Архитектура и возможности Tarantool Data Grid

В 2017 году мы выиграли конкурс на разработку транзакционного ядра инвестиционного бизнеса Альфа-Банка и приступили к работе (на HighLoad++ 2018 с докладом о ядре инвестиционного бизнеса выступал Владимир Дрынкин, руководитель направления транзакционного ядра инвестиционного бизнеса Альфа-банка). Эта система должна была агрегировать данные о сделках из разных источников в различных форматах, приводить данные к унифицированному виду, сохранять их и предоставлять к ним доступ.
В процессе разработки система эволюционировала и обрастала функционалом, и в какой-то момент мы поняли, что у нас кристаллизуется что-то намного большее, чем просто прикладное ПО, созданное для решения строго определенного круга задач: у нас получилась система для построения распределенных приложений с персистентным хранилищем. Полученный нами опыт лег в основу нового продукта — Tarantool Data Grid (TDG).
Я хочу рассказать об архитектуре TDG и о тех решениях, к которым мы пришли в процессе разработки, познакомить вас с основным функционалом и показать, как наш продукт может стать базой для построения законченных решений.
Архитектурно мы разделили систему на отдельные роли, каждая из которых ответственна за решение определенного круга задач. Один запущенный экземпляр приложения реализует один или несколько типов ролей. В кластере может быть несколько ролей одного типа:
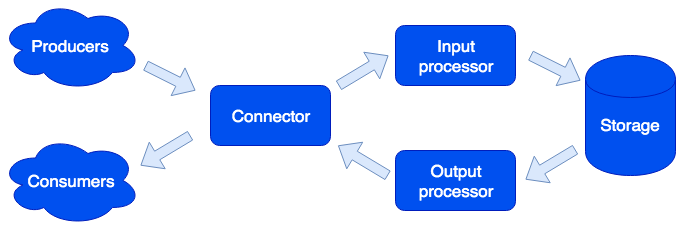
Connector
Connector отвечает за связь с внешним миром; его задача — принять запрос, распарсить его, и если это удалось, то отправить данные на обработку в input processor. Мы поддерживаем форматы HTTP, SOAP, Kafka, FIX. Архитектура позволяет просто добавлять поддержку новых форматов, скоро появится поддержка IBM MQ. Если разбор запроса завершился ошибкой, то connector вернет ошибку; в противном случае он ответит, что запрос был обработан успешно, даже если и возникла ошибка при его дальнейшей обработке. Это сделано специально, для того чтобы работать с системами, которые не умеют повторять запросы — или наоборот, делают это слишком настойчиво. Для того чтобы не терять данные, используется ремонтная очередь: объект сначала попадает в нее и только после успешной обработки удаляется из нее. Администратор может получать оповещения об объектах, оставшихся в ремонтной очереди, а после устранения программной ошибки или аппаратного сбоя выполнить повторную попытку.
Input processor
Input processor классифицирует полученные данные по характерным признакам и вызывает подходящие обработчики. Обработчики — это код на языке Lua, запускаемый в песочнице, таким образом повлиять на функционирование системы они не могут. На этом этапе данные можно привести к требуемому виду, а также при необходимости запустить произвольное количество задач, которые могут реализовывать необходимую логику. Например, в продукте MDM (Master Data Management), построенном на Tarantool Data Grid, при добавлении нового пользователя мы, чтобы не замедлять обработку запроса, создание золотой записи запускаем отдельной задачей. Песочница поддерживает запросы на чтение, изменение и добавление данных, позволяет выполнять некоторую функцию на всех ролях типа storage и агрегацию результата (map/reduce).
Обработчики могут быть описаны в файлах:
sum.lua
local x, y = unpack(...)
return x + y
И затем, объявлены в конфигурации:
functions:
sum: { __file: sum.lua }
Почему Lua? Lua очень простой язык. Исходя из нашего опыта, спустя пару часов после знакомства с ним, люди начинают писать код, решающий их задачу. И это не только профессиональные разработчики, а например, аналитики. Кроме того, благодаря jit-компилятору, Lua работает очень быстро.
Storage
Storage хранит персистентные данные. Перед сохранением данные проходят валидацию на соответствие схеме данных. Для описания схемы мы используем расширенный формат Apache Avro. Пример:
{
"name": "User",
"type": "record",
"logicalType": "Aggregate",
"fields": [
{ "name": "id", "type": "string"},
{"name": "first_name", "type": "string"},
{"name": "last_name", "type": "string"}
],
"indexes": ["id"]
}
По этому описанию автоматически генерируется DDL (Data Definition Language) для СУБД Тарантул и GraphQL схема для доступа к данным.
Поддерживается асинхронная репликация данных (в планах добавить синхронную).
Output processor
Иногда о поступлении новых данных нужно оповестить внешних потребителей, для этого существует роль Output processor. После сохранения данных, они могут быть переданы в соответствующий им обработчик (например, чтобы привести их к виду, который требует потребитель) — и после этого переданы в connector на отправку. Здесь тоже используется ремонтная очередь: если объект никто не принял, администратор может повторить попытку позже.
Масштабирование
Роли connector, input processor и output processor не имеют состояния, что позволяет нам масштабировать систему горизонтально, просто добавляя новые экземпляры приложения с включенной ролью нужного типа. Для горизонтального масштабирования storage используется подход к организации кластера с использованием виртуальных бакетов. После добавления нового сервера часть бакетов со старых серверов в фоновом режиме переезжает на новый сервер; это происходит прозрачно для пользователей и не сказывается на работе всей системы.
Свойства данных
Объекты могут быть очень большими и содержать другие объекты. Мы обеспечиваем атомарность добавления и обновления данных, сохраняя объект со всеми зависимостями на один виртуальный бакет. Таким образом исключается «размазывание» объекта по нескольким физическим серверам.
Поддерживается версионность: каждое обновление объекта создает новую версию, и мы всегда можем сделать временной срез и посмотреть, как мир выглядел тогда. Для данных, которым не нужна длинная история, мы можем ограничить количество версий или даже хранить только одну — последнюю, — то есть фактически отключить версионирование для определенного типа. Также можно ограничить историю по времени: например, удалять все объекты некоторого типа старше 1 года. Поддерживается и архивация: мы можем выгружать объекты старше указанного времени, освобождая место в кластере.
Задачи
Из интересных функций стоит отметить возможность запуска задач по расписанию, по запросу пользователя или программно из песочницы:

Здесь мы видим еще одну роль — runner. Эта роль не имеет состояния, и при необходимости в кластер можно добавить дополнительные экземпляры приложения с этой ролью. Ответственность runner — выполнение задач. Как говорилось, из песочницы возможно порождение новых задач; они сохраняются в очереди на storage и потом выполняются на runner. Этот тип задач называется Job. Также у нас есть тип задач, называемый Task — это задачи, определяемые пользователем и запускаемые по расписанию (используется синтаксис cron) или по требованию. Для запуска и отслеживания таких задач у нас есть удобный диспетчер задач. Для того чтобы данный функционал был доступен, необходимо включить роль scheduler; эта роль имеет состояние, поэтому не масштабируется, что впрочем и не требуется; при этом она, как и все остальные роли, может иметь реплику, которая начинает работать, если мастер вдруг отказал.
Logger
Еще одна роль называется logger. Она собирает логи со всех членов кластера и предоставляет интерфейс для их выгрузки и просмотра через веб-интерфейс.
Сервисы
Стоит упомянуть, что система позволяет легко создавать сервисы. В конфигурационном файле можно указать, какие запросы направлять на написанный пользователем обработчик, выполняемый в песочнице. В этом обработчике можно, например, выполнить какой-то аналитический запрос и вернуть результат.
Сервис описывается в конфигурационном файле:
services:
sum:
doc: "adds two numbers"
function: sum
return_type: int
args:
x: int
y: int
GraphQL API генерируется автоматически и сервис становится доступным для вызова:
query {
sum(x: 1, y: 2)
}
Это приведет к вызову обработчика sum, который вернет результат:
3
Профилирование запросов и метрики
Для понимания работы системы и профилирования запросов мы реализовали поддержку протокола OpenTracing. Система может по требованию отправлять информацию инструментам, поддерживающим этот протокол, например Zipkin, что позволит разобраться с тем, как выполнялся запрос:
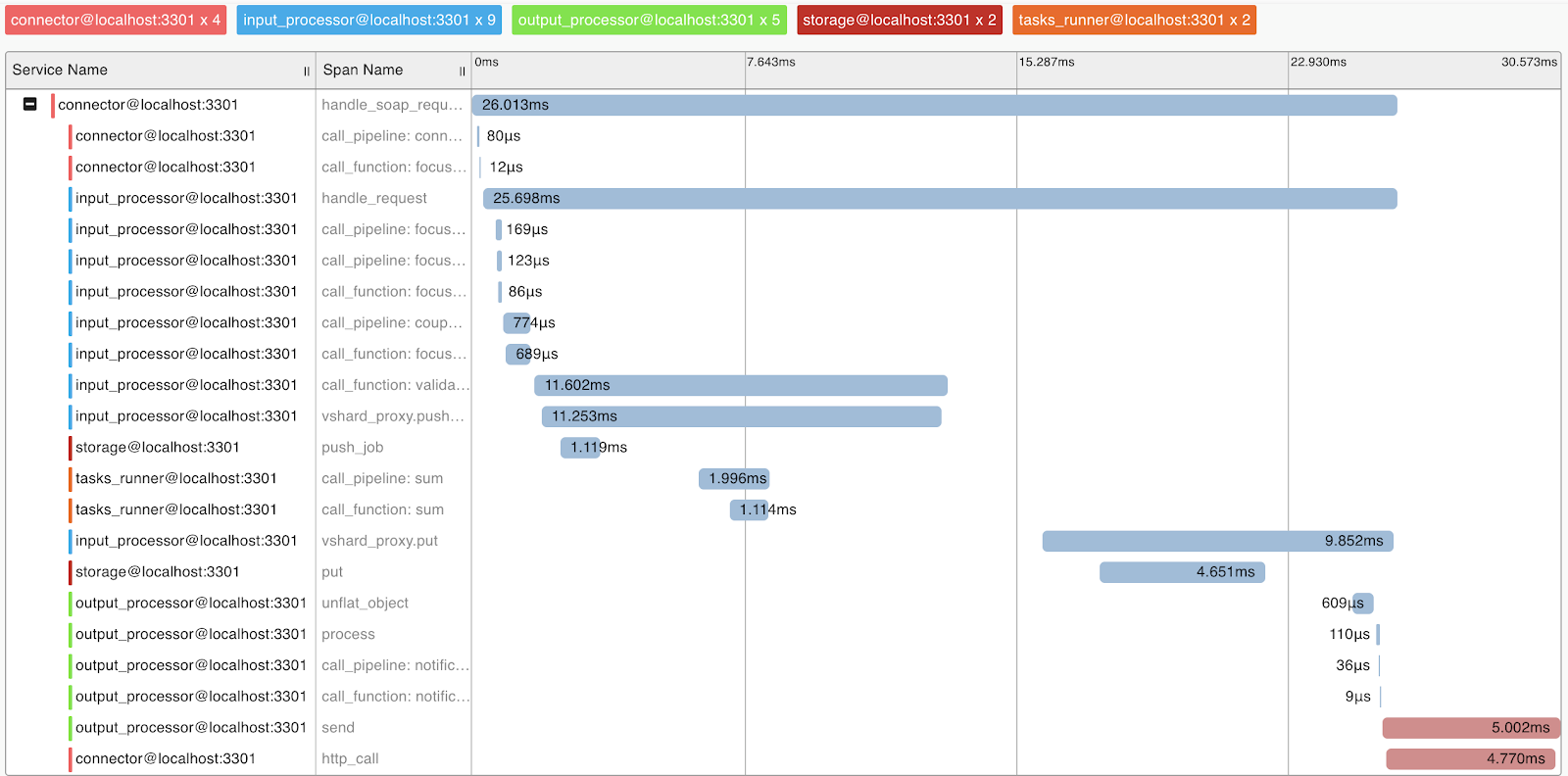
Естественно, система предоставляет внутренние метрики, которые можно собирать с помощью Prometheus и визуализировать с помощью Grafana.
Деплой
Tarantool Data Grid может быть задеплоен из RPM-пакетов или архива, с помощью утилиты из поставки или Ansible, также есть поддержка Kubernetes (Tarantool Kubernetes Operator).
Приложение реализующее бизнес логику (конфигурация, обработчики) загружаются в задеплоенный кластер Tarantool Data Grid в виде архива через UI или с помощью скрипта, через предоставленный нами API.
Примеры приложений
Какие приложения можно создать с помощью Tarantool Data Grid? На самом деле большинство бизнес-задач так или иначе связаны с обработкой потока данных, хранением и доступом к ним. Поэтому, если у вас есть большие потоки данных, которые необходимо надежно хранить и иметь к ним доступ, то наш продукт может сэкономить вам много времени на разработке и сосредоточится на своей бизнес-логике.
Например, мы хотим собирать информацию о рынке недвижимости, чтобы в последующем, например, иметь информацию о самых выгодных предложениях. В этом случае мы выделим следующие задачи:
- Роботы, собирающие информацию с открытых источников — это будут наши источники данных. Эту задачу вы можете решить, используя готовые решения или написав код на любом языке.
- Далее Tarantool Data Grid примет и сохранит данные. Если формат данных из разных источников отличается, то вы можете написать код на языке Lua, который выполнит приведение к единому формату. На этапе предварительной обработки вы также сможете, например, фильтровать повторяющиеся предложения или дополнительно обновлять в базе данных информацию об агентах, работающих на рынке.
- Сейчас у вас уже есть масштабируемое решение в кластере, которое можно наполнять данными и делать выборки данных. Дальше вы можете реализовывать новый функционал, например, написать сервис, который сделает запрос к данным и выдаст наиболее выгодное предложение за сутки — это потребует нескольких строк в конфигурационном файле и немного кода на Lua.
Что дальше?
У нас в приоритете — повышение удобства разработки с помощью Tarantool Data Grid. Например, это IDE с поддержкой профилирования и отладки обработчиков, работающих в песочнице.
Также мы большое внимание уделяем вопросам безопасности. Прямо сейчас мы проходим сертификацию ФСТЭК России, чтобы подтвердить высокий уровень безопасности и соответствовать предъявляемым требованиям по сертификации программных продуктов, используемых в информационных системах персональных данных и государственных информационных системах.
