Автоматическая виртуализация рендеринга произвольной вёрстки
Здравствуйте, меня зовут Дмитрий Карловский и я. прибыл к вам из недалёкого будущего. Недалёкого, потому что там уже всё и все тормозят. Писец подкрался к нам незаметно: сначала перестали расти мощности компьютеров, потом пропускная способность сетей. А пользователи… они продолжали генерировать контент как не в себя. В итоге, за считанные годы UX интерфейсов деградировал настолько, что ими стало невозможно пользоваться и многие пользователи поспешили перейти на облачный стриминг своих браузеров, которые работают на суперкомпьютерах, принадлежащих корпорациям, которые не дают людям устанавливать на них блокировщики рекламы. Поэтому я пришёл к вам именно сейчас, в этот момент, когда проблема уже заметна, но ещё можно всё исправить, пока не стало слишком поздно.

Это — текстовая расшифровка выступления на HolyJS'20 Moscow. Вы можете либо посмотреть видео запись, либо открыть в интерфейсе проведения презентаций, либо читать как статью… Короче, где угодно лучше, чем на Хабре, ибо новый редактор плохо импортирует статьи…
Тяжёлое прошлое: Огромные списки задач
Сперва расскажу немного о своём опыте. Мой релевантный опыт начался с разработки огромных списков задач, состоящих из нескольких десятков тысяч задач. Они образовывали иерархию и имели довольно причудливый дизайн, что осложняло применение virtal scroll. А таких списков задач на экране могло быть десятки разом. И всё это в реальном времени обновлялось, дрегендропилось и анимировалось.
Рекламная пауза: Богатый редактор
Так же я разрабатывал богатый, но компактный редактор текста, позволяющий множеству пользователей редактировать 200 страничные документы в реальном времени. У нас там применялся уникальный механизм синхронизации, минимизирующий конфликты, множество оригинальных UX решений и полностью кастомный виртуализированный рендеринг на холсте.
К сожалению, он пал жертвой коронавируса, так что если кто-то захочет поднять знамя и продолжить его разработку, то пишите мне — я сведу с нужными людьми. Нужно будет выкупить права и доработать под свои нужды.
Альтернативная линия времени: $mol
Ну и, конечно, нельзя не упомянуть про разработанный мною фреймворк, обеспечивающий автоматическую виртуализацию. Который задоминировал всех конкурентов. В альтернативной линии времени. Там у нас все хорошо и поэтому я пришёл к вам.
mol.hyoo.ru
Короче, съел я на теме виртуализации собаку, кошку, хорька, енота и даже морскую свинку. В общем, подкрепился как следует. Так что далее я расскажу вам как эффективно предоставлять пользователю огромные объёмы данных, почему вообще возникает такая необходимость, какие технологии нам с этим могут помочь, и почему React ведёт нас в тупик.
Типичный цикл разработки
Типичный цикл разработки выглядит так:
Написали код.
Проверили в тепличных условиях.
Пришли пользователи и всё заспамили.
Оптимизировали.
Пользователи всё не унимаются.
Мы уже взрослые ребята мы не пишем тяп-ляп и в продакшен. Теперь мы пишем код, проверяем его на тестовых данных, и если все хорошо, выкладываем в прод. Но тут приходят пользователи генерируют кучу контента и всё начинает тормозить. Тогда мы закатываем рукава и начинаем оптимизировать. Но приходят пользователи и генерят ещё больше контента и тормоза возвращаются вновь.
Наивный рендеринг: Скорость загрузки и Отзывчивость
Этот порочный круг приводит к таким вот последствиям:

Сейчас вы видите timeline загрузки и рендера двух с половиной тысяч комментариев. Скрипту требуется 50 секунд на формирование DOM, после чего ещё 5 секунд нужно браузеру чтобы рассчитать стили, лейаут и дерево слоёв.
И это не картинка из будущего. Это самое натуральное настоящее. Замечу, что это хоть и мобильная версия, но открытая на ноуте. На мобилке все куда печальнее.
Наивный рендеринг: Потребление памяти
Если мы заглянем на вкладку «память» то заметим, что такая страница потребляет аж гигабайт.

На моем телефоне (потряхивает своим тапком) её меньше 3 гигов. И я думаю не надо объяснять откроется ли она у меня вообще. Тут мы плавно переходим к следующему риску…
Наивный рендеринг: Риск неработоспособности
Если мы не влезаем по памяти, то приложение может закрыться. Причём может закрыть не одно, а утянуть с собой ещё несколько. А даже если не закроется, то чем больше приложение, тем дольше оно грузится. А чем дольше грузится, тем выше риск, что соединение оборвётся и всё придётся начинать заново. Ну либо довольствоваться первыми 4 комментариями из двух с половиной тысяч — реальная ситуация на моей мобилке.
Не влезли по памяти — приложение закрывается.
Обрыв соединения — страница обрывается.
Браузер может заглючить на больших объёмах.
Наивный рендеринг: Резюме
Короче, если мы продолжим разрабатывать наши интерфейсы том же духе, то неизбежно возникнут проблемы с медленной загрузкой, плохой отзывчивостью, засиранием памяти, а то и вообще падениями на ровном месте.
Медленная загрузка.
Плохая отзывчивость.
Высокое потребление памяти.
Риск неработоспособности.
Первый подопытный: Статья на Хабре
Недавно я опубликовал статью, где рассказывал как можно ускорить Хабр раз в десять, отказавшись от SSR.
Вырезаем SSR и ускоряем Хабр в 10 раз
И там я собственно разобрал пример переписывания страницы дерева комментариев с применением виртуализации.
https://nin-jin.github.io/habrcomment/#article=423889
Второй подопытный: Ченьжлог на GitLab
На сей раз мы разберём новый кейс — страница коммита на GitLab.
Я просто взял второй попавшийся коммит в первом попавшемся репозитории. Это всего порядка 5 тысяч строк в 100 файлах. Казалось бы — совсем не много. Однако, грузится всё довольно долго. Сначала 10 секунд ждём ответа сервера, потом ещё пол минуты любуемся мёртвыми кусками кода без подсветки синтаксиса. Короче, приходится ждать почти минуту, прежде чем приложением становится возможно пользоваться.
Перенос рендеринга HTML на сервер
Что ж, давайте откроем таймлайн и увидим там следующую картину.
Пол минуты HTML выдаётся браузеру. Обратите внимание что она вся фиолетовая. Это значит что каждый раз, когда браузер получает очередной чанк HTML и подкрепляет его в документ, то пересчитывает стили, лейаут и дерево слоёв. А это весьма не быстрый процесс. И чем больше DOM, тем медленнее он становится.
Наконец, подключаются скрипты и сравнительно быстро добавляют к коду подсветку синтаксиса. Но чтобы переварить такое массовое изменение огромного дерева, браузеру требуется потом ещё целых 3 секунды непрерывной работы.
Страдания Ильи Климова по GitLab-у
Ну да ладно со скоростью загрузки. Один раз подождать ведь не проблема? Как бы не так! Браузер делает пересчёт стилей, лейаута и слоёв чуть ли не на каждый чих. И если вы попробуете поработать со страницей, то заметите, что на наведение указателя она реагирует весьма не рьяно, а вводить текст с лютыми задержками крайне не комфортно.
Год назад Илья Климов как раз рассказывал в своём выступлении страшные истории про работу как раз над этой страницей. Например, прикручивание спинера заняло 3 месяца работы не самого дешёвого разработчика. А сворачивание небольшого файла вешало вкладку на 10 секунд. Но это, правда, уже оптимизировали — теперь на это требуется всего лишь пара секунд!
Причина этих ужастиков в том, что изначально была выбрана такая себе архитектура с такими себе технологиями, и писалось много типового кода пяткой левой ноги, а теперь вот нужно вкладывать кучу денег в Фонд Оплаты Труда, чтобы делать простейшие вещи долго и без существенного профита.
На мой вопрос «что ж вы на $mol всё это не перепишите, чтобы у вас всё летало?» Илья ответил, что не знает как его продать в компании. Что ж, надеюсь дальнейший разбор техник виртуализации поможет ему в этом нелёгком деле.
Оптимизации вёрстки
Первое что приходит на ум -, а давайте упростим вёрстку и DOM уменьшится. В качестве примера — кейс от Альфа-банка, который я разбирал в своей статье об истории $mol.
$mol: 4 года спустя
Там был компонент вывода денежных сумм, который рендерился в 8 DOM элементов вместо 3.
1 233
,
43
₽
1 233
,43 ₽
Не смотря на высокую частоту использования он был не оптимизирован. После моей статьи над ним поработали и теперь он рендерится в 5 элементов.
Если так поработать и над остальными компонентами, думаю можно уменьшить размер DOM раза в 2. Однако…
Достоинства оптимизации вёрстки
Важно понимать, что асимптотика таким образом не меняется. Допустим страница грузилась 30 секунд. Вы оптимизировали, и она сала грузиться 10 секунд. Но пользователи сгенерируют в 3 раза больше контента и страница снова грузится 30 секунд. А оптимизировать вёрстку уже не куда.
Кратное ускорение ✅
Асимптотика не меняется ❌
Короче, годится эта техника лишь как временная мера, пока вы прикручиваете что-то по серьёзней.
Прикладная оптимизация
Можно пошаманить над вашим прикладным кодом — кодом приложения, кодом ваших компонент. Тут есть несколько вариантов с разными ограничениями…
Пагинация
Экспандеры
Бесконечный скролл
Виртуальный скролл
Прикладная оптимизация: Пагинация
Первое, что приходит на ум — это пагинация.

Не буду рассказывать что это такое — все и так с ней прекрасно знакомы. Поэтому сразу к достоинствам…
Достоинства пагинации
Во-первых пользователю приходится много кликать переключаясь между страницами — это тренирует его мелкую моторику. Кроме того приходится ждать загрузки ну или хотя бы рендеринга очередной страницы — есть время подумать о высоком: что он здесь делает, зачем и возможно решить что оно ему и не надо. Также постоянно теряется контекст, то есть тренируется память — ему нужно помнить что было там на предыдущей странице.
Бывает, что элемент перескакивает между страницами при переключении между ними. Это позволяет, например, ещё раз прочитать один и тот же комментарий, чтобы лучше его понять. Или наоборот, пропустить незамеченным — мало ли там какой-то негатив. А так он сохранит душевное равновесие.
Пагинация применима лишь для плоских списков, что избавляет пользователя от мудрёных древовидных интерфейсов.
Однако, если среди элементов на странице окажется какой-то особо крупный элемент, то опять вернутся тормоза. Но это будет всяко быстрее чем рендерить вообще все элементы на одной странице.
И, наконец, нельзя забывать про пользователей скрин ридеров, которые будут вспоминать вас тёплым словом каждый раз, когда им придётся при переключении на очередную страницу снова стрелочками клавиатуры навигироваться от корня страницы до того контента который им интересен.
Много кликать ❌
Ожидание загрузки каждой страницы ❌
Теряется контекст ❌
Элементы скачут между страницами ❌
Вероятность пропустить элемент ❌
Применимо лишь для плоских списков ❌
Большой элемент возвращает тормоза ❌
Слепые вас ненавидят ❌
Работает быстрее, чем всё скопом рендерить ✅
В общем, думаю вы уже поняли какое тёплое у меня отношение к пагинации. Я даже отдельную статью ей посвятил…
Популярные анти паттерны: пагинация
Прикладная оптимизация: Экспандеры
Можно выводить и на одной странице, но свернув каждый элемент под спойлером, а показывать его содержимое уже по клику.
https://nin-jin.github.io/my_gitlab/#collapse=true
Достоинства экспандеров
Тут опять же приходится много кликать и ждать загрузки очередной ветки. Соответственно, мы тренирую мелкую моторику пользователя и позволяем ему подумать. Работает оно быстро, ведь нам нужно показать лишь список элементов, но не их содержимое. Но если пользователь откроет много экспандеров, то снова вернутся тормоза. Пользователи скрин ридеров будут вас жарко вспоминать за то, что им приходится ещё и искать эти экспандеры и нажимать на них, что крайне неудобно когда пользуется клавиатура. и, наконец, самое главное преимущество: экспандер можно применять и для иерархических структур, а не только плоских списков.
Очень много кликать ❌
Ожидание загрузки каждой ветки ❌
Если не закрывать, то снова тормоза ❌
Слепые вас проклинают ❌
Открывается быстро ✅
Применимо не только для плоских списков ✅
Прикладная оптимизация: Бесконечный скролл
Но что если мы не хотим тренировать мелкую моторику наших пользователей? Тогда можно применить, например, бесконечный скролл, так популярный в интерфейсах Яндекса, например.
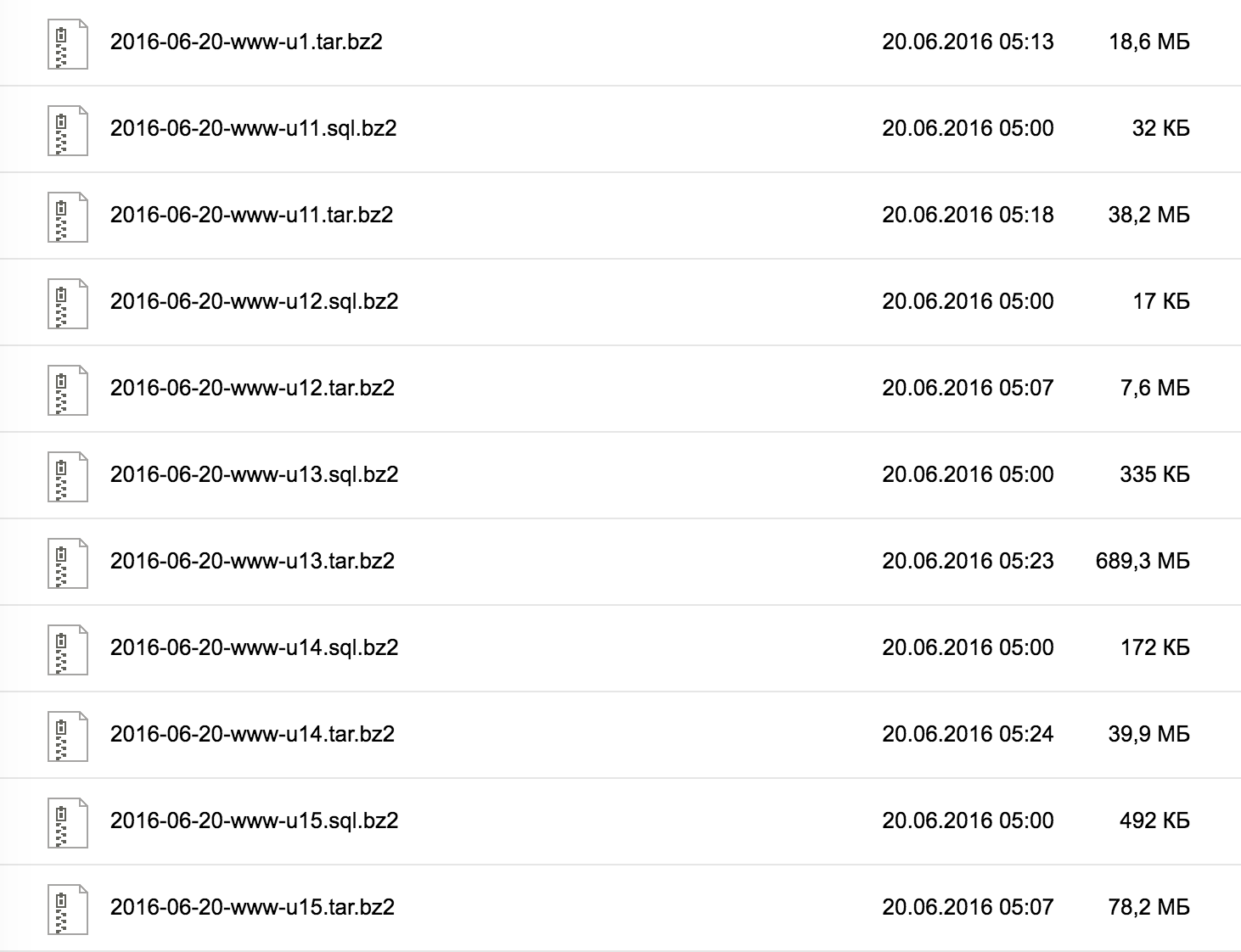
И сейчас вы видите скриншот Яндекс.Диска. У меня есть там директория состоящая из пяти тысяч файлов. И если открытие её происходит относительно быстро, то, чтобы домотать до самого низа, требуется 3 с лишним минуты реального времени. Всё потому, что по мере скролла вниз, DOM становится всё больше и больше, от чего добавление очередного куска данных становится всё медленнее. В итоге, добавление последнего куска, например, занимает уже несколько секунд.
Достоинства бесконечного скролла
Применимо лишь для плоских списков ❌
Ожидание загрузки каждой ветки ❌
Увеличение тормозов по мере прокрутки ❌
Быстрое появление ✅
Прикладная оптимизация: Виртуальный скролл
Дальнейшее развитие бесконечного скролла — это виртуальный скролл, который не только дорендеривается снизу, но и удаляет контент сверху, по мере прокрутки вниз. И наоборот, при прокрутке вверх.
https://bvaughn.github.io/react-virtualized/#/components/WindowScroller
Достоинства виртуального скролла
Тут размер DOM остаётся примерно постоянным, то есть интерфейс остаётся отзывчивым. Но годится это лишь для плоских списков. Для иерархических применять его зачастую больно — смотря какой визуал нарисовал дизайнер. Тут еще есть ещё такое ограничение, что нам должны быть известны примерные размеры элементов, чтобы мы могли рассчитать, какие элементы попадают в видимую область, а какие точно не попадают.
Применимо лишь для плоских списков ❌
Размеры элементов должны быть предсказуемы ❌
Работает быстро ✅
Прикладная оптимизация: Резюме
Ухудшение пользовательского опыта ❌
Не решают проблему полностью ❌
Ограниченная применимость ❌
Полный контроль где какую применять ✅
Нужно не забыть ❌
Нужно продавить ❌
Нужно реализовать ❌
Нужно оттестировать ❌
Нужно поддерживать ❌
Оптимизация инструментов
Чтобы не заниматься ручными оптимизациями каждый раз в каждом приложении можно пойти другим путём и оптимизировать инструментарий, то есть библиотеки, фреймворки, компиляторы и тому подобное. Тут есть опять же несколько подходов…
Тайм слайсинг
Прогрессивный рендеринг
Ленивый рендеринг
Виртуальный рендеринг
Оптимизация инструментов: Тайм слайсинг
Можно попробовать так называемый time slicing. На одной из прошлых Holy JS я рассказывал про технику квантования вычислений, где долгое вычисление разбивается на кванты по 16 миллисекунд, и между этими квантами браузер может обрабатывать какие-то события делать плавную анимацию и так далее. То есть вы не блокируете поток на долгое время, получая хорошую отзывчивость…
Квантовая механика вычислений в JS

Достоинства тайм слайсинга
Звучит вроде бы не плохо. Но тут есть такая проблема, как замедление общего времени работы всего вычисления. Например, если просто взять и выполнить вычисление без квантования занимает полсекунды, то если его постоянно прерывать каждые 16 мс, позволяя браузеру делать свои дела, то до завершения может пройти и пара секунд. Для пользователя это может выглядеть как замедление работы. Ну и другой аспект заключается в том что javascript не поддерживает файберы, то есть такие потоки исполнения, которые можно останавливать и возобновлять в любое время. Их приходится эмулировать тем или иным способом, а это всегда костыли, замедление работы и некоторые ограничения на то, как пишется код. В общем, с этим подходом всё не очень хорошо, поэтому в $mol мы и отказались от квантования.
Хорошая отзывчивость ✅
Замедленность работы ❌
Эмуляция файберов в JS ❌
Оптимизация инструментов: Прогрессивный рендеринг
Частным случаем тайм слайсинга является прогрессивный рендеринг, где DOM генерируется и подклеивается по кусочкам. Это позволяет очень быстро да ещё и анимированно показать первый экран и в фоне дорендерить страницу до конца. Такой подход реализован, например, во фреймворке Catberry…
catberry.github.io
Достоинства прогрессивного рендеринга
В $mol мы тоже экспериментировали с подобным подходом, но в итоге отказались, так как время появления даже первого экрана существенно замедлялось, а если страница была по настоящему большой, то всё вообще умирало, ибо по мере роста размеров DOM добавление даже маленького кусочка в него становилось всё медленнее и медленнее.
Хорошая отзывчивость в процессе появления ✅
Эмуляция файберов в JS ❌
На больших объёмах всё встаёт колом ❌
Оптимизация инструментов: Ленивый рендеринг
Вообще, изначально в $mol у нас был так называемый ленивый рендер. Суть его в том, что мы сначала рендерим первый экран и по мере прокрутки добавляем столько контента снизу, чтобы видимая область была гарантированно накрыта. А при прокрутке вверх, наоборот, удаляем снизу тот контент, что гарантированно на экран не попадает, чтобы минимизировать размер DOM для лучшей отзывчивости.
https://nin-jin.github.io/my_gitlab/#lazy=true
Достоинства ленивого рендеринга
Чтобы понимать сколько рендерить элементов, необходимо знать заранее минимальные размеры элементов, которые мы ещё не отрендерили. Но это решаемая проблема. А вот другая — не очень. Хоть появляется первая страница и быстро, но по мере прокрутки вниз увеличивается размер DOM, что неизбежно приводит к снижению отзывчивости. Так что если пользователь домотал до самого низа, то нам всё равно придётся отрендерить весь DOM целиком. То есть проблема отзывчивости решена не полностью.
Размеры элементов должны быть предсказуемы ❌
Увеличение тормозов по мере прокрутки ❌
Быстрое появление ✅
Оптимизация инструментов: Виртуальный рендеринг
Дальнейшее развитие ленивого рендера — это при прокрутке не только добавлять контент снизу, но и удалять сверху. И наоборот при прокрутке вверх. В примере, вы можете заметить, что это работает не только с плоскими списками, но и с вёрсткой произвольной сложности.
https://nin-jin.github.io/my_gitlab/
Достоинства виртуального рендеринга
Размеры элементов должны быть предсказуемы ❌
Работает, наконец, быстро ✅
Оптимизация инструментов: Резюме
На уровне инструментов поддержка сейчас есть лишь в полутора фреймворках: time slicing в React, прогрессивный рендер в catberry и виртуальный рендер в $mol. Зато, такую оптимизацию инструмента достатоxно реализовать один раз? и далее наслаждаться ею во всех своих приложениях не тратя дополнительное время на оптимизацию.
Поддерживает полтора фреймворка ❌
Работает само по себе ✅
Оптимизации: Резюме
Так что именно на оптимизации инструментов я и предлагаю вам сконцентрировать свои усилия. И далее мы разберём, что нужно для добавления виртуализации на уровне фреймворка.
Оптимизация | Стоит того? |
|---|---|
Вёрстка | ❌ |
Прикладной код | ❌ |
Инструментарий | ✅ |
Виртуализация браузера
Самое простое, что можно сделать, — это воспользоваться браузерной виртуализацией, которая появилась сравнительно недавно. Итак, открываем гитлаб и видим как всё лагает при движении мыши и вводе текста. Теперь произносим пару волшебных слов в девтулзах вокруг стилей «файла»…
content-visibility: auto;
contain-intrinsic-size: 1000px;И всё начинает летать. Устанавливая эти свойства, мы говорим браузеру, что он может пересчитывать layout только для видимой части, а для не видимой он будет брать ту оценку, что мы предоставили. Тут есть, конечно же, ограничение из-за которого иконка добавления нового комментария обрезается, но это решаемая проблема. А вот нерешаемая — это то, что нам всё-равно нужно потратить кучу времени на формирование огромного DOM. То есть таким образом мы можем обеспечить хорошую отзывчивость, но не быстрое открытие. Поэтому мы реализуем виртуализацию именно на стороне яваскрипта.
Логика рендеринга
Для каждого компонента нам нужно получить следующие данные.

Во первых нужно пройтись по всем вложенным компонентом и узнать их оценку размеров. Так же нам нужно спросить у браузера как компонент расположен относительно вьюпорта. Использую эту информацию мы можем рассчитать какие элементы нашего контейнера попадают в видимую область, а какие не попадают. После чего добавить/удалить элементы в DOM. И, на конец, обновить отступы, чтобы не полностью отрендеренный контент сместить в видимую область. И все эти операции повторяются рекурсивно для всех компонентов.
Далее мы пройдёмся по этим шагам подробнее.
Оценка размеров
Мы можем брать в качестве оценки, например, последний вычисленный размер. То есть при рендере запоминаем какой получился размер и далее используем эту информацию уже до рендера. Но тут такая проблема, что это не работает для тех элементов, которых мы ещё рендерили. При плавном скроллинге — ничего страшного, но когда пользователь хватает скроллбар и тащит в другой конец страницы, нам не от куда взять информацию о размерах. Но самое страшное даже не это, а то, что нужно уметь вовремя инвалидировать кеш размеров, ведь они зависят от очень многих факторов, которые очень сложно все учесть.
Можно попробовать брать усреднённое значение. То есть мы отрендерили, например, пять элементов из тысячи, вычислили среднее, и считаем что все остальные тоже в среднем такие же. Но это средняя температура по больнице получается, ибо в общем случае размеры элементов могут отличаться на несколько порядков. Среднее значение годится лишь в частном случае плоских виртуализированных списков, когда нам заранее известно, что все элементы примерно одинакового размера. В общем же случае, для виртуализации на уровне фреймворка это совсем не подходит.
Так что самое оптимальное — это минимальная оценка. То есть сколько элемент точно занимает места. Он может быть больше, но точно не меньше. Это позволяет для заданной видимой области рассчитать сколько нам нужно отрендерить элементов, чтобы точно накопить суммарной высоты больше, чем размер видимой области. Отрендерим чуть больше — ничего страшного. Важно лишь, что видимой области не будет дырок и пользователь не увидит, что мы немного сэкономили на рендеринге.
Последняя ❌
Усреднённая ❌
Минимальная ✅
Типы компонент: Атомарный
Теперь о том как рассчитать размеры. Во первых мы можем просто напрямую задать эти размеры.
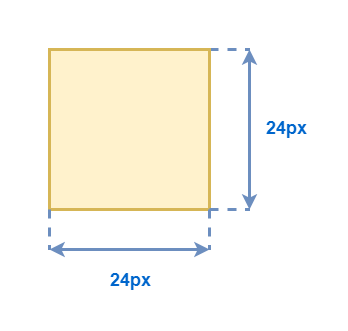
Например, допустим все иконки у нас умеют размер 24×24, или любая строка текста имеет минимальную высоту в 24 пикселя.
Типы компонент: Стек наложения
Если компонент составной, то нам скорее всего хочется, чтобы его оценка размера исходила из того, что мы поместили внутри него. Например, возьмём компонент «стек наложения» — этот компонент, который содержит другие компоненты, которые накладываются друг на друга, и его размер определяется максимальными габаритами среди всех вложенных в него элементов.

Соответственно мы просто берём максимальное значение минимального значения его элементов по соответствующим осям.
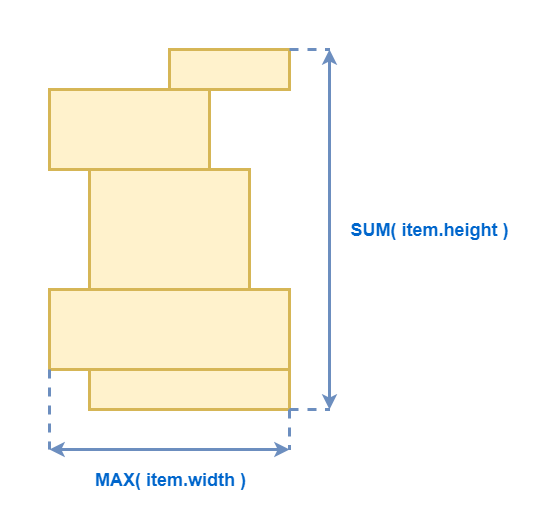
Типы компонент: Вертикальный список
Для вертикального списка по горизонтали вычисляем так же, как для стека наложения. А вот минимальная высота списка равна сумме минимальных высот его элементов.
Типы компонент: Горизонтальный список
С горизонтальным списком всё аналогично, но возможно вам ещё потребуется учитывать смещение элементов относительно базовой линии, для вычисления минимальной высоты.
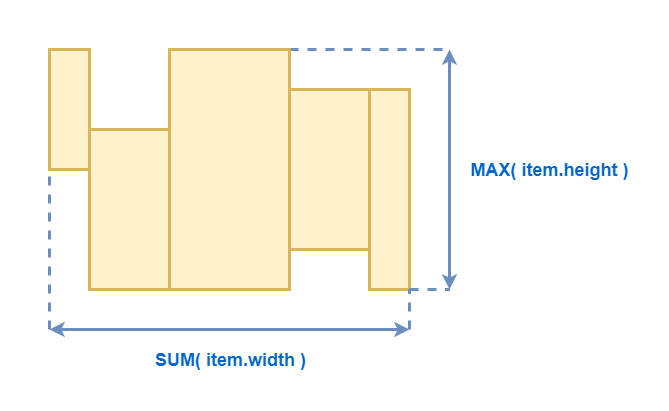
Типы компонент: Горизонтальный список с переносами
А вот с горизонтальным списком с переносами все несколько сложнее. Во первых нам нужно вычислить максимальную ширину нашего контейнера. Самая грубая оценка — это, например, ширина окна. Если у вас есть более точная оценка — замечательно. Но даже грубая оценка — лучше, чем ничего.
Далее мы берём все компоненты все вложенные компоненты и рассчитываем их суммарную ширину. Поделив одно значение на другое, мы получаем количество строк, которые точно будут в нашем списке с переносами.
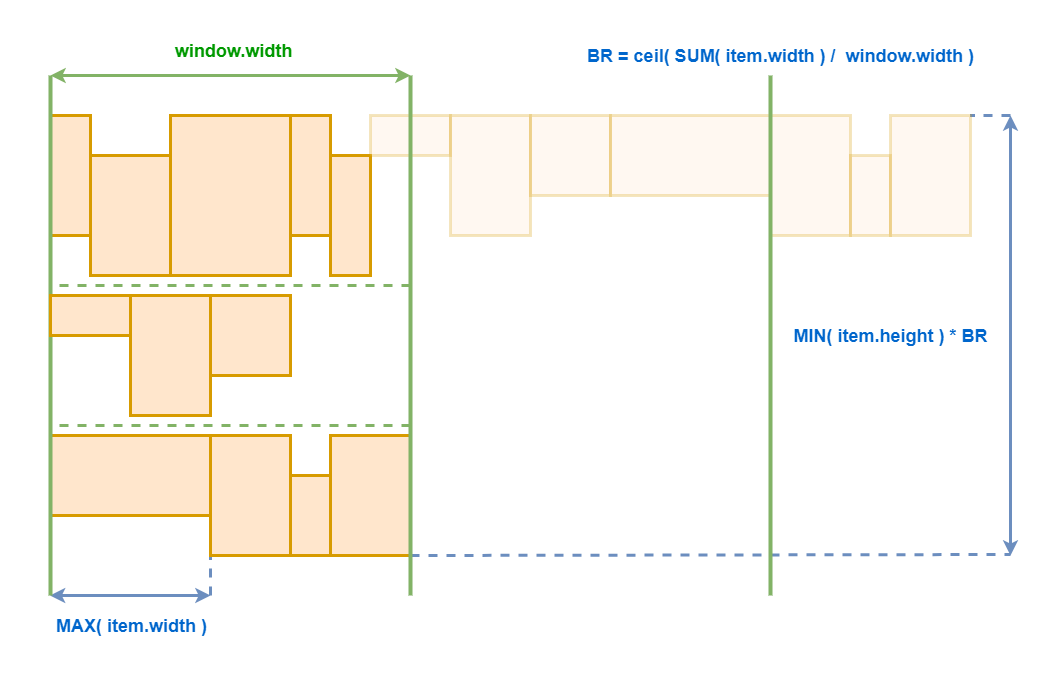
В данном примере у нас будет два переноса, а следовательно после рендеринга он расползётся не менее чем три строки.
Далее, нам нужно рассчитать минимальную высоту строки. Это просто минимальное значение среди всех минимальных высот всех элементов. Так как мы не знаем места переносов, то более точно вычислить размеры строк не получится. Но нам важно, чтобы это значение было хотя бы не нулевым, чтобы виртуализация вообще работала. Умножая высоту строки на количество строк мы получаем минимально высоту всего компонента.
К сожалению, полную виртуализацию такого компонента сделать скорее невозможно, потому что не известно в каких местах произойдёт перенос. И если мы будем виртуализировать в обе стороны, то элементы будут скакать по горизонтали. Поэтому для таких компонент применим лишь ленивый рендеринг. То есть снизу добавляем и удаляем элементы, а сверху ничего не меняем.
Типы компонент: Грид и Буклет
Такие компоненты, как гриды и буклеты, — это просто композиция упомянутых ранее.

Грид — это вертикальный список из горизонтальных списков. А буклет — это горизонтальный список из вертикальных списков.
Типы компонент: Резюме
Итого, мы получаем 4 вида лейаутов, которые позволяют построить интерфейс любой сложности.
Атомарный
Стек наложения
Вертикальный список
Горизонтальный список
Но тут важно обратить внимание на то, что любой наш компонент должен быть одного из этих четырёх типов лейаута, иначе мы не сможем правильно оценивать размер. Эта информация должна быть задана в JS, а не определяться отдельно стилями.
Отслеживание положения: onScroll
Теперь перейдем к вопросу о том, когда производить обновление DOM. Самое очевидное — это реагировать на событие scroll…
document.addEventListener( 'scroll', event => {
// few times per frame
}, { capture: true } )Достоинства отслеживания onScroll
Тут есть 2 проблемы. Во первых, событие возникает слишком часто — его нет смысла обрабатывать чаще, чем 60 раз в секунду. Во вторых, размер и положение элемента относительно вьюпорта зависит от от многих вещей, а не только от позиции скроллбара. Учитывать все это в принципе можно, но очень легко что-то пропустить и не обновить DOM. В результате, пользователь может столкнуться с ситуацией, что он видит лишь половину страницы, но не имеет никакой возможности вызвать её дорендер даже вручную.
Слишком часто ❌
Изменения DOM ❌
Изменения стилей ❌
Изменения состояния элементов ❌
Изменения состояния браузера ❌
Отслеживание положения: IntersectionObserver
Может показаться что IntersectionObserver решит все наши проблемы, ведь он позволяет детектировать, когда пара элементов начинает или перестаёт визуально пересекаться. Точнее, когда изменяется процент их пересечения. Если растянуть body на размер вьюпорта, то таким образом можно отслеживать процент пересечения любого элемента с видимой областью.
const observer = new IntersectionObserver(
event => {
// calls on change of visibility percentage
// doesn't call when visibility percentage doesn't changed
},
{ root: document.body }
)
observer.observe( watched_element )Достоинства отслеживания IntersectionObserver
К сожалению, это не работает, когда у нас элемент выходит за границы видимой области и сверху, и снизу. При скролле, процент наложения таким образом может не меняться, а значит и событие вызваться не будет. А нам отслеживать такое перемещение все равно необходимо, чтобы понимать, что теперь нужно рендерить, например, элементы не с 5 по 10, а с 10 по 15.
Облом, если степень наложения не меняется ❌
Отслеживание положения: requestAnimationFrame
Самый простой и надёжный способ отслеживать габариты элементов — это опрос по requestAnimationFrame. Обработчик вызывается 60 раз в секунду и первое, что делает, — подписывается себя на следующий фрейм.
Важно, чтобы обработчик вызывался самым первым, чтобы никто не успел до него внести изменения в DOM. Тогда размеры и координаты элементов будут браться максимально быстро — из кеша. Поэтому, следующим шагом мы пробегаемся по всем интересным нам элементам и получаем их габариты.
И только в самом конце производим изменения DOM. Если же читать размеры элементов после любого изменения в DOM, то браузеру придётся тут же произвести относительно медленный пересчёт layout.
function tick() {
requestAnimationFrame( tick )
for( const element of watched_elements ) {
element.getBoundingClientRect()
}
render()
}Достоинства отслеживания requestAnimationFrame
Недостатком такого подхода является постоянная фоновая загрузка процессора. То есть мы тратим где-то одну-две миллисекунды на каждый фрейм. Это примерно 5% загрузка процессора на моём ноуте, что не очень много для интерфейса с которым в данный момент идёт работа. К счастью requestAnimationFrame не вызывается для фоновых вкладок, так что открытие произвольного числа вкладок не приведёт к неконтролируемому росту потребления ресурсов. Кажется это — разумная плата за простое и надёжное решение, накладывающее минимум ограничений.
Постоянная фоновая нагрузка ❌
Просто и надёжно ✅
Обновление: Резюме
onScroll ❌
IntersectionObserver ❌
requestAnimationFrame ✅
Скачки при прокрутке
Если мы все это аккуратно реализуем, то у нас получится полностью виртуальный рендеринг произвольный вёрстки. Страница открывается мгновенно. Если мотнуть в другой конец страницы — всё тоже показывается во мгновение ока.
https://nin-jin.github.io/my_gitlab/#anchoring=false
Но тут есть одна проблема. Если скроллить очень медленно, то легко заметить что контент немного скачет. Это происходит из-за несоответствия расчётной высоты элемента и фактической. И чем больше эта разница, тем сильнее будут скачки. Вплоть до невозможности пользоваться скроллом.
Привязка скролла: Предотвращает скачки
Есть классический пример демонстрирующий проблему…
https://codepen.io/chriscoyier/embed/oWgENp? theme-id=dark&default-tab=result
Справа у нас есть некоторый контент. После того как мы проскроллим, сверху добавляется куча дополнительных боков. Эти блоки смещают контент вниз, из-за чего он улетает из видимой области. Вроде бы логично, но нифига не удобно для пользователя.
Слева же применяется новая браузерная фича, которая привязывает скроллбар к видимой области. И после добавления блоков сверху, браузер автоматически смещает скроллбар вниз, чтобы видимый контент остался на месте.
Привязка скролла: Выбор точки привязки
Чтобы выбрать элемент для привязки скролла, браузер идёт по DOM от корня в поисках первого же элемента, попадающего в видимую область. Заходит в него и снова ищет первый попавшийся. И так далее. При этом совершенно не важно как элементы друг относительно друга расположены визуально. Важно лишь расположение их в доме и попадают ли они в видимую область. Разберём этот процесс на простом примере…

Элемент 1 не видим, поэтому пропускаем. 2 видим, так что заходим в него. Тут и 2.2, и 2.3 видимы, поэтому заходим в первый. Далее ближайший видимый 2.2.2, внутри которых видимых больше нет, так что именно этот элемент становится якорем для привязки скролла. Браузер запоминает смещение верхней границы якорного элемента относительно вьюпорта и старается его сохранить постоянным.
Привязка скролла: Подавление привязки
Тут есть один нюанс — якорным элементом может быть только такой, для которого и для всех предков которого не запрещена привязка скролла. То есть элементы с запрещённой привязкой просто перескакиваются в поиске якорного элемента. А запрещена она может быть либо явно, через свойство overflow-anchor, либо неяв
