Altera + OpenCL: программируем под FPGA без знания VHDL/Verilog

Всем привет!
Altera SDK for OpenCL — это набор библиотек и приложений, который позволяет компилировать код, написанный на OpenCL, в прошивку для ПЛИС фирмы Altera. Это даёт возможность программисту использовать FPGA как ускоритель высокопроизводительных вычислений без знания HDL-языков, а писать на том, что он привык, когда это делает под GPU.
Я поигрался с этим инструментом на простом примере и хочу об этом вам рассказать.
План:
Добро пожаловать под кат! Осторожно, будут картинки!
Пару слов об FPGA (ПЛИС)
FPGA (Field-Programmable Gate Array) — это программируемая пользователем вентильная матрица, является разновидностью ПЛИС.
В основе таких чипов лежат небольшие блоки логических элементов. На таких примитивах можно построить логику любого чипа — от 8-битного микроконтроллера до майнера биткоинов.
Так же есть неплохая книга FPGAs for Dummies, где очень простым языком объясняется что такое FPGA, и как эти чипы используются.
«Классическая» разработка под FPGA выглядит так:
программа схема описывается на HDL языках типа VHDL/Verilog и скармливается компилятору, который переводит описание в уровень примитивов, а так же находит оптимальное расположение этих блоков в чипе с учетом заданных временных ограничений (констрейнов). Тактовая частота схема — пример такого констрейна.
Иногда ПЛИС воспринимается как более дорогая разновидность микроконтроллеров: там и там можно моргать светодиодом, огранизовывать UART, SPI, I2C. Раньше отчасти это было справедливо из-за того, что ПЛИС были маленькие (по ресурсам и частотам), и о какой-то серьезной обработке данных и конкуренции с процессорам нельзя было говорить. Сейчас чипы FPGA становится всё жирнее, а по производительности их сравнивают с GPU.
FPGA даёт возможность управлять обработкой на самом низком уровне: создавать кэши нужного размера в нужном месте, организовывать конвейеризацию, описывать явный параллелизм. Можно подключать различную периферию (например, видеокамеры или Ethernet-порты) и производить вычисления без процессора общего назначения.
Все прелести FPGA нивелируются тем, что если есть управление низким уровнем, то этот низкий уровень и надо программировать! Низкий уровень абстракции всегда приводит к усложнению разработки и отладки, увеличению сроков.
Производители FPGA весьма разумно задумались о том, что нужно сокращать time-to-market: позволить программистам очень легко и быстро писать под FPGA. Одним из стандартных вариантов описания программы для параллельных вычислений является OpenCL. Altera решила поддержать OpenCL: был разработан Altera SDK for OpenCL.
Я намеренно опускаю описание OpenCL: в русскоязычном интернете есть много литературы на эту тему, например, Введение в OpenCL.
На чём запускать?

Запустить OpenCL можно не каждой плате с FPGA: Altera создала специальную партнерскую программу, в рамках которой девкиты получают вышеуказанную лычку, если плата готова для запуска OpenCL, проходит постоянные регрессионные тесты и пр.
PCIe
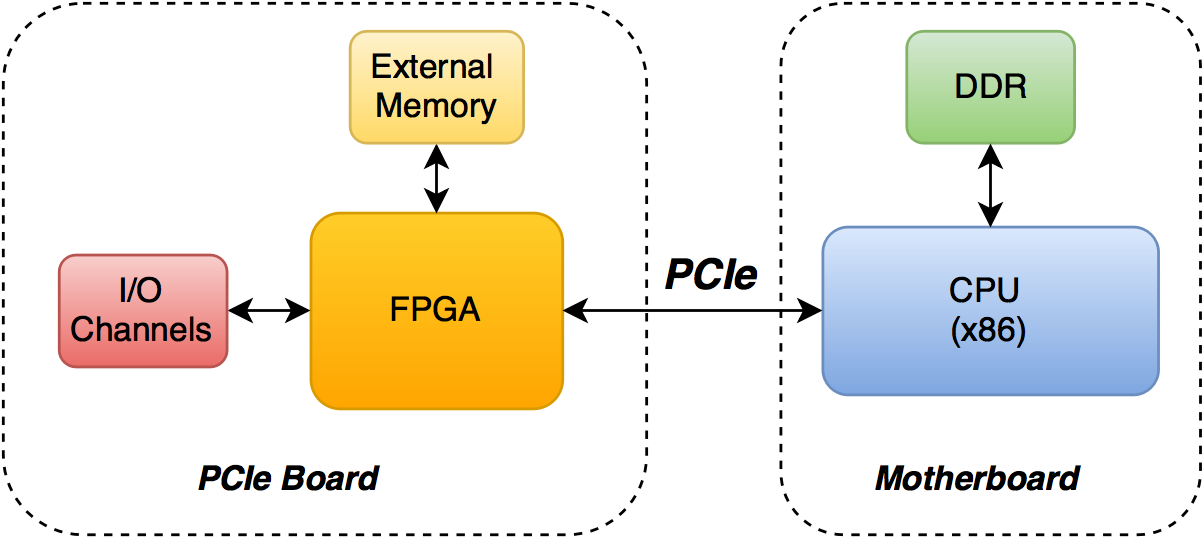
Чип с ПЛИС может быть размещен на PCIe карточке, которая втыкается в материнскую плату в соответствующий разъем (хоть вместо GPU). Через DMA и PCIe FPGA может общаться с DDR памятью, которая подключена к процессору (забирать данные для расчетов). Так же на плате может быть размещена внешняя память, которая доступна только для FPGA (ОС на CPU доступа к этой памяти иметь не будет).
Внешняя память может понадобиться для хранения промежуточных расчетов: доступ к ней будет дешевле, чем доступ через DMA в хостовую память. Она не обязательно должна быть DDR: для некоторых вычислений low-latency SRAM может подойти лучше.
Данные для обработки могут подаваться в ядро не только с глобальной памяти, но еще и с I/O каналов, например с Ethernet-портов. В этом случае хост только настраивает кернелы, а данные обрабатываются с минимальной задержкой. (Если вы видите рядом слова Ethernet, FPGA и low-latency, то в большинстве случаев подразумевается high-frequency trading).
SoC
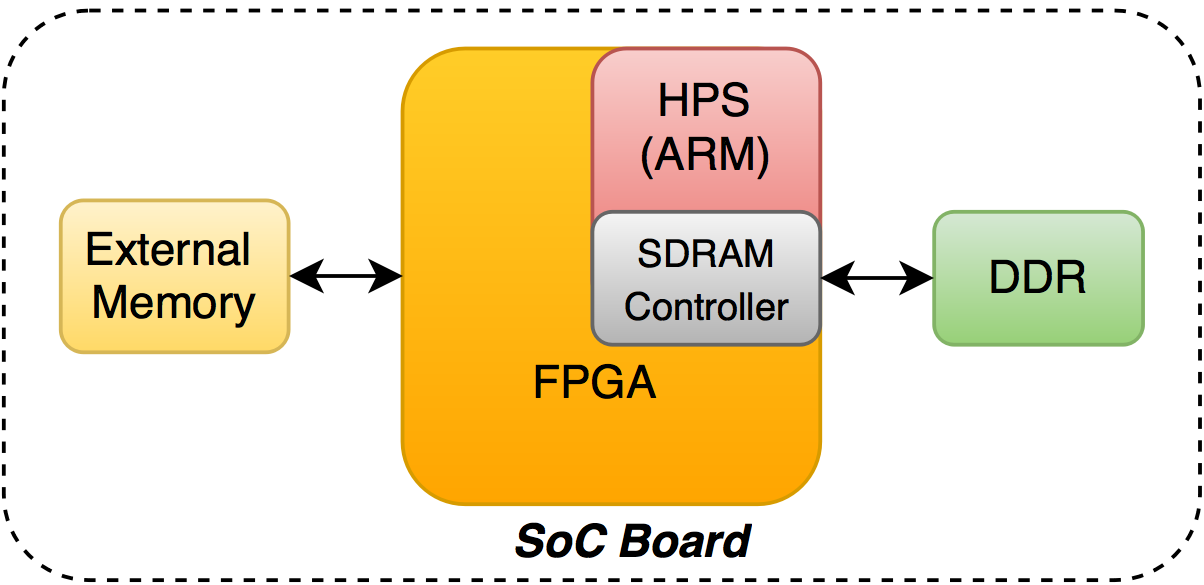
Второй вариант возможен на SoC'ax, где в одном кристале расположена программируемая логика и ARM-процессор.
DDR-память, закрашеная зеленым, является разделяемым ресурсом: с одной стороны им пользуется CPU (там можно запустить linux), а с другой, FPGA может «напрямую» читать/писать в эту память через SDRAM-контроллер с минимальным оверхедом. Как и с PCIe карточкой к FPGA может быть подключена внешняя память, но необходимость в этом меньше, т.к. всегда под рукой DDR.
Подробнее о платформах можно прочитать тут.
Существует возможность запуска OpenCL на тех платах, которые не имеют знака Altera Preferred Board for OpenCL. Я рассказывать об этом не буду, в качестве отправной точки предлагаю глянуть официальное руководство Altera SDK for OpenCL: Custom Platform Toolkit User Guide.
Процесс разработки (workflow)
Какие шаги надо выполнить для запуска ядра?
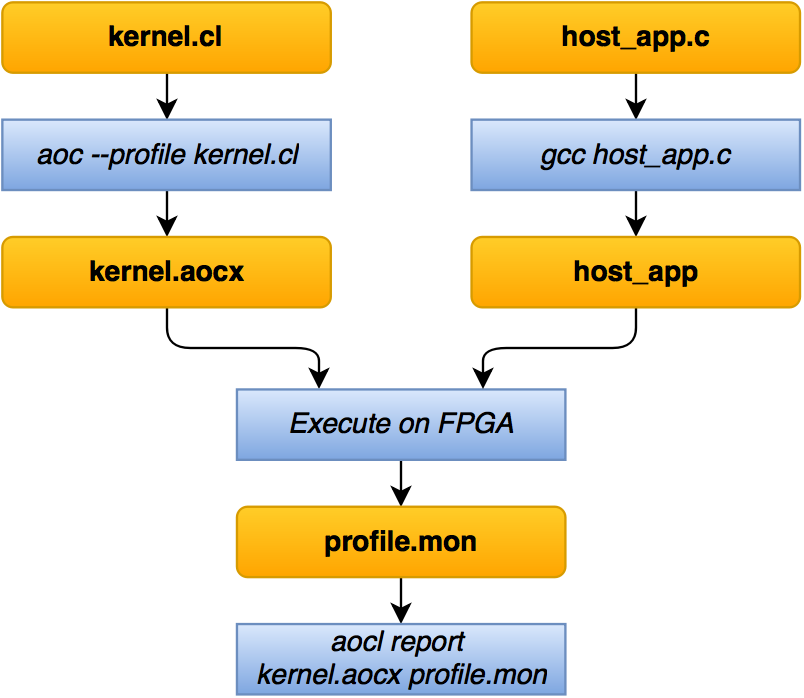
- Код кернела описывается в файле *.cl.
- Готовится хостовое приложение на С/C++, которое будет производить выделение необходимых объемов памяти и «загрузку» значений в кернел.
- С помощью утилиты aoc, которая входит в Altera OpenCL SDK, «компилируется» ядро в aocx файл. С помощью gcc собирается хостовое приложение.
- При запуске host_app произойдет загрузка прошивки FPGA, в ядро загрузятся подготовленные данные и начнется их обработка.
- Счетчики для профилирования собирают данные, которые поместятся в файл profile.mon.
- С помощью утилиты aocl можно посмотреть этот отчет и сделать вывод: удовлетворяет ли по времени выполнения/производительности эта реализация.
- Если удовлетворяет, то можно перекомпилировать ядро без --profile, т.к. профилирующие счетчики отнимают ресурсы в FPGA. С другой стороны, если дополнительных ядер не планируется добавлять, то можно и не пересобирать.
- Если не удовлетворяет, то надо оптимизировать/писать ручками/взять другой чип или смириться.
Замечу, что компиляция в aocx файл может достигать нескольких часов!
Что же происходит, когда вызывается aoc kernel.cl?
Сборка aocx
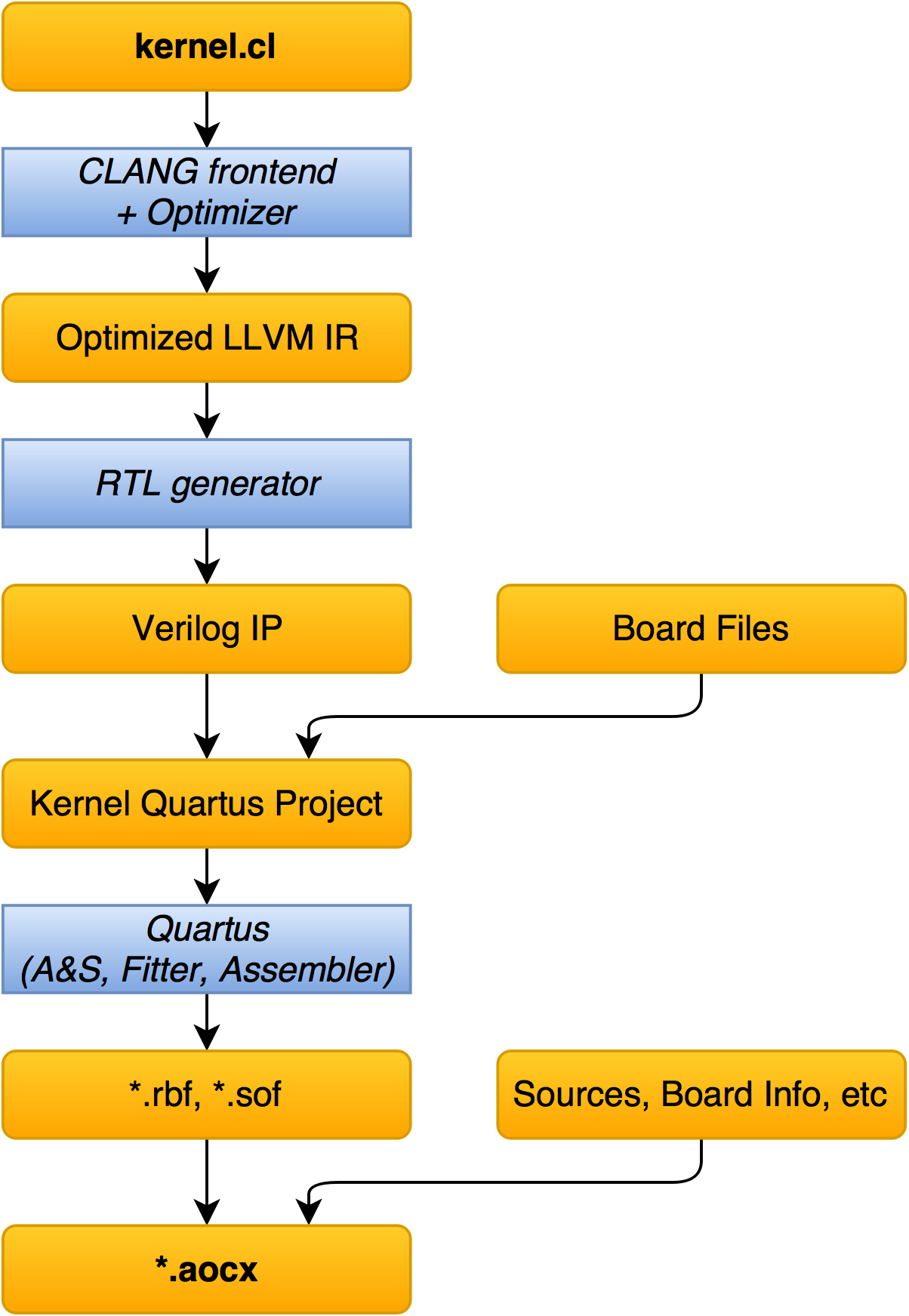
- kernel.cl скармливается clang, который переводит описание в IR, а так же проводит различные оптимизации.
- Генерируется RTL-ное Verilog IP-ядро. Сгенеренные файлы доступны для чтения (незашифрованы) и могут быть просимулировать в обычном симуляторе (например, ModelSim). Однако, там не весь код автосгенеренный: есть модули, которые явно писал человек.
- Полученное IP «присоединяется» к дефолтому проекту для платы и получается обычный проект для Quartus'a.
- Проходит сборка проекта (Analysis & Synthesis, Fitter, Assembler). Именно этот пункт занимает наибольшее время (от десяти минут до нескольких часов): поиск оптимальных мест расположения примитивов требует много вычислений.
- Результат сборки, информация о борде и прочее размещают в aocx, который является просто ELF-файлом.
Этот aocx-файл затем и используется для «загрузки» ядра.
DE1-SoC OpenCL BSP
На словах и картинках всё выглядит очень складно: знания Verilog'а не нужны.
Что же на самом деле?
В моих руках снова появилась плата DE1-SoC от Terasic’a. В её основе лежит камень Cyclone V SoC (5CSEMA5F31C6).

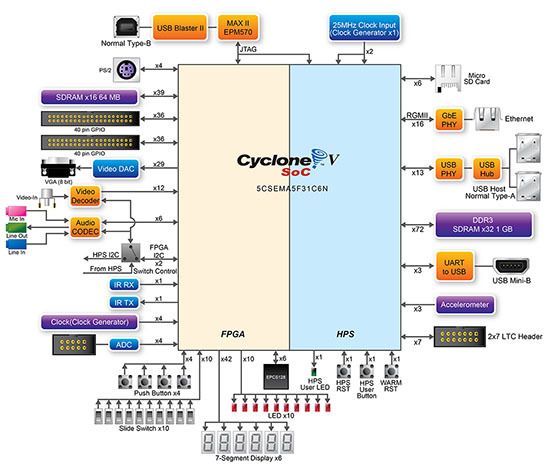
Эта плата имеет знак Altera Preferred Board for OpenCL, поэтому запуск OpenCL должен быть из коробки: нам нужен OpenCL BSP для конкретно этой платы. Его можно взять тут.
В архив с OpenCL BSP входит:
- Образ флешки (с неё загрузится linux).
- Дефолтный проект, где уже настроены все пины, а так же интерфейсы (fpga2sdram, lwhps2fpga и др.).
- Простенькие примеры.
Образ записывается на MicroSD просто через dd.
Примечание: желательно использовать флешки 10 класса.
Там уже лежит linux:
root@socfpga:~# uname -a
Linux socfpga 3.13.0-00298-g3c7cbb9-dirty #3 SMP Fri Jul 4 15:42:32 CST 2014 armv7l GNU/Linux
root@socfpga:~# cat /etc/issue
Poky 8.0 (Yocto Project 1.3 Reference Distro) 1.3 \n \l
root@socfpga:~# cat /proc/cpuinfo
processor : 0
model name : ARMv7 Processor rev 0 (v7l)
Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3 tls vfpd32
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x3
CPU part : 0xc09
CPU revision : 0
processor : 1
model name : ARMv7 Processor rev 0 (v7l)
Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3 tls vfpd32
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x3
CPU part : 0xc09
CPU revision : 0
Hardware : Altera SOCFPGA
Revision : 0000
Serial : 0000000000000000
Там же можно найти скомпилированные примеры и OpenCL Run-Time Environment.
Заботливая README предлагает:
Run "source ./init_opencl.sh" to setup OpenCL Run-Time Environment, including loading driver, on this board.
Do it once right after booting the board.
OpenCL Run-Time Environment is pre-installed in opencl_arm32_rte folder.
Сам init_opencl.sh выглядит очень тривиально:
root@socfpga:~# cat init_opencl.sh
export ALTERAOCLSDKROOT=/home/root/opencl_arm32_rte
export AOCL_BOARD_PACKAGE_ROOT=$ALTERAOCLSDKROOT/board/c5soc
export PATH=$ALTERAOCLSDKROOT/bin:$PATH
export LD_LIBRARY_PATH=$ALTERAOCLSDKROOT/host/arm32/lib:$LD_LIBRARY_PATH
insmod $AOCL_BOARD_PACKAGE_ROOT/driver/aclsoc_drv.ko
Выполняем этот скрипт, идем в директорию helloworld и запускаем одноименное приложение:
root@socfpga:~/helloworld# ./helloworld
Querying platform for info:
==========================
CL_PLATFORM_NAME = Altera SDK for OpenCL
CL_PLATFORM_VENDOR = Altera Corporation
CL_PLATFORM_VERSION = OpenCL 1.0 Altera SDK for OpenCL, Version 14.0
Querying device for info:
========================
CL_DEVICE_NAME = de1soc_sharedonly : Cyclone V SoC Development Kit
CL_DEVICE_VENDOR = Altera Corporation
CL_DEVICE_VENDOR_ID = 4466
CL_DEVICE_VERSION = OpenCL 1.0 Altera SDK for OpenCL, Version 14.0
CL_DRIVER_VERSION = 14.0
CL_DEVICE_ADDRESS_BITS = 64
CL_DEVICE_AVAILABLE = true
CL_DEVICE_ENDIAN_LITTLE = true
CL_DEVICE_GLOBAL_MEM_CACHE_SIZE = 32768
CL_DEVICE_GLOBAL_MEM_CACHELINE_SIZE = 0
CL_DEVICE_GLOBAL_MEM_SIZE = 536870912
CL_DEVICE_IMAGE_SUPPORT = false
CL_DEVICE_LOCAL_MEM_SIZE = 16384
CL_DEVICE_MAX_CLOCK_FREQUENCY = 1000
CL_DEVICE_MAX_COMPUTE_UNITS = 1
CL_DEVICE_MAX_CONSTANT_ARGS = 8
CL_DEVICE_MAX_CONSTANT_BUFFER_SIZE = 134217728
CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS = 3
CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS = 8192
CL_DEVICE_MIN_DATA_TYPE_ALIGN_SIZE = 1024
CL_DEVICE_PREFERRED_VECTOR_WIDTH_CHAR = 4
CL_DEVICE_PREFERRED_VECTOR_WIDTH_SHORT = 2
CL_DEVICE_PREFERRED_VECTOR_WIDTH_INT = 1
CL_DEVICE_PREFERRED_VECTOR_WIDTH_LONG = 1
CL_DEVICE_PREFERRED_VECTOR_WIDTH_FLOAT = 1
CL_DEVICE_PREFERRED_VECTOR_WIDTH_DOUBLE = 0
Command queue out of order? = false
Command queue profiling enabled? = true
Using AOCX: hello_world.aocx
Kernel initialization is complete.
Launching the kernel...
Thread #2: Hello from Altera's OpenCL Compiler!
Kernel execution is complete.
Окей, какие-то специально подготовленные примеры и файлы на флешке работают и что-то печатают.
Что надо сделать для сборки и запуска простого примера?
Установка SDK
Нам нужно:
Установка всех этих тулзов дело тривиальное, но есть тонкие моменты:
- Могут потребоваться рутовые права, причем об этом вам скажут только в конце установки.
- После установки необходимо кое-чего прописывать в PATH, ALTERAOCLSDKROOT, QUARTUS_ROOTDIR. Что туда прописывать можно подчерпнуть из соответствующих гайдов.
Возможно я что-то сделал не так, но в итоге мой скрипт для настройки переменных окружений стал выглядеть вот так:
export PATH=/home/ish/altera/14.1/quartus/bin:$PATH
export PATH=/home/ish/altera/14.1/hld/bin:$PATH
export PATH=/usr/local/DS-5/bin:$PATH
export PATH=/usr/local/DS-5/sw/gcc/bin:$PATH
export PATH=/home/ish/altera/14.1/hld/linux64/bin/:$PATH
export ALTERAOCLSDKROOT=/home/ish/altera/14.1/hld/
export QUARTUS_ROOTDIR=/home/ish/altera/14.1/quartus/
export LD_LIBRARY_PATH=/home/ish/altera/14.1/hld/linux64/lib/:$LD_LIBRARY_PATH
# необходимость в этой строчке появится чуть позже, но я указал эту переменную вместе с остальными
export AOCL_BOARD_PACKAGE_ROOT=/home/ish/altera/14.1/hld/board/de1soc
Да, у меня стоит не самая последняя Quartus'a, и поэтому, возможно, то, что я покажу чуть ниже было улучшено в пятнадцатой версии.
Если там что-то координально поменялось в плане OpenCL, буду признателен, если стукните мне в личку.
После того, как всё это поставили и озаботились лицензиями, то необходимо установить нашу борду.
Как это сделать подсказывает README.txt, который лежит в архиве c BSP:
note:before the below operations,make sure you have install the opencl SDK 14.0 and SoCEDS 14.0.
1. directly unzip the de1soc_openCL_bsp.zip into %ALTERAOCLSDKROOT%/board directory.
2. set the "User variables" AOCL_BOARD_PACKAGE_ROOT to %ALTERAOCLSDKROOT%/board/de1soc
3. open the windows command window and type "aoc --list-boards", it should output "de1soc_sharedonly"
Выполняем и проверяем:
ish@xmr:~$ aoc --list-boards
Board list:
de1soc_sharedonly
Плата в списке появилась — значит всё сделали верно.
Собираем пример
Для запуска я выбрал очень простой пример:
Z = X + Y,
где X и Y — массивы из N uint (32-битных) чисел.
Кернел vector_add выглядит очень просто:
// ACL kernel for adding two input vectors
__kernel void vector_add( __global const uint *restrict x,
__global const uint *restrict y,
__global uint *restrict z )
{
// get index of the work item
int index = get_global_id(0);
// add the vector elements
z[index] = x[index] + y[index];
}
Полностью код для хоста приводить не буду: его можно глянуть вот тут.
Что он делает:
- пытается распознать, какие есть OpenCL девайсы
- перепрограммирует FPGA, используя aocx-файл
- инициализирует буфера для массивов X, Y, Z
- генерирует данные в массивах X и Y, а так же вычисляет (на процессоре) референсный ответ
- передает указатели на массивы в кернел
- запускает обработку
- дожидается её окончания
- сравнивает референсный ответ с тем, что посчитал кернел
Сборка его тривиальна: запускаем очень простой Makefile, который использует ARM-овский кросс компилятор. (Хостом же в нашем случае будет являться ARM, который находится в SoC'e).
Получаем aocx:
ish@xmr:~/tmp/cl/vector_add$ aoc device/vector_add.cl -o bin/vector_add.aocx --board de1soc_sharedonly --profile -v
aoc: Environment checks are completed successfully.
You are now compiling the full flow!!
aoc: Selected target board de1soc_sharedonly
aoc: Running OpenCL parser....
aoc: OpenCL parser completed successfully.
aoc: Compiling....
aoc: Linking with IP library ...
aoc: First stage compilation completed successfully.
aoc: Hardware generation completed successfully.
Напомню, что флаг --profile добавляет в прошивку счетчики для профилирования, а -v просто для verbose.
Это займет минут десять-пятнадцать.
В директории bin появился vector_add.aocx, а в bin_vector_add квартусовский проект, который и собирался всё это время.
Отчёт о сборке:
+-------------------------------------------------------------------------------+
; Fitter Summary ;
+---------------------------------+---------------------------------------------+
; Fitter Status ; Successful - Sat Oct 17 21:36:01 2015 ;
; Quartus II 64-Bit Version ; 14.1.0 Build 186 12/03/2014 SJ Full Version ;
; Revision Name ; top ;
; Top-level Entity Name ; top ;
; Family ; Cyclone V ;
; Device ; 5CSEMA5F31C6 ;
; Timing Models ; Final ;
; Logic utilization (in ALMs) ; 5,570 / 32,070 ( 17 % ) ;
; Total registers ; 9685 ;
; Total pins ; 103 / 457 ( 23 % ) ;
; Total virtual pins ; 0 ;
; Total block memory bits ; 127,344 / 4,065,280 ( 3 % ) ;
; Total DSP Blocks ; 0 / 87 ( 0 % ) ;
; Total HSSI RX PCSs ; 0 ;
; Total HSSI PMA RX Deserializers ; 0 ;
; Total HSSI TX PCSs ; 0 ;
; Total HSSI PMA TX Serializers ; 0 ;
; Total PLLs ; 2 / 6 ( 33 % ) ;
; Total DLLs ; 1 / 4 ( 25 % ) ;
+---------------------------------+---------------------------------------------+
Больше всего здесь интересует две строчки: Logic utilization и Total block memory bits.
Этот простой пример занял 5570 ALM. На самом деле операция сложения занимает меньше 1% от этого числа: всё остальное заняла «инфраструктура», которая читает и записывает данные из DDR (а так же профилирующие счетчики). Еще важно отметить, что проект в Квартусе собирался с дефолтными настройками, которые не включали никакую оптимизации по ресурсам/частоте.
Так же интересно, что автоматически «где-то» появилась память с сумарным объемом на ~128 Кбит.
Кстати, можно глянуть, какие появились секции в vector_add.aocx:
ish@xmr:~/tmp/cl/vector_add$ readelf -a bin/vector_add.aocx
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: NONE (None)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 2370388 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 40 (bytes)
Number of section headers: 20
Section header string table index: 1
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .shstrtab STRTAB 00000000 000080 00011c 00 S 0 0 128
[ 2] PROGBITS 00000000 000200 001000 00 0 0 128
[ 3] .acl.board PROGBITS 00000000 001200 000011 00 0 0 128
[ 4] .acl.compileoptio PROGBITS 00000000 001280 000002 00 0 0 128
[ 5] .acl.version PROGBITS 00000000 001300 00000a 00 0 0 128
[ 6] .acl.file.0 PROGBITS 00000000 001380 000030 00 0 0 128
[ 7] .acl.source.0 PROGBITS 00000000 001400 0006c2 00 0 0 128
[ 8] .acl.nfiles PROGBITS 00000000 001b00 000001 00 0 0 128
[ 9] .acl.source PROGBITS 00000000 001b80 0006c2 00 0 0 128
[10] .acl.opt.rpt.xml PROGBITS 00000000 002280 000019 00 0 0 128
[11] .acl.mav.json PROGBITS 00000000 002300 00107f 00 0 0 128
[12] .acl.area.json PROGBITS 00000000 003380 0009da 00 0 0 128
[13] .acl.profiler.xml PROGBITS 00000000 003d80 002f08 00 0 0 128
[14] .acl.profile_base PROGBITS 00000000 006d00 0009c8 00 0 0 128
[15] .acl.autodiscover PROGBITS 00000000 007700 000071 00 0 0 128
[16] .acl.autodiscover PROGBITS 00000000 007780 00021e 00 0 0 128
[17] .acl.board_spec.x PROGBITS 00000000 007a00 0003eb 00 0 0 128
[18] .acl.fpga.bin PROGBITS 00000000 007e00 23ab98 00 0 0 128
[19] .acl.quartus_repo PROGBITS 00000000 242a00 000151 00 0 0 128
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), l (large)
I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
There are no section groups in this file.
There are no program headers in this file.
There are no relocations in this file.
There are no unwind sections in this file.
No version information found in this file.
Запускаем кернел
Копируем через scp vector_add и vector_add.aoсx на плату и запускаем:
root@socfpga:~/myvectoradduint# ls -l
-rwxr-xr-x 1 root root 42525 Apr 16 06:57 vector_add
-rw-r--r-- 1 root root 2371188 Apr 16 06:58 vector_add.aocx
root@socfpga:~/myvectoradduint# ./vector_add
Initializing OpenCL
Platform: Altera SDK for OpenCL
Using 1 device(s)
de1soc_sharedonly : Cyclone V SoC Development Kit
Using AOCX: vector_add.aocx
Launching for device 0 (1000000 elements)
Time: 112.475 ms
Kernel time (device 0): 7.270 ms
Verification: PASS
Нам удалось сложить 1 миллион пар 32-битных чисел за 7.270 ms или одну пару за 7.27 ns. На самом деле этот показатель прямо сейчас не так интересен: пример не был оптимизирован по производительности. (Спойлер: использовался только один сумматор: распараллеливания вычислений не было).
После выполнения в директории появился profile.mon:
root@socfpga:~/myvectoradduint# ls -l
-rw-r--r-- 1 root root 170 Apr 16 06:58 profile.mon
-rwxr-xr-x 1 root root 42525 Apr 16 06:57 vector_add
-rw-r--r-- 1 root root 2371188 Apr 16 06:58 vector_add.aocx
Копируем его обратно к себе на компьютер и смотрим результат профилирования:
ish@xmr:~/tmp/cl/vector_add$ aocl report bin/vector_add.aocx profile.mon
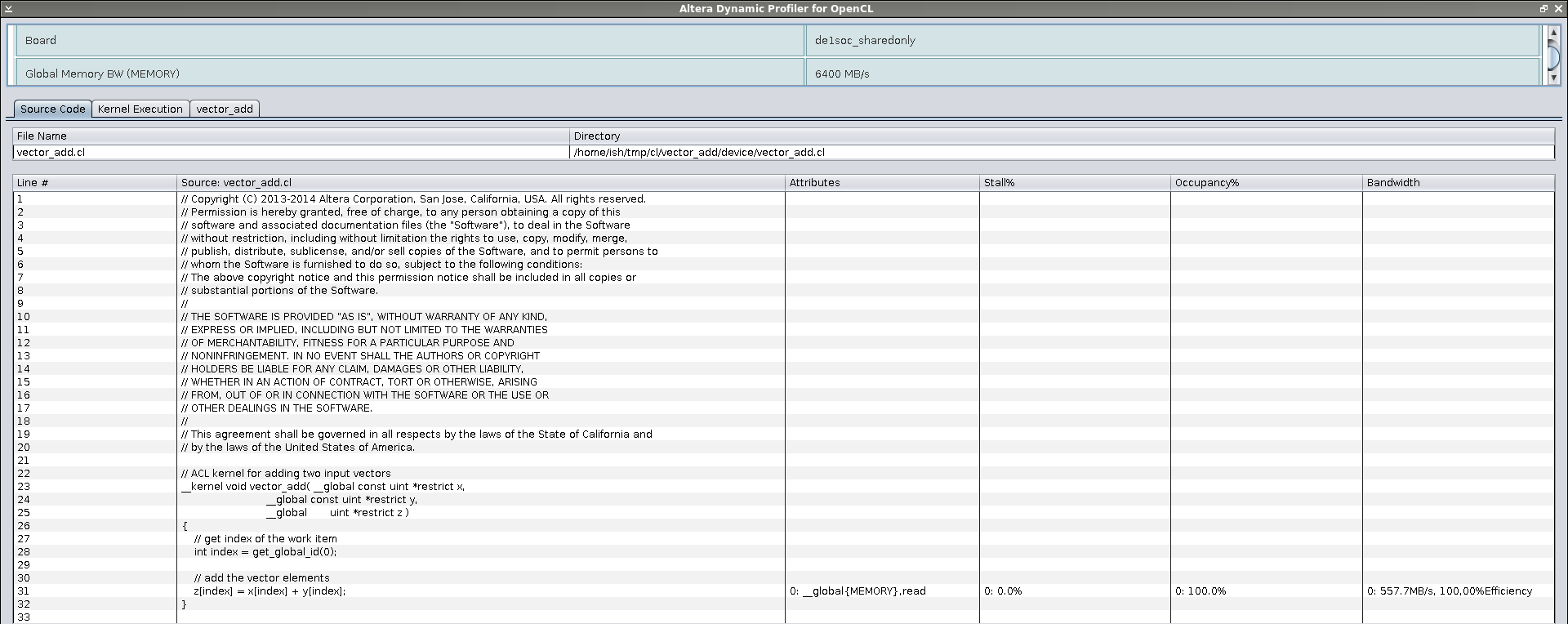


Профилировщик показал, что мы использовали только треть пропускной способности до глобальной памяти.
Есть возможность запуска визуализатора:
ish@xmr:~/tmp/cl/vector_add$ aocl vis bin/vector_add.aocx
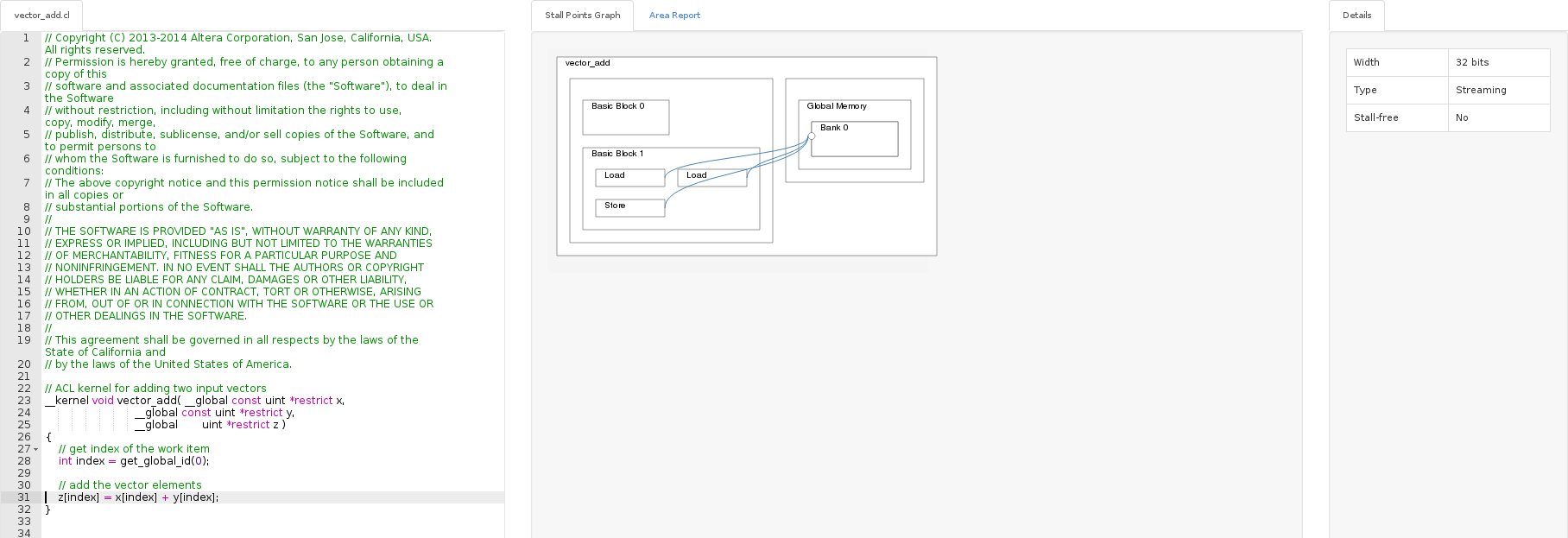
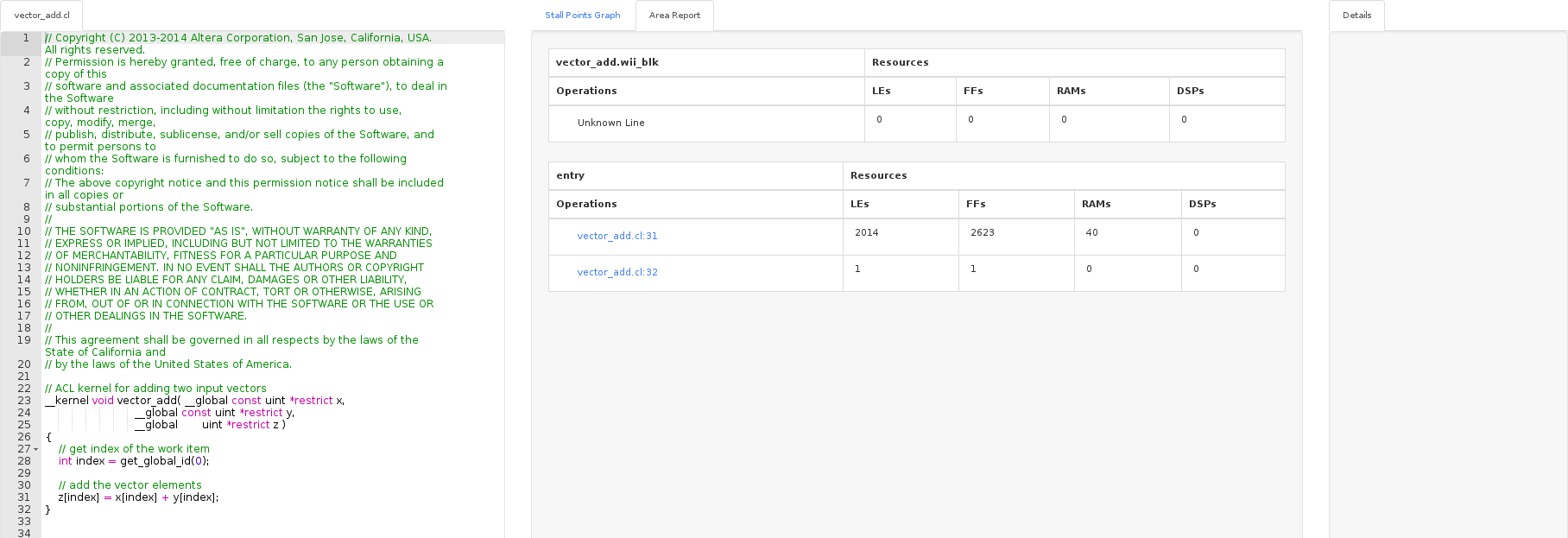
Визуализатор показал, что есть три блока, которые общаются с глобальной памятью: два на чтение, один на запись. Доступ к глобальной памяти в данном случае может оказаться узким звеном. В Area report для каждой строчки можно увидеть количество ресурсов, которое тратится в FPGA на реализацию. Конечно, пример из одной строчки не показателен.
На youtube-канале Альтеры есть видео, где подробно показываются все шаги, о которых я говорил выше:
Остальные видеозаписи из этого цикла можно найти под спойлером:
Заключение
В этой статье я попробовал инструмент, который позволяет писать под FPGA на высоком уровне без знания HDL-языков. Как видим, он работает (на простом примере), и нам правда ничего не пришлось дополнительно делать.
OpenCL под FPGA не будет золотым молотком:
- Не позволяет описывать процессы с точностью до такта (но ведь от этого мы и хотели уйти!)
- Неприменим на маленьких чипах: инфраструктура отъедает огромное количество ресурсов.
Однако с помощью него FPGA может составить очень реальную конкуренцию GPU в таких областях как видеообработка (машинное зрение), шифрование, ЦОС, симулирование (моделирование) различных процессов. Если говорить про те области, где я работаю (генерация, фильтрация, коммутация Ethernet-пакетов), где выжимание максимальной производительности как раз происходит благодаря управлению самым низким уровнем, то понимания, как использовать OpenCL (и получать аналогичный результат) у меня нет.
Если есть потребность в максимальной производительности, то надо очень хорошо понимать во что получается та или иная конструкция языка. Поэтому, мне кажется, тем, кто захочет что-то более менее серьезное писать на OpenCL под FPGA придется на базовом уровне изучить Quartus, Qsys и Verilog (на уровне чтения). Возможно, визуализатора и профилировщика будет хватать, но пока они выглядят как студенченские подделки, надеюсь, в новых релизах квартуса это исправят.
Если говорить о реалтаймовой обработке видео, то рекомендую глянуть вот эту демку:
Ребята из iABRA изначально делали машинное зрение на OpenCL под AMD GPU, но затем переехали на Altera. Программист подчеркивает, что использование OpenCL позволило «не разбираться в VHDL, т.к. у них в этом опыта нет, а писать на том, что они умеют».
В некоторых докладах, где сравниваются реализации алгоритмов (шифрование, видеообработка) на GPU и OpenCL FPGA утверждается, что количество выполненных операций в секунду у них примерно одинаковое, но FPGA потребляет в 10 раз меньше электроэнергии. Я всегда к таким бенчмаркам отношусь немного скептически, потому что сам их не пробовал)
С выходом новых семейств Arria 10 и Stratix 10 я допускаю, что всё больше параллельных вычислений перейдет на использование FPGA: мы эти чипы увидим в суперкомпьютерах и в датацентрах.
И еще одно видео о реальном использовании Altera SDK for OpenCL:
Спасибо за внимание! Буду рад вопросам и замечаниям в комментариях или в личке)
Полезные ссылки:
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
