Анализ распределения интервалов между покупками на R
Известно, что интервалы между сообщениями в онлайн-чате подчиняются степенному распределению, как утверждали ученые из Цюриха и Вены в 2012 году, а интервалы между двумя последовательными покупателями или двумя последовательными звонками в колл-центре подчиняются экспоненциальному распределению, как утверждает википедия.
А вот автор статьи на Хабре про типичные распределения вероятностей сказал бы, что глупо постулировать принадлежность чего-то определенному распределению, потому что разные сущности могут вести себя по-разному при соответствующих допущениях. Экспоненциальное распределение, например, лишь частный случай более общего распределения Вейбулла, которое позволяет моделировать увеличивающуюся (или уменьшающуюся) со временем интенсивность событий (поступления звонков или прихода покупателей). Таким образом, экспоненциальное распределение покупателей в магазине — абстракция, которая лишь в общих чертах описывает реальность. Посмотрите, например, историю с автобусами на Хабре.
Вернемся к примеру с распределением интервалов между сообщениями в онлайн-чате. Результаты указанной статьи лучше посмотреть в интерпретации журнала Physics Today. Можно утверждать, что процесс отправки сообщений коренным образом отличается от процессов поступления звонков в колл-центр или прихода автобусов на остановку. Поэтому и распределения у них отличаются.
Я решил сделать ресёрч интервалов между собственными банковскими тратами за последние полгода и с помощью статистических методов на R определить, какому распределению эти интервалы будут подчиняться. Ожидается, что процесс совершения оплаты в большей степени должен быть похож на процесс отправки сообщений, чем на процесс поступления звонков или прихода покупателей, хотя бы потому, что исходит от первого лица.

В статье я представляю:
Код на R для анализа любых временных интервалов.
Подбор экспоненциального и степенного распределения под данные с помощью метода максимального правдоподобия (MLE). Для экспоненциального я использую
fitdistr()из пакетаMASS, а для степенногоfit_power_law()из пакетаigraph.Проверку данных на соответствие подобранному распределению с помощью теста Колмогорова-Смирнова. Я использую функцию
ks.test()из пакетаstats.
В конце статьи я оставляю ряд открытых вопросов и буду рад, если в комментарии придет эксперт по подбору распределений под данные и сможет их прояснить.
Выгрузка данных
Для начала стоит выгрузить данные из банковского приложения. Как это сделать в Тинькоф или Рокетбанк, можно подсмотреть в статье на Хабре про статистику расходов по МСС.
В статье я буду рассматривать только интервалы размером менее суток, потому что для анализа интервалов продолжительностью более суток моих данных маловато (я не слишком часто оказывался вдали от цивилизации или сидел в спецприемниках).
library(data.table) # для работы с дата-фреймами
operations <- fread('operations.csv')
operations <- operations[`Сумма операции` < 0] # Оставим только покупки
operations <- operations[`Статус` == 'OK'] # Оставим только успешные покупки
operations <- operations[`Описание` != 'Комиссия за операцию']
# Уберем комиссию за переводы
operations <- operations[`Номер карты` != ''] # Уберем плату за обслуживание карты
# 1. Переводим строку в числовой формат с помощью strptime()
operations[, time := strptime(`Дата операции`, "%d.%m.%Y %H:%M:%S")]
# 2. Добавим в датафрейм разность между временем двух последовательных покупок (в секундах)
operations <- cbind(operations, as.numeric(diff(operations$time)))
colnames(operations)[17] <- "intervals" #Переименуем колонку для красоты
# 3. Переведем интервалы в часы и сделаем интервалы положительными
operations$intervals <- operations$intervals / (60*60)*(-1)
nrow(operations[intervals > 24])
# 4. Оставим только успешно проведенные операции
# интервалы меньше 24 часов и строго больше нуля
operations <- operations[intervals < 24, ,]
nrow(operations[intervals > 8 & intervals < 24])UPD: Прошу обратить внимание, что при очистке я не удалял регулярные платежи. Их очень мало в моей выборке, но на них стоит обратить внимание в случае большого количества подписок.
Итоговый вектор с интервалами, использованный для написания статьи, я выложил в открытый доступ.
Смотрим на данные глобально
После выгрузки и очистки посчитаем основные описательные статистики среди интервалов до 24 часов. Таких оказалось 912, а 36 интервалов в рассматриваемый промежуток не попали.
Построим базовые графики — плотность, гистограмму и боксплот.
Раскройте для просмотра кода на R
# Добавим в данные качественную переменную, разделяющую наши данные на 2 распределения
operations$distr <- ifelse(operations$intervals < 8, 'exp', 'norm')
# Медиана и среднее для экспоненциального распределения
med_exp <- median(operations[intervals < 8, intervals,])
mean_exp <- mean(operations[intervals < 8, intervals,])
# Медиана, среднее и стандартное отклонение для нормального распределения
med_norm <- median(operations[intervals > 8, intervals,])
mean_norm <- mean(operations[intervals > 8, intervals,])
sd_norm <- sd(operations[intervals > 8, intervals,])
# Гистограмма с цветовым разделением данных.
g1 <- ggplot(data = operations, aes(x = intervals, fill = distr)) +
geom_histogram(alpha = 0.5, binwidth = 1, show.legend = FALSE, colour = "black") +
coord_cartesian(xlim = c(0, 24)) +
labs(x = "Time intervals between two consecutive operations (hours)", y = NULL) +
annotate("label", x = 4, y = 150,
size = 4,
label= "n = 722",
fill="red", alpha = 0.25) +
annotate("label", x = 16, y = 100,
size = 4,
label= "n = 190",
fill="#00AFBB", alpha = 0.25) +
theme_bw()
# Двойной боксплот так же с разделением.
g2 <- ggplot(data = operations, aes(x = intervals, fill = distr)) +
geom_boxplot(alpha = 0.5, show.legend = FALSE)+
labs(x = "Time intervals between two consecutive operations (hours)", y = NULL) +
annotate("label", x = 16, y = -0.07,
size = 4,
label= paste("median =", round(med_norm, 2)) ,
fill="#00AFBB", alpha = 0.25) +
annotate("label", x = 16, y = -0.195,
size = 4,
label = paste("mean =", round(mean_norm, 2)),
fill = "#00AFBB", alpha = 0.25) +
annotate("label", x = 16, y = -0.318,
size = 4,
label = paste("sd =", round(sd_norm, 2)),
fill = "#00AFBB", alpha = 0.25) +
annotate("label", x = 2, y = 0.27,
size = 4,
label = paste("median =", round(med_exp, 2)),
fill="red", alpha = 0.2) +
annotate("label", x = 2, y = 0.13,
size = 4,
label = paste("mean =", round(mean_exp, 2)),
fill = "red", alpha = 0.2) +
coord_cartesian(xlim = c(0, 24)) +
theme_bw()
# 4. Соединяем график вместе
grid.arrange(g1, g2, nrow = 2, top = "The distribution of intervals between two consecutive operations of Vladimir Silkin (me)\n Focus on two parts of distribution") 
После анализа полученного распределения я принимаю решение разделить данные на 2 группы — примерно от 0 до 8 часов и от 8 до 24.
Распределение первых похоже на экспоненциальное или степенное, состоит из небольших промежутков и может быть связано с тратами, проходящими по определенным паттернам (сходить на прогулку и в разных местах много чего купить). Это мое оценочное суждение.
Распределение вторых похоже на нормальное. Оно состоит из промежутков около среднего времени бодрствования — 16 часов.
Можно ли описать данные указанными распределениями, узнаем чуть позже. Давайте сперва взглянем на них более детально.
Берем фокус на двух частях распределения
Экспоненциальное/степенное, которое связано небольшими промежутками трат обозначено на следующем графике красным цветом. Околонормальное распределение данных возле среднего промежутка бодрствования обозначено синим цветом.
Раскройте для просмотра кода на R
# Добавим в данные качественную переменную, разделяющую наши данные на 2 распределения
operations$distr <- ifelse(operations$intervals < 8, 'exp', 'norm')
# Медиана и среднее для экспоненциального распределения
med_exp <- median(operations[intervals < 8, intervals,])
mean_exp <- mean(operations[intervals < 8, intervals,])
# Медиана, среднее и стандартное отклонение для нормального распределения
med_norm <- median(operations[intervals > 8, intervals,])
mean_norm <- mean(operations[intervals > 8, intervals,])
sd_norm <- sd(operations[intervals > 8, intervals,])
# Гистограмма с цветовым разделением данных.
g1 <- ggplot(data = operations, aes(x = intervals, fill = distr)) +
geom_histogram(alpha = 0.5, binwidth = 1, show.legend = FALSE, colour = "black") +
coord_cartesian(xlim = c(0, 24)) +
labs(x = "Time intervals between two consecutive operations (hours)", y = NULL) +
annotate("label", x = 4, y = 150,
size = 4,
label= "n = 722",
fill="red", alpha = 0.25) +
annotate("label", x = 16, y = 100,
size = 4,
label= "n = 190",
fill="#00AFBB", alpha = 0.25) +
theme_bw()
# Двойной боксплот так же с разделением.
g2 <- ggplot(data = operations, aes(x = intervals, fill = distr)) +
geom_boxplot(alpha = 0.5, show.legend = FALSE)+
labs(x = "Time intervals between two consecutive operations (hours)", y = NULL) +
annotate("label", x = 16, y = -0.07,
size = 4,
label= paste("median =", round(med_norm, 2)) ,
fill="#00AFBB", alpha = 0.25) +
annotate("label", x = 16, y = -0.195,
size = 4,
label = paste("mean =", round(mean_norm, 2)),
fill = "#00AFBB", alpha = 0.25) +
annotate("label", x = 16, y = -0.318,
size = 4,
label = paste("sd =", round(sd_norm, 2)),
fill = "#00AFBB", alpha = 0.25) +
annotate("label", x = 2, y = 0.27,
size = 4,
label = paste("median =", round(med_exp, 2)),
fill="red", alpha = 0.2) +
annotate("label", x = 2, y = 0.13,
size = 4,
label = paste("mean =", round(mean_exp, 2)),
fill = "red", alpha = 0.2) +
coord_cartesian(xlim = c(0, 24)) +
theme_bw()
# 4. Соединяем график вместе
grid.arrange(g1, g2, nrow = 2, top = "The distribution of intervals between two consecutive operations of Vladimir Silkin (me)\n Focus on two parts of distribution")
1. Проверка на нормальность
Сперва разберемся с околонормальным распределением. Посчитаем вероятность получить такие как у нас и более выраженные отклонения от нормальности с помощью тета Шапиро-Уилка.
shapiro.test(operations[intervals > 8, intervals])Получаем  То есть, если наша выборка, действительно, взята из нормального распределения, то вероятность получить такие и сколько угодно более выраженные отклонения от нормальности случайно равняется 3%. Я не стану отклонять гипотезу о том, что наши данные взяты из генеральной совокупности с нормальным распределением признака.
То есть, если наша выборка, действительно, взята из нормального распределения, то вероятность получить такие и сколько угодно более выраженные отклонения от нормальности случайно равняется 3%. Я не стану отклонять гипотезу о том, что наши данные взяты из генеральной совокупности с нормальным распределением признака.
Раскройте для просмотра кода на R
g1 <- ggplot(data = operations[intervals > 8], aes(x = intervals)) +
geom_density(size = 1,
aes(color = 'real density function')) +
stat_function(fun = dnorm,
aes(color = 'ideal normal distrubution'),
args = list(16,4),
size = 1) +
scale_colour_manual(NULL, values = c("darkgreen", "black")) +
geom_histogram(aes(y = stat(count) / sum(count)),
fill = "#00AFBB",
alpha = 0.4,
colour = "black",
binwidth = 1) +
coord_cartesian(xlim = c(8, 24)) +
labs(x = "Time intervals between two consecutive operations (hours)", y = NULL) +
theme_bw() +
theme(legend.position = c(0.82, 0.85),
legend.background = element_rect(fill = "white", color = "black"))
grid.arrange(g1, nrow = 1, top = "The distribution of intervals between two consecutive operations of Vladimir Silkin (me) \n Long intervals (longer than 8 hours and shorter than 24 hours)")На графике сплошная линия показывает функцию плотности наших данных, а пунктирная — функцию плотности идеального нормального распределения.
2. Подбор экспоненциального и степенного распределений.
Теперь попробуем фитануть плотность вероятности с помощью двух распределений — экспоненциального и степенного. Они перед вами.

Множитель перед степенной функцией во втором уравнении возникает из-за необходимости нормировки распределения, а сам степенной закон подбирается к данным, начиная от указанного  . В качестве его я буду брать минимальное значение интервала.
. В качестве его я буду брать минимальное значение интервала.
В работе Data-Scientist`а нет ничего сложного. Главное — подгрузить нужные библиотеки. (Маэстро)
library(MASS) # Для подбора экспоненциального распределения с помощью fitdistr()
library(igraph) # Для подбора степенного распределения с помощью fit_power_law()
library(stats) # Для проведения теста Колмогорова-СмирноваФитуем данные экспоненциальным распределением:
fit_e <- fitdistr(operations[intervals < 8, intervals], "exponential")
fit_e$estimate[1][[1]] # alpha
fit_e$sd[1][[1]] # alpha_error
ks.test(operations[intervals < 8, intervals], "pexp", fit_e$estimate, exact = TRUE)$p.value #p.valueПолучим  и
и 
Первое найдено с помощью метода максимального правдоподобия, а второе — с помощью теста Колмогорова-Смирнова.
Физический смысл результатов теста такой же, как и у результатов теста Шапиро-Уилка: если в генеральной совокупности данные, действительно, распределены экспоненциально, то вероятность получить такие и сколь угодно выраженные отклонения от экспоненциального распределения случайно, практически равна нулю. Про рассчитываемую в тесте статистику можно почитать в англоязычной статье википедии.
Фитуем данные степенным распределением:
fit_p <- fit_power_law(operations[intervals < 8, intervals],
xmin = min(operations$intervals),
implementation = "plfit")
# В xmin передается точка, начиная с которой выполняется подбор распределения
fit_p$alpha # alpha
fit_p$KS.p # p-уровень значимости из теста Колмогорова-СмирноваПолучим  и
и 
В случае со степенным распределением p.value повышается, но все равно не достигает ни одного общепринятого порога значимости.
Составим итоговую таблицу с результатами:
Equation | Parameter | Significance |
|---|---|---|
|
|
|
|
|
|






Посмотрим, как будут выглядеть наши фиты на графике.
Раскройте для просмотра кода на R
plaw <- function(x){(fit_p$alpha-1)*0.004166667^(fit_p$alpha-1)*x^(-fit_p$alpha)}
# plaw <- function(x, a, xmin){(a-1)*xmin^(a-1)*x^(-a)}
gf <- ggplot(data = operations[intervals < 8], aes(x = intervals)) +
geom_density(size = 1) +
geom_histogram(alpha = 0.3,
aes(y = stat(count) / sum(count)),
binwidth = 1,
fill = "red",
colour = "black")+
stat_function(fun = dexp, args = list(0.6136122), size = 1, colour = 'blue') +
stat_function(fun = plaw, size = 1, colour = 'red') +
# scale_colour_manual(NULL, values = c("red", "blue")) +
coord_cartesian(xlim = c(0, 8), ylim = c(0, 0.5))+
labs(x = "Time intervals between two consecutive operations (hours)", y = NULL) +
theme_bw()
# theme(legend.position = c(0.82, 0.85),
# legend.background = element_rect(fill = "white", color = "black"))
grid.arrange(gf, nrow = 1, top = "The distribution of time between two consecutive operations of Vladimir Silkin (me) \n Short intervals (shorter than 8 hours)")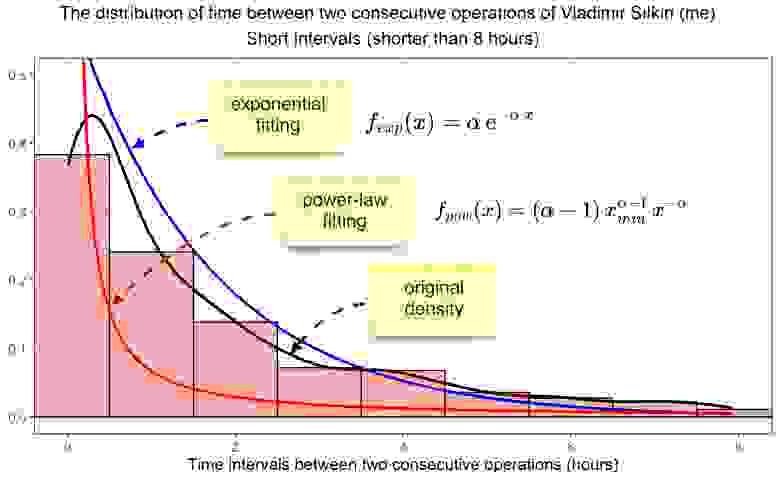
Выводы
Судя по финальной таблице с результатами, я не могу утверждать, что наши данные взяты из определенного распределения. Но совершенно точно можно сказать, что степенное распределение гораздо лучше под них подходит, несмотря на крошечный уровень значимости.
Я буду рад, если моя статья оказалось кому-то полезной. Если копать глубже, дальше и больше, то хотелось бы найти ответы на следующие вопросы:
Есть ли какой-то физический смысл у медианы распределения интервалов? Сейчас мне кажется, что она характеризует способность человека принимать спонтанные решения о покупках, поэтому я ожидаю, что она будет увеличиваться с возрастом.
Можно ли что-то сказать о теоретическом распределении интервалов между транзакциями и можно ли на основе полученных результатов утверждать о принадлежности к нему наших данных?
