Аппаратное ускорение корпоративных вычислений
Хорошими примерами таких «ускорителей» могут служить GPU от NVIDIA или сопроцессоры Xeon Phi, без которых не обходится практически ни один проект в сфере научных или инженерных вычислений. Однако в корпоративном секторе подобные технологии практически не применялись (если не считать использование GPU в фермах виртуализации рабочих мест).
Именно поэтому выход серверов на чипе Oracle SPARC M7, содержащего помимо ядер общего назначения специализированные сопроцессоры Data Analytics Accelerators (DAX), можно считать отправной точкой в проникновении «ускоренных вычислений» на корпоративный рынок.
Основной задачей DAX является ускорение in-memory вычислений за счёт разгрузки основных ядер путём выполнения операций поиска по содержимому оперативной памяти на сопроцессорах.
В случае необходимости переноса операции поиска на DAX ядро общего назначения формирует запрос и передаёт его на выполнение «ускорителям», после чего продолжает выполнение основного кода. При этом происходит автоматическое распараллеливание задачи по всем акселераторам чипа, а затем сбор результатов (похоже на MapReduce) в кэше чипа и уведомление ядра о завершении операции. Сопроцессоры подключены к L3-кэшу чипа, что позволяет обеспечить быстрое взаимодействие с ядрами общего назначения и передачу результатов поиска:

Стоит отметить, что для обеспечения возможности поиска по данным с помощью DAX они должны располагаться в памяти в специальном формате (In-Memory Column Store). Характерным свойством этого формата является возможность хранения данных в сжатом виде (алгоритм сжатия — проприетарный Oracle Zip), что позволяет разместить в оперативной памяти больший объём информации и положительно влияет на скорость обработки данных акселераторами за счёт экономии пропускной способности шины, связывающей чип и оперативную память. При поиске декомпрессия выполняется аппаратно, средствами DAX, и не влияет на производительность. Другой особенностью является наличие индексов, содержащих минимальные и максимальные значения для каждого из множества сегментов памяти (In-Memory Compression Units — IMCUs), составляющих In-Memory Column Store. Получается, что «ускорение» выборки имеет свою цену — долгое первичное размещение данных в памяти, во время которого происходит их сжатие и предварительный анализ (своего рода индексирование).
Основным потребителем данной технологии на данный момент является СУБД Oracle Database 12c, использующая DAX для ускорения операций поиска по таблицам, расположенным в In-Memory Column Store. СУБД автоматически переносит часть операций на DAX, что приводит к значительному ускорению некоторых запросов.
Однако нам в «Инфосистемы Джет» было интересно изучить технологию DAX без промежуточного «чёрного ящика» в виде СУБД Oracle Database, скрывающего интересные подробности и создающего дополнительные накладные расходы, не позволяющие точно оценить преимущества, создаваемые использованием сопроцессоров.
Использование сопроцессоров DAX из сторонних приложений
В начале марта 2016 года Oracle открыла API доступа к DAX для независимых разработчиков (Open DAX API). Теперь DAX можно использовать не только в СУБД Oracle Database, но и в любых других приложениях.
Oracle пригласила всех желающих в свое облако протестировать DAX не только из СУБД, но и с использованием SDK для различных языков программирования (C, Python и Java). Поскольку низкоуровневый API, предназначенный для взаимодействия непосредственно с аппаратной частью сопроцессора, достаточно сложен, для ознакомления с новой технологией помимо самого SDK было предложено использовать дополнительную библиотеку, предоставляющую высокоуровневые средства для работы с данными (libvector), расположенными в оперативной памяти. Именно на её основе и был сделан ряд тестов для проверки работы DAX.
Компоненты SDK
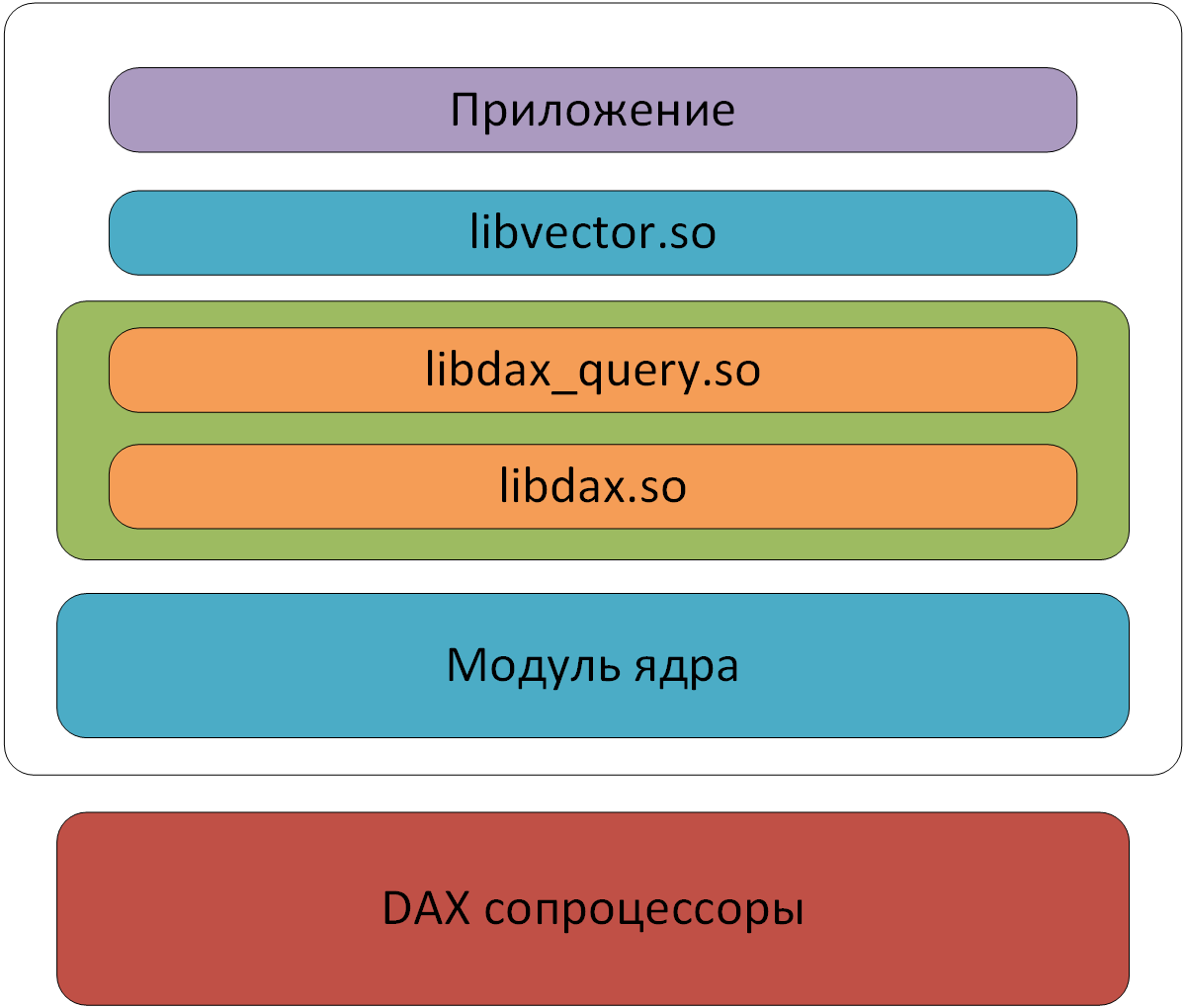
Сценарий тестирования
В качестве тест-кейса рассматривалась простая аналитическая задача — поиск значений в расположенном в памяти целочисленном массиве, удовлетворяющих заданному условию. В виде SQL-запроса эту задачу можно было бы записать так:
SELECT value FROM values WHERE value BETWEEN value_low AND value_high;Задачу планировалось решать двумя способами — классическим перебором всех элементов и с помощью сопроцессоров DAX.
Реализация
На языке C решение этой задачи выглядело приблизительно следующим образом:
#define RANDOM_SEED 42
int *values, *results;
int low = VALUE_LOW, high = VALUE_HIGH;
values = generate_random_values_array(NUM_VALUES, RANDOM_SEED);
results = malloc(NUM_VALUES * sizeof(int));
for (i=0; i= low && values[i] <= high) {
results[n] = values[i];
n++;
}
} Отметим, что при поиске сразу происходит сохранение результатов в новый массив. Еще раз отметим, что вышеприведенный код выполняется на ядре основного процессора.
Для DAX поиск и получение результатов разделены на две операции:
#include /* DAX */
#define RANDOM_SEED 42
int low = VALUE_LOW, high = VALUE_HIGH;
vector valuesVec, bitVec, resultsVec;
valuesVec = generate_random_values_vector(NUM_VALUES, RANDOM_SEED);
/* Поиск */
bitVec = vector_in_range(valuesVec, &low, &high);
/* Подсчёт количества значений, удовлетворяюших условию */
n = bit_vector_count(bitVec);
/* Извлечение значений, удовлетворяюших условию */
resultsVec = vector_extract(valuesVec, bitVec); В случае с DAX операция поиска значений (функция vector_in_range), удовлетворяющих условию, возвращает битовый вектор (bit vector), на основе которого еще одним запросом (vector_extract) формируется новый вектор с результатами. Искомые записи будут извлечены из своих IMCU и записаны в новые IMCU, с которыми снова можно работать через DAX.
Такой подход позволяет эффективно работать с наборами данных типа ключ/значение, когда требуется найти ключи, значения которых удовлетворяют условию. В этом случае в памяти формируются два массива данных — вектор ключей и вектор значений:
vector keysVec, valuesVec;
int low = VALUE_LOW, high = VALUE_HIGH;
populateKeyValueVectors(&keysVec, &valueVec);Выполняется поиск по вектору значений с помощью DAX, результатом которого является битовая карта:
bitVec = vector_in_range(valuesVec, &low, &high);Для извлечения искомых элементов полученная битовая карта применяется с помощью DAX к вектору ключей:
resultsVec = vector_extract(keysVec, bitVec);К тому же над множеством битовых векторов можно проводить операции типа AND и OR, то есть перекладывать на DAX объединение результатов нескольких сравнений, как, например, в запросе:
SELECT part FROM parts WHERE mass > 100 AND volume < 30;Наши эксперименты с объединением через AND двух битовых векторов показали преимущество вызова, выполненного на DAX:
bit_vector_and2(bitVec1, bitVec2);Перед поэлементным (с элементами типа long) объединением битовых карт на процессоре вида:
for (i=0; iв 3–6 раз по скорости выполнения в зависимости от количества элементов.
Но вернемся к программе. Элементами нашего массива будут случайные целые числа, а поиск будет выполняться по диапазону от –109 до 109 (то есть примерно половина чисел будет удовлетворять условию).
Мы запустили оба варианта реализации нашего теста несколько раз на количествах чисел в массиве от 1 миллиона до 500 миллионов и измерили время выполнения поиска и время копирования результатов в новый массив, с которым можно снова работать. Для классического перебора не имеет смысла разделять эти две операции, т.к. копировать в новый массив придется либо адрес элемента (8 байт), либо сам элемент (4 байта).
Результаты
Итак, ниже представлен график зависимости времени поиска и получения данных от количества элементов массива:
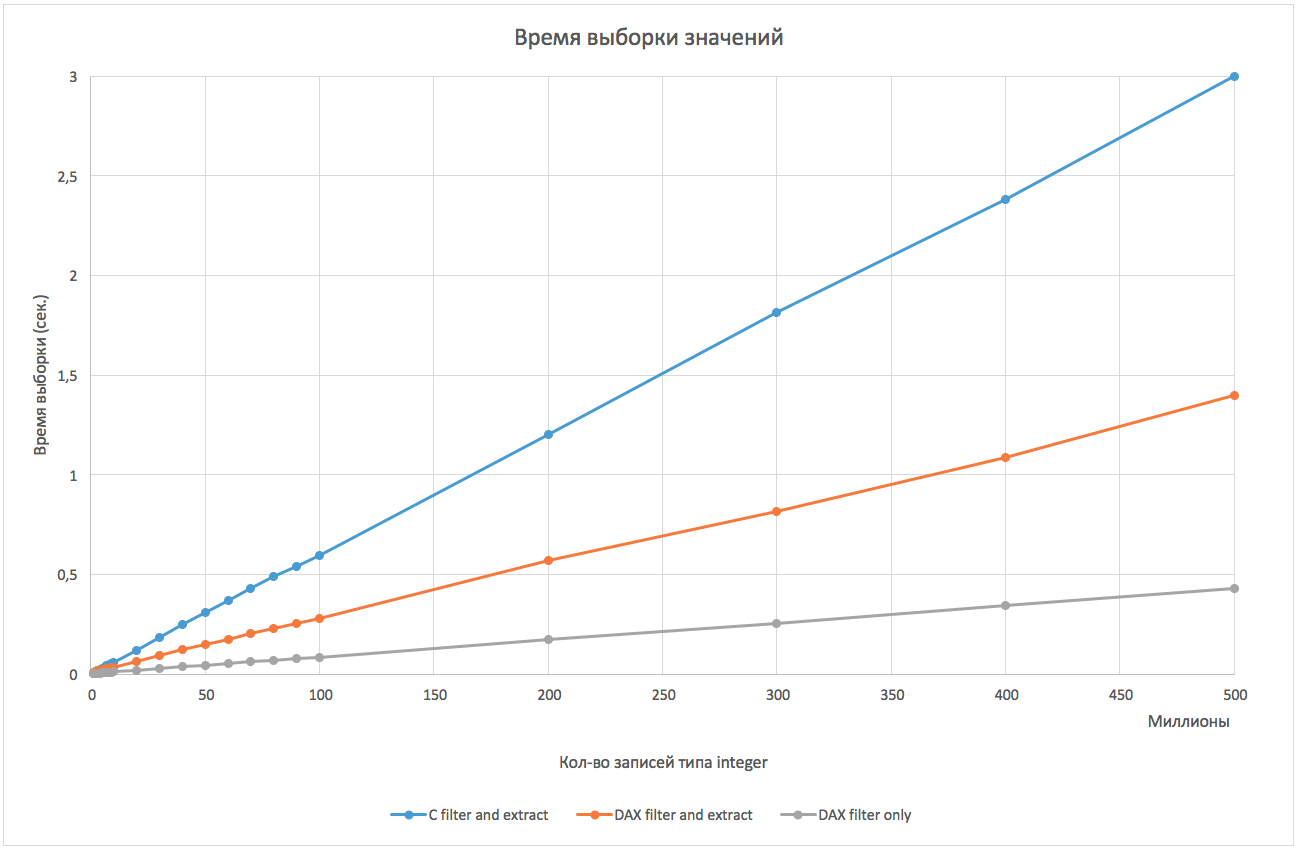
Использование DAX показало 2-кратное превосходство над простым перебором. Если сравнивать только поиск (без сохранения найденных значений, т.е. при выполнении операции вида «SELECT COUNT (*)» или в целях получения битовой карты), то скорость поиска через DAX более чем в 5 раз выше.
Следить за использованием сопроцессоров в системе можно с помощью утилиты busstat, собирающей метрики производительности с различных компонентов процессора (busstat -w dax 30 1). Во время выполнения наших тестов мы наблюдали распараллеливание запросов на 8 из 32 сопроцессоров DAX (в каждом процессоре M7 их по восемь). При использовании нескольких пользовательских процессов параллельно загрузка будет видна на всех 32 сопроцессорах.
Безусловно, можно реализовать все алгоритмы DAX программно (что и было реализовано в Oracle Database In-Memory Option до появления DAX), сделать дополнительные оптимизации и получить ещё более впечатляющие результаты, чем с DAX (особенно если вручную распараллелить задачу на все процессорные нити SPARC M7). Но назначение DAX в том, чтобы переложить работу ядер процессора на специализированные сопроцессоры. Т.е. в целом важен не сам прирост производительности, а именно возможность разгрузки основного CPU.
Прочие интересные моменты
В числе примеров кода для DAX инженеры Oracle реализовали его поддержку в приложении для Apache Spark. По заверениям производителя, при использовании DAX производительность выросла в 6 раз. Суть оптимизации заключалась во множестве операций с битовыми картами через DAX, что получилось гораздо быстрее, чем на процессоре.
Выводы
Перенос исполнения программной логики с процессоров на специализированные устройства в очередной раз доказал свою целесообразность. Особенно в такой «горячей» в настоящий момент области как In-Memory Computing.
Возможность использовать DAX через открытый API может привлечь в мир SPARC новые программные продукты.
Однако подобные функции могут быть реализованы в будущем и на платформе Intel на уже существующих аппаратных решениях — с использованием сопроцессора Xeon Phi. Как минимум исследования в этой области уже ведутся:
- Rethinking SIMD Vectorization for In-Memory Databases.
- Design of an In-Memory Database Engine Using Intel Xeon Phi Coprocessors.
Post Scriptum
Тестовые программы собирались с помощью компилятора Solaris Studio 12.4. Использовался максимальный уровень оптимизации (-xO5), с помощью которого удавалось значительно ускорить «классические» вычисления. Исходные коды доступны на github.
SPARC M7 и DAX — официальный релиз Oracle.
Статья подготовлена Дмитрием Глушенком, системным архитектором Центра проектирования вычислительных комплексов компании «Инфосистемы Джет». Мы будем рады вашим конструктивным комментариям.
