Алгоритм расчёта расстояния между строками
По работе стояла задача оптимизации поиска по адресам (улицы, дома и объекты). Главный критерий — нахождение адреса, если написано с ошибками или не дописан он в полной мере. Bert«ы, косинусные расстояния эмбеддингов и т.д. не подходили, так как они заточены под смысловой поиск, а в адресах смысла нет. TF-IDF c лемматизацией тоже не очень подходил для этой задачи, результаты были плохие.
Для реализации начал использовать расстояние Дамерау-Левенштейна, и в последствие, развил это до собственного алгоритма, который находит расстояние между двумя строками.
Цель данного поста описание только алгоритма.
Описание алгоритма
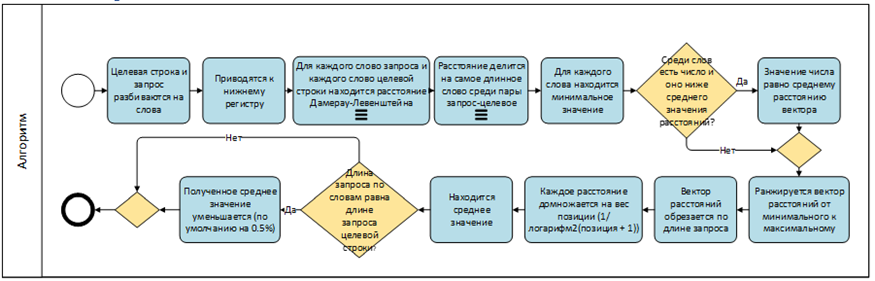
Процесс работы алгоритма
Формула
Tew — это получаемое расстояние между двумя строками.

Если рассмотреть по этапам:

Реализация кодом на R
Функция реализации алгоритма.
library(stringr)
library(data.table)
library(magrittr)
library(stringdist)
Присоединяю пакет: 'stringdist'
Следующий объект скрыт от 'package:magrittr':
extract
stringDistination <- function(src_query, trg_query){
clearSplit <- function(x){
x %>%
strsplit(split = " ") %>%
unlist() %>%
tolower() %>%
.[. %ilike% "\\w+"] %>%
str_squish()
}
# Splitting queries
src = clearSplit(src_query)
trg = clearSplit(trg_query)
# By every word find closeness
x <- list()
y <- c()
for (i in seq(length(src))) {
for (l in seq(length(trg))) {
y[trg[l]] <- stringdist(a = trg[l], b = src[i], weight = c(0.8, 1, 1, 1)) / max(nchar(src[i]), nchar(trg[l]), na.rm = TRUE) # finding similarity word by word
}
x[[src[i]]] <- y
}
# min value by each word
vec <- x %>%
unlist() %>%
{
str <- names(.) %>% tstrsplit(split = "\\.")
c(
setNames(
object = .,
nm = str[[1]]
),
setNames(
object = .,
nm = str[[2]]
)
)
} %>%
sort %>%
.[unique(names(.))]
# finding digitals
num_names <- which(str_detect(string = names(vec), pattern = "\\d+"))
# if number, number have to be low impactable
if(length(num_names) > 0){
mean_val <- mean(vec, na.rm = TRUE)
vec[num_names] <- fifelse(vec[num_names] > mean_val, vec[num_names], mean_val)
}
vec %>%
.[seq(length(src))] %>%
{
. * (1/log(order(.)+1)) # calculate distance value depending on its position
} %>%
mean() %>% # take mean value
{
if(length(src) == length(trg)){ . * (1 - 0.005)} else {.} # if lengths of src and trg are equal, in this case the obtained average value is reduced by 0.5%
}
}Пример работы функции
queries <- c("Эски сары", "Нарты")
target_vector <- c("Эски сары кёл", "Хасаутская", "Нартов", "Новый Карачай", "Мара-Аягъы", "Кавказская")
data.table(query = rep(queries, each = length(target_vector)),
target = rep(target_vector, length(queries))) %>%
.[, similarity := stringDistination(src_query = query, trg_query = target) %>% round(3), by = 1:nrow(.)] %>%
.[, .SD[order(similarity)], by = query] %>%
.[, position := 1:.N, by = query]
query target similarity position
1 Эски сары Эски сары кёл 0.000 1
2 Эски сары Нартов 0.784 2
3 Эски сары Мара-Аягъы 0.824 3
4 Эски сары Новый Карачай 0.836 4
5 Эски сары Хасаутская 0.941 5
6 Эски сары Кавказская 0.941 6
7 Нарты Нартов 0.478 1
8 Нарты Эски сары кёл 0.519 2
9 Нарты Мара-Аягъы 1.005 3
10 Нарты Новый Карачай 1.030 4
11 Нарты Хасаутская 1.148 5
12 Нарты Кавказская 1.292 6
Вывод
По сравнению с существующими поисковыми движками (а сравнивал с meilisearch) есть свои преимущества:
Алгоритм показывает достойный результат в задачах нечёткого поиска. Например, основная проблема поисковых движков в том, что второе слово и последующие очень слабо влияют на выдачу, а первое крайне сильно, так что если местами поменять слова при вводе, то и результат изменится. Разработанный поисковик таких проблем не имеет.
Не нужно отдельное место для сервера, оркестрирование контейнеров и т.д. А также индексацию проводить. Работает всё сразу.
Недостатки:
Он медленее существующих поисковых движков (0,4 секунды против 0,09). Поэтому для быстрого поиска он не используется. Может можно его как-то ускорить, однако я пока не смог придумать.
Поисковый движок отлично подойдёт, если сравниваются строки по словам, нужно локально реализовать и вопрос скорости не стоит слишком остро (качество выдачи приоритетнее).
