Бесконечная локализация, или как мы переводим карту в режиме реального времени
Что происходит, когда ваш продукт начинает продаваться в другой стране со своим языком и культурными особенностями? Скорее всего, его ждёт локализация. В большинстве случаев требуется перевести только ресурсные файлы, чтобы меню и элементы интерфейса были на привычном пользователю языке. Но что делать, если основа того, что вы продаёте, — данные, которых много, они поступают постоянно, в большом объёме и требуют регулярного перевода. Причём не на один язык, а сразу на несколько.
Под катом вы найдете историю, как этот вопрос решали в 2ГИС. Я расскажу на примере последнего кейса с Дубаем, но практики применимы для любого языка.
Про шейха
Вся эта история началась с того, что 2ГИС запустился в Дубае, где в ходу два языка: арабский и английский.
Высокая точность данных — важнейшая ценность компании. Она достигается ручным трудом картографов и специалистов на местности. В Дубае, где и местные специалисты, и конечные пользователи знают английский язык, данные вносились только на нём. При этом хранение данных на других языках не подразумевалось.
Схема успешно работала, пока в дело не вмешалась бюрократия. Для осуществления картографической деятельности нужна лицензия, а лицензию выдаёт правительство той страны, на чьей территории ты работаешь. Местному шейху не понравилось отсутствие арабского языка в приложении, и он пригрозил лицензию не выдать, если его просьба останется без внимания.
Портить отношения с шейхом — дело неблагодарное. Мы решили выработать требования так, чтобы один раз сделать и больше не вспоминать об этой проблеме при выходе на другие территории и новые языки.
Fiji
Для работы картографов у нас есть собственный софт. Эта штука называется Fiji и служит мастер-системой по сбору картографических данных. Мы уже писали, как Fiji помогает картографам редактировать домики и рисовать дороги. Выгруженные из Fiji данные после обработки и подготовки идут в конечный продукт, чтобы радовать пользователей. В статье я рассказываю именно про то, что мы реализовали в Fiji для редактирования / хранения / отображения мультиязычных данных.
Термины
В команде мы используем специфичную лексику. Ниже четыре примера ↓
Система поддерживает работу с двумя типами языков:
Язык метаданных — язык, на котором отображаются все пользовательские элементы управления: UI, метаданные.
Язык данных — язык, на котором отображаются значения атрибутов фич, некоторые справочники и классификаторы.
Языки привязаны к территориям. У территории может быть два типа языков:
Основной язык территории — язык, официально принятый на данной территории.
Дополнительный язык территории — язык, на котором мы хотим выпускать продукт. Идёт в дополнение к основному.
Языки и диалекты
Диалекты, принятые в разных регионах страны, могут существенно отличаться. Поэтому в некоторых системах отдельно хранят ядро языка (= базовый вариант) и диалекты, а потом при выгрузке их мерджат. Нам такой подход показался очень сложным, поэтому мы решили считать каждый диалект самостоятельным языком.
Нюанс, связанный с арабскими языками и диалектами. Для каждого языка нужно ввести флаг направления каретки с двумя значениями: слева направо и справа налево. По умолчанию каретка должна двигаться слева направо. Если выставлено значение справа налево, то нужно менять направление каретки для всех редактируемых, мультиязычных полей. Как это делалось в конечных продуктах было написано тут. Нам нужно было сделать примерно то же самое.
Привязка к территориям
Весь мир у нас поделен на определенные территории — это могут быть страны, области, регионы. Для каждой территории мы задаем несколько языков, один из которых считается основным, а остальные — дополнительными. Перевод происходит с основного языка на дополнительные.
Например, в случае с Дубаем основным языком мы оставили английский, ведь на нём было много данных. Арабский же сделали дополнительным.
Ввод и смена языка
Для комфортной работы картографов мы переработали наш интерфейс в тех местах, где подразумевается мультиязычный ввод.

На этой картинке видно, что мы разбили языки по вкладкам, где самая левая — это основной язык, а дальше идут дополнительные.
Во вкладках дополнительных языков доступны для редактирования только те поля, у которых в базе данных стоит флаг необходимости перевода. Это служит защитной мерой и помогает сфокусировать внимание пользователя на переводе нужных данных. Всё остальное редактируется на основном языке.

На самом деле редактирование данных на дополнительном языке может понадобиться только в том случае, если картограф сам знает несколько языков и не хочет прибегать к помощи переводчика. Для всех остальных есть CrowdIn.
CrowdIn, или перевод на потоке
Итак, мы дали возможность нашим картографам заполнять данные на разных языках. Но гораздо лучше передать задачу по переводу профессионалам.
Первое, что приходит в голову при переводе приложения, — это отдавать ресурсные файлы переводчикам и после перевода загружать их назад.
В этом деле нам сильно помогла платформа CrowdIn. Она позволяет переадресовать ваши файлы профессиональным переводчикам. Дело оставалось за малым — интегрировать переведённые данные в нашу систему.
Ситуация осложняется тем, что данные к нам поступают непрерывным потоком, поэтому и переводы мы бы хотели получать непрерывно.
Оптимизировали систему так: если изменения внесены на основном языке территории — мы выгружаем изменения на перевод на все дополнительные языки этой территории. Исключения делаем для случаев, когда перевод внёс сам картограф. Тут мы считаем, что он понимает, что делает, и незачем подключать переводчика.
Для каждого справочника или объекта карты у нас заведена сквозная версия, которая инкрементируется при каждом обновлении данных. Так мы можем быстро получать все изменения с определённой версии.
Система версионности очень проста и эффективна, но имеет существенный недостаток: по сути мы имеем единую очередь и не можем ею никак управлять. Наш максимум — это пропустить версию. Потребность перейти на нормальную очередь, например, на RabitMQ или Kafka, есть, но руки пока не дошли.
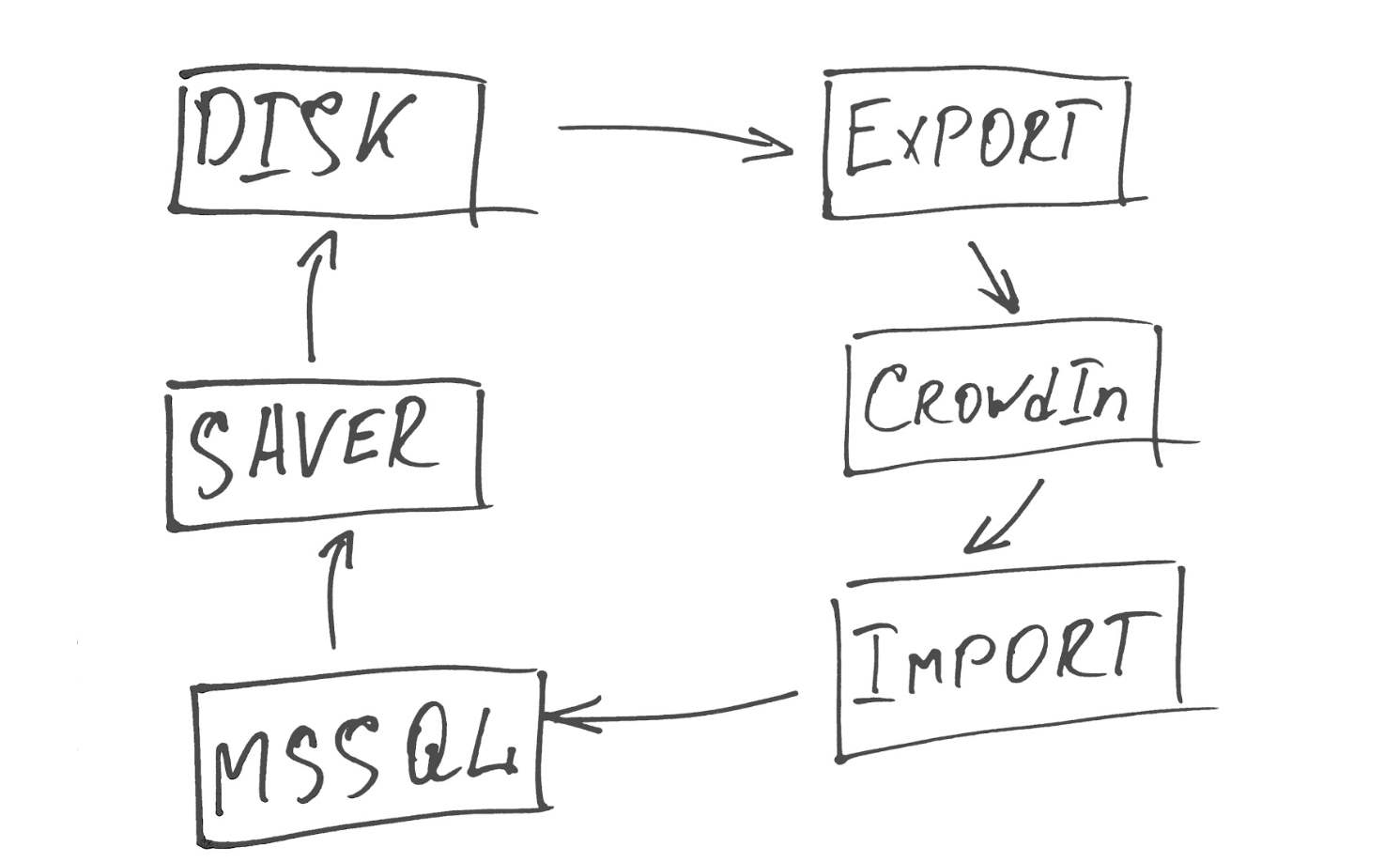
Для оперативного обновления контента мы написали небольшой сервис, работающий в три потока.
Первый поток (Saver) выгребает все данные, требующие перевода, и формирует из них xml-файлы.
Второй (Export) засылает их на CrowdIn и складывает в нужный проект, где указан основной язык, с которого переводим, и список языков, на которые нужно переводить.
Третий (Import) периодически опрашивает API CrowdIn на наличие файлов, у которых перевод был сделан и заапрувлен на 100%, и импортирует готовые файлы в нашу БД.
Без грабель не обошлось. Мы споткнулись об нашу систему версионности данных.
Когда мы загружали перевод слова, версия данных обновлялась и слово снова попадало на перевод.
Чтобы избежать бесконечного цикла перевода, мы начали вести учёт данных. Каждое переведённое слово маркируется, что позволяет исключить его повторную отправку в CrowdIn.
Туториал
Теперь расскажу, как происходит сама работа с CrowdIn. Есть несколько способов работы с платформой, например, можно залить файлы в Git-репозиторий и CrowdIn их сам засосёт. Но мы посчитали, что работа через API выглядит удобнее.
У CrowdIn есть довольно подробный туториал, но ниже я напишу, как делали мы.
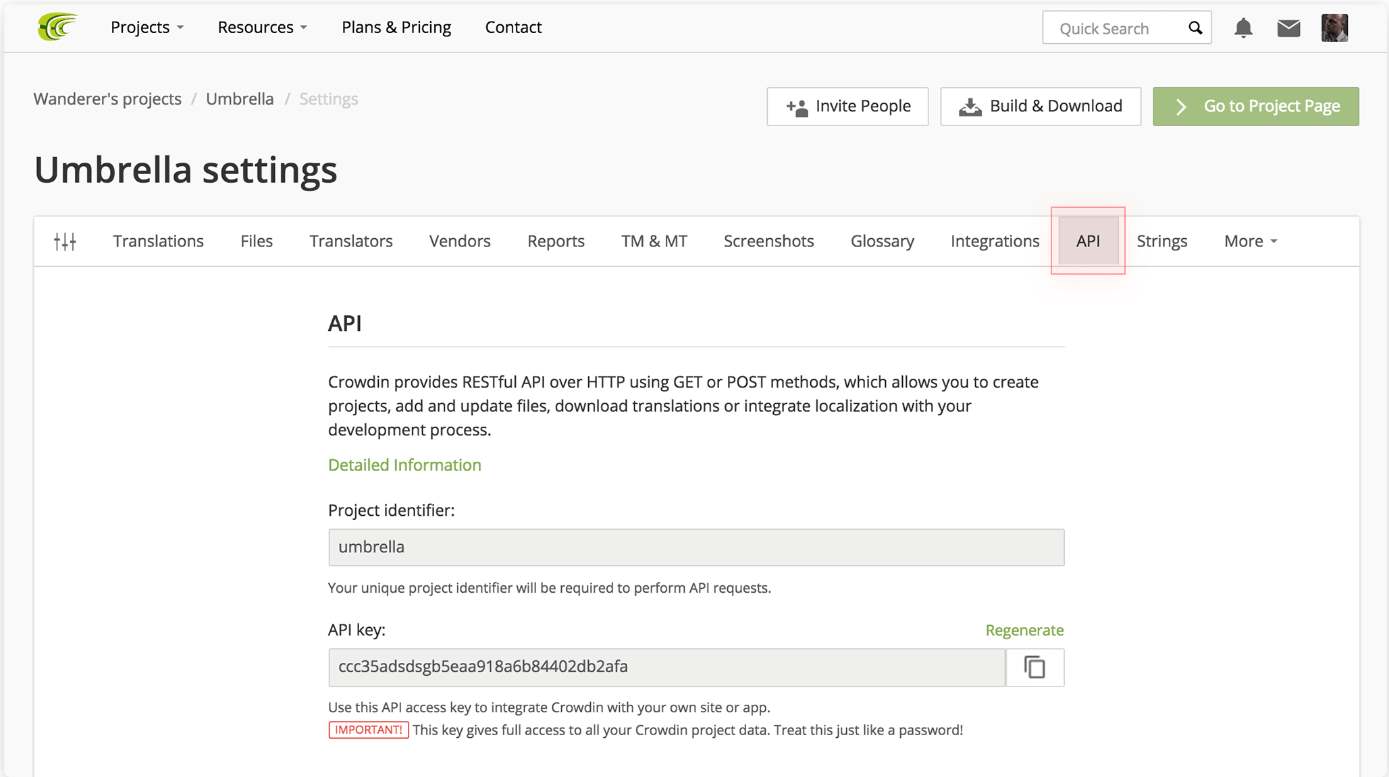
Нужно получить API key, который мы будем цеплять к каждому нашему запросу, чтобы система нас верифицировала. Идём на вкладку API в настройках проекта и смотрим, что написано в графе API key.
Этот ключ нужно дописывать в конце каждого вашего запроса к платформе. Например так:
GET: https://api.crowdin.com/api/project/{myLitleProject}/download/all.zip?key={project-key}
2. Создаём папку, куда будем заливать файлы внутри проекта.
var uri = $"project/{_projectName}/add-directory?key={apiKey}";
var content = new MultipartFormDataContent { { new StringContent(crowdInDirectoryPath), "name" } };
return PostAsync(uri, content);
Тут есть немного корявый момент. Мы пишем сервис, неплохо бы, чтобы он вначале проверял, присутствует ли нужная нам папка, перед тем, чтобы пытаться её создавать. У CrowdIn нет нормального способа проверить наличие папки, поэтому мы отправляем запрос на создание. Если её нет, CrowdIn её создаст и вернёт код 200. Если папка была, он ничего создавать не будет и вернёт код 500.
3. Экспорт файлов. У функции add-file очень много опций и параметров, как читать и откуда. Ниже пример, как мы загружаем данные xml-файлами.
…
Чтобы CrowdIn мог разобрать, какие данные из файла нужно переводить, ему нужно это указать. Для этого в контент нужно записать массив параметров translatable_elements с путями до нужных элементов документа. В нашем случае это выглядело так:
var uri = $"project/{_projectName}/add-file?key={apiKey}";
var content = new MultipartFormDataContent { { new StringContent("/LocalizableDocument/LocalizableValues/LocalizableValue/Attributes/LocalizableAttributeValue/Value"), "translatable_elements[0]" } };
foreach (var filePath in filePaths)
{
var fileName = Path.GetFileName(filePath);
var fileStream = File.OpenRead(filePath);
var fileContent = new StreamContent(fileStream);
content.Add(fileContent, $"files[{_crowdInDirectoryPath}/{fileName}]", fileName);
}
return PostAsync(uri, content);
Обратите внимание: в документации прописано, что CrowdIn может прожевать максимум 20 файлов за раз, при этом размер одного файла не должен превышать 100 MB.
4. Узнаём, какие файлы у нас полностью переведены. Это мы делаем с помощью команды для конкретного языка.
var uri = $"project/{_projectName}/language-status?key={apiKey}";
var content = new MultipartFormDataContent {{ new StringContent(langCode), "language" } };
return PostAsync(uri, content);
Платформа вернёт нам что-то такое:
-
directory
29812
Version 1.0
-
file
29827
strings.xml
file
7
0
0
32
0
0
Здесь нас интересуют значения
5. Импортируем файл обратно в нашу систему.
Это делается с помощью простого GET-запроса.https://api.crowdin.com/api/project/{_projectName}/export-file?file={_crowdInDirectoryPath}/{fileName}&language={langCode}&key={project-key}
Полученный файл десериализуется и данные импортируются в нашу систему.
Вместо заключения
В общих чертах это всё. Конечно, нам ещё потребовалось дорабатывать отображение подписей на карте Fiji, чтобы они показывались на нужном языке в зависимости от того, какую территорию сейчас правит картограф. Нужно было договориться с другими системами, как мы им будем поставлять мультиязычные данные, но это уже другая история.
В итоге мы получили сервис в духе «включил и забыл». Картографы вносят данные, переводчики — переводят, шейх доволен, сервис заливает данные куда надо, а мы решаем более актуальные задачи, не задумываясь о том, как наша система работает на нескольких языках.
