Apache Superset. Первый взгляд на BI инструмент
В последнее время изучая вакансии на сайтах по поиску работы, все чаще стал отмечать, что помимо платных инструментов BI от кандидатов требуется знание еще бесплатных платформ. Мой предыдущий опыт работы по построению графической отчетности был связан исключительно с коммерческими продуктами, поэтому я решил выделить время на ознакомление с альтернативными решениями. Выбор Superset был случайным, так как я обратил внимание на него лишь потому, что он входит в экосистему Apache. Сразу хочу оговориться, что в данной заметке не будет сравнения Superset с платными инструментами. Такое сопоставление функционала просто некорректно из-за разных «весовых категорий». Также я не буду выделять плюсы и минусы решения по сравнению с бесплатными аналогами, так как это очень дискуссионный вопрос. Неизбежно найдутся адепты того или иного продукта, которые будут доказывать ошибочность моих суждений. Поэтому я построил публикацию в форме простого описания «нюансов», которые я выделил для себя, начав знакомство с Superset. Читатели же сами смогут сделать свои выводы.
Тестирование Superset решил начать с полноценной установки программы на Linux (Debian). Несмотря на то, что я полностью выполнил список действий, описанный в документации, данный эксперимент завершился ошибкой. Попытка с запуском docker образа удалась с первого раза, список команд на Docker Hub. Как и в случае с Apache Airflow на этапе развертывания системы разработчики предлагают загрузить демонстрационные примеры. Я решил пропустить этот шаг (docker exec -it superset superset load_examples), чтобы в дальнейшем не удалять вручную предустановленные элементы. Вариант с разворачиваем сервиса из файла docker-compose.yml также попробовал. Список команд вы можете найти в официальном руководстве. Единственное замечание, я указал не последний релиз, а 1.5.0.
Далее нужно было настроить коннект к базе данных. Superset поддерживает возможность подключения к нескольким десяткам БД, но я выбрал PostgreSQL, как наиболее понятное для себя хранилище. На Хабр уже есть публикация («Поднимаем Apache Superset — необходимый и достаточный гайд»), в которой описан пошаговый алгоритм, но там приводился пример, где PostgreSQL запускается в docker контейнере. Мне же захотелось реализовать случай, когда БД установлена локально. Разумеется, когда на этапе настройки соединения я указал стандартные 127.0.0.1 и 5432 меня постигла неудача: порт был закрыт. Первая причина указана в документации (последние два абзаца), которую традиционно никто не читает. Вторая помеха кроется в первоначальных настройках самой PostgreSQL.
По умолчанию, PostgreSQL в целях безопасности принимает только локальные подключения. Чтобы разрешить подключения извне, нужно в файле postgresql.conf раскомментировать параметр и заменить localhost на звездочку: listen_addresses = '*'. Сам файл расположен по адресу /etc/postgresql/14/main/postgresql.conf. Отредактировать его напрямую не получиться, поэтому нужно прибегнуть к услугам терминала (root, плюс редактор nano или vim). Второй файл, в который необходимо внести изменения это pg_hba.conf (/etc/postgresql/14/main/pg_hba.conf). Добавляем в самый конец страницы строку: host all all 172.17.0.0/16 trust. Вместо trust нужно использовать scram-sha-256, если доступ требуется по паролю. Данный момент я также вычитал в Хабр публикации «Настройка PostgreSQL под Linux». Работаем из терминала, с количеством пробелов между словами не ошибетесь, так как в файле будут образцы для заполнения. На финальном шаге перезагружаем БД командой в терминале: systemctl restart postgresql. В настройках сервера PostgreSQL через pgAdmin4 ничего менять не нужно. Теперь можно перейти в веб-интерфейс Superset и указать верные значения для хоста и порта: 172.17.0.1 и 5432. Название базы данных, логин и пароль указываете исходя из ваших настроек.
Так как адреса хостов отличаются в рекомендациях из Интернета, советую проверить значения для вашего конкретного случая до начала правки файлов. Для этого в терминале последовательно введите две команды: docker network ls (для получения списка запущенных сетей, ищем id bridge), далее docker network inspect id. Нас интересуют пункты: Subnet: 172.17.0.0/16 и Gateway: 172.17.0.1. Так как я не devops и не администратор БД, я не могу утверждать, что приведенные настройки адекватны с точки зрения безопасности. Поэтому не рекомендую использовать их без дополнительной консультации со специалистом на боевой БД! Все эксперименты только в тестовой среде и на демо БД.
Базовый алгоритм работы с Superset можно описать четырьмя шагами.
Шаг 1. Настроить коннект к БД (Databases).
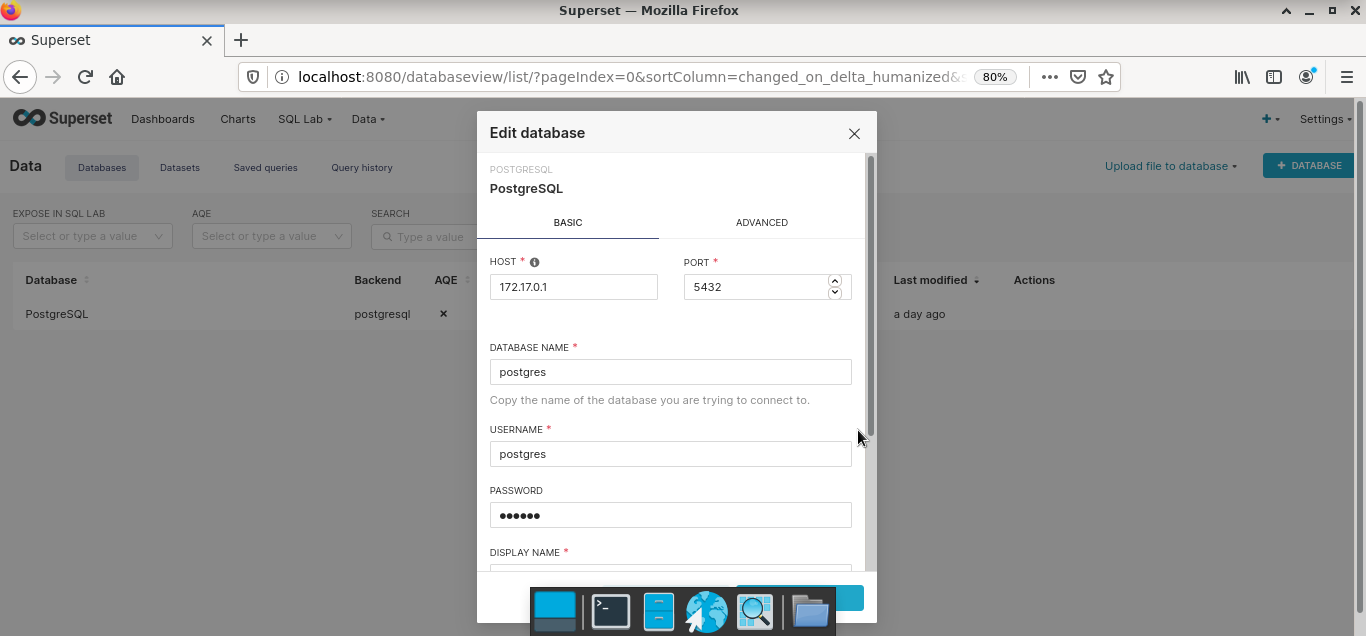 Настройка подключения к БД
Настройка подключения к БД
Шаг 2. Подключить физические таблицы / представления к «витринам» платформы (Datasets). Если требуется «вытащить» агрегированные данные, то можно написать запрос в разделе SQL Lab и сохранить результат как датасет.
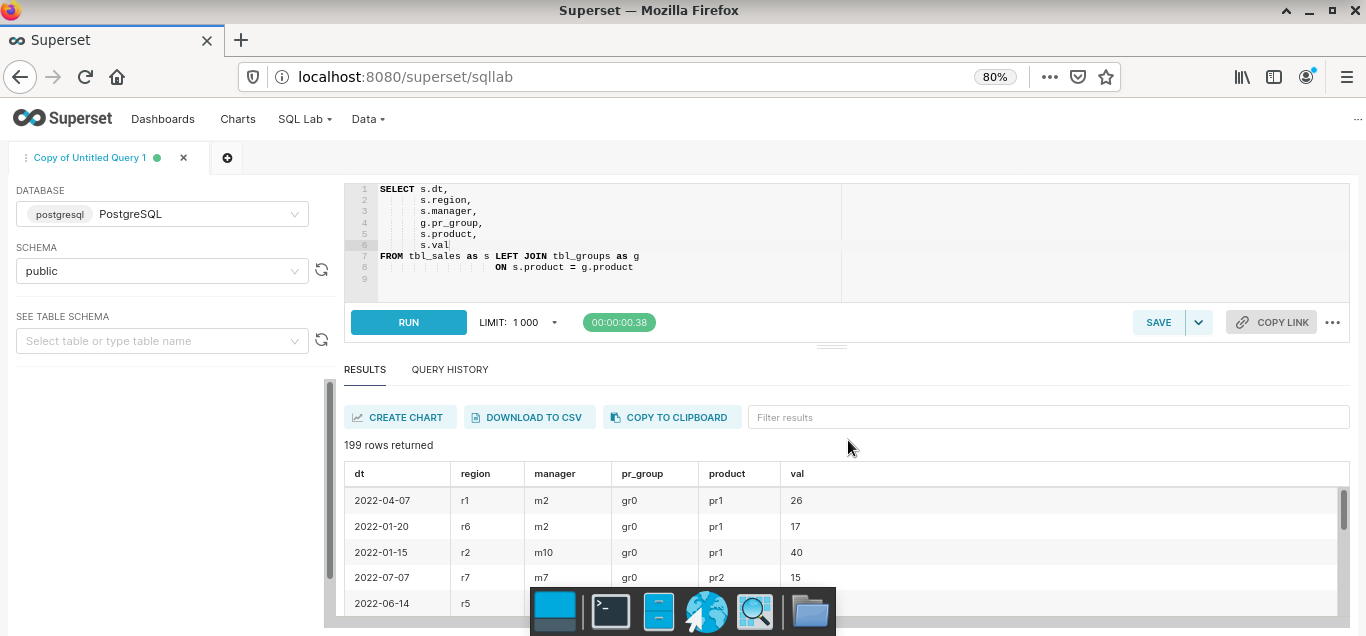 Запрос к БД, который будет сохранен как датасет
Запрос к БД, который будет сохранен как датасет
Для созданных датасетов можно рассчитывать базовые метрики.
 Формирование базовых метрик, которые можно будет использовать на этапе создания графиков и диаграмм
Формирование базовых метрик, которые можно будет использовать на этапе создания графиков и диаграмм
Шаг 3. Сформировать в режиме виртуального конструктора на основе датасетов отдельные графики и диаграммы (Charts). Superset из коробки содержит большой набор типовых визуализаций. Возможно создавать кастомные решения. Насколько целесообразна данная затея — большой вопрос, так как я еще ни разу не видел, чтобы замысловатая диаграмма приводила к инсайту менеджера. А вот когда все было наоборот, такие случаи мне известны.
 Создание графика в режиме визуального конструктора
Создание графика в режиме визуального конструктора
Шаг 4. Создать новую управленческую панель путем простого перетаскивания созданных элементов (Dashboards). По данному шагу у меня будут два замечания. Во-первых, на рисунке видно, что в отчете применены два типа фильтров. Вариант в левом углу, создается на этапе моделирования дашборда, он более современный и рекомендуется к использованию. Элементы для фильтрации, включенные в тело самого дашборда, как отдельные элементы — устаревший подход, о чем вам будет сигнализировать всплывающее окно. Во-вторых, на части визуальных элементов присутствуют надписи на языке Шекспира. От части из них можно избавиться с помощью имеющихся настроек, вот удастся ли добиться 100%-ого перевода я не уверен. Лично мне в результате беглой рекогносцировки этого не удалось, но перфекционистам с хорошим знанием программирования эта задача будет по плечу.
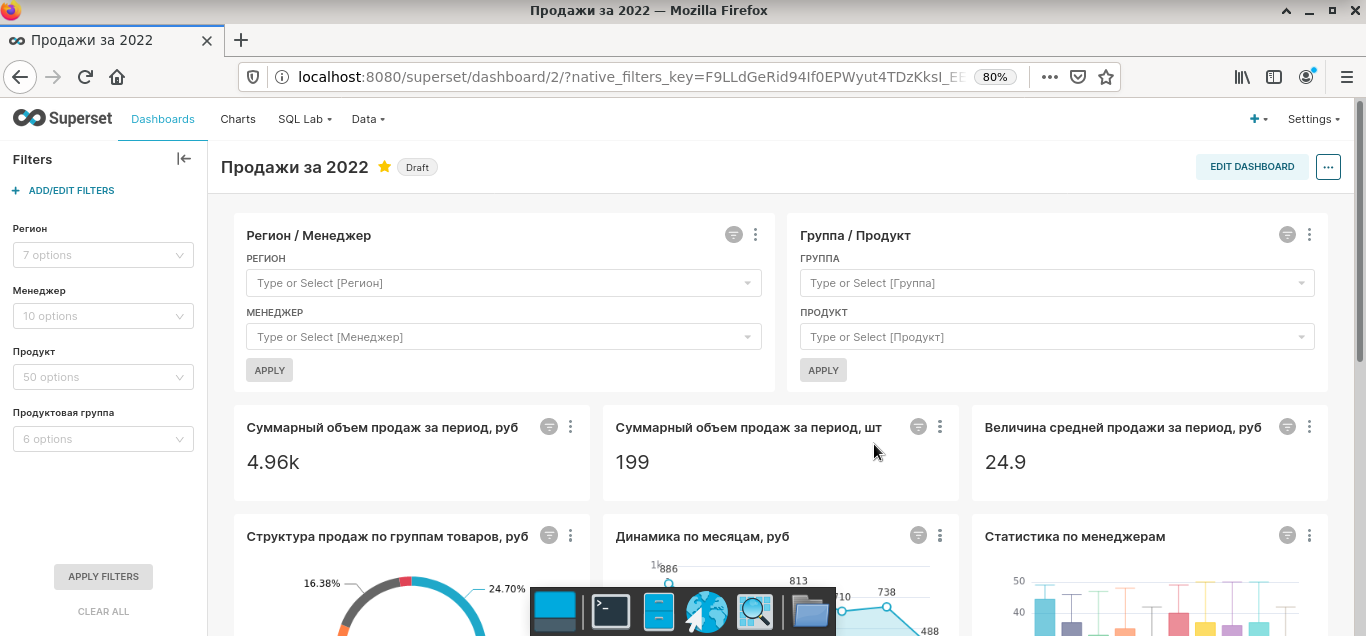 Прототипирование дашборда
Прототипирование дашборда
В целом интерфейс программы интуитивно понятен. Базовые возможности реализованы практически также, как и у аналогичных продуктов. Поэтому заострять внимание на них нет смысла. Если разобраться с функционалом программы, то дашборд, как на приведенном рисунке, можно собрать за считанные минуты.
 В программе реализована возможность сохранения дашборда в формате JPEG
В программе реализована возможность сохранения дашборда в формате JPEG
Работать напрямую с файлами txt, csv, xlsx нельзя. Нужно предварительно загружать информацию в БД и только потом писать SQL запросы. Заливка информации возможна прямо из интерфейса, но нужно разрешить данную операцию в настройках БД. Инструментов для предварительной обработки сырых данных нет. Поэтому быстрая ad hoc аналитика со сбором данных из разрозненных плохо структурированных файлов с помощью Superset крайне затруднена. Так как SQL, по сути, основной язык платформы, то и реализация сложных расчетов на стыке данных из разных датасетов будет также проблематична. Но функциональность языка можно расширить путем использования шаблонов Jinja в запросах.
Для старта работы с Superset от специалистов компании могут потребоваться следующие вещи.
Если Superset еще не установлен — нужны знания бэкенд-разработчика: умение работать с Docker; базовые команды терминала Linux; настройка Flask, Redis, Celery; выбор веб-сервера для платформы и т.д. Важно понимать, что данный BI инструмент это продукт с открытым исходным кодом. Это дает плацдарм для доработки под нужды бизнеса, но, с другой стороны, требует затрат времени на грамотную настройку компонентов системы и последующую утилизацию возможностей (как пример, возможность взаимодействия с артефактами Superset посредством Rest API).
Если продукт уже развернут, но подходящее DWH отсутствует — навыки дата инженера данных: создание Data Lake для сырых логов; ETL/ELT; умение выбрать, установить и настроить DWH (возможно колоночную базу данных, чтобы ускорить обработку запросов).
Если в DWH уже есть подготовленные витрины с актуальными данными — знание SQL хотя бы на среднем уровне, плюс экспресс-курс по возможностям BI решения.
Вместо выводов. Apache Superset — интересный продукт со своим характером. BI инструмент плохо подходит для срочной разработки дашбордов на основе разрозненных источников данных. Из-за нюансов платформы на этапе внедрения нетехническим компаниям обязательно потребуется помощь в установке и настройке. В организациях, где хорошо развита культура дата инжиниринга, Superset вполне может использоваться для создания несложной регламентированной отчетности.
На этом все. Всем здоровья, удачи и профессиональных успехов!
