Архитектура хранения и отдачи фотографий в Badoo

Артем Денисов (bo0rsh201, Badoo)
Badoo — это крупнейший в мире сайт знакомств. На данный момент у нас зарегистрировано порядка 330 миллионов пользователей по всему миру. Но, что гораздо более важно в контексте нашего сегодняшнего разговора, — это то, что мы храним около 3 петабайт пользовательских фотографий. Каждый день наши пользователи заливают порядка 3,5 миллионов новых фотографий, и нагрузка на чтение составляет порядка 80 тысяч запросов в секунду. Это достаточно много для нашего бэкенда, и с этим иногда бывают трудности.

Я расскажу про дизайн этой системы, которая хранит и отдает фотки в целом, и приведу на нее взгляд с точки зрения разработчика. О том, как она развивалась, будет краткая ретроспектива, где я основные вехи обозначу, но уже более подробно буду говорить только о тех решениях, которые мы сейчас используем.
А теперь давайте начнем.
Как я уже сказал, это будет ретроспектива, и для того чтобы ее с чего-то начать, давайте возьмем самый банальный пример.

У нас есть общая задача, нам нужно принимать, хранить и отдавать фотографии пользователей. В таком виде задача общая, мы можем использовать что угодно:
- современный облачный storage,
- коробочное решение, которых сейчас тоже очень много;
- можем засетапить несколько машин в своем дата-центре и поставить на них большие жесткие диски и хранить фотографии там.
Badoo исторически — и сейчас, и тогда (на то время, когда это только зарождалось) — живет на собственных серверах, внутри наших собственных ДЦ. Поэтому для нас этот вариант был оптимальным.
Мы просто взяли несколько машин, назвали их «photos», у нас получился такой кластер, который хранит фотографии. Но, кажется, чего-то не хватает. Для того чтобы все это работало, нужно каким-то образом определить, на какой машине какие фотографии мы будем хранить. И здесь тоже не надо открывать Америку.
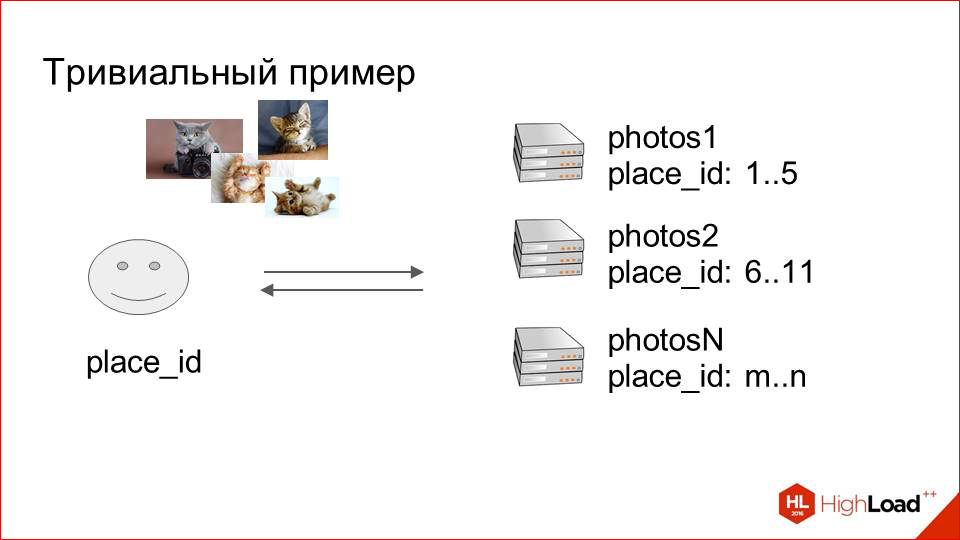
Мы добавляем в наше хранилище с инфой о пользователях какое-то поле. Это будет ключ шардинга. В нашем случае мы назвали его place_id, и вот этот id мест и указывает на место, в котором хранятся фотографии пользователей. Мы составляем карты.
На первом этапе это можно даже делать руками — мы говорим, что фотография этого пользователя с таким плэйсом будет приземляться на такой сервер. Благодаря этой карте мы всегда знаем, когда пользователь загружает фотографию, где ее сохранить, и знаем, откуда ее отдать.
Это абсолютно тривиальная схема, но она имеет достаточно существенные плюсы. Первое — это то, что она простая, как я уже сказал, а второе — это то, что с таким подходом мы можем легко горизонтально масштабироваться, просто доставляя новые тачки и добавляя их в карту. Больше ничего делать не надо.
Так оно какое-то время и было у нас.
Это было где-то в 2009 году. Доставляли машины, доставляли…
И в какой-то момент мы начали замечать, что эта схема обладает определенными недостатками. Какие недостатки?
В первую очередь, это ограниченная вместимость. Мы на один физический сервер можем запихать не так много жестких дисков, как нам хотелось бы. И это с течением времени и с ростом dataset«а стало определенной проблемой.
И второе. Это нетипичная конфигурация машин, поскольку такие машины тяжело переиспользовать в каких-то других кластерах, они достаточно специфические, т.е. они должны быть слабые по производительности, но в то же время с большим жестким диском.
Это все было на 2009 год, но, в принципе, эти требования актуальны и на сей день. У нас ретроспектива, поэтому в 2009 году все было плохо с этим совсем.
И последний пункт — это цена.
Цена тогда была очень кусачая, и нам нужно было искать какие-то альтернативы. Т.е. нам нужно было как-то лучше утилизировать и место в дата-центрах, и непосредственно физические сервера, на которых все это размещено. И наши системные инженеры начали большое исследование, в котором пересмотрели кучу разных вариантов. Они смотрели и на кластерные файловые системы, такие, как PolyCeph и Lustre. Там были проблемы с производительностью и достаточно тяжелая эксплуатация. Отказались. Пробовали монтировать весь dataset по NFS на каждую тачку, чтобы таким образом как-то cмасштабировать. Чтение тоже плохо зашло, пробовали разные решения от разных вендоров.
И в итоге мы остановились на том, что мы стали использовать так называемое Storage Area Network.
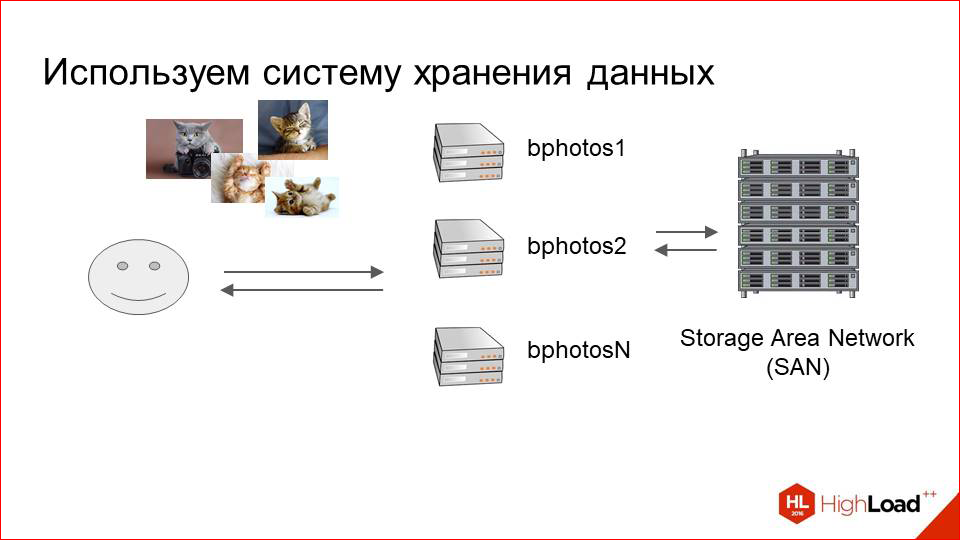
Это такие большие SHD, которые как раз ориентированы на хранение больших объемов данных. Они представляют собой полки с дисками, которые смонтированы на конечные отдающие машины по оптике. Т.о. мы имеем какой-то пул машин, достаточно небольшой, и эти SHD, которые прозрачны для нашей отдающей логики, т.е. для нашего nginx или кого-то еще, обслуживают запросы за этими фотографиями.
У этого решения были очевидные плюсы. Это SHD. Оно ориентировано на то, чтобы хранить фотки. Это получается дешевле, чем мы просто сетапим машины жесткими дисками.
Второй плюс.
Это то, что вместимость стала гораздо больше, т.е. мы в гораздо меньшем объеме можем разместить гораздо больше storage«а.
Но были и минусы, которые обнаружились достаточно быстро. С ростом числа пользователей и нагрузки на эту систему начали возникать проблемы с производительностью. И проблема здесь достаточно очевидная — любая SHD, предназначенная для того, чтобы хранить много фотографий в маленьком объеме, как правило, страдает от интенсивного чтения. Это на самом деле актуально и для любого облачного storage«а, и чего бы то ни было. Сейчас у нас не существует идеального storage«а, который был бы бесконечно масштабируемый, в него можно было бы все, что угодно, запихивать, и он бы очень хорошо переносил чтения. Особенно случайные чтения.

Как и в случае с нашими photos, потому что фотографии запрашиваются непоследовательно, и это очень сильно аффектит их performance.
Даже вот по сегодняшним цифрам, если у нас выпадает где-то больше 500 RPS за фотками на машину, к которой подключен storage, уже начинаются проблемы. И это было достаточно плохо для нас, потому что число пользователей растет, все должно становиться только хуже. Надо это как-то оптимизировать.
Для того чтобы оптимизировать, мы в то время решили, очевидно, посмотреть на профиль нагрузки — что, вообще, происходит, что надо оптимизировать.

И тут все играет нам на руку.
Я в первом слайде уже говорил: у нас 80 тысяч запросов в секунду на чтение при всего 3,5 миллионов aплоадов в день. То есть это разница на три порядка. Очевидно, что оптимизировать надо чтение и практически понятно как.
Есть еще один маленький момент. Специфика сервиса такая, что человек регистрируется, заливает фотографию, далее начинает активно смотреть других людей, лайкать их, его активно показывают другим людям. Потом он находит себе пару или не находит пару, это уж как получится, и на какое-то время перестает пользоваться сервисом. В этот момент, когда он пользуется, его фотки очень горячие — они востребованы, их просматривает очень много людей. Как только он перестает это делать, достаточно быстро он выпадает из таких интенсивных показов другим людям, как были раньше, и его фотки практически не запрашиваются.

Т.е. у нас очень маленький горячий dataset. Но при этом за ним прямо очень много запросов. И совершенно очевидным решением тут напрашивается добавить кэш.
Кэш с LRU все проблемы наши решит. Что мы делаем?
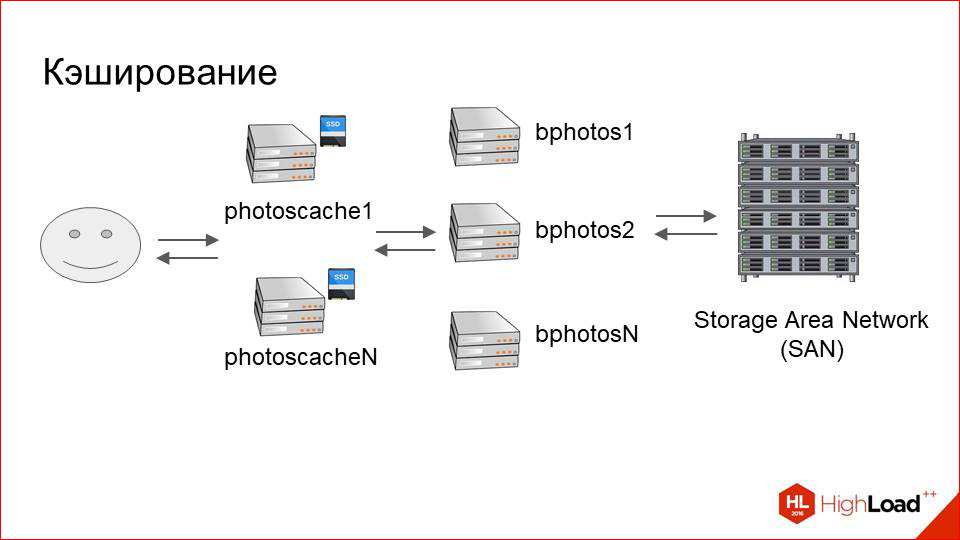
Мы добавляем перед нашим большим кластером со storage«ем еще один сравнительно небольшой, который называемся фотокэши (photoscache). Это, по сути, просто кэширующий proxy.
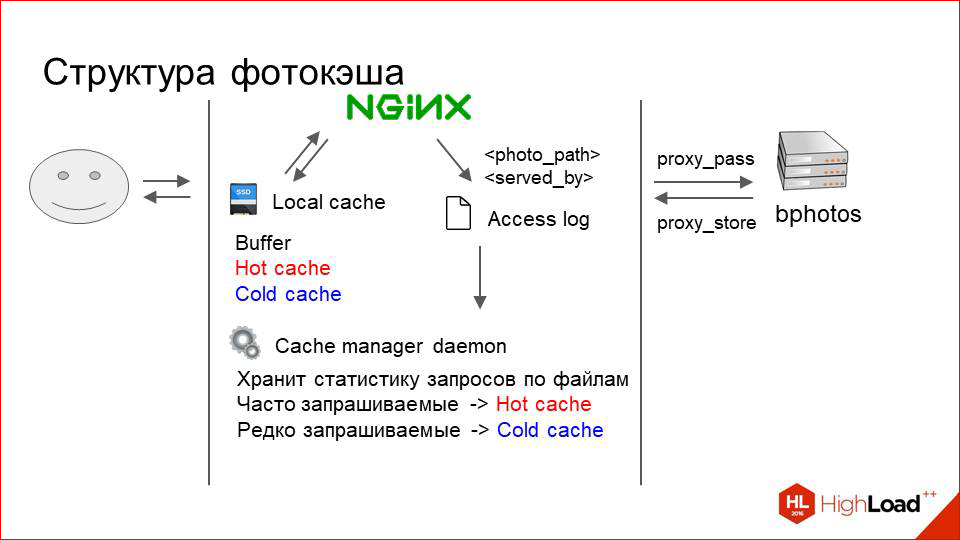
Как это работает изнутри? Вот наш пользователь, вот storage. Все, как раньше. Что мы добавляем между ними?

Это просто машина с физическим локальным диском, который быстрый. Это с SSD, допустим. И вот на этом диске хранится какой-то локальный кэш.
Как это выглядит? Пользователь посылает запрос за фоткой. NGINX ищет ее сначала в локальном кэше. Если нет, то делает просто proxy_pass на наш storage, скачивает фотографию оттуда и дает ее пользователю.
Но этот очень банально и непонятно, что внутри происходит. Работает это примерно так.

Кэш логически разделен на три слоя. Когда я говорю «три слоя», это не значит, что там какая-то сложная система. Нет, это условно просто три директории в файловой системе:
- Это буфер, куда попадают только что загруженные из proxy фотографии.
- Это горячий кэш, в котором хранятся активно запрашиваемые сейчас фотографии.
- И холодный кэш, куда постепенно фотографии выталкиваются из горячего, когда к ним приходит меньше request«ов.
Чтобы это работало, нам надо как-то менеджить этот кэш, надо переставлять фотографии в нем и т.д. Это тоже очень примитивный процесс.
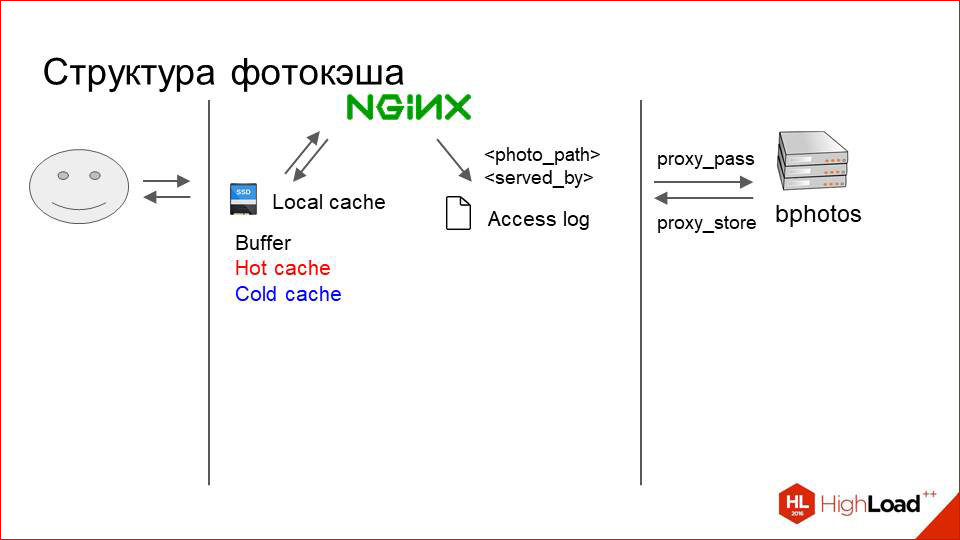
Nginx просто на каждый запрос пишет на RAMDisk access.log, в котором указывает путь до фотки, которую он сейчас обслужил (относительный путь, естественно), и то, каким разделом она была обслужена. Т.е. там может быть написано «photo 1» и дальше или буфер, или горячий кэш, или холодный кэш, или proxy.
В зависимости от этого нам нужно как-то принять решение, что делать с фоткой.
У нас на каждой машине работает небольшой демон, который постоянно вычитывает этот лог и у себя в памяти хранит статку по использованию тех или иных фотографий.

Он просто собирает там, ведет счетчики и периодически делает следующее. Активно запрашиваемые фотографии, за которыми приходит много request«ов, он двигает в горячий кэш, где бы они ни лежали.

Фотографии, которые запрашиваются редко и стали запрашиваться реже, он постепенно выталкивает из горячего кэша в холодный.
И когда у нас в кэше кончается место, мы просто начинаем все удалять из холодного кэша без разбора. И это, кстати, хорошо работает.
Для того чтобы фотка сохранялась сразу же при проксировании в буфер, мы используем директиву proxy_store и буфер — это тоже RAMDisk, т.е. для пользователя это работает очень быстро. Это что касается внутренностей самого кэширующего сервера.
Остался вопрос с тем, как распределять request«ы по этим серверам.
Допустим, есть кластер из двадцати storage-машин и три кэширующих сервера (так получилось).

Нам нужно каким-то образом определить, какие request«ы за какими фотками и куда приземлить.
Самый банальный вариант — это Round Robin. Или случайно это делать?
Это, очевидно, имеет ряд недостатков, потому что мы будем очень неэффективно использовать кэш в такой ситуации. Запросы будут приземляться на какие-то случайные машины: здесь она закэшировалась, на соседней ее уже нету. И работать все это если и будет, то очень плохо. Даже при небольшом числе машин в кластере.
Нам нужно каким-то образом однозначно определять, на какой сервер приземлять какой request.
Есть банальный способ. Мы берем хэш от URL«а или хэш от нашего ключа шардинга, который есть в URL«е, и делим его нацело на количество серверов. Будет работать? Будет.

Т.е. у нас стопроцентный request, например, за каким-то «example_url» всегда будет приземляться на сервер с индексом »2», и кэш будет постоянно утилизирован как можно лучше.
Но возникает проблема с решардингом в такой схеме. Решардинг — я имею в виду изменение количества серверов.
Предположим, что наш кэширующий кластер перестал справляться, и мы решили добавить еще одну машину.
Добавляем.

У нас теперь все делится нацело не на три, а на четыре. Таким образом, практически все ключи, которые у нас раньше были, практически все URL«ы теперь живут на других серверах. Весь кэш инвалидировался просто моментом. Все запросы повалили на наш кластер-storage, ему стало плохо, отказ обслуживания и недовольные пользователи. Так не хочется делать.
Этот вариант нам тоже не подходит.
Т.о. что мы должны сделать? Мы должны каким-то образом эффективно использовать кэш, постоянно приземлять один request на один и тот же сервер, но при этом быть устойчивыми к решардингу. И такое решение есть, оно не то чтобы сложное. Называется consistent hashing.

Как это выглядит?

Мы берем какую-то функцию от шардинг-ключа и размазываем все ее значения на окружности. Т.е. в точке 0 у нас сходятся ее минимальные и максимальные значения. Далее мы на этой же окружности размещаем все наши сервера примерно таким образом:
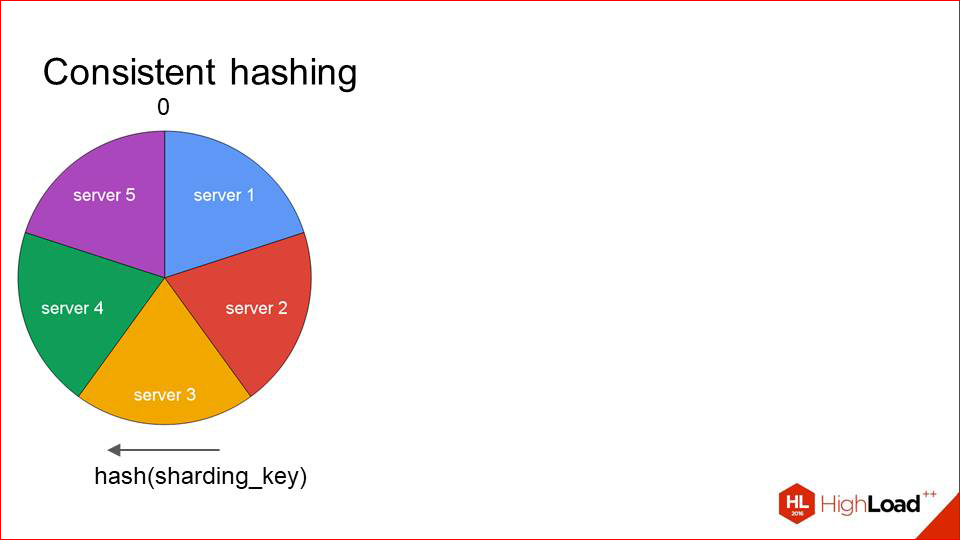
Каждый сервер определяется одной точкой, и тот сектор, который идет до него по часовой стрелке, соответственно, обслуживается этим хостом. Когда нам приходят запросы, мы сразу же видим, что, например, запрос А — у него там хэш такой — и он обслуживается сервером 2. Запрос Б — сервером 3. И так далее.

Что в этой ситуации происходит при решардинге?
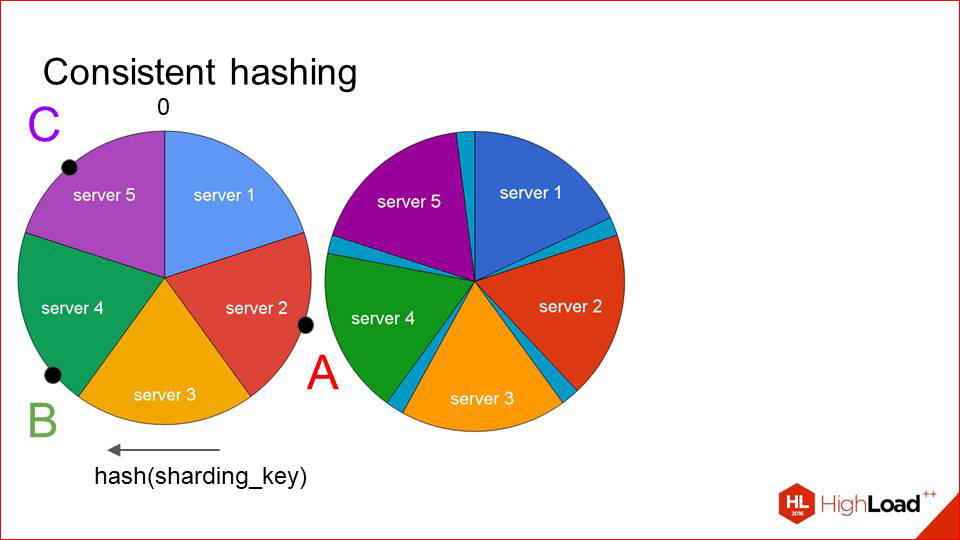
Мы не инвалидируем весь кэш, как раньше, и не сдвигаем все ключи, а мы сдвигаем каждый сектор на небольшое расстояние таким образом, чтобы в освободившееся место, условно говоря, влез наш шестой сервер, который хотим добавить, и добавляем его туда.
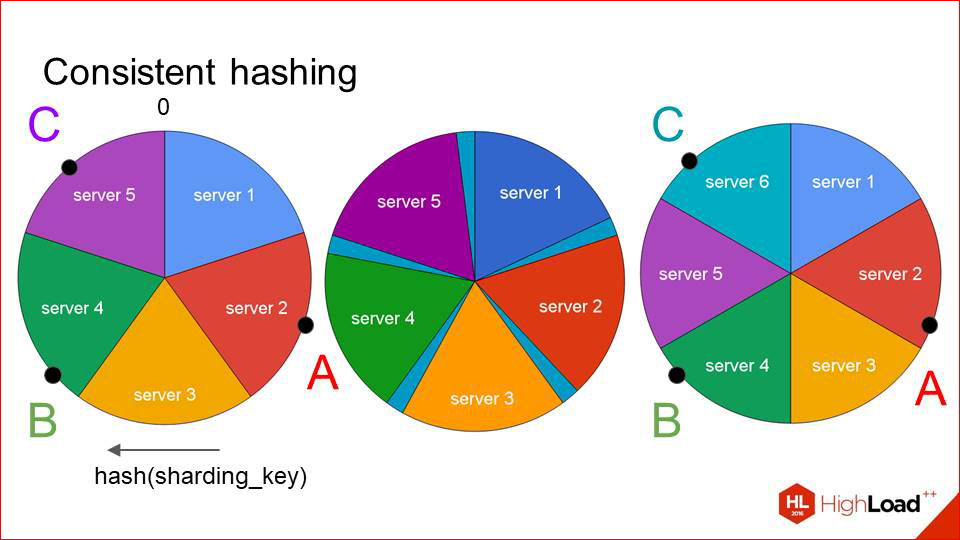
Конечно, в такой ситуации ключи тоже съезжают. Но они съезжают гораздо слабее, чем раньше. И мы видим, что два наших первых ключа остались на своих серверах, а поменялся кэширующий сервер только для последнего ключа. Это работает достаточно эффективно, и если вы добавляете новые хосты инкрементально, то большой проблемы здесь нет. Вы по чуть-чуть добавляете-добавляете, ждете, пока кэш опять наполнится, и все хорошо работает.
Единственный вопрос остается при отказах. Предположим, что у нас какая-то тачка вышла из строя.
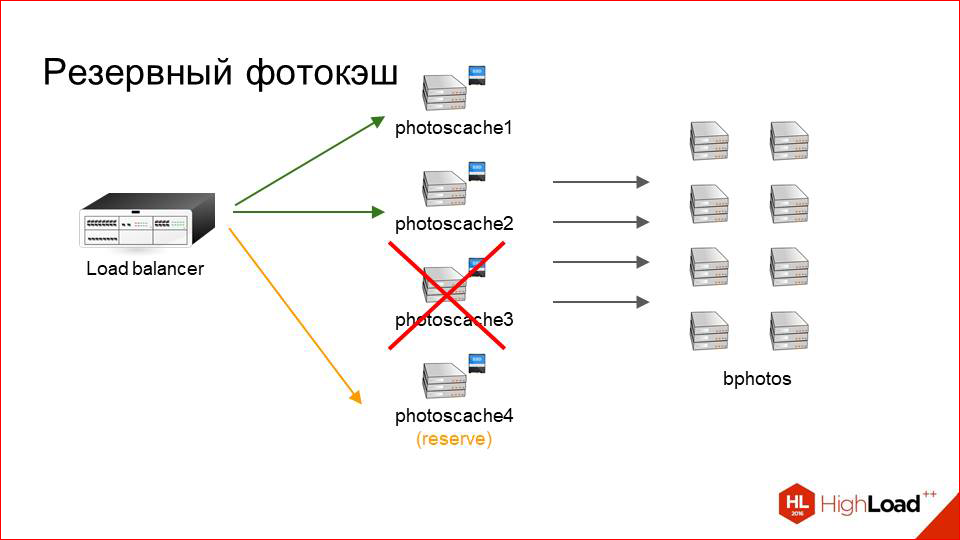
И нам не очень бы хотелось в этот момент перегенерить эту карту, инвалидировать часть кэша и так далее, если, например, машина ребутнулась, а нам надо как-то обслуживать запросы. Мы просто держим на каждой площадке один резервный фотокэш, который выполняет роль замены для любой машины, которая сейчас вышла из строя. И если вдруг у нас какой-то сервер стал недоступен, трафик идет туда. У нас при этом, естественно, там нет никакого кэша, т.е. он холодный, но, как минимум, запросы пользователей обрабатываются. Если это короткий интервал, то мы совершенно спокойно это переживаем. Просто больше нагрузка на storage идет. Если это интервал долгий, то мы уже можем принять решение — убрать этот сервер из карты или нет, или, может быть, заменить его другим.
Это по поводу системы кэширования. Давайте посмотрим на результаты.
Казалось бы, ничего сложного здесь нет. Но вот такой способ управления кэшом дал нам хитрейт порядка 98%. Т.е. из вот этих 80 тысяч request«ов в секунду только 1600 доходит до storage«ей, и это совершенно нормальная нагрузка, они спокойно это переживают, у нас всегда есть запас.
Мы разместили эти сервера в трех наших DC, и получили три точки присутствия — Прага, Майами и Гонконг.

Т.о. они более-менее локально расположены к каждому из наших целевых рынков.
И в качестве приятного бонуса мы получили вот этот кэширующий proxy, на котором CPU на самом деле простаивает, потому что для отдачи контента он не так сильно нужен. И там с помощью NGINX+ Lua мы реализовали очень много утилитарной логики.

Например, можем экспериментировать с webp или progressive jpeg (это эффективные форматы современные), смотреть, как это влияет на трафик, принимать какие-то решения, включать для определенных стран и т.д.; делать динамический resize или crop фотографии на лету.
Это хороший usecase, когда у вас, например, есть мобильное приложение, которое показывает фотки, и мобильное приложение не хочет тратить CPU клиента на то, чтобы запросить большую фотографию и ресайзить ее потом до какого-то размера, чтобы запихнуть во вьюшку. Мы можем просто динамически указать в URL«е какие-то параметры в UPort условный, и фотокэш сам отресайзит фотографию. Как правило, он подберет тот размер, который у нас физически есть на диске, максимально близкий к запрашиваемому, и задаунскеллит его в конкретных уже координатах.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Также мы можем добавлять туда много продуктовой логики. Например, мы можем по параметрам URL«а добавлять разные watermark«и, можем блюрить фотографии, размывать или пикселизовать. Это когда мы хотим показать фотографию человека, но не хотим показывать его лицо, это хорошо работает, это все реализовано тут.
Что мы получили? Мы получили три точки присутствия, хороший хитрейт, и при этом у нас не простаивает CPU на этих машинах. Он теперь стал, конечно, важнее, чем раньше. Нам нужно ставить машины себе посильнее, но это того стоит.
Это что касается отдачи фотографий. Здесь все достаточно понятно и очевидно. Я думаю, что я не открыл Америку, так работает практически любой СDN.
И, скорее всего, у искушенного слушателя мог возникнуть вопрос:, а почему просто не взять и не поменять все на СDN? Было бы примерно то же самое, все современные СDN это умеют. И здесь ряд причин.
Первая — это фотки.

Это один из ключевых моментов нашей инфраструктуры, и нам нужно над ними как можно больше контроля. Если это какое-то решение у стороннего вендора, и вы не имеете над ним никакой власти, вам будет достаточно тяжело с этим жить, когда у вас большой dataset, и когда у вас очень большой поток запросов пользователей.
Приведу пример. Сейчас на своей инфраструктуре мы можем, например, в случае каких-то проблем или подземных стуков, зайти на машину, подебажиться там, условно говоря. Мы можем добавить сбор каких-то метрик, которые только нам нужны, можем как-то экспериментировать, смотреть, как это повлияет на графики и так далее. Сейчас собирается очень много статистики по вот этому кэширующему кластеру. И мы периодически смотрим на нее и долго исследуем какие-то аномалии. Если бы это было на стороне СDN, это было бы гораздо тяжелее контролировать. Или, например, если происходит какая-то авария, мы знаем, что случилось, мы знаем, как с этим жить и как это побороть. Это первый вывод.
Второй вывод тоже, скорее, исторический, потому что система развивается уже давно, и много разных бизнес-требований на разных этапах были, и далеко не всегда они укладываются в концепцию СDN.
И пункт, вытекающий из предыдущего –

Это то, что на фотокэшах у нас много специфической логики, которую далеко не всегда можно добавить по запросу. Вряд ли какой-то CDN будет по вашему запросу добавлять вам какие-то кастомные вещи. Например, шифрование URL«ов, если вы не хотите, чтобы клиент мог что-то менять. Хотите сменить URL на сервере и зашифровать его, а потом отдать сюда какие-то динамические параметры.
Какой вывод напрашивается? В нашем случае CDN — это не очень хорошая альтернатива.

А в вашем случае, если у вас есть какие-то специфические бизнес-требования, то вы можете сами совершенно спокойно реализовать то, что я вам показал. И это при похожем профиле нагрузки будет отлично работать.
Но если у вас какое-то общее решение, и задача не очень частная, вы можете совершенно спокойно брать CDN. Или если для вас гораздо важнее время и ресурсы, чем контроль.

И современные СDN имеют практически все то, о чем я вам рассказал сейчас. За исключением плюс минус каких-то фич.
Это по поводу отдачи фотографий.
Давайте теперь немножко переместимся вперед в нашей ретроспективе и поговорим про хранение.
2013 год шел.
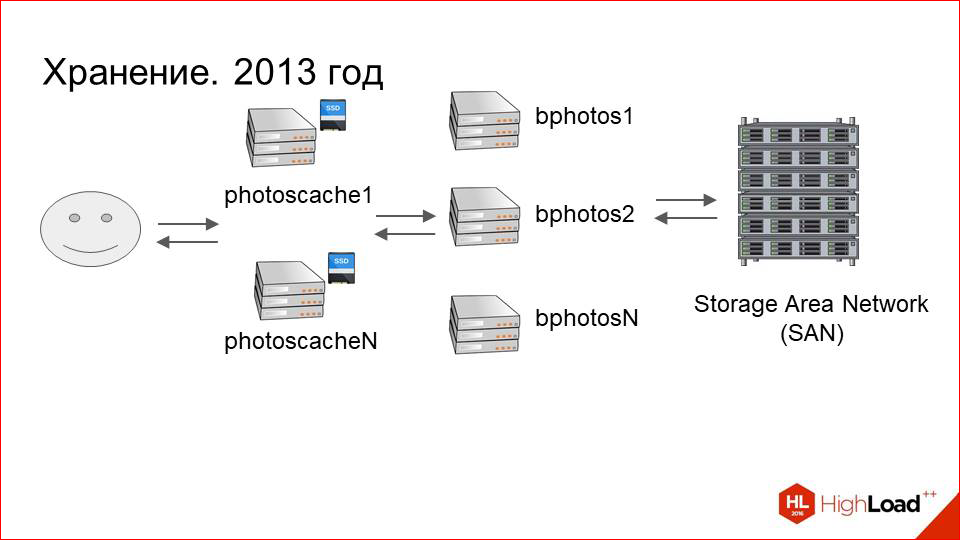
Кэширующие сервера добавились, проблемы с performance«ом ушли. Все хорошо. Dataset растет. На 2013 год у нас было порядка 80 серверов, которые подключены к storage«ам, и порядка 40 кэширующих в каждом ДЦ. Это по 560 терабайт данных на каждом ДЦ, т.е. около петабайта в сумме.
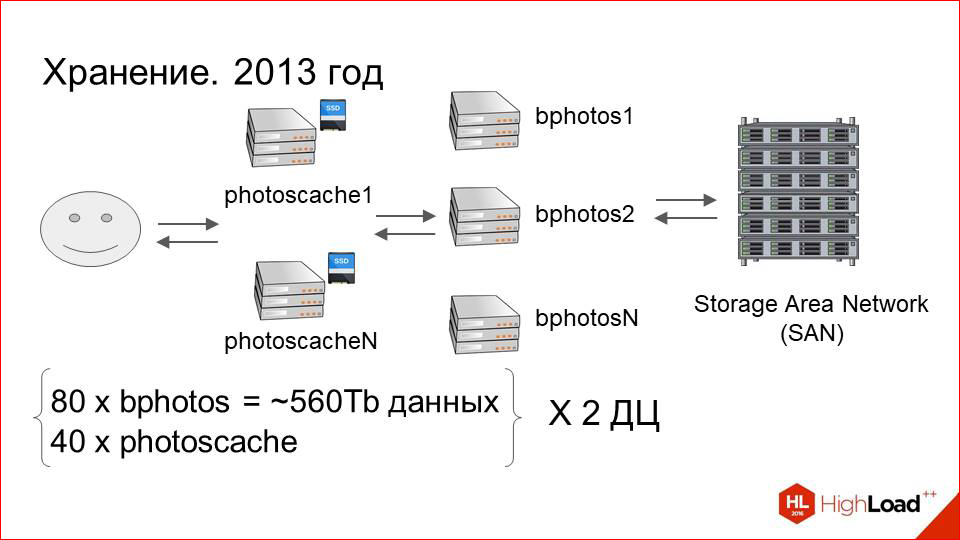
И с ростом dataset«а начали сильно расти эксплуатационные издержки. В чем это выражалось?
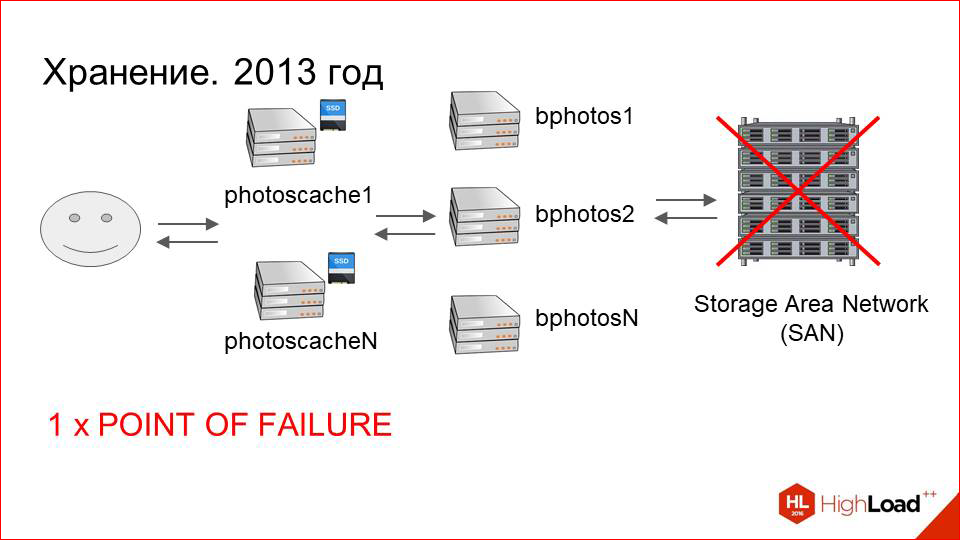
В этой схеме, которая нарисована — с SAN«ом, с подключенными к нему машинами и кэшами — очень много точек отказа. Если с отказом кэширующих серверов мы раньше уже справились, там все более-менее прогнозируемо и понятно, то на стороне именно storage«а все было гораздо хуже.
Во-первых, сам Storage Area Network (SAN), который может отказать.
Во-вторых, он подключен по оптике на конечные машины. Могут быть проблемы с оптическими картами, свечами.
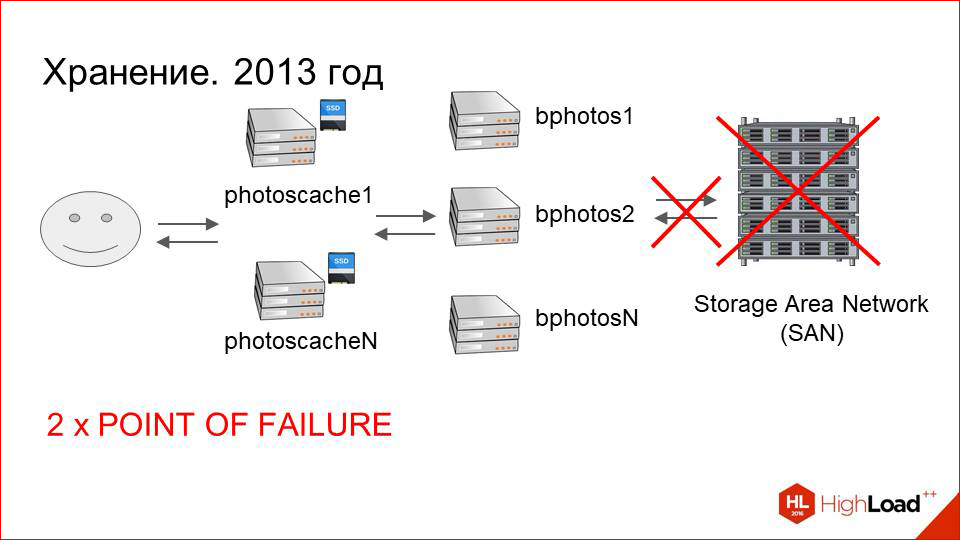
Их, конечно, не так много, как с самим SAN«ом, но, тем не менее, это тоже точки отказа.
Далее сама машина, которая подключена к storage«у. Она тоже может выйти из строя.

Итого у нас три точки отказа.
Далее, помимо точек отказа, это тяжелый maintenance самих storage«ей.
Это сложная многокомпонентная система, и системным инженерам бывает с ней тяжело.
И последний, самый важный пункт. Если в любой из этих трех точек произойдет отказ, у нас есть ненулевая вероятность потерять данные пользователя, поскольку может побиться файловая система.
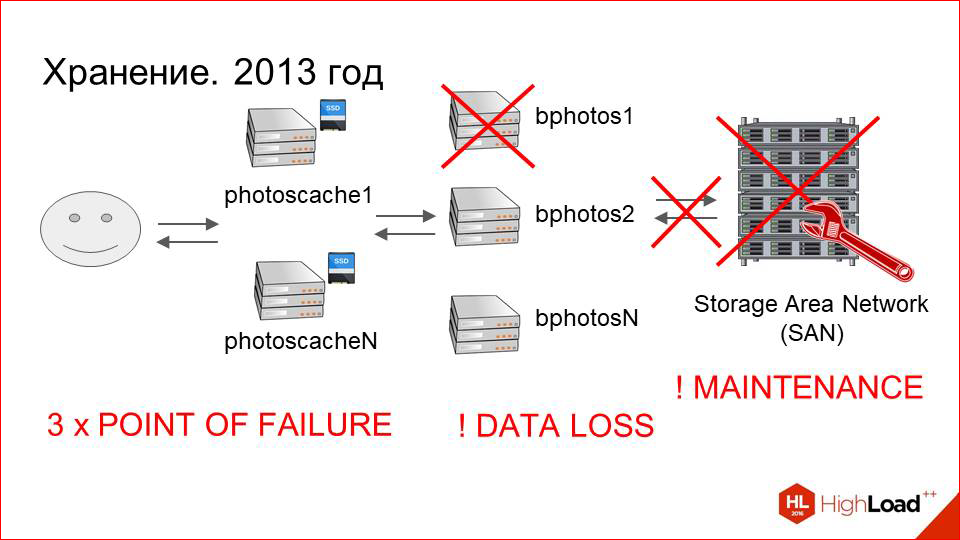
Предположим, у нас побилась файловая система. Ее восстановление идет, во-первых, долго — это может занимать неделю при большом объеме данных. А во-вторых, в итоге мы, скорее всего, получим кучу непонятных файлов, которые нужно будет каким-то образом сматчить на фотографии пользователей. И мы рискуем потерять данные. Риск достаточно высокий. И чем чаще такие ситуации случаются, и чем больше возникает проблем во всей этой цепочке, тем этот риск выше.
С этим надо было что-то делать. И мы решили, что надо просто резервировать данные. Это на самом деле очевидное решение и хорошее. Что мы сделали?

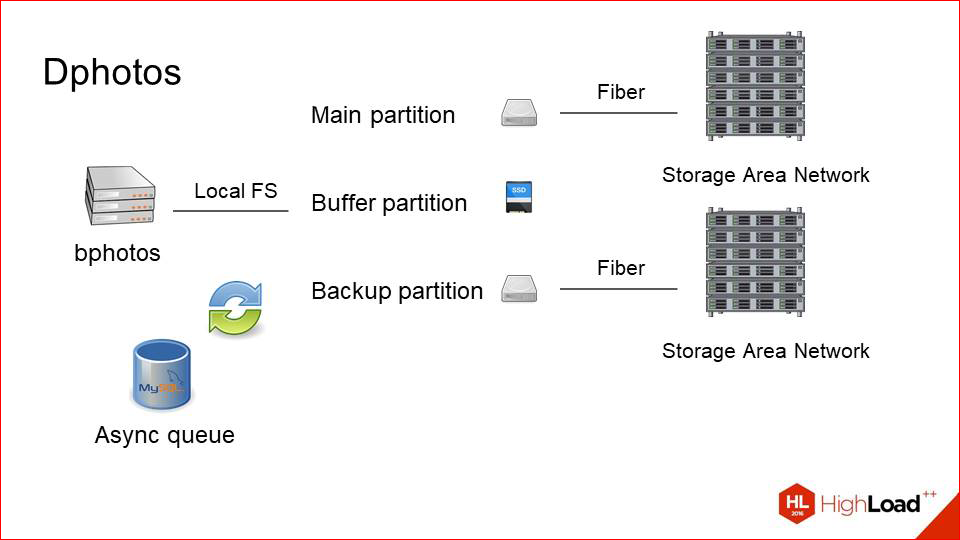
Так выглядел наш сервер, который был подключен к storage«у раньше. Это один основной раздел, это просто блочное устройство, которое представляет на самом деле маунт на удаленный storage по оптике.
Мы просто добавили второй раздел.
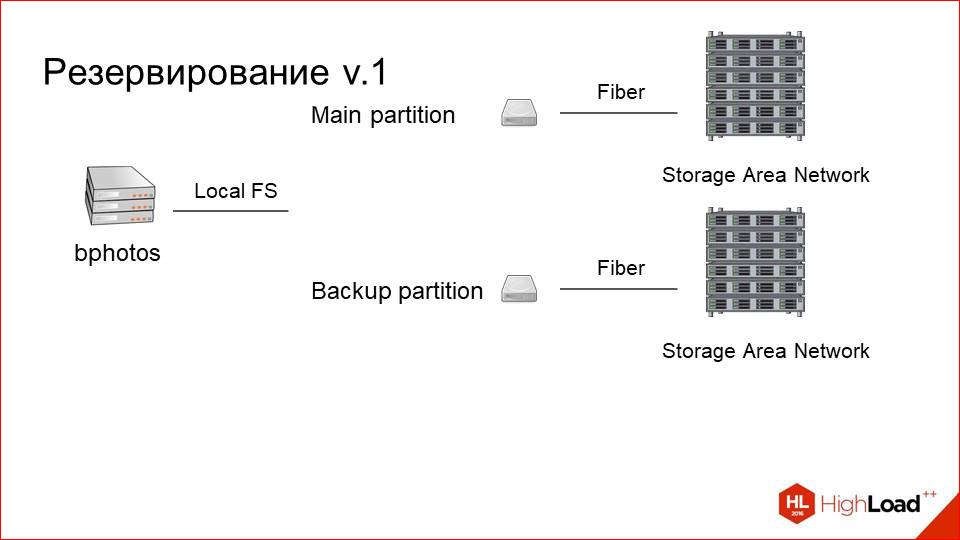
Поставили рядом второй storage (благо, по деньгам это не так дорого), и назвали его backup-разделом. Он тоже подключен по оптике, на той же машине находится. Но нам надо как-то синхронизировать между ними данные.
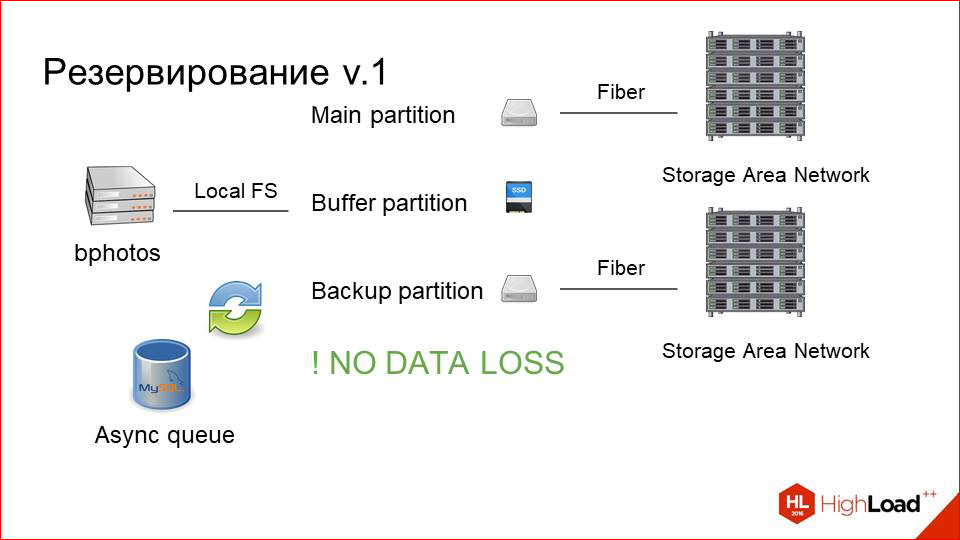
Здесь мы просто делаем рядом асинхронную очередь.

Она не очень нагружена. Мы знаем, что у нас мало записей. Очередь — это просто табличка в MySQL, в которую пишутся строчки типа «надо забэкапить вот эту фотографию». При любом изменении или при upload«е мы копируем с основного раздела на backup асинхронным или просто каким-то background worker«ом.
И таким образом мы имеем всегда два консистентных раздела. Даже если одна часть этой системы выйдет из строя, мы всегда можем поменять основной раздел с backup«ом, и все продолжит работать.
Но из-за этого сильно возрастает нагрузка на чтение, т.к. помимо клиентов, которые читают с основного раздела, потому что они сначала смотрят фотографию там (она же там более свежая), а потом уже ищут на backup«е, если не нашли (но это уже NGINX просто делает), еще плюс и наша система backup«а теперь вычитывает с основного раздела. Не то чтобы это было узким местом, но не хотелось увеличивать нагрузку, по сути, просто так.
И мы добавили третий диск, который маленький SSD, и назвали его буфером.

Как это теперь работает.
Пользователь upload«ит фотку на буфер, далее кидается event в очередь о том, что ее надо раскопировать на два раздела. Она копируется, и фотография какое-то время (допустим, сутки) живет на буфере, а только потом оттуда пуржится. Это здорово улучшает user experience, потому что пользователь заливает фотографию, как правило, за ней сразу же начинают идти request «ы, или он сам обновил страницу, зарефрешил. Но это все зависит от приложения, которое делает upload.
Или, например, другие люди, которым он начал показываться, сразу же за этой фоткой посылают request «ы. В кэше ее еще нет, первый запрос происходит очень быстро. По сути, так же, как с фотокэша. Медленный storage не участвует вообще в этом. А когда через сутки она будет спуржена, она уже либо закэширована на нашем кэширующем слое, либо она уже, скорее всего, никому не нужна. Т.е. user experience здесь очень здорово подрос за счет таких простых манипуляций.
Ну, и самое главное: мы перестали терять данные.
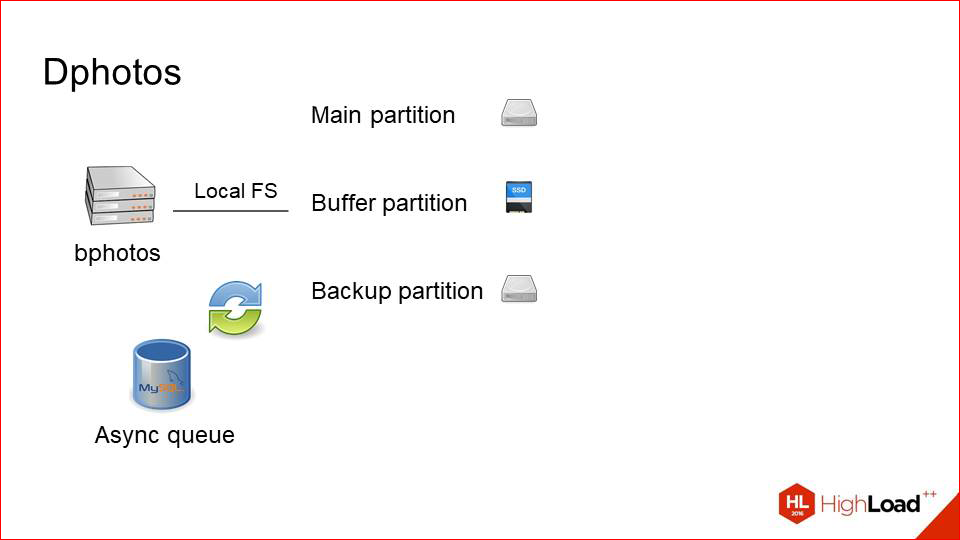
Мы, скажем так, перестали потенциально терять данные, потому что мы их особо и не теряли. Но опасность была. Мы видим, что такое решение, конечно, хорошее, но оно слегка похоже на сглаживание симптомов проблемы, вместо того чтобы решить ее до конца. И проблемы здесь некоторые остались.
Во-первых, это точка отказа в виде самого физического хоста, на котором вся эта машинерия работает, она никуда не делась.

Во-вторых, остались проблемы с SAN«ами, остался их тяжелый maintenance и т.д. Это не то чтобы было критическим фактором, но хотелось попробовать как-то без этого пожить.
И мы сделали третью версию (по сути, вторую на самом деле) — версию резервирования. Как это выглядело?
Это то, что было –
Основные проблемы у нас с тем, что это физический хост.
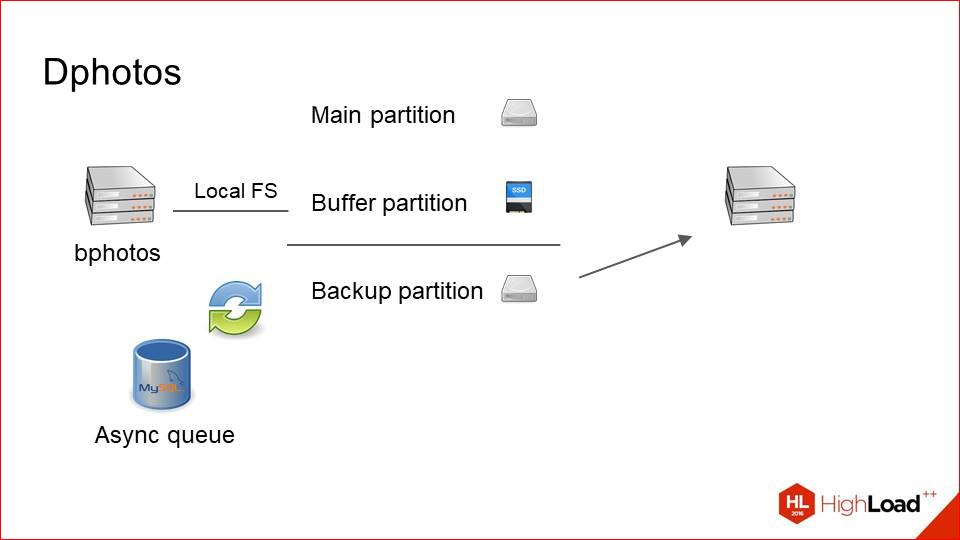
Мы, во-первых, убираем SAN«ы, потому что хотим поэкспериментировать, хотим попробовать просто локальные жесткие диски.
Это уже 2014–2015 год, и на тот момент ситуация с дисками и с их вместимостью в один хост стала гораздо лучше. Мы решили, почему бы не попробовать.
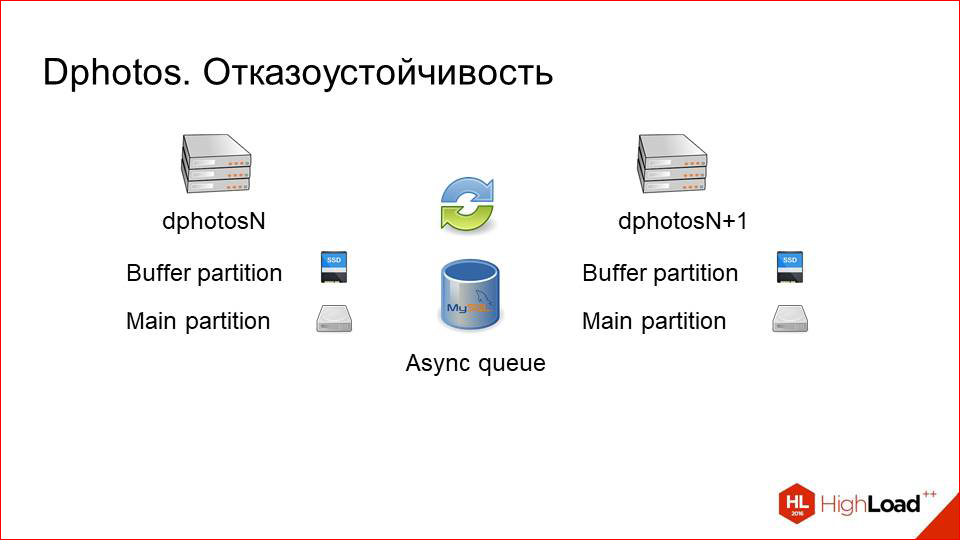
И далее мы просто берем наш backup-раздел и переносим его физически на отдельную машину.
Таким образом, мы получаем вот такую схему. У нас есть две тачки, которые хранят одинаковые dataset«ы. Они резервируют друг друга полностью и синхронизируют данные по сети через асинхронную очередь в том же самом MySQL.
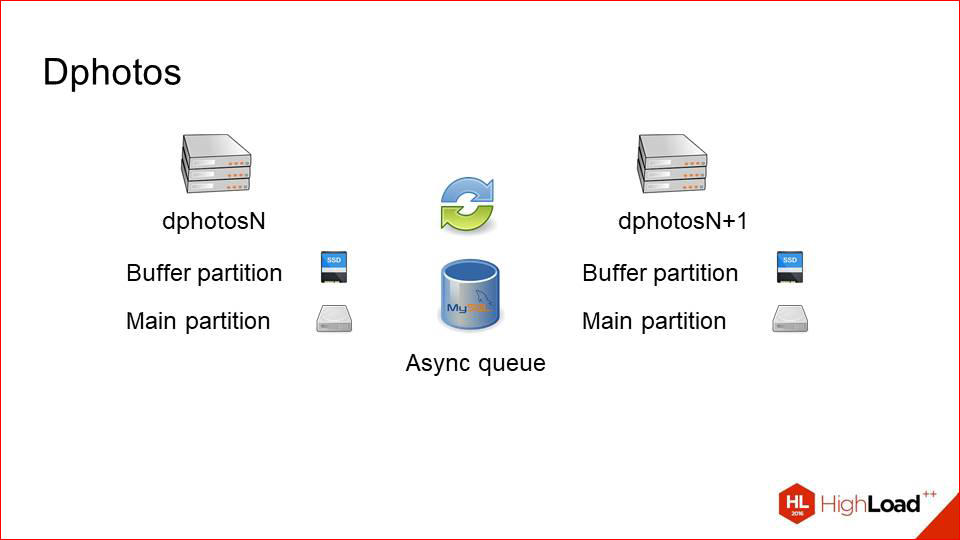
Почему это хорошо работает — потому что у нас мало записей. Т.е. если бы запись была соизмерима с чтением, возможно, мы бы получили какой-то сетевой overhead и проблемы. Записи мало, чтения много — этот способ работает хорошо, т.е. мы достаточно редко копируем фотографии между двумя этими серверами.
Каким образом это работает, если чуть-чуть детальнее посмотреть.

Upload. Балансировщик просто выбирает случайные хосты с парой и делает upload на него. При этом он естественно делает health checks, смотрит, чтобы машина не выпала. Т.е. он upload«ит фотки только на живой сервер, а потом через асинхронную очередь это все копируется на его соседа. С upload«ом все предельно просто.
С задачей чуть-чуть сложнее.

Здесь нам помог Lua, потому что на ванильном NGINX такую логику сделать трудновато бывает. Мы сначала делаем request на первый сервер, смотрим, есть ли фотография там, потому что потенциально она может быть залита, например, на соседа, а сюда еще не доехала. Если фотография там есть, это хорошо. Мы ее сразу же отдаем клиенту и, возможно, кэшируем.
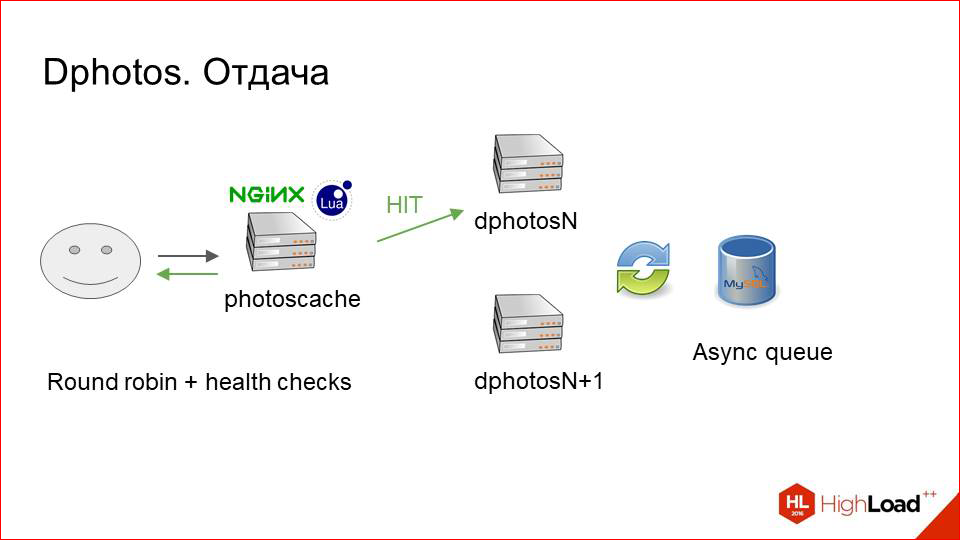
Если ее нет, мы просто делаем запрос на соседа и оттуда ее гарантированно получаем.

Т.о. опять можно сказать: могут быть проблемы с performance«ом, потому что постоянные round trip«ы — фотографию залили, тут ее нет, мы делаем два запроса вместо одного, это должно медленно работать.
В нашей ситуации это работает не медленно.

У нас собирается куча метрик по этой системе, и условный хитрейт такого механизма составляет около 95%. Т.е. лаг вот этого backup«а маленький, и за счет этого мы практически гарантированно, после того как фотка была загружена, забираем ее уже с первого раза и никуда два раза не ходим.
Таким образом, что мы еще получили, и что очень круто?
Раньше у нас были основные backup-раздел, и мы с них читали последовательно. Т.е. мы всегда сначала искали на основном, а потом на backup«е. Это был один ход.
Теперь мы утилизируем чтение с двух машин сразу. Распределяем запросы Round Robin«ом. В небольшом проценте случаев мы делаем два запроса. Но зато в целом у нас теперь в два раза больше запас по чтению, чем был раньше. И нагрузка прямо здорово снизилась и на отдающие машины, и непосредственно на storage«и, которые у нас на тот момент тоже были.
Что касается отказоустойчивости. Собственно, за это мы и боролись в основном. С отказоустойчивостью здесь все вышло шикарно.
Одна тачка выходит из строя.

Никаких проблем! Системный инженер может даже не просыпаться ночью, подождет до утра, ничего страшного не будет.
Если даже при отказе этой машины вышла из строя очередь, тоже никаких проблем, просто лог будет копиться сначала на живой машине, а потом уже добиваться в очередь, а потом уже на ту тачку, которая войдет в строй через какое-то время.
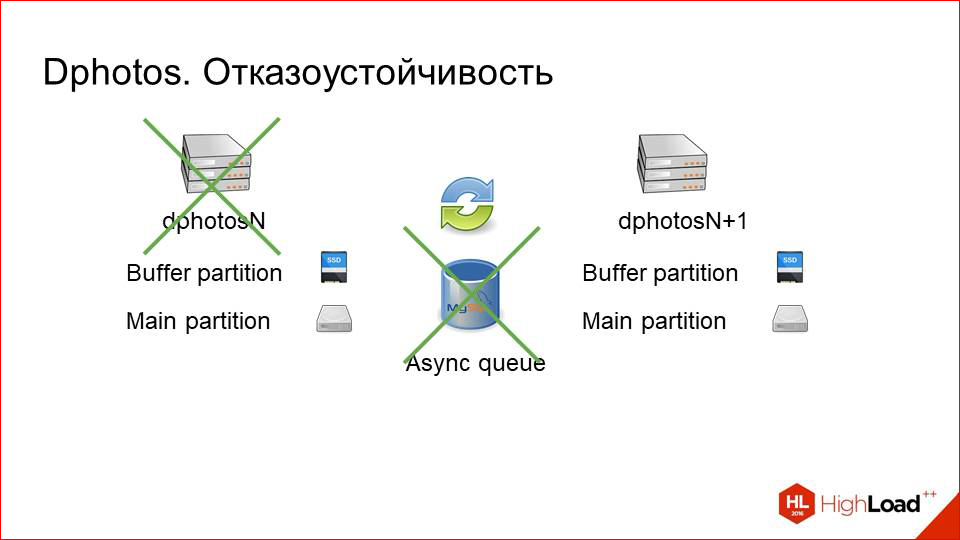
То же самое с maintenance. Мы просто выключаем одну из машин, руками вытаскиваем ее из всех пулов, у нее перестает идти трафик, делаем какой-то maintenance, что-то там правим, после этого возвращаем ее в строй, и вот этот backup догоняется достаточно быстро. Т.е. за сутки downtime одной тачки догоняется в пределах пары минут. Это прямо сильно мало. С отказоустойчивостью, еще раз говорю, здесь все круто.
Какие можно итоги подвести из вот этой схемы с резервированием?
Получили отказоустойчивость.
Простая эксплуатация. Поскольку на машинах локальные жесткие диски, это гораздо более удобно с точки зрения эксплуатации инженеров, которые с этим работают.
Получили двойной запас по чтению.
Э
