Автоматизируем локализацию макетов в Figma
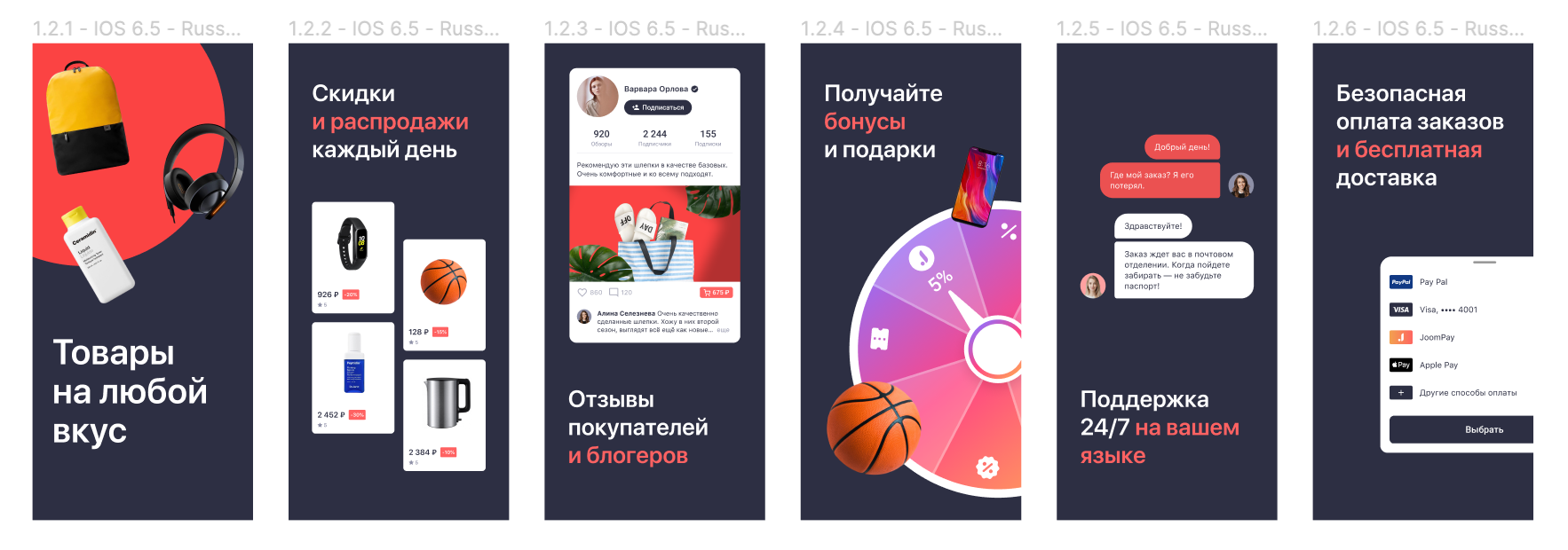
В один прекрасный момент наши дизайнеры решили, что пора обновить обложки
нашего приложения в Apple Store и Google Play. На всех 17 языках.
Это история про то, как нырнуть в незнакомый язык программирования, незнакомую платформу и незнакомую задачу, собрать много всего интересного, помочь коллегам и оставить след в open source community.

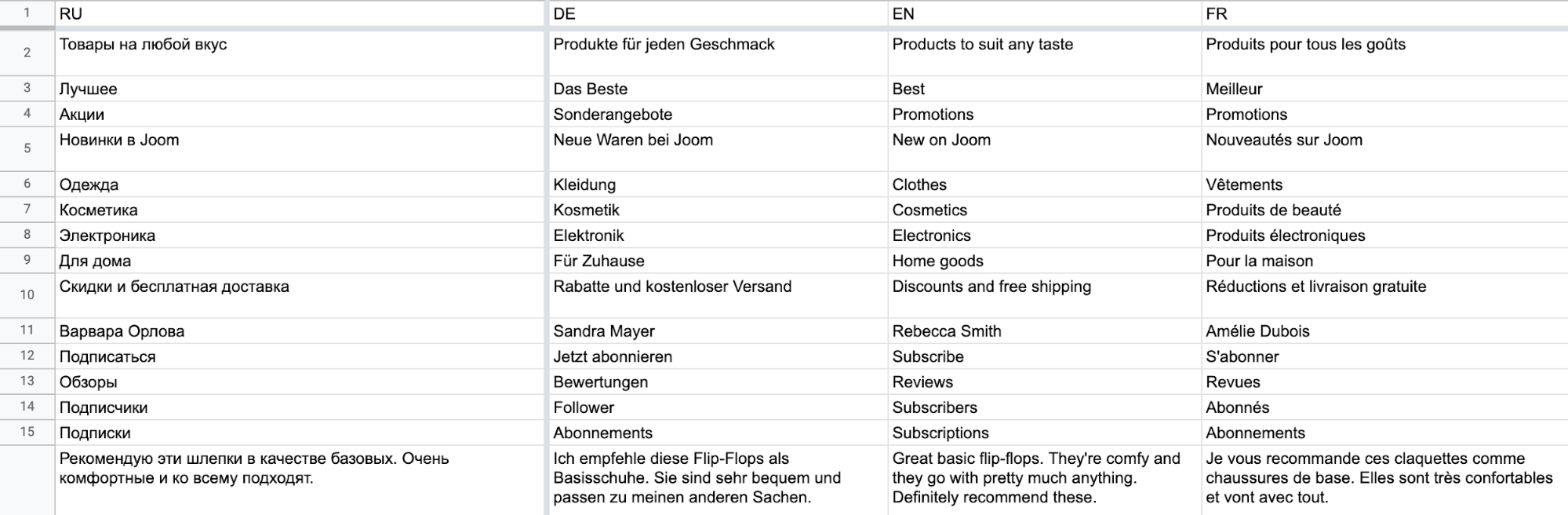
После подготовки макетов в Figma пришло осознание страшного факта: мы должны поддержать 17 различных языков! Причем максимально качественно и согласованно, так что автоматические переводы через Google Translate (или даже сервис Crowdin) нам не подходили. Что ж, задача была поручена ответственным людям, и вот через некоторое время у нас появилась табличка Google Sheets с переводами всех фраз.
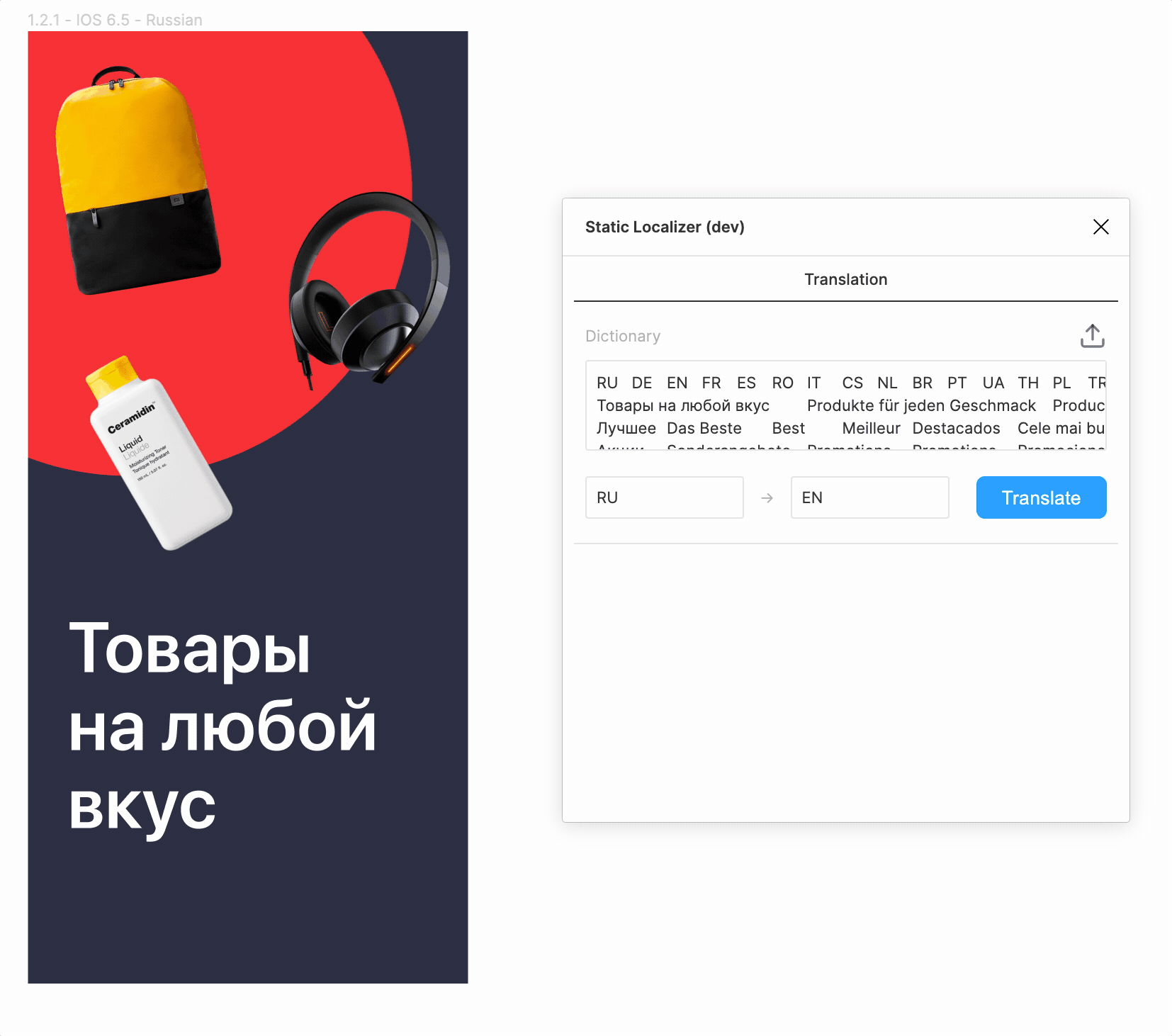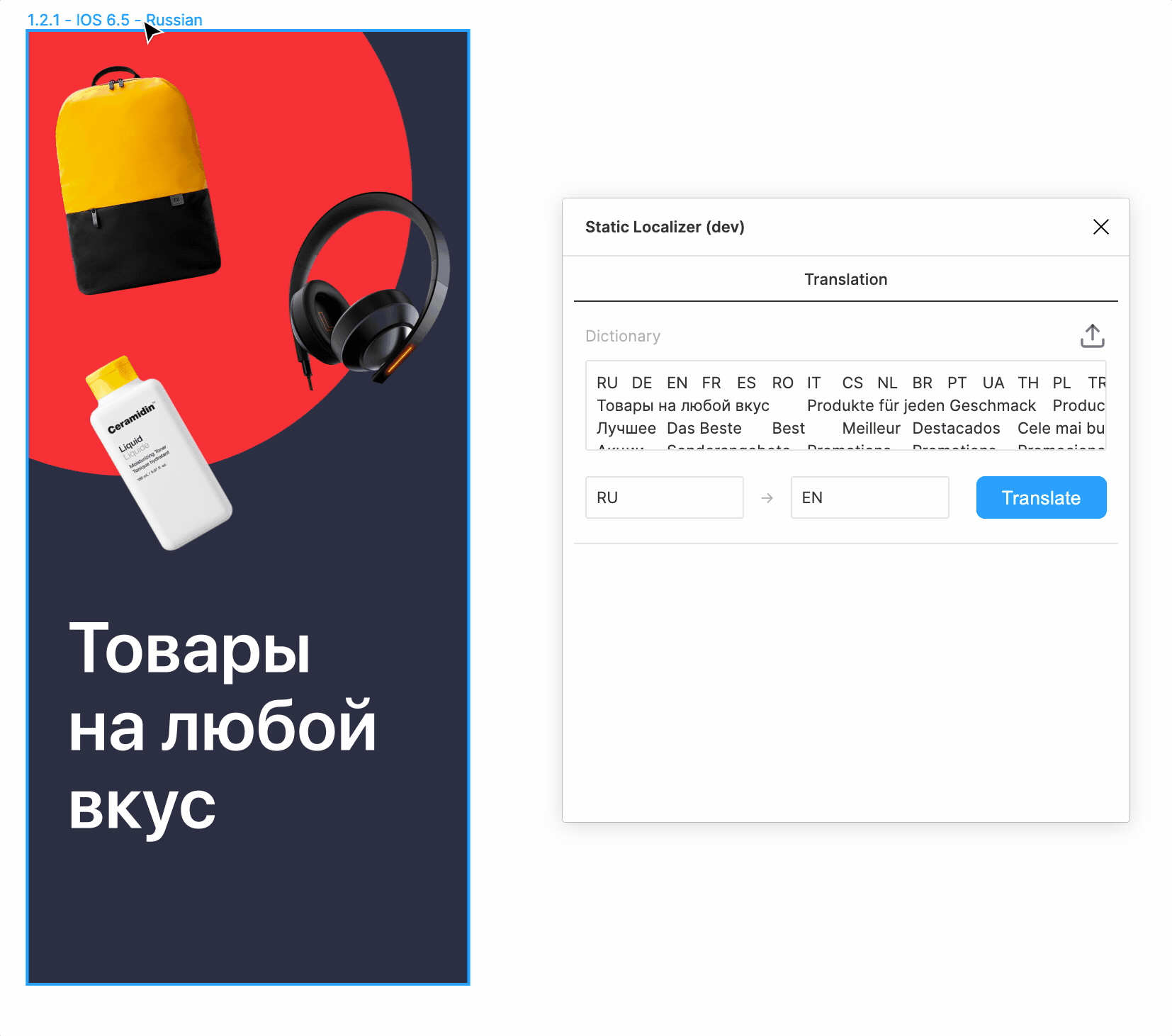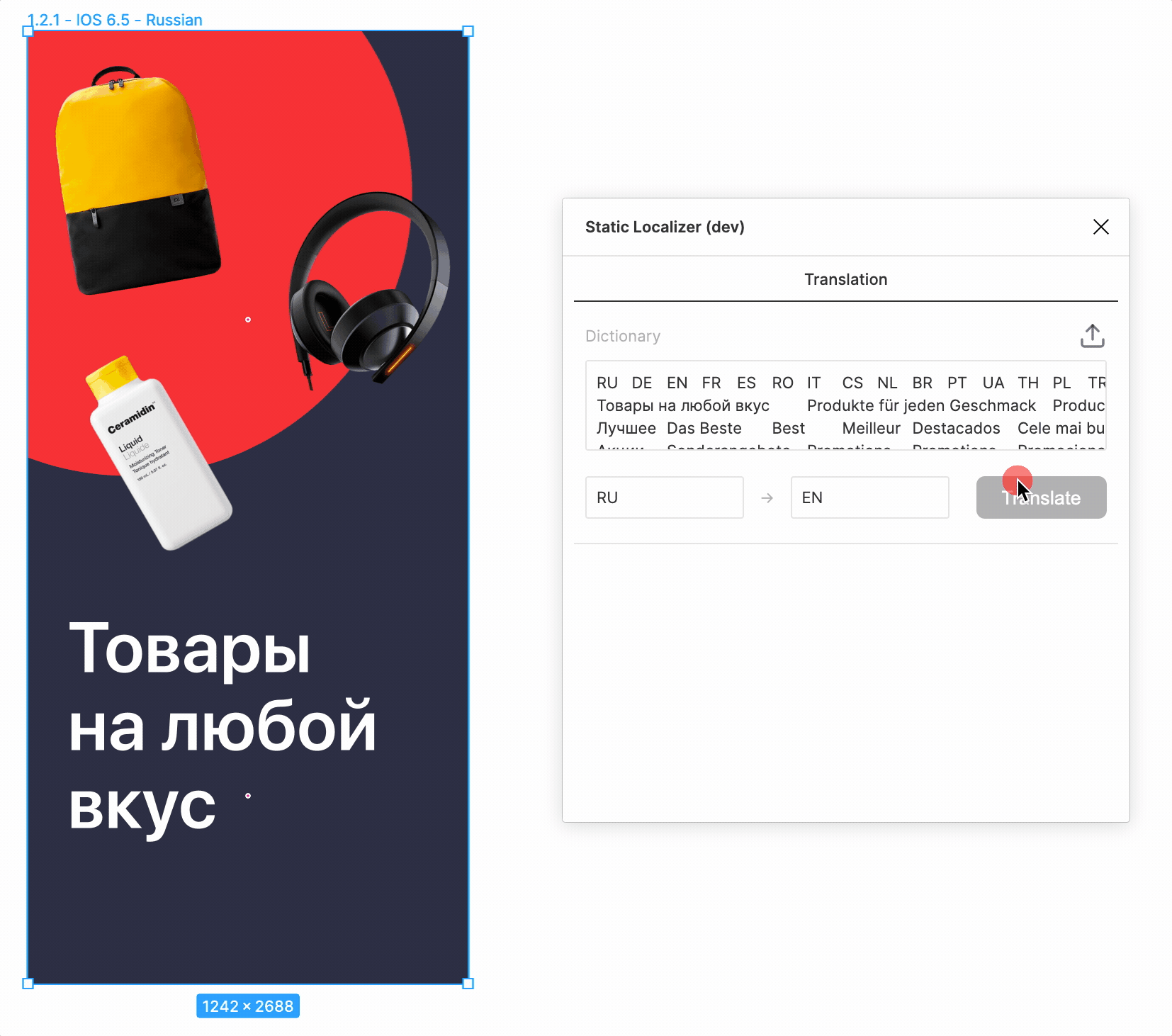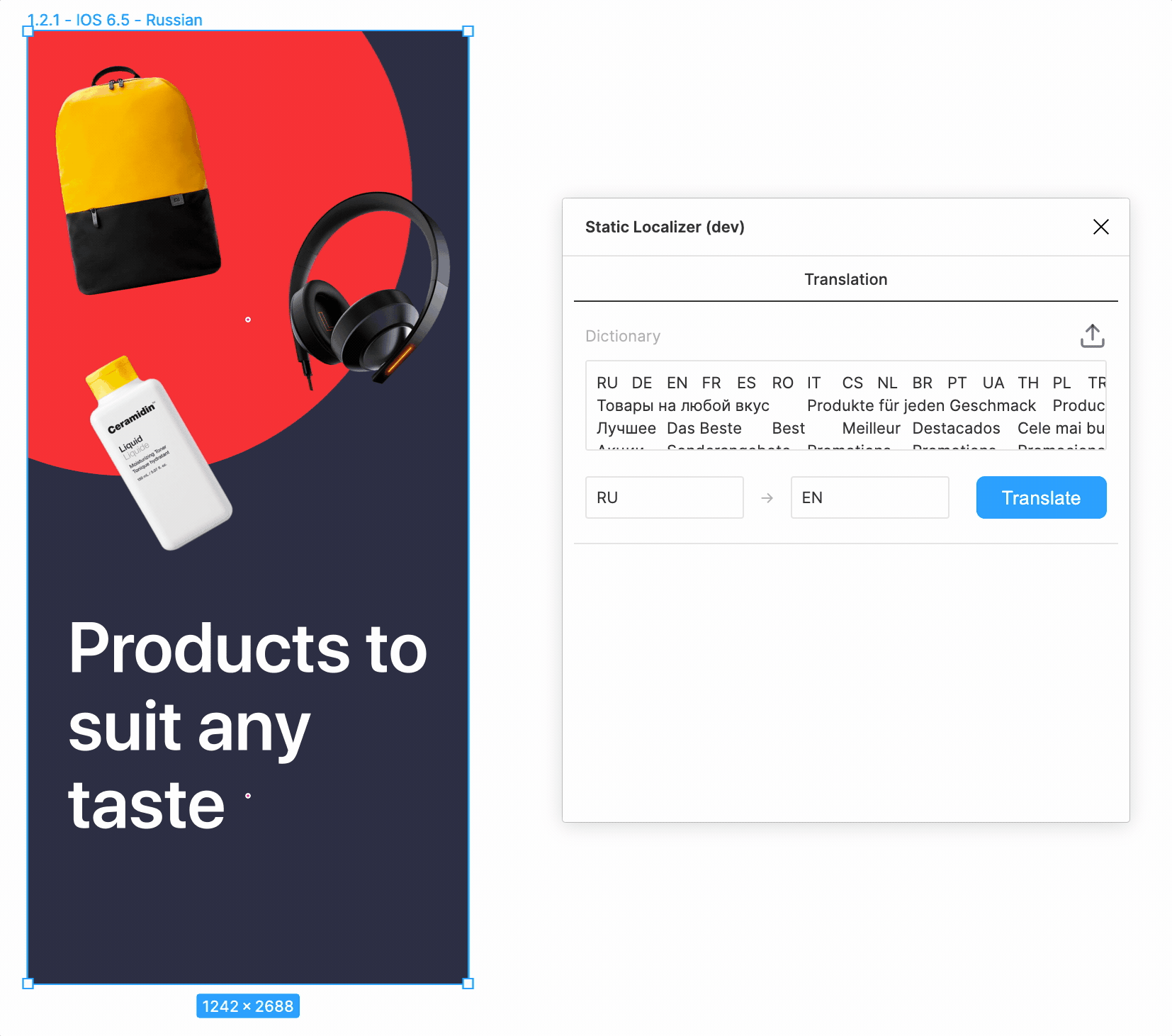
Первая попытка ручной замены текстов в макетах привела к следующему:
- было потрачено около 40 минут;
- были допущены мелкие ошибки форматирования;
- заменяющий вносил свои правки в переводы (потому что «знал язык») и нигде это не фиксировал;
- пропало желание повторять эту процедуру, а значит, и вносить какие-либо изменения.
И задача резко обрела пугающий объем и сложность. Требовалась автоматизация.
Конечно же, хотелось бы воспользоваться готовым решением. Однако из рассмотренных (Crowdin, Localize, Yandex.Translate) ни одно нас не устроило, так как они не позволяют использовать кастомизированные переводы и полностью игнорируют форматирование (подсветку, выделения). А в идеале решение должно было давать практически готовый результат, не требующий вмешательства человека.
Как известно, подобные проблемы лучше всего решаются за чашечкой чая в компании коллег-разработчиков на уютной офисной кухне. Несмотря на то, что в нашей команде нет разработчиков, хорошо знакомых с Figma и ее возможностями, никто не брезгует TypeScript’ом, и все способны написать на нем плагин по документации. Даже Golang и Kotlin разработчики заднего конца. Более того, небольшой опыт у некоторых уже имелся.
Написание плагинов для Figma
Figma предоставляет достаточно подробную документацию по созданию плагинов. Код плагина делится на «клиентскую» и «серверную» части, при этом только у последней есть доступ к структуре документа (названия условные, потому что обе выполняются локально). Клиентская часть отвечает за взаимодействие с пользователем через HTML-интерфейс. Возможности API так же хорошо описаны в соответствующей документации.
Разработка плагина ведется исключительно в десктоп-версии Figma, которая по сути является обычным WebView, поэтому разработчику доступна консоль JavaScript и прочие привычные инструменты.
После беглого осмотра стало ясно, что API поддерживает поиск нод, редактирование текста и стилей, то есть в теории позволяет нам осуществить задуманное.
Автоматический перевод по словарю
Автозамена
Было решено за полчасика сделать PoC, который будет в состоянии просто подменить все тексты в соответствии с табличкой. Пока с максимально примитивным UI, конечно же.
Итак, для начала нам нужно загрузить словарь. Поскольку заморачиваться с подключением сторонних модулей на первом этапе не хотелось, решил выбрать самый простой формат, в который можно выгрузить имеющуюся табличку из Google Sheets. Между CSV и TSV выбор пал на TSV: в текстах могли присутствовать запятые, это усложнило бы парсинг.
type Dictionary = {
header: string[];
rows: string[][];
};
async function parseDictionary(serializedDictionary: string): Promise {
const table = serializedDictionary.split('\n').map(line => line.split('\t').map(field => field.trim()));
if (table.length === 0) {
throw {error: 'no header in the dictionary'};
}
// в заголовке будут языковые коды
const header = table[0];
const expectedColumnCount = header.length;
const rows = table.slice(1, table.length);
console.log('Dictionary:', {header, rows});
rows.forEach((row, index) => {
if (row.length != expectedColumnCount) {
throw {error: 'row ' + (index + 2) + ' of the dictionary has ' + row.length + ' (not ' + expectedColumnCount + ') columns'};
}
});
return {header, rows};
}
type Mapping = {
[source: string]: string;
};
async function getMapping(dictionary: Dictionary, sourceLanguage: string, targetLanguage: string): Promise {
const sourceColumnIndex = dictionary.header.indexOf(sourceLanguage);
if (sourceColumnIndex == -1) {
throw {error: sourceLanguage + ' not listed in [' + dictionary.header + ']'};
}
const targetColumnIndex = dictionary.header.indexOf(targetLanguage);
if (targetColumnIndex == -1) {
throw {error: targetLanguage + ' not listed in [' + dictionary.header + ']'};
}
const result: Mapping = {};
dictionary.rows.forEach(row => {
const sourceString = row[sourceColumnIndex];
const targetString = row[targetColumnIndex];
if (targetString.trim() !== '') {
if (sourceString in result) {
throw {error: 'multiple translations for `' + sourceString + '` in the dictionary'};
}
result[sourceString] = targetString;
}
});
// крайне удобный способ отладки в случае с Figma
console.log('Extracted mapping:', result);
return result;
}
type Replacement = null | {
// в какой ноде заменяем текст
node: TextNode;
// на что заменяем
translation: string;
};
type ReplacementFailure = {
// в какой ноде произошла ошибка
nodeId: string;
// описание самой ошибки
error: string;
};
type ReplacementAttempt = Replacement | ReplacementFailure;
// Settings получаются элементарно из UI
async function translateSelection(settings: Settings): Promise {
const dictionary = await parseDictionary(settings.serializedDictionary);
const mapping = await getMapping(dictionary, settings.sourceLanguage, settings.targetLanguage);
await replaceAllTexts(mapping);
}
async function replaceAllTexts(mapping: Mapping): Promise {
const textNodes = await findSelectedTextNodes();
let replacements = (await Promise.all(textNodes.map(node => computeReplacement(node, mapping)))).filter(r => r !== null);
let failures = replacements.filter(r => 'error' in r) as ReplacementFailure[];
if (failures.length > 0) {
console.log('Failures:', failures);
throw {error: 'found some untranslatable nodes', failures};
}
replacements.forEach(replaceText);
}
async function findSelectedTextNodes(): Promise {
const result: TextNode[] = [];
figma.currentPage.selection.forEach(root => {
if (root.type === 'TEXT') {
// либо в выделение попала текстовая нода
result.push(root as TextNode);
} else if ('findAll' in root) {
// либо фрейм/группа,
// тогда в ней можно найти все текстовые подноды встроенной функцией findAll
(root as ChildrenMixin).findAll(node => node.type === 'TEXT').forEach(node => result.push(node as TextNode));
}
});
return result;
}
async function computeReplacement(node: TextNode, mapping: Mapping): Promise {
// текст ноды может содержать лишние пробелы и переносы слов,
// и это не должно влиять на возможность перевода,
// поэтому предварительно нормализуем строки
const content = normalizeContent(node.characters);
if (!(content in mapping)) {
// не нашли перевод? жаль
return {nodeId: node.id, error: 'No translation for `' + content + '`'};
}
const result: Replacement = {
node,
translation: mapping[content],
};
console.log('Replacement:', result);
return result;
}
function normalizeContent(content: string): string {
// интересные факты из жизни Unicode:
// \u2028 — разделитель строк (но не \n)
// \u202F — невидимый разделитель пробелов (?)
// по-хорошему, стоит добавить и прочие разделители,
// но они на практике пока не встречались
return content.replace(/[\u000A\u00A0\u2028\u202F]/g, ' ').replace(/ +/g, ' ');
}
async function replaceText(replacement: Replacement): Promise {
const {node, translation} = replacement;
// интересная особенность Figma:
// перед тем, как менять что-либо в текстовой ноде, нужно предварительно
// загрузить все шрифты, которые в ней используются
await loadFontsForNode(node);
node.characters = translation;
}
async function loadFontsForNode(node: TextNode): Promise {
await Promise.all(Array.from({length: node.characters.length}, (_, k) => k).map(i => {
// очень забавный момент, конечно:
// Figma позволяет узнать свойства любой секции текста в ноде,
// при этом если в секции оно неоднородно (например, используется несколько шрифтов),
// то возвращается специальный объект mixed
return figma.loadFontAsync(node.getRangeFontName(i, i + 1) as FontName);
}));
}
Вся эта конструкция довольно быстро заработала, что порадовало и вселило уверенность.
Исключения
При первом же запуске было обнаружено множество текстов, не требующих переводов. Потому они и не фигурировали в исходной табличке.

Имена собственные, числа, валюты, какие-то символы, эмодзи… Не беда. Достаточно задать исключения в виде списка регулярок.
async function translateSelection(settings: Settings): Promise {
const dictionary = await parseDictionary(settings.serializedDictionary);
const mapping = await getMapping(dictionary, settings.sourceLanguage, settings.targetLanguage);
// дополнительно учитываем список исключений
const exceptions = await parseExceptions(settings.serializedExceptions);
await replaceAllTexts(mapping, exceptions);
}
async function parseExceptions(serializedExceptions: string): Promise {
return serializedExceptions.split('\n').filter(pattern => pattern !== '').map(pattern => {
try {
return new RegExp(pattern);
} catch (_) {
throw {error: 'invalid regular expression `' + pattern + '`'};
}
});
}
async function replaceAllTexts(mapping: Mapping, exceptions: RegExp[]): Promise {
const textNodes = await findSelectedTextNodes();
// пробрасываем список в функцию вычисления подстановки
let replacements = (await Promise.all(textNodes.map(node => computeReplacement(node, mapping, exceptions)))).filter(r => r !== null);
let failures = replacements.filter(r => 'error' in r) as ReplacementFailure[];
if (failures.length > 0) {
console.log('Failures:', failures);
throw {error: 'found some untranslatable nodes', failures};
}
replacements.forEach(replaceText);
}
async function computeReplacement(node: TextNode, mapping: Mapping, exceptions: RegExp[]): Promise {
const content = normalizeContent(node.characters);
// если содержимое подходит под одну из регулярок
if (keepAsIs(content, exceptions)) {
// то говорим, что заменять текст в этой ноде не нужно совсем
return null;
}
if (!(content in mapping)) {
// не нашли перевод? жаль
return {nodeId: node.id, error: 'No translation for `' + content + '`'};
}
const result: Replacement = {
node,
translation: mapping[content],
};
console.log('Replacement:', result);
return result;
}
function keepAsIs(content: string, exceptions: RegExp[]): boolean {
for (let regex of exceptions) {
if (content.match(regex)) {
return true;
}
}
return false;
};
Форматирование
Теперь не хватало лишь вишенки на торте.
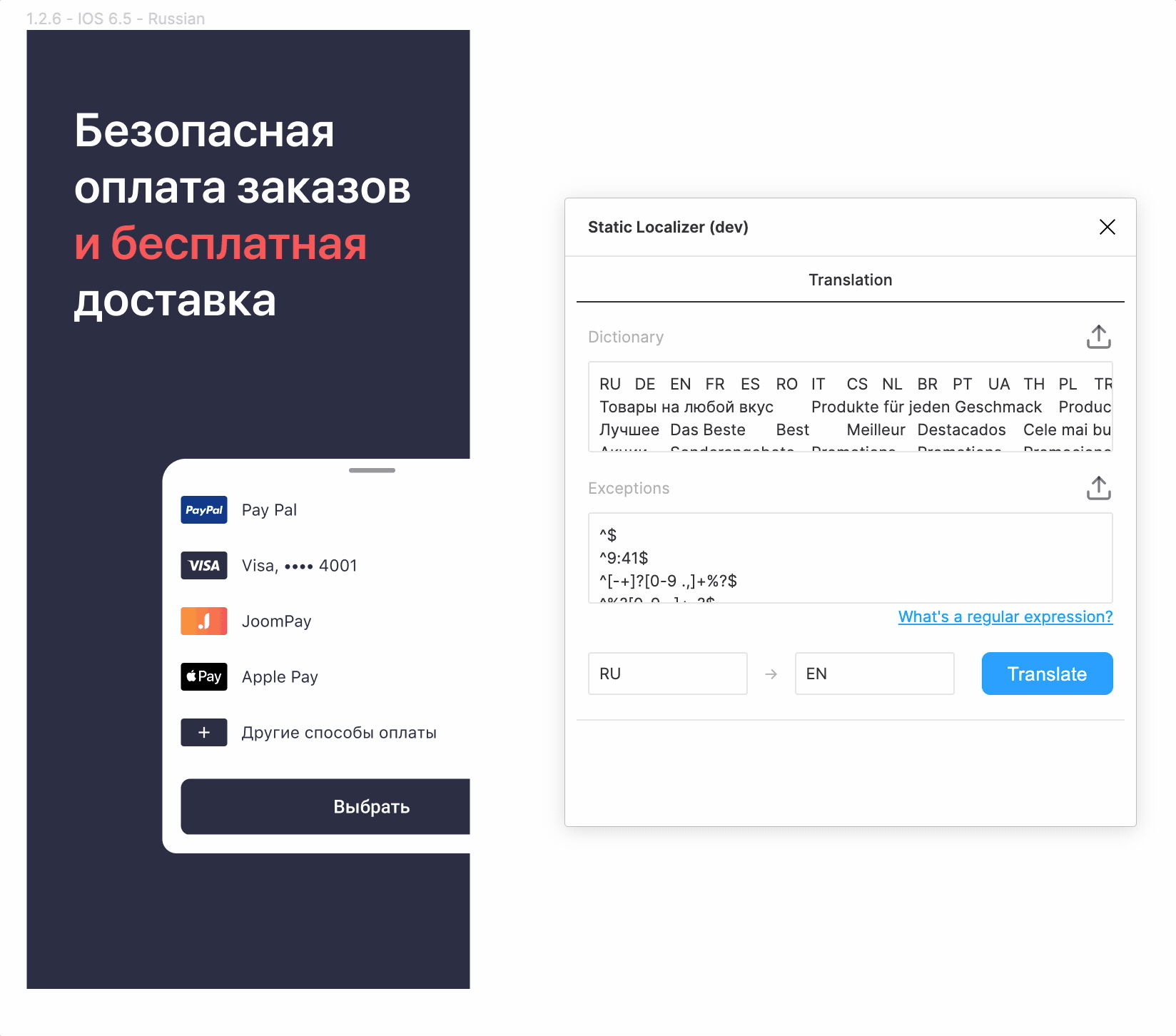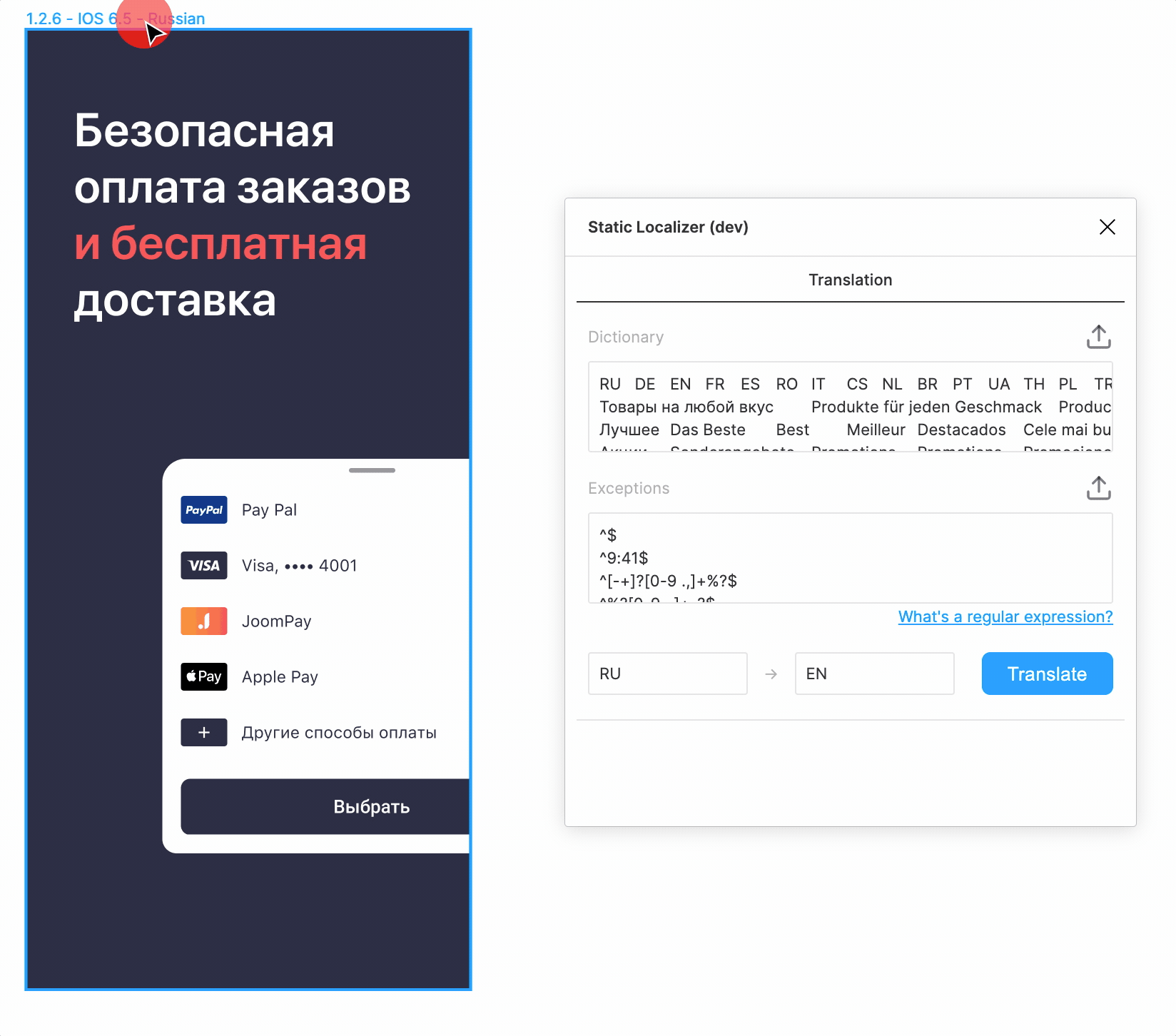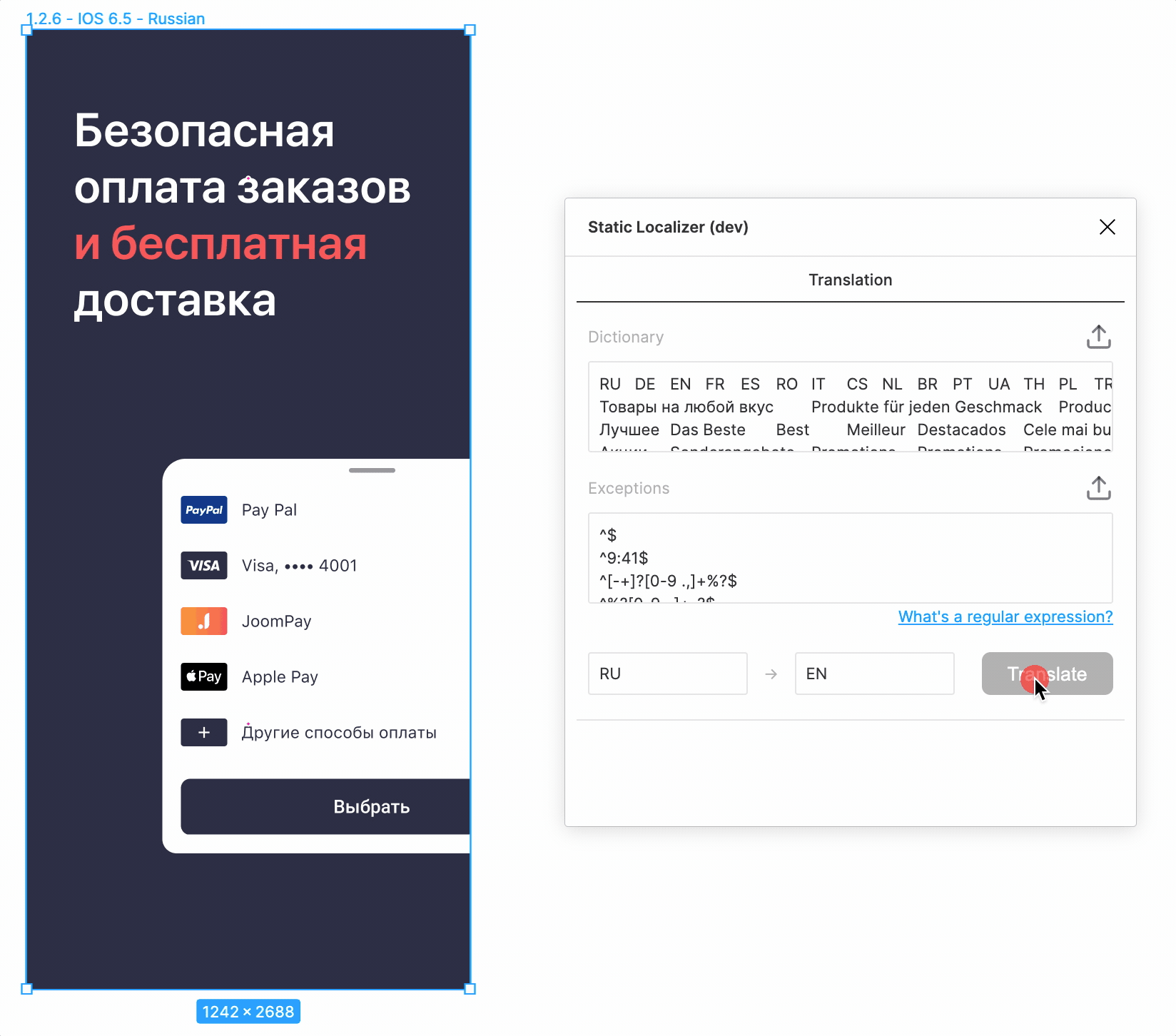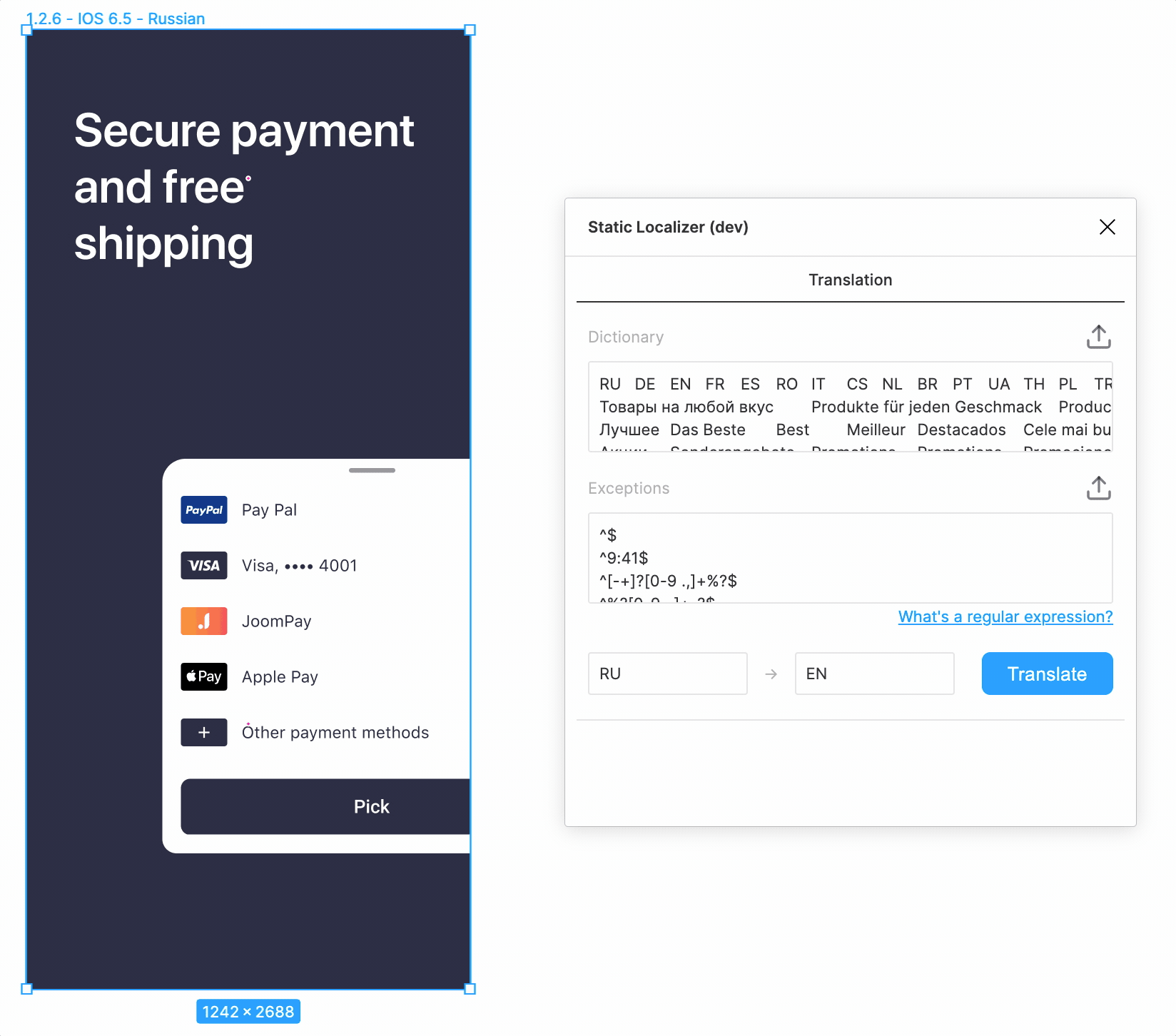
Видно, что наивная подстановка текста переформатирует его в соответствии со стилем
самой первой буквы. Можем ли мы как-то сохранить сложное форматирование? Кажется, да. Можно дополнительно к основному тексту перевести отдельно выделенную часть. Затем в переводе основного текста найти перевод выделенной части и переформатировать его. Только вот далеко не всегда ясно, какая часть текста является «выделенной». Но мы можем перебирать имеющиеся стили в поисках «основного», мы же точно знаем, что он один.
Итого.
- Разбиваем исходный форматированный текст на непрерывные моностильные секции.
- Перебираем использующиеся в тексте стили, рассматривая каждый в качестве основного.
- Пробуем перевести все секции других стилей.
- Пробуем найти переводы секций других стилей внутри общего перевода (перевода всего текста).
- Считаем, что нашли основной стиль, если предыдущие два пункта завершились успешно.
- Подставляем сначала общий перевод и применяем к нему основной стиль.
- Для каждого вычисленного выделения в переводе применяем соответствующий ему стиль.
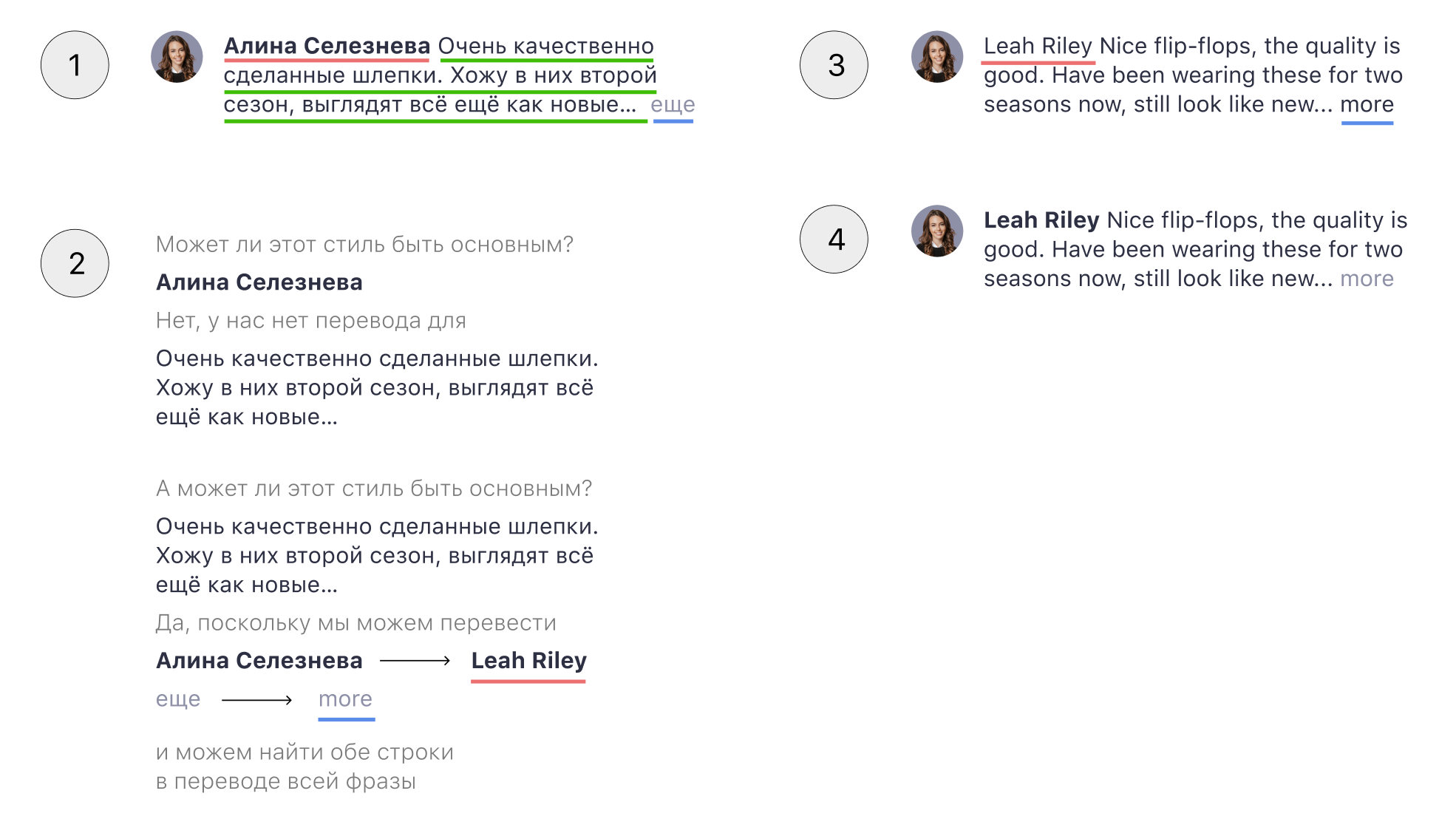
При реализации пришлось учесть, что Figma не имеет какого-то общего объекта для описания стиля, только для отдельных его параметров, и дописать небольшую обертку для этого. При этом естественная посимвольная итеративная реализация пункта 1 становится крайне дорогой. Благо, существует довольно элегантный и эффективный рекурсивный алгоритм.
type Style = {
// это поле будет хранить уникальный идентификатор
// так можно будет быстро сравнивать стили между собой
id: string;
fills: Paint[];
fillStyleId: string;
fontName: FontName;
fontSize: number;
letterSpacing: LetterSpacing;
lineHeight: LineHeight;
textDecoration: TextDecoration;
textStyleId: string;
};
type Section = {
// начало секции, включительно, индексация с 0
from: number;
// конец секции, не включительно, индексация с 0
to: number;
// стиль всей секции
style: Style;
};
function sliceIntoSections(node: TextNode, from: number = 0, to: number = node.characters.length): Section[] {
if (to == from) {
return [];
}
const style = getSectionStyle(node, from, to);
if (style !== figma.mixed) {
// это моностильная секция
return [{from, to, style}];
}
// разделяй и властвуй!
const center = Math.floor((from + to) / 2);
const leftSections = sliceIntoSections(node, from, center);
const rightSections = sliceIntoSections(node, center, to);
const lastLeftSection = leftSections[leftSections.length-1];
const firstRightSection = rightSections[0];
if (lastLeftSection.style.id === firstRightSection.style.id) {
firstRightSection.from = lastLeftSection.from;
leftSections.pop();
}
return leftSections.concat(rightSections);
}
function getSectionStyle(node: TextNode, from: number, to: number): Style | PluginAPI['mixed'] {
const fills = node.getRangeFills(from, to);
if (fills === figma.mixed) {
return figma.mixed;
}
const fillStyleId = node.getRangeFillStyleId(from, to);
if (fillStyleId === figma.mixed) {
return figma.mixed;
}
const fontName = node.getRangeFontName(from, to);
if (fontName === figma.mixed) {
return figma.mixed;
}
const fontSize = node.getRangeFontSize(from, to);
if (fontSize === figma.mixed) {
return figma.mixed;
}
const letterSpacing = node.getRangeLetterSpacing(from, to);
if (letterSpacing === figma.mixed) {
return figma.mixed;
}
const lineHeight = node.getRangeLineHeight(from, to);
if (lineHeight === figma.mixed) {
return figma.mixed;
}
const textDecoration = node.getRangeTextDecoration(from, to);
if (textDecoration === figma.mixed) {
return figma.mixed;
}
const textStyleId = node.getRangeTextStyleId(from, to);
if (textStyleId === figma.mixed) {
return figma.mixed;
}
const parameters = {
fills,
fillStyleId,
fontName,
fontSize,
letterSpacing,
lineHeight,
textDecoration,
textStyleId,
};
return {
id: JSON.stringify(parameters),
...parameters,
};
}
// придется немного расширить нашу структуру подстановки
type Replacement = null | {
node: TextNode;
translation: string;
// тот самый "основной" стиль
baseStyle: Style;
// разметка translation на секции со стилями, отличными от основного
sections: Section[];
};
async function computeReplacement(node: TextNode, mapping: Mapping, exceptions: RegExp[]): Promise {
const content = normalizeContent(node.characters);
if (keepAsIs(content, exceptions)) {
return null;
}
if (!(content in mapping)) {
return {nodeId: node.id, error: 'No translation for `' + content + '`'};
}
// режем на моностильные секции
const sections = sliceIntoSections(node);
// готовим результат
const result: Replacement = {
node,
translation: mapping[content],
baseStyle: null,
sections: [],
};
// формируем лог ошибок на случай безуспешных поисков
const errorLog = [
'Cannot determine a base style for `' + content + '`',
'Split into ' + sections.length + ' sections',
];
// собираем множество задействованных стилей
const styles = [];
const styleIds = new Set();
sections.forEach(({from, to, style}) => {
if (!styleIds.has(style.id)) {
styleIds.add(style.id);
styles.push({humanId: from + '-' + to, ...style});
}
});
for (let baseStyleCandidate of styles) {
const prelude = 'Style ' + baseStyleCandidate.humanId + ' is not base: ';
let ok = true;
// будем попутно собирать разметку для «неосновных» стилей
result.sections.length = 0;
for (let {from, to, style} of sections) {
if (style.id === baseStyleCandidate.id) {
continue;
}
const sectionContent = normalizeContent(node.characters.slice(from, to));
let sectionTranslation = sectionContent;
// либо мы должны уметь переводить секцию,
// либо она должна входить в список исключений
if (sectionContent in mapping) {
sectionTranslation = mapping[sectionContent];
} else if (!keepAsIs(sectionContent, exceptions)) {
errorLog.push(prelude + 'no translation for `' + sectionContent + '`');
ok = false;
break;
}
const index = result.translation.indexOf(sectionTranslation);
if (index == -1) {
errorLog.push(prelude + '`' + sectionTranslation + '` not found within `' + result.translation + '`');
ok = false;
break;
}
if (result.translation.indexOf(sectionTranslation, index + 1) != -1) {
errorLog.push(prelude + 'found multiple occurrencies of `' + sectionTranslation + '` within `' + result.translation + '`');
ok = false;
break;
}
result.sections.push({from: index, to: index + sectionTranslation.length, style});
}
if (ok) {
// нашли основной стиль!
result.baseStyle = baseStyleCandidate;
break;
}
}
if (result.baseStyle === null) {
return {nodeId: node.id, error: errorLog.join('. ')};
}
console.log('Replacement:', result);
return result;
}
async function replaceText(replacement: Replacement): Promise {
// нет необходимости вызывать загрузку для каждого символа,
// когда мы уже получили разбиение по стилям
await loadFontsForReplacement(replacement);
const {node, translation, baseStyle, sections} = replacement;
node.characters = translation;
if (sections.length > 0) {
setSectionStyle(node, 0, translation.length, baseStyle);
for (let {from, to, style} of sections) {
setSectionStyle(node, from, to, style);
}
}
}
async function loadFontsForReplacement(replacement: Replacement): Promise {
await figma.loadFontAsync(replacement.baseStyle.fontName);
await Promise.all(replacement.sections.map(({style}) => figma.loadFontAsync(style.fontName)));
}
function setSectionStyle(node: TextNode, from: number, to: number, style: Style): void {
node.setRangeTextStyleId(from, to, style.textStyleId);
node.setRangeFills(from, to, style.fills);
node.setRangeFillStyleId(from, to, style.fillStyleId);
node.setRangeFontName(from, to, style.fontName);
node.setRangeFontSize(from, to, style.fontSize);
node.setRangeLetterSpacing(from, to, style.letterSpacing);
node.setRangeLineHeight(from, to, style.lineHeight);
node.setRangeTextDecoration(from, to, style.textDecoration);
}
Стоит сразу отметить, что много внимания теперь было уделено адекватным сообщениям
об ошибке. Алгоритм не совсем очевидный для непосвященного человека, и понятно сформулировать, что именно в алгоритме выше пошло не так — крайне сложно.
Да и алгоритм при этом далеко не идеальный. Например, во фразе «Отличное качество, все еще как новые… еще» слово «еще» встречается два раза, что при переводе на некоторые языки ведет к тому, что и в переводе оно встречается тоже в двух местах. В итоге наш алгоритм не в состоянии определить, какое из двух вхождений нужно выделить жирным. Такую ситуацию, к сожалению, невозможно исправить без прокачки формата входных данных. Еще может так произойти, что одно и то же слово используется в разных контекстах, при этом оно как-то выделено. В этом случае мы упадем еще на этапе обработки словаря, так как не поддерживаем несколько переводов для одного слова.
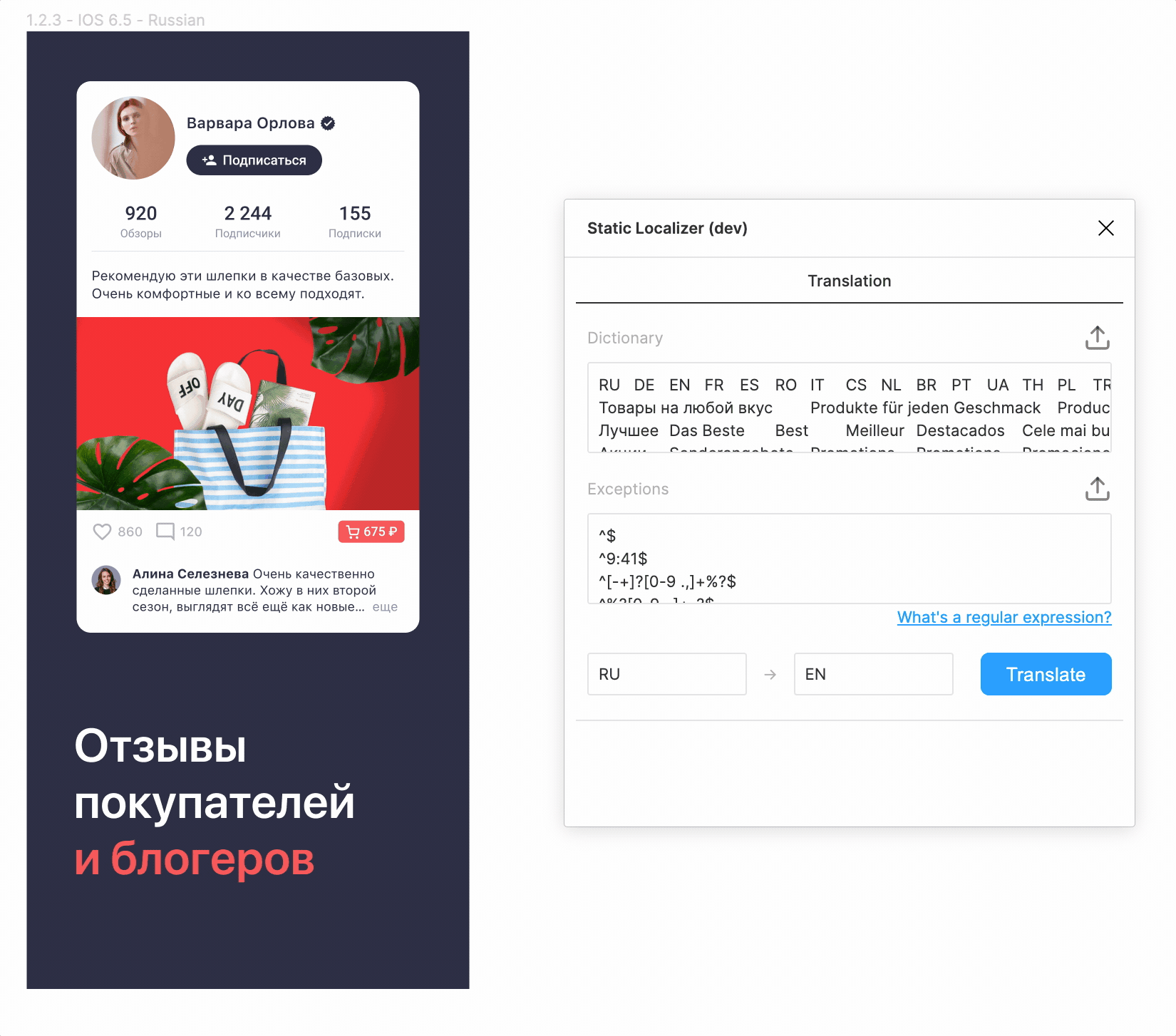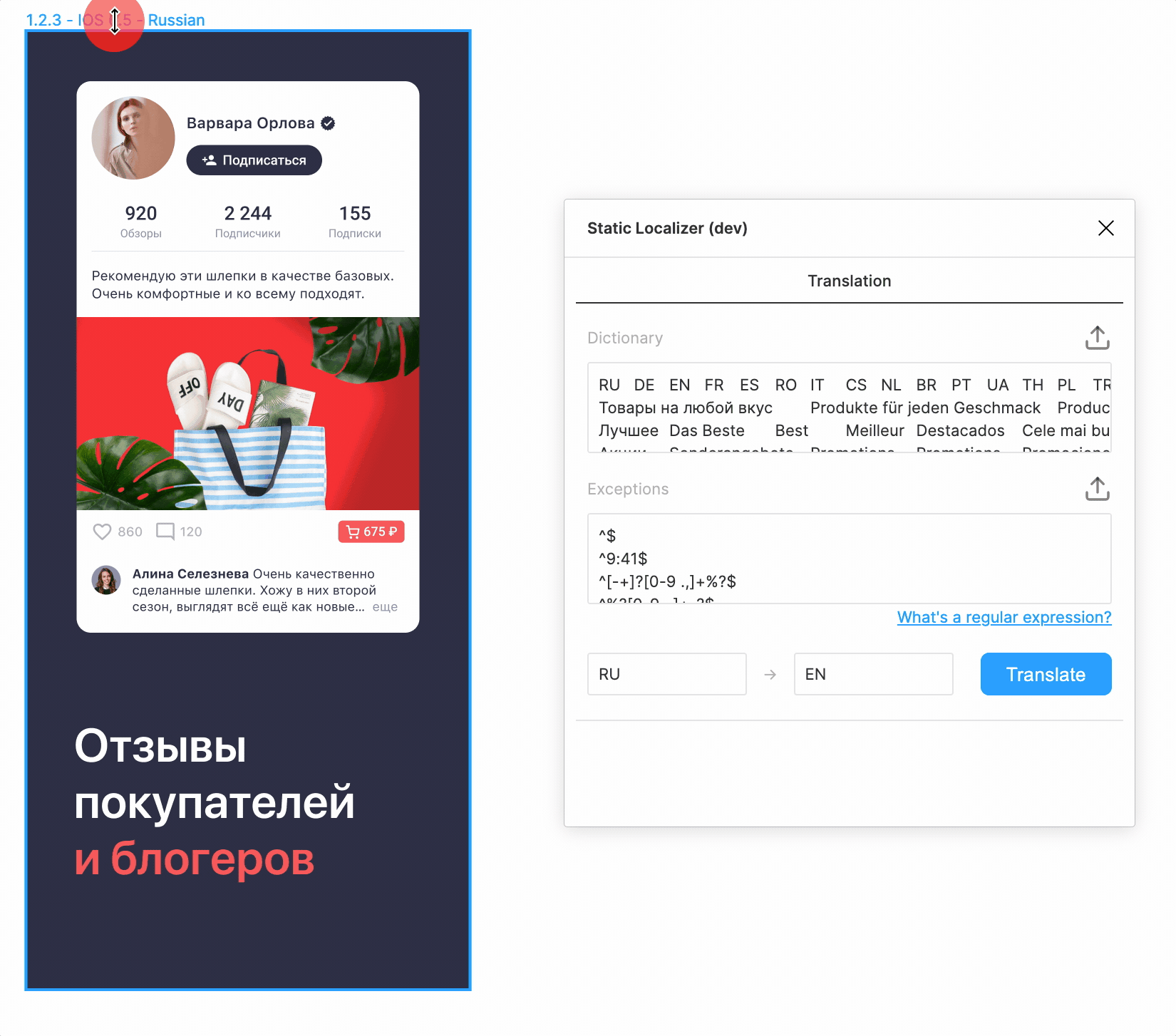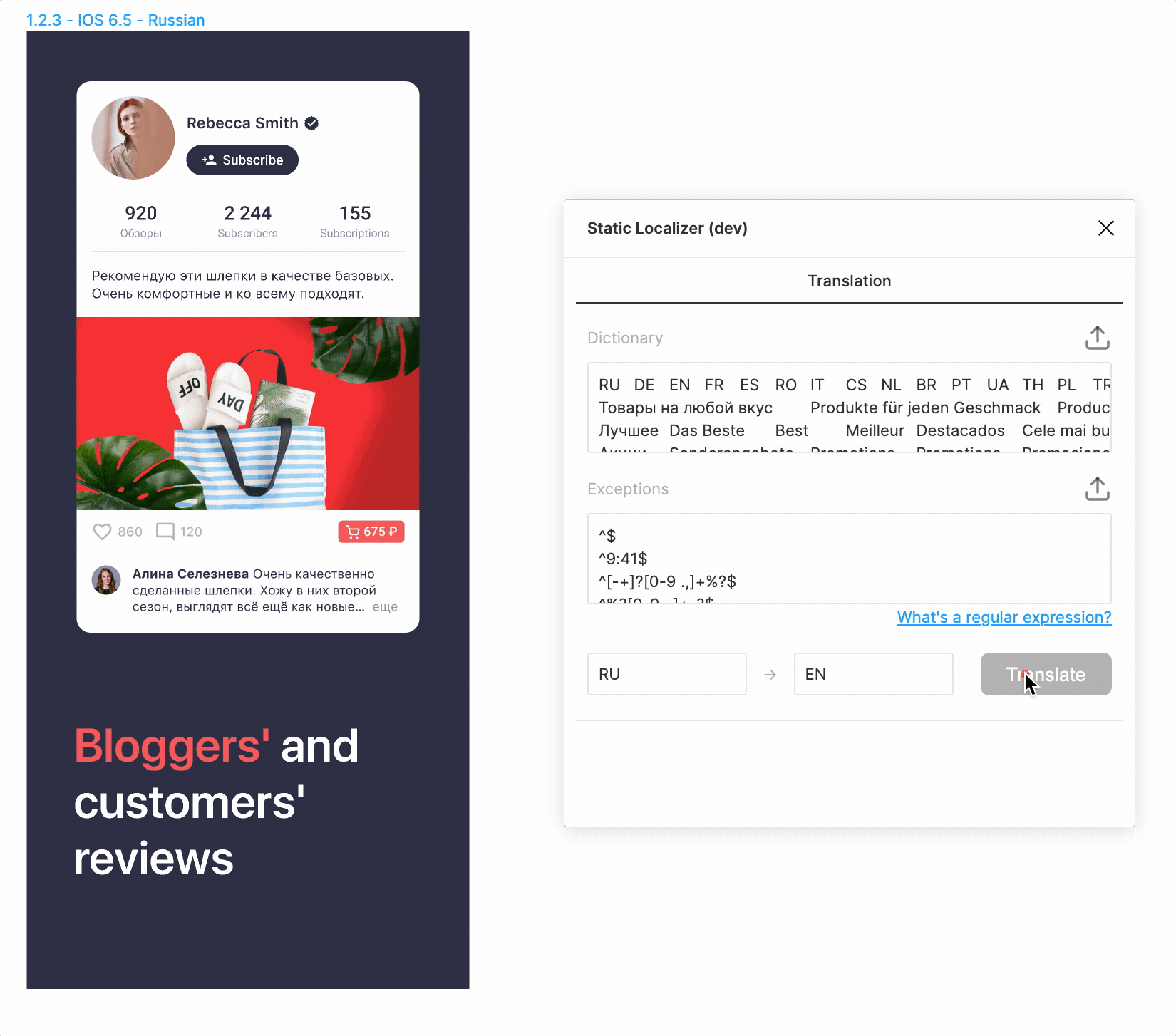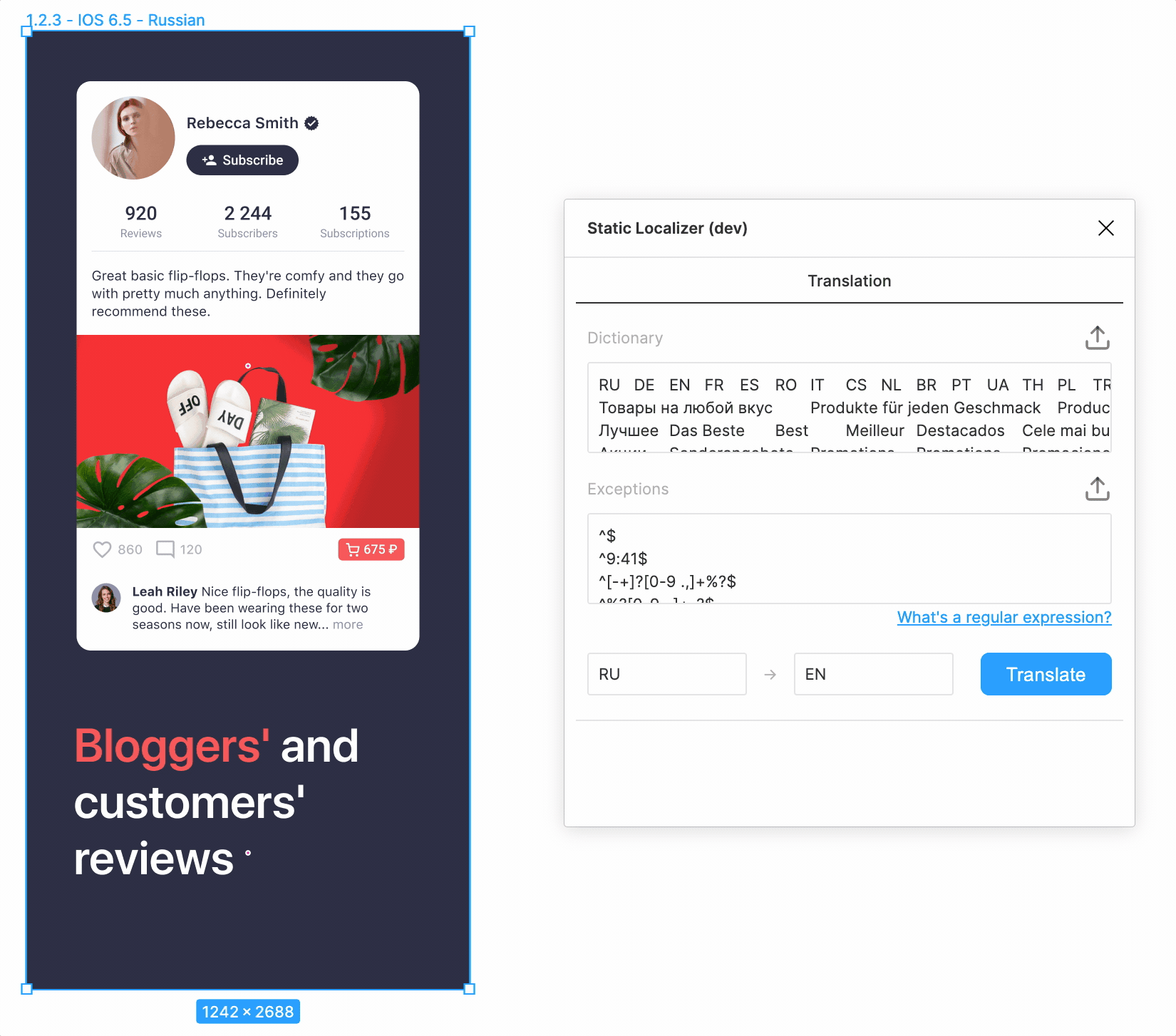
На данном этапе мы уже сделали приятный интерфейс и могли переводить макеты на почти все языки одним нажатием на кнопку! Выглядело фантастически, честно говоря.
Сообщения об ошибках и отладка
На удивление сложно было донести до переводчиков, что переводы нужных нам частей фраз должны быть согласованы с тем, как переведена сама фраза. Так, например, регулярно слово «еще» в очередном комментарии пользователя переводилось по-новому.
Нас спас только развернутый список ошибок с интерактивными ссылками на ноды, в которых те возникли. В Figma это можно организовать посылкой специального сообщения в серверную часть плагина с таким обработчиком:
if (message.type === 'focus-node') {
// максимально приближаемся
figma.viewport.zoom = 1000.0;
// перемещаем viewport в положение, где нода видна целиком
figma.viewport.scrollAndZoomIntoView([figma.getNodeById(message.id)]);
// немного отдаляем для комфортного восприятия
figma.viewport.zoom = 0.75 * figma.viewport.zoom;
}
В дальнейшем также оказалось полезным уметь формировать задания для переводчиков автоматически. Все, что необходимо для этого, мы, на самом деле, уже подготовили. Просто среди потенциальных основных стилей выберем тот, что охватывает наибольшее число символов.
function suggest(node: TextNode, content: string, sections: Section[], mapping: Mapping, exceptions: RegExp[]): string[] {
const n = content.length;
const styleScores = new Map();
for (let {from, to, style} of sections) {
styleScores.set(style.id, n + to - from + (styleScores.get(style.id) || 0));
}
let suggestedBaseStyleId: string = null;
let suggestedBaseStyleScore = 0;
for (let [styleId, styleScore] of styleScores) {
if (styleScore > suggestedBaseStyleScore) {
suggestedBaseStyleId = styleId;
suggestedBaseStyleScore = styleScore;
}
}
const result: string[] = [];
if (!(content in mapping)) {
result.push(content);
}
for (let {from, to, style} of sections) {
if (style.id === suggestedBaseStyleId) {
continue;
}
const sectionContent = normalizeContent(node.characters.slice(from, to));
if (!keepAsIs(sectionContent, exceptions) && !(sectionContent in mapping)) {
result.push(sectionContent);
}
}
return result;
}

עם האוכל בא התיאבון
Казалось, все должно было прекрасно работать и с RTL языками, так как мы лишь выполнили замену вхождений по точному совпадению. Однако внезапно выяснилось, что Figma не умеет корректно отображать RTL тексты — рендерит их слева направо. А лезть в дебри особенностей рендеринга RTL текстов — последнее, чего бы хотелось.
Да, нашлось несколько плагинов для интерактивного ввода арабского текста и один разломанный плагин, пытающийся разворачивать RTL тексты, но все это не решило нашу проблему. Хотя бы потому, что при этом напрочь слетало форматирование.
Аппетит приходит во время еды. Пути назад уже не было. Была видна лишь возможность сделать из этого проекта действительно полнофункциональный плагин.
Что может быть сложного? Давайте просто развернем текст посимвольно.

Так. Теперь все рендерится справа налево, но Figma вставляет по привычке автопереносы строк так, словно это LTR текст. В итоге строки нужно читать снизу вверх. Беда. Факт расстановки автопереносов Figma не отражает в содержимом ноды, да и вообще, никак нигде не отражает… Разве что… Если нода имеет адаптивную высоту, то при возникновении автопереноса высота ноды изменяется!
Итак, план такой.
- Разворачиваем перевод, как раньше.
- Создаем невидимую текстовую ноду с адаптивной высотой и той же шириной (если, конечно, ширина исходной ноды тоже фиксирована).
- Разбиваем развернутый перевод на слова и начинаем добавлять их в скрытую ноду по одному (справа налево). Если вдруг высота скрытой ноды изменилась, откатываемся, вставляем разделитель строк и продолжаем.
- Получившееся разбиение на строки просто конкатенируем.
- Удаляем временную ноду.
- Инвертируем выравнивание текста (если было по левому краю, то делаем по правому, и наоборот).
Большая сложность заключается в том, что в процессе нужно внимательно следить за тем, как видоизменяются секции.
К тому же, на ровном месте возникло несколько подводных камней.
- Большинство шрифтов из коробки не поддерживают арабский и иврит. Пришлось искать похожие по начертанию (а их не так много).
- Нельзя просто брать и разворачивать текст, если он содержит, например, латиницу, цифры и т.п. Эти части должны писаться слева направо даже в RTL тексте.
- От стиля зависит размер слов, так что внутри скрытой ноды текст нужно правильно форматировать.
- Первое слово в очередной строке может не влезть по ширине, тогда это ошибка, о которой нужно сообщить.
- Нашлись слова в арабском, которые в отсутствие пробела после них отображались в Figma некорректно.
Полный код поддержки RTL языков я здесь приводить не стану — он доступен в репозитории.
Этот этап занял гораздо больше времени и сил, чем реализация базовой функциональности плагина, но результат был поистине впечатляющим!
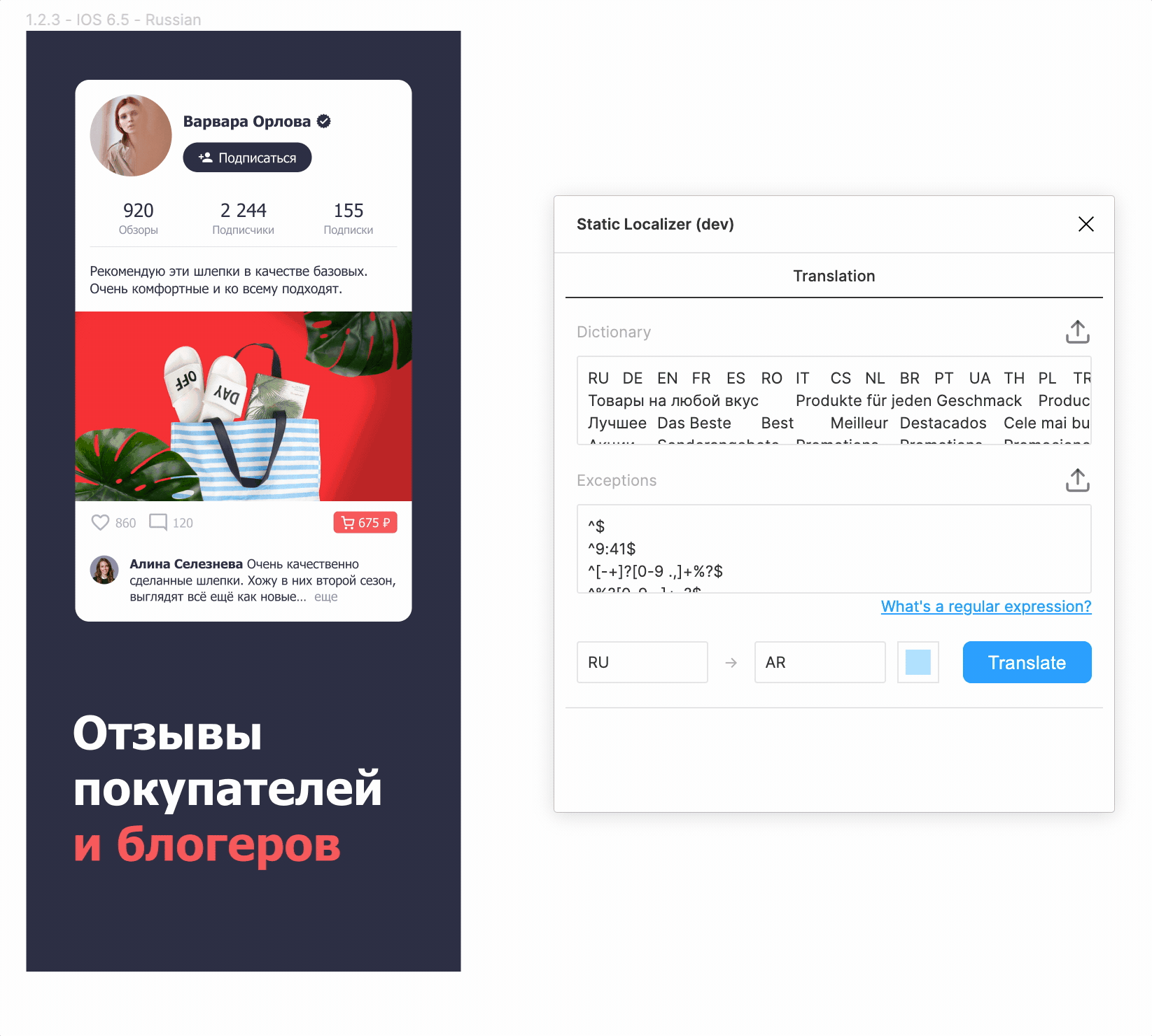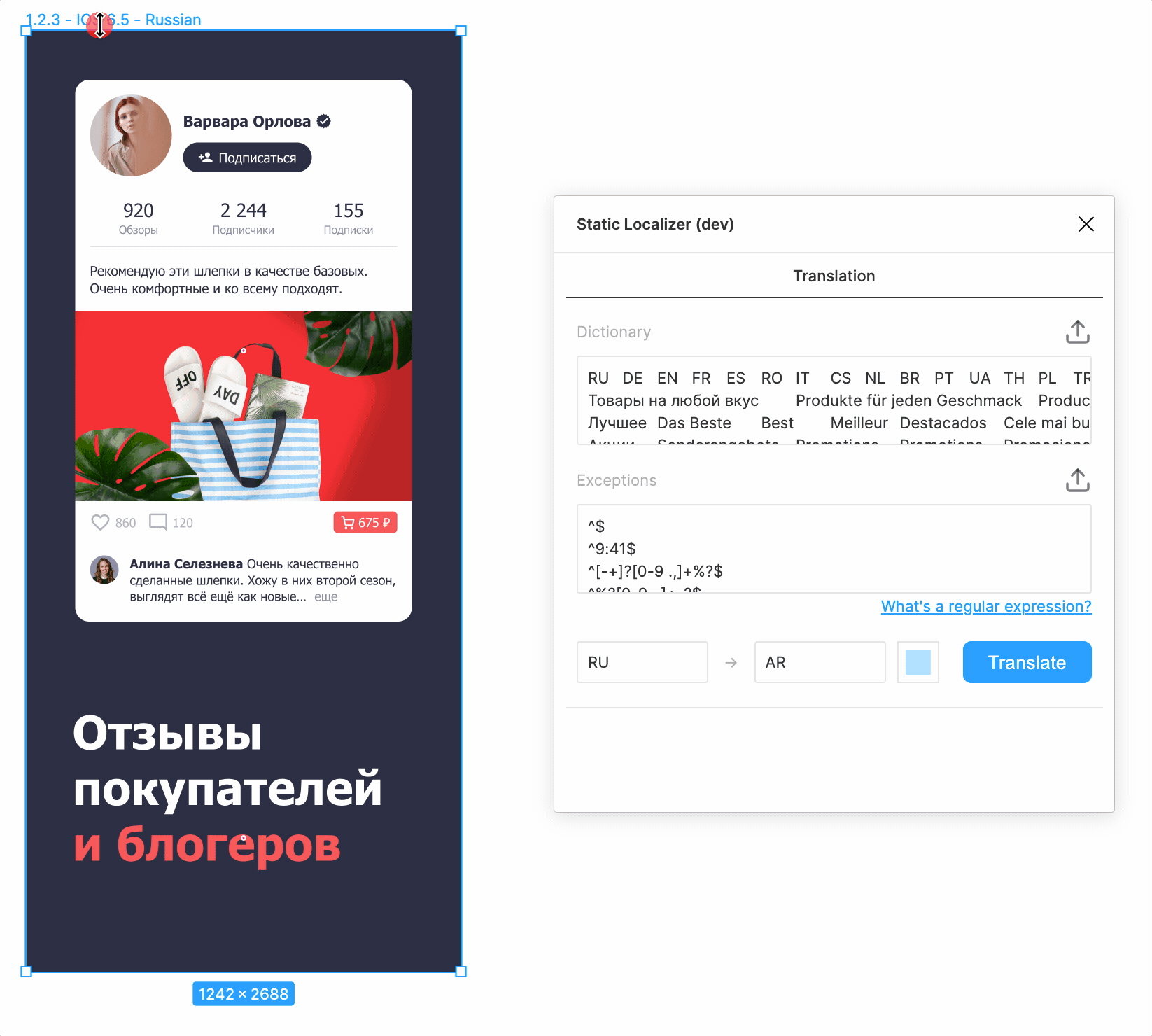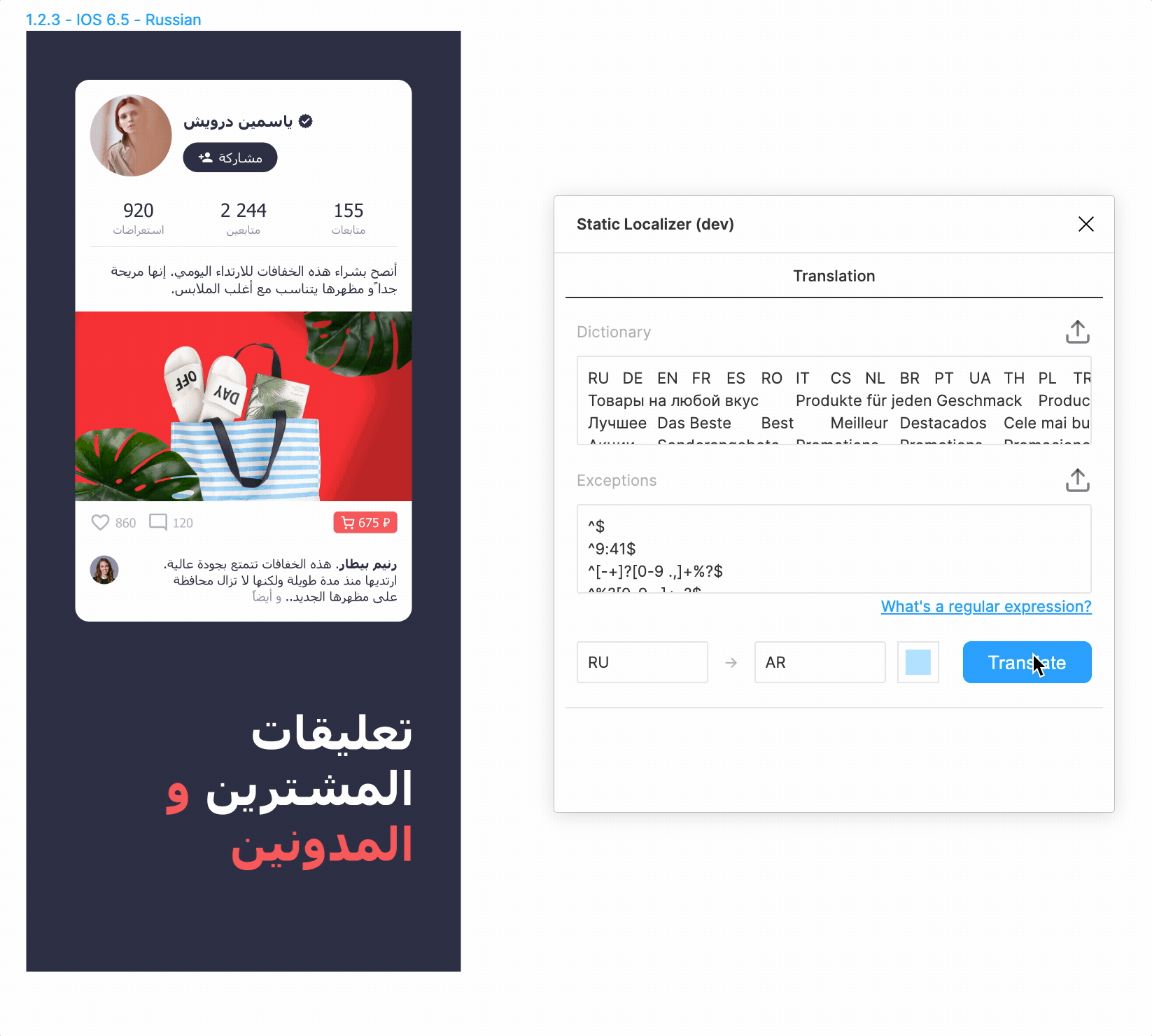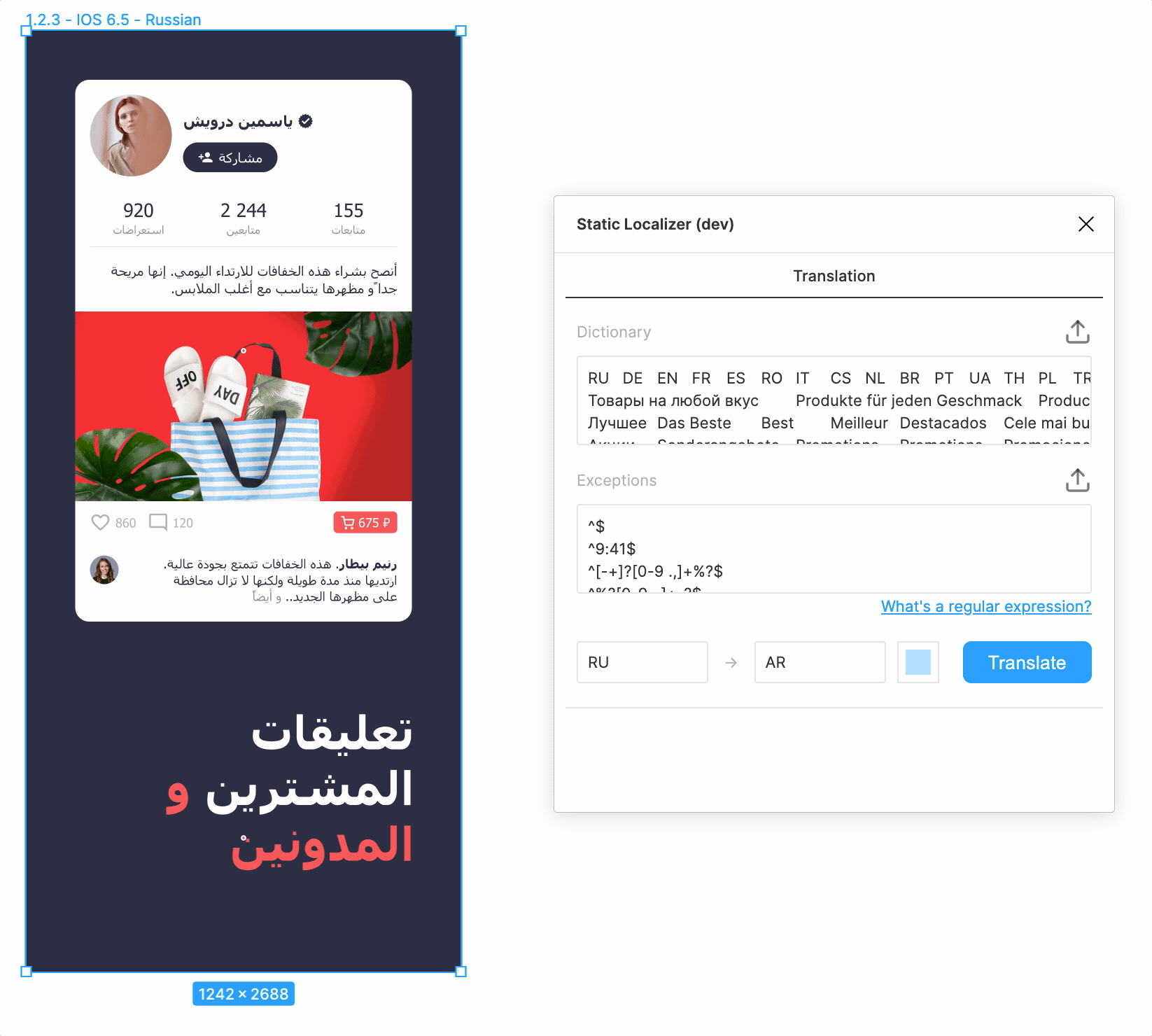
На десерт.
- Правильное обращение арабского текста — куда более сложная задача, чем кажется, если учесть всевозможные примеси из других языков и специальные лигатуры.
- Интерфейсы на RTL языках необходимо отразить по горизонтали, что пока приходится делать вручную, хотя потенциально и это автоматизируется.
- Попутно нами был обнаружен и зарепорчен баг в Figma, из-за которого при добавлении латиницы в арабский текст лигатуры «развязывались».
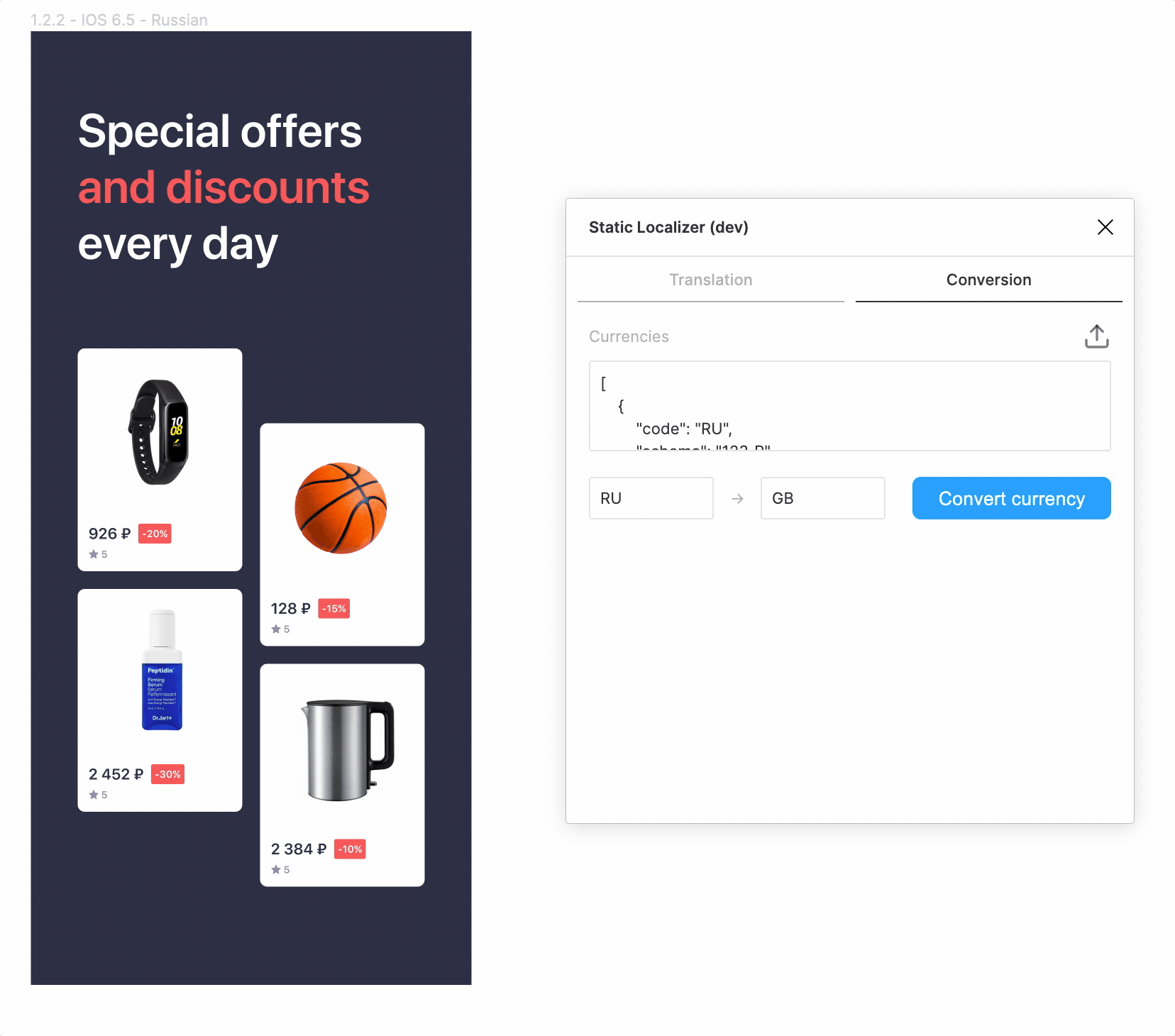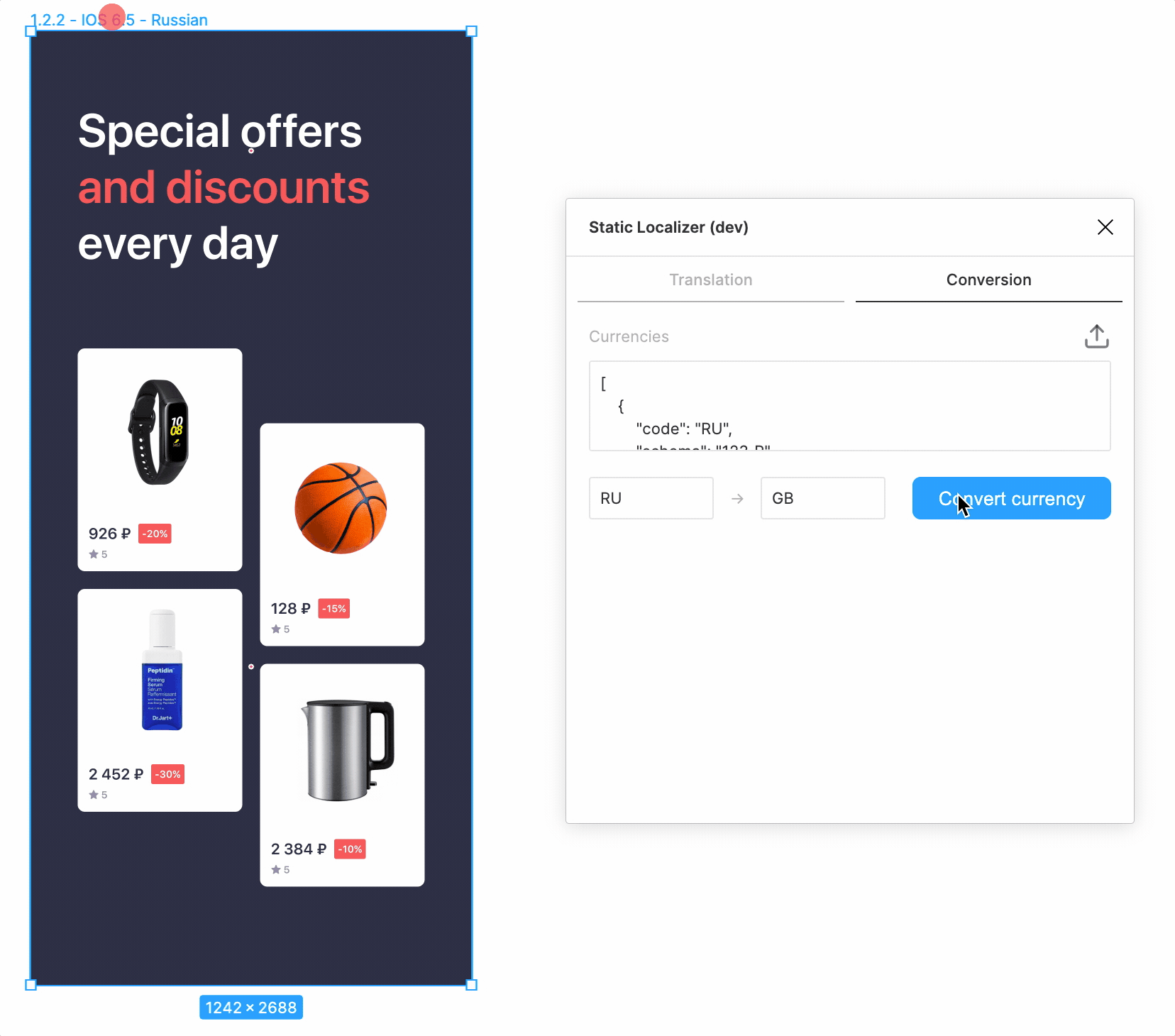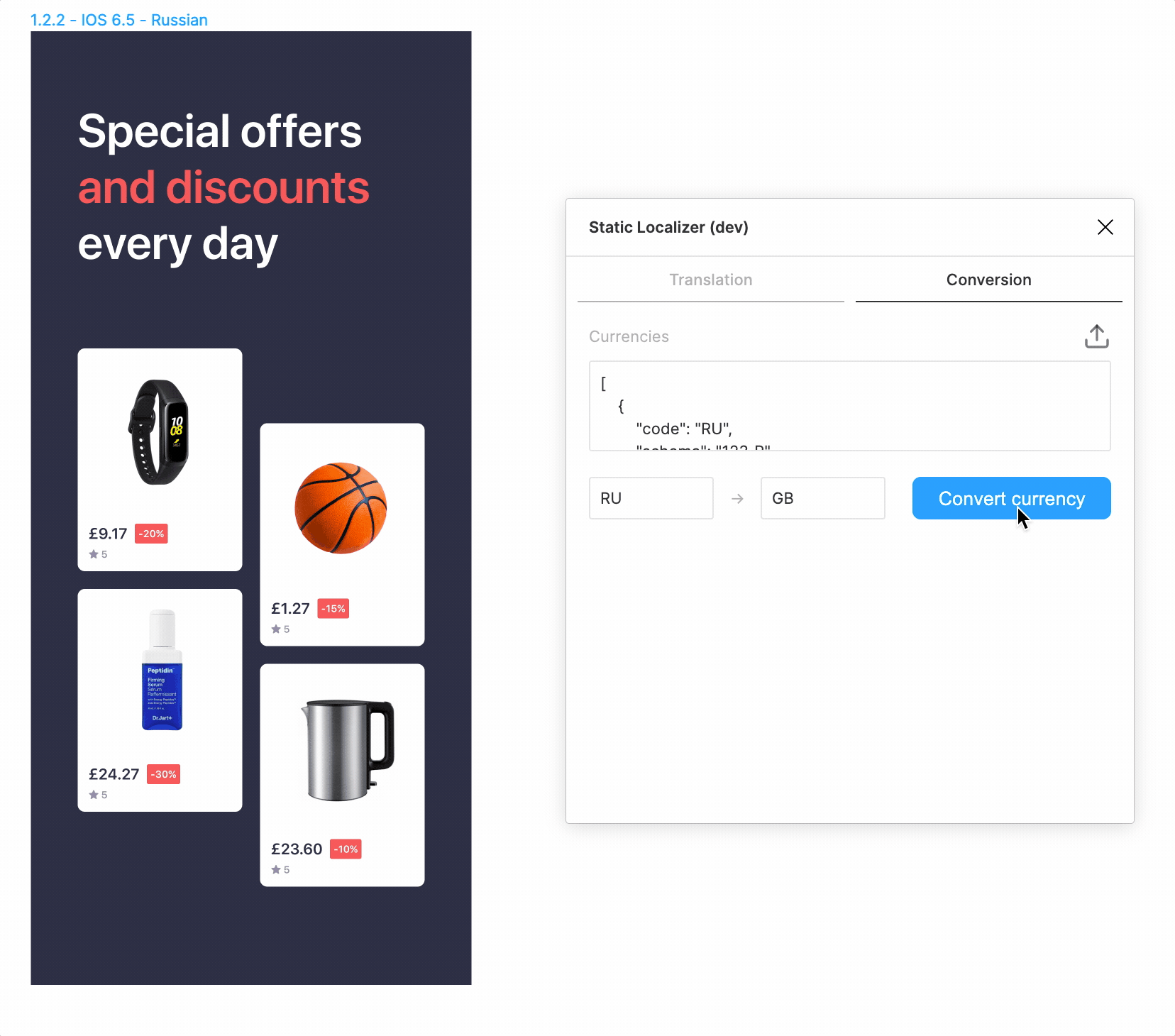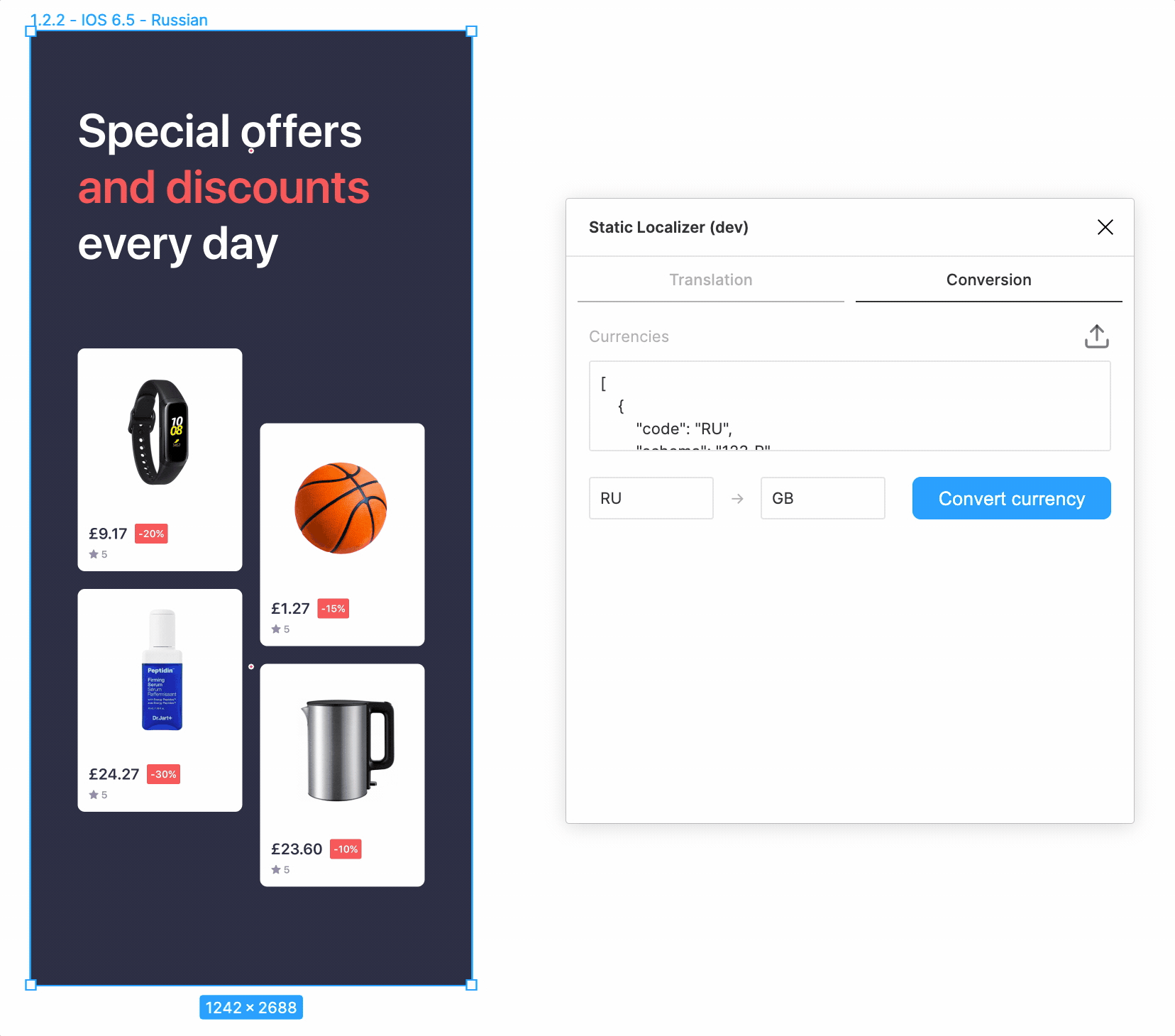
Конвертирование валют
Так уж случилось, что мы маркетплейс, и у нас есть товары. И товары имеют цену. Можно, конечно, отдать с десяток текстов вида »1 234 ₽» переводчикам и надеяться, что они правильно локализуют цены, использовав верные разделители, верные знаки валют и верное количество цифр после запятой… Но зачем, если можно все это проделать автоматически, один раз настроив несложный конвертер?
type Currency = {
// уникальный код, у нас для удобства совпадает с языковым
code: string;
// схема, в которой 123 нужно заменить на нужную сумму в нужном формате, вроде "$123"
schema: string;
// разделитель тысяч
digitGroupSeparator: string;
// разделитель дробной части (обычно точка или запятая)
decimalSeparator: string;
// кол-во десятичных знаков в дробной части
precision: number;
// курс к некоторой базовой валюте (должна быть общей для всего конфига)
rate: number;
};
async function convertCurrencyInSelection(settings: Settings): Promise {
const currencies = parseCurrencies(settings.serializedCurrencies);
console.log('Currencies:', currencies);
const sourceCurrency = currencies.filter(currency => currency.code === settings.sourceCurrencyCode)[0];
if (sourceCurrency === undefined) {
throw {error: 'unknown currency code `' + settings.sourceCurrencyCode + '`'};
}
const targetCurrency = currencies.filter(currency => currency.code === settings.targetCurrencyCode)[0];
if (targetCurrency === undefined) {
throw {error: 'unknown currency code `' + settings.targetCurrencyCode + '`'};
}
await replaceCurrencyInAllTexts(sourceCurrency, targetCurrency);
}
function parseCurrencies(serializedCurrencies: string): Currency[] {
const codeSet = new Set();
return JSON.parse(serializedCurrencies).map((x: any, index: number) => {
const currency: Currency = {
code: null,
schema: null,
digitGroupSeparator: null,
decimalSeparator: null,
precision: null,
rate: null,
};
Object.keys(currency).forEach(key => {
if (x[key] === undefined || x[key] === null) {
throw {error: 'invalid currency definition: no `' + key + '` in entry #' + (index + 1)};
}
if (key === 'schema' && x[key].indexOf('123') === -1) {
throw {error: 'schema in entry #' + (index + 1) + ' should contain `123`'};
}
if (key === 'rate' && x[key] <= 0) {
throw {error: 'non-positive rate in entry #' + (index + 1)};
}
currency[key] = x[key];
});
if (currency.precision > 0 && currency.decimalSeparator === '') {
throw {error: 'entry #' + (index + 1) + ' must have a non-empty decimal separator'};
}
if (codeSet.has(currency.code)) {
throw {error: 'multiple entries for `' + currency.code + '`'};
}
codeSet.add(currency.code);
return currency;
});
}
async function replaceCurrencyInAllTexts(sourceCurrency: Currency, targetCurrency: Currency): Promise {
const textNodes = await findSelectedTextNodes();
const escapedSchema = escapeForRegExp(sourceCurrency.schema);
const escapedDigitGroupSeparator = escapeForRegExp(sourceCurrency.digitGroupSeparator);
const escapedDecimalSeparator = escapeForRegExp(sourceCurrency.decimalSeparator);
const sourceValueRegExpString = '((?:[0-9]|' + escapedDigitGroupSeparator + ')+' + escapedDecimalSeparator + '[0-9]{' + sourceCurrency.precision + '})';
const sourceRegExp = new RegExp('^' + escapedSchema.replace('123', sourceValueRegExpString) + '$');
console.log('Source regular expression:', sourceRegExp.toString());
await Promise.all(textNodes.map(async node => {
const content = node.characters;
const match = content.match(sourceRegExp);
if (match !== null && match[1] !== null && match[1] !== undefined) {
const style = getSectionStyle(node, 0, node.characters.length);
if (style === figma.mixed) {
throw {error: 'node `' + content + '` has a mixed style'};
}
let sourceValueString = match[1].replace(new RegExp(escapedDigitGroupSeparator, 'g'), '');
if (sourceCurrency.decimalSeparator !== '') {
sourceValueString = sourceValueString.replace(sourceCurrency.decimalSeparator, '.');
}
const sourceValue = parseFloat(sourceValueString);
const targetValue = sourceValue * targetCurrency.rate / sourceCurrency.rate;
const truncatedTargetValue = Math.trunc(targetValue);
const targetValueFraction = targetValue - truncatedTargetValue;
const targetValueString = (
truncatedTargetValue.toString().replace(/(\d)(?=(\d{3})+(?!\d))/g, '$1,').replace(/,/g, targetCurrency.digitGroupSeparator) +
targetCurrency.decimalSeparator +
targetValueFraction.toFixed(targetCurrency.precision).slice(2)
);
await figma.loadFontAsync(style.fontName);
node.characters = targetCurrency.schema.replace('123', targetValueString);
}
}));
}
function escapeForRegExp(s: string): string {
return s.replace(/([[\^$.|?*+()])/g, '\\$1');
}
Публикация
Перед публикацией плагина был проделан ряд улучшений UX. Например, настройки в интерфейсе плагина сохранялись в localStorage (да, Figmа такое умеет!). Это позволяет не загружать словари каждый раз и быстро выполнять переводы на несколько языков. А чтобы интерфейс не зависал во время активных операций с документом, по рекомендации самой же Figma, была ограничена интенсивность асинхронных параллельных операций с помощью простой самописной функции mapWithRateLimit. На сдачу в плагин была добавлена возможность заменять шрифты.
Процедура публикации плагина заняла больше двух недель, но никаких проблем не возникло.
В заключение
Без плагина не обошлась и подготовка к Новому году.
Возможно, когда-нибудь мы расскажем, как в рамках той же задачи научились выгружать из Figma весь документ в виде одного структурированного архива из картинок.
Хочется поблагодарить Аню Ноджа́к, дизайн-директора Joom, за веру в мои силы. Очень рекомендую почитать ее взгляд на задачу.
Ссылки
Исходный код плагина Static Localizer на GitHub
Плагин Static Localizer на сайте Figma
