Albumentations: Feedback

Warning: Текст сухой, так как написан больше для публичного логирования и интересен скорее тем, кто библиотеку уже использует.
Я являюсь одним из разработчиков open source библиотеки Albumentations.
Библиотека предназначена для аугментации изображений, и обычно применяется в задачах компьютерного зрения.
Для тренировки нейронных сетей требуется много размеченных данных. И тут есть два варианта:
собрать да разметить. Дорого, долго, но гарантированно улучшить качество модели.
вариант для бедных — аугментации. Какая от них ценность заранее не известно, зато бесплатно и уже сейчас.
На практике комбинируют оба подхода.
Над библиотекой мы работаем уже 4 года. В том году я написал развернутый текст на Хабре про то, как библиотека родилась и развивалась. [ Рождение Albumentations ]
На текущий момент мы имеем:

Как видно по карте библиотекой пользуются по всему миру, и больше всего пользователей (по убыванию): США, Южная Корея, Индия, Китай, Япония, Россия.
Есть разные причины почему библиотека взлетела. Это и функционал, и грамотное продвижение, но в первую очередь скорость.
В идеале надо, чтобы скорость тренировки упиралась в GPU, как следствие требуется чтобы CPU не был блокером. А он им моментально становится если аугментационный pipeline медленный.
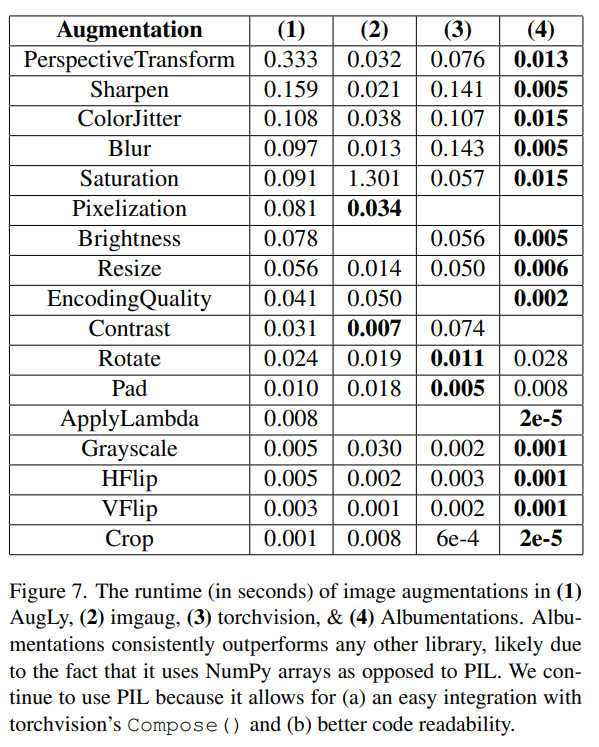 От авторов библиотеки Augly, разрабатываемую в Facebook
От авторов библиотеки Augly, разрабатываемую в Facebook
Развитие проекта шло как типичный Open Source. Core Team в разных странах. Когда кому-то что-то требовалось добавить — он добавляет, без планирования, sync«ов и OKR«ов.
Не прошло и пяти лет, я решил спросить как вообще библиотека используется и чего не хватает. Спросил на LinkedIn, на Twitter и в сообещстве ODS, как кто библиотеку использует на работе (то есть помогает зарабатывать деньги :)). Ребята откликнулись — я позадовал вопросы.
Вот что получилось:
Q: В каких доменах используется библиотека?
Медицина (от распознавания родинок на коже, до диагностики рака)
Распознование документов
Спутниковые снимки
Автономные машины
Робототехника
Детекция дефектов на производстве
Распознование лиц и AntiSpoofing
Редактирование и улучшение фото
Мониторинг траффика
Beauty сфера
Retail
Тестрирование моделей перед деплоем на устойчивость к дрифту данных
Обработка видео со спортивных мероприятий
Мемогенерация.
То есть там где есть картинки или видео — там библиотека используется, что логично и приятно.
Q: Какие типы задач?
Classification
Detection
Segmentation
Action Recognition
Pose estimation
Super Resolution
Image inpainting
Изначально библиотека разрабатывалась под классификацию и сегментацию. Остальной функционал мы добавили позже и, видимо, не зря.
Q: Чего не хватает в библиотеке?
Примеры приобразование картинками в документацию.
Инструкции о том, как добавить новое преобразование. Сейчас все сводится к — найди похожее преобразование, адаптируй к своему случаю. Практически все с кем я общался делали кастомные преобразовани, то есть разобраться, в прнципе, можно. С другой стороны всем приходилось разбираться в кодовой базе вместо того, чтобы следовать несложному туториалу.
Работы на GPU. Для каких-то задач не хватает скорости Albumentations. Кто-то пробовал использовать DALI для задач классификации и возрадовался. Получается у DALI хорошо, но там наркоманский интерфейс + только задачи классификации. Есть Библитека Kornia, которая как раз аушментирует на GPU. Применяя ее к батчам получается хорошо, но если покартиночно, то получается не быстрее Albumentations.
Не хватает поддержки 1D и 3D. 3D — это может быть полноценное 3D как в задачах медицины, либо работа с видео. Уже есть какие-то решения на рынке, но по удобству использования и функционалу не дотягивают до Albumentations. Для 3D есть Monai и Volumentations от Романа Соловьева, но там есть куда стремиться. Еще есть мысль, что 3D более ресурсоемко и там точно надо лезть в GPU.
Экспорта аугментационного пайплайна на Pytorch, в другие языки программирования как C++ или другие платформы.
Q: Каких преобразований не хватает в библиотеке?
Добавление текста на лету — это может как на медицинских изображениях, а может быть кирилица, как в TextRecognitionGenerator.
AugMix, CutMix, MixUp
CutAndPaste — это когда есть картинка объект«а и его надо поместить на разные фоновые картинки, но так, чтобы граница между объктом и фоном была замазана через Inpainting или Poisson Blending.
Аугментация пририсовать маску или очки на лицо. Тут, как я понимаю, заранее находятся facial keypoints и маска или очки на них натягиваются.
Больше преобразований с компрессией. Для задач где картинки в плохом качестве или со старых телефонов -, а это большая часть существующих задач, хорошо заходят преобразований ImageCompression. Сейчас у нас есть поддержка Jpeg и WebP, был запрос на добавление heic и jpeg2000
Mosaic transform — это когда из несокльких картинок собирается одна. Используется в YOLO v4
Аугментация только в выбранном регионе картнки:
В преобазованиях вида Pixel DropOut — не обнулять, а переводить выбранные области в Grayscale.
Аугментации только внутри bounding boxes.
Аугментации только там где ненулевая маска. Скажем, вам нужно, чтобы вас были каритнки где у людей куртки разного цвета ⇒ можно заранее отсегментировать куртки, а потом применять цветовые преобразования только в областям где маска не ноль.
Q: Какие примеры нестандартных преобразований хорошо заходят?
Там где не хватает людей с другим оттенком кожи — темнокожие, молодые или старые, добрасывает FDA.
В распознавании документов FDA, RandomSunFlare и RandomFog
Q: Как вообще выбираются аугментации?
Тут у всех по разному, не очень структурированно примерно так же, как всю дорогу делал я.
Подрезаются из соревнований с Kaggle.
Из предыдущих похожих задач. Часто есть стадартный набор преобразований вида: Heavy, Medium, Light, который кочует из задачи в задачу.
Так чтобы не портили исходное расределение. Условный HorizonalFlip на естественных картинках или D4 на спутниковых.
Для подбора преобразований и параметров кто-то использует тулзу на Heroku (Руки не доходили обнавить ее несколько лет, там нет многих новых преобразований.), а кто-то эксперементирует в Jupyter Notebook.
В целом, такое ощущение, что вопрос не раскрыт и тут, прям хочется чтобы появилась тулза, которая берет датасет, тип задачи и возвращает хороший аугментационный пайплайн.
Но есть проблемы:
Никто толком не знает как это делать. Да, есть популярное направление исследований AutoAugment, которое является подмножеством еще более популярного AutoML, но там все не очень хорошо.
Аугментации зависят не только от датасета и задачи, но и от модели. Чем тяжелее модель — тем более плотные преобразования к ней можно применять.
Аугментации докидывают к точности и обобщающей способности модели, причем чем меньше тренировочный датасет, тем больше добрасывают. Но сколько добросят и добросят ли вообще заранее неизвестно, что не добавляет людям пытаться инвестировать силы и время в разработку продукта на основе AutoAugment.
Подытоживая, есть куда работать и развивать. Тут и документация и новый функционал.
Так что если кому-то хочется поучаствовать в разработке Open Source — добро пожаловать. Море простых задач на которых можно попробовать что-то сделать в первый раз :)
Вообще хочется, чтобы кто-то работал над проектом full time, но для этого, видимо, надо будет настраивать систему пожертвований и кого-то нанимать. Пока не соображу как это все настроить, но такое ощущение, что при текущей популярности библиотеки это реально.
P.S. English version
