Анализ таблиц сопряженности средствами Python. Часть 1. Визуализация
АКТУАЛЬНОСТЬ ТЕМЫ
Категориальные данные имеет огромное значение в DataScience. Как справедливо заметили авторы в [1], мы живем в мире категорий: информация может быть сформирована в категориальном виде в самых различных областях — от диагноза болезни до результатов социологического опроса.
Частным случаем анализа категориальных данных является анализ таблиц сопряженности (contingency tables), в которые сводятся значения двух или более категориальных переменных.
Однако, прежде чем написать про статистический анализ таблиц сопряженности, остановимся на вопросах их визуализации. Казалось бы, об этом уже написано немало — есть статьи про графические возможности python, есть огромное количество информации и примеров с программным кодом. Однако, как всегда имеются нюансы — в процессе исследования возникают вопросы как с выбором средств визуализации, так и с настройкой инструментов python. В общем, есть о чем поговорить…
В данном обзоре мы рассмотрим следующие способы визуализации таблиц сопряженности:
Трехмерные гистограммы.
Мозаичные диаграммы.
Столбчатые диаграммы и графики взаимодействия частот.
Графики «тепловой карты» (heatmap).
Конечно, этот список не исчерпывающий (в этой области огромное поле деятельности — можно ознакомиться, например, здесь https://hr-portal.ru/statistica/gl7/gl7.php) -, но мы остановимся на выбранных способах, ибо нельзя объять необъятное, а данный перечень охватывает достаточный набор инструментов для использования на практике. Каждый специалист волен сам выбирать инструменты для работы себе по душе.
Применение пользовательских функций
Как и в предыдущих обзорах, здесь будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля my_module__stat.py, который доступен в моем репозитории на GitHub (https://github.com/AANazarov/MyModulePython).
Вот перечень данных функций:
Ряд пользовательских функций мы создаем в процессе данного обзора (они тоже включена в пользовательский модуль my_module__stat.py):
graph_contingency_tables_hist_3D — функция для визуализации категориальных данных: построение трехмерных гистограмм;
graph_contingency_tables_mosaicplot_sm — функция для визуализации категориальных данных: построение мозаичных диаграмм;
make_color_mosaicplot_dict — функция формирует словарь (dict) для задания цветовых свойств мозаичной диаграммы, является вспомогательной для функции graph_contingency_tables_mosaicplot_sm;
graph_contingency_tables_bar_freqint — функция для визуализации категориальных данных: построение столбчатых диаграмм и графиков взаимодействия частот;
graph_contingency_tables_heatmap — функция для визуализации категориальных данных: построение графика «тепловой карты».
ВИЗУАЛИЗАЦИЯ ТАБЛИЦ СОПРЯЖЕННОСТИ
Вначале мы сформируем пользовательские функции для визуализации, а затем рассмотрим их применение на примере.
Трехмерные гистограммы
Трехмерные гистограммы являются очень выигрышными в визуальном плане, но, на мой взгляд, уступают в аналитическом значении мозаичным или столбчатым диаграммам. Их реализации в python выполняется с помощью функции mpl_toolkits.mplot3d.axes3d.Axes3D.bar3d (https://matplotlib.org/stable/api/_as_gen/mpl_toolkits.mplot3d.axes3d.Axes3D.bar3d.html); для получения нормального визуального изображения требуется настройка разнообразных параметров (подписей меток осей, расстояния между метками и осями и пр.); подробнее можно также ознакомится здесь: https://matplotlib.org/stable/gallery/mplot3d/3d_bars.html, https://matplotlib.org/stable/gallery/mplot3d/hist3d.html#, https://coderslegacy.com/python/3d-bar-chart-matplotlib/, https://pythonprogramming.net/3d-bar-chart-matplotlib-tutorial/.
def graph_contingency_tables_hist_3D(
data_df_in: pd.core.frame.DataFrame = None,
data_XY_list_in: list = None,
title_figure = None, title_figure_fontsize = 14,
title_axes = None, title_axes_fontsize = 16,
rows_label = None, cols_label = None, vertical_label = None, label_fontsize = 14,
rows_ticklabels_list = None, cols_ticklabels_list = None,
tick_fontsize = 11, rows_tick_rotation = 0, cols_tick_rotation = 0,
legend = None, legend_fontsize = 14,
labelpad = 20,
color=None,
tight_layout=True,
graph_size = (297/INCH, 210/INCH),
file_name = None):
"""Функция для визуализации категориальных данных: построение трехмерных гистограмм
Args:
data_df_in (pd.core.frame.DataFrame, optional): Массив исходных данных (тип - dataframe). Defaults to None.
data_XY_list_in (list, optional): Массив исходных данных (тип - list). Defaults to None.
title_figure (_type_, optional): Заголовок рисунка (Figure). Defaults to None.
title_figure_fontsize (int, optional): Размер шрифта заголовка рисунка (Figure). Defaults to 14.
title_axes (_type_, optional): Заголовок области рисования (Axes). Defaults to None.
title_axes_fontsize (int, optional): Размер шрифта заголовка области рисования (Axes). Defaults to 16.
rows_label (_type_, optional): Подпись оси (по срокам). Defaults to None.
cols_label (_type_, optional): Подпись оси (по столбцам). Defaults to None.
vertical_label (_type_, optional): Подпись вертикальной оси. Defaults to None.
label_fontsize (int, optional): Размер шрифта подписей осей. Defaults to 14.
rows_ticklabels_list (_type_, optional): Список меток для оси (по строкам). Defaults to None.
cols_ticklabels_list (_type_, optional): Список меток для оси (по столбцам). Defaults to None.
tick_fontsize (int, optional): Размер шрифта меток осей. Defaults to 11.
rows_tick_rotation (int, optional): Угол поворота меток для оси (по строкам). Defaults to 0.
cols_tick_rotation (int, optional): Угол поворота меток для оси (по столбцам). Defaults to 0.
legend (_type_, optional): Текст легенды. Defaults to None.
legend_fontsize (int, optional): Размер шрифта легенды. Defaults to 14.
labelpad (int, optional): Расстояние между осью и метками. Defaults to 20.
color (_type_, optional): Цвет графика. Defaults to None.
tight_layout (bool, optional): Автоматическая настройка плотной компоновки графика (да/нет, True/False). Defaults to True.
graph_size (tuple, optional): Размера графика. Defaults to (297/INCH, 210/INCH).
file_name (_type_, optional): Имя файла для сохранения на диске. Defaults to None.
"""
# создание рисунка (Figure) и области рисования (Axes)
fig = plt.figure(figsize=graph_size)
ax = plt.axes(projection = "3d")
#ax = fig.gca(projection='3d')
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
ax.set_title(title_axes, fontsize = title_axes_fontsize)
# данные для построения графика
if data_df_in is not None:
data = np.array(data_df_in)
NumOfCols = data_df_in.shape[1]
NumOfRows = data_df_in.shape[0]
else:
data = np.array(data_XY_list_in)
NumOfCols = np.shape(data)[1]
NumOfRows = np.shape(data)[0]
# координаты точки привязки столбцов
xpos = np.arange(0, NumOfCols, 1)
ypos = np.arange(0, NumOfRows, 1)
# формируем сетку координат
xpos, ypos = np.meshgrid(xpos + 0.5, ypos + 0.5)
xpos = xpos.flatten()
ypos = ypos.flatten()
# инициализируем для zpos нулевые значение, чтобы столбцы начинались с нуля
zpos = np.zeros(NumOfCols * NumOfRows)
# формируем ширину и глубину столбцов
dx = np.ones(NumOfRows * NumOfCols) * 0.5
dy = np.ones(NumOfCols * NumOfRows) * 0.5
# формируем высоту столбцов
dz = data.flatten()
# построение трехмерного графика
if not color:
ax.bar3d(xpos, ypos, zpos, dx, dy, dz)
else:
ax.bar3d(xpos, ypos, zpos, dx, dy, dz, color=color)
# подписи осей
x_label = cols_label if cols_label else ''
y_label = rows_label if rows_label else ''
z_label = vertical_label if vertical_label else ''
ax.set_xlabel(x_label, fontsize = label_fontsize)
ax.set_ylabel(y_label, fontsize = label_fontsize)
ax.set_zlabel(z_label, fontsize = label_fontsize)
# метки осей
x_ticklabels_list = cols_ticklabels_list if cols_ticklabels_list \
else list(data_df.columns) if (data_df is not None) else ''
y_ticklabels_list = rows_ticklabels_list if rows_ticklabels_list \
else list(data_df.index) if data_df is not None else ''
# форматирование меток осей (https://matplotlib.org/stable/api/ticker_api.html)
ax.xaxis.set_major_locator(IndexLocator(1.0, 0.25))
ax.yaxis.set_major_locator(IndexLocator(1.0, 0.25))
# устанавливаем метки осей
ax.set_xticklabels(x_ticklabels_list, fontsize = tick_fontsize, rotation=rows_tick_rotation)
ax.set_yticklabels(y_ticklabels_list, fontsize = tick_fontsize, rotation=cols_tick_rotation)
# расстояние между подписями осей и метками осей
ax.xaxis.labelpad = labelpad
ax.yaxis.labelpad = labelpad
# легенда
if legend:
b1 = plt.Rectangle((0, 0), 1, 1)
ax.legend([b1], [legend], prop={'size': legend_fontsize})
# автоматическая настройка плотной компоновки графика
if tight_layout:
fig.tight_layout()
# вывод графика
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
returnМозаичные диаграммы
Мозаичные диаграммы (диаграммы Маримекко) эффективны как в визуальном, так и в аналитическом плане. Их реализации в python выполняется с помощью функции statsmodels.graphics.mosaicplot.mosaic (https://www.statsmodels.org/dev/generated/statsmodels.graphics.mosaicplot.mosaic.html); для получения нормального визуального изображения требуется весьма своеобразная настройка параметров, в частности задание свойств цветов графика выполняется с помощью специального словаря (dict), для этого мы формируем пользовательскую функцию make_color_mosaicplot_dict.
Можно, конечно, сформировать мозаичную диаграмму из обычной столбчатой диаграммы (см., например, https://towardsdatascience.com/marimekko-charts-with-pythons-matplotlib-6b9784ae73a1), но здесь мы рассматривать этот способ не будем.
def graph_contingency_tables_mosaicplot_sm(
data_df_in: pd.core.frame.DataFrame = None,
data_XY_list_in: list = None,
properties: dict = {},
labelizer: bool = True,
title_figure = None, title_figure_fontsize = 12,
title_axes = None, title_axes_fontsize = 16,
x_label = None, y_label = None, label_fontsize = 14,
x_ticklabels_list = None, y_ticklabels_list = None,
x_ticklabels: bool = True, y_ticklabels: bool = True,
#tick_fontsize = 11,
tick_label_rotation = 0,
legend_list = None, legend_fontsize = 11,
text_fontsize = 16,
gap = 0.005,
horizontal: bool = True,
statistic: bool = True,
tight_layout=True,
graph_size = (297/INCH, 210/INCH),
file_name = None):
"""Функция для визуализации категориальных данных: построение мозаичных диаграмм
Args:
data_df_in (pd.core.frame.DataFrame, optional): Массив исходных данных (тип - DataFrame). Defaults to None.
data_XY_list_in (list, optional): Массив исходных данных (тип - list). Defaults to None.
properties (dict, optional): Функция возвращает словарь свойств плиток графика (цвет, штриховка и пр.). Defaults to {}.
labelizer (bool, optional): Функция генерирует текст для отображения в центре каждой плитки графика. Defaults to True.
title_figure (_type_, optional): Заголовок рисунка (Figure). Defaults to None.
title_figure_fontsize (int, optional): Размер шрифта заголовка рисунка (Figure). Defaults to 12.
title_axes (_type_, optional): Заголовок области рисования (Axes). Defaults to None.
title_axes_fontsize (int, optional): Размер шрифта заголовка области рисования (Axes). Defaults to 16.
x_label (_type_, optional): Подпись оси OX. Defaults to None.
y_label (_type_, optional): Подпись оси OY. Defaults to None.
label_fontsize (int, optional): Размер шрифта подписей. Defaults to 14.
x_ticklabels_list (_type_, optional): Список меток для оси OX. Defaults to None.
y_ticklabels_list (_type_, optional): Список меток для оси OY. Defaults to None.
x_ticklabels (bool, optional): Отображать на графике (да/нет, True/False) метки для оси OX. Defaults to True.
y_ticklabels (bool, optional): Отображать на графике (да/нет, True/False) метки для оси OY. Defaults to True.
tick_fontsize (int, optional): Временно заблокировано. Defaults to 11.
tick_label_rotation (int, optional): Угол поворота меток для оси. Defaults to 0.
legend_list (_type_, optional): Список названий категорий для легенды. Defaults to None.
legend_fontsize (int, optional): Размер шрифта легенды. Defaults to 11.
text_fontsize (int, optional): Размер шрифта подписей в центре плиток графика. Defaults to 16.
gap (float, optional): Список зазоров. Defaults to 0.005.
horizontal (bool, optional): Начальное направление разделения. Defaults to True.
statistic (bool, optional): Применять статистическую модель для придания цвета графику (да/нет, True/False). Defaults to True.
tight_layout (bool, optional): Автоматическая настройка плотной компоновки графика (да/нет, True/False). Defaults to True.
graph_size (tuple, optional): Размера графика. Defaults to (297/INCH, 210/INCH).
file_name (_type_, optional): Имя файла для сохранения на диске. Defaults to None.
"""
# создание рисунка (Figure) и области рисования (Axes)
fig, axes = plt.subplots(figsize=graph_size)
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
axes.set_title(title_axes, fontsize = title_axes_fontsize)
# данные для построения графика
if data_df_in is not None:
data_df = data_df_in.copy()
if x_ticklabels_list:
data_df = data_df.set_index(pd.Index(x_ticklabels_list))
else:
data_df = pd.DataFrame(data_XY_list_in)
if x_ticklabels_list:
data_df = data_df.set_index(pd.Index(x_ticklabels_list))
if y_ticklabels_list:
data_df.columns = y_ticklabels_list
data_np = np.array(data_XY_list_in) if data_XY_list_in is not None \
else np.array(data_df_in)
# установка шрифта подписей в теле графика
if text_fontsize:
plt.rcParams["font.size"] = text_fontsize
# метки осей
if data_df is not None:
x_list = list(map(str, x_ticklabels_list)) if x_ticklabels_list \
else list(map(str, data_df.index))
y_list = list(map(str, y_ticklabels_list)) if y_ticklabels_list \
else list(map(str, data_df.columns))
else:
x_list = list(map(str, x_ticklabels_list)) if x_ticklabels_list \
else list(map(str, range(data_np.shape[0])))
y_list = list(map(str, y_ticklabels_list)) if y_ticklabels_list \
else list(map(str, range(data_np.shape[1])))
if not labelizer:
if not x_ticklabels:
axes.tick_params(axis='x', colors='white')
if not y_ticklabels:
axes.tick_params(axis='y', colors='white')
# подписи осей
x_label = x_label if x_label else ''
y_label = y_label if y_label else ''
axes.set_xlabel(x_label, fontsize = label_fontsize)
axes.set_ylabel(y_label, fontsize = label_fontsize)
# формируем словарь (dict) data
data_dict = {}
for i, x in enumerate(x_list):
for j, y in enumerate(y_list):
data_dict[(x, y)] = data_np[i, j]
print(f'data_dict = \n{data_dict}')
# формируем словарь (dict) labelizer и функцию labelizer_func
labelizer_dict = {}
for i, x in enumerate(x_list):
for j, y in enumerate(y_list):
labelizer_dict[(x, y)] = data_np[i, j] if labelizer else ''
labelizer_func = lambda k: labelizer_dict[k]
# построение графика
from statsmodels.graphics.mosaicplot import mosaic
mosaic(data_dict,
title=title_axes,
statistic=statistic,
ax=axes,
horizontal=horizontal,
gap=gap,
label_rotation=tick_label_rotation,
#axes_label=False,
labelizer=labelizer_func,
properties=properties)
# легенда
if legend_list:
axes.legend(legend_list,
bbox_to_anchor=(1, 0.5),
loc="center left",
#mode="expand",
ncol=1)
# автоматическая настройка плотной компоновки графика
if tight_layout:
fig.tight_layout()
# вывод графика
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
# возврат размера шрифта подписей в теле графика по умолчанию
if text_fontsize:
plt.rcParams["font.size"] = 10
returnНастройка цвета в мозаичных диаграммах
Настройку цвета в мозаичных диаграммах можно выполнить двумя способами:
С помощью функции — предпочтительно для таблиц 2×2.
С помощью словаря (dict).
Оба этих способа мы рассмотрим далее.
С помощью словаря можно задать индивидуально цвет каждой плитки диаграммы, или настроить цвет отдельных строк или столбцов. Для формирования словаря будем применять пользовательскую функцию make_color_mosaicplot_dict:
def make_color_mosaicplot_dict(
rows_list, cols_list,
props_dict_rows=None,
props_dict_cols=None):
"""Функция формирует словарь свойств плиток мозаичного графика (цвет, штриховка и пр.) для функции graph_contingency_tables_mosaicplot_sm
Args:
rows_list (_type_): Список категорий (по строкам)
cols_list (_type_): Список категорий (по столбцам)
props_dict_rows (_type_, optional): Словарь цветовых свойств категорий (по строкам). Defaults to None.
props_dict_cols (_type_, optional): Словарь цветовых свойств категорий (по столбцам). Defaults to None.
Returns:
_type_: словарь свойств плиток мозаичного графика (цвет, штриховка и пр.) для функции graph_contingency_tables_mosaicplot_sm
"""
result = {}
rows = list(map(str, rows_list))
cols = list(map(str, cols_list))
if props_dict_rows:
for col in cols:
for row in rows:
result[(col, row)] = {'facecolor': props_dict_rows[row]}
if props_dict_cols:
for col in cols:
for row in rows:
result[(col, row)] = {'facecolor': props_dict_cols[col]}
return result Столбчатая диаграмма и графики взаимодействия частот
Старая добрая столбчатая диаграмма pandas.DataFrame.plot.bar (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.bar.html) будет более эффективной, если объединить график абсолютных частот, график относительных частот и график взаимодействия частот.
На графиках взаимодействия частот следует остановиться отдельно. Считается, что это способ экспресс-оценки значимости связей между категориальными переменными (чем больше наклон линий на графике, тем сильнее связь; горизонтальная линия означает полное отсутствие связи), но наиболее эффективным этот график будет для таблиц сопряженности 2×2 (подробнее об этом — см. например, [3], https://cyberleninka.ru/article/n/razrabotka-vizualnogo-metoda-issledovaniya-zavisimosti-kategorialnyh-peremennyh-na-osnove-tablits-sopryazhennosti/viewer). Разумеется, подтверждать оценку значимости нужно проверкой статистических гипотез.
def graph_contingency_tables_bar_freqint(
data_df_in: pd.core.frame.DataFrame = None,
data_XY_list_in: list = None,
graph_inclusion='arf',
title_figure=None, title_figure_fontsize=14, title_axes_fontsize=11,
x_label = None, y_label = None, label_fontsize = 11,
x_ticklabels_list = None, y_ticklabels_list = None, #tick_fontsize = 11,
color = None,
tight_layout=True,
result_output=False,
graph_size=None,
file_name=None):
"""Функция для визуализации категориальных данных: построение столбчатых диаграмм и графиков взаимодействия частот
Args:
data_df_in (pd.core.frame.DataFrame, optional): Массив исходных данных (тип - DataFrame). Defaults to None.
data_XY_list_in (list, optional): Массив исходных данных (тип - list). Defaults to None.
graph_inclusion (str, optional): Параметр, определяющий перечень графиков, которые строит функция:
'a' - столбчатая диаграмма (в абсолютных частотах)
'r' - столбчатая диаграмма (в относительных частотах)
'f' - график взаимодействия частот
Defaults to 'arf'.
title_figure (_type_, optional): Заголовок рисунка (Figure). Defaults to None.
title_figure_fontsize (int, optional): Размер шрифта заголовка рисунка (Figure). Defaults to 14.
title_axes_fontsize (int, optional): Размер шрифта заголовка области рисования (Axes). Defaults to 11.
x_label (_type_, optional): Подпись оси OX. Defaults to None.
y_label (_type_, optional): Подпись оси OY. Defaults to None.
label_fontsize (int, optional): Размер шрифта подписей по осям_. Defaults to 11.
x_ticklabels_list (_type_, optional): Список меток для оси OX. Defaults to None.
y_ticklabels_list (_type_, optional): Список меток для оси OY. Defaults to None.
tick_fontsize (int, optional): Временно заблокировано. Defaults to 11.
color (_type_, optional): Список, задающий цвета для категорий. Defaults to None.
tight_layout (bool, optional): Автоматическая настройка плотной компоновки графика (да/нет, True/False). Defaults to True.
result_output (bool, optional): Выводить таблицу (DataFrame) c числовыми данными (да/нетб True/False). Defaults to False.
graph_size (_type_, optional): Размера графика. Defaults to None.
file_name (_type_, optional): Имя файла для сохранения на диске. Defaults to None.
"""
# данные для построения графика
if data_df_in is not None:
data_df_abs = data_df_in.copy()
if x_ticklabels_list:
data_df_abs = data_df_abs.set_index(pd.Index(x_ticklabels_list))
if y_ticklabels_list:
data_df_abs.columns = y_ticklabels_list
else:
data_df_abs = pd.DataFrame(data_XY_list_in)
if x_ticklabels_list:
data_df_abs = data_df_abs.set_index(pd.Index(x_ticklabels_list))
if y_ticklabels_list:
data_df_abs.columns = y_ticklabels_list
data_df_rel = None
data_np = np.array(data_XY_list_in) if data_XY_list_in is not None \
else np.array(data_df_in)
# определение формы и размеров области рисования (Axes)
count_graph = len(graph_inclusion) # число графиков
ax_rows = 1
ax_cols = count_graph # размерность области рисования (Axes)
# создание рисунка (Figure) и области рисования (Axes)
graph_size_dict = {
1: (297/INCH*0.75, 210/INCH),
2: (297/INCH*1.5, 210/INCH),
3: (297/INCH*2.25, 210/INCH)}
if not(graph_size):
graph_size = graph_size_dict[count_graph]
fig = plt.figure(figsize=graph_size)
if count_graph == 3:
ax1 = plt.subplot(1,3,1)
ax2 = plt.subplot(1,3,2)
ax3 = plt.subplot(1,3,3)
elif count_graph == 2:
ax1 = plt.subplot(1,2,1)
ax2 = plt.subplot(1,2,2)
elif count_graph == 1:
ax1 = plt.subplot(1,1,1)
# заголовок рисунка (Figure)
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
# столбчатая диаграмма (абсолютные частоты)
if 'a' in graph_inclusion:
if color:
data_df_abs.plot.bar(
color = color,
stacked=True,
rot=0,
legend=True,
ax=ax1)
else:
data_df_abs.plot.bar(
#color = color_list,
stacked=True,
rot=0,
legend=True,
ax=ax1)
ax1.legend(loc='best', fontsize = 12, title=data_df_abs.columns.name)
ax1.set_title('Absolute values', fontsize=title_axes_fontsize)
ax1.set_xlabel(x_label, fontsize = label_fontsize)
ax1.set_ylabel(y_label, fontsize = label_fontsize)
# столбчатая диаграмма (относительные частоты)
if 'r' in graph_inclusion:
data_df_rel = data_df_abs.copy()
sum_data = np.sum(data_np)
data_df_abs.sum(axis=1)
for col in data_df_rel.columns:
data_df_rel[col] = data_df_rel[col] / data_df_abs.sum(axis=1)
if color:
data_df_rel.plot.bar(
color = color,
stacked=True,
rot=0,
legend=True,
ax = ax1 if (graph_inclusion == 'r') or (graph_inclusion == 'rf') else ax2,
alpha = 0.5)
else:
data_df_rel.plot.bar(
#color = color,
stacked=True,
rot=0,
legend=True,
ax = ax1 if (graph_inclusion == 'r') or (graph_inclusion == 'rf') else ax2,
alpha = 0.5)
if (graph_inclusion == 'r') or (graph_inclusion == 'rf'):
ax1.legend(loc='best', fontsize = 12, title=data_df_abs.columns.name)
ax1.set_title('Relative values', fontsize=title_axes_fontsize)
ax1.set_xlabel(x_label, fontsize = label_fontsize)
ax1.set_ylabel(y_label, fontsize = label_fontsize)
else:
ax2.legend(loc='best', fontsize = 12, title=data_df_abs.columns.name)
ax2.set_title('Relative values', fontsize=title_axes_fontsize)
ax2.set_xlabel(x_label, fontsize = label_fontsize)
ax2.set_ylabel(y_label, fontsize = label_fontsize)
# график взаимодействия частот
if 'f' in graph_inclusion:
if color:
sns.lineplot(
data=data_df_abs,
palette = color,
dashes=False,
lw=3,
#markers=['o','o'],
markersize=10,
ax=ax1 if (graph_inclusion == 'f') else ax3 if (graph_inclusion == 'arf') else ax2)
else:
sns.lineplot(
data=data_df_abs,
#palette = color,
dashes=False,
lw=3,
#markers=['o','o'],
markersize=10,
ax=ax1 if (graph_inclusion == 'f') else ax3 if (graph_inclusion == 'arf') else ax2)
if (graph_inclusion == 'f'):
ax1.legend(loc='best', fontsize = 12, title=data_df_abs.columns.name)
ax1.set_title('Graph of frequency interactions', fontsize=title_axes_fontsize)
ax1.set_xlabel(x_label, fontsize = label_fontsize)
ax1.set_ylabel(y_label, fontsize = label_fontsize)
elif (graph_inclusion == 'arf'):
ax3.legend(loc='best', fontsize = 12, title=data_df_abs.columns.name)
ax3.set_title('Graph of frequency interactions', fontsize=title_axes_fontsize)
ax3.set_xlabel(x_label, fontsize = label_fontsize)
ax3.set_ylabel(y_label, fontsize = label_fontsize)
else:
ax2.legend(loc='best', fontsize = 12, title=data_df_abs.columns.name)
ax2.set_title('Graph of frequency interactions', fontsize=title_axes_fontsize)
ax2.set_xlabel(x_label, fontsize = label_fontsize)
ax2.set_ylabel(y_label, fontsize = label_fontsize)
# автоматическая настройка плотной компоновки графика
if tight_layout:
fig.tight_layout()
# вывод графика
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
# формирование и вывод результата
if result_output:
data_df_abs['sum'] = data_df_abs.sum(axis=1)
if data_df_rel is not None:
data_df_rel['sum'] = data_df_rel.sum(axis=1)
print('\nAbsolute values:')
display(data_df_abs)
print('\nRelative values:')
display(data_df_rel)
else:
print('\nAbsolute values:')
display(data_df_abs)
return
График «тепловой карты» (heatmap)
График «тепловой карты» (heatmap) весьма эффективен в визуальном и аналитическом плане, он реализуется в python с помощью функции seaborn.heatmap (https://seaborn.pydata.org/generated/seaborn.heatmap.html). В зависимости от особенностей исходных данных имеет смысл строить этот график либо для абсолютных, либо для относительных частот (долей); ну и для эффективной визуализации настроить цветовую шкалу (https://matplotlib.org/stable/tutorials/colors/colormaps.html).
def graph_contingency_tables_heatmap(
data_df_in: pd.core.frame.DataFrame = None,
data_XY_list_in: list = None,
title_figure = None, title_figure_fontsize = 12,
title_axes = None, title_axes_fontsize = 14,
x_label = None, y_label = None, #label_fontsize = 11,
x_ticklabels_list = None, y_ticklabels_list = None, #tick_fontsize = 11,
values_type = 'absolute',
color_map='binary',
robust = False,
fmt = '.0f',
tight_layout=True,
#result_output = False,
graph_size = (297/INCH/2, 210/INCH/2),
file_name = None):
"""Функция для визуализации категориальных данных: построение графика тепловой карты (heatmap)
Args:
data_df_in (pd.core.frame.DataFrame, optional): Массив исходных данных (тип - DataFrame). Defaults to None.
data_XY_list_in (list, optional): Массив исходных данных (тип - list). Defaults to None.
title_figure (_type_, optional): Заголовок рисунка (Figure). Defaults to None.
title_figure_fontsize (int, optional): Размер шрифта заголовка рисунка (Figure). Defaults to 12.
title_axes (_type_, optional): Заголовок области рисования (Axes). Defaults to None.
title_axes_fontsize (int, optional): Размер шрифта заголовка области рисования (Axes). Defaults to 14.
x_label (_type_, optional): Подпись оси OX. Defaults to None.
y_label (_type_, optional): Подпись оси OY. Defaults to None.
label_fontsize (int, optional): Временно заблокировано. Defaults to 11.
x_ticklabels_list (_type_, optional): Список меток для оси OX. Defaults to None.
y_ticklabels_list (_type_, optional): Список меток для оси OY. Defaults to None.
tick_fontsize (int, optional): Временно заблокировано. Defaults to 11.
values_type (str, optional): Параметр, задающий в каких частотах строится график:
абсолютные/относительные, absolute/relative.
Defaults to 'absolute'.
color_map (str, optional): Цветовая карта (colormap) для графика. Defaults to 'binary'.
robust (bool, optional): Если True и vmin или vmax отсутствуют, диапазон цветовой карты вычисляется
с надежными квантилями вместо экстремальных значений. Defaults to False.
fmt (str, optional): Числовой формат подписей в центре плиток графика. Defaults to '.0f'.
tight_layout (bool, optional): Автоматическая настройка плотной компоновки графика (да/нет, True/False). Defaults to True.
graph_size (tuple, optional): Размера графика. Defaults to (297/INCH/2, 210/INCH/2).
file_name (_type_, optional): Имя файла для сохранения на диске. Defaults to None.
"""
# создание рисунка (Figure) и области рисования (Axes)
fig, axes = plt.subplots(figsize=graph_size)
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
axes.set_title(title_axes, fontsize = title_axes_fontsize)
# данные для построения графика
if data_df_in is not None:
data_df = data_df_in.copy()
if x_ticklabels_list:
data_df = data_df.set_index(pd.Index(x_ticklabels_list))
if y_ticklabels_list:
data_df.columns = y_ticklabels_list
else:
data_df = pd.DataFrame(data_XY_list_in)
if x_ticklabels_list:
data_df = data_df.set_index(pd.Index(x_ticklabels_list))
if y_ticklabels_list:
data_df.columns = y_ticklabels_list
data_np = np.array(data_XY_list_in) if data_XY_list_in is not None \
else np.array(data_df_in)
data_df_rel = None
if values_type == 'relative':
data_df_rel = data_df.copy()
sum_data = np.sum(data_np)
data_df.sum(axis=1)
for col in data_df_rel.columns:
data_df_rel[col] = data_df_rel[col] / sum_data
# построение графика
if values_type == "absolute":
if not robust:
sns.heatmap(data_df.transpose(),
#vmin=0, vmax=1,
linewidth=0.5,
cbar=True,
fmt=fmt,
annot=True,
cmap=color_map,
ax=axes)
else:
sns.heatmap(data_df.transpose(),
#vmin=0, vmax=1,
linewidth=0.5,
cbar=True,
robust=True,
fmt=fmt,
annot=True,
cmap=color_map,
ax=axes)
else:
if not robust:
sns.heatmap(data_df_rel.transpose(),
vmin=0, vmax=1,
linewidth=0.5,
cbar=True,
fmt=fmt,
annot=True,
cmap=color_map,
ax=axes)
else:
sns.heatmap(data_df_rel.transpose(),
vmin=0, vmax=1,
linewidth=0.5,
cbar=True,
robust=True,
fmt=fmt,
annot=True,
cmap=color_map,
ax=axes)
# автоматическая настройка плотной компоновки графика
if tight_layout:
fig.tight_layout()
# вывод графика
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
returnПРИМЕРЫ ВИЗУАЛИЗАЦИИ ТАБЛИЦ СОПРЯЖЕННОСТИ
В качестве примера рассмотрим хорошо известную всем специалистам по DataScience задачу (известную, так сказать, «в узком кругу ограниченных людей»©) , а именно — задачу о «Титанике» (https://www.kaggle.com/c/titanic).
Замечу, что мы здесь рассматриваем датасет о «Титанике» просто как пример для визуализации таблиц сопряженности, цели решать эту задачу мы здесь не ставим, поэтому выполнять визуализацию многофакторных зависимостей (например, зависимость выживаемости от класса билета, возраста и пола пассажира) не будем. Это выходит за рамки данного обзора, так что ограничимся двухфакторными зависимостями.
Настройка заголовков отчета:
# Общий заголовок проекта
Task_Project = 'Titanic - Machine Learning from Disaster (https://www.kaggle.com/c/titanic)'Подготовка исходных данных
Скачаем с сайта https://www.kaggle.com/c/titanic и загрузим исходные данные из csv-файлов:
тренировочный набор данных train.csv (содержит выборку пассажиров с известным исходом, т.е. выжил или нет);
набор данных для тестирования test.csv (содержит другую выборку пассажиров без зависимой переменной).
train_df = pd.read_csv('data/train.csv')
display(train_df)
#display(train_df.head(), train_df.tail())
train_df.info()
train_df.describe()

test_df = pd.read_csv('data/test.csv')
display(test_df)
#display(test_df.head(), test_df.tail())
test_df.info()
test_df.describe()

Создадим рабочие копии DataFrame:
dataset_train_df = train_df.copy()
dataset_test_df = test_df.copy()Пример 1: визуализация состава и структуры совокупности пассажиров
Предположим, вначале мы хотим проанализировать состав и структуру совокупности пассажиров «Титаника».
Для этого объединим оба файла исходных данных в один датасет:
dataset_df = pd.concat([dataset_train_df, dataset_test_df], axis=0, ignore_index=True)
display(dataset_df)
#display(dataset_df.head(), dataset_df.tail())
dataset_df.info()
dataset_df.describe()
display(dataset_df['PassengerId'].nunique())
#display(dataset_df.describe(include = ['category']))
К слову, не всегда начинают исследование с такого анализа, наоборот, часто он выполняется как элемент дополнительного изучения отдельных закономерностей, вызвавших вопросы у исследователя. Например, несколько забегая вперед, далее при анализе факторов, влияющих на выживаемость пассажиров «Титаника», мы установим, что вероятность выжить несколько выше для пассажиров, взошедших на борт судна в порту Шербура (Cherbourg). Чтобы разобраться в причинах этого явления, придется проанализировать совокупность пассажиров в разрезе зависимости порта посадки и прочих факторов (класса билета, пола, возраста, наличия детей и т.д.). Но в данном обзоре, в целях визуализации, мы вначале все-таки остановимся на анализе состава и структуры изучаемого датасета.
Распределение пассажиров по классам билета (Pclass) и полу (Sex)
Первичная обработка и группировка данных
Проверим пропуски по полям Pclass и Sex с помощью графика «тепловой карты»:
data_df = dataset_df.loc[:, ['Pclass', 'Sex']]
result_df, detection_values_df = df_detection_values(data_df, detection_values=[0, ' ', nan, None])
display(result_df)
Вывод: пропуски отсутствуют.
Группировка данных:
dataset_df_Pclass_Sex = dataset_df.pivot_table(
values='PassengerId',
index='Pclass',
columns='Sex',
aggfunc='count',
fill_value=0,
margins=True)
#display(dataset_df_Pclass_Sex)
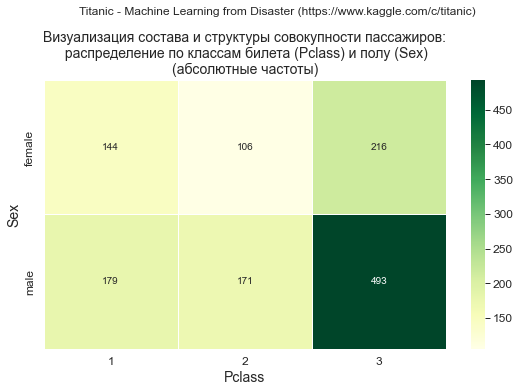
print(dataset_df_Pclass_Sex)Sex female male All
Pclass
1 144 179 323
2 106 171 277
3 216 493 709
All 466 843 1309Визуализация с помощью трехмерной гистограммы и мозаичной диаграммы
dataset_df_sample = dataset_df_Pclass_Sex.copy()
data_df = dataset_df_sample.iloc[:dataset_df_sample.shape[0]-1, :dataset_df_sample.shape[1]-1]
title_axes = 'Визуализация состава и структуры совокупности пассажиров:\n распределение по классам билета (Pclass) и полу (Sex)'
graph_contingency_tables_hist_3D(data_df,
title_figure = Task_Project, title_figure_fontsize = 12,
title_axes = title_axes, title_axes_fontsize = 16,
rows_label = 'Pclass',
cols_label = 'Sex',
vertical_label = 'Number of passengers',
#graph_size = (297/INCH*1.5, 210/INCH*1.5)
)
props_func = lambda key: {'color': 'grey' if 'male' in key else 'orange'}
graph_contingency_tables_mosaicplot_sm(
data_df_in=data_df,
properties=props_func,
title_figure = Task_Project, title_figure_fontsize = 12,
title_axes = title_axes,
x_label = 'Pclass',
y_label = 'Sex',
#statistic = False,
#graph_size = (297/INCH, 210/INCH)
)

Вывод: доля мужчин среди пассажиров 3 класса выше, чем в 1 и 2 классе.
Визуализация с помощью столбчатой диаграммы и графика взаимодействия частот
graph_contingency_tables_bar_freqint(
data_df_in=data_df,
graph_inclusion='arf',
title_figure = title_axes, title_figure_fontsize = 16,
result_output=True,
tight_layout=False,
graph_size=(297/INCH*1.5, 210/INCH/1.25)
)
Вывод: график взаимодействия частот позволяет предположить наличие связи между признаками.
Визуализация с помощью графика «тепловой карты» (heatmap)
Формируем графики абсолютных и относительных (доли каждой категории в общем объеме совокупности) частот:
# абсолютные частоты
graph_contingency_tables_heatmap(
data_df_in=data_df,
title_figure = Task_Project, #title_figure_fontsize = 14,
title_axes = title_axes + '\n(абсолютные частоты)', title_axes_fontsize = 14,
#values_type = 'absolute',
color_map='YlGn',
graph_size=(297/INCH/1.5, 210/INCH/1.5)
)
# относительные частоты
graph_contingency_tables_heatmap(
data_df_in=data_df,
title_figure = Task_Project, #title_figure_fontsize = 14,
title_axes = title_axes + '\n(относительные частоты)', title_axes_fontsize = 14,
values_type = 'relative',
#color_map='YlGn',
fmt = '.4f',
graph_size=(297/INCH/1.5, 210/INCH/1.5)
)

Распределение пассажиров по классам билета (Pclass) и возрасту (Age)
Первичная обработка и группировка данных
Так как возраст (Age) в нашем датасете есть количественная категория, трансформируем его в качественную, используя следующую периодизацию:
ранний возраст (early age): до 3 лет;
раннее детство (early childhood): свыше 3 до 7 лет;
детство (childhood): свыше 7 до 13 лет;
юность (adolescence): свыше 13 до 21 года;
зрелость (maturity): свыше 21 до 55 лет;
преклонный возраст (advanced age): свыше 55 до 75 лет;
старость (old age): свыше 75 лет.
# функция для трансформации поля Age
def age_transform_func(age):
age_periods_dict = {
'early age': 3,
'early childhood': 7,
'childhood': 13,
'adolescence': 21,
'maturity': 55,
'advanced age': 75,
'old age': 130}
age_scale = list(age_periods_dict.values())
if not age or isnan(age):
result = None
else:
for i, elem in enumerate(age_scale):
if abs(age) <= elem:
result = list(age_periods_dict.keys())[i]
break
return result
# добавляем в датасет поле Age period
dataset_df['Age period'] = dataset_df['Age'].apply(age_transform_func)
display(dataset_df)
# сохраняем откорректированный датасет в формате Excel (может пригодиться)
dataset_df.to_excel('dataset_df.xlsx')
Проверим пропуски по полям Pclass и Age с помощью графика «тепловой карты»:
data_df = dataset_df.loc[:, ['Pclass', 'Age', 'Age period']]
result_df, detection_values_df = df_detection_values(data_df, detection_values=[' ', 0, nan, None])
display(result_df)
Видим, что среди значений поля Age имеются пропуски, которые нужно исключить, чтобы они не исказили результаты анализа:
# формируем список строк, подлежащих удалению
drop_labels = []
for elem in detection_values_df.index:
if detection_values_df.loc[elem].any():
drop_labels.append(elem)
#display(drop_labels)
# удаляем строки
dataset_df_age = dataset_df.drop(index=drop_labels)
# проверяем результат удаления
data_df = dataset_df_age.loc[:, ['Pclass', 'Age', 'Age period']]
result_df, detection_values_df = df_detection_values(data_df, detection_values=[' ', 0, nan, None])
display(result_df)
Вывод: пропуски отсутствуют.
Группировка данных:
dataset_df_Pclass_AgePeriod = dataset_df_age.pivot_table(
values='PassengerId',
index='Pclass',
columns='Age period',
aggfunc='count',
fill_value=0,
margins=True)
#display(dataset_df_Pclass_AgePeriod)
print(dataset_df_Pclass_AgePeriod)Age period adolescence advanced age childhood early age early childhood \
Pclass
1 25 37 2 2 2
2 38 12 7 13 5
3 128 8 24 26 18
All 191 57 33 41 25
Age period maturity old age All
Pclass
1 214 2 284
2 186 0 261
3 297 0 501
All 697 2 1046 Изменим порядок столбцов в DataFrame в соответствии с порядком увеличения возраста:
dataset_df_Pclass_AgePeriod = dataset_df_Pclass_AgePeriod.loc[:, ['early age', 'early childhood', 'childhood', 'adolescence', 'maturity', 'advanced age', 'old age']]
#display(dataset_df_Pclass_AgePeriod)
print(dataset_df_Pclass_AgePeriod)Age period early age early childhood childhood adolescence maturity \
Pclass
1 2 2 2 25 214
2 13 5 7 38 186
3 26 18 24 128 297
All 41 25 33 191 697
Age period advanced age old age
Pclass
1 37 2
2 12 0
3 8 0
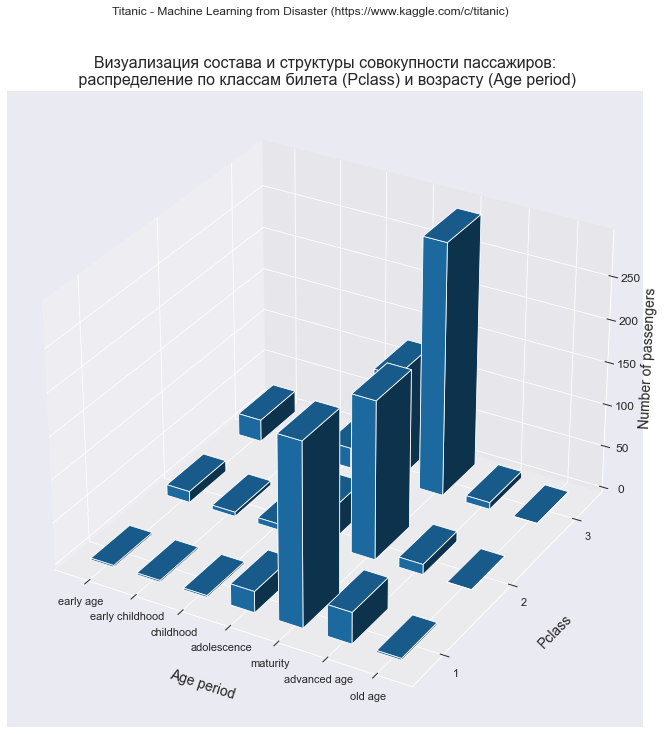
All 57 2 Визуализация с помощью трехмерной гистограммы
dataset_df_sample = dataset_df_Pclass_AgePeriod.copy()
data_df = dataset_df_sample.iloc[:dataset_df_sample.shape[0]-1, :dataset_df_sample.shape[1]]
title_axes = 'Визуализация состава и структуры совокупности пассажиров:\n распределение по классам билета (Pclass) и возрасту (Age period)'
graph_contingency_tables_hist_3D(data_df,
title_figure = Task_Project, title_figure_fontsize = 12,
title_axes = title_axes, title_axes_fontsize = 16,
rows_label = 'Pclass',
cols_label = 'Age period',
vertical_label = 'Number of passengers',
graph_size = (420/INCH, 297/INCH)
) 
Визуализация с помощью мозаичной диаграммы
Если мы построим мозаичную диаграмму с настройками по умолчанию, получится не очень визуально эстетическое изображение — из-за того, что в нашей таблице с
