Яндекс открывает датасеты Толоки для исследователей
Толока — крупнейший источник размеченных людьми данных для задач машинного обучения. Каждый день в Толоке десятки тысяч исполнителей производят более 5 миллионов оценок. Для любых исследований и экспериментов, связанных с машинным обучением, необходимы большие объёмы качественных данных. Поэтому мы начинаем публиковать открытые датасеты для академических исследований в разных предметных областях.
Сегодня мы поделимся ссылками на первые публичные датасеты и расскажем о том, как они собирались. А ещё подскажем, где же правильно ставить ударение в названии нашей платформы.
Интересный факт: чем сложнее технология искусственного интеллекта, тем больше ей нужна помощь человека. Люди размечают изображения по категориям, чтобы натренировать компьютерное зрение; люди оценивают релевантность страниц поисковым запросам; люди преобразуют речь в текст, чтобы голосовой помощник научился понимать и говорить. Человеческие оценки нужны машине, чтобы дальше она работала без людей и лучше людей.
Раньше многие компании собирали такие оценки исключительно с помощью специально обученных сотрудников — асессоров. Но со временем задач в области машинного обучения стало слишком много, а сами задачи в массе своей перестали требовать особых знаний и опыта. Так появился спрос на помощь «толпы» (crowd). Но самостоятельно найти большое количество случайных исполнителей и работать с ними не каждому под силу. Краудсорсинговые платформы решают эту проблему.
Яндекс.Толока́ (правильно произносить именно так, с ударением на последний слог) — одна из крупнейших в мире краудсорсинговых платформ. У нас более 4 млн зарегистрированных пользователей. Более 500 проектов каждый день собирают оценки с нашей помощью. Приятный факт: в этом году на секции Data Labeling на конференции Data Fest все шесть докладчиков из разных компаний упоминали Толоку как источник разметки для своих проектов.
О применении Толоки в бизнесе уже много сказано. Сегодня мы поговорим о другом нашем направлении, которое считаем не менее полезным.
Исследования в Толоке
Краудсорсинг и вообще задача массового сбора человеческих разметок существует примерно столько же, сколько и промышленное применение машинного обучения. Это область, на которую во всех технологических компаниях тратятся огромные деньги. Но при этом почему-то именно она сильно недоинвестирована с точки зрения исследований: о работе с краудом, в отличие от других областей ML, относительно мало серьёзных исследований и статей.
Мы бы хотели это изменить. Наша команда видит Толоку не только как инструмент для решения прикладных задач, но и как площадку для научных исследований в разных предметных областях.
Публичные датасеты Толоки
Мы хотим поддержать научное сообщество и привлечь исследователей в Толоку, поэтому начинаем публиковать наборы данных для некоммерческих, академических целей. Они могут быть интересны исследователям разных направлений: здесь и чат-боты, и данные для тестирования моделей агрегации вердиктов толокеров, для лингвистических исследований, для задач компьютерного зрения. Расскажем о них:
Как собирались данные
На первом этапе с помощью пользователей Толоки мы собрали профили, содержащие сведения о человеке, его увлечениях, профессии, семье и событиях жизни, и отобрали те, что подходят для диалогов.
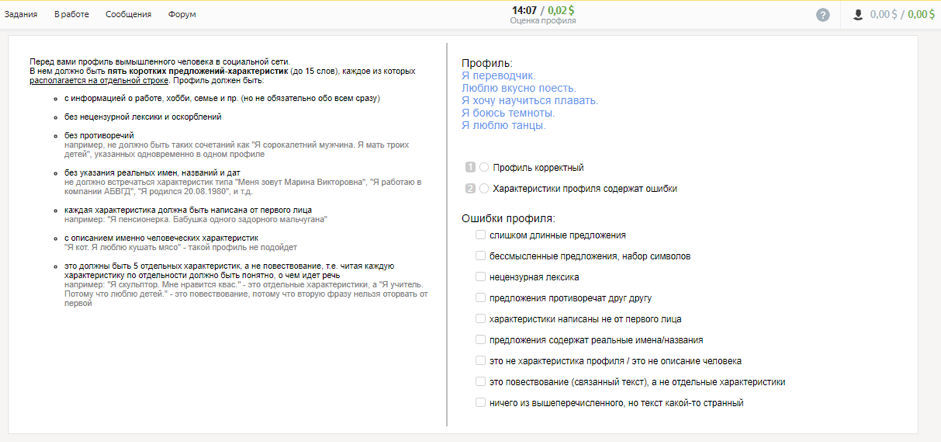
На втором этапе мы предложили участникам сыграть роль человека, описанного одним из таких профилей, и пообщаться друг с другом в мессенджере. Цель диалога — узнать больше о собеседнике и рассказать о себе. Полученные диалоги проверили другие исполнители.

Как собирались данные
Исполнителю предлагался запрос и регион пользователя, который его задал, скриншот документа и ссылка на него, возможность воспользоваться поисковыми системами и варианты ответов: «Релевантен», «Нерелевантен», «Не отображается».
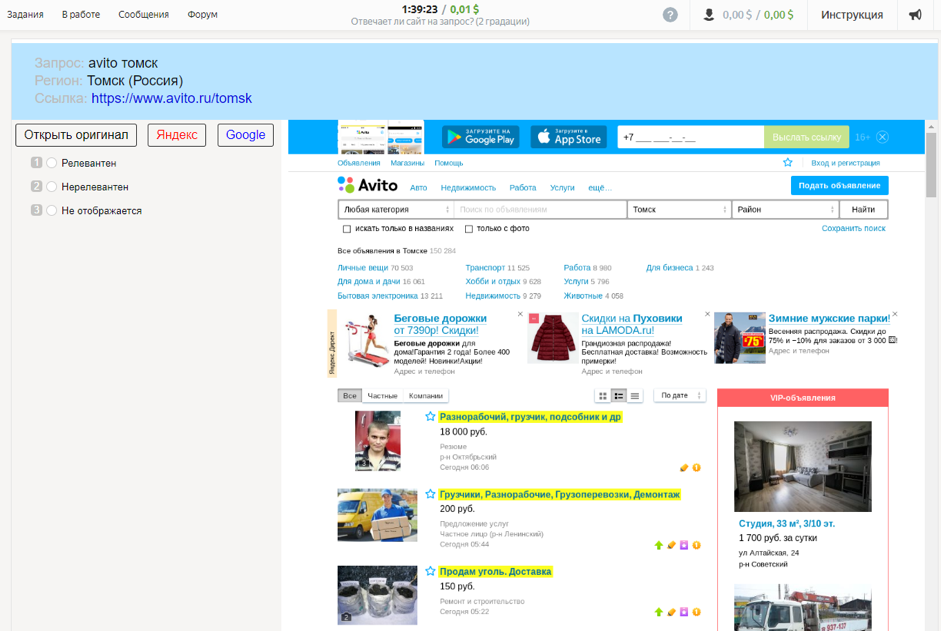
Как собирались данные
Оценка документов по пяти градациям более сложная и требует большей квалификации. Исполнителю предлагался запрос и регион пользователя, который его задал, скриншот документа и ссылка на него, кнопки для использования поисковых систем и пять вариантов ответа: «Витальный», «Полезный», «Релевантный +», «Релевантный –», «Нерелевантный».

Основной показатель качества — точность агрегированных ответов, оцениваемая на основе контрольных заданий (голденсетов). У некоторых заданий в датасете не один, а несколько правильных ответов. Любой из таких ответов считается правильным. Точность по основным методам агрегации:
● Мнение большинства — 89,92%.
● Dawid-Skene — 90,72%.
● GLAD — 90,16%.
Как собирались данные
Для исследования взято 300 наиболее употребляемых в современном русском языке существительных. С помощью тезаурусов (РуТез, RuWordNet) и автоматизированных методов образования гиперонимов (Watset, Hyperstar) получено 10 600 родо-видовых пар (типа «котёнок» — «млекопитающее»). Участникам исследования нужно было ответить на вопрос: «Правда ли, что котёнок — это разновидность млекопитающего?» Чтобы грамотно сформулировать вопрос, гиперонимы поставили в родительный падеж при помощи морфологического анализатора и генератора pymorphy2.
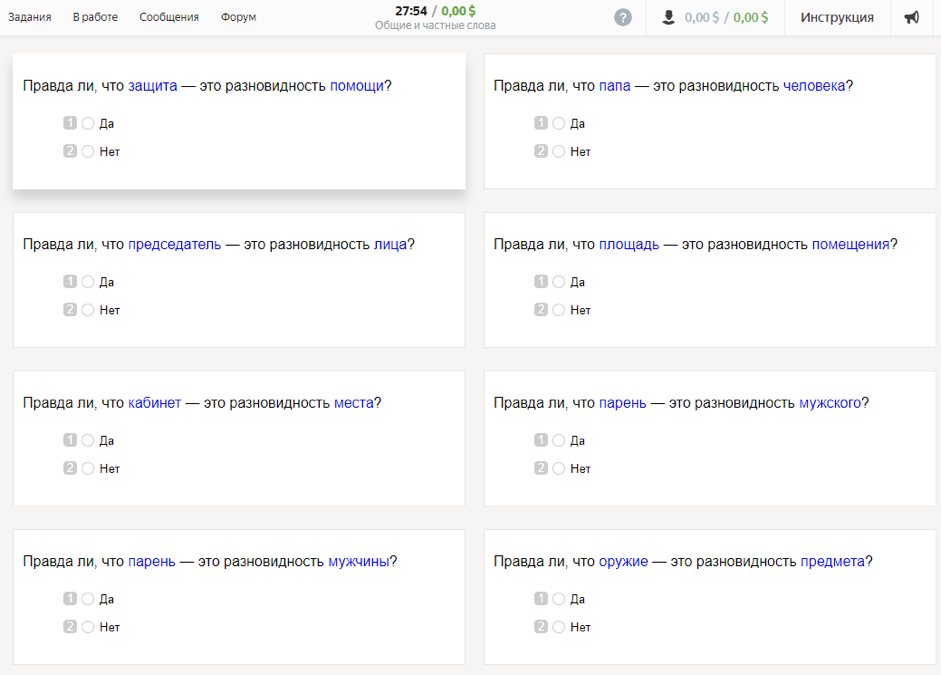
Каждую пару разметили семь русскоязычных исполнителей старше 20 лет. По результатам, полученным после агрегации всех оценок, 4576 пар слов получили положительные ответы, а 6024 — отрицательные. Интересно, что участники исследования оказались более единодушны в выборе отрицательного ответа, чем положительного.
Как собирались данные
Участникам исследования демонстрировалось слово и пример его употребления в речи. Нужно было определить значение слова в контексте высказывания и выбрать один из вариантов ответа.

Как собирались данные
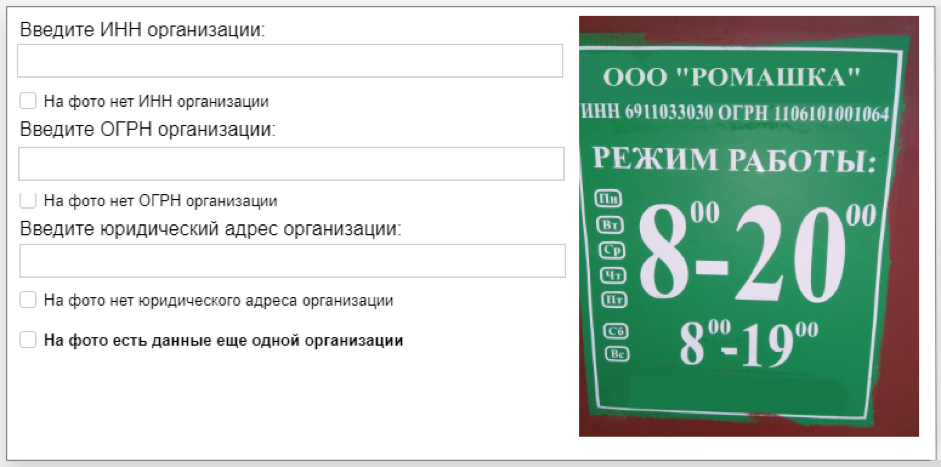
Сначала мы запустили задание в мобильном приложении Толоки: исполнителям предлагалось приехать по адресу, отмеченному на карте, найти организацию и сфотографировать её информационную табличку. Это и другие полевые задания помогают поддерживать актуальной информацию в Яндекс.Справочнике.
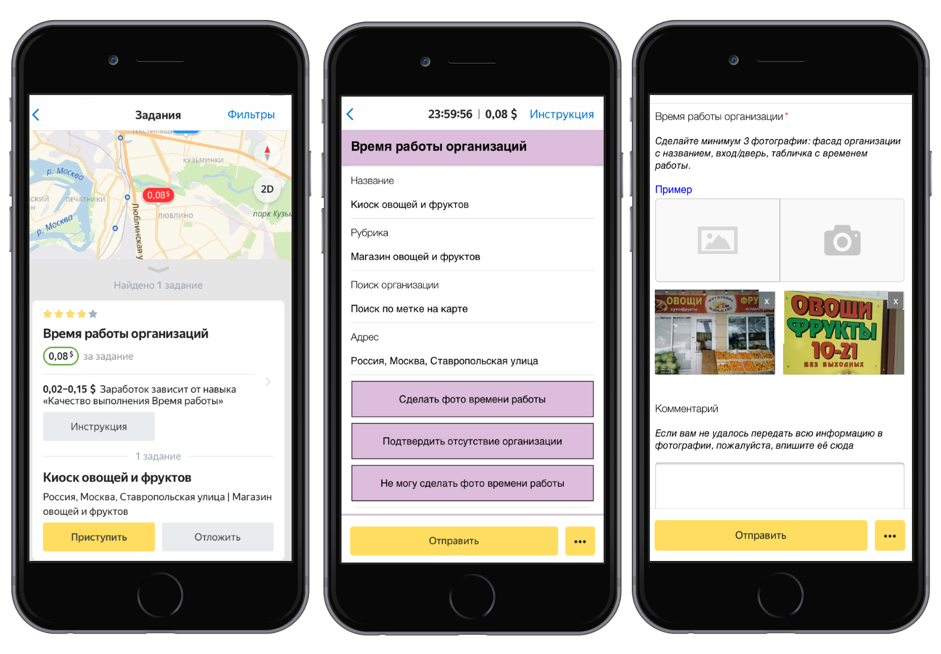
Затем качество выполненных заданий проверили другие исполнители. Фотографии, на которых указаны ИНН и ОГРН, мы отправили на расшифровку. Толокеры перепечатали эти номера с фотографий, после чего мы обработали результаты и сформировали датасет.
Датасет содержит около 60 тыс. оценок в 1 тыс. заданий с правильными ответами почти для всех заданий. Исполнители классифицировали сайты по пяти категориям по наличию контента для взрослых. Дополнительно к каждому заданию прилагаются 52 действительнозначных показателя, которые можно использовать для предсказания категории.
Выбрать и скачать датасеты можно по ссылке: https://toloka.yandex.ru/datasets/. Мы не планируем останавливаться на этом и призываем исследователей обратить внимание на краудсорсинг и рассказывать о своих проектах.
