Активное обучение ранжированию
Этим постом я открываю серию, где мы с коллегами расскажем, как используется ML у нас в Поиске Mail.ru. Сегодня я объясню, как устроено ранжирование и как мы используем информацию о взаимодействии пользователей с нашей поисковой системой, чтобы сделать поисковик лучше.
Задача ранжирования
Что подразумевается под задачей ранжирования? Представим, что в обучающей выборке есть какое-то множество запросов, для которых известен порядок документов по релевантности. Например, вы знаете, какой документ самый релевантный, какой второй по релевантности и т.д. И вам нужно восстановить такой порядок для всей генеральной совокупности. То есть для всех запросов из генеральной совокупности на первое место поставить самый релевантный документ, а на последнее — самый нерелевантный.
Давайте посмотрим, как такие задачи решаются в больших поисковых системах.
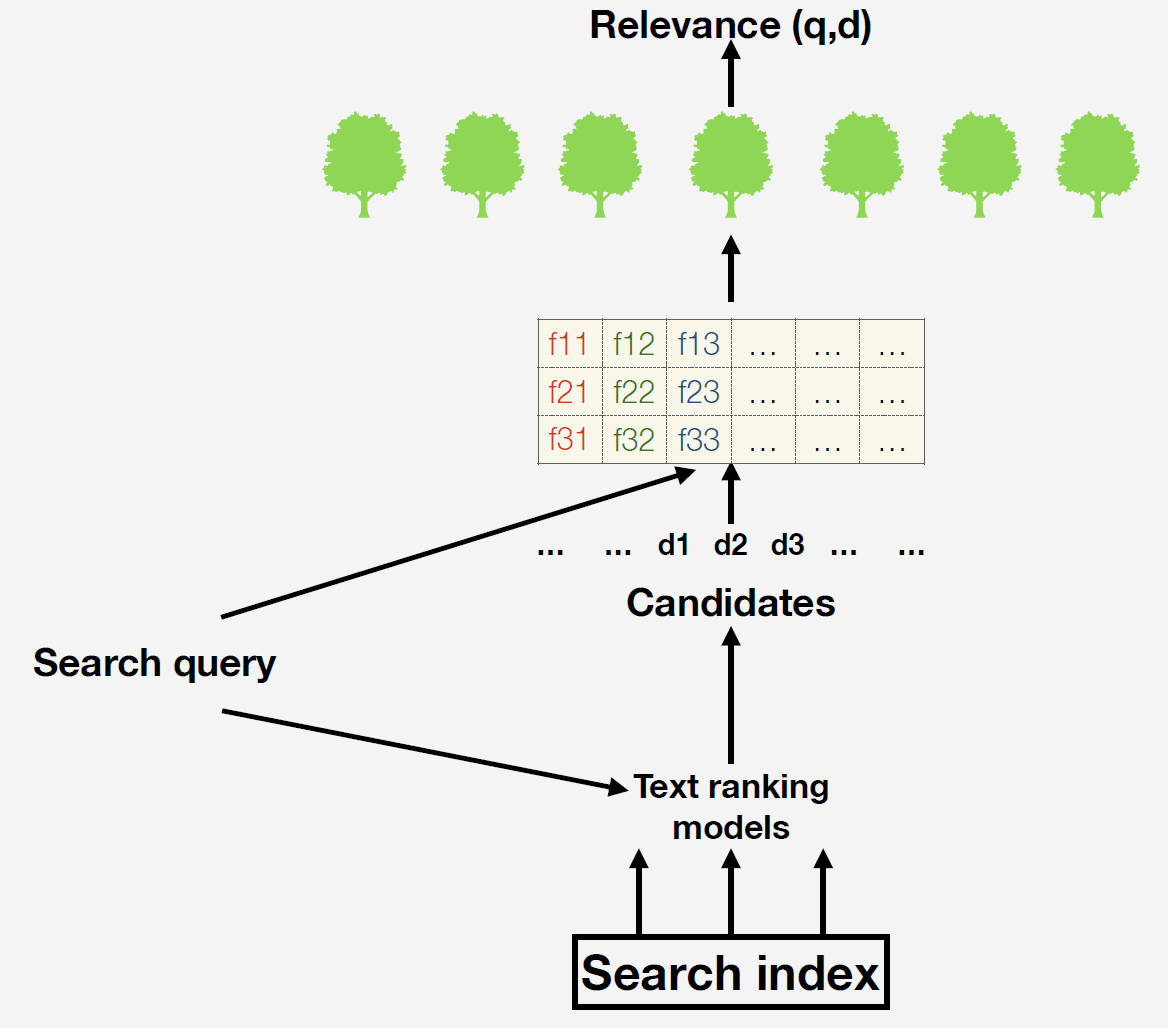
У нас есть поисковый индекс — это база из многих миллиардов документов. Когда приходит запрос, мы сначала простыми текстовыми моделями генерируем список кандидатов для финального ранжирования. Самый простой вариант — поднять те документы, в которых в принципе есть слова из запроса. Зачем нужен этот этап? Дело в том, что невозможно для всех имеющихся документов построить признаки и сформировать прогнозирование финальной модели. После мы уже вычисляем признаки. Какие признаки мы можем взять? Например, количество вхождений в документ слов из запроса или число кликов на данный документ. Можно использовать сложные машинно-обученные факторы: мы в Поиске с помощью нейросетей прогнозируем релевантность документа по запросу и вставляем этот прогноз новым столбцом в наше пространство признаков.
Для чего мы всё это делаем? Мы хотим максимизировать пользовательские метрики, чтобы пользователи как можно проще находили релевантные результаты в нашей выдаче и как можно чаще возвращались к нам.
В нашей финальной модели используется ансамбль деревьев решений, построенный с помощью градиентного бустинга. Есть два варианта построения целевой метрики для обучения:
- Делаем отдел асессоров — специально обученных людей, которым мы даем запросы и говорим: «Ребята, оцените, насколько наша выдача релевантна». Они в ответ будут выдавать числа, оценивающие релевантность. Чем плох такой подход? В данном случае мы будем максимизировать модель относительно мнения людей, которые не являются нашими пользователями. Мы будем оптимизироваться не под ту метрику, которую на самом деле хотим оптимизировать.
- По этой причине мы используем второй подход для целевой переменной: мы показываем пользователям выдачу, смотрим, на какие документы они переходят, какие пропускают. А потом используем эти данные для обучения финальной модели.
Как решается задача ранжирования?
Есть три подхода к решению задачи ранжирования:
- Pointwise, он же поточечный. Мы будем рассматривать релевантность как абсолютное мерило и будем штрафовать модель за абсолютную разность между предсказанной релевантностью и той, которую мы знаем по обучающей выборке. Например, асессор поставил документу оценку 3, а мы бы сказали 2, поэтому штрафуем модель на 1.
- Pairwise, попарный. Мы будем сравнивать документы друг с другом. Например, в обучающей выборке есть два документа, и нам известно, какой из них более релевантный по данному запроса. Тогда мы будем штрафовать модель, если она более релевантному поставила прогноз ниже, чем менее релевантному, то есть неправильно сранжировала пару.
- Listwise. Он тоже основан на относительных релевантностях, но уже не внутри пар: мы ранжируем моделью всю выдачу и оцениваем результат — если на первом месте оказался не самый релевантный документ, то получаем большой штраф.
Какой из подходов лучше использовать для выбранной нами целевой переменной? Для этого стоит обсудить важный вопрос: «можно ли использовать клики как мерило абсолютной релевантности документа?». Нельзя, потому что они зависят от позиции документа в выдаче. Получив выдачу, вы, скорее всего, кликните на документ, который будет выше, потому что вам кажется, что первые документы более релевантные.
Как можно такую гипотезу проверить? Берем два документа в топе выдачи и меняем их местами. Если бы клики были абсолютным мерилом релевантности, то их количество зависело бы только от самого документа, а не от позиции. Но это не так. Тот документ, который выше, всегда получает больше кликов. Поэтому клики ни в коем случае нельзя использовать как мерило абсолютной релевантности. Поэтому можно использовать либо pairwise, либо listwise.
Собираем датасет
Теперь извлекаем данные для обучающей выборки. У нас была вот такая сессия:

Из четырёх документов был клик по второму и четвёртому. Как правило, люди смотрят выдачу сверху вниз. Вы посмотрели на первый документ, вам он не понравился, кликнули на второй. Потом вернулись в поиск, посмотрели третий и кликнули на четвертый. Очевидно, что второй вам понравился больше, чем первый, а четвертый больше, чем первый и третий. Вот такие пары мы генерируем для всех запросов и используем для обучения модели.
Вроде бы всё хорошо, но есть одна проблема: люди кликают только на документы из самого верха выдачи. Поэтому, если вы будете делать обучающую выборку только таким образом, то распределение в ней будет совершенно такое же, как в тестовой выборке. Нужно как-то выровнять распределение. Мы делаем это с помощью добавления негативных примеров: это документы, которые были на дне ранжирования, пользователь их точно не видел, но мы знаем, что они плохие.

Итак, у нас получилась такая схема обучения ранжированию: показали пользователям выдачу, собрали с них клики, добавили негативные примеры, чтобы выровнять распределение, и переобучили модель ранжирования. Таким образом, мы учитываем реакцию пользователей на ваше текущее ранжирование, учитываем ошибки и улучшаем ранжирование. Эти процедуры повторяем много раз до сходимости. Важно отметить, что мы ищем не только по вебу, но и по видео, по картинкам, и описанная схема отлично работает в любом виде поиска. В результате очень сильно вырастают поведенческие метрики. Во второй итерации чуть поменьше, в третьей итерации еще меньше, и в итоге сходится к локальному оптимуму.
Давайте подумаем, почему же мы сходимся в локальный оптимум, а не в глобальный.
Допустим, вы футбольный фанат и вечером не успели посмотреть матч своей любимой команды. Утром просыпаетесь и вводите в поисковую строку название команды, чтобы узнать результат матча. Смотрите первые три документа — это официальные страницы о клубе, тут нет полезной информации. Вы не будете листать всю выдачу, не будете подбирать другой запрос. Возможно, вы даже кликните на какой-нибудь нерелеватный документ. Но в результате расстроитесь, закроете выдачу и откроете другой поисковик.

Хотя эта проблема встречается не только в поиске, здесь она особенно актуальна. Представьте интернет-магазин, который представляет собой одну большую ленту без возможности сказать, какую именно категорию товаров вы хотите посмотреть. Именно это происходит с поисковой выдачей: после отправки запроса вы уже никак не можете пояснить, что вам на самом деле нужно: информацию о футбольной команде или счёт последнего матча.
Представим, что какой-нибудь брутальный мужчина зашёл в такой странный интернет магазин, состоящий из одной ленты рекомендаций, и в своих рекомендациях он видит только типично женские товары. Возможно, он даже кликнет на какое-нибудь платье, потому что оно надето на красивую девушку. Мы этот клик отправим в обучающее множество и решим, что мужчине это платье нравится больше, чем спонж. Когда он снова приходит в нашу систему, он уже увидет одни платья. У нас изначально не было товаров, валидных для пользователя, поэтому такой подход не позволит нам эту ошибку исправить. Мы попали в локальный оптимум, в котором бедный человек уже не может нам рассказать, что ему не нравятся ни спонжи, ни платья. Часто эту проблему называют проблемой положительной обратной связи.
Дальнейшее совершенствование
Как сделать поисковую систему лучше? Как выбраться из локального оптимума? Нужно добавлять новые факторы. Допустим, мы сделали очень хороший фактор, который поднимет по запросу с названием футбольной команды релевантный документ, то есть результаты последнего матча. В чем здесь может быть проблема? Если вы обучаете модель на старых данных, на офлайн-данных, то берете старый датасет с кликами и добавляете туда этот признак. Возможно, он релевантный, но вы раньше не использовали его в ранжировании, и поэтому люди не кликали на те документы, по которым этот признак хорош. Он не коррелирует с вашей целевой переменной, поэтому просто не будет использоваться моделью.
В подобных случаях мы часто используем такое решение: в обход финальной модели заставляем наше ранжирование использовать этот признак. Мы насильно показываем по запросу с названием команды результат последнего матча, и если пользователь кликнул на него, то для нас это та информация, которая позволяет понять, что признак хороший.
Давайте разберем это на примере. Недавно мы сделали красивые картинки для документов с Instagram:

Кажется, что такие красивые картинки должны максимально удовлетворять наших пользователей. Очевидно, нам нужно сделать признак наличия у документа такой картинки. Добавляем в датасет, переобучаем модель ранжирования и смотрим, как этот признак используется. А потом анализируем изменение поведенческих метрик. Они немного улучшились, но оптимальное ли это решение?
Нет, потому что по многим запросам вы не показываете красивые картинки. Вы не давали пользователю возможность показать, как они ему нравятся. Чтобы решить эту проблему, мы по некоторым запросам, которые предполагают показ Instagram-документов, принудительно в обход модели показывали красивые картинки и смотрели, кликают ли на них. Как только пользователи оценили нововведение, то стали переобучать модель на датасетах, в которых у пользователей была возможность показать важность этого фактора. После этой процедуры на новом датасете фактор стал использоваться во много раз чаще и значительно повысил пользовательские метрики.
Итак, мы рассмотрели постановку задачи ранжирования и обсудили подводные камни, которые вас будут поджидать при обучении на обратной связи от пользователей. Главное, что вам стоит вынести из этой статьи: используя обратную связь в качестве таргета для обучения, помните, что этот фидбек пользователь сможет оставить только там, где ему это позволит текущая модель. Такая обратная связь может сыграть с вами злую шутку при попытке построить новую модель машинного обучения.
