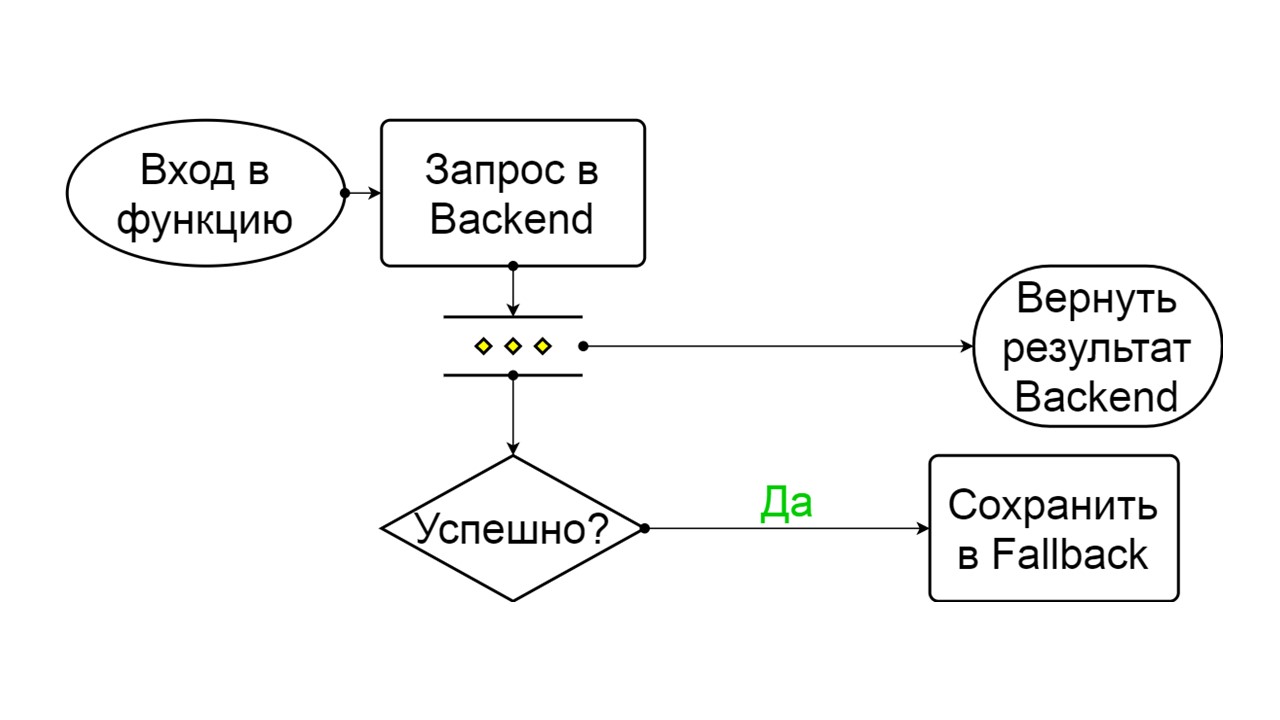
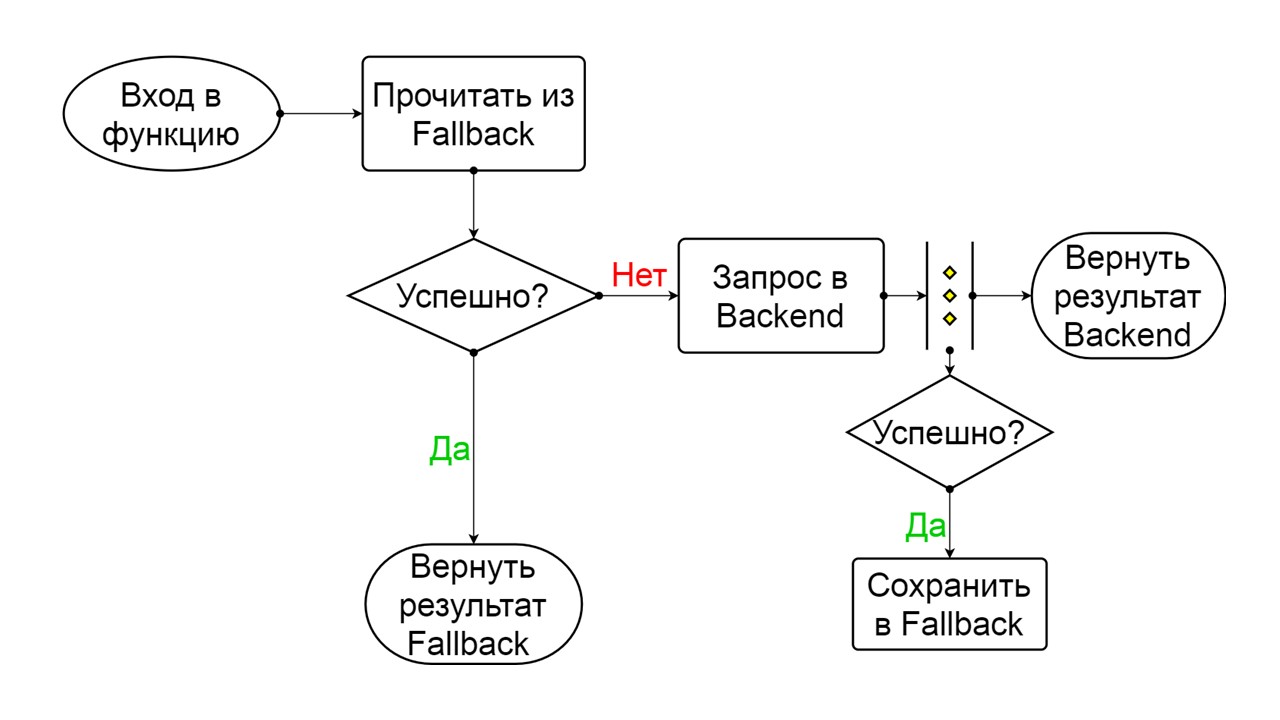
Closed — замкнутое состояние по умолчанию, которое закрывает наш бэкенд. Принцип в том, что мы читаем данные сначала из бэкенда, и только если не удалось их получить — идем в Fallback. Если данные удалось получить — не ищем в Fallback, а сохраняем в нем данные, и ничего не происходит.
Если проблемы идут одна за другой, мы предполагаем, что бэкенд лежит. Чтобы не спамить его гигантским количеством новых запросов мы переходим в Open — в разорванное состояние. В нем пытаемся читать данные только из Fallback. Если не получается — сразу возвращаем ошибку, и даже не трогаем основной бэкенд.
Спустя время мы решаем узнать, очнулся ли бэкенд, и пытаемся сбросить состояние Half-Open — короткоживущее состояние. Срок его жизни — один запрос.
В короткоживущем состоянии мы выбираем сомкнуться снова или разомкнуться на еще более длительное время. Если в состоянии Half-Open успешно достучимся до Fallback и получим следующий запрос — переходим в состояние Closed. Если не удалось достучаться — возвращаемся в Open, но уже на длительное время.
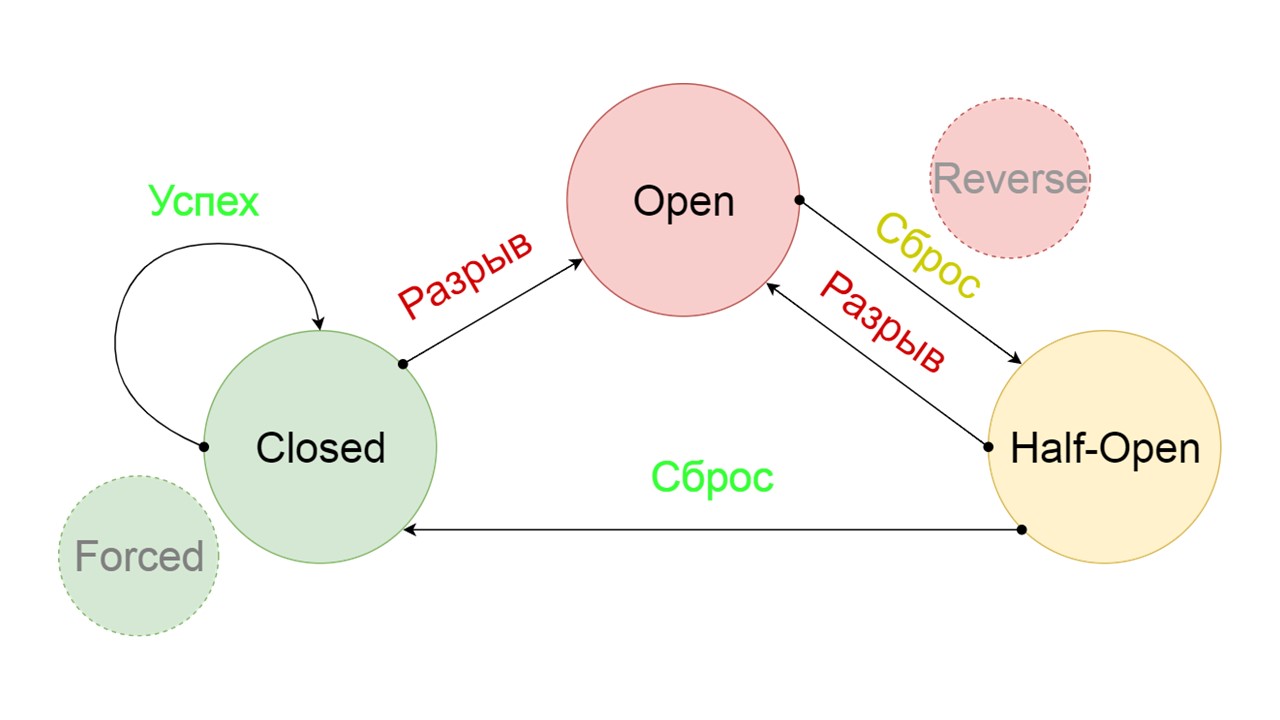
Мы добавили два дополнительных состояния, которые явно не связаны со схемой Circuit Breaker:
- Forced — насильно замкнутое состояние;
- Reversed — приоритет на разомкнутое, инвертировано замкнутое состояние.
Разберем, что они делают.
Принцип работы состояний
Closed. Схема большая, но из нее достаточно понять общий принцип. Мы сохраняем Fallback параллельно с тем, как возвращаем результат из бэкенда, если там все прошло хорошо и читаем из Fallback. Если плохо везде — приоритетно возвращаем ошибку.
Из двух ошибок выбираем ошибку бэкенда.
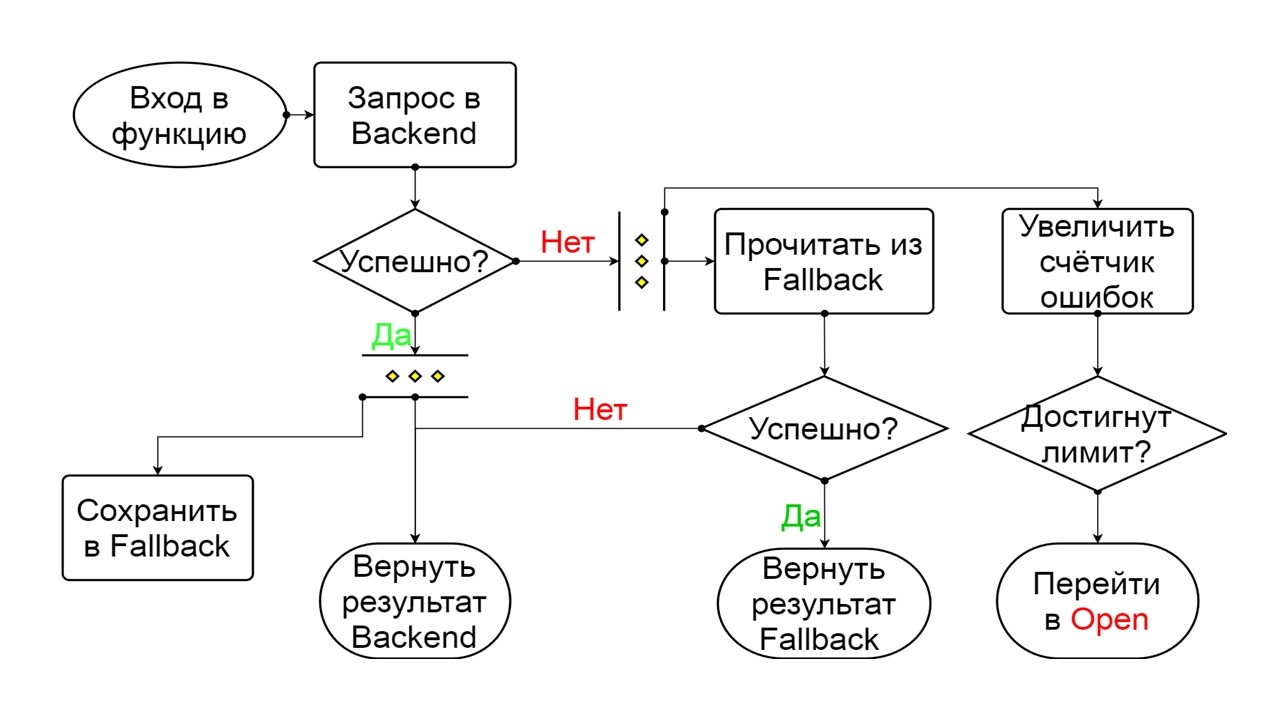
Если ошибок нет — параллельно с этим инкрементируем счетчик и переходим в разомкнутое состояние, когда запросов слишком много.
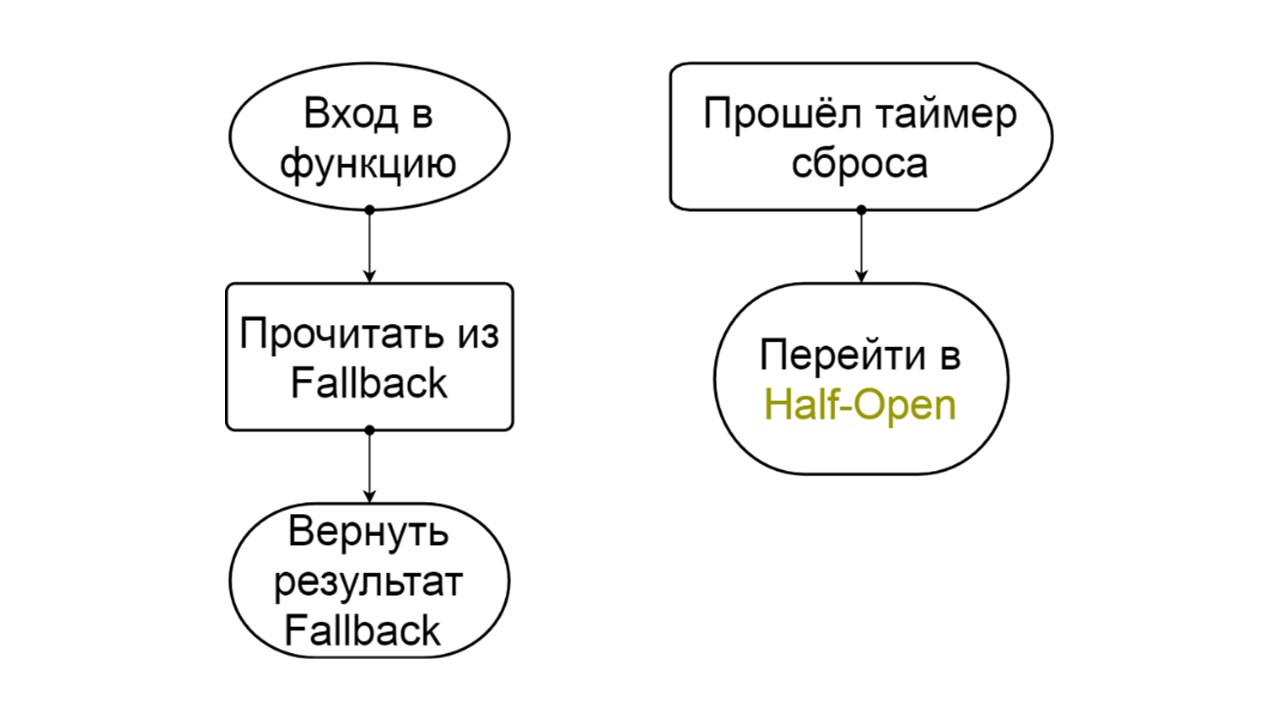
Open. Разомкнутое состояние Open проще — постоянно читаем из Fallback, что бы ни произошло, и через некоторое время пытаемся перейти в состояние Half-Open.
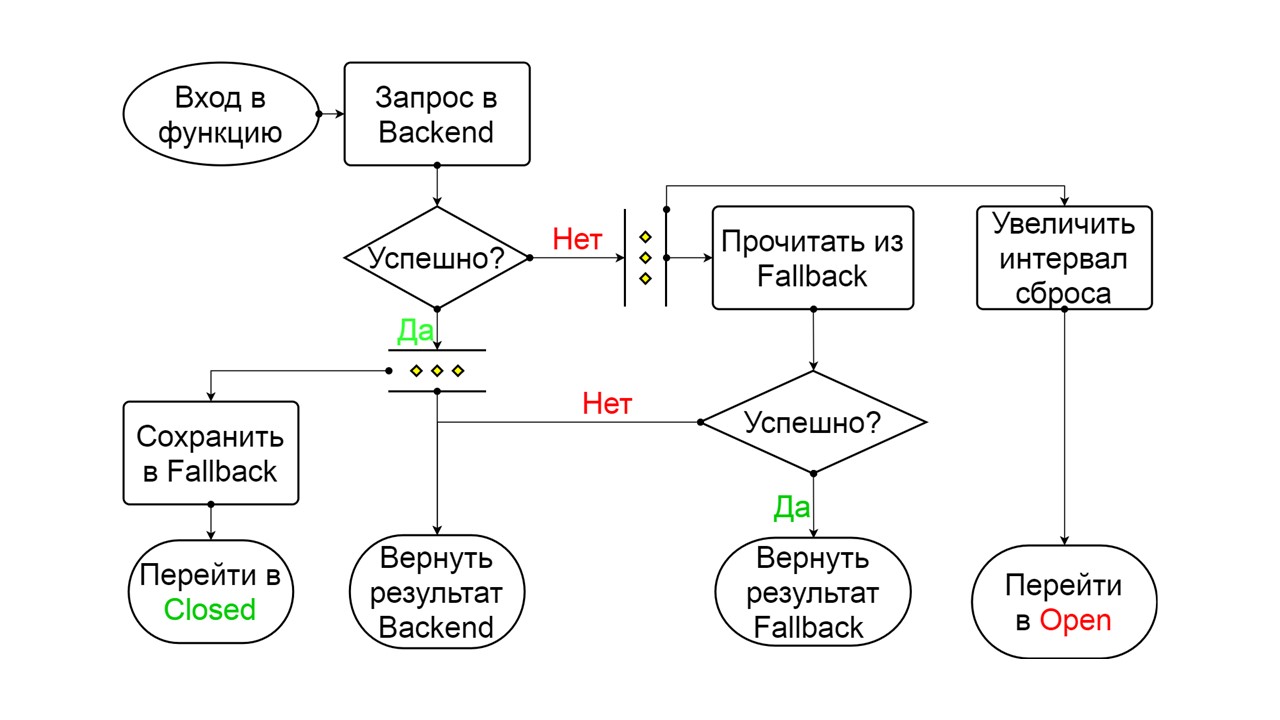
Half-Open. Состояние по структуре напоминает Closed. Разница в том, что в случае успешного ответа мы переходим в замкнутое состояние. В случае неудачи — возвращаемся обратно в разомкнутое с увеличенным интервалом.
Forced — это дополнительное состояние для прогрева кэша. Когда заполняем его данными, не пытается никогда читать из Fallback, а только добавляет записи.
Reversed — второе надуманное состояние. Работает как персистентный кэш. Состояние включаем, когда хотим перманентно снять нагрузку с бэкенда, даже если данные могут быть неактуальны. Reversed сначала ищет в Fallback, и если поиск не удался — идет в бэкенд и разбирается с ним.
Проблемы
Со всей этой схемой у нас возникло несколько проблем. Самая серьезная — с осознанием того, как работают prepared statements в Cassandra. Эта проблема исправлена в версии 4.0, которая еще не вышла, поэтому расскажу.
Cassandra рассчитана на то, что к ней одновременно подключаются миллионы клиентов, и все пытаются подготовить свои prepared statements. Естественно, Cassandra не готовит каждый prepared statement, иначе у нее закончится память. Она вычисляет параметр MD5 на основе текста, key space и опций запроса. Если ей приходит точно такой же запрос с точно таким же MD5, она берет уже подготовленный запрос. В нем уже есть информация о метаданных и как с ними обращаться.
Но возникают проблемы версий. Мы выпускаем новый релиз, в нем успешно накатили миграции, добавили поля в типах и запускаем prepared statements. Они возвращаются с предыдущей версией нашего состояния и метаданных — с типами без полей. На момент чтения данных, мы пытаемся записать их новые обязательные столбцы, и сталкиваемся с тем, что их просто нет! Cassandra говорит, что это вообще другой тип, который она не знает.
Мы справились с этой проблемой так: добавили в каждый из наших подготовленных запросов уникальный текст.
create table get_offer(
key frozen, bigint>> PRIMARY KEY,
value frozen,
query_tag text
)
insert into get_offer (key, value, query_tag)
values (?key, ?value, ‘tag_123’);
select value as tag_123 from get_offer where key = ?key;
У нас не будет миллионов подключаемых клиентов, а всего одна сессия на каждую ноду, которая держит несколько подключений. Для каждой подготавливаем один раз statement. Мы предполагаем, что ничего страшного, если на каждую версию приложения или на каждый старт ноды, генерируется уникальный текст, который явно будет в тексте нашего запроса.
Мы добавили специальное поле, чтобы с ним хитрить. При вставке записываем в это поле константу. Она уникальна для каждого старта или версии приложения — это настраивается в библиотеке. При чтении мы используем это имя, как alias для value, который мы достаём. Запрос точно такой же, мы все еще делаем select value, но текст у него уже другой. Cassandra не догадывается, что это тот же самый запрос, вычисляет другой MD5 и подготавливает запрос заново с новыми метаданными.
Вторая проблема — мigration race. Например, мы хотим сделать несколько параллельных миграций. Запустим несколько нод и они одновременно начнут вычисления, запустят create tables, create types. Это может привести к тому, что на каждой ноде или в каждом из параллельных потоков все пройдет успешно и вроде бы успешно будут созданы две таблицы. Но внутри себя Cassandra запутается, и мы будем получать timeouts на запись и чтение.
Можно сломать Cassandra, если пытаться параллелить процессы с нескольких потоков или c нескольких нод.
Если знаем, что у нас должна быть миграция Fallback — проводим миграции с одной специальной ноды перед релизом. Только потом стартуем все свои ноды во время релиза. Так мы решили эту проблему.
Третья проблема связана с недостатком данных в Fallback Cache. Может быть так, что мы «зафуллбэчили» метод, он должен хранить исторические данные за год назад, а в реальности мы запустили его вчера.
Проблему решили прогревом. Мы использовали состояние Forced и запустили специальные ноды, которые не будут общаться с реальными пользователями. Они возьмут все возможные ключи, которые мы предполагаем, и будут по кругу прогревать кэш. Прогрев идет с такой скоростью, чтобы не убить бэкенд, с которого мы читаем.
Масштабирование приложений, бэкенд, большие данных и фронтенд — для всего этого подходит Scala. 26 ноября мы проводим профессиональную конференцию для Scala-разработчиков. Стили, подходы, десятки способов решений для одной и той же задачи, нюансы использования старых и проверенных подходов, практика функционального программирования, теория радикальной функциональной космонавтики — вас ждет много открытий. Подавайте заявку на доклад, если хотите поделиться своим опытом по Scala до 26 сентября, или бронируйте билеты.
