Анализ тональности текстов с помощью сверточных нейронных сетей
Представьте, что у вас есть абзац текста. Можно ли понять, какую эмоцию несет этот текст: радость, грусть, гнев? Можно. Упростим себе задачу и будем классифицировать эмоцию как позитивную или как негативную, без уточнений. Есть много способов решать такую задачу, и один из них — свёрточные нейронные сети (Convolutional Neural Networks). CNN изначально были разработаны для обработки изображений, однако они успешно справляются с решением задач в сфере автоматической обработки тестов. Я познакомлю вас с бинарным анализом тональности русскоязычных текстов с помощью свёрточной нейронной сети, для которой векторные представления слов были сформированы на основе обученной Word2Vec модели.
Статья носит обзорный характер, я сделал акцент на практическую составляющую. И сразу хочу предупредить, что принимаемые на каждом этапе решения могут быть неоптимальными. Перед прочтением рекомендую ознакомиться с вводной статьей по использованию CNN в задачах обработки естественных языков, а также прочитать материал про методы векторного представление слов.
Архитектура
Рассматриваемая архитектура CNN основана на подходах [1] и [2]. Подход [1], в котором используется ансамбль сверточных и рекуррентных сетей, на крупнейшем ежегодном соревновании по компьютерной лингвистике SemEval-2017 занял первые места [3] в пяти номинациях в задаче по анализу тональности Task 4.
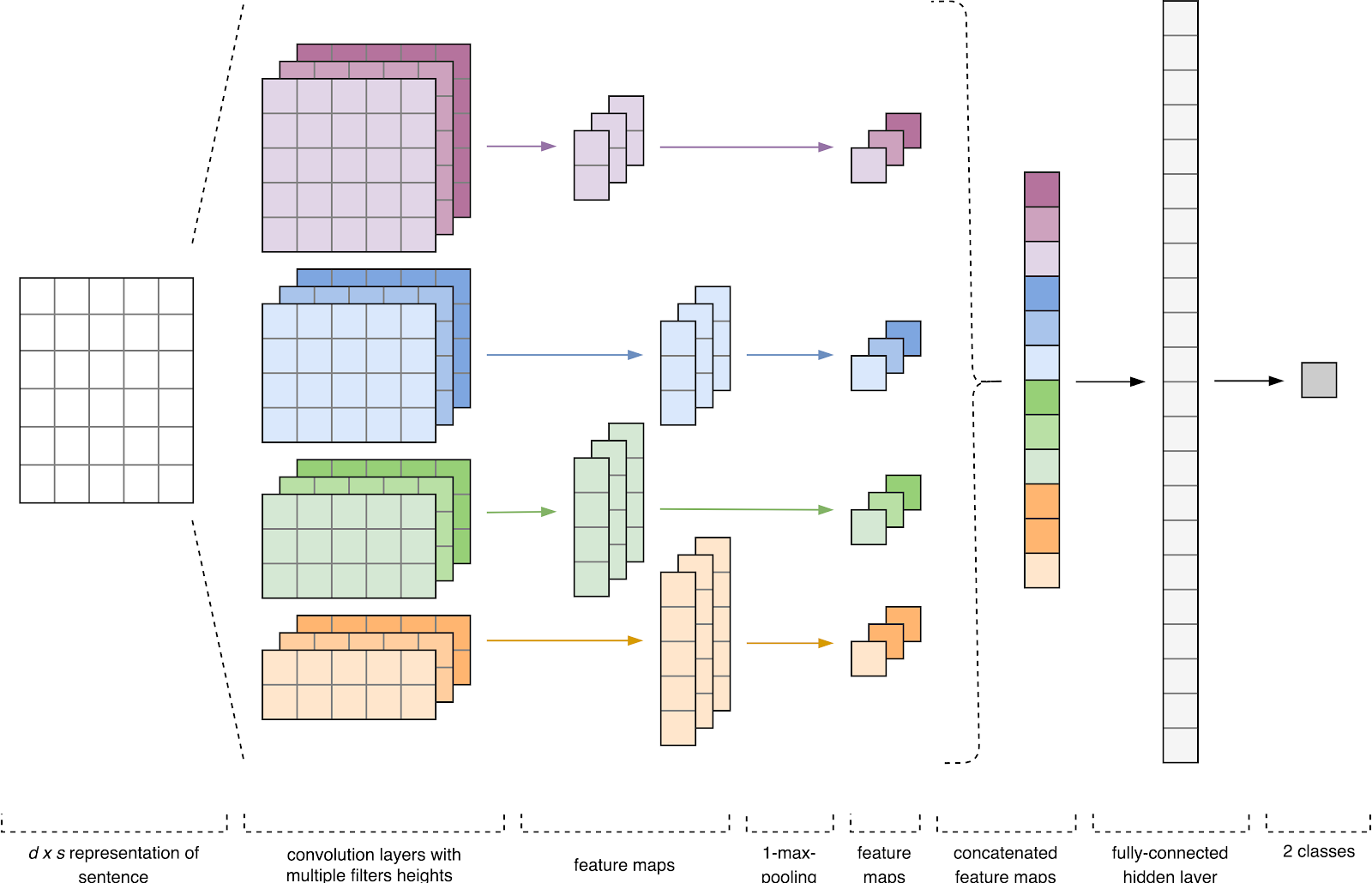
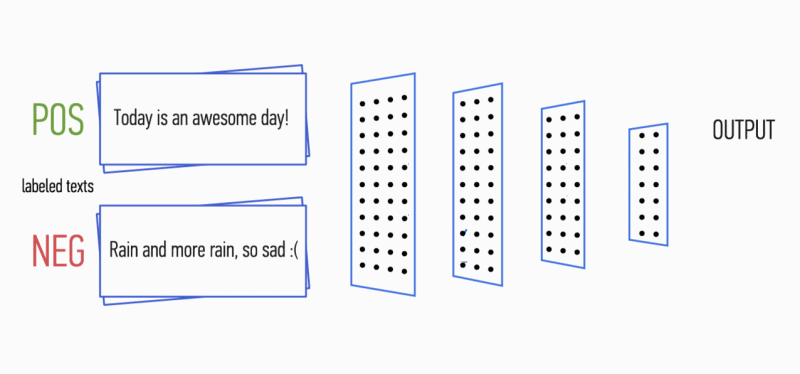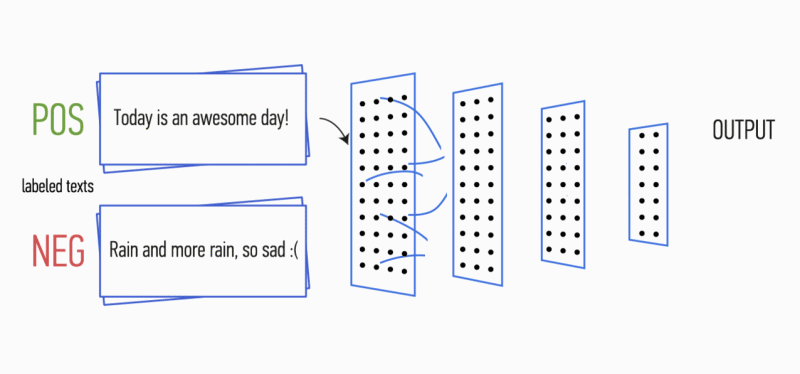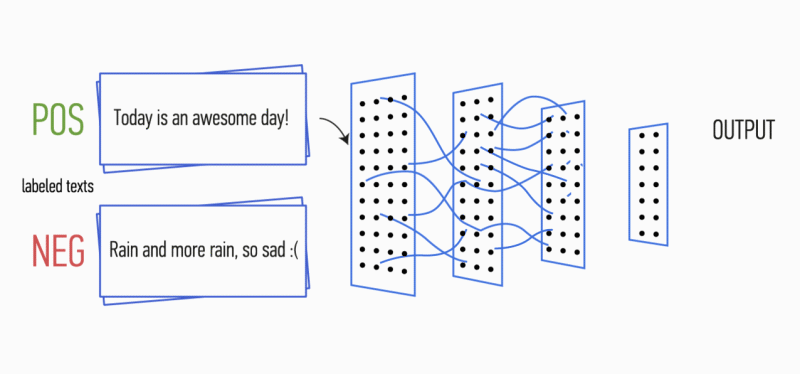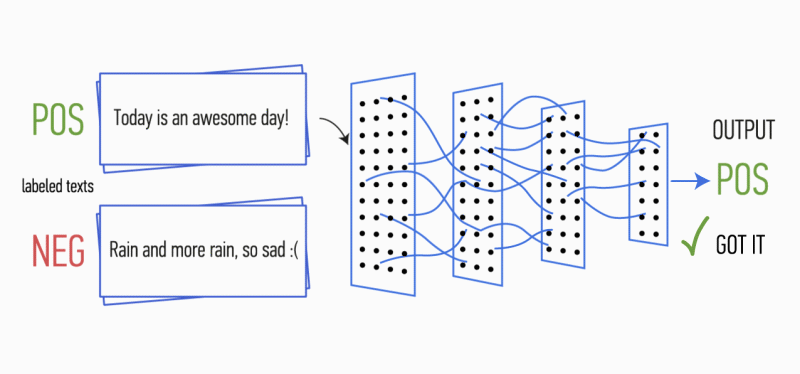
Рисунок 1. Архитектура CNN [2].
Входными данными CNN (рис. 1) является матрица с фиксированной высотой n, где каждая строка представляет собой векторное отображение токена в признаковое пространство размерности k. Для формирования признакового пространства часто используют инструменты дистрибутивной семантики, такие как Word2Vec, Glove, FastText и т.д.
На первом этапе входная матрица обрабатывается слоями свертки. Как правило, фильтры имеют фиксированную ширину, равную размерности признакового пространства, а для подбора размеров у фильтров настраивается только один параметр — высота h. Получается, что h — это высота смежных строк, рассматриваемых фильтром совместно. Соответственно, размерность выходной матрицы признаков для каждого фильтра варьируется в зависимости от высоты этого фильтра h и высоты исходной матрицы n.
Далее карта признаков, полученная на выходе каждого фильтра, обрабатывается слоем субдискретизации с определенной функцией уплотнения (на изображении — 1-max pooling), т.е. уменьшает размерность сформированной карты признаков. Таким образом извлекается наиболее важная информация для каждой свертки независимо от её положения в тексте. Другими словами, для используемого векторного отображения комбинация слоев свёртки и слоев субдискретизации позволяет извлекать из текста наиболее значимые n-граммы.
После этого карты признаков, рассчитанные на выходе каждого слоя субдискретизации, объединяются в один общий вектор признаков. Он подаётся на вход скрытому полносвязному слою, а потом поступает на выходной слой нейронной сети, где и рассчитываются итоговые метки классов.
Данные для обучения
Для обучения я выбрал корпус коротких текстов Юлии Рубцовой, сформированный на основе русскоязычных сообщений из Twitter [4]. Он содержит 114 991 положительных, 111 923 отрицательных твитов, а также базу неразмеченных твитов объемом 17 639 674 сообщений.
import pandas as pd
import numpy as np
# Считываем данные
n = ['id', 'date', 'name', 'text', 'typr', 'rep', 'rtw', 'faw', 'stcount', 'foll', 'frien', 'listcount']
data_positive = pd.read_csv('data/positive.csv', sep=';', error_bad_lines=False, names=n, usecols=['text'])
data_negative = pd.read_csv('data/negative.csv', sep=';', error_bad_lines=False, names=n, usecols=['text'])
# Формируем сбалансированный датасет
sample_size = min(data_positive.shape[0], data_negative.shape[0])
raw_data = np.concatenate((data_positive['text'].values[:sample_size],
data_negative['text'].values[:sample_size]), axis=0)
labels = [1] * sample_size + [0] * sample_size
Перед началом обучения тексты прошли процедуру предварительной обработки:
- приведение к нижнему регистру;
- замена «ё» на «е»;
- замена ссылок на токен «URL»;
- замена упоминания пользователя на токен «USER»;
- удаление знаков пунктуации.
import re
def preprocess_text(text):
text = text.lower().replace("ё", "е")
text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text)
text = re.sub('@[^\s]+', 'USER', text)
text = re.sub('[^a-zA-Zа-яА-Я1-9]+', ' ', text)
text = re.sub(' +', ' ', text)
return text.strip()
data = [preprocess_text(t) for t in raw_data]
Далее я разбил набор данных на обучающую и тестовую выборку в соотношении 4:1.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
Векторное отображение слов
Входными данными сверточной нейронной сети является матрица с фиксированной высотой n, где каждая строка представляет собой векторное отображение слова в признаковое пространство размерности k. Для формирования embedding-слоя нейронной сети я использовал утилиту дистрибутивной семантики Word2Vec [5], предназначенную для отображения семантического значения слов в векторное пространство. Word2Vec находит взаимосвязи между словами согласно предположению, что в похожих контекстах встречаются семантически близкие слова. Подробнее о Word2Vec можно прочитать в оригинальной статье, а также тут и тут. Поскольку твитам характерна авторская пунктуация и эмотиконы, определение границ предложений становится достаточно трудоемкой задачей. В этой работе я допустил, что каждый твит содержит лишь одно предложение.
База неразмеченных твитов хранится в SQL-формате и содержит более 17,5 млн. записей. Для удобства работы я конвертировал её в SQLite с помощью этого скрипта.
import sqlite3
# Открываем SQLite базу данных
conn = sqlite3.connect('mysqlite3.db')
c = conn.cursor()
with open('data/tweets.txt', 'w', encoding='utf-8') as f:
# Считываем тексты твитов
for row in c.execute('SELECT ttext FROM sentiment'):
if row[0]:
tweet = preprocess(row[0])
# Записываем предобработанные твиты в файл
print(tweet, file=f)
Далее с помощью библиотеки Gensim обучил Word2Vec-модель со следующими параметрами:
- size = 200 — размерность признакового пространства;
- window = 5 — количество слов из контекста, которое анализирует алгоритм;
- min_count = 3 — слово должно встречаться минимум три раза, чтобы модель его учитывала.
import logging
import multiprocessing
import gensim
from gensim.models import Word2Vec
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# Считываем файл с предобработанными твитами
data = gensim.models.word2vec.LineSentence('data/tweets.txt')
# Обучаем модель
model = Word2Vec(data, size=200, window=5, min_count=3, workers=multiprocessing.cpu_count())
model.save("models/w2v/model.w2v")

Рисунок 2. Визуализация кластеров похожих слов с использование t-SNE.
Для более детального понимания работы Word2Vec на рис. 2 представлена визуализация нескольких кластеров похожих слов из обученной модели, отображенных в двухмерное пространство с помощью алгоритма визуализации t-SNE.
Векторное отображение текстов
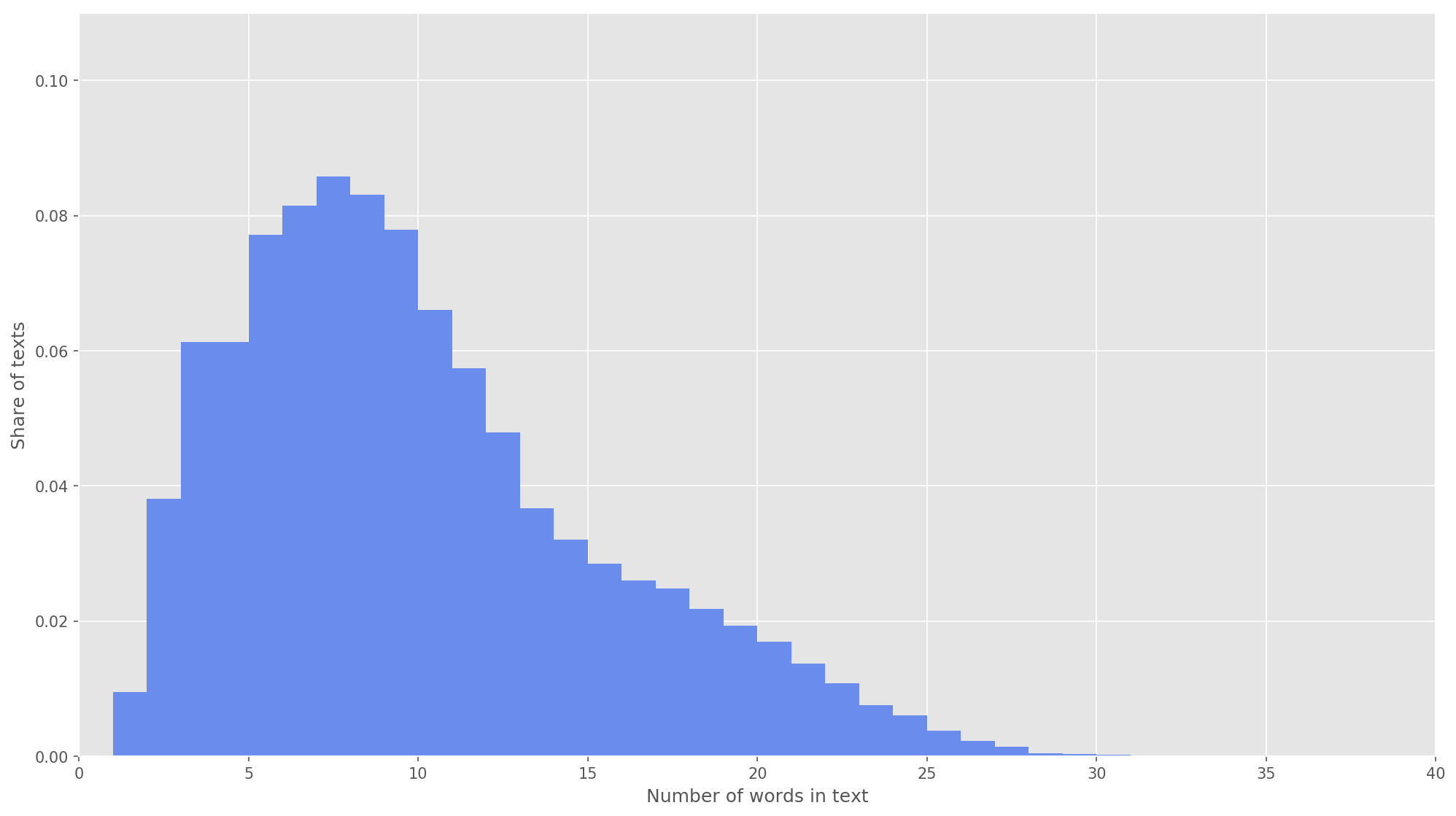
Рис 3. Распределение длины текстов.
На следующем этапе каждый текст был отображен в массив идентификаторов токенов. Я выбрал размерность вектора текста s=26, поскольку при данном значении полностью покрываются 99,71% всех текстов в сформированном корпусе (рис. 3). Если при анализе количество слов в твите превышало высоту матрицы, оставшиеся слова отбрасывались и не учитывались в классификации. Итоговая размерность матрицы предложения составила s×d=26×200.
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
# Высота матрицы (максимальное количество слов в твите)
SENTENCE_LENGTH = 26
# Размер словаря
NUM = 100000
def get_sequences(tokenizer, x):
sequences = tokenizer.texts_to_sequences(x)
return pad_sequences(sequences, maxlen=SENTENCE_LENGTH)
# Cоздаем и обучаем токенизатор
tokenizer = Tokenizer(num_words=NUM)
tokenizer.fit_on_texts(x_train)
# Отображаем каждый текст в массив идентификаторов токенов
x_train_seq = get_sequences(tokenizer, x_train)
x_test_seq = get_sequences(tokenizer, x_test)
Свёрточная нейронная сеть
Для построения нейронной сети я использовал библиотеку Keras, которая выступает высокоуровневой надстройкой над TensorFlow, CNTK и Theano. У Keras есть отличная документация, а также блог, который освещает многие задачи машинного обучения, к примеру, инициализацию embedding-слоя. В нашем случае embedding-слой был инициирован весами, полученными при обучении Word2Vec. Чтобы минимизировать изменения в embedding-слое, я заморозил его на первом этапе обучения.
from keras.layers import Input
from keras.layers.embeddings import Embedding
tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32')
tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH,
weights=[embedding_matrix], trainable=False)(tweet_input)
В разработанной архитектуре использованы фильтры с высотой h=(2, 3, 4, 5), которые предназначены для параллельной обработки биграмм, триграмм, 4-грамм и 5-грамм соответственно. Добавил в нейронную сеть по 10 свёрточных слоев для каждой высоты фильтра, функция активации — ReLU. С рекомендациями по поиску оптимальной высоты и количества фильтров можно ознакомиться в работе [2].
После обработки слоями свертки, карты признаков поступали на слои субдискретизации, где к ним применялась операция 1-max-pooling, тем самым извлекая наиболее значимые n-граммы из текста. На следующем этапе происходило объединение в общий вектор признаков (слой объединения), который подавался в скрытый полносвязный слой с 30 нейронами. На последнем этапе итоговая карта признаков подавалась на выходной слой нейронной сети с сигмоидальной функцией активации.
Поскольку нейронные сети склонны к переобучению, после embedding-слоя и перед скрытым полносвязным слоем я добавил dropout-регуляризацию c вероятностью выброса вершины p=0.2.
from keras import optimizers
from keras.layers import Dense, concatenate, Activation, Dropout
from keras.models import Model
from keras.layers.convolutional import Conv1D
from keras.layers.pooling import GlobalMaxPooling1D
branches = []
# Добавляем dropout-регуляризацию
x = Dropout(0.2)(tweet_encoder)
for size, filters_count in [(2, 50), (3, 50), (4, 50), (5, 50)]:
for i in range(filters_count):
# Добавляем слой свертки
branch = Conv1D(filters=1, kernel_size=size, padding='valid', activation='relu')(x)
# Добавляем слой субдискретизации
branch = GlobalMaxPooling1D()(branch)
branches.append(branch)
# Конкатенируем карты признаков
x = concatenate(branches, axis=1)
# Добавляем dropout-регуляризацию
x = Dropout(0.2)(x)
x = Dense(30, activation='relu')(x)
x = Dense(1)(x)
output = Activation('sigmoid')(x)
model = Model(inputs=[tweet_input], outputs=[output])
Итоговую модель сконфигурировал с функцией оптимизации Adam (Adaptive Moment Estimation) и бинарной кросс-энтропией в качестве функции ошибок. Качество работы классификатора оценивал в критериях макро-усредненных точности, полноты и f-меры.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1])
model.summary()
На первом этапе обучения заморозил embedding-слой, все остальные слои обучались в течение 10 эпох:
- Размер группы примеров, используемых для обучения: 32.
- Размер валидационной выборки: 25%.
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1)
history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
Train on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
Затем выбрал модель с наивысшими показателями F-меры на валидационном наборе данных, т.е. модель, полученную на восьмой эпохе обучения (F1=0.7791). У модели разморозил embedding-слой, после чего запустил еще пять эпох обучения.
from keras import optimizers
# Загружаем веса модели
model.load_weights('models/cnn/cnn-frozen-embeddings-09-0.77.hdf5')
# Делаем embedding слой способным к обучению
model.layers[1].trainable = True
# Уменьшаем learning rate
adam = optimizers.Adam(lr=0.0001)
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=[precision, recall, f1])
model.summary()
checkpoint = ModelCheckpoint("models/cnn/cnn-trainable-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1)
history_trainable = model.fit(x_train_seq, y_train, batch_size=32, epochs=5, validation_split=0.25, callbacks = [checkpoint])
Train on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703
Наивысший показатель F1=76.80% на валидационной выборке был достигнут на третьей эпохе обучения. Качество работы обученной модели на тестовых данных составило F1=78.1%.
Таблица 1. Качество анализа тональности на тестовых данных.
| Метка класса |
Точность |
Полнота |
F1 |
Количество объектов |
| Negative |
0.78194 |
0.78243 |
0.78218 |
22457 |
| Positive |
0.78089 |
0.78040 |
0.78064 |
22313 |
| avg / total |
0.78142 |
0.78142 |
0.78142 |
44770 |
Результат
В качестве baseline-решения я обучил наивный байесовский классификатор с мультиномиальной моделью распределения, результаты сравнения представлены в табл. 2.
Таблица 2. Сравнение качества анализа тональности.
| Классификатор |
Precision |
Recall |
F1 |
| MNB |
0.7577 |
0.7564 |
0.7560 |
| CNN |
0.78142 |
0.78142 |
0.78142 |
Как видите, качество классификации CNN превысило MNB на несколько процентов. Значения метрик можно увеличить еще больше, если поработать над оптимизацией гиперпараметров и архитектуры сети. К примеру, можно изменить количество эпох обучения, проверить эффективность использования различных векторных представлений слов и их комбинаций, подобрать количество фильтров и их высоту, реализовать более эффективную предобработку текстов (исправление опечаток, нормализация, стемминг), настроить количество скрытых полносвязных слоев и нейронов в них.
Исходный код доступен на Github, обученные модели CNN и Word2Vec можно скачать здесь.
Источники
- Cliche M. BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs //Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). — 2017. — С. 573–580.
- Zhang Y., Wallace B. A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification //arXiv preprint arXiv:1510.03820. — 2015.
- Rosenthal S., Farra N., Nakov P. SemEval-2017 task 4: Sentiment Analysis in Twitter //Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). — 2017. — С. 502–518.
- Ю.В. Рубцова. Построение корпуса текстов для настройки тонового классификатора // Программные продукты и системы, 2015, №1(109), —С. 72–78.
- Mikolov T. et al. Distributed Representations of Words and Phrases and Their Compositionality //Advances in Neural Information Processing Systems. — 2013. — С. 3111–3119.
