Багоцид и Zero Bug Policy — как мы побеждали баги, а они нас

Кадр из фильма «Космический десант». Начало войны с багами.
Принцип такой: если баг обнаружен, то мы его либо исправляем в рамках SLA, либо сразу решаем, что фиксить не будем — когда это особенность продукта, тривиальная ошибка или стоимость фикса выше, чем последствия бага. Если исправление занимает больше нескольких часов или откладывается на конец спринта, должен быть точный запланированный срок, чтобы поддержка могла ответить клиенту не «мы в курсе, работы идут», а »мы в курсе, завтра в 17:30 починим».
Мы решили раскатить это на всю компанию.
К последнему времени мы накопили достаточно багов и техдолга, чтобы это стали замечать пользователи. Понизились метрики удовлетворённости продуктом, и мы все вместе решили бороться с багами. Остановили на неделю работу части команд разработки и устроили багатон, исправили штук двести с лишним багов за этот единый порыв.
Стало приятно и весело, но ненадолго. Эффект надо было сохранить.
Спойлер: у нас не вышло. Но прогресс есть.
С чего начиналось
Сначала мы осознали проблему, решили внедрять ZBP и провели багатон: вот пост про то, как это делалось, там же есть про оценку и приоритизацию багов.
После багатона стало понятно, что рутина никуда не девается, эффект от багатона быстро развеивается, и надо было менять подход к самому процессу обработки багов. В целом нам виделось, что это цепочка из трёх больших вещей:
- Багатона.
- Новой политики работы с багами и новых процессов качества.
- Работы с самим производством, чтобы снижать уровень возможных багов или хотя бы правильно регистрировать ошибки, чтобы их было легче обрабатывать.
Багатон провели, багбэклоги перестали напрягать 18 из 50 команд (тех самых, что участвовали в багатоне), а дальше мы решили, что будет простой принцип: если появляется баг, его надо лечить сразу. Либо не лечить, потому что мы готовы с этим жить.
«Готовы с этим жить» — это, например, если кнопка нежно-светло-зелёная, а нужна была оливково-зелёная — можно не тратить ресурсы, а просто принять, что чёрт с ней, кнопки имеют право на самоопределение. Что интересно, на этих тикетах чаще бывает сложнее и дороже объяснить, что нужно в задаче, чем исправить.
Второй тип «готовы с этим жить» — это когда баг проявляется на малом проценте пользователей, а чтобы его поправить, нужно переписать всю архитектуру. В такой ситуации проще ходить через поддержку вручную, а не делать как правильно. В этом плане вспоминается прекрасный анекдот про то, как в хостинге клиент жалуется на то, что процесс в личном кабинете работает то быстро, то медленно. Решение там такое: он создаёт задачу в интерфейсе, вместо бэкенда она отправляется тикетом в поддержку, а клиенту показывается прогресс-бар на время SLA. Дальше поддержка может сделать сразу, а может по верхней границе SLA. После закрытия тикета клиент видит, что операция в личном кабинете выполнена. Кратко — бывают баги, которые дешевле закрывать примерно так.
Третий тип «готовы жить» — это когда баг есть, но мы знаем, что либо продукт с ним будет закрыт через 2 месяца, либо случится что-то ещё, что сделает неактуальным всю ветку кода с ним. Задачу не ставим, описываем, чтобы при повторном обращении поддержка могла увидеть, с какой резолюцией баг был закрыт, и могла сразу дать ответ клиенту.
В итоге багбэклог должен стремиться к нулю. В теории.
А теперь практика
Естественно, не все команды были готовы к тому, чтобы принять такую политику. Идея как таковая понравилась всем. Собственно, у нас было несколько команд, которые сами дошли до такого подхода и уже давно его использовали. Кто-то видел такой подход в других компаниях. Мы организовали митап для всех разработчиков, позвали туда QA-лидов и всех сочувствующих. Рассказали про Zero Bug Policy как о явлении, её типах, плане внедрения и ДОДах, послушали тех, кто уже имел подобный опыт. И пришли к выводу, что это всё хорошо бы внедрить в компании.
Чего не ожидали, так это огромного количества вопросов от команд по деталям. Заинтересовались все, но почти у каждого была куча особенностей, не дающих реализовать ZBP в полной мере. Плюс просто многое было непонятно. В итоге если сначала казалось, что встреча будет одна большая, а после неё наступит счастье, то нет.
Вторая встреча была про ответы на вопросы, разбор сомнений и возражений. СТО и рабочая группа проекта разложили всё по полочкам.
Примеры:
— Должна ли быть разница в политиках для внутренней разработки и внешних продуктов? И какая?
— Нет, разницы быть не должно.
— Хочется конкретики в том, что считаем багом, чтобы потом не особо спорить, баг это или фича, или это вообще баг в требованиях, а не в коде или ещё где-то.
— Тут мы прописали в политике определение бага, проанализировали оферту и статистику, на основании чего зафиксировали рекомендации.
— Какие метрики ещё можно отслеживать?
— Помимо SLA и суммарного веса багов рекомендуем отслеживать в продуктовых командах оценки в сторах и отзывы, количество обращений в каналы с багами, плотность багов (количество открытых багов / количество закрытых фич), количество редевов по задачам.
После этой встречи вопросы стали специфичнее, но ящик Пандоры не закрылся.
Дальше мы решили, что все вопросы достаточно узкие, и разбирали их уже с конкретными командами, чтобы не отвлекать вообще всю разработку компании.
Итогом всех этих итераций стало то, что у нас появилось целых 4 вариации Zero Bug Policy:
- Классическая строгая. «Это наш баг, и мы его фиксим». Тривиал по выбору команды закрывается сразу после регистрации или закрывается автоматически через 2 недели. Если это минор — мы можем запланировать на конкретную дату, но мы должны понимать когда, чтобы те, кто на саппорте, говорили нашим ученикам и учителям: «Да, мы в курсе, планируем тогда-то». Если мейджор, то это должно пройти в текущий спринт. Если это критикал или блокер — по их стандартным SLA, блокер — за 1 день. Очень важно, что баги в приоритете в спринтах, то есть их нельзя таскать из недели в неделю, потому что они не уместились. Дедлайны реальные.
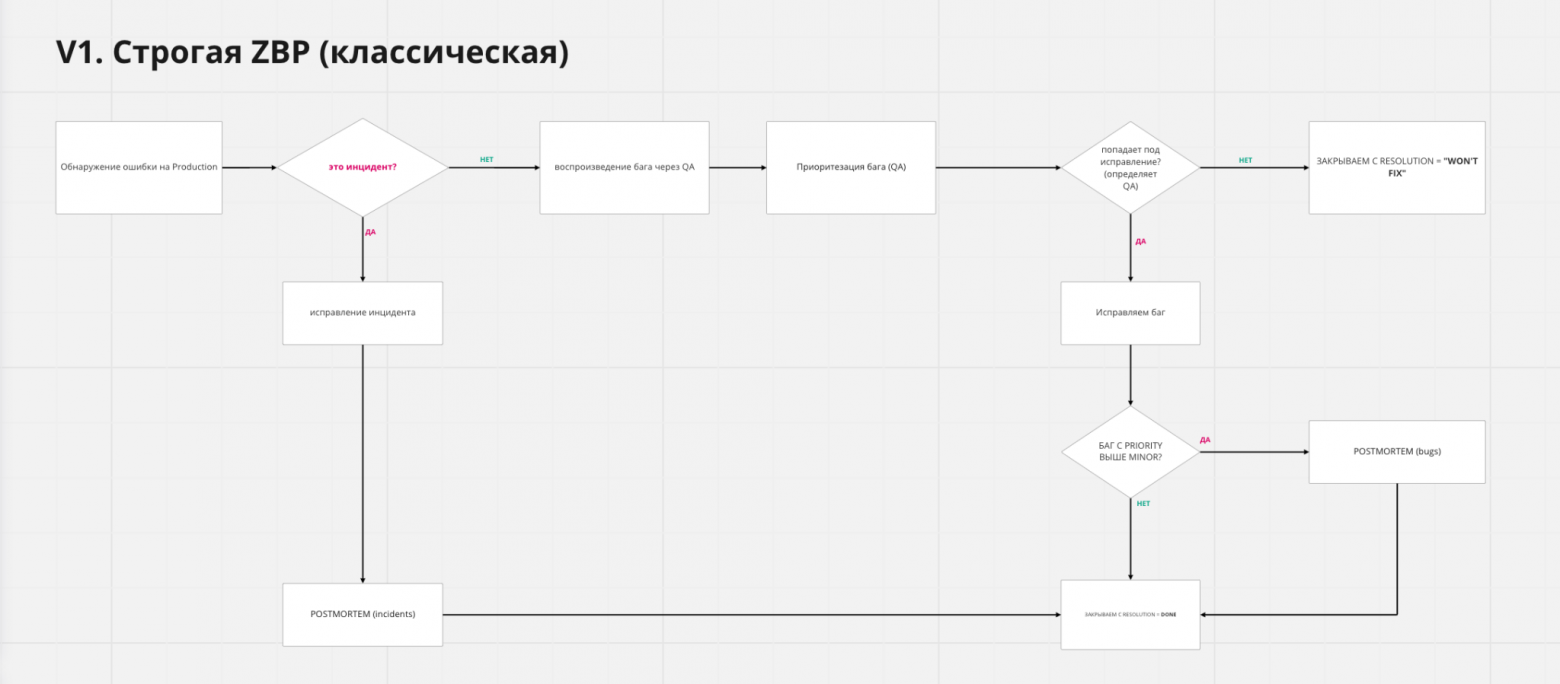
Рекомендуется для платформенных команд, в которых стабильность превыше всего и где есть сильный QA - Багоцид, или спринты любви, — это упрощённый вариант, когда баги можно откладывать, если они не блокер или критикал. Мейджоры и миноры можно не чинить сразу, а складывать в бэклог. Но дальше в течение пары спринтов нужно разобрать этот бэклог до нуля или близкого значения. Можно взять это в следующий продуктовый спринт как задачу, а можно выделить отдельный спринт. Например, 2 бизнесовых, потом один багоцидный. На практике в итоге у нас никто не делает чисто багоцидные спринты, просто берут некоторое количество багов как задачи в бизнесовые.
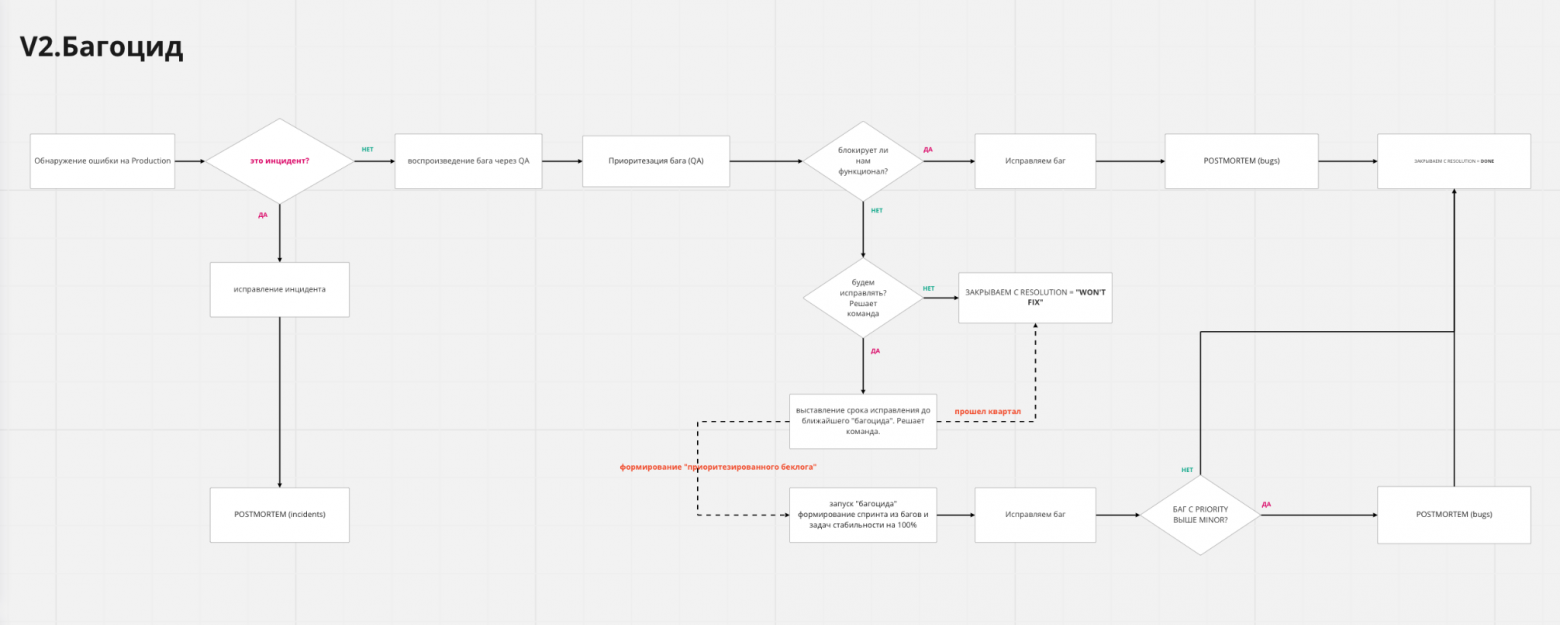
Оптимально для тех, кто чётко планирует спринты - По стоимости — команды выбирают метрику, по которой учитывают стоимость бага. Это могут быть трудозатраты на поддержку, количество обращений пользователей и так далее. Подходит любая метрика, близкая бизнесу. Дальше стоимость бага сравнивается со стоимостью продуктовой задачи (внедрения фичи). В силу сложности расчёта всего пара команд это использует. Такая схема рекомендуется для команд, которые умеют agile-testing и могут автоматизировать свои процессы. QA не должны стать прослойкой принятия решения, разработчики должны сами уметь брать баги в работу.
- Кастомная. Это когда берётся какая-то из политик выше, и в неё вносятся изменения, облегчающие жизнь с ней. Это либо команды с невероятно огромным багбэклогом, либо компромисс продакт-менеджера или тимлида — например, «сейчас примем лайтовую политику, а со следующего полугодия будем идти по строгой, дайте только сервис доделать». Отдельный кастомный вариант понадобился и для мобильной разработки: там завязка на внесении изменений, а не на релизе в силу особенностей release train.
В процессе внедрения оказалось, что баги передаются из команды в команду с разными оценками. В компании просто не было единой методологии определения уровня бага. Например, были команды, которые писали в критикалы вообще всё. Но ничего с этим не делали. Или были команды, которые считали, что половина пользователей — это ещё не критикал, до критикала надо, чтобы каждый это почувствовал.
Правила внедрения:
- При возникновении проблемы — определяем баг или доработка.
- Все баги заводятся и фиксируются. Тривиальные баги закрываются сами, если за 2 недели не перерастают во что-то посерьезнее.
- Блокирующий — вообще всё бросаем и делаем.
- Критический — дописываем строчку в коде, бросаем и делаем.
- Основной и ниже — отдаём первому освободившемуся или выбираем приоритет среди других задач.
- Если не успели пофиксить в этом спринте — баги встают на самый верх следующего спринта.
- Стараться делать работу над ошибками и не допускать похожие баги несколько раз.
- Не порождать известные баги.
- Каждый участник команды может и должен влиять на качество.
- Починка бага не должна создавать новые баги. Если при починке бага сломалось что-то другое — необходимо починить сразу же.
- Обязательные ретроспективы по каждому багу. После закрытия багов команда инициирует процесс проведения разбора причин возникновения бага + формирует план действий, в котором описано, что необходимо сделать, чтобы не повторить баг вновь. В процессе разбора багов, постмортема и приоритизации должна участвовать вся команда.
Некоторые баги с низкой оценкой постепенно могли повыситься в приоритете. Например, когда новый сервис, которым пользовались десятки человек, вдруг становился востребованным сотнями тысяч. Для этого у нас есть Support Tab вот такого типа в поддержке:
Каждый раз, когда приходит обращение по известному багу, первая линия нажимает кнопку счётчика. В какой-то момент баг получает повышение приоритета и с криком «хватит с этим жить» отправляется на исправление.
Но на самом деле ещё более волшебным было то, что мы на старте не знали весь скоуп команд. У нас ушла куча времени на актуализацию того, какой проект в Джире чей. Какие-то проекты учитывались в метриках, хотя не должны были. Какие-то не учитывались, хотя должны были. Мы прошли вторую большую уборку — как при оценке актуальности багов, когда почти половину получилось выкинуть как самозакрывшиеся (про это есть в посте про багатон).
В тот момент, когда суммарный вес багов (это доля пользователей, умноженная на серьёзность бага) превысил то, что у нас было до багатона — то есть мы потеряли результаты всей уборки, и поддерживать, по сути, было уже нечего — мы начали ходить по командам и закреплять QA-лидов за каждой, где закреплённого лида по какой-то причине не было. Где-то ушёл и не нашли замену, где-то исторически команда создавалась без связки с QA и так далее.
Дальше общие встречи, про которые вы уже знаете.
Потом мы ещё раз выстрелили себе в ногу тем, что поставили и объявили одни ожидания от внедрения, а потом пару раз их поменяли.
Следующим сюрпризом стало то, что команды очень не хотели подписываться на снижение суммарного веса багов. Причина простая: прямо в конце спринта перед измерением мог прилететь баг с большим весом. Получалось, что весь спринт команда работала, а итоговый результат хуже, чем до начала. Пришлось менять метрику с «багвес» на «багвес по багам, у которых уже кончился SLA». То есть мы хотели очиститься от старых багов почти полностью и не допускать протухания новых.
Вторая метрика была связана с закрытием багов в текущем месяце. Это процент от имеющихся горящих. Логично было закрывать 80% багов в срок их SLA, остальные уже как пойдёт. Ну, для нас логично. Но не учли, что команды доставали баги из бэклога и закрывали их, то есть если половина багов была старая, то метрика шла вниз, а если старые баги никто не трогал, то метрика шла вверх. А оценивался результат именно по дашбордам, и под это наметилась, скажем так, некоторая оптимизация работ в командах. Поправили, конечно, но это был интересный момент.
Что получилось
На старте ожидали, что 80% команд перейдут на ZBP, то есть начнут применять методологию и покажут результаты. 53% от целевых команд перешли на Zero Bug. 78% команд улучшили багвес. Хотели сократить багбэклог до 30% от изначального (сейчас 45%) и прокачать SLA с 85 до 95% (сейчас SLA 89%).
График заведения багов к решению вот:
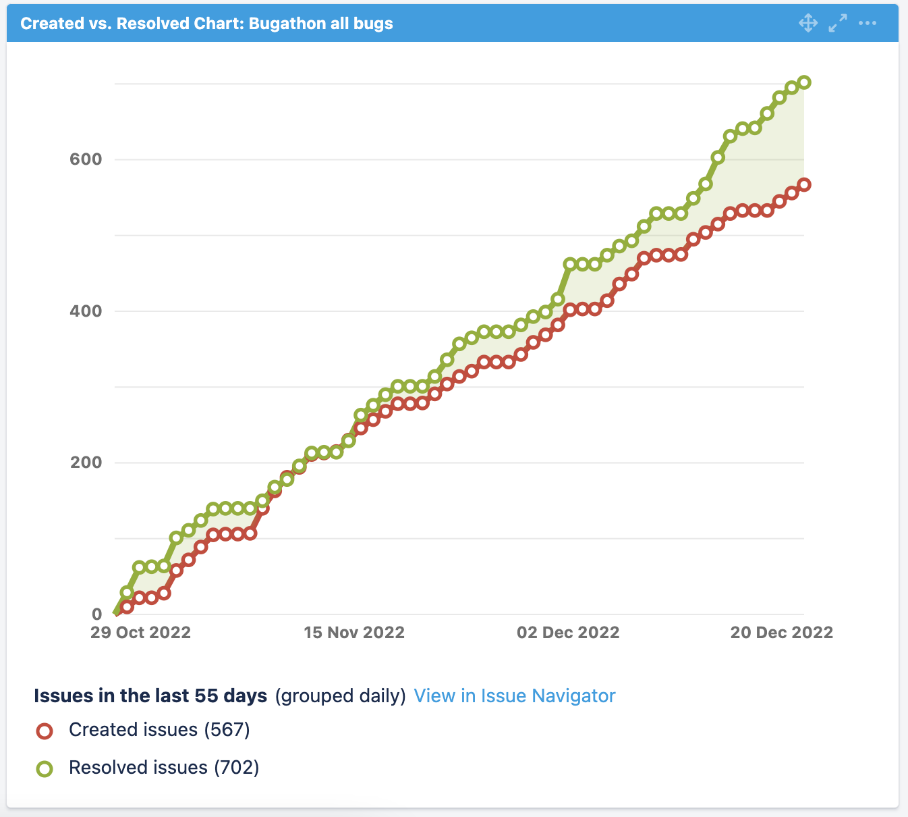
Еще мы отслеживали график багвеса. Он стал для нас как курс доллара: штука, на которую смотришь каждый день, попивая кофе. Здесь явно видны все переломные моменты и наши достижения:

Очень важно, что мы унифицировали очень много вещей, которые раньше складывались исторически по-разному в разных командах. Процессы были разные, лейблы были разные — в итоге образовался один процесс в Джире, общий для всех.
Можно сказать, что то, что получилось, — это наши попытки найти компромисс между качеством и хотелками бизнеса. Бизнес хочет быстрее и новые фичи, но при этом нужно не забывать про поддержку уже имеющегося продукта. Сейчас появился понятный инструмент удержания качества.
Плюсы внедрения:
- Снизили нагрузку на поддержку.
- Не тратим время на споры: есть баг — правим.
- QA не нужно приоритизировать баги.
- Не позволяет делать плохой продукт — кара настигнет неминуемо.
- Нет багов — нет неявного поведения. Не надо что-то разматывать и править данные.
- Чистая Sentry — чистая совесть. Легко детектить новые проблемы.
- Мотивирует писать тесты. Особенно, если договориться, что фикс бага выходит вместе с тестами на это поведение/место.
- Работающий продукт проще и приятнее разрабатывать.
- Не надо искать воркэраунды и транслировать их раз за разом.
- Растёт скорость решения проблем, с которыми сталкивается пользователь.
- Чистый бэклог, не нужно актуализировать старые проблемы.
- Прозрачные сроки решения по проблемам для поддержки.
Минусы:
- Сложно договориться, что такое баг и кто принимает это решение.
- Нужно договориться с бизнесом (убедить продакта). Нужно заручиться поддержкой сверху (но не на самом верху, именно в своей вертикали).
- Закладываем воздух в спринт на баги: как утилизировать свободное время — уж найдёте.
- Рано или поздно будет спринт, состоящий из целых багов: нужно быть готовыми отстоять, иначе эффект сойдёт на нет.
- Трудно доказать важность фикса на раннем этапе так как «мы это через Х дней будем переделывать».
- Трудно втянуть баг. Сразу после заведения — спринт уже забит, на планировании — спринт собираются забить. В самом спринте ошибки лежат внизу, поэтому мы их часто переносим в следующий.
- Если внедрено неполностью правильно, снижается ТТМ.
- Риски ретроспективы и постмортемов, т.к. команду может устраивать исправление, но не проработка причин.
- Могут появиться плохие хотфиксы и в погоне за скоростью создавать конвейер багов.
Мы смотрим, как это пойдёт дальше. Пока далеко не всё гладко и не всем нравится, баги нас ещё побеждают, но тенденцию мы переломили и готовы отыграть у них следующий квартал.
