Базы данных. Тенденции общемировые и в России
Эта статья не является ответом на множество вопросов по базам данных (БД) и системам управлениям базами данных (СУБД). Я как автор выражаю своё собственное мнение о трендах, стараясь опираться на беспристрастные показатели, статистики и т.д., но для примера приводя собственный опыт. Я не являюсь ангажированным представителем какой-либо компании и выражаю точку зрения опираясь на опыт более 25 лет работы с разными СУБД, в том числе, которую создавал своими руками. Не так много даже опытных программистов и архитекторов, которые знают все термины, технологии, какие подводные камни и куда идёт движение. Тема поистине огромная, поэтому в рамках одной статьи не раскрыть даже верхний уровень информации. Если кто-то не встретит свою любимую СУБД или её невероятный плюс, который стоит упомянуть, то прошу в комментариях указать и этим дополнить общую картину, что поможет другим разобраться и понять лучше предметную область. Поехали!
Open Source DBMS vs Commercial DBMS
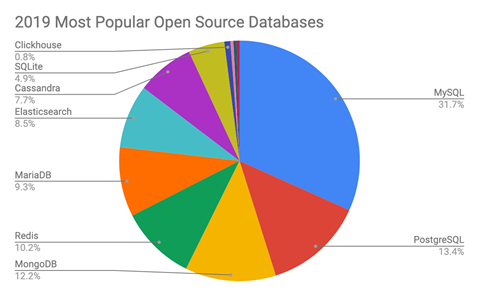
Для начала приведу график с сайта, db-engines.com, по моим ощущениям, неплохо отслеживающим тренды БД. Именно этот график добавил желания написать статью о текущем положении дел. Когда мы говорим фразу «база данных», то на самом деле чаще имеем в виду конкретную систему управления базами данных (СУБД), поэтому если в тексте встретится БД вместо СУБД, то это в силу такой привычки.
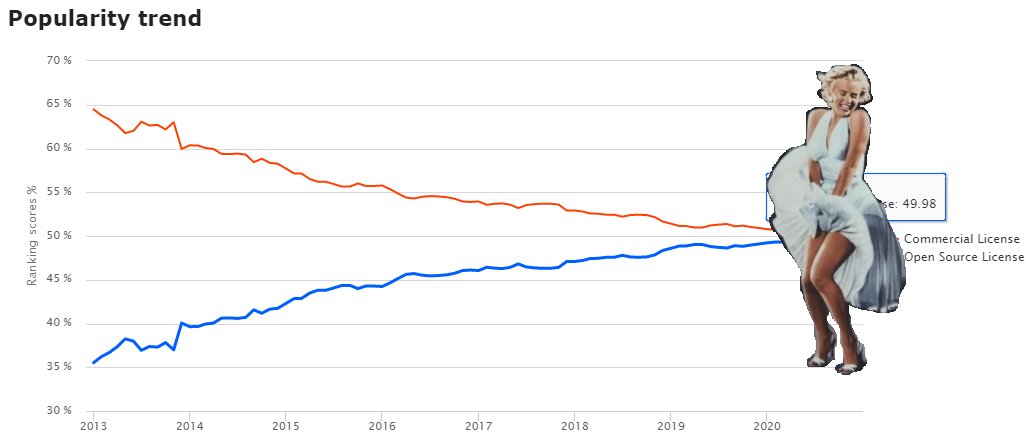
Open Source DBMS — системы управления баз данных с открытым исходным кодом догнали коммерческие СУБД с закрытым исходным кодом. Open Source 49.98% против 50.02% у Commercial. Итогом 2020 года становится момент, когда можно будет сказать, что open source не менее популярны. Как вы видите, эта ситуация возникла не внезапно. Подсчёт на графике не в численном соотношении, а в очках, которые набирают те или иные системы.
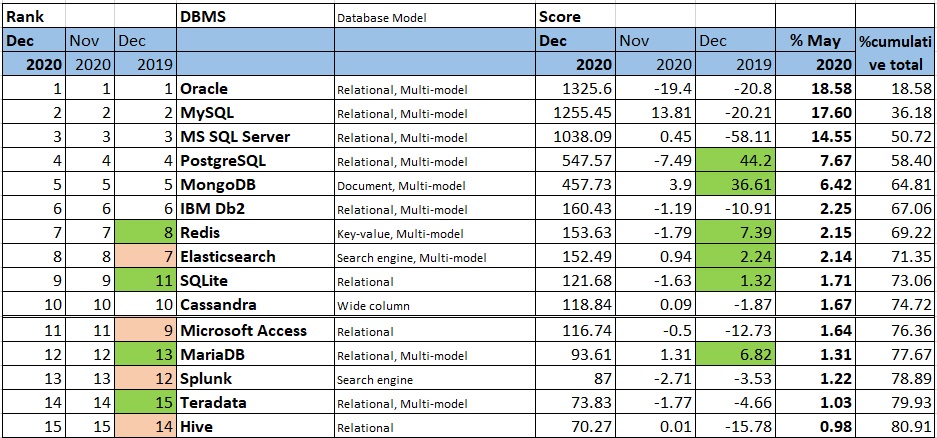
Для интереса можете посмотреть на сайте где находится ваша любимая СУБД в рейтинге. Итогом последнего года стал вылет Microsoft Access из десятки, он вместе с языком программирования COBOL напоминает, что жизненный цикл технологий может быть очень длинным. Полагаю, что в следующем году IBM DB2 будет опускаться сильнее всего в топе. Топ 10 СУБД — это 75% всех набранных баллов. За год топ 10 в очках почти не поменялся.
Open Source вырос качественно за последние годы и всё больше ИТ специалистов, принимающих решение задаются вопросом, а стоят ли лицензии Oracle, MS SQL, IBM DB2 и прочих коммерческих продуктов, чтобы в них вкладываться. Не в малой степени этому способствуют аппетиты одноимённых компаний. В последние годы стало модно в коммерческих продуктах продавать enterprise licenses (лицензии уровня предприятий без искусственных ограничений функционала) за ядра процессоров. Можете по ссылке посчитать, что выходит для сервера с 4 процессорами по 16 ядер — всего 64 ядра если вам не подходят лицензии за пользователей.
MS SQL — 439 936$
Oracle — 1 368 000$
Мало того, запутанная система лицензирования, в которой не всегда разбираются даже в компаниях, продающих эти лицензии приводит к ситуации, когда к вам придут и скажут, что вы не докупили лицензий за нечто на сумму большую чем вы уже приобрели и заложили в бюджет. И это не редкая ситуация.
Прошлый 2019 год и текущий 2020 проходили с растущим влиянием компании AMD и её центральных процессоров, включая серверные EPYC, которые кардинально меняют стоимость физических ядер, а это значит, что ядер будут покупать всё больше. Многоядерность AMD развилась с внедрением чиплетов и теперь 64 ядра в одном процессоре — это реальность. Готовы ли будут компании покупать платные лицензии платных СУБД на ядра в разы больше? Не уверен. Физический сервер будет получаться по стоимости на порядок ниже лицензий. Серверный рынок довольно инертный и на AMD не перейдут и за несколько лет, но Oracle, Microsoft и прочие начнут терять долю ещё быстрее если не изменят политику. Microsoft выпускал версию SQL Server для Linux, но опять же за деньги и не нашлось большого числа желающих её купить. IBM DB2 теряет долю рынка уже давно.
Переход многих компаний на микросервисы (наверняка слышали на российских конференциях и форумах «мы пилим монолит на микросервисы») зачастую приводит к отделению данных физически на разные сервера, для коммерческих СУБД это платные лицензии, для Open Source нет. Чтобы не выйти из бюджета выбирают бесплатные решения.
Уместно будет сказать, что бизнес коммерческих СУБД выгоден и ими владеют богатейшие люди планеты. В топе самых богатых людей оказываются владельцы компаний, владеющих коммерческими СУБД: Билл Гейтс (Microsoft), Ларри Эллисон (Oracle), которые занимают значительную долю в топе СУБД. Ещё из топ 10 списка Forbes богатейших людей, у которых есть огромные или облачные БД присутствуют Джефф Безос (Amazon RDS), Ларри Пейдж и Сергей Брин (Google с их Bigtable).
В последнее время крупные ИТ компании с большими деньгами развивают open source проекты. Можно было бы подумать, что они прониклись идеями сообщества открытого кода, хотят сделать полезное для общества, их наполнило человеколюбие и прочее меценатство. Но нет, нужно понимать, что крупные акулы в бизнесе рассчитывают на некотором этапе монетизировать эти вложения, повысить положительное мнение о своих компаниях, занять рынки, воспользоваться бесплатным трудом сообщества, взять выстрелившие идеи. Шутка ли тысячи светлых голов коммитят в репозитории качественный код, тестируют на реальных проектах и денег не просят.
Тот же MySQL несмотря на название open source был уже продан за 1 млрд.$, Sun Microsystem, а потом поглощён Oracle. Основатель MySQL Майкл Видениус переоткрыл проект назвав его MariaDB. Я был на его выступлении в Москве где он призывал переходить на их продолжение оригинальной СУБД и надо сказать, что немалая часть разработчиков так и поступило. MariaDB уже на 12 месте.
Коммерческие СУБД дороги, но есть и масса плюсов, они стабильны, удобны, легко интегрируемы в ИТ инфраструктуру, есть система подготовки специалистов, сторонние компании расширяют функционал. Плюсом open source помимо бесплатности и растущей части возможностей платных СУБД можно считать и то, что вы можете взять код БД и поменять под свои нужды, как делал Facebook c MySQL. Для одной СУБД open source может быть несколько движков или несколько веток развития и вы можете выбирать любой вариант, который вам подходит. Влетевшая в топ 10 SQLite — мультиплатформенный продукт. Это персональная БД не использующая парадигму Сервер-Клиент, когда вам нужно с минимальными затратами просто локально хранить данные для приложения и пользоваться всеми плюсами СУБД.
Что в России: Нужно понимать, что когда в 70–80 годах году появились первые коммерческие продукты, например Oracle, у нас ещё был Брежнев, Олимпиада в Москве, перестройка, отставание в электронной промышленности и т.д. Мы пока догоняем или развиваем существующие системы.
Первые версии СУБД в мире были коммерческие, распространялись точечно, требовали присутствия специалистов. Покупать программное обеспечение (ПО) за валюту в нашей стране исторически не всегда принято (опустим обсуждение политических и экономических мотивов), поэтому альтернатива в виде бесплатных СУБД и пиратских версий коммерческих продуктов присутствуют. В институтах сейчас часто учат на бесплатных движках БД, открытое ПО — это стильно, модно, молодёжно. Поэтому рынок очень быстро наполняется специалистами в области open source. В России есть разработки СУБД в виде ClickHouse, Tarantool, ветки PostgreSQL и т.д., коммерческих экспортируемых БД нет. Есть реестр российских программ где можно поинтересоваться текущим положением дел по отечественным СУБД. Состав правда вызывает сомнение, например, наряду с названиями, которые вы могли слышать встречаются и с названием типа «Паспортный стол общежитий ВУЗа».
Переход на open source в России ускорился и в связи с санкциями. Помнится, выходившая новость об Oracle о возможном запрете продавать технологии для нефтегазовой отрасли России поменяло вектор видения будущего в умах и бюджетах некоторых наших компаний с хорошими бюджетами на ИТ. Как выше сказал фраза «мы пилим монолит на микросервисы» зачастую приводит в Open Source. В России, да как и во всём мире, растут PostgreSQL, MySQL, SQLite, MongoDB проекты.
Многим могло показаться, что open source давно обогнал commercial, но это мнение может сложиться если вы относитесь к миру online проектов, сайтов, приложений для смартфонов и т.д. Из этого следует следующее сравнение online vs. offline.
БД online проектов против offline
Есть 2 класса проектов, которые в чём-то похожи, а в чём-то нет. Это проекты с основным направлением онлайн продаж или оффлайн бизнес.
Если вы берёте классический бизнес оффлайн, связанный с добычей природных ресурсов, банковским делом, дистрибьюцией (оптовые продажи) или ритейлом (розничные продажи), то развивался он чаще всего из стека технологий на базе Windows решений. И переходя в онлайн он может использовать стек технологий WISA (Windows, IIS, MS SQL, ASP.Net). Есть и онлайн проекты изначально на WISA, для примера, всем известный StackOverflow. На текущий момент, в чисто онлайн проектах доминирует стек технологий типа LAMP (Linux Apache MySQL PHP). Новые молодые команды, приходящие в существующий бизнес, часто не работали с Windows стэком технологий и предлагают переписывать существующие системы. В России эта тенденция очень хорошо ощущается в последние годы.
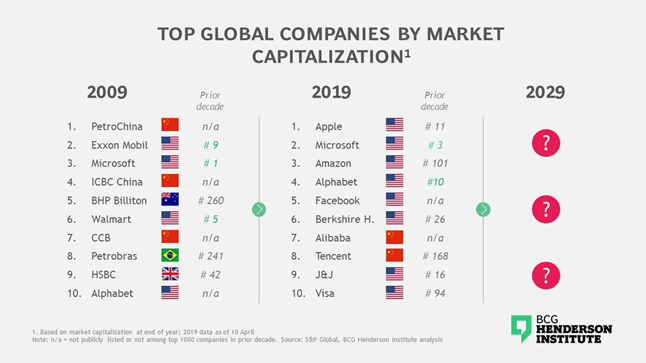
Деньги любят счёт, и чтобы сравнить долю онлайн или оффлайн проектов давайте посмотрим рейтинг по выручке в мире. В топе ритейл, добыча ресурсов, автомобилестроение и т.д. В крупнейших компаниях (не только России) обычно зоопарк из технологий, тут будут ERP, CRM системы в виде SAP, Microsoft Dynamics NAV или AX, 1C в России и много чего ещё. Компании с большим оборотом используют разные системы управления предприятием, которые в свою очередь часто используют коммерческие БД, Oracle, MS SQL, IBM DB2.
Но капитализация компаний в мире за последние 10 лет изменилась и мы видим, что в топе теперь ИТ гиганты и всего 2 компании из прошлого топа Microsoft и Alphabet (Google). В динамике изменения тут. Это значит смещение денежного потока в онлайн. Мы все уже привыкли и платить онлайн и переводить деньги, покупать товары с доставкой и т.д. А текущий 2020 год принёс немало прибыли именно онлайн компаниям.
Рейтинг компаний России по выручке. На первых местах добыча ресурсов, банки, ритейл, а не ИТ корпорации. Яндекс на 113 месте. Правда по капитализации Яндекс входит в топ 20. Тенденции по внедрению большего числа решений с open source есть, причины описаны выше. Исторически многие крупнейшие онлайн-ритейлеры (магазины) в России на платных БД, но задумываются над переходом тестируя части функционала на open source. Банки начали миграцию в онлайн, пример Тинькофф банка подтверждает, что нужно развивать онлайн банкинг.
По итогам года из-за текущей ситуации с вирусом явно число и размер online проектов выросло. Растут и облачные решения, об этом ниже.
Реляционные СУБД против остальных
Обилие статей в том числе на Хабре про разные виды БД вводят в заблуждение, что весь мир уже перестаёт использовать классические реляционные СУБД. На самом деле RDBMS — это подавляющее большинство всех СУБД в мире. На другие виды приходится около ¼ части и нужно понимать, что это чаще всего специфический функционал.
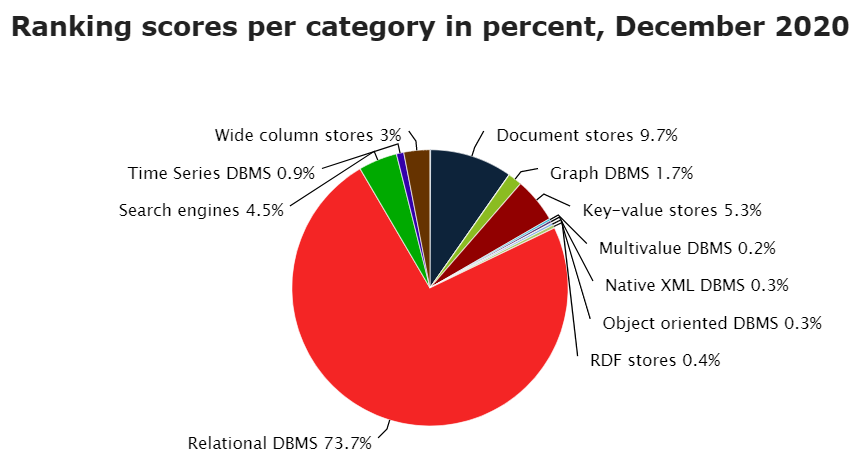
Для примера скажу, что в данный момент изо дня в день в работе типичной крупной компании может широко использоваться одновременно разные СУБД как платные MS SQL (Oracle) и ещё набор из MongoDB, Redis, MySQL, ClickHouse, ElasticSearch и т.д.
Рассмотрим очень кратко основные типы:
Relational: Главный тип, который ассоциируется с БД. Данные хранятся в виде 2-мерных таблиц с определёнными столбцами и строками, в которых хранятся значения. Индексы используются для ускорения поиска по указанному в создании индекса полю или полям. Связь между 2 таблицами идёт по одинаковым полям в них — ключам (Key). Для добавления, изменения, удаления данных используется язык SQL (Structured Query Language), о нём ниже. Описание структуры данных хранится в самой же БД в данных системных реляционных таблиц. Эта простая идея с 2-мерными таблицами выдержала проверку временем и продолжает быть самой распространённой.
Document stores:
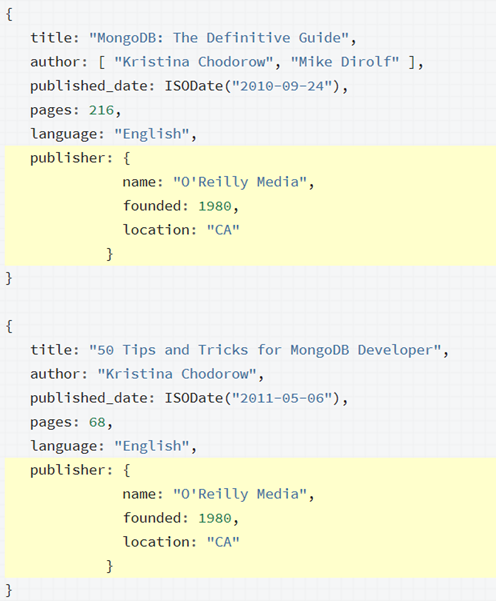
Отличие от реляционных БД в том, что данные хранятся в виде документов с любой структурой. То есть колонки таблицы жёстко не определены. Но тем не менее можно создавать индексы, которые вставляют ссылку на строку если находится указанный аттрибут документа. Типичный представитель MongoDB — хранение документов используя синтаксис JSON (Java Script Object Notation). На самом деле BSON (Binary JSON), который компактнее, как и любые бинарные типы чем строковые.
Вот так выглядят строки в коллекции (это аналог таблиц)
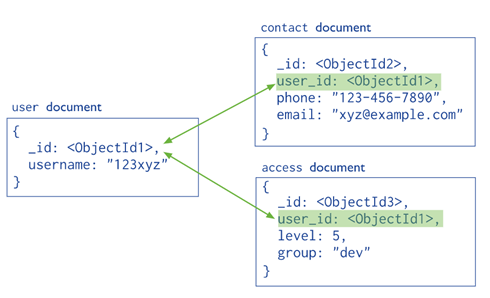
Точно также таблицы могут ссылаться друг на друга.
Key-Value: появился этот тип NoSQL решения из-за необходимости быстро записывать, менять и получать значения по какому-то параметру. Не редко это используют для некритичных, быстроменяющихся значений, которые нет смысла записывать и хранить. Типичный представитель — Redis. На старом ноутбуке вы можете получить десятки тысяч операций в секунду по записи, изменению данных. Достигается это тем что данные хранятся в памяти, с которой операции быстрее. Отсюда же и минус, что если памяти недостаточно, то скорость будет деградировать. Например, вы хотите измерять число запросов с 1 IP за минуту. Заводится строка где ключ это IP, любое обращение добавляет счётчику +1. Если запросов много, то троттлинг (ограничение). Ключ может иметь TTL и обнуляться раз в X минут.
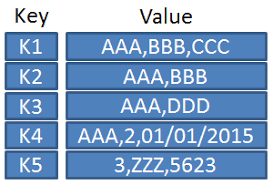
Search Engines: Поиск — это важная функция в любой системе. Если c поиском по точному совпадению в виде ID (кода, артикула, партномера и т.д.) реляционные БД справляются очень качественно и быстро, то поиск внутри документа по фразе, включая использование разных форм слова, множественного числа и прочих составляющих живого языка уже не выходит так быстро. Нужно сканировать данные от начала до конца и выискивать походящие документы. Поэтому поступают так как делают крупные поисковики индексируя страницы, если представить по простому, то они проходят по документам предварительно, составляют список слов, которые встречаются в документе и когда нужен поиск, то ищут по преподготовленным спискам слов с ссылками на документы, чем больше слов совпало тем вероятнее, что этот документ и нужен. Типичный представитель ElasticSearch его большое число инсталляций обусловлено ещё и тем, что существует типичный стек ELK (англ. лось) ElasticSearch+Logstash+Kibana для мониторинга событий, например, логов веб серверов или сервисов.

Wide column stores: Лучше всего представлять как среднее между реляционной БД и Key-Value БД. Есть таблицы, строки и колонки. Но колонки не имеют жёсткой структуры и могут иметь в разных строках разные названия и значения.
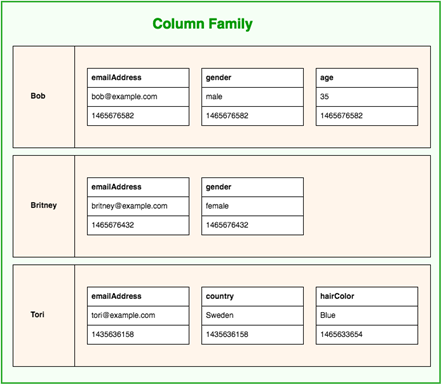
Представители этого типа БД — Cassandra, HBase.
Graph: Тип БД, который призван обрабатывать данные, которые представлены в виде графов. В виде графов можно представить населённые пункты (вершины) и дороги между ними (ребро). Типичная задача поиск нахождения кратчайшего маршрута между пунктами путём обхода графа в ширину или более продвинутыми алгоритмами.
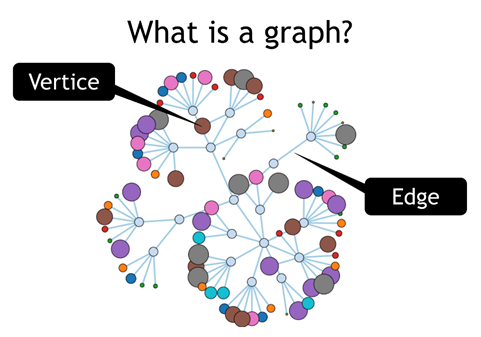
Также удобно представлять графами связи между людьми (вершины), что он знает кого-то (ребро) или их возраст и интересы. Формула химического соединения можно представить, что вершины графа — атомы молекулы, а рёбра это связи между молекулам. Теория графов обширна и развивается с 18 века, так что математическая база накоплена большая. Типичный представитель графовой СУБД — Neo4j.
Columnstore
Хотя в рейтинге db-engines этот вид не идёт отдельно, а относится к реляционным, но стоит его упомянуть. Коммерческие реляционные СУБД включают в себя и этот вид как отдельную особенность, но и существуют специализированные отдельные решения. Основное отличие колоночных БД, что данные хранятся не в строках, а в столбцах. Если у вас в столбце одни и те же значения, то они очень сильно компрессируются и меньше места занимают на диске и в памяти. Представители этого типа ClickHouse, Vertica. Эту картинку с анимацией лучше смотреть на сайте ClickHouse.
В последнее время стала появляться в диаграммах СУБД ClickHouse от Яндекса. Цифры разные, но то что её стали замечать и включать уже хорошо для её развития.
Multi-model databases
Во многих СУБД, помимо основного исторического типа хранения добавлялись новые с течением времени. Мир не стоит на месте, поэтому если создатели СУБД видели необходимость поддержать другие типы хранения данных, то они добавлялись. Поэтому у большинства современных СУБД из топа в описании может присутствовать «multi-model». Перевод крупных реляционных СУБД в разряд multi-model ограничила рост многих NoSQL решений в последние годы. Зачем использовать что-то ещё, если нужный тип включен в основную СУБД как вторичный.
SQL vs NoSQL
Сам термин NoSQL возник чуть более 10 лет назад примерно в 2009 году и как говорят сейчас «пошёл хайп». Многие новые программные продукты, которые были призваны решить некую проблему присущую связке Реляционная БД + SQL гордо начали именоваться NoSQL, чтобы показать, что они новые и продвигают невиданные доселе технологии способные решить много проблем. А проблемы действительно были. Нужна была возможность легко горизонтально масштабировать решения в связи с ростом данных, которые могли прибывать в больших количествах, объёмы данных стали резко увеличиваться. Причём стали сохраняться данные, которые не были структурированы, например, с сайта информация на что кликал, куда переходил пользователь, что искал, какие элементы всплывали, баннер показывался и т.д. Всё это сваливается и хранится. Сейчас вы и не удивляетесь, что вам упорно показывают рекламу по теме, которая вас однажды заинтересовала, вас уверенно ведут к воронке принятия решения, о покупке, подписке и т.д.
График роста данных, он немного не свежий, но показывающий рост данных более 10 лет назад.
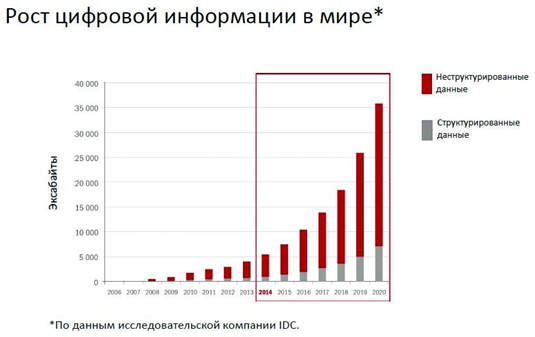
По своему опыту скажу, в 0-вых годах оффлайн компании генерили больше долларов выручки на 1 Gb данных в БД, чем сейчас онлайн компания. И соотношение примерно раз в 100–200 меньше долларов на Гб у онлайн.
Второй вытекающей из роста данных проблемой SQL были тяжелые транзакционные операции по записи в БД и не могли достигать показателя 10 или 100 тысяч в секунду на простом оборудовании. Я не буду сейчас распространяться, что есть плюс, а что минус транзакций, но оказалось, что можно ускорить транзакции, упростить их или часто они не нужны. Не нужны если данных так много, что потеряв некоторые вы восстановите всю картину запросто на оставшихся данных. Не все данные важны настолько, что их частичная потеря критична для бизнеса.
И появились простые, но эффективные NoSQL системы, которые решают проблемы, не связанные накопленными ограничениями SQL, работают быстро и чаще всего ещё и бесплатные. Но чудес не бывает, поэтому часто NoSQL решения имеют ограниченный функционал или работают быстро пока не кончится какой-нибудь ресурс, например, оперативная память или число коннектов.
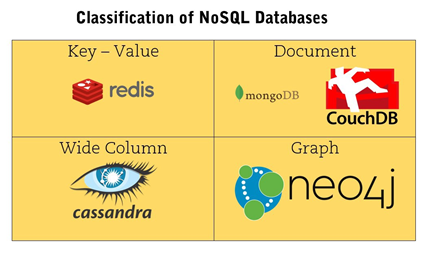
Часто можно встретить такого рода картинки классификаций NoSQL БД по типам и с примерами СУБД. Выше мы их рассмотрели.
A что же SQL — Structured Query Language — структурированный язык запросов? Он существует с начала 1970-х годов, был стандартизирован и благодаря этим стандартам, которые поддерживают все создатели реляционных БД минимизирует разницу в работе с разными реляционными СУБД. Да, производители вставляют свои собственные фичи (features — особенности), которые могут выходить за пределы стандартов SQL, так как предлагают некую новые конкурентные технологии, если они будут поддержаны массово, то эти новые технологии и их описание будут включены со временем в стандарт SQL. Если вы пишете SQL запросы в одной СУБД, то вам не составит большого труда перейти на другую и продолжить работать с ней. Мало того, часто в клиентах NoSQL СУБД, есть фишка в виде запросов на SQL. Например, для MongoDB я часто использую Studio3T, где вы можете писать обычный SQL и он переводится в специализированные запросы MongoDB, для самого MongoDB есть SQL адаптер. ClickHouse и Tarantool (российские разработки) поддерживают SQL запросы. Также во многих NoSQL СУБД появились особенности присущие SQL, например, join-ы, схемы данных, логика NULL для значений и т.д.
Cloud DBs vs DBs
Облачные технологии постепенно растут. Рост этот составляет десятки и сотни процентов в год на разные облачные технологии. Среди них есть и облачные БД. Если в любой области экономики есть рост с такими цифрами значит всё больше усилий будут прилагать компании, чтобы занять этот рынок и получить свой кусок пирога, а дальше заинтересовать побольше клиентов и включить их в этот пирог растущий дальше. Да, мы с вами — это часть их пирога. На Хабре много статей про облака, плюсы и минусы, чтобы не повторяться можно почитать например, тут или в другой статье по соответствующим тэгам.
По оценкам Gartner объём всего облачного рынка за 5 лет вырастет в 2 раза.
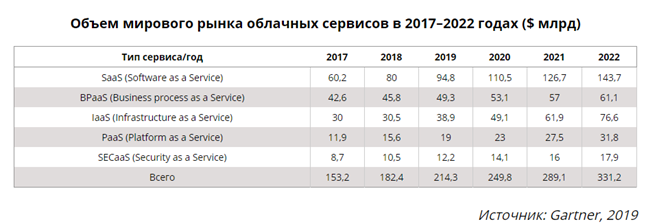
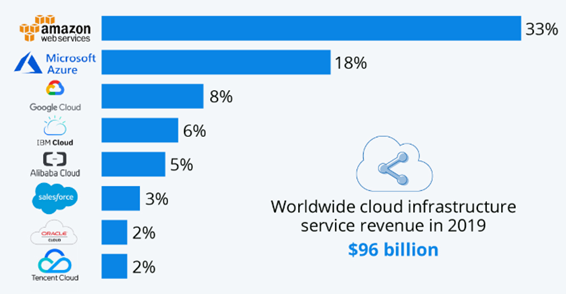
Вот такие распределения по компаниям если брать BPaaS и IaaS. По моим ощущениям очень похоже на правду. AWS лидер, Microsoft понемногу догоняет в последние годы, Alibaba растёт и дешевле всего на рынке Китая, который уже нельзя игнорировать глобальным компаниям.
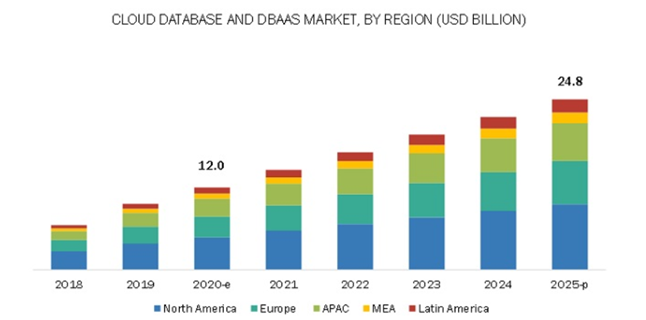
Рынок БД в облаке (DBaaS) выглядит в цифрах гораздо скромнее по сравнению с цифрами всех облачных трат, при том, что каждая компания имеет свои БД и не малые.
Объясняется это такими факторами:
Зачастую компании не используют специфичные облачные БД провайдера, потому что нужно адаптировать приложения, есть особенности, которые не позволяют это делать. Чаще сейчас используется облачная инфраструктура, то есть вы получаете свои виртуальные хосты с CPU, RAM, SSD (HDD) и используете её, чтобы там установить экземпляры стандартных СУБД.
Компании не спешат переводить именно данные в облако, переводя туда другие сервисы. Встаёт вопрос безопасности данных. Одно дело, когда ваши данные в конкретном точном месте вашей сети, физических хостингов, пускай и распределённых по миру, а другое когда вы затолкали данные в чёрный ящик поставщика облачных услуг и вам непонятно как, где оно хранится, как охраняется и т.д.
Кто столкнулся с облаками, тот знает, что траты могут возникнуть откуда вы не ждёте и соответственно не просчитали стоимость. Приведу пример, положить данные на хранение в холодное облачное хранилище стоит не дорого, а вот скачать обратно уже в десятки или сотни раз дороже. Поэтому если вы делаете бэкапы и храните их не трогая, то это дешевле своих дисков, но вот когда захотите обратно скачать, то сначала вы подождёте много часов до извлечения, а потом заплатите значительную сумму за каждый Mb. И такая ситуация и для AWS и для Azure и остальных. Вот недавняя история про NASA, когда им аудиторы сказали, что будут платить гораздо больше. Случаи перерасходов бюджетов от роста функционала сплошь и рядом.
Скорости перемещения информации из облака иногда удручают. Например, вы сделали бэкап на одном хостинге в облако, а потом решили поднять на другом хостинге. Это же облако. Но если вы и подключили платную опцию, что у вас распределённое хранение данных во многих регионах, то вас может неприятно удивить скорость восстановления в соседнем штате США. Если бэкап на сотни Gb, то в разы будет быстрее сделать бэкап на локальный диск, скопировать по выделенному каналу бэкап и поднять его на другом хостинге.
Могут возникать небольшие изменения производительности, которые трудно чем-то объяснить как работой соседних виртуальных хостов, которые разделяют с вами физический хост провайдера. Если вы работали с виртуальными хостами в локальной сети, то наверняка сталкивались как могут влиять друг на друга загруженные виртуальные сервера на одной физике. В своей сети вы можете на это повлиять или сделать замеры вынося виртуальные сервера с физического сервера.
Если вас подсадили на облака, то вы зависите от этого провайдера облачных услуг, а это ещё одна точка отказа в вашей информационной инфраструктуре. Например, Alibaba выключает ресурсы не глядя, как только пробьёт 12 часов и что-то у вас превратится в тыкву по причине того, что на вашем счете в облаке нет заранее добавленных юаней.
В России к этому добавляется ситуация, что не так давно проводилась масштабная блокировка зарубежных ресурсов, блокировали многое включая IP адреса облачных БД. Это реальность и она может быть во многих странах.
В связи с санкциями применяемых к России у отечественных компаний возникают вопросы с хранением данных в облаках американских компаний из топа. Нет гарантий, что завтра все ваши данные не пропадут вместе с отключённым аккаунтом. Отключать облачные аккаунты можно очень быстро и удобно.
В России есть Яндекс.Облако, SberCloud, честно не пользовался ими в плане БД. Был опыт использования других сервисов Яндекса, которые потом перевели в облако, поменяли протоколы и сделали платными. Пока не заинтересовали платить деньги, так как есть другие поставщики как Microsoft, Google, которые имеют бесплатные квоты для небольших объёмов и есть ещё ряд преимуществ.
Подводя итоги: переход в облака идёт в мире чуть быстрее чем у нас, мне известны целые компании на западе, которые перевели почти всё в облака и это их стратегия, но доля таких ещё гораздо меньше кто ещё это не сделал. Для иллюстрации вот такой график c указанием совокупного среднегодового темпа роста.
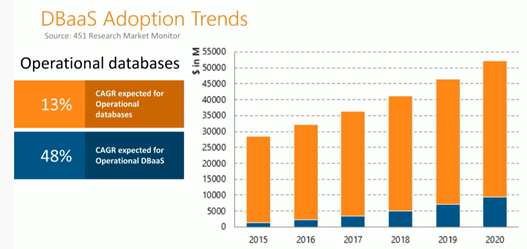
Если вам нужно развернуть быстро в любой точке мира функционал, то альтернативы облакам нет, но будьте готовы потом оплачивать счета соразмерные потраченным ресурсам, про которые вы и не подозревали. Нужно просчитывать заранее траты или пробовать в реалиях. И безопасность в облаках ещё не убедительна.
В России цены на облачное хранение данных ниже чем в мире, но иностранные компании не стремятся хранить здесь данные, поэтому развиваются они чаще за счёт государственных заказчиков и не очень большой доли компаний.
OLTP vs OLAP
Данные в БД могут использоваться для проведения текущих операций бизнеса Online Transaction Processing (OLTP): найти клиента, выписать счёт, оплатить ресурс, списать остаток со склада при заказе товара и т.д. Почти все эти операции должны проводиться в режиме реального времени. Если пользователь на сайте или во внутрикорпоративной системе ожидает по несколько секунд простые операции и это проблема с БД, то значит есть что оптимизировать. OLTP — изначально проектируются для ведения бизнеса в реальном времени. Если компания имеет базы данных, то там есть OLTP.
Есть данные, которые используются для анализа работы компании Online Analytical Processing (OLAP). То есть для OLAP собираются большие массивы данных и чтобы их быстро просчитывать в любом разрезе нужна простая магия по предрасчитыванию всего, что с наибольшей вероятность может понадобится бизнесу. То есть если вы хотите знать количества кликов на вашем глобальном сайте по странам или страницам, то их нужно заранее просчитать да ещё делая эту группировку по времени, чтобы потом смотреть динамику во времени, сравнивать с историческими трендами. И OLAP хранилища могут быть не реляционными да и вообще не структурированными, использовать специализированные языки управления большими массивами данных, или языки для статистической обработки данных. В последнее время стало модно называть обычных специалистов по аналитике в бизнесе Data Scientist. Это не совсем верно, но термин уже прижился. Обычно это смесь из следующих ингредиентов SQL, Python, R, фреймворков для работы с нейронными сетями, математическими моделями разного вида и т.д.
Количество OLAP БД обычно меньше в количественном отношении чем OLTP, но размеры их больше. Для OLAP БД важна поддержка многопоточности, когда запрос распараллеливается между ядрами и каждое ядро делает свою часть работы. Если ваша OLAP СУБД умеет шардироваться на много серверов, хорошо работает с многопоточностью, поддерживает все последние SIMD (single instruction, multiple data) инструкции процессоров, когда за 1 операцию обрабатываются большие пакеты данных, то скорость обработки данных увеличивается кратно на все эти множители.
Общая тенденция такая, что аналитику отделяют от данных необходимы для операционной деятельности. Вынос аналитических данных, обычно может состоять из выноса на отдельные сервера где можно считать, что угодно не влияя на работу компании. Для просчётов нейросетей и прочих тяжёлых математических моделей используют облака с услугой облачных вычислений на специализированных платах, например, NVidia Tesla.
SSD vs HDD vs Storage vs Tape vs Other
Эта часть о том на каких хранителях хранить данные для БД.
В 2020 году не остаётся сомнений в том, что SSD побеждают в борьбе с HDD. В серверных системах с БД это понимание пришло гораздо раньше, чем где либо. Всё дело в том, что в большинстве типов БД, важно не последовательное чтение, а чтение в память из разных мест с диска. И такая же случайная запись для данных. С этим нет проблем у SSD, тогда как скорость доступа до случайного места на диске у HDD достигается скоростью вращения шпинделя и скоростью перемещения считывающего механизма между дорожками. Попробуйте одновременно копировать несколько десятков файлов на HDD из разных мест, скорость быстро деградирует до неприемлемых значений. Так и запросы данных от 1000 пользователей, которые лежат в разных местах диска быстро сведут на нет скорость любого HDD. Поэтому для операционных OLTP систем нет большого смысла использовать HDD. На картинке ниже обычные SSD c 6000 IOPS (операций считывания и записи на диск в секунду), в серверных решениях особенно с NVME есть гораздо больше, но стоит отделять маркетинговые цифры на коротких замерах, попадающих в кэш от реальной работы диска в таком режиме круглыми сутками.

HDD есть смысл использовать в OLAP системах, когда данные лежат последовательно и их нужно читать и записывать только так или есть смысл использовать для бэкапов данных, это крупная последовательная запись и чтение. Также в больших архивных БД и везде где стоимость хранения 1 Гб — это решающая единица. HDD дешевле SSD по стоимости за 1 Гб.
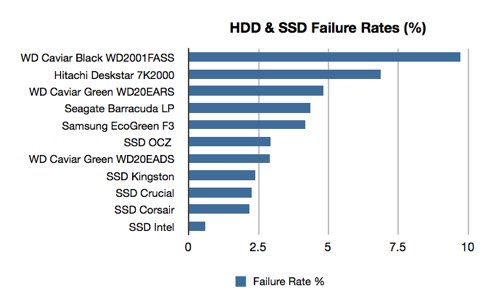
По отказоустойчивости SSD лучше HDD если их рассматривать как отдельные устройства. Это личный опыт на тысячах экземплярах. Выходы из строя SSD гораздо реже HDD, но нужно понимать, что это статистика по серверным моделям, многие из которых производились по нормам SLC и MLC, стоящие дороже, позволяющие перезаписывать данные гораздо больше раз чем продвигаемые сейчас TLC и QLC, которые не рекомендуются для БД. Для серверных систем где хранятся БД используют диски и комплектующие с повышенной отказоустойчивостью. SSD диск в 1Tb и стоимостью 1000$ — это нормальная ситуация для БД. В них заложены возможности работать месяцами на пределе, не только много читая, но и много записывая, не перегреваясь или резко сбрасывая скорость. Не нашлось картинки по сравнению отказоустойчивости серверных SSD и HDD, но есть про обычные. SSD выходят из строя реже.
Форм-фактор SSD — это 2.5 дюйма устройства для горячей замены, PCI-X карты, U.2– серверный аналог M.2, который в настольных компьютерах. Современный протокол SSD — NVME.
Storage — Система Хранения Данных (СХД) — это внешние хранилища данных, которые подключаются к серверам по оптоволокну или сетевому интерфейсу. Хранилища ставятся в те же серверные стойки, что и сервера и соединяются с ними. СХД — это ещё один огромный пласт информации, которого хватит на 10 статей. Специализированное оборудование для хранения данных. Их основное предназначение — это высокая отказоустойчивость, повышенная скорость обработки данных. Ст
