Архитектура современных корпоративных Node.js-приложений
Ох, не зря в названии намёк на нетленку Фаулера. И когда фронтенд-приложения успели стать настолько сложными, что мы начали рассуждать о высоких материях? Node.js… фронтенд… погодите, но Нода же на сервере, это бэкенд, а там ребята и так всё знают!
Давайте по порядку. И сразу небольшой дисклеймер: статья написана по мотивам моего выступления на Я.Субботнике Pro для фронтенд-разработчиков. Если вы занимаетесь бэкендом, то, возможно, ничего нового для себя не откроете. Здесь я попробую обобщить свой опыт фронтендера в крупном энтерпрайзе, объяснить, почему и как мы используем Node.js.
Определимся, что мы в рамках этой статьи будем считать фронтендом. Оставим в стороне споры о задачах и сконцентрируемся на сути.
Фронтенд — часть приложения, отвечающая за отображение. Он может быть разным: браузерным, десктопным, мобильным. Но всегда остаётся важная черта — фронтенду нужны данные. Без бэкенда, который эти данные предоставит, он бесполезен. Здесь и проходит достаточно чёткая граница. Бэкенд умеет ходить в базы данных, применять к полученным данным бизнес-правила и отдавать результат фронтенду, который данные примет, шаблонизирует и выдаст красоту пользователю.
Можно сказать, что концептуально бэкенд нужен фронтенду для получения и сохранения данных. Пример: типичный современный сайт с клиент-серверной архитектурой. Клиент в браузере (назвать его тонким язык уже не повернётся) стучится на сервер, где крутится бэкенд. И, конечно, везде есть исключения. Есть сложные браузерные приложения, которым не нужен сервер (этот случай мы не будем рассматривать), и есть необходимость исполнения фронтенда на сервере — то, что называется Server Side Rendering или SSR. Давайте с него и начнём, потому что это самый простой и понятный случай.
SSR
Идеальный мир для бэкенда выглядит примерно так: на вход приложения поступают HTTP-запросы с данными, на выходе мы имеем ответ с новыми данными в удобном формате. Например, JSON. HTTP API легко тестировать, понятно, как разрабатывать. Однако жизнь вносит коррективы: иногда одного API недостаточно.
Сервер должен отвечать готовым HTML, чтобы скормить его краулеру поисковой системы, отдать превью с метатегами для вставки в социальную сеть или, что ещё важнее, ускорить ответ на слабых устройствах. Совсем как в древние времена, когда мы разрабатывали Web 2.0 на PHP.
Всё знакомо и давно описано, но клиент изменился — в него пришли императивные клиентские шаблонизаторы. В современном вебе бал правит JSX, о плюсах и минусах которого можно рассуждать долго, вот только одно отрицать нельзя — в серверном рендеринге не обойтись без JavaScript-кода.
Получается, когда нужна реализация SSR силами бэкенд-разработки:
- Смешиваются зоны ответственности. Бэкенд-программисты начинают отвечать за отображение.
- Смешиваются языки. Бэкенд-программисты начинают работать с JavaScript.
Выход — отделить SSR от бэкенда. В простейшем случае мы берём JavaScript runtime, ставим на него самописное решение или фреймворк (Next, Nuxt и т.д.), работающий с нужным нам JavaScript-шаблонизатором, и пропускаем через него трафик. Привычная схема в современном мире.
Так мы уже немножко пустили фронтенд-разработчиков на сервер. Давайте перейдём к более важной проблеме.
Получение данных
Популярное решение — создание универсальных API. Эту роль чаще всего берёт на себя API Gateway, умеющий опрашивать множество микросервисов. Однако здесь тоже возникают проблемы.
Во-первых, проблема команд и зон ответственности. Современное большое приложение разрабатывают множество команд. Каждая команда сконцентрирована на своём бизнес-домене, имеет свой микросервис (или даже несколько) на бэкенде и свои отображения на клиенте. Не будем вдаваться в проблему микрофронтендов и модульности, это отдельная сложная тема. Предположим, что клиентские отображения полностью разделены и являются мини-SPA (Single Page Application) в рамках одного большого сайта.
В каждой команде есть фронтенд и бэкенд-разработчики. Каждый работает над своим приложением. API Gateway может стать камнем преткновения. Кто за него отвечает? Кто будет добавлять новые эндпоинты? Отдельная суперкоманда API, которая будет вечно занята, решая проблемы всех остальных на проекте? Какова будет цена ошибки? Падение этого шлюза положит всю систему целиком.
Во-вторых, проблема избыточных/недостаточных данных. Давайте посмотрим, что происходит, когда два разных фронтенда используют один универсальный API.
Эти два фронтенда сильно отличаются. Им нужны разные наборы данных, у них разный релизный цикл. Вариативность версий мобильного фронтенда максимальна, поэтому мы вынуждены проектировать API с максимальной обратной совместимостью. Вариативность веб-клиента низка, фактически мы должны поддерживать только одну предыдущую версию, чтобы снизить количество ошибок в момент релиза. Но даже если «универсальный» API обслуживает только веб-клиентов, мы всё равно столкнёмся с проблемой избыточных или недостаточных данных.

Каждому отображению требуется отдельный набор данных, вытащить который желательно одним оптимальным запросом.
В таком случае нам не подойдёт универсальный API, придётся разделить интерфейсы. Значит, потребуется свой API Gateway под каждый фронтенд. Слово «каждый» здесь обозначает уникальное отображение, работающее со своим набором данных.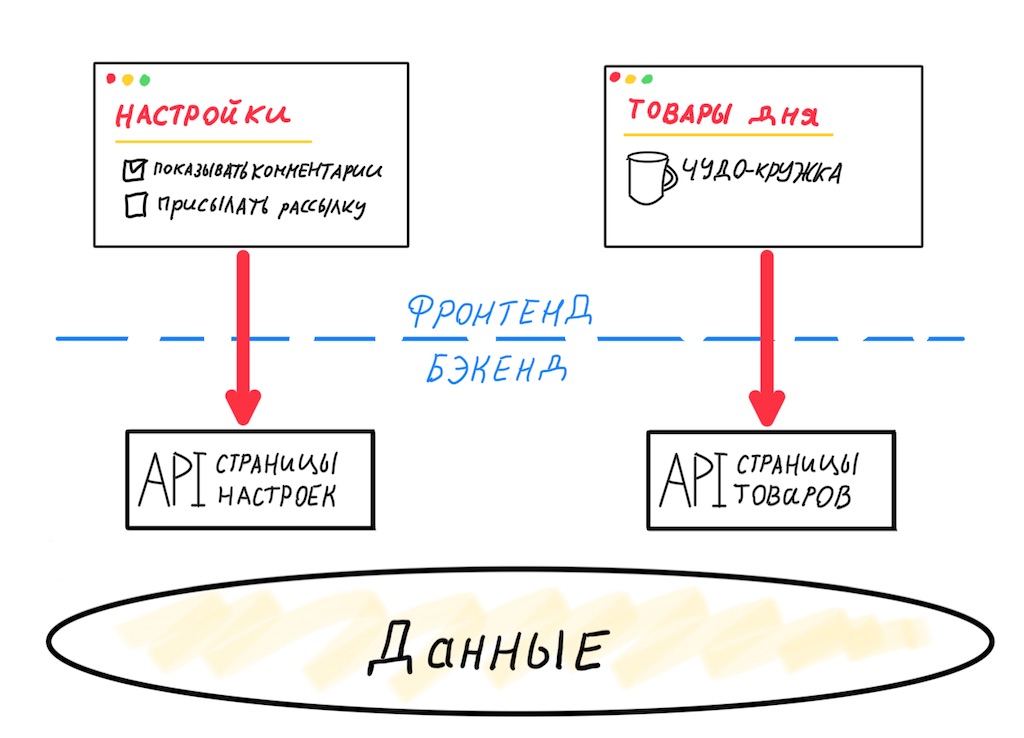
Мы можем поручить создание такого API бэкенд-разработчику, которому придётся работать с фронтендером и реализовывать его хотелки, либо, что гораздо интереснее и во многом эффективнее, отдать реализацию API команде фронтенда. Это снимет головную боль из-за реализации SSR: уже не нужно ставить прослойку, которая стучится в API, всё будет интегрировано в одно серверное приложение. К тому же, контролируя SSR, мы можем положить все необходимые первичные данные на страницу в момент рендера, не делая дополнительных запросов на сервер.
Такая архитектура называется Backend For Frontend или BFF. Идея проста: на сервере появляется новое приложение, которое слушает запросы клиента, опрашивает бэкенды и возвращает оптимальный ответ. И, конечно же, это приложение контролирует фронтенд-разработчик.

Больше одного сервера в бэкенде? Не проблема! 
Независимо от того, какой протокол общения предпочитает бэкенд-разработка, мы можем использовать любой удобный способ общения с веб-клиентом. REST, RPC, GraphQL — выбираем сами.
Но разве GraphQL сам по себе не является решением проблемы получения данных одним запросом? Может, не нужно никакие промежуточные сервисы городить?
К сожалению, эффективная работа с GraphQL невозможна без тесного сотрудничества с бэкендерами, которые берут на себя разработку эффективных запросов к базе данных. Выбрав такое решение, мы снова потеряем контроль над данными и вернёмся к тому, с чего начинали. 
Можно, конечно, но неинтересно (для фронтендера)
Что же, давайте реализовывать BFF. Конечно, на Node.js. Почему? Нам нужен единый язык на клиенте и сервере для переиспользования опыта фронтенд-разработчиков и JavaScript для работы с шаблонами. А как насчёт других сред исполнения?

GraalVM и прочие экзотические решения проигрывают V8 в производительности и слишком специфичны. Deno пока остаётся экспериментом и не используется в продакшене.
И ещё один момент. Node.js — удивительно хорошее решение для реализации API Gateway. Архитектура Ноды позволяет использовать однопоточный интерпретатор JavaScript, объединённый с libuv, библиотекой асинхронного I/O, которая, в свою очередь, использует тред-пул.
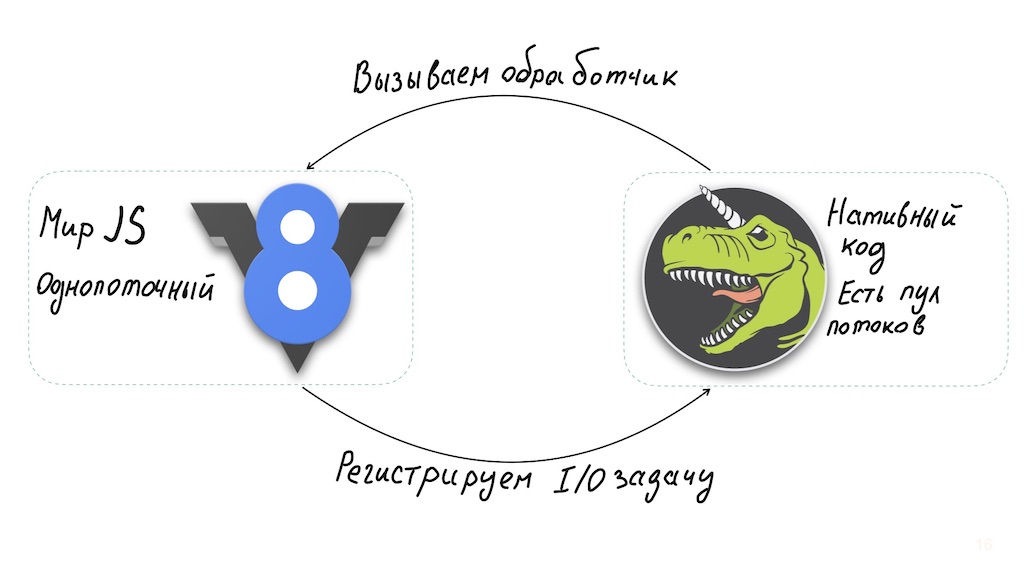
Долгие вычисления на стороне JavaScript бьют по производительности системы. Обойти это можно: запускать их в отдельных воркерах или уносить на уровень нативных бинарных модулей.
Но в базовом случае Node.js не подходит для операций, нагружающих CPU, и в то же время отлично работает с асинхронным вводом/выводом, обеспечивая высокую производительность. То есть мы получаем систему, которая сможет всегда быстро отвечать пользователю, независимо от того, насколько нагружен вычислениями бэкенд. Обработать эту ситуацию можно, мгновенно уведомляя пользователя о необходимости подождать окончания операции.
Где хранить бизнес-логику
В нашей системе теперь три большие части: бэкенд, фронтенд и BFF между ними. Возникает резонный (для архитектора) вопрос: где же держать бизнес-логику? 
Конечно, архитектор не хочет размазывать бизнес-правила по всем слоям системы, источник правды должен быть один. И этот источник — бэкенд. Где ещё хранить высокоуровневые политики, как не в наиболее близкой к данным части системы?

Но в реальности это не всегда работает. Например, приходит бизнес-задача, которую можно эффективно и быстро реализовать на уровне BFF. Идеальный дизайн системы это классно, но время — деньги. Иногда приходится жертвовать чистотой архитектуры, а слои начинают протекать.
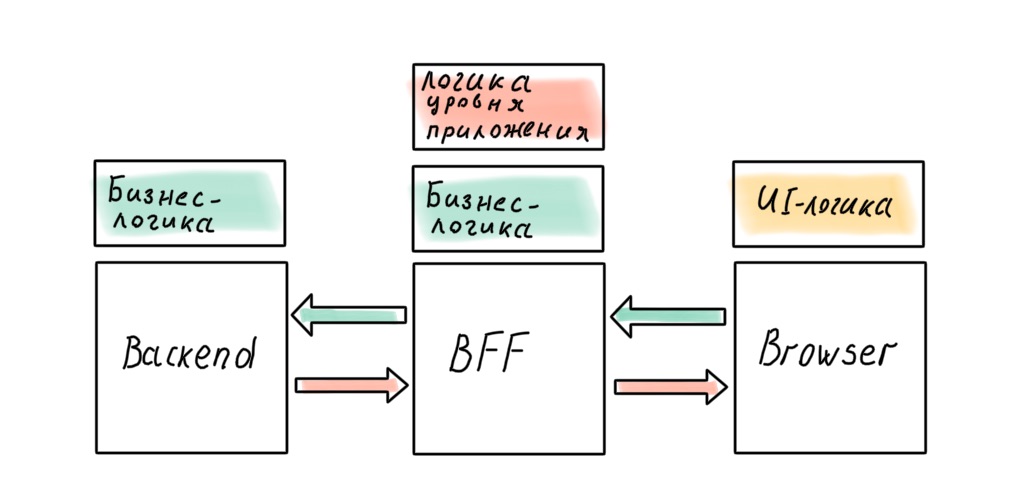
Можем ли мы получить идеальную архитектуру, отказавшись от BFF в пользу «полноценного» бэкенда на Node.js? Кажется, в этом случае не будет протечек.
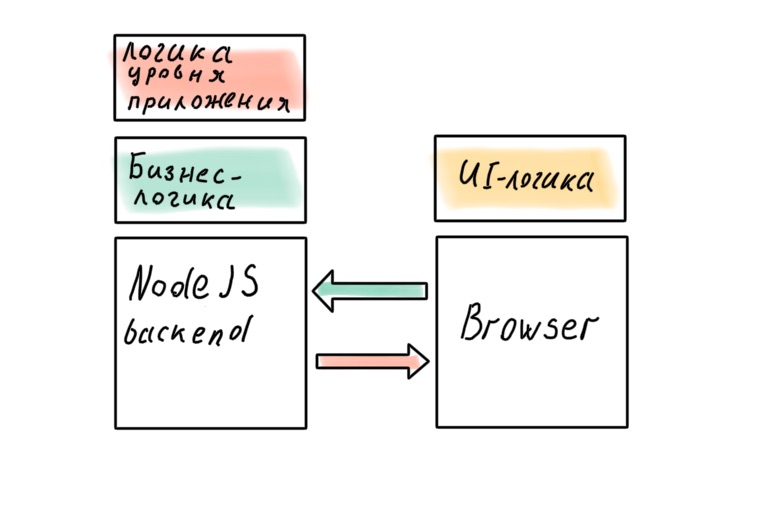
Не факт. Найдутся бизнес-правила, перенос которых на сервер ударит по отзывчивости интерфейса. Можно до последнего сопротивляться этому, но избежать полностью, скорее всего, не получится. Логика уровня приложения тоже проникнет на клиент: в современных SPA она размазана между клиентом и сервером даже случае, когда есть BFF.
Как бы мы ни старались, бизнес-логика проникнет в API Gateway на Node.js. Зафиксируем этот вывод и перейдём к самому вкусному — имплементации!
Big Ball of Mud
Самое популярное решение для Node.js-приложений в последние годы — Express. Проверенное, но уж больно низкоуровневое и не предлагающее хороших архитектурных подходов. Основной паттерн — middleware. Типичное приложение на Express напоминает большой комок грязи (это не обзывательство, а антипаттерн).
const express = require('express');
const app = express();
const {createReadStream} = require('fs');
const path = require('path');
const Joi = require('joi');
app.use(express.json());
const schema = {id: Joi.number().required() };
app.get('/example/:id', (req, res) => {
const result = Joi.validate(req.params, schema);
if (result.error) {
res.status(400).send(result.error.toString()).end();
return;
}
const stream = createReadStream( path.join('..', path.sep, `example${req.params.id}.js`));
stream
.on('open', () => {stream.pipe(res)})
.on('error', (error) => {res.end(error.toString())})
});
Все слои перемешаны, в одном файле находится контроллер, где есть всё: инфраструктурная логика, валидация, бизнес-логика. Работать с этим больно, поддерживать такой код не хочется. А можем ли мы писать на Node.js код энтерпрайз-уровня? 
Для этого требуется кодовая база, которую легко поддерживать и развивать. Иначе говоря, нужна архитектура.
Архитектура Node.js-приложения (наконец-то)
«Цель архитектуры программного обеспечения — уменьшить человеческие трудозатраты на создание и сопровождение системы».Роберт «Дядя Боб» Мартин
Архитектура состоит из двух важных вещей: слоёв и связей между ними. Мы должны разбить наше приложение на слои, не допустить протечек из одного в другой, правильно организовать иерархию слоёв и связи между ними.
Слои
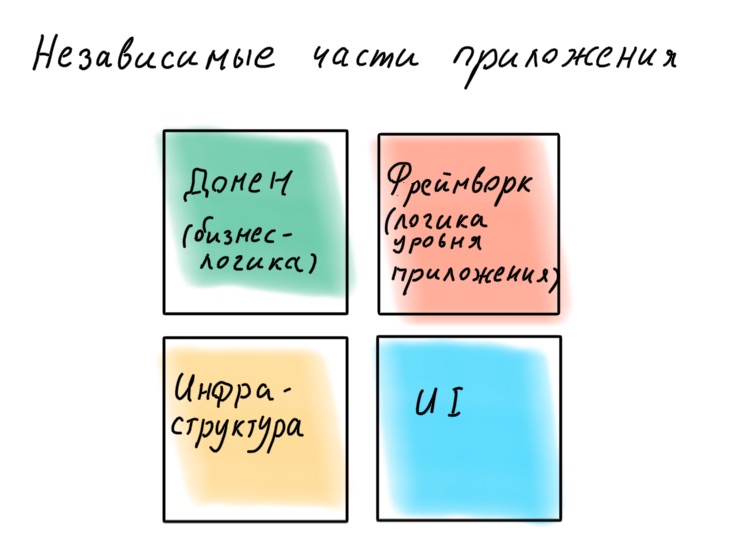
Как разбить приложение на слои? Есть классический трёхуровневый подход: данные, логика, представление.
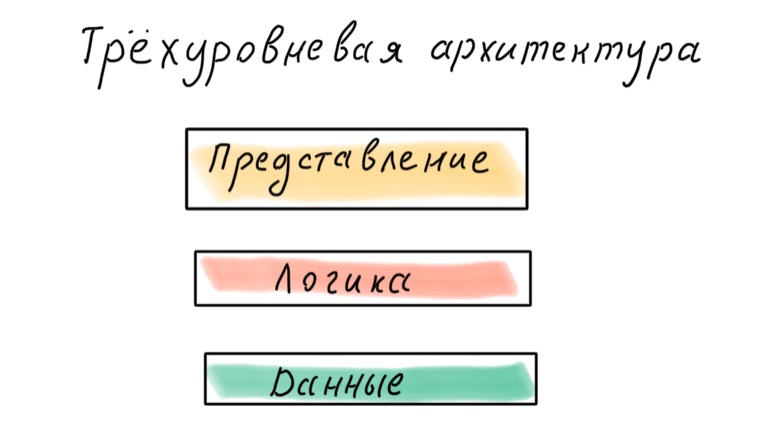
Сейчас такой подход считается устаревшим. Проблема в том, что основой являются данные, а значит, приложение проектируется в зависимости от того, как данные представлены в БД, а не от того, в каких бизнес-процессах они участвуют.
Более современный подход предполагает, что в приложении выделен доменный слой, который работает с бизнес-логикой и является представлением реальных бизнес-процессов в коде. Однако если мы обратимся к классическому труду Эрика Эванса Domain-Driven Design, то обнаружим там такую схему слоёв приложения: 
Что здесь не так? Казалось бы, основой приложения, спроектированного по DDD, должен быть домен — высокоуровневые политики, самая важная и ценная логика. Но под этим слоем лежит вся инфраструктура: слой доступа к данным (DAL), логирование, мониторинг, и т. д. То есть политики гораздо более низкого уровня и меньшей важности.
Инфраструктура оказывается в центре приложения, и банальная замена логгера может привести к перетряхиванию всей бизнес-логики.
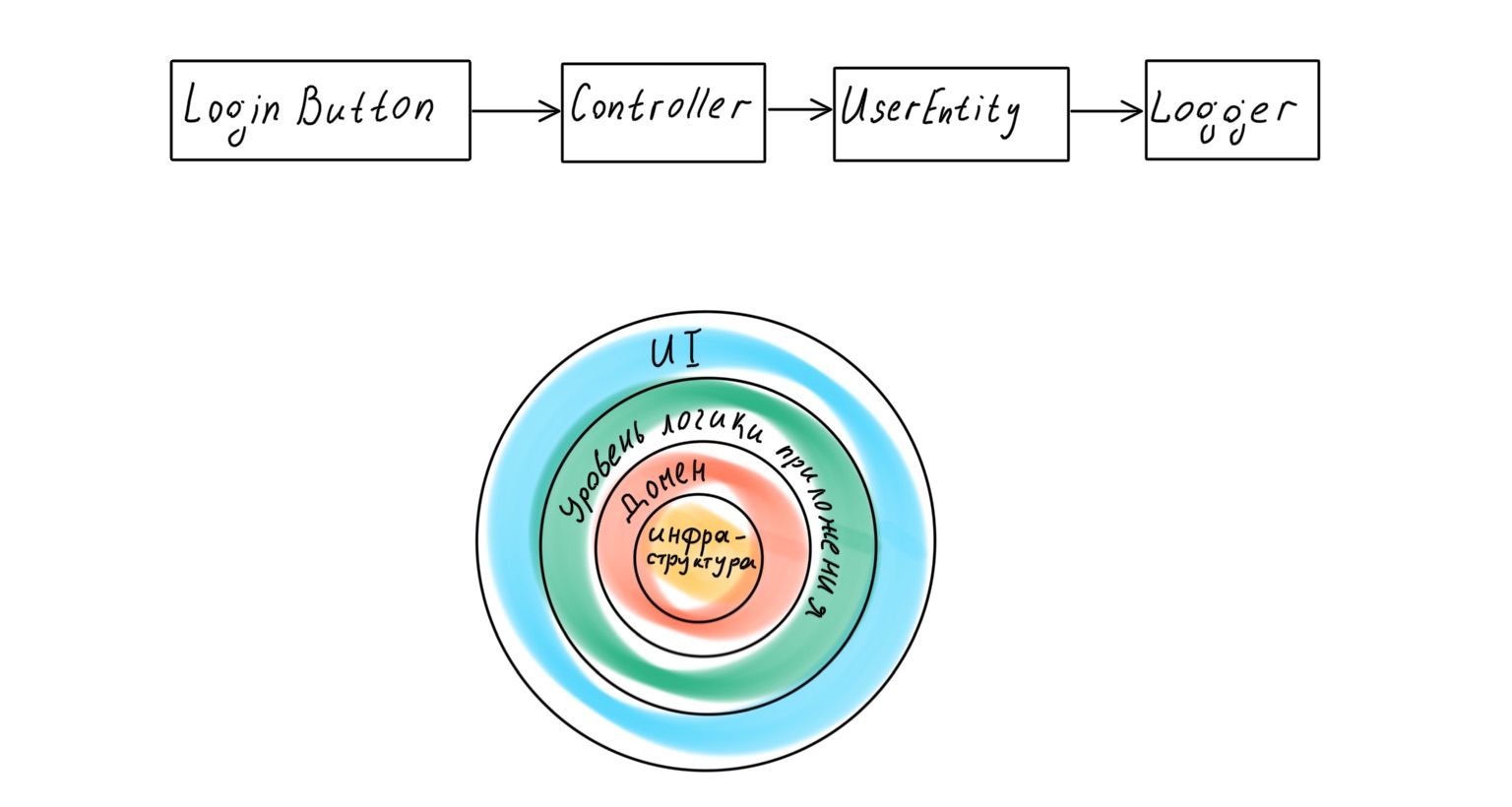
Если мы снова обратимся к Роберту Мартину, то обнаружим, что в книге Clean Architecture он постулирует иную иерархию слоёв в приложении, с доменом в центре.
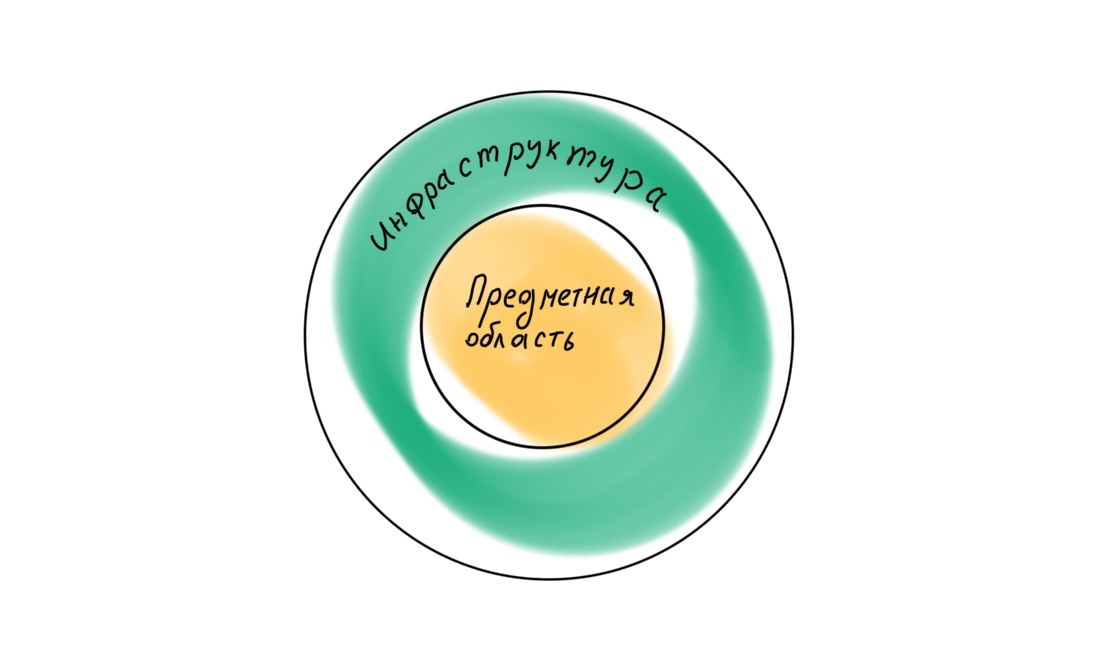
Соответственно, все четыре слоя должны располагаться иначе:
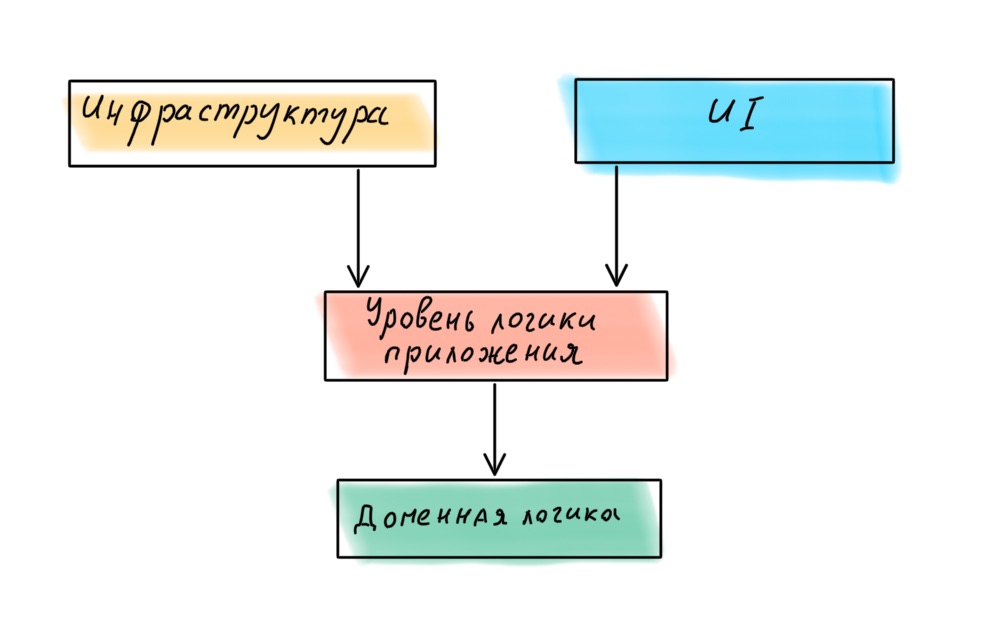
Мы выделили слои и определили их иерархию. Теперь перейдём к связям.
Связи
Вернёмся к примеру с вызовом логики пользователя. Как избавиться от прямой зависимости от инфраструктуры, чтобы обеспечить правильную иерархию слоёв? Есть простой и давно известный способ разворота зависимостей — интерфейсы.
Теперь высокоуровневый UserEntity не зависит от низкоуровневого Logger. Наоборот, он диктует контракт, который нужно реализовать, чтобы включить Logger в систему. Замена логгера в данном случае сводится к подключению новой реализации, соблюдающей тот же контракт. Важный вопрос — как её подключать?
import {Logger} from ‘../core/logger’;
class UserEntity {
private _logger: Logger;
constructor() {
this._logger = new Logger();
}
...
}
...
const UserEntity = new UserEntity();
Слои связаны жёстко. Есть завязка и на файловую структуру, и на реализацию. Нам нужна инверсия зависимости (Dependency Inversion), делать которую мы будем с помощью внедрения зависимости (Dependency Injection).
export class UserEntity {
constructor(private _logger: ILogger) { }
...
}
...
const logger = new Logger();
const UserEntity = new UserEntity(logger);
Теперь «доменный» UserEntity больше ничего не знает о реализации логгера. Он предоставляет контракт и ожидает, что реализация будет соответствовать этому контракту.
Конечно, ручная генерация экземпляров инфраструктурных сущностей дело не самое приятное. Нужен корневой файл, в котором мы будем всё подготавливать, придётся как-то протащить созданный экземпляр логгера через всё приложение (выгодно иметь один, а не создавать множество). Утомительно. И здесь вступают в игру IoC-контейнеры, которые могут взять на себя эту боллерплейтную работу.
Как может выглядеть использование контейнера? Например, так:
export class UserEntity {
constructor(@Inject(LOGGER) private readonly _logger: ILogger){ }
}
Что здесь происходит? Мы воспользовались магией декораторов и написали инструкцию: «При создании экземпляра UserEntity внедри в его приватное поле _logger экземпляр той сущности, что лежит в IoC-контейнере под токеном LOGGER. Ожидается, что она соответствует интерфейсу ILogger». А дальше IoC-контейнер сделает всё сам.
Мы выделили слои, определились с тем, как будем их развязывать. Пора выбрать фреймворк.
Фреймворки и архитектура
Вопрос простой: уйдя от Express на современный фреймворк, получим ли мы хорошую архитектуру? Давайте посмотрим на Nest:
- написан на TypeScript,
- построен поверх Express/Fastify, есть совместимость на уровне middleware,
- декларирует модульность логики,
- предоставляет IoC-контейнер.
Кажется, здесь есть всё, что нам нужно! Ещё и от концепции приложения как цепочки middleware ушли. Но что насчёт хорошей архитектуры?
Dependency Injection в Nest
Давайте попробуем сделать всё по инструкции. Так как в Nest термин Entity применяется обычно к ORM, переименуем UserEntity в UserService. Логгер поставляется фреймворком, поэтому вместо него заинжектируем абстрактный FooService.
import {FooService} from ‘../services/foo.service’;
@Injectable()
export class UserService {
constructor(
private readonly _fooService: FooService
){ }
}
И… кажется, мы сделали шаг назад! Инъекция есть, а инверсии нет, зависимость
направлена на реализацию, а не на абстракцию.
Давайте попробуем исправить. Вариант номер один:
@Injectable()
export class UserService {
constructor(
private _fooService: AbstractFooService
){ } }
Где-то рядом описываем и экспортируем этот абстрактный сервис:
export {AbstractFooService};
FooService теперь использует AbstractFooService. В таком виде мы регистрируем его вручную в IoC.
{ provide: AbstractFooService, useClass: FooService }
Второй вариант. Пробуем описанный ранее подход с интерфейсами. Так как в JavaScript не существует интерфейсов, вытащить требуемую сущность из IoC в рантайме, воспользовавшись рефлексией, уже не получится. Мы должны явно указать, что нам нужно. Используем для этого декоратор @Inject.
@Injectable()
export class UserService {
constructor(
@Inject(FOO_SERVICE) private readonly _fooService: IFooService
){ } }
И регистрируем по токену:
{ provide: FOO_SERVICE, useClass: FooService }
Победили фреймворк! Но какой ценой? Мы отключили довольно много сахара. Это подозрительно и наводит на мысль, что не стоит укладывать всё приложение во фреймворк. Если я вас ещё не убедил, есть и другие проблемы.
Исключения
Nest прошит исключениями. Более того, он предлагает использовать выбрасывание исключений для описания логики поведения приложения.
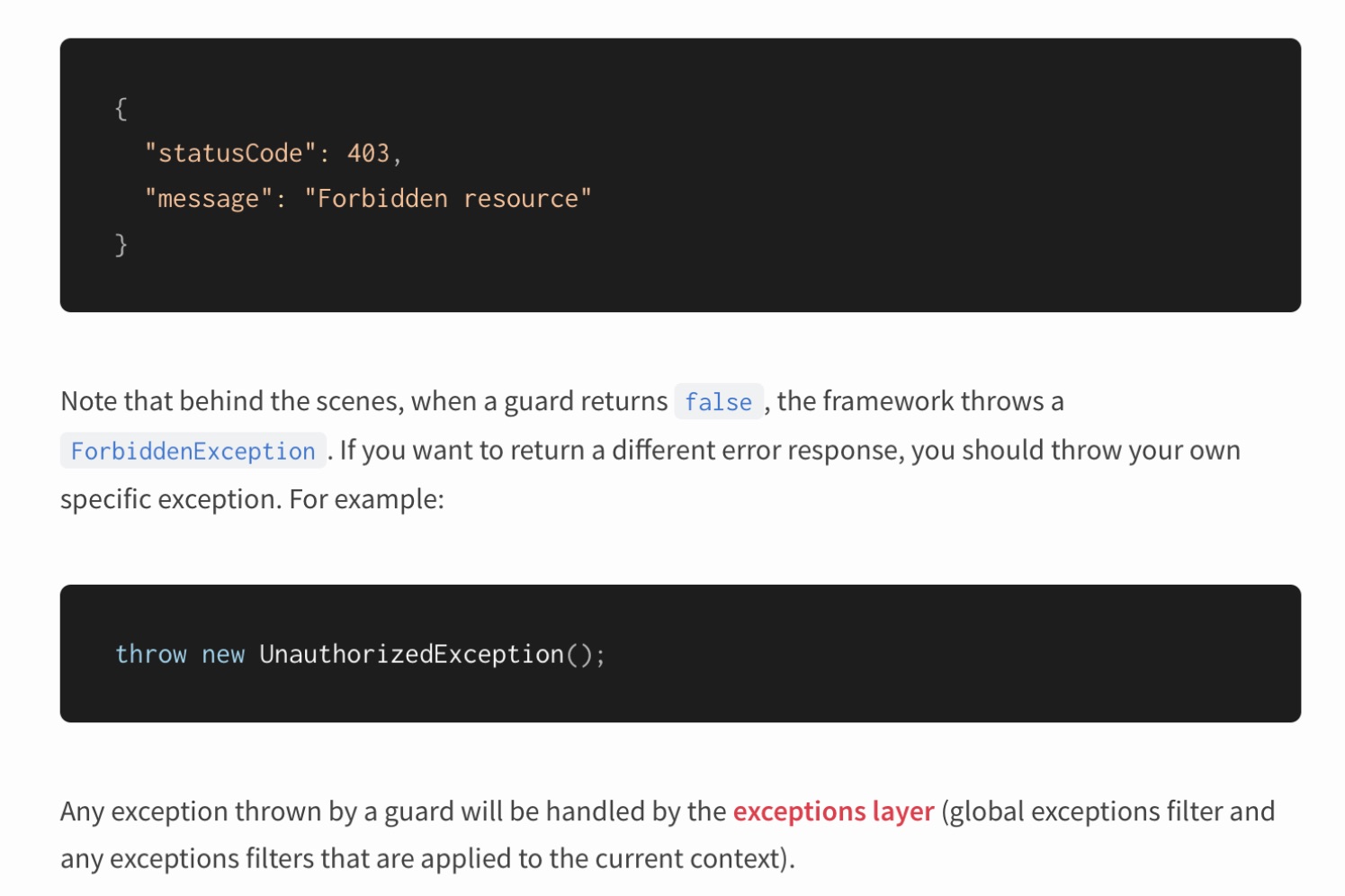
Всё ли тут в порядке с точки зрения архитектуры? Снова обратимся к корифеям:
«Если ошибка — это ожидаемое поведение, то вы не должны использовать исключения».
Мартин Фаулер
Исключения предполагают исключительную ситуацию. При написании бизнес-логики мы должны избегать выбрасывания исключений. Хотя бы по той причине, что ни JavaScript, ни TypeScript не дают гарантий, что исключение будет обработано. Более того, оно запутывает поток исполнения, мы начинаем программировать в GOTO-стиле, а значит, во время исследования поведения кода читателю придётся прыгать по всей программе.

Есть простое правило, помогающее понять, законно ли использование исключений:
«Будет ли код работать, если я удалю все обработчики исключений?» Если ответ «нет», то, возможно, исключения используются в неисключительных обстоятельствах».
The Pragmatic Programmer
Можно ли избежать этого в бизнес-логике? Да! Необходимо минимизировать выбрасывание исключений, а для удобного возврата результата сложных операций использовать монаду Either, которая предоставляет контейнер, находящийся в состоянии успеха или ошибки (концепция, очень близкая к Promise).
const successResult = Result.ok(false);
const failResult = Result.fail(new ConnectionError())
К сожалению, внутри предоставляемых Nest сущностей мы часто не можем действовать иначе — приходится выбрасывать исключения. Так устроен фреймворк, и это очень неприятная особенность. И снова возникает вопрос: может быть, не стоит прошивать приложение фреймворком? Может, получится развести фреймворк и бизнес-логику по разным архитектурным слоям?
Давайте проверим.
Сущности Nest и архитектурные слои
Суровая правда жизни: всё, что мы пишем с помощью Nest, можно уложить в один слой. Это Application Layer.
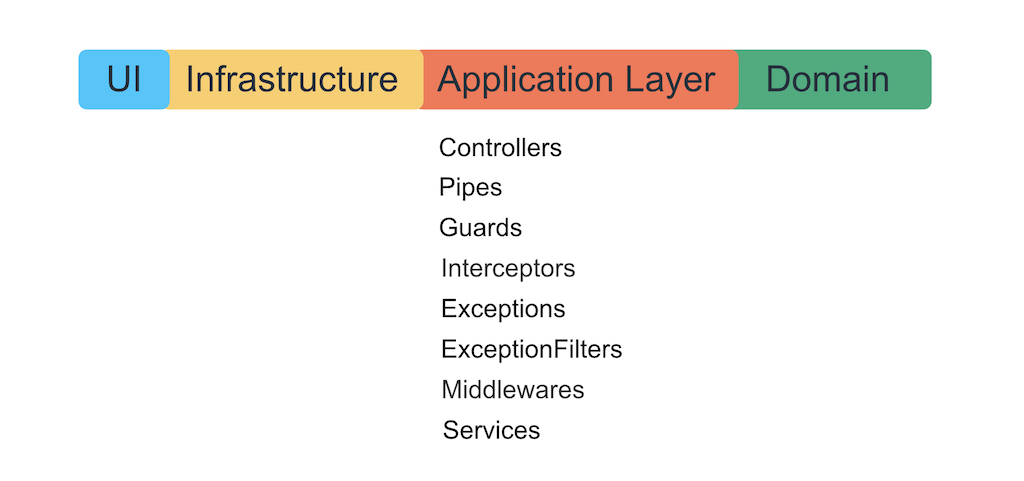
Мы не хотим пускать фреймворк глубже в бизнес-логику, чтобы он не прорастал в неё своими исключениями, декораторами и IoC-контейнером. Авторы фреймворка будут раскатывать, как здорово писать бизнес-логику, используя его сахар, но их задача — навсегда привязать вас к себе. Помните, что фреймворк — лишь способ удобно организовать логику уровня приложения, подключить к нему инфраструктуру и UI.

«Фреймворк — это деталь».
Роберт «Дядя Боб» Мартин
Приложение лучше проектировать как конструктор, в котором легко заменить составные части. Один из примеров такой реализации — гексагональная архитектура (архитектура портов и адаптеров). Идея интересна: доменное ядро со всей бизнес-логикой предоставляет порты для общения с внешним миром. Всё, что нужно, подключается снаружи через адаптеры.
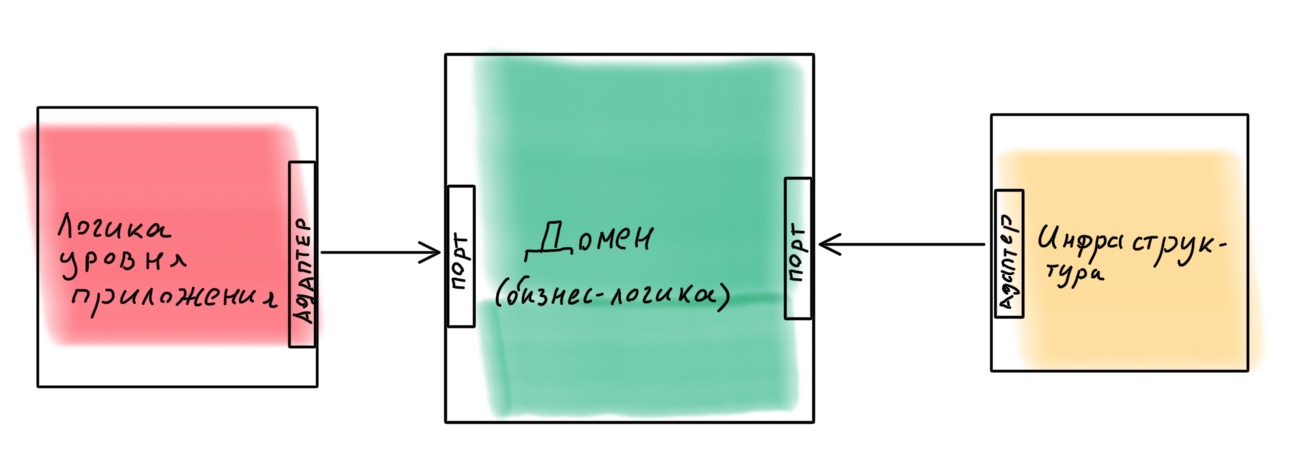
Реально ли реализовать такую архитектуру на Node.js, используя Nest как основу? Вполне. Я сделал урок с примером, если интересно — ознакомиться можно по ссылке.
Подведём итоги
- Node.js — это хорошо для BFF. С ней можно жить.
- Готовых решений нет.
- Фреймворки не важны.
- Если ваша архитектура становится слишком сложной, если вы упираетесь в типизацию — возможно, выбран не тот инструмент.
Рекомендую эти книги:
