AdBlock: особенности работы и продвинутые методы блокировки

Привет, Хабр! Часто по работе сталкиваюсь с вопросами вроде: как же работают блокировщики рекламы?
Хочу поделиться с вами некоторыми интересными, но порой сомнительными решениями, которые можно встретить в работе расширений, и обсудить в комментариях работу блокировщиков.
В своей статье расскажу о самых интересных и необычных решениях по блокировке рекламы с помощью JavaScript«a и не только. Также посмотрим на новые направления разработки блокировщиков и куда все движется.
Статья будет полезна прежде всего веб-разработчикам, так как пользователи с блокировщиками могут столкнуться с проблемами на их проектах. А также тем, кто в данный момент ими пользуется, для более глубокого понимания работы.
Рынок блокировщиков
На данный момент самыми популярными решениями являются различные браузерные расширения, однако ими все не заканчивается. На картинке указаны основные, хотя, например, в Chrome Web Store можно найти еще сотню других.


В некоторых мобильных браузерах есть специальные опции для включения блокировки (например, Opera), некоторые изначально работают как браузеры — со встроенным блокировщиком рекламы и отслеживания (AdBlock Browser, Brave).
В некоторых мобильных браузерах есть специальные опции для включения блокировки (например, Opera), некоторые изначально работают как браузеры — со встроенным блокировщиком рекламы и отслеживания (AdBlock Browser, Brave).
Отдельным списком можно выделить следующие инструменты:
VPN сервера с функцией блокировки рекламы;
DNS сервера с блокировкой рекламы
мобильные операторы с услугами блокировки рекламы.
Браузерные расширения
 Общая схема работы расширений
Общая схема работы расширенийМногие представляют, как работают браузерные расширения, у блокировщиков тот же принцип. Подробнее почитать про устройство расширений под Chrome.
Основными действующими лицами в AdBlock* расширениях являются background.js скрипты, которые позволяют фильтровать различные ресурсы, загружаемые по сети с помощью специального API для расширений, и content-script.js, которые позволяют работать с DOM-деревом страницы: скрывать элементы и не только.
Стоит упомянуть, что каждый из скриптов работает в отдельном фрейме, который общается с другими за счет API chrome.runtime.sendMessage и chrome.runtime.onMessage.addListener.
Перейдем к общей схеме работы расширения на примере AdBlock Plus.

Почти все блокировщики основаны на списках фильтрации, это такие файлы https://easylist-downloads.adblockplus.org/ruadlist+easylist.txt, которые содержат список правил для фильтрации контента на определенных сайтах. Также в них есть общая часть, которая относится к фильтрации на всех ресурсах, так что вы ненароком тоже можете случайно попасть под фильтрацию одного из общих фильтров (которые работают на всех сайтах).
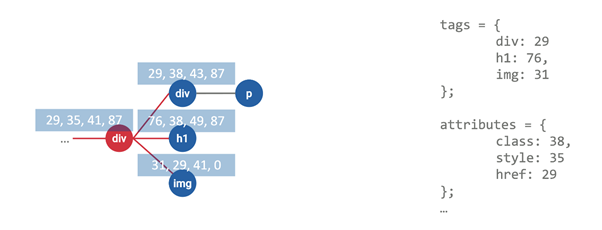
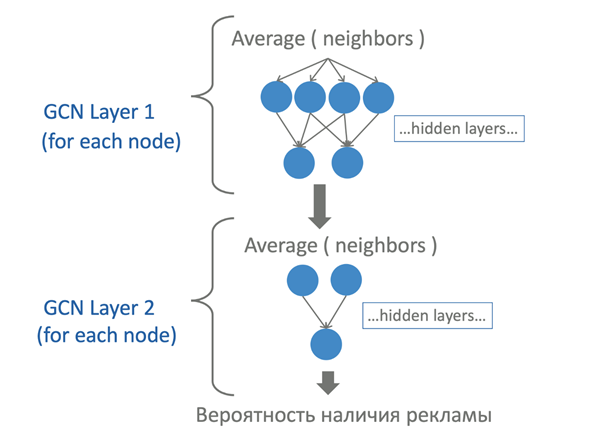
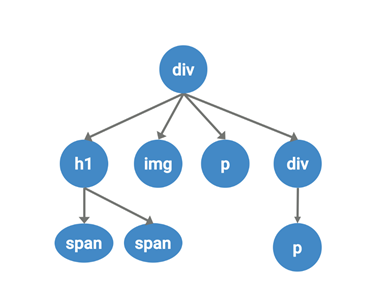
Например, вы создали на своем сайте какой-то На основе этих файлов и происходит вся фильтрация контента сайта. Изменениями в этих списках занимаются конкретные форумы и модераторы (например: RuAdList https://forums.lanik.us/viewforum.php? f=102), некоторые можно найти и на github«e https://github.com/abp-filters/abp-filters-anti-cv. Браузерные расширения сами обновляют эти списки путем простого скачивания, в начале файла указано, как часто нужно обновлять фильтр, например у RuAdList указано: Для общего понимания стоит разобрать, как выглядят типичные фильтры. Слева указывается блокируемый адрес, а справа, после разделителя, идут особые параметры: какие запросы блокировать и на каком домене это нужно делать. Подробнее можно почитать здесь. С помощью подобных фильтров можно заблокировать почти любой, загружаемый на странице ресурс. Среди которых могут быть: изображения стили скрипты объекты шрифты HTTP-запросы и другие. Сниппеты (в некоторых блокировщиках называются скриплеты) — это функция JavaScript, которая содержится в исходном коде расширения и исполняется в Для примера возьмем snippet В данном случае, если мы успели переписать стандартное значение метода Давайте рассмотрим на примере: На живом примере мы видим, что блокировщик успешно справился с задачей блокировки закрытого Shadow DOM на основании его внутреннего контента. Следующий пример — это сниппет В данном сниппете используется аналогичная идея, которая заключается в переписывании стандартных свойств. Функция В данном примере рассмотрено создание типичного класса, который прогнали, например, через Babel. Таким образом, если блокировщик переписал глобально Возможно, некоторые уже сталкивались с языком запросов X-Path, но немногие знают, что его можно применять в вебе (зачастую он используется парсерами страниц). Тут отличный справочник, если кого-то заинтересовало. В браузере также существует особое API для исполнения следующих выражений, что позволяет блокировщикам избирательнее выбирать элементы для блокировки. Еще одно интересное направление работы — это работа с изображениями, так как во многих рекламных объявлениях можно встретить одинаковые картинки с логотипом рекламной сети, по этим картинкам зачастую можно найти расположение всего объявления и целиком заблокировать. Начнем с начала — есть такая библиотека blockhash.js, которая реализует хеширование изображений по их значению на основе алгоритма из исследования «Block Mean Value Based Image Perceptual Hashing» by Bian Yang, Fan Gu and Xiamu Niu. Алгоритм примерно следующий: Нормализуем размер картинки под общий пресет; Разделяем картинку на I1, I2… In не перекрывающихся блоков, где N — кол-во блоков, равных длине финальной hash bit строки; Зашифровываем I1, … In блоки с помощью секретного ключа K в новую последовательность блоков; Для каждого этого блока вычисляем его среднее M1….Mn, а затем вычисляем общее среднее Md = median (Mi), где I = 1…N; Создаем 64-битный хэш на основании того, находится значение выше или ниже среднего (подробнее). Давайте рассмотрим на примере этих двух изображений: Если мы сравним 2 хэша, получившиеся из двух изображений, то увидим, что дистанция Хэмминга между этими хэшами равна 3, что означает схожесть изображений. На этом примере мы можем видеть, что блокировщик проходится по всем картинкам и ищет среди них похожие на рекламу, что позволит найти похожую даже если по url об этом догадаться нельзя. Для начала напомню, что DNS позволяет нам, кроме всего прочего, по имени хоста получить IP адрес. DNS фильтрация работает в том случае, если вы укажете в качестве DNS адресов для вашего устройства, например адреса AdGuard«a. Далее AdGuard по своему усмотрению предоставляет для обычных доменных имен их реальные IP адреса, а для рекламных — IP адреса, которые возвращают заглушки. Минус в том, что они пропускают все или ничего, зато DNS сервера можно установить прямо на свой роутер и убрать часть рекламы со всех устройств (или получить проблемы со всеми сайтами/приложениями, которые начнут некорректно работать). Ну и конечно никто не может гарантировать, что данные ваших посещений никто не сольет. Итак, есть еще один тип блокирования, когда вы устанавливаете к себе на устройство специальное приложение (например AdGuard). И взамен получаете рутовый сертификат AdGuard к себе на устройство, который позволяет перехватывать ваш HTTPS трафик еще до того, как он попал в браузер и вырезать оттуда рекламу. (А может и не только рекламу). Как по мне, способ очень экстремальный и экстравагантный, доверять кому-то весь свой трафик я не готов. Ну и конечно куда уж в 2021 году без Machine Learning в вебе. Сразу оговорюсь, что разбираюсь в теме на уровне новичка и эксперты в комментариях, надеюсь, меня если что поправят. Одним из развивающихся направлений по блокировке рекламы с помощью нейронных сетей являются Итак, в качестве входных данных для нейронной сети выступает часть DOM модели исходного веб-сайта. Например возьмем следующую простую DOM структуру. Начнем с верхнего HTML элемента и вычислим все его соседние элементы. В последствии необходимо будет пройтись по всем элементам. Затем нам необходимо составить вектор фич для каждого элемента. В качестве примера можно использовать любые свойства элементов. Например, мы обозначили, что элемент с типом div обозначается числом 29 и т.д. Тоже самое повторяет с названиями атрибутов у элементов, возможно, их размерами и т.д. Затем с помощью любого подходящего алгоритма, например, вычисление среднего или поиск максимума, получаем среднее по выборке соседних векторов фич элементов. После этого полученные значения попадают в обученную нейронную сеть, которая на входе имеет количество нейронов, соответствующее размерности вектора после получения среднего. Может иметь любое количество скрытых слоев, и на выходе иметь несколько коэффициентов, которые нам пока ни о чем не говорят. Но конечно же, вся мощь открывается после того, как мы создадим несколько подобных слоев. Это необходимо, чтобы наша нейронная сеть ориентировалась не только на первых соседей заданного элемента, но и смотрела глубже, в зависимости от того, как мы хотим ее обучить. На втором слое в нашем примере, будет происходить все то же самое, за исключением того, что входом для сети будут коэффициенты, полученные на первом слое. В конце концов, мы должны получить какой-то конечный коэффициент, позволяющий нам говорить о наличие или отсутствии в данном элементе рекламы. AdGraph — это такой необычный набор патчей для Chromium в движок Blink и JavaScript движок V8, которые позволяют на основе загружаемых ресурсов выстраивать граф зависимостей на основе трех слоев HTML, HTTP и JavaScript. Затем AdGraph, с помощью натренированной нейронной сети Random Forest, классифицирует граф. В качестве исходной информации для обучения были использованы фильтры блокировки, о которых мы говорили ранее. Подробнее можно посмотреть тут: Пользоваться блокировщиками или нет — личное дело каждого пользователя. Про себя скажу, что не пользовался и не пользуюсь, а сталкиваюсь с этим в основном по работе в департаменте рекламных технологий. Для всех тех, кто пользуется, считаю полезным знать и понимать как ваши инструменты работают. Для остальной части аудитории если вы занимаетесь веб-разработкой, то вы скорее всего не раз и не два столкнетесь с проблемами пользователей на ваших проектах при включенном блокировщике рекламы.topbanner, и он содержит важный виджет на вашем сайте. AdBlock по-умолчанию будет блокировать такой элемент на странице. Тоже самое касается и загружаемых на странице ресурсов, например с содержанием определенных триггерных слов в URL, таких как */baner. ! Expires: 1 days , что означает период обновления раз в день.Как читать/писать фильтры
 https://kb.adguard.com/ru/general/how-to-create-your-own-ad-filters#examples
https://kb.adguard.com/ru/general/how-to-create-your-own-ad-filters#examples$image;$stylesheet;$script;$object;$font;$xmlhttprequest;Блокировка с помощью JavaScript
content-script.js, что позволяет исполнять JavaScript прямо на странице конкретного сайта.hide-if-shadow-contains, основная идея которого заключается в добавлении дополнительного поведения через дескрипторы (подробнее) для прототипов глобальных браузерных объектов или JavaScript объектов.Object.defineProperty(Element.prototype, "attachShadow", {
value(...args)
{
let shadows = new WeakMap();
function observeShadow(mutations, observer)
{
let {host, root} = shadows.get(observer) || {};
// Скрываем ближайший родительский элемент
// если он содержит текст, который надо заблокировать
if (re.test(root.textContent))
{
let closest = host.closest(selector);
if (closest)
hideElement(closest);
}
}
// Создаем Shadow root и сохраняем его значение в root
let root = originalAttachShadow.apply(this, args);
// Слушаем мутации DOM в shadow-root
let observer = new MutationObserver(observeShadow);
observer.observe(root, {
childList: true,
characterData: true,
subtree: true
});
// Держим ссылку на root, в случае если shadow-dom создан закрытый
// чтобы в будущем скрывать элементы оттуда
shadows.set(observer, {host: this, root});
return root;
}
// https://gitlab.com/eyeo/adblockplus/adblockpluscore/-/blob/next/lib/content/snippets.js#L569attachShadow у каждого элемента до исполнения другого JS кода на странице (что позволяет сделать Chrome Extension API), мы сможем контролировать Shadow DOM через MutationObserver, подписываясь на любое изменение внутри него.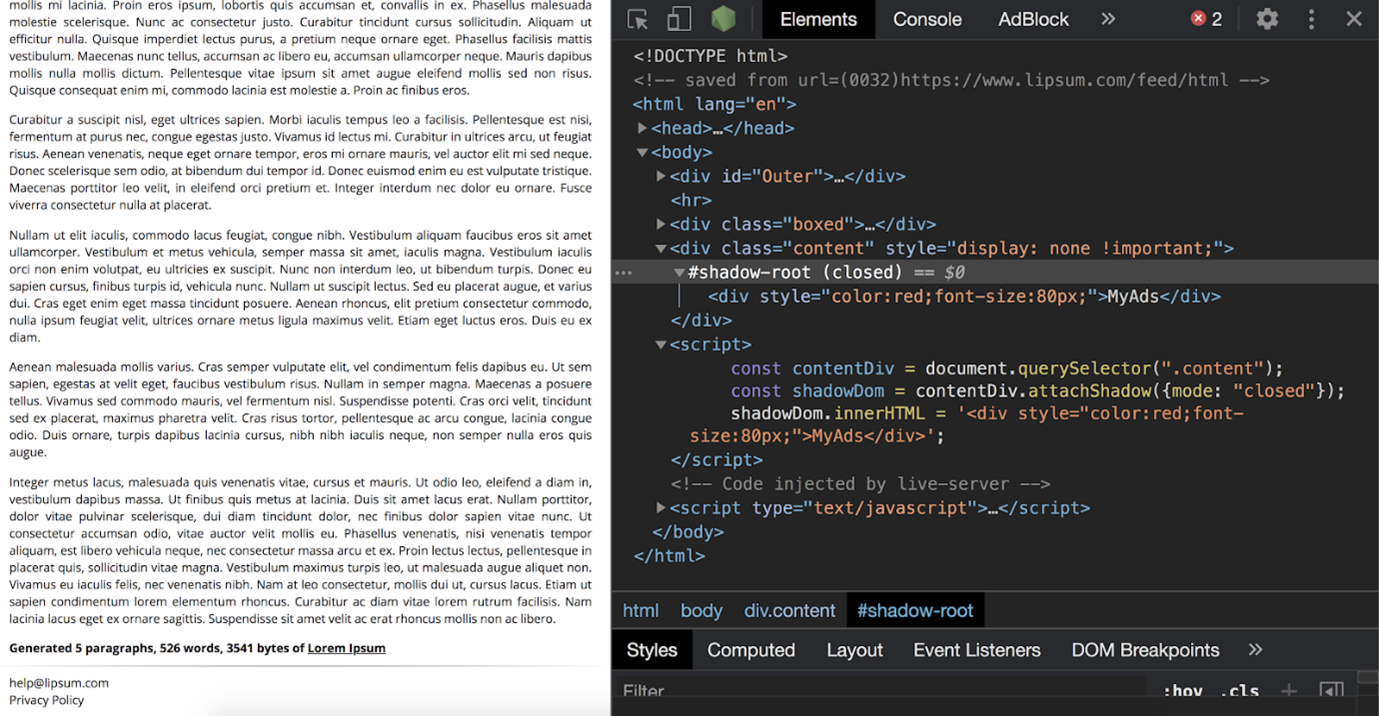 Фильтр на примере: localhost#$#hide-if-shadow-contains /MyAds/
Фильтр на примере: localhost#$#hide-if-shadow-contains /MyAds/abort-on-property-read из AdBlock Plus (код немного упрощен): function abortOnRead(loggingPrefix, context, property)
{
let rid = randomId();
function abort()
{
debugLog(`${property} access aborted`);
throw new ReferenceError(rid);
}
wrapPropertyAccess(context, property, {get: abort, set() {}});
overrideOnError(rid);
}
// https://gitlab.com/eyeo/adblockplus/adblockpluscore/-/blob/next/lib/content/snippets.js#L1139wrapPropertyAccess() реализует вызов Object.defineProperty(), который позволяет навесить специальный getter и вызывать исключения вместо нормальной работы функции.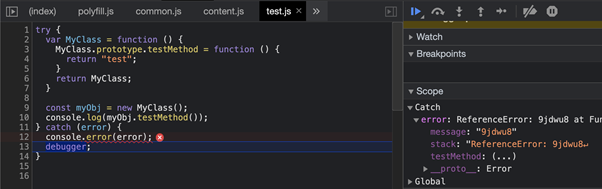 Фильтр: localhost#$#abort-on-property-read Object.prototype.testMethod
Фильтр: localhost#$#abort-on-property-read Object.prototype.testMethodObject.prototype.testMethod, то наш класс успешно наследует getter который начнет возвращать исключения вместо нормального исполнения кода функции.X-Path
![Выражение: .//*[@id='w3c_home_upcoming_events']/ul/li[1]/div[2]/p[1]/a](https://habrastorage.org/getpro/habr/upload_files/07b/5ac/d0a/07b5acd0a3633695737a952a7b7b59a6.png) Выражение: .//*[@id='w3c_home_upcoming_events']/ul/li[1]/div[2]/p[1]/a
Выражение: .//*[@id='w3c_home_upcoming_events']/ul/li[1]/div[2]/p[1]/aPerceptual Image Hash
 Img#1
Img#1 Img#2
Img#2Img#1: 3c3e0e1a3a1e1e1e (0011110000111110000011100001101000111010000111100001111000011110)
Img#2: 3c3e0e3e3e1e1e1e (0011110000111110000011100011111000111110000111100001111000011110)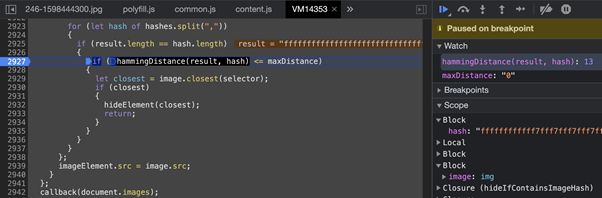 Часть кода фильтра hide-if-contains-image-hash из AdBlock Plus.
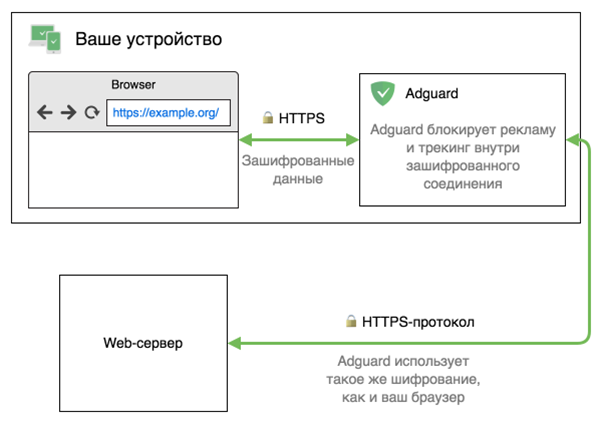
Часть кода фильтра hide-if-contains-image-hash из AdBlock Plus.DNS фильтрация

HTTPS фильтрация

Нейронные сети для блокирования рекламы GCNN
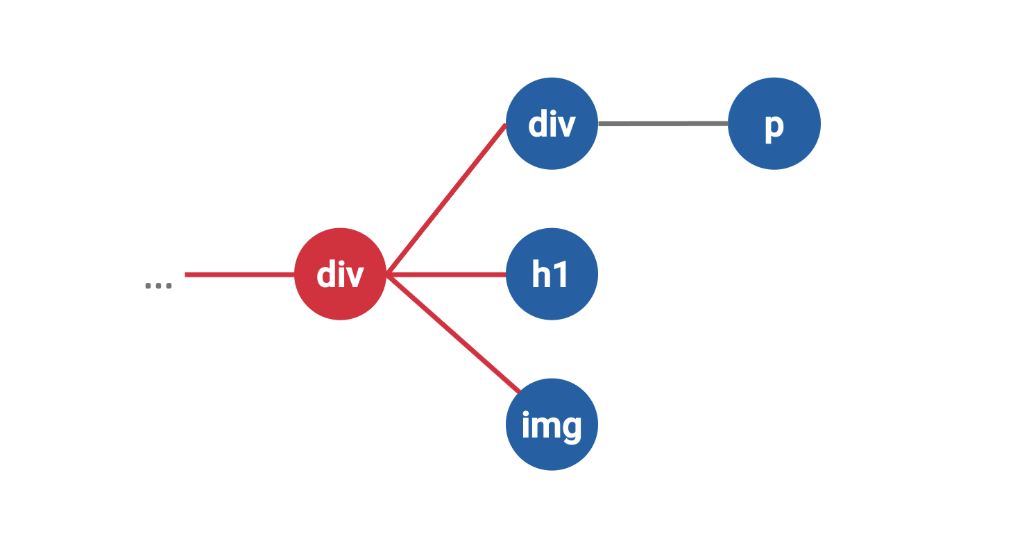
Graph Convolutional Neural Networks, которые уже с некоторыми оговорками можно запускать и на клиенте с помощьюTensorflow.js. Поэтому давайте рассмотрим примерную схему работы.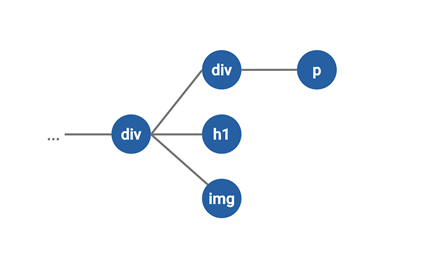

AdGraph
 Общая схема работа
Общая схема работаВместо итогов
