Apache NiFi: что это такое и краткий обзор возможностей
Сегодня на тематических зарубежных сайтах о Big Data можно встретить упоминание такого относительно нового для экосистемы Hadoop инструмента как Apache NiFi. Это современный open source ETL-инструмент. Распределенная архитектура для быстрой параллельной загрузки и обработки данных, большое количество плагинов для источников и преобразований, версионирование конфигураций — это только часть его преимуществ. При всей своей мощи NiFi остается достаточно простым в использовании.
Мы в «Ростелекоме» стремимся развивать работу с Hadoop, так что уже попробовали и оценили преимущества Apache NiFi по сравнению с другими решениями. В этой статье я расскажу, чем нас привлек этот инструмент и как мы его используем.
Предыстория
Не так давно мы столкнулись с выбором решения для загрузки данных из внешних источников в кластер Hadoop. Продолжительное время для решения подобных задач у нас использовался Apache Flume. К Flume в целом не было никаких нареканий, кроме нескольких моментов, которые нас не устраивали.
Первое, что нам, как администраторам, не нравилось — это то, что написание конфига Flume для выполнения очередной тривиальной загрузки нельзя было доверить разработчику или аналитику, не погруженному в тонкости работы этого инструмента. Подключение каждого нового источника требовало обязательного вмешательства со стороны команды администраторов.
Вторым моментом были отказоустойчивость и масштабирование. Для тяжелых загрузок, например, по syslog, нужно было настраивать несколько агентов Flume и ставить перед ними балансировщик. Все это затем нужно было как-то мониторить и восстанавливать в случае сбоя.
В-третьих, Flume не позволял загружать данные из различных СУБД и работать с некоторыми другими протоколами «из коробки». Конечно, на просторах сети можно было найти способы заставить работать Flume с Oracle или с SFTP, но поддержка таких «велосипедов» — занятие совсем не из приятных. Для загрузки данных из того же Oracle приходилось брать на вооружение еще один инструмент — Apache Sqoop.
Откровенно говоря, я по своей натуре являюсь человеком ленивым, и мне совсем не хотелось поддерживать зоопарк решений. А еще не нравилось, что всю эту работу приходится выполнять самому.
Есть, разумеется, достаточно мощные решения на рынке ETL-инструментов, которые умеют работать с Hadoop. К ним можно отнести Informatica, IBM Datastage, SAS и Pentaho Data Integration. Это те, о которых чаще всего можно услышать от коллег по цеху и те, что первыми приходят на ум. К слову, у нас используется IBM DataStage для ETL на решениях класса Data Warehouse. Но так уж исторически сложилось, что использовать DataStage для загрузок в Hadoop наша команда не имела возможности. Опять же, нам не нужна была вся мощь решений такого уровня для выполнения достаточно простых преобразований и загрузок данных. Что нам требовалось, так это решение с хорошей динамикой развития, умеющее работать со множеством протоколов и обладающее удобным и понятным интерфейсом, с которым способен справиться не только администратор, разобравшийся во всех его тонкостях, но и разработчик с аналитиком, которые зачастую и являются для нас заказчиками самих данных.
Как вы могли понять из заголовка, мы решили перечисленные проблемы с помощью Apache NiFi.
Что такое Apache NiFi
Название NiFi происходит от «Niagara Files». Проект в течение восьми лет разрабатывался агентством национальной безопасности США, а в ноябре 2014 года его исходный код был открыт и передан Apache Software Foundation в рамках программы по передаче технологий (NSA Technology Transfer Program).
NiFi — это open source ETL/ELT-инструмент, который умеет работать со множеством систем, причем не только класса Big Data и Data Warehouse. Вот некоторые из них: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. Ознакомиться с полным списком можно в официальной документации.
Работа с конкретной СУБД реализуется за счет добавление соответствующего JDBC-драйвера. Есть API для написания своего модуля в качестве дополнительного приемника или преобразователя данных. Примеры можно найти здесь и здесь.
Основные возможности
В NiFi используется веб-интерфейс для создания DataFlow. С ним справится и аналитик, который совсем недавно начал работать с Hadoop, и разработчик, и бородатый админ. Последние двое могут взаимодействовать не только с «прямоугольниками и стрелочками», но и с REST API для сбора статистики, мониторинга и управления компонентами DataFlow.
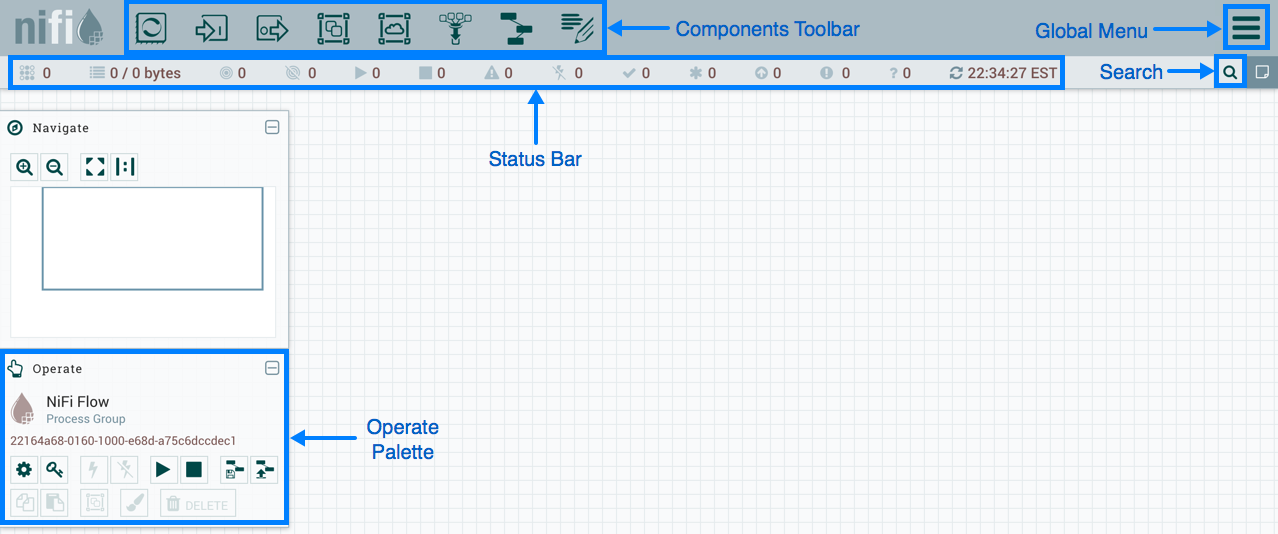
Веб-интерфейс управления NiFi
Ниже я покажу несколько примеров DataFlow для выполнения некоторых обыденных операций.
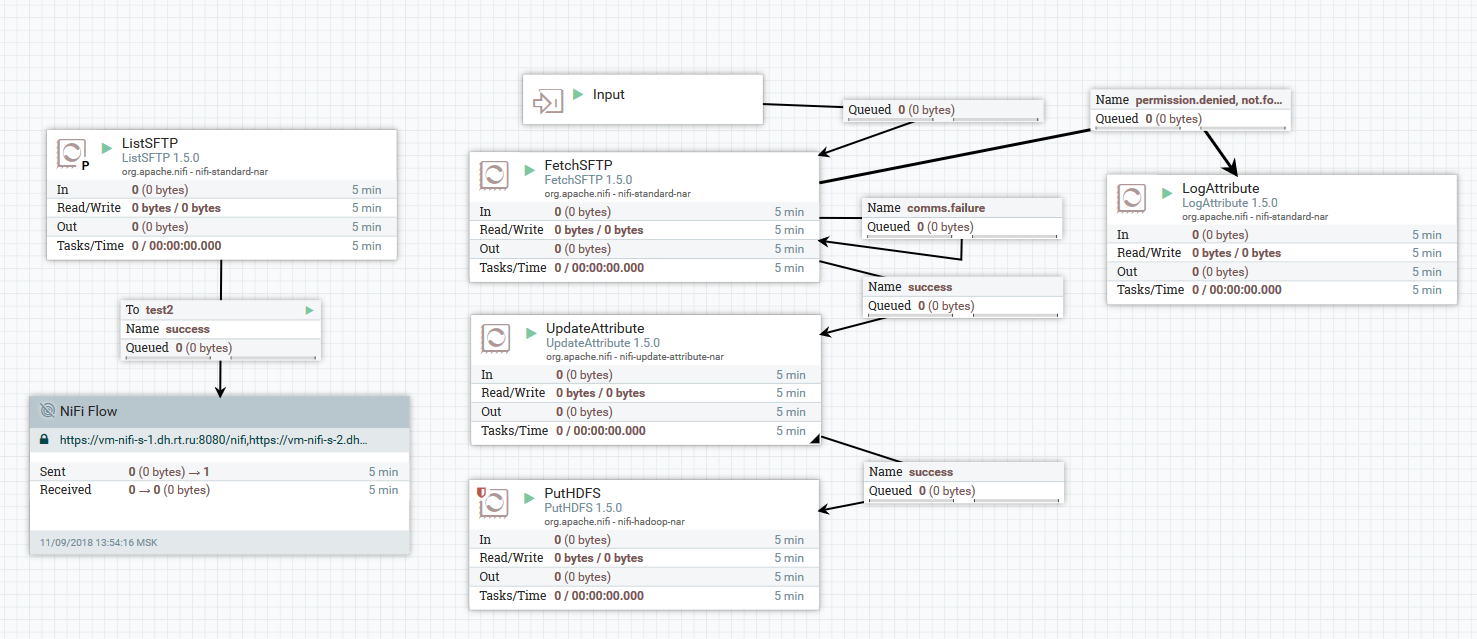
Пример загрузки файлов с SFTP-сервера в HDFS
В этом примере процессор «ListSFTP» делает листинг файлов на удаленном сервере. Результат этого листинга используется для параллельной загрузки файлов всеми нодами кластера процессором «FetchSFTP». После этого, каждому файлу добавляются атрибуты, полученные путем парсинга его имени, которые затем используются процессором «PutHDFS» при записи файла в конечную директорию.
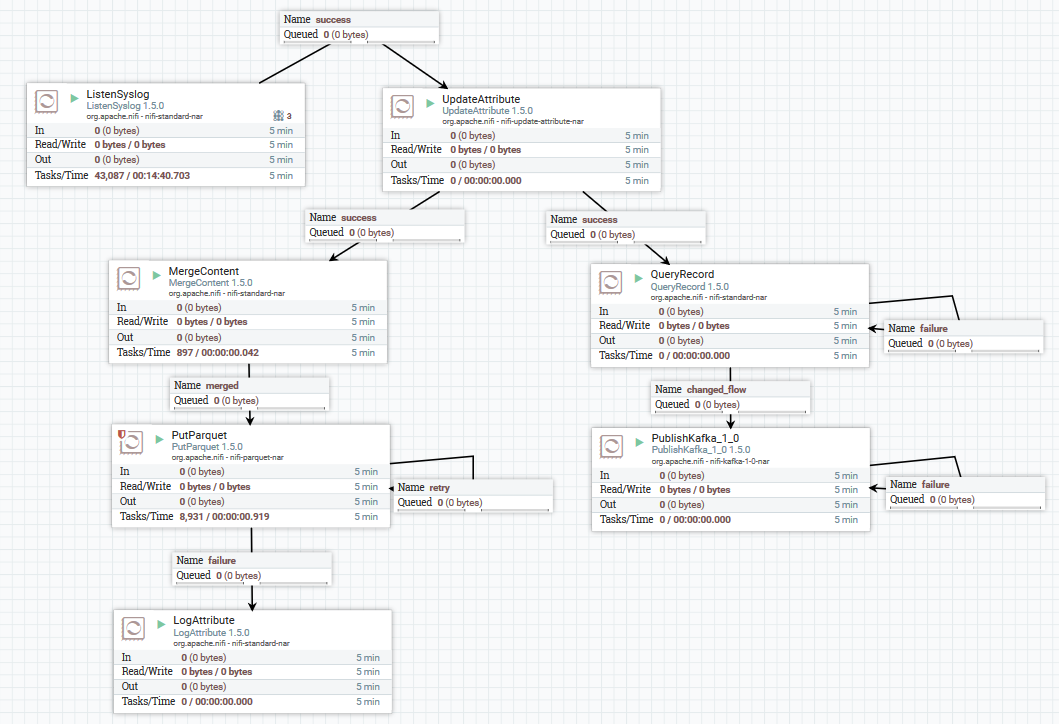
Пример загрузки данных по syslog в Kafka и HDFS
Здесь с помощью процессора «ListenSyslog» мы получаем входной поток сообщений. После этого каждой группе сообщений добавляются атрибуты о времени их поступления в NiFi и название схемы в Avro Schema Registry. Далее первая ветвь направляется на вход процессору «QueryRecord», который на основе указанной схемы читает данные и выполняет их парсинг с помощью SQL, а затем отправляет их в Kafka. Вторая ветвь направляется процессору «MergeContent», который агрегирует данные в течение 10 минут, после чего отдает их следующему процессору для преобразования в формат Parquet и записи в HDFS.
Вот пример того, как еще можно оформить DataFlow: 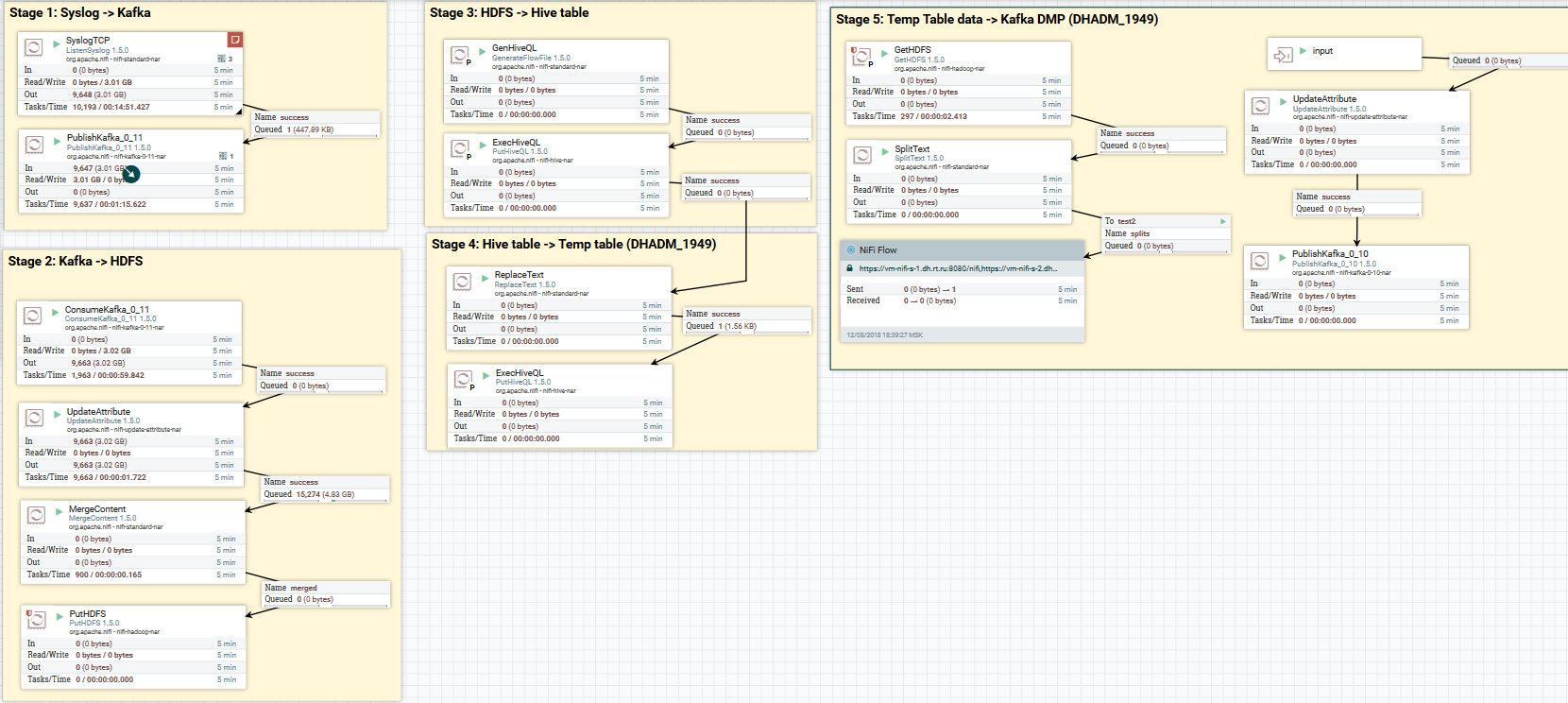
Загрузка данных по syslog в Kafka и HDFS. Очистка данных в Hive
Теперь о преобразовании данных. NiFi позволяет парсить данные регуляркой, выполнять по ним SQL, фильтровать и добавлять поля, конвертировать один формат данных в другой. Еще в нем есть собственный язык выражений, богатый различными операторами и встроенными функциями. С его помощью можно добавлять переменные и атрибуты к данным, сравнивать и вычислять значения, использовать их в дальнейшем при формировании различных параметров, таких как путь для записи в HDFS или SQL-запрос в Hive. Подробнее можно прочитать тут.
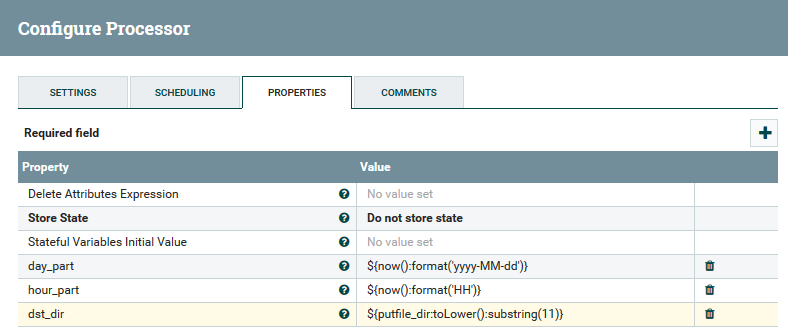
Пример использования переменных и функций в процессоре UpdateAttribute
Пользователь может отслеживать полный путь следования данных, наблюдать за изменением их содержимого и атрибутов.
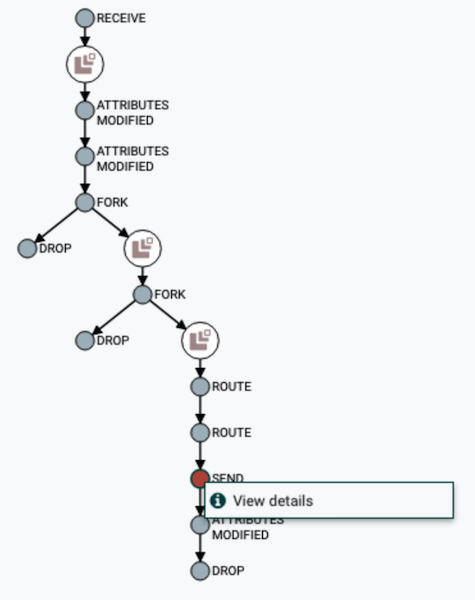
Визуализация цепочки DataFlow
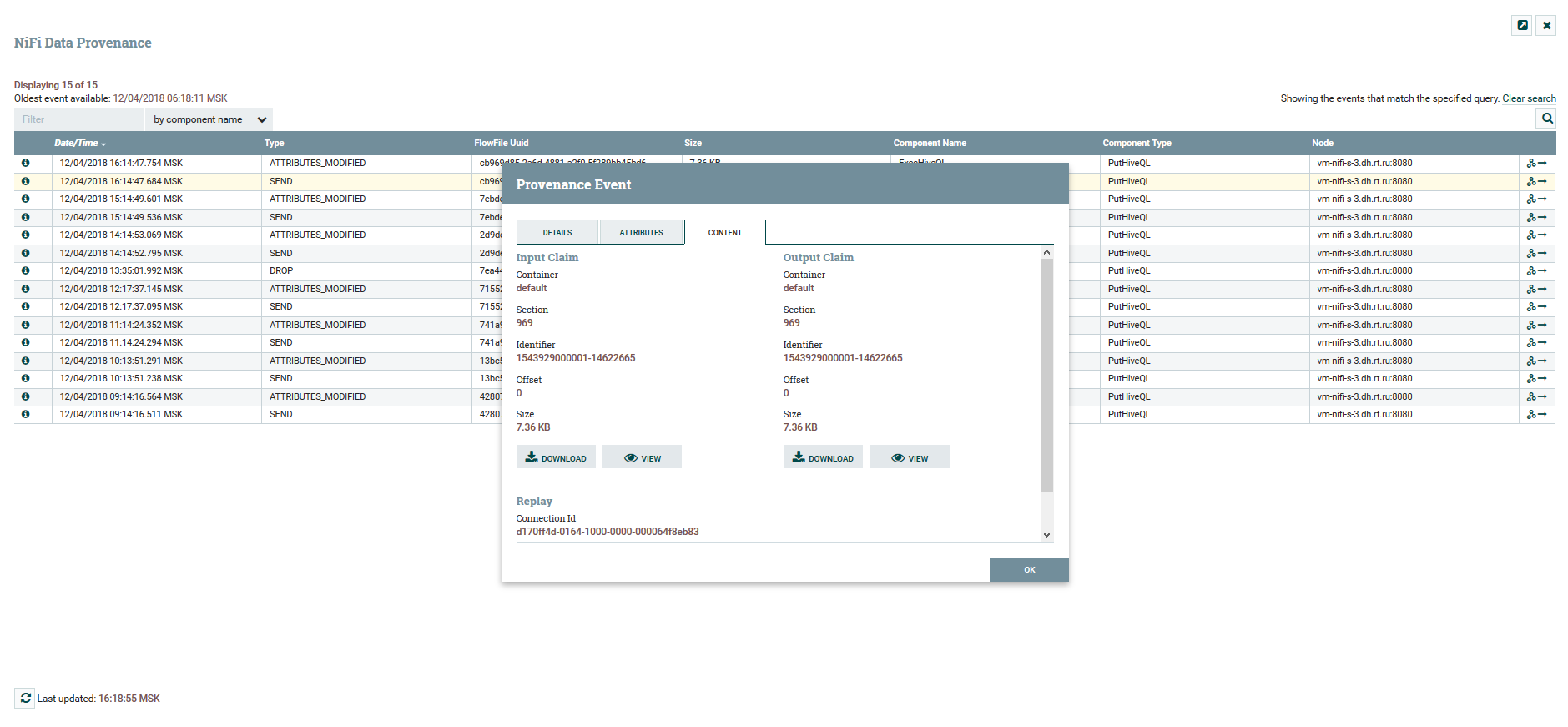
Просмотр содержимого и атрибутов данных
Для версионирования DataFlow есть отдельный сервис NiFi Registry. Настроив его, вы получаете возможность управлять изменениями. Можно запушить локальные изменения, откатиться назад или загрузить любую предыдущую версию.

Меню Version Control
В NiFi можно управлять доступом к веб-интерфейсу и разделением прав пользователей. На текущий момент поддерживаются следующие механизмы аутентификации:
- На основе сертификатов
- На основе имени пользователя и пароля посредством LDAP и Kerberos
- Через Apache Knox
- Через OpenID Connect
Одновременное использование сразу нескольких механизмов не поддерживается. Для авторизации пользователей в системе используются FileUserGroupProvider и LdapUserGroupProvider. Подробнее про это можно прочитать здесь.
Как я уже говорил, NiFi умеет работать в режиме кластера. Это обеспечивает отказоустойчивость и дает возможность горизонтально масштабировать нагрузку. Статично зафиксированной мастер-ноды нет. Вместо этого Apache Zookeeper выбирает одну ноду в качестве координатора и одну в качестве primary. Координатор получает от других нод информацию об их состоянии и отвечает за их подключение и отключение от кластера.
Primary-нода служит для запуска изолированных процессоров, которые не должны запускаться на всех нодах одновременно.
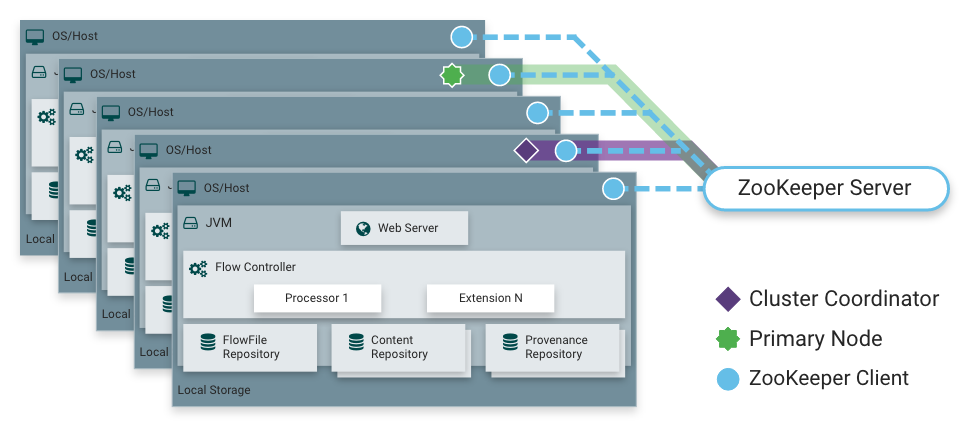
Работа NiFi в кластере
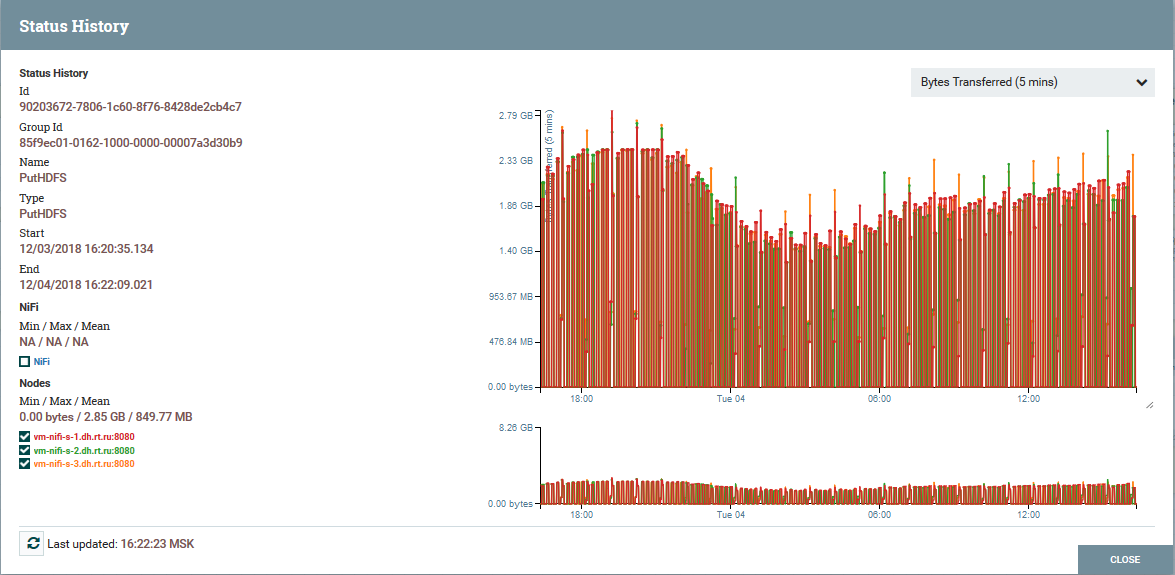
Распределение нагрузки по нодам кластера на примере процессора PutHDFS
Краткое описание архитектуры и компонентов NiFi

Архитектура NiFi-инстанса
NiFi опирается на концепцию «Flow Based Programming» (FBP). Вот основные понятия и компоненты, с которыми сталкивается каждый его пользователь:
FlowFile — сущность, представляющая собой объект с содержимым от нуля и более байт и соответствующих ему атрибутов. Это могут быть как сами данные (например, поток Kafka сообщений), так и результат работы процессора (PutSQL, например), который не содержит данных как таковых, а лишь атрибуты сгенерированные в результате выполнения запроса. Атрибуты представляют собой метаданные FlowFile.
FlowFile Processor — это именно та сущность, которая выполняет основную работу в NiFi. Процессор, как правило, имеет одну или несколько функций по работе с FlowFile: создание, чтение/запись и изменение содержимого, чтение/запись/изменение атрибутов, маршрутизация. Например, процессор «ListenSyslog» принимает данные по syslog-протоколу, на выходе создавая FlowFile«ы с атрибутами syslog.version, syslog.hostname, syslog.sender и другими. Процессор «RouteOnAttribute» читает атрибуты входного FlowFile и принимает решение о его перенаправлении в соответствующее подключение с другим процессором в зависимости от значений атрибутов.
Connection — обеспечивает подключение и передачу FlowFile между различными процессорами и некоторыми другими сущностями NiFi. Connection помещает FlowFile в очередь, после чего передает его далее по цепочке. Можно настроить, как FlowFile«ы выбираются из очереди, их время жизни, максимальное количество и максимальный размер всех объектов в очереди.
Process Group — набор процессоров, их подключений и прочих элементов DataFlow. Представляет собой механизм организации множества компонентов в одну логическую структуру. Позволяет упростить понимание DataFlow. Для получения и отправки данных из Process Groups используются Input/Output Ports. Подробнее об их использовании можно прочитать здесь.
FlowFile Repository — это то место, в котором NiFi хранит всю известную ему информацию о каждом существующем в данный момент FlowFile в системе.
Content Repository — репозиторий, в котором находится содержимое всех FlowFile, т.е. сами передаваемые данные.
Provenance Repository — содержит историю о каждом FlowFile. Каждый раз, когда с FlowFile происходит какое-либо событие (создание, изменение и т.д.), соответствующая информация заносится в этот репозиторий.
Web Server — предоставляет веб-интерфейс и REST API.
Заключение
С помощью NiFi «Ростелеком» смог улучшить механизм доставки данных в Data Lake на Hadoop. В целом, весь процесс стал удобнее и надежнее. Сегодня я могу с уверенностью сказать, что NiFi отлично подходит для выполнения загрузок в Hadoop. Проблем в его эксплуатации у нас не возникает.
К слову, NiFi входит в дистрибутив Hortonworks Data Flow и активно развивается самим Hortonworks. А еще у него есть интересный подпроект Apache MiNiFi, который позволяет собирать данные с различных устройств и интегрировать их в DataFlow внутри NiFi.
Дополнительная информация о NiFi
Пожалуй, на этом все. Спасибо всем за внимание. Пишите в комментариях, если у вас есть вопросы. С удовольствием на них отвечу.
