Анти–Тьюринг
В.А. Крюков
VAK_53@mail.ru
Догмы спокойного прошлого не годятся для бурного настоящего.
А. Линкольн
Введение
«Предлагаемый труд вовсе не есть плод какого–нибудь «внутреннего побуждения»[1], а результат анализа производственной задачи разработки системы управления экспериментальной технологической установкой типа автоклава. Согласно ТЗ необходимо было обеспечить быструю перенастройку установки для проведения новых экспериментов. Процесс проектирования системы управления привел к неожиданным результатам, который заставил вернуться к основам и философски переосмыслить некоторые привычные положений программирования.
Прямая и обратная польские записи как борьба и единство противоположностей
Теоретическая основа современных трансляторов для компьютеров базируются на обратной польской записи для создания объектного кода программ, выполняемых в стеке. Но из теории известно, что помимо обратной, или суффиксной польской записи, имеет место быть и прямая польская запись — префиксная [1].
О ее свойствах и применении практически ничего неизвестно. В русском переводе многотомного «Искусство программирования для ЭВМ» Д.Кнута [2] вскользь указывается на наличие двух форм «польских обозначений» и говорится, что польская запись имеет непосредственное отношение к трем основным порядкам прохождения деревьев. Известно еще, что Lisp для записи языковых конструкций использует префиксную польскую запись по форме, но для вычисления использует ее свертку на стеке.
Возникают вопросы: можно ли вторую форму польской записи тоже использовать в вычислении? Чем отличается такой вычислитель? Запрос темы в поисковых машинах Internet «использование префиксной польской записи в вычислителе» ничего не выдает.
Проведем сравнительный анализ и синтез вычислителя прямой польской записи самостоятельно.
Напомним суть преобразования выражения в польскую запись. Начнем с простого арифметического выражения (7–5)*(1+1).
Соответствующая ему обратная польская запись:
7 5 — 1 1 + *.
В последовательности вначале идут параметры, которые завершаются знаком операции.
И соответствующей прямой польской записью будет:
(*(– 7 5) (+ 1 1)).
В последовательности вначале идет знак операции, за которым следуют параметры. Для удобства восприятия полученной прямой польской записи она дана в синтаксисе языка Lisp с круглыми скобками, которые можно опустить без потери смысла.
В результате преобразования инфиксного арифметического выражения в обратную польскую запись получается свертка выражения в объектный код, который в потоке можно передавать в стек для автоматического вычисления выражения. В результате такой свертки мы имеем простые машинные представления и эффективные вычислительные средства, что является несомненным достоинством обратной польской записи.
В свою очередь анализ прямой польской записи выражения показывает, что она является сверткой дерева решения, которая при чтении записи в потоке (по аналогии с объектным кодом) легко развертывается в иерархическую структуру дерева. Граф развернутого дерева решения рассмотренного выражения представлен на рис. 1.
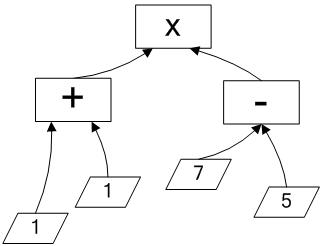 Рис. 1. Граф дерево решения, развернутое при однопроходном чтении прямой польской записи.
Рис. 1. Граф дерево решения, развернутое при однопроходном чтении прямой польской записи.
Направление стрелок графа задает направление потока данных вычисления решения. Граф дерева решения является обратно ориентированным деревом в смысле теория графов: дуги направлены от листьев через узлы к вершине. Узлы дерева решения содержат знаки операций, листья — числовые аргументы операций. Количество входящих дуг узла показывает арность соответствующей операции.
В отличии от объектного кода обратной польской записи, приспособленного для вычислении на стеке[2], код прямой польской записи подготовлен к транслированию в древовидную структуру вычислителей, принимающих потоки данных. Заметим, что подчиненные ветки дерева решения (поддеревья вычисления) »–» и »+» могут быть в процессе развертки программы[3] в структуру дерева переданы на другие распределенные узлы коллектива вычислителей.
Выбор способа реализация узла остается за разработчиком программы. Узел может рассматриваться как черный ящик с заданным функционалом и программным интерфейсом. Предпочтение разработчика может отдано отлаженным быстрым узлам на традиционных языках программирования, как например, C и Python. Здесь мы в описании абстракции дерева решений забежали немного вперед, но необходимо было подчеркнуть, что «чистое» дерево решений легко трансформируется в гетерогенное дерево, отдельные узлы которого представляют собой свертки обратной польской записи.
Для сохранения ясности и понимания как будет выполняться полученный код, важно на уровне программы сохранять структуру дерева решения для человеческого восприятия. При использовании обратной польской записи это не удается сделать: появляется семантический разрыв между программной сверткой алгоритма и прикладными знаниями, который не устраняется никакими надстройками типа объектно–ориентированного программирования [3] над базовым стековым механизмом выполнения программы.
И так, коренное отличие прямой польской записи от обратной — обратная польская запись является моделью потока операция (и функций) над полем данных, а прямая польская запись представляет поток данных над полем операций (и функций). Причем цели обеих моделей одинаковы — это формализация решения задач пользователя.
Решение квадратного уравнения с помощью дерева решения
В качестве примера отображения алгоритма на дерево решения рассмотрим обычное квадратное уравнение:
ax2 + bx + c = 0
В этом примере можно найти:
· элементы параллельного программирования, причем, потоки управления как распараллеливаются, так и сливаются в точке (узле),
· проблему гонки данных.
Традиционное описание алгоритма решения данного уравнения следующий:
1. Вычисление дискриминанта D по формуле
D = b2 — 4ac (1)
2. Если D < 0, то квадратное уравнение не имеет действительных корней: цепочка вычислений прерывается.
3. Если D ≥ 0, то квадратное уравнение имеет два или один корень:

и

Представим алгоритм в виде дерева решений в нотации, близкой по ГОСТ 19.701–90:
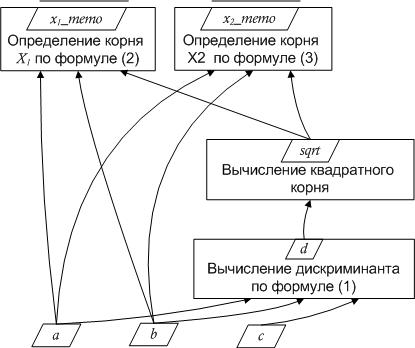 Рис. 2. Дерево решения квадратного уравнения
Рис. 2. Дерево решения квадратного уравнения
Схема на рис. 2 требует небольших комментариев:
схема не может быть получена трансляцией формул (1)–(3) в программу на современном языке программирования: схема по сути сама является программой;
потоковые данные a, b, c, d, sqrt и т.д. обозначены рамкой в форме косого четырехугольника, у конечных данных результата server_x1 и server_x2 над четырехугольником проведена черта, символизирующая, что в рамках данного алгоритма данные уже не передаются в другие узлы дерева решения; эти стационарные данные будем называть memo–данными,
узлы дерева решения являются исполняющимися блоками или функциями (об этом можно судить по надписям), в которые входят аргументы и выходит результат;
в дереве решения узлы не развернуты в элементарные операции, несущественный для потока управления функционал можно скрыть; например, узел sqrt показан без извлечения корня и без проверки дискриминанта на отрицательность. Да и вообще, узлы следует рассматривать как черный ящик.
Из схемы можно сделать несколько следующих выводов:
Для данного уровня абстракции неважно, откуда берутся первичные данные: они могут вводиться с клавиатуры, могут поступать из компьютерной сети, могут считываться с датчиков в режиме реального времени. Важно, что первичные данные поступают в дерево решения асинхронно. Фактически узлы a, b и с являются независимыми параллельными процессами генерации данных.
Восходящие параллельные потоки данных могут замыкаться, как, например, в узле d.
Исполняющие узлы могут поставлять результат, например, sqrt, параллельно в несколько адресов.
В примере вычислительный процесс делится на два независимых процесса в узлах x1 и x2. В программировании параллельных потоков это называется «распараллеливание по данным». В результате, дерево решений имеет две вершины. В общем случае их может быть еще больше и в конечном итоге мы можем иметь дело с лесом решений.
Узлы вычисления могут начать выполняться только по мере готовности их входных аргументов. Должна быть обеспечена синхронизация поступления данных на вход вычислителя. Если актуальность данных со временем может «испариться», возникает временной фактор, учет которого подводит к системам реального времени.
Узлы дерева решения можно агрегировать в более крупные блоки, которые скрывают несущественные мелкие детали вычислений. Их внутреннее устройство можно рассматривать как «черный ящик», о чем мы говорили ранее: блоки вычислений могут быть реализованы как угодно, в том числе стековым образом, т.к. программы на стеках показывают высокую производительность и вычислительную эффективность. Поэтому лучше иметь в виду именно гетерогенную архитектуру вычисления.
Завершение решения произойдет при получении данных в корнях дерева решения или при вычислении квадратного корня из отрицательного дискриминанта с выводом соответствующего предупреждения на экран терминала оператора, но цепочка вычисления корней будет постоянно готова к повторению вычисления при получении данных a, b и с.
Представленный шаблон может легко модифицироваться, адаптироваться и расширяться; например, по этой диаграмме можно описать выполнение процессов PID–регулятора, но это тема уже другой статьи.
Потоковые данные и memo–данные
Из рассмотренной схемы можно получить еще одно интересное заключение.
Данные на схеме на рис. 2 мы разделили на потоковые, которые передаются от узла к узлу, и хранимые, над которыми проведена горизонтальная черта.
Потоковые данные не находятся стационарно в ячейках памяти, а находятся в движении «как ртуть». Все узлы дерева решения на рис. 2 связаны единым потоком данных в ориентированным связный граф, поэтому справедливо назвать его деревом потока данных.
Хранимые данные мы обозначили суффиксом memo, чтобы подчеркнуть их стационарность. Это общие данные, которые необходимо хранить для внешнего «потребления», например, для транспортировки на OPC–сервер.
Далее из примера на Erlang будет ясно, что по сути memo–данные отличаются от потоковых данных наличием механизма принудительной транспортировки данных по запросу get. Это специфичное взаимодействие с чужим процессом показано на рис. 3. Для обобщения можно сказать, что фактически все потоковые данные транспортируются по запросу типа put.
 Рис. 3. Дерево потока данных и взаимодействие с «чужим» потоком через данные–memo
Рис. 3. Дерево потока данных и взаимодействие с «чужим» потоком через данные–memo
Наш поток данных и «чужой» поток являются несвязанными или слабосвязанными процессами вычисления.
Мы подробно рассмотрели вопрос о существовании memo–данных потому, что они являются по сути глобальными объектами параллельного программирования. В программировании на традиционных языках они размещаются в общей разделяемой памяти, доступ к которой необходимо защищать (блокировать), например, мьютексами. Но это уже другая тема.
Выбор экспериментального движка для вычисления дерева решения
Попробуем реализовать дерево потока данных решения квадратного уравнения на каком-либо подходящем языке, чтобы наши рассуждения подкрепить фактологическим материалом. Не вдаваясь в малоинтересные подробности предварительных изысканий, сразу скажу, что мой выбор остановился на языке Erlang, хотя сам я не являюсь экспертом по функциональному программированию. (Специалистами языка Erlang считаю программистов, применяющих шаблоны поведения OTP.)
Перечислим полезные характеристика Erlang:
Изначальная параллельность процессов. Вместо использования потоков вычислений, которые обмениваются данными с помощью разделяемой памяти, в Erlang для каждого процесса выделяется отдельная область памяти, Процессы взаимодействуют друг с другом через передачу сообщений. Сообщение может содержать любой терм значения в Erlang. Сообщения передаются асинхронно.
Распределённые вычисления. Средства распределённого программирования встроены в синтаксис и семантику языка. По умолчанию узлы (средства выполнения Erlang) обмениваются данными по протоколу TCP/IP. Они могут быть соединены в однородную сеть, в которой каждый из узлов не зависит от операционной системы, на которой он запущен.
Применение в системах реального времени. Несмотря на то что Erlang — высокоуровневый язык, его можно использовать и в системах псевдореального времени (soft real-time system).
Надежность. Процессы в Erlang могут быть соединены (link) так, что если один из них падает, то второй узнает об этом и либо исправит проблему, либо сам завершится. Обобщённые процессы соединяются с процессом-наблюдателем (supervisor). Единственная обязанность процесса–наблюдателя заключается в наблюдении за процессами и обработке завершения процессов.
Интеграция с другими программными компонентами, написанными на традиционных языках программирования, например, С и Python (здесь уместно вспомнить о гетерогенной природе дерева решений). Это может быть использовано для получения интерфейса, например, к протоколу Modbus через стороннюю библиотеку.
Импонировала лаконичность языка Erlang при достаточной выразительности операторов, например, включение охранных выражений в оператор приема и обработки сообщений. Было понятно, что в Erlang:
легко организовать структуру узлов процессов для моделирования дерева решений,
легко организовать работу потоков данных в дереве решения при помощи посылок сообщений между узлами,
Реализовывать движок для вычисления дерева решения на современном языке Scala средствами библиотеки акторов [4] я не стал бы из–за перегруженности этого языка как следствие компромиссного решения собрать несколько разнородных моделей в одной среде.
Вспомним, что в дереве потока данных операция на вычислителе выполняется по мере готовности его входных аргументов, например, операция x1 может быть выполнена только после получения аргументов входных процессов a и b и результата от нижележащего вычислителя sqrt. Но в Erlang нет готового механизма синхронизации гонки данных. Его придется изобретать и реализовывать самостоятельно.
Синхронизация данных на входе вычислительного блока в дереве решения. Решение проблемы «Гонки данных»
Как мы уже отметили, все вычислители необходимо заставить работать слаженно, и на вход вычислительных узлов поступление данных в качестве аргументов должно происходить синхронно. Необходимость в синхронизации потока данных приводит к учету временного фактора в движке вычисления. Этот вопрос нуждается в дальнейшем исследовании, но уже на этапе понятно, что он чрезвычайно актуален в системах управления реального времени.
Можно предложить несколько решений проблемы синхронизации данных.
1) «Ленивая» синхронизация методом тупого ожидания прихода всех аргументов.
Здесь стратегия синхронизации простая — вычислительный блок тупо ждет прихода своих аргументов, чтобы потом произвести вычисления. Этот способ используется в движке решения задачи, приведенной в статье.
2) Контроль поступления данных в заданном интервале временной разбежки.
Данные двигаются снизу непрерывным потоком, что характерно для данных, поступающих от датчиков в системе реального времени. Для управления этим процессом предлагается использовать метод задания и контроля временной разбежки прихода данных к вычислителю.
Проведем некоторую аналогию. В электротехнике известна задача «гонки сигналов», т.е. n входных сигналов должны по возможности одновременно прийти от входов устройства по цепочке элементов к выходному элементу устройства, чтобы произвести правильный выходной сигнал. При этом в переходный период возможно появление на выходах устройства некоторых промежуточных значений сигналов, не соответствующих заданному состоянию устройства. Наиболее часто используемый способ борьбы с гонками сигналов сводится к учету времени задержки распространения сигнала в устройстве.
Метод временной разбежки данных не стремится рассчитать задержку гонки данных, а направлен на контроль временного диапазона прихода данных. Если временной диапазон разбежки получения очередного порции определенных данных превысил допустимый установленный порог, то процесс может решить, что набор полученных данных, устарел и «обнулить» все данные, чтобы начать сеанс приема сначала. Или решить прекратить сеанс ожидание и подать сигнал тревоги о внештатной ситуации. А может увеличить время ожидания. Все зависит от стратегии, заложенной в логике контроля гонки данных.
3) Принудительная синхронизация методом «рекурсивного спуска» по дереву решения вниз и инициализации нижележащих блоков.
При такой синхронизации все данные будут гарантированно вычислены, а программа выполнена. Такая синхронизация теоретически допустима, однако здесь есть два возражения:
рекурсивный спуск сродни структуре традиционного стека,
мы ограничились рассмотрением только восходящих потоков данных.
Спуск от верхней точки дерева решений может быть применен при развертывании (загрузки) дерева решений на вычислительные средства, но этот вопрос нуждается в отдельном исследовании.
Прототип движка управления потоками
Программный код на языке Erlang решения квадратного уравнения как прототипа движка управления потоками размещен на сайте https://github.com/VAK-53/anti-turing.
Язык Erlang заставляет программиста следовать наработанным канонам, в чем я убедился на личном опыте, приступая к реализации движка. Движок дерева решений был реализован в точности с рекомендациями построения процессов по шаблону из [5], хотя я к этому изначально не стремился, но так получилось. Приведу выписку рекомендации:
«Существует общий шаблон поведения процессов, который не зависит от их назначения. Процесс должен быть запущен и зарегистрирован. Первым действием инициализируются данные цикла обработки процесса. Данные цикла — это обычно аргументы, передаваемые в spawn[4], их мы будем называть состоянием процесса (process state). Далее состояние передаётся функции выполнения цикла, которая принимает сообщение, обрабатывает его, обновляет состояние и рекурсивно вызывает себя с этим состоянием. Если в функцию поступает сообщение stop, процесс освобождает ресурсы и завершается. Эту схему построения процесса мы будем называть шаблоном проектирования (design pattern). Она будет часто встречаться … вне зависимости от выполняемой процессом задачи. Cхема шаблона процесса изображена» на рис. 4.
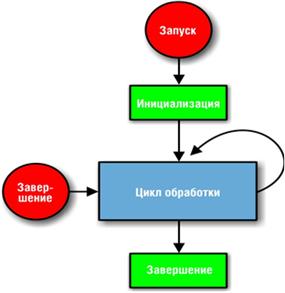 Рис. 4 Схема шаблона процесса.
Рис. 4 Схема шаблона процесса.
Внешние функции модуля движка называются start_a/0, start_b/0 и start_c/0 в соответствии с названиями входных параметров a, b и c. В них же производится инициализация данных a, b и c атомом (начального значения) undefined. И все потоковые данные инициализируютсязначением атома undefined.
В начале программного модуля при запуске строится дерево потока данных в соответствии с деревом решения на рис. 3.
Входные параметры a, b и c считываются в терминалах асинхронно циклически.
Содержательная часть программы, реализующая алгоритм потока решения, соответствует дереву потока данных схемы на рис. 3. Работа алгоритма реализована через механизм посылки сообщений от узла к узлу, а доступ к memo–данным x1–memo и x2–memo канонически скрыт оберткой в виде экспортируемыми функциями get ().
Гонка входных аргументов на вход процесса решается простой проверкой отсутствия среди входных данных экземпляра со значением undefined. После срабатывания процесса в узле всем входным аргументам снова присваиваются значение undefined для подготовки выполнения новой итерации расчетов.
Memo–данные x1–memo и x2–memo хранятся в виде переменных состояния в процессах с хвостовой рекурсией. (Собственно говоря, все процессы в программе являются процессами с хвостовой рекурсией.) В примере внешний несвязанный процесс запускается в отдельном узле и выводит полученное значение на экране. При достаточной степени абстрагирования процесс можно уподобить некоторому получению данных с OPC–сервера и построение отчета для оператора.
При испытании программный модель Анти–Тьюринг запускался в четырех терминальных окнах. Результат испытаний программы показан на рис. 5.
 Рис. 5. Результат работы программы Анти–Тьюринг.
Рис. 5. Результат работы программы Анти–Тьюринг.
Асинхронные процессы задания коэффициентов a, b и c запускались в узлах самостоятельных вычислителей. В четвертом окне был запущен несвязанный процесс для запроса результатов вычисления.
Испытания программы показали работоспособность предлагаемой парадигмы дерева потока. Работу парадигмы можно описать образом как «вычисление через переписку по почте» (ВЧП). Думаю, что это может вызвать в памяти ряд ассоциативных примеров.
Совпадения и отличия от модели акторов
Основные элементы модели акторов [6] и предлагаемой парадигмы программирования в потоке данных в исполнении на языке Erlang полностью совпадают. Совпадают и формулировки декларируемых целей — программирование параллельных и распределенных вычислений. Но есть и различия.
Первые статьи по акторам в 70–е годы проходили по теме искусственного интеллекта и основоположники модели акторов, очевидно, преследовали широкие цели академического характера. Вообще, 70–е годы — это время компьютерных гениев, способных генерировать и продвигать прорывные технологии.
При написании данной статьи доминировал простой прагматический интерес построения инструмента разработки прикладных систем реального времени. Поэтому естественно, что есть существенные несовпадения в мотивации и, как следствие, различия в проектных решениях.
Основные различия:
1. В модели акторов поддерживается динамическая топонимика программы, причем состав актеров монотонно возрастает.
Мы со своей стороны, придерживаясь принципа, что система управления должна быть ясной, понятной и фиксированной, при построении дерева решений ограничились статичной топонимикой. Тогда в программе будет необходимо руководить не переменной «труппой актеров», а постоянным штатом «уокеров» на конвейере.
2. В модели акторов отсутствует понятие глобального времени, т.к. в модели нельзя гарантировать определенное время доставки сообщения. Модель акторов просто гарантирует, что сообщение обязательно будет доставлено актору.
В статье же поставлена задача гонки данных и вводится временной фактор актуальности данных, т.е. предлагается контролировать относительный временной интервал прихода аргументов.
3. В модели акторов состояние останова (halt), когда каждый актор обработал все свои входные сообщения и находится в ожидании новых, которые не появляются по причине неактивности остальных акторов, трактуется как завершение вычислений. Т.е. решение о завершении является внутренним делом замкнутой модели.
В потоковом вычислении входные данные являются внешними по отношению к коллективу вычислителей и только супервизор, контролирующий каналы внешних данных, может принять решение о завершении вычислений.
Кстати, есть спорное мнение, что Erlang является реализацией модели акторов, хотя это мнение вызывает критику [7], думаю, справедливую. Все дело опять же в мотивации и целях разработки.
Анти–Тьюринг. Заклятие доминирования модели машины Тьюринга
Здесь речь пойдет не о практическом значении той или иной концепции, а о господствующих идиомах в программировании.
Как видно из рассмотренной концепции потока данных дерева решения данные не стационарны в памяти, а постоянно порождаются и передаются следующему процессу. Почему в традиционных языках программирования данные привязаны к ячейкам оперативной памяти? Почему данные статичны? Отчасти это можно объяснить доминированием у разработчиков представления о работе вычислительного устройства на базе парадигмы абстрактной машины Тьюринга, предложенной Алан Тьюрингом в 1936 г. в научном эссе «О вычислимых числах».
В «машине Тьюрига» управляющее устройство с головкой записи–чтения последовательно перемещается и обрабатывает неподвижную бесконечную ленту с данными. В состав логических операций входили только: чтение, запись и стирание символа в клетках ленты. Не густо. На каждом шаге вычислений следующее действие машины целиком и полностью определялось её текущим состоянием и считанным символом. Состояний было 5.
Как мы понимаем, практической ценности такая машина не имела, но в рамках теории алгоритмов Тьюринг выдвинул тезис, получивший название тезиса Тьюринга, согласно которому всякий алгоритм представим в форме машины Тьюринга. Это выдвинутый без доказательства фундаментальное положение теории алгоритмов [8] принималось научным сообществом неукоснительно из поколения в поколение.
С другой стороны, знакомясь с теорией алгоритмов, начинающие программисты под бесконечной лентой всегда понимали ОЗУ с последовательными ячейкам памяти, под управляющим устройством — процессор с регистром счетчика команд.
Справедливо будет отметить, что парадигма машины Тьюринга была нарушена в архитектуре фон Неймана. В 1945 г был опубликован документ «Предварительный доклад о машине EDVAC» — отчёт для Баллистической Лаборатории Армии США о революционном для своего времени компьютере EDVAC за авторством математика Д. фон Нейман, входившего в состав консультантов разработчиков EDVAC. В Отчете фон Нейман излагает только логическую структуру компьютера, намеренно не вдаваясь в детали его технического устройства. Ключевая идея отчета — хранимая в памяти компьютера программа. Таким образом, данные и инструкции процессора были «уравнены в правах». Изложенные принципы логического устройства компьютера получили название архитектуры фон Неймана и приобрели широкое распространение[5].
Исторически так сложилось, что разработка и построение первых компьютеров велась с целью автоматизации рутинных больших числовых расчетов для военных (артиллерийские таблицы) и ВПК (моделирование зарядов). Компьютеры оказались универсальным инструментом и в дальнейшем стали использоваться в системах управления устройствами широкого спектра: станки, двигатели, силовые установки и т.д. Но концепция стационарности данных в памяти сохранилась: для межзадачного обмена данными используется общая память коллективного пользования, что влечет за собой ряд проблем. Одна такая проблема связана с синхронизацией. Несоответствие представлений о способах решения изначальных численных задач и возникших задач управления вызывает некоторое недоумение.
В предлагаемой парадигме вычислений отсутствует понятие общая память коллективного пользования, вместо нее — поток данных внутри коллектива распределенных вычислителей, организованных в дерево решений. Вычислители операций являются событийными устройствами (реагирующими на сообщение) и находятся в постоянном ожидании готовности своих аргументов.
Важно отметить, что данные в памяти как набор 0 и 1 теряют свой семантический смысл и приобретают его в совокупности с вычислителем с нужным алгоритмом. В отличии от ООП данные не инкапсулируют функции, а наоборот «обволакиваются» функциональными узлами и разработчики функциональных языков похоже восприняли эту идиому для реализации в виде абстракции структур [7].
Как было показано в статье, в предлагаемой альтернативной парадигме можно успешно описывать алгоритмы и решать задачи. Дальнейший интерес представляет разработка соответствующих языковых средств распределенного программирования.
Резюме
В предлагаемой альтернативной парадигме можно успешно описывать алгоритмы и решать задачи. На базе новой парадигмы возможно создание языковых средств программирования, ориентированных на программирование потоков данных. Предполагаемый движок (коллектив вычислителей) позволит программировать в стиле связывания функциональных узлов и вычисления через почту.
Выявлена грань соприкосновения между традиционным программированием и программированием потоков данных. Оптимальная система программирования является открытой и гетерогенной; исполнительные блоки могут быть написаны на традиционным современных языках программирования, которые высокоэффективно исполняются на стеках.
С самого начала настоящей работы ставилась цель достижения цели активного участия в работе узкопрофильного специалиста на стадии конфигурирования системы управления гипотетическим устройством. Задача решается наработкой пула общих понятийных идиом потоковой обработки данных в качестве мостика через семантический разрыв между пользователем и программистом.
Существует предпосылка для разработки управляющих систем устройствами и технологическими установками на новых базовых принципах.
Априори в дереве решения отсутствует гонка и конкуренция между потоками процессов. Но имеется гонка данных. Рассмотрены способы синхронизации потоков данных на параллельных асинхронных потоках.
30.11.2021
Литература
1. Трамбле Ж., Моренсон П. Введение в структуры данных — М.: Машиностроение, 1982.
2. Кнут Д. Искусство программирования. т.1. — М.: Мир, 1976.
3. Илья Суздальницкий, Мнение: объектно-ориентированное программирование — катастрофа на триллион долларов, https://tproger.ru/translations/oop-the-trillion-dollar-disaster/
4. А. Прокопец, Конкурентное программирование на Scala, — М.: ДМК Пресс, 2018.
5. Томпсон С., Чезарини Ф. Программирование в Erlang — М.: ДМК Пресс, 2010.
6. И. Федотов, Модели параллельного программирования. — М.: Солон-Пресс, 2012.
7. Саша Юрич, Elixir в действии. — М.: ДМК Пресс, 2020
8. В.Е. Зюбин Программирование информационно-управляющих систем на основе конечных автоматов. Учебно–методическое пособие — Новосиб.: НГУ, 2006.
9. Язык компьютера. Пер. с англ. — М.: Мир, 1989.
[1] Первая фраза из работы Ф. Энгельса «Анти–Дюринг».
[2] Конечно, программа устроена более сложно, но процесс вычисления сводится именно к обработке на стеке.
[3] Будем понимать термин программа в традиционном смысле этого слова, как заданную последовательность действий, хотя, весьма вероятно, возможно будут отличия.
[4] spawn — встроенная в Erlang функция запуска новых процессов
[5] Доклад породил всеобщее заблуждение, что заслуга изобретения архитектуры размещения команд управляющего устройства компьютера в оперативной памяти вместе с данными целиком и полностью принадлежит фон Нейману, но это не так [9].
