[Перевод] Как найти и купить дом, если вы Data Scientist

Атма Мани, переводом статьи которого мы делимся к старту флагманского курса по Data Science, — ведущий инженер по продуктам ArcGIS API для Python в компании Esri. В этом материале он рассказывает, как при помощи ArcGIS и Python создать модель, выводящую короткий список домов в соответствии с потребностями и желаниями покупателя. Ссылку на репозиторий GitHub вы найдёте в конце статьи.
Сбор данных
Данные о жилье, собранные с сайта по недвижимости, пришли в нескольких CSV-файлах разных размеров. Они считывались pandas в объекты DataFrame, формирующие основу как пространственного, так и атрибутивного анализа. Файлы CSV объединены в списка из приблизительно 4200 объектов недвижимости.
Очистка и замена отсутствующих или неверных значений (вменение данных)
Первый и важнейший этап любого проекта по анализу данных и машинному обучению — обработка и очистка данных. Здесь данные страдают от дубликатов, недопустимых символов в названиях столбцов и выбросов.
Вменение данных выполнялось так:
Меры центральности, такие как среднее и медиана, использовались для вменения недостающих значений в столбцах LOT SIZE, PRICE PER SQ FT, и SQ FT.
Меры частоты, такие как мода, использовались для таких столбцов, как ZIP.
Строки с пропущенными значениями в BEDS, BATHS, PRICE, YEAR BUILT, LATITUDE и LONGITUDE были отброшены, способа спасти их не нашлось. Осталось 3 652 объекта.
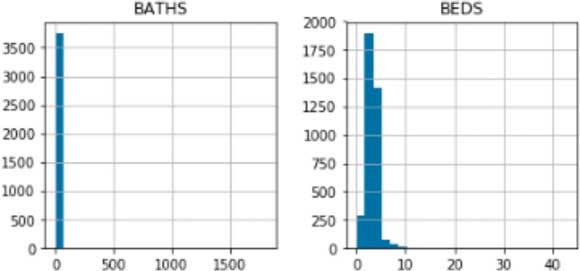 Гистограммы количества ванных комнат и спален показывают сильные искажения выбросами
Гистограммы количества ванных комнат и спален показывают сильные искажения выбросами
Удаление выбросов
Выбросы в данных о недвижимости могут быть вызваны многими причинами, такими как ошибочные форматы данных, плохие значения по умолчанию и типографские ошибки ввода данных. Выбросы могут обнаружить гистограммы числовых столбцов. На рисунке выше видно, что все дома имеют одинаковое количество спален и ванных комнат.
# explore distribution of numeric columns
ax_list = prop_df.hist(bins=25, layout=(4,4), figsize=(15,15))
Выбросы фильтруются по-разному. Популярен фильтр 6 сигма, удаляющий превышающие 3 стандартных отклонения от среднего значения. Фильтр предполагает, что данные следуют нормальному распределению, и использует среднее значение как меру центральности. Однако, когда данные сильно страдают от выбросов, как здесь, среднее значение может исказиться.
Фильтр Inter Quartile Range (IQR) использует медиану — более надёжную меру центральности. Он может надёжнее отфильтровать выбросы на заданном расстоянии от медианы. После удаления выбросов с помощью фильтра IQR распределение числовых столбцов выглядит гораздо более здоровым.
Гистограммы тех же числовых столбцов после вменения пропущенных значений и удаления выбросов
Разведывательный анализ данных
Pandas предоставляет эффективный API изучения статистического распределения числовых столбцов. Чтобы изучить пространственное распределение, воспользуйтесь API ArcGIS для Python.
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from arcgis.gis import GIS
from arcgis.features import GeoAccessor, GeoSeriesAccessorКлассы GeoAccessor и GeoSeriesAccessor добавляют фреймам данных pandas пространственную функциональность, то есть с помощью этих классов объект DataFrame со столбцами местоположения можно преобразовать в пространственный фрейм данных.
>>> prop_sdf = pd.DataFrame.spatial.from_xy(prop_df, 'LONGITUDE','LATITUDE')Аналогично статистической диаграмме DataFrame с помощью виджета можно построить график из пространственного фрейма интерактивной карты.
Для быстрой визуализации плотности объявлений возможен рендеринг, например тепловая карта.
Тепловая карта показывает «горячие точки»
API ArcGIS для Python поставляется с набором сложных рендеров, помогающих визуализировать пространственные изменения в таких колонках, как PROPERTY PRICE, AGE или SQUARE FOOTAGE.
Сочетание карт со статистическими графиками даёт более глубокое понимание и позволяет исследовать общие предположения.
Первый шорт-лист
Для составления шорт-листа использовались правила, основанные на внутренних особенностях домов.
>>> filtered_df = prop_sdf[(prop_df['BEDS']>=2) &
(prop_df['BATHS']>1)&
(prop_df['HOA PER MONTH']<=200) &
(prop_df['YEAR BUILT']>=2000) &
(prop_df['SQUARE FEET'] > 2000) &
(prop_df['PRICE']<=700000)]
>>> filtered_df.shape
(331, 23)Число объектов сократилось с 3 624 до 331. На карте эти объекты разбросаны по всему Портленду.
Гистограммы оставшегося 331 дома показывают, что большинство из них имеют четыре спальных места и большинство из них находятся в верхней части диапазона цен.
Количественная оценка доступности инфраструктуры
Покупая дом, вы ищете недвижимость, близкую к продуктовым магазинам, аптекам, пунктам неотложной помощи и паркам. Модуль геокодирования ArcGIS можно использовать, чтобы найти объекты в пределах заданного расстояния вокруг дома:
from arcgis.geocoding import geocode
# search for restaurants in neighborhood
restaurants = geocode('restaurant', search_extent=prop_buffer.extent, max_locations=200)
# search for hospitals
hospitals = geocode('hospital', search_extent=prop_buffer.extent, max_locations=50)Карта ниже показывает бакалеи, рестораны, больницы, кофейни, бары, заправки, магазины и сервисы, парки и образовательные учреждения в радиусе 5 миль от дома:
Выбранный случайным образом дом обозначен красной звездой, а расстояние в 5 миль — чёрным кругом. Синяя линия — самый быстрый маршрут от дома до места назначения (здесь это офис Esri Portland R&D).
Важный момент — время поездки на работу или в школу. Модуль network API ArcGIS для Python предоставляет инструменты расчёта направления движения и продолжительности поездки на основе исторической информации о дорожном движении. Сниппет в листинге ниже рассчитывает маршрут от дома до офиса Esri Portland R&D и время поездки в обычный понедельник в 8 часов утра.
Можно добавить несколько остановок. Эта информация может быть преобразована в pandas DataFrame и визуализирована в виде таблицы или гистограммы. Таким образом, дома сравнимы по доступности к удобствам в районе.
from arcgis.geocoding import geocode
# search for restaurants in neighborhood
restaurants = geocode('restaurant', search_extent=prop_buffer.extent, max_locations=200)
# search for hospitals
hospitals = geocode('hospital', search_extent=prop_buffer.extent, max_locations=50)Оставшийся 331 дом сравнивался с другими в пакетном режиме. В набор данных были добавлены различные объекты микрорайона. Был добавлен новый столбец с количеством объектов, к которым у объекта есть доступ в пределах заданного расстояния. Если рядом много однотипных объектов, все они конкурируют за один рынок, снижая цены и повышая качество обслуживания, то есть такие дома привлекательнее других.
Судя по гистограмме, многие из 331 дома находятся рядом с различными сервисами, и рынок Портленда, по-видимому, демонстрирует очень хорошие показатели, когда речь идёт о продолжительности поездки на работу и длине маршрута. Благодаря пространственному обогащению данных можно учитывать атрибуты местоположения в дополнение к внутренним характеристикам, таким как количество спален, ванных комнат и площадь.
Оценка недвижимости
Оценка домов — дело глубоко личное. Разные покупатели ищут разные дома. Есть приоритеты, поэтому присвоение различных весов характеристикам позволит получить взвешенную сумму (балл) для каждого дома.
Ниже показана функция подсчёта баллов, которая отражает относительную важность каждой характеристики дома. Желательные атрибуты обладают положительным весом, нежелательные — отрицательным.
def set_scores(row):
score = ((row['PRICE']*-1.5) + # penalize by 1.5 times
(row['BEDS']*1)+
(row['BATHS']*1)+
(row['SQUARE FEET']*1)+
(row['LOT SIZE']*1)+
(row['YEAR BUILT']*1)+
(row['HOA PER MONTH']*-1)+ # penalize by 1 times
(row['grocery_count']*1)+
(row['restaurant_count']*1)+
(row['hospitals_count']*1.5)+ # reward by 1.5 times
(row['coffee_count']*1)+
(row['bars_count']*1)+
(row['shops_count']*1)+
(row['travel_count']*1.5)+ # reward by 1.5 times
(row['parks_count']*1)+
(row['edu_count']*1)+
(row['commute_length']*-1)+ # penalize by 1 times
(row['commute_duration']*-2) # penalize by 2 times
)
return scoreМасштабирование данных
Хотя функция оценки может оказаться очень удобной для сравнения характеристик домов шорт-листа, без масштабирования она возвращает набор оценок, на которые сильно влияет небольшое количество атрибутов с численным значением больше остальных. Цена недвижимости — это, как правило, большое число в сравнении, например, с количеством спален. Без масштабирования цена недвижимости будет доминировать в оценке сверх отведённого ей веса.
 Графики оценки свойств до и после масштабирования числовых столбцов
Графики оценки свойств до и после масштабирования числовых столбцов
Баллы, рассчитанные без масштабирования, сильно коррелируют с переменной цены. Цена важна для большинства покупателей, но она не может быть единственным критерием.
Чтобы исправить это и вычислить новый набор баллов, все числовые столбцы были масштабированы к единому диапазону 0–1 с помощью функции MinMaxScaler из библиотеки scikit-learn. На рисунке выше гистограмма и диаграмма рассеяния в правой части показывают результаты масштабирования: оценки выглядят нормально распределёнными, а разброс между ценой недвижимости и оценками показывает лишь слабую корреляцию.
Ранжирование
После оценки объектов их отсортировали в порядке убывания и присвоили им ранг, составив уточнённый короткий список домов, которые можно посетить.
Интересно, что 50 лучших домов распределены по всему Портленду без какой-либо сильной пространственной кластеризации. С другой стороны, цены на недвижимость проявляются кластерами.
У большинства домов из 50 лучших имеются:
Две ванные комнаты, четыре спальни (хотя критерием отбора было минимум две спальни).
Площадь менее 2500 квадратных футов (232 квадратных метра).
Они построены в последние 4 года.
Удачно расположены в смысле инфраструктуры.
Находятся в пределах 10 миль от центрального офиса Esri: доехать можно за 25 минут.
Функция масштабирования обеспечила, чтобы не было ни одной характеристики, которая бы доминировала в оценке объекта сверх отведённого ей веса. Тем не менее могут быть некоторые характеристики, которые, как правило, коррелируют с оценками.
Функция pairplot () из библиотеки seaborn используется для получения диаграммы рассеяния каждой переменной относительно друг друга, как показано ниже. Диагонали матриц представляют гистограммы соответствующей переменной.
Диаграмма рассеяния ранга и пространственные характеристики
На диаграмме рассеяния наблюдаются случайность и расслоение в ранге переменной, кроме (что вполне понятно) commute_duration и commute_length.
На второй диаграмме, которая показывает ранг и различные внутренние характеристики недвижимости, разброс между рангом и ценой недвижимости довольно случайный, то есть можно купить дом с рангом выше других по цене ниже средней. Разброс между рангом и площадью показывает интересную форму «U», означающую, что с увеличением размера недвижимости ранг повышается, но после определённого момента ухудшается.
Построение движка рекомендаций
Сейчас набор данных обработан с помощью внутренних и пространственных атрибутов. Весовые коэффициенты для различных характеристик чётко определены, чтобы оценивать и ранжировать недвижимость. Решения покупателей хотя и логичны, но не настолько просчитаны и более туманны.
Покупатели, скорее всего, не будут обращать внимание на некоторые недостатки, если их впечатлит другая характеристика. Если покупатели просто предпочитают одни дома и заносят другие в чёрный список, для вывода предпочтений можно воспользоваться моделью ML.
Собрать такие тренировочные данные для большого количества объектов трудно, поэтому был создан макетный набор данных с использованием 50 лучших домов как избранных, оставшийся 281 дом — как чёрный список. Эти данные переданы в модель ML логистической регрессии.
Обучаясь, модель пытается присвоить веса внутренним и пространственным характеристикам и предсказать, будет ли этот дом предпочтительным для покупателя. Когда на рынке появляется новый объект недвижимости, эта модель может предсказать, понравится ли он покупателю, и представить только соответствующие задаче результаты.
>>> classification_report(y_test, test_predictions,
target_names=['blacklist','favorite'])
precision recall f1-score
blacklist 0.94 0.98 0.96
favorite 0.88 0.71 0.79
average 0.93 0.93 0.92 Выше показана точность этой модели на упомянутом выше наборе данных. Точность — это способность модели определить, хорошо ли подходит дом покупателю. Под воспроизводимостью понимается способность определить все лучшие дома в тестовом наборе. Мера f1 вычисляет среднее гармоническое значение precision и recall для получения комбинированной оценки точности модели.
Тренировочный набор мал по сегодняшним стандартам и не сбалансирован: в них 50 лучших и 281 худший дом. Модель демонстрирует значительные результаты с высокими показателями f1 в смысле исключения домов, вероятно, попадающих в чёрный список.
Присвоенные моделью веса показаны в правой части рисунка ниже. На основе обучающих данных модель узнала относительную важность каждого признака. По сравнению с присвоенными вручную весами в левой части рисунка ниже модель логистической регрессии лишь незначительно снижает рейтинг дома из-за цены недвижимости, длины и продолжительности маршрута до работы. Площадь, количество продуктовых магазинов, парков и учебных заведений оцениваются отрицательно, а остальные — положительно. Такие характеристики, как количество больниц, кофеен, баров и автозаправочных станций, получили вес больше, чем при ручном присвоении весов.
 Сравнение присвоенных вручную весов и весов модели
Сравнение присвоенных вручную весов и весов модели
Заключение
Тип построенного в исследовании рекомендательного механизма называется фильтрацией на основе содержания: он использует только внутренние и разработанные для прогнозирования пространственные характеристики. Для такого типа рекомендаций необходим обучающий набор слишком велик, чтобы генерировать его вручную.
На практике используется другой тип рекомендательной системы — фильтрация на основе сообщества. Он использует разработанные для недвижимости характеристики в сочетании с данными о белых и чёрных списках, чтобы найти сходство между большим количеством покупателей. Затем, чтобы создать большой набор данных, он объединяет обучающие наборы похожих покупателей.
В данном исследовании исходный набор обогащён информацией о доступе к различным объектам. При помощи модуля geoenrichment из API ArcGIS для Python его можно расширить инженерными социально-экономическими характеристиками, такими как возраст дома, доход, уровень образования и множество других параметров.
Также возможно включить данные от местных органов власти в рамках инициативы открытых данных. Здесь для дальнейшего обогащения набора можно воспользоваться полезными пространственными слоями с сайта открытых данных города Портленда.
Хотя покупка дома индивидуальна, многие решения значительно зависят от местоположения. Pandas или другие библиотеки можно использовать для визуализации и статистического анализа, а библиотеки, такие как ArcGIS API for Python, — для пространственного анализа. Вы можете применить методы из статьи к другому рынку недвижимости и создать собственную систему рекомендаций.
Эта статья показывает, что машинное обучение и наука о данных могут применяться везде, где есть информация самых разных видов и необходимость делать прогнозы и выводы, а значит, профессии в Data Science и Machine Learning будут актуальны многие годы.
Ссылка на блокноты Jupyter на Github.
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:
