Балансировка нагрузки в Openstack (Часть 2)
В прошлой статье мы рассказали о попытках использовать Watcher и представили отчет испытаний. Такие испытания мы периодически проводим для балансировки и других критических функций большого корпоративного или операторского облака.
Высокая сложность решаемой задачи, возможно, потребует нескольких статей для описания нашего проекта. Сегодня мы публикуем вторую статью цикла, посвященную балансировке виртуальных машин в облаке.
Немного терминологии
Компания VmWare ввела утилиту DRS (Distributed Resource Scheduler) для балансировки нагрузки разработанной и предлагаемой ими среды виртуализации.
Как пишет searchvmware.techtarget.com/definition/VMware-DRS
«VMware DRS (Планировщик распределенных ресурсов) — это утилита, которая балансирует вычислительные нагрузки с доступными ресурсами в виртуальной среде. Утилита является частью пакета виртуализации под названием VMware Infrastructure.
С помощью VMware DRS пользователи определяют правила распределения физических ресурсов между виртуальными машинами (ВМ). Утилита может быть настроена на ручное или автоматическое управление. Пулы ресурсов VMware могут быть легко добавлены, удалены или реорганизованы. При желании пулы ресурсов могут быть изолированы между различными бизнес-единицами. Если рабочая нагрузка на одну или несколько виртуальных машин резко меняется, VMware DRS перераспределяет виртуальные машины между физическими серверами. Если общая рабочая нагрузка уменьшается, некоторые физические серверы могут быть временно отключены, а рабочая нагрузка консолидирована.»
Зачем нужна балансировка?
По нашему мнению, DRS является обязательной функцией облака, хотя это не значит, что DRS нужно использовать всегда и везде. В зависимости от назначения и потребностей облака могут существовать разные требования к DRS и к методам балансировки. Возможно, существуют ситуации, когда балансировка не нужна совсем. Или даже вредна.
Чтобы было лучше понятно, где и для каких клиентов DRS нужна, рассмотрим их цели и задачи. Облака можно разделить на публичные и частные. Вот основные отличия этих облаков и целей клиентов.
Мы для себя делаем следующие выводы:
Для частных облаков, предоставляемых крупным корпоративным заказчикам, DRS может применяться с учетом ограничений:
- информационная безопасность и учет аффинити-правил при балансировке;
- наличие в резерве достаточного объема ресурсов в случае аварии;
- данные виртуальных машин находятся на централизованной или распределенной СХД;
- разнесение во времени процедур администрирования, резервного копирования и балансировки;
- балансировка только в пределах агрегата хостов клиента;
- балансировка только при сильном дисбалансе, самые действенные и безопасные миграции ВМ (ведь миграция может закончиться неудачно);
- балансировка относительно «спокойных» виртуальных машин (миграция «шумных» виртуальных машин может идти очень долго);
- балансировка с учетом «стоимости» — нагрузки на СХД и сеть (при кастомизированных архитектурах для крупных клиентов);
- балансировка с учетом индивидуальных особенностей поведения каждой ВМ;
- балансировка желательно в нерабочее время (ночь, выходные, праздники).
Для публичных облаков, предоставляющих сервисы небольшим заказчикам, DRS может применяться гораздо чаще, с расширенными возможностями:
- отсутствие ограничений информационной безопасности и аффинити-правил;
- балансировка в пределах облака;
- балансировка в любое разумное время;
- балансировка любой ВМ;
- балансировка «шумных» виртуальных машин (чтобы не мешать остальным);
- данные виртуальных машин часто находятся на локальных дисках;
- учет усредненной производительности СХД и сети (архитектура облака единая);
- балансировка по обобщенным правилам и имеющейся статистике поведения ЦОД.
Сложность проблемы
Сложность балансировки заключается в том, что DRS должна работать с большим количеством неопределенных факторов:
- поведение пользователей каждой из информационных систем клиентов;
- алгоритмы работы серверов информационных систем;
- поведение серверов СУБД;
- нагрузка на вычислительные ресурсы, СХД, сеть;
- взаимодействие серверов между собой в борьбе за ресурсы облака.
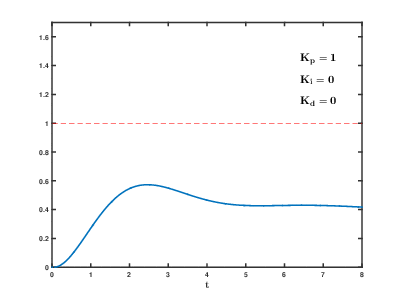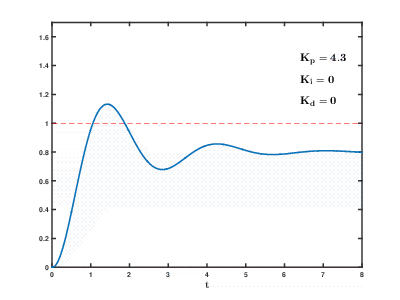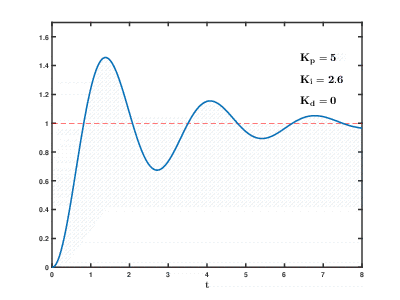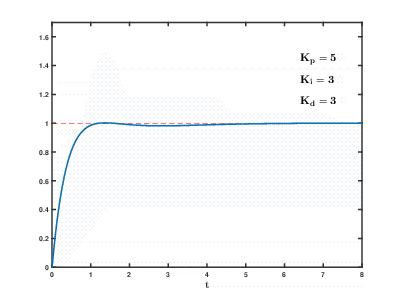
Нагрузка большого количества виртуальных серверов приложений и баз данных на ресурсы облака проистекает во времени, последствия могут проявляться и накладываться друг на друга с непредсказуемым эффектом через непредсказуемое время. Даже для управления относительно простыми процессами (например, для управления двигателем, системой водяного отопления дома) системам автоматического регулирования необходимо использовать сложные пропорционально-интегрально-дифференцирующие алгоритмы с обратной связью.

Наша задача на много порядков сложнее, и существует риск, что система за разумное время не сможет провести балансировку нагрузки к устоявшимся значениям, даже если не будет возникать внешних воздействий со стороны пользователей.
История наших разработок
Для решения этой проблемы мы приняли решение не начинать с нуля, а отталкиваться от существующего опыта, и стали взаимодействовать с имеющими в этой области опыт специалистами. К счастью, понимание проблематики у нас полностью совпадало.
Этап 1
Мы использовали систему, базирующуюся на технологии нейронных сетей, и попробовали на ее основе оптимизировать наши ресурсы.
Интерес данного этапа состоял в апробировании новой технологии, а его важность — в применении нестандартного подхода к решению задачи, где в прочих равных условиях стандартные подходы практически исчерпали себя.
Мы запустили систему, и у нас действительно пошла балансировка. Масштаб нашего облака не позволил нам получить оптимистичные результаты, заявленные разработчиками, но было видно, что балансировка работает.
При этом мы имели достаточно серьезные ограничения:
- Для обучения нейронной сети необходимо, чтобы виртуальные машины работали без существенных изменений в течение недель или месяцев.
- Алгоритм рассчитан на оптимизацию на основе анализа более ранних «исторических» данных.
- Для обучения нейронной сети требуется достаточно большой объем данных и вычислительных ресурсов.
- Оптимизацию и балансировку можно делать относительно редко — раз в несколько часов, что явно недостаточно.
Этап 2
Поскольку нас не устраивало положение дел, мы решили модифицировать систему, и для этого ответить на главный вопрос — для кого мы её делаем?
Сначала — для корпоративных клиентов. Значит, нам нужна система, работающая оперативно, с теми корпоративными ограничениями, которые только упрощают реализацию.
Второй вопрос — что понимать под словом «оперативно»? В результате недолгих дебатов мы решили, что можно отталкиваться от времени реагирования 5 — 10 минут, чтобы кратковременные скачки не вводили систему в резонанс.
Третий вопрос — какой размер балансируемого количества серверов выбирать?
Этот вопрос решился сам собой. Как правило, клиенты не делают агрегаты серверов очень большими, и это соответствует рекомендациям из статьи ограничить агрегаты 30–40 серверами.
Кроме того, сегментируя пул серверов, мы упрощаем задачу алгоритму балансировки.
Четвертый вопрос — насколько нам подходит нейронная сеть с ее долгим процессом обучения и редкими балансировками? Мы приняли решение отказаться от нее в пользу более простых оперативных алгоритмов, чтобы получать результат за секунды.
С описанием системы, использующей такие алгоритмы и ее недостатками, можно ознакомиться тут
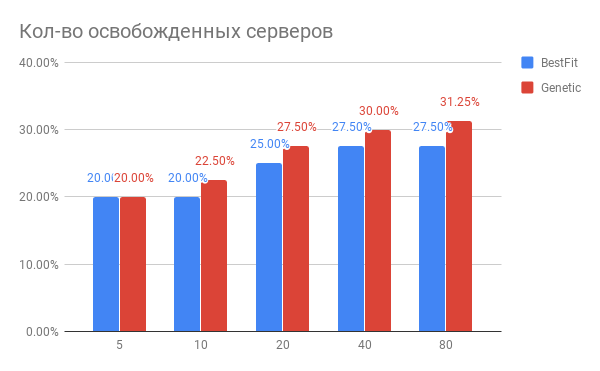
Мы реализовали и запустили данную систему и получили обнадеживающие результаты — сейчас она регулярно анализирует нагрузку облака и дает рекомендации по перемещению виртуальных машин, которые в значительной степени являются правильными. Даже сейчас видно, что мы можем добиться 10–15% освобождения ресурсов под новые виртуальные машины с улучшением качества работы имеющихся.

При обнаружении дисбаланса по RAM или CPU система дает команды в планировщик Тионикс на выполнение живой миграции требуемых виртуальных машин. Как видно из системы мониторинга, виртуальная машина переехала с одного (верхнего) на другой (нижний) хост и освободила память на верхнем хосте (выделено в желтые круги), заняв ее соответственно на нижнем (выделено в белые круги).
Сейчас мы стараемся более точно оценить эффективность действующего алгоритма и пытаемся найти в нем возможные ошибки.
Этап 3
Казалось бы, на этом можно успокоиться, дождаться доказанной эффективности и закрыть тему.
Но нас подталкивают к проведению нового этапа следующие явные возможности оптимизации
- Статистика, например, тут и тут показывает, что двух- и четырех- процессорные системы по своей производительности существенно ниже однопроцессорных. Значит, все пользователи получают от купленных в многопроцессорных системах CPU, RAM, SSD, LAN, FC значительно меньшую отдачу, по сравнению с однопроцессорными.
- Сами планировщики ресурсов могут работать с серьезными ошибками, вот одна из статей на эту тему.
- Предлагаемые компаниями Intel и AMD технологии для мониторинга RAM и кэша позволяют изучать поведение виртуальных машин и размещать их таким образом, чтобы «шумные» соседи не мешали жить «спокойным» виртуальным машинам.
- Расширение набора параметров (сеть, СХД, приоритет виртуальной машины, стоимость миграции, ее готовность к миграции).
Итого
Результатом нашей работы по совершенствованию алгоритмов балансировки стал однозначный вывод о том, что за счет современных алгоритмов можно добиться существенной оптимизации ресурсов (25–30%) датацентров и повысить при этом качество обслуживания клиентов.
Алгоритм, базирующийся на основе нейронных сетей, является, безусловно, интересным, но нуждающимся в дальнейшем развитии решением, и ввиду существующих ограничений не подходящим для решения такого рода задач на объемах, характерных для частных облаков. При этом в публичных облаках значительного размера алгоритм показал хорошие результаты.
Подробнее о возможностях процессоров, планировщиков и высокоуровневой балансировки мы расскажем в следующих статьях.
