Адаптивная балансировка нагрузки или как повысить надёжность микросервиса
Привет, меня зовут Геннадий, я работаю в Ozon, занимаюсь разработкой backend-сервисов.
Избыточностью компонентов, кластеризацией или балансировкой уже никого не удивишь в наши дни. Это очень важные и нужные механизмы. Но так ли они хороши? На сколько они защищают нас от возможных отказов?
В Ozon все перечисленное используется, но мы сталкивается с проблемами, которые выходят за рамки возможностей стандартных решений и нужны иные подходы и инструменты. Я уверен, что и у вас есть кластеризация и она также не спасает на все сто.
В статье я хочу затронуть некоторые из этих вопросов и показать, как мы повышаем надежность сервисов с помощью адаптивной балансировки.
Изначально решалась проблема клиентской балансировки запросов к PostgreSQL и Redis, но описываемое ниже решение этим не ограничивается — можно применить и для других случаев.
Алгоритм достаточно простой, не привязан к какой-то технологии или языку программирования и может быть адаптирован под разные платформы.
Но обо всем по порядку.
Начнём с проблематики.
Узкие места масштабирования
Есть некий сервис, который должен отвечать на запросы. Он выглядит вот так:
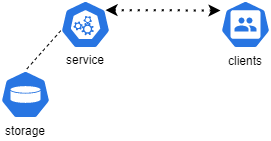
Данные извлекаются, к примеру, из PostgreSQL и передаются потребителям.
В данной схеме узких мест несколько. Если не вдаваться в окружение (сетевую инфраструктуру, вычислительные узлы и т.д.), то их два. Сам сервис и хранилище.
Сервис можно масштабировать горизонтально и тем самым добиться высокой доступности и отказоустойчивости (примем это за истину). Плюс, мы же не в вакууме живем — под рукой обычно есть средства балансировки трафика. А какой-нибудь Kubernetes ещё и отслеживает состояние нашего сервиса (или сам балансировщик — с помощью проб).
Получаем такую картину:
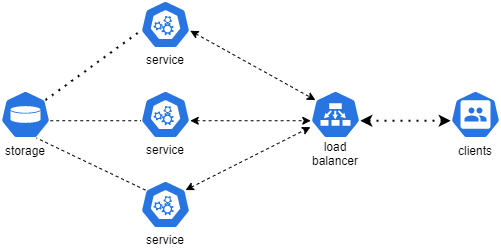
Остаётся хранилище.
Хранилище тоже можно масштабировать горизонтально. Например, сделать несколько реплик и организовать кластер, как в случае с PostgreSQL или тем же Redis.
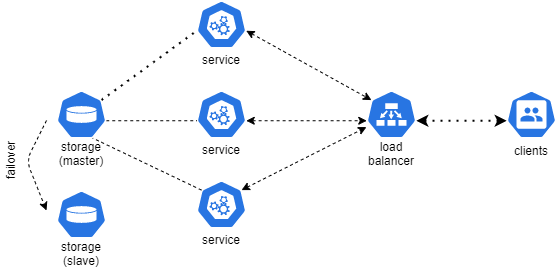
Если бы мы жили в идеальном мире, то на этом можно было завершить статью — проблема решена и бизнес может спать спокойно.
Но в реальном мире остаётся ещё куча других проблем, которые не решаются только лишь кластеризацией.
Больше кластеров
Есть человеческий фактор. Кто-то случайно удалил логин, поменял пароль, удалил таблицу — такое редко, но бывает. В этой ситуации сервис будет полностью недоступен, хотя кластер продолжит работать.
Или, например, в системах, где «много» данных, кто-то запустил долгий запрос и это повлияло на всё остальное. В микросервисах с eventual consistency не так редки случаи запуска различных синхронизаций (пересчётов), индексаций, которые также грузят систему.
Долгие ответы, недоступность по таймауту. Кластер этого не заметит.
Как долго вы будете искать причину? Сколько времени займет исправление? Клиент не ждет, бизнес теряет деньги.
И тут мы приходим к выводу: нам нужны независимые системы, чтобы отказ одной, не влиял на другую!
Хорошо, давайте сделаем два кластера.
В подробности сходимости вдаваться не будем, решений очень много: репликация на уровне железа (СХД), репликация на уровне софта или, к примеру, клиент, мутирующий данные, может писать сразу в несколько мест.
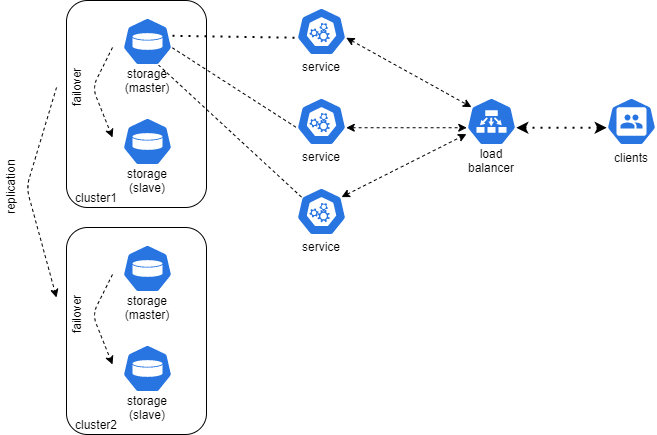
Получили подходящую по согласованности систему из двух «независимых» источников.
И тут нужно решить откуда читать — копий-то две (а то и больше).
Есть несколько вариантов:
1) читаем из первой и, в случае недоступности, обращаемся ко второй;
2) балансируем запросы между системами и, в случае недоступности одной, делаем обращение к другой;
3) ходим сразу в оба кластера, берём первый (или лучший) полученный результат, второй отбрасываем.
Допустим, мы выбрали какую-то из схем доступа. Решили ли мы проблемы? Какие-то да. Если «сломается» одна система, то мы будем получать данные от другой.
Но часть проблем осталась.
В первом и втором варианте остаются все те же долгие ответы и таймауты. Если система быстро «падает», то хорошо — мы без потерь можем переключиться на другую и получить ответ от неё (на самом деле это тоже плохо, но об этом чуть позже). А вот если первый узел отвечает долго, то общее время ответа может быть неприемлемым.
Во втором варианте проблема будет сглажена балансировкой. Если запросы балансируются 1-к-1, то мы теряем всего 50% трафика. Стало лучше, но устраивает ли нас это?
В случае с холодным резервным узлом (первый вариант) может наблюдаться такой эффект: основной узел работает, а второй ждёт. Первый падает, на второй обрушивается лавина запросов. Не факт, что он будет готов к этому. Не прогрет кэш (или какие-то структуры), произошли изменения в конфигурации сервера, поменялся профиль нагрузки. Сервер больше не может держать удар. Периодическое тестирование может решить часть проблем, а вот что делать с прогреванием?
Третий вариант (одновременные запросы к обоим узлам) — очень хороший и мы долгое время его использовали. Он даёт очень достойный с точки зрения отклика результат. Даже на предельной нагрузке ответы были константами, без деградации; узлы компенсировали «тормоза» друг друга. Плюс, решаются проблемы с прогреванием и мониторингом способности держать нагрузку. Если используются ответы только от одного узла, значит, скорее всего второй не справляется.
Но есть проблема: так потребляется больше ресурсов. Одно дело вы обращается к одной базе данных, другое дело сразу два I/O-запроса.
Немного о .NET
Чуть выше я упомянул ещё об одной проблеме. Она точно есть в .NET-средах (возможно, ещё и на других платформах, но по личному опыту могу говорить только за эту).
Приведу пример. На проде работает релиз, за данными он ходит одновременно в PostgreSQL и Redis. Начинаем выкатывать новый релиз, канарейкой. Переключаем трафик: 5%, 10%, 15% и т. д. Видим, что новый релиз генерирует исключения о нехватке соединений к БД: «FATAL: connection limit exceeded for non-superusers». Ничего страшно, Redis же отвечает!
Переключаем трафик дальше. И в какой-то момент, условно на 80% трафика — поды начинают перезагружаться.
Что случилось? Проблема в исключениях (Exceptions).
Основной способ работы с исключениями на платформе .NET: бросаем исключение, и кто-то выше по стеку его обрабатывает. Это не только очень удобный механизм в том плане, что вам не нужно писать «лапшу» из проверок на ошибки, но ещё и очень богатый набор информации: тип, текстовое сообщение, коды и, конечно же, stack trace. И что в этом плохого? В том, что это не бесплатно (с точки зрения CPU и RAM).
Я думаю, не секрет, что обработка исключения в тысячи раз «медленнее», чем обработка кода возврата. И чем дальше по стеку происходит «захват», тем затратнее такая обработка. Это всё stack trace.
Во всех вариантах балансировки (и без балансировки) исключения могут сыграть роковую роль. Сервис тратит на это много вычислительных ресурсов и сам деградирует, в конечном итоге. В контейнерной среде это выглядит как повышенная утилизация CPU, throttling, «подвисание» контейнера и его последующий перезапуск. А пока происходит перезапуск, запросы будут перенаправлены на другие узлы, где произойдет то же самое. Сервис будет полностью недоступен.
Из описанного выше случая с нехваткой соединений, контейнеру «хватило» всего 200 Exceptions в секунду, чтобы произошёл лавинообразный отказ всего приложения.
Чтобы решить эту проблему, можно перестать кидать исключения и перейти на soft-exception — коды возврата. Оставить исключения только для исключительных случаев.
Хорошо, в своём коде и библиотеках мы можем поменять подход. А как быть со сторонними? Они то продолжают использовать исключения. Будем переписывать библиотеку, скажем, NpgSql, которая по-другому не умеет сообщать о проблемах?
Подведём промежуточные итоги. У нас есть следующие проблемы:
долгие ответы;
недоступность (таймауты);
исключения (для .NET).
И есть требования к отказоустойчивости и высокой доступности.
Нам нужен какой-то балансировщик, который бы мог распределять запросы между узлами, в соответствии с временем ответа, учитывая таймауты, и при этом как-то отключать «плохие» узлы. А когда система вернётся к штатному функционированию, автоматически перераспределить нагрузку.
Сделаем такой балансировщик.
Балансировщик
Распределять запросы в соответствии с response time узла — не сложно. Мы должны считать время ответа каждого и распределять запросы в соответствии с этим показателем.
Как считать время? Можно вычислять среднее время всех ответов, начиная со старта приложения. Ок, но с таким подсчётом текущие «проблемы» очень нескоро повлияют на балансировку.
Можно считать средний показатель за период — скользящую. Например, среднее время ответа за 100 последних запросов. Уже лучше.
У простой скользящей есть две проблемы. Первая — все значения имеют равный вес, а это значит, что старые значения будут одинаково влиять на результат наряду с новыми (хотя старые уже не вызывают интереса, как правило).
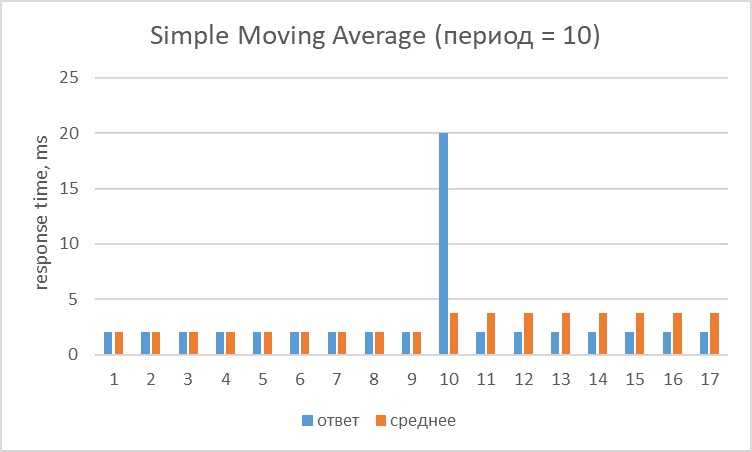
Здесь видно, что десятый запрос с response time в 20ms будет влиять на все последующие десять запросов.
Вторая проблема — значения, которые «приходят» в скользящую, влияют на неё 2 раза (когда входят и когда выходят).
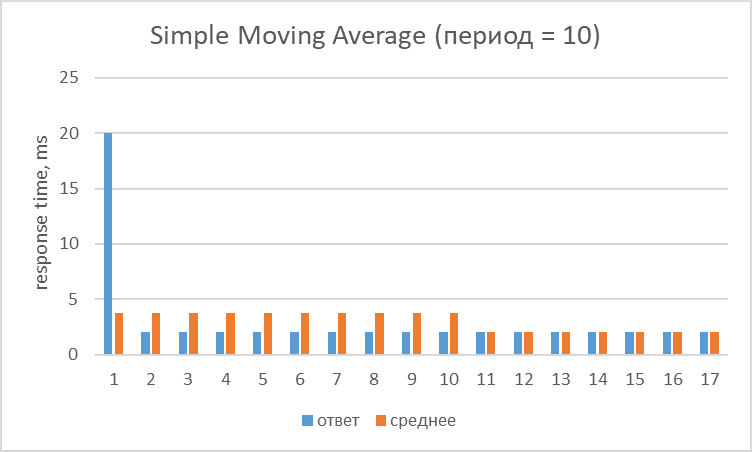
Решить эти проблемы позволяют взвешенные скользящие — они сглаживают этот эффект.
Например, экспоненциальная скользящая средняя. Вот её формула:

где
F — фактор сглаживания; это значение можно подобрать, обычно используется «стандартное»: 2/(n+1), где n — период скользящей;
RT — время ответа;
i — текущий период;
EMA (i-1) — значение EMA за предыдущий период.
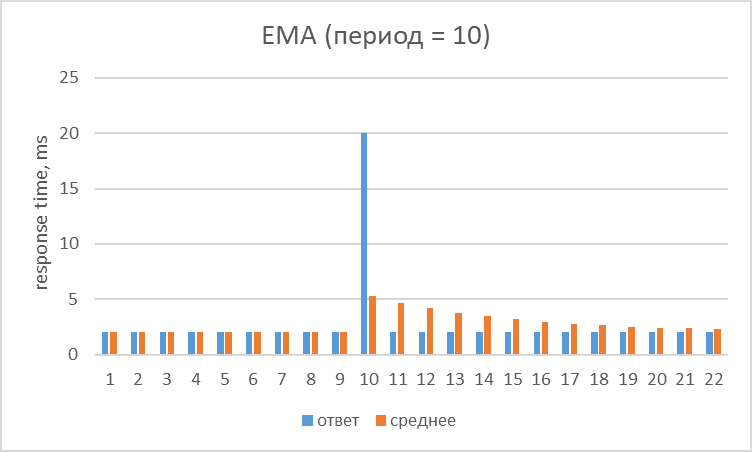
Если простым языком, то предыдущее значение RT (за период) уменьшается на некоторый коэффициент и к нему прибавляется текущее значение с большим весом. Получаем, что текущие значения имеют более высокий приоритет, а старые и те, что выходят из «окна» — влияют в меньшей степени.
Вот так выглядит предыдущий всплеск. Он в большей степени влияет на среднюю при появлении и постепенно уменьшает своё влияние на более новые значения.
А вот как выглядит значение средней с периодом 30, если, скажем, сервис начал постоянно отвечать «плохо»:
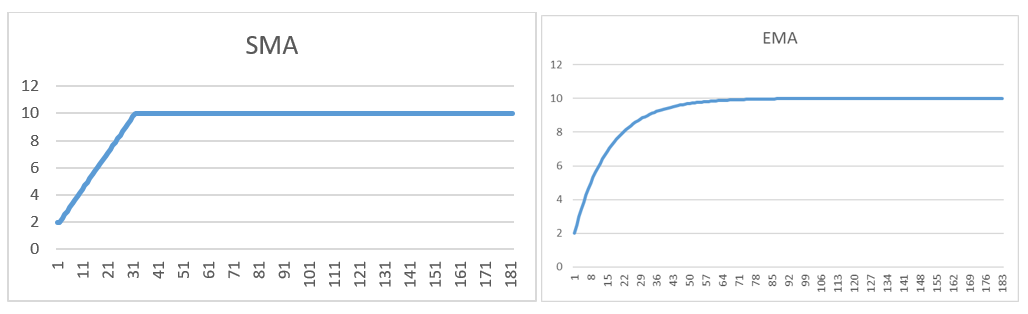
Средний ответ был 2ms, а потом резко упал до 10ms и остановился на этом уровне. Как видим, «поведение» обычной скользящей средней (SMA) линейное и грубое. Хотя при этом стало быстрее соответствовать реальной картине. EMA наоборот, более сглаженное, но немного отстаёт. Чтобы для EMA получить отклик лучше, необходимо «поиграться» с периодом или фактором сглаживания.
Есть другие взвешенные: AMA, Double EMA, Triple EMA, Fractal AMA. Суть балансировки не меняется, в статье их рассматривать не будем.
Отлично, мы научились считать среднее и теперь можем балансировать трафик между узлами.
Давайте разбираться с таймаутами и устойчивыми исключениями (permanent exceptions). Их можно обрабатывать отдельно. Но тогда механизм балансировки станет сложнее — необходимо будет отслеживает ошибки за период и принимать решение об ограничении трафика уже на основе двух показателей. Сложно, не подходит.
А что, если учитывать их как response time? Здесь также есть несколько подходов.
Можно назначить разным показателям разные значения RT. К примеру, договориться что timeout — это 100ms, ошибка — 200ms и т. д. Но в этом случае долгие ответы будут мало отличимыми от этих обособленных.
Или можно задать им коэффициенты от нормального отклика — чтобы в случае замедления ответов нормального узла, мы не получили распределение трафика близкого 1-к-1. Тогда опять придётся отдельно считать среднюю RT для нормальных ответов и вводить ещё какой-то общий счетчик.
А что, если ввести коэффициенты от среднего response time? То есть применить геометрическую прогрессию. Timeout к примеру, будет с коэффициентом 1.5, ошибки — 2 и т. д.
Тогда единичные ошибки будут умножать нормальное время на этот коэффициент и не сильно влиять на среднюю, а постоянные ошибки будут увеличивать это значение и вносить «существенный» вклад в общую картину. То, что нужно!
Есть еще некоторые нюансы, которые мы должны учесть, но хватит теории — пора писать алгоритм.
Адаптивный балансировщик: алгоритм
/// Адаптивный двух-узловой балансировщик///
//Сначала определим константы, относящиеся к средней взвешенной:
const EmaPeriod = 250
const EmaFactor = 2 / (EmaPeriod + 1)
//Далее определим коэффициенты умножения для «плохих» ситуаций:
const BusyMultFactor = 1.5
const TimeoutMultFactor = 2
const ErrorMultFactor = 4
//Чтобы посчитать скользящую среднюю за период, нужно сначала посчитать обычную среднюю за период, а для этого понадобится N значений.
//Чтобы упростить задачу и не выделять массив, будем считать, что при старте приложения средний ответ первых N запросов равен этому числу:
const InitialReponseTime = 2 //Две миллисекунды
//Устанавливаем исходное время ответа для первого и второго узла:
var firstNodeResponseTime = InitialResponseTimeMs
var secondNodeReponseTime = InitialResponseTimeMs
//Сразу определим исходные веса для балансировки
var firstNodeRatio = 1
var secondNodeRatio = 1
//Веса узлов высчитываются, как отношение response time и для сбойных ответов используется геометрическая прогрессия.
//К чему это может привести? К бесконечному росту RT одного из узлов и, как следствие, к существенному уменьшению трафика на него.
//Может быть, это и не плохо, но нам нужно как-то восстанавливаться, а для этого мы должны отправлять запросы на «упавший» узел.
//MaxRatio – тот объём трафика, которым мы можем пожертвовать. Здесь это 1 к 200 или примерно 0.5% трафика.
//Вы на самом деле не теряете эти 0.5% трафика, поскольку после неудачного ответа можно сделать переключение на другой узел.
//Максимум, что может случиться – ухудшение времени ответа. Но, с другой стороны, это позволит автоматически восстановить узел, когда он придёт в норму.
//Значение 0.5% постепенно будут улучшать статистику и выравнивать балансировку.
const MaxRatio = 200
var RequestTotal = 0 // Счётчик запросов
//Введём еще две константы, их назначение я опишу позже
const ThrottlingResponseRt = 1000;
const MaxResponseRt = 250 * MaxRatio
//Функция возвращает узел, который должен обслужить запрос.
//В нашем случае узел – 0 или 1, поскольку балансировщик двухузловой:
func GetNext()
//Определяем какой узел быстрее
if firstNodeRatio >= secondNodeRatio then
fastestNode = 0
else
fastestNode = 1
fi
RequestTotal++; // Увеличиваем счётчик запросов
requestId = RequestTotal mod (firstNodeRatio + secondNodeRatio) // У медленного узла вес всегда равен 1.
//У быстрого может быть до MaxRatio (в нашем случае 200).
//Поэтому если номер запроса делится на 201 без остатка, то отправляем на медленный узел, иначе – на быстрый.
//Это не очень точный механизм, поскольку не учитываются моменты перебалансировки.
//Но нас это не должно волновать в highload-системах, поскольку один лишний запрос не в тот узел
//не окажет значительного влияния на общий результат
if (requestId = 0) then
return not fastestNode // Возвращаем медленный узел
else
return fastestNode // Возвращаем быстрый узел
fi
end func
//Функция обновления статистики. После каждого запроса к хранилищу необходимо обновлять статистику ответов.
func updateStatistics(nodeId, responseTime, status)
if nodeId = 0 then
prevNodeResponseTime = firstNodeResponseTime //Текущее среднее время ответа. По нему посчитается, как время ответа для сбойных ответов, так и новое среднее значение.
fallbackNodeRatio = secondNodeRatio //Этот параметр нужен, чтобы счётчик средней не ушёл в «бесконечность.
else
prevNodeResponseTime = secondNodeResponseTime
fallbackNodeRatio = firstNodeRatio
fi
currentResponseTime = getResponseTime(prevNodeResponseTime, responseTime, status, fallbackNodeRatio)
newNodeResponseTime = calcEma(prevNodeResponseTime, currentResponseTime)
//Сохраняем среднюю
if nodeid = 0 then
firstNodeResponseTime = newNodeResposneTime
else
secondNodeResponseTime = newNodeResponseTIme
fi
updateRequestRatio();
end func
//Функция для расчёта времени ответа – умножение на коэффициенты, возврат как есть и некоторые другие оптимизации
func getResponseTime(prevNodeResponseTime, responseTime, status, fallbackNodeRatio)
if status != OK AND prevNodeResponseTime > ThrottlingResponseRt && fallbackNodeRatio == MaxRatio then
return prevNodeResponseTime;
//Если статус ответа от узла не успешен и текущее среднее выше значения ThrottlingResponseRt и при этом вес «другого» узла равен максимальному,
//то мы не применяем коэффициент и просто возвращаем текущее значение средней.
//Это делается для того, чтобы не увеличивать среднее значение responseTime до бесконечности,
//поскольку балансировка уже осуществляется 1 к MaxRatio (в нашем случае 1 к 200).
//TrottlingResponseRt – это граница, которая должна быть немного больше, чем MaxRatio, умноженное на типичное время ответа от узла.
//К примеру, вы знаете, что обычно узлы отвечают за 2ms, соответственно, 1 к 200 наступит уже при 400ms.
//После этого значения нет смысла увеличивать среднее время ответа.
//Но нужно подобрать это значение. Если сделать его слишком маленьким, то среднее «плохого» узла быстро начнёт
//увеличиваться до определенного предела и соответственно медленнее потом восстанавливаться.
//То же самое справедливо для очень больших значений.
end fi
// Применяем коэффициенты
If status = busy then
nodeResponseTime = BusyMultFactor * prevNodeResponseTime
else if status = … then // Здесь другие коэффициенты для плохих «ответов»
….
else // Для успешного ответа – просто его и возвращаем
return responseTime
fi
if nodeResponseTime > MaxResponseRt then
return MaxResponseRt // Это значение определяет максимальное время, после которого наш ответ скорее всего будет не интересен.
//Может произойти такая ситуация, когда один узел отказал, а второй, получив поток трафика, начал деградировать.
//В этом случае, для сбойного узла мы должны выйти за пределы TrottlingResponseRt. Но опять же встает вопрос, до какого предела?
//Этот предел и определяет MaxResponseRt.
//Мы знаем, что потребителю не интересен наш ответ после 250ms (назовем его deadline_timeout).
//Исходя из этого мы определяем MaxResponseRt, как deadline_timeout умноженный на MaxRatio.
else
return nodeResponseTime
fi
end func
//Функция обновления весов балансировки:
func UpdateRequestRatio()
if firstNodeResponseTime <= secondNodeResponseTime then
fastestNode = 0
else
fastestNode = 1
fi
overallRt = firstNodeResponseTime + secondNodeResponseTime
if fastestNode = 0 then
fastestNodePercent = firstNodeResponseTime / overallRt
else
fastestNodePercent = secondNodeResponseTime / overallRt
fi
slowestNodePercent = 1 - fastestNodePercent
slowNodeRatio = slowestNodePercent / fastestNodePercent
if slowNodeRatio > MaxNodeRatio then
slowNodeRatio = MaxNodeRatio
fi
if fastestNode = 0 then
firstNodeRatio = slowNodeRatio
secondNodeRatio = 1
else
firstNodeRatio = 1
secondNodeRatio = slowNodeRatio
fi
end func
//Функция для расчета EMA:
func calcEma(prevNodeResponseTime, currentResponseTime)
return currentResponseTime*EmaFactor + prevNodeResponseTime * (1-EmaFactor)
end func
Вот и весь код.
Использовать его нужно следующим образом:
nodeId = GetNext()
cluster = getClusterByNodeId(nodeId) // Получаем информацию о кластере, по номеру узла. Это функцию вы определяете самостоятельно
responseInfo = getData(cluster, request) // Это также ваша функция, но для получения данных
updateStatistics(nodeId, responseInfo.responseTimeMs, responseInfo.status) // Вам нужно замерить время ответа от узла и передать статус
if responseInfo.status != OK then // Если предыдущий ответ был неудачным, то обращаемся к другому узлу
cluster = getClusterByNodeId(not nodeId)
responseInfo = getData(cluster, request)
updateStatistics(not nodeId, responseInfo.responseTimeMs, responseInfo.status) // Опять обновляем статистику
…
fi
То есть для запроса вы должны спросить у балансировщика, «кто следующий», и после запроса обновить информацию о нём. Для второго ответа, если он случился, также обновляем статистику.
Что ещё забыли? Конечно, про синхронизацию потоков. Этот вопрос нельзя обойти стороной, поскольку он очень важен в реальном мире.
Структуры балансировки (счётчики, веса) сосредоточены в одном месте, и в высоконагруженном приложении в любом случае произойдёт конкурентный доступ.
Я использую синхронизацию, когда обновляю счётчик запросов (функция GetNext, инструкция RequestTotal++). Конкретно, в С# используется конструкция синхронизации пользовательского режима — Interlocked.
Нужно ли использовать синхронизацию при обновлении счётчиков средних ответов (firstNodeResponseTime и secondNodeResponseTime)? Мой ответ — нет. И вот почему.
Как правило, на протяжении некоторого продолжительного времени, сервис отвечает с константной задержкой или не отвечает вовсе. То есть ведёт себя ожидаемо, стабильно.
Даже если случайные всплески в порыве конкуренции перезатрут «хорошие» (или «плохие») данные, вряд ли это существенно повлияет на общую картину. Поэтому здесь их можно не использовать.
А вот для обновления весов (nodeRatio) синхронизация нужна. Мы должны обеспечить балансировку 1-к-X, поэтому структура должна быть целостной. Значит, за это должен отвечать один поток. Используем Interlocked.
А есть ли смысл обновлять веса для каждого запроса? В highload-системах можно этой точностью пренебречь. Одного раза на каждые 50 запросов будет вполне достаточно.
На этом обсуждение самого алгоритма можно завершить. На мой взгляд все ключевые вопросы мы разобрали.
Практика
Первым делом запускаем нагрузочные тесты.
У нас есть приложение, которое ходит за данными в PostgreSQL и Redis. Даём на него нагрузку и через какое-то время производим отключение одного из хранилищ.
Отключаем PostgreSQL.
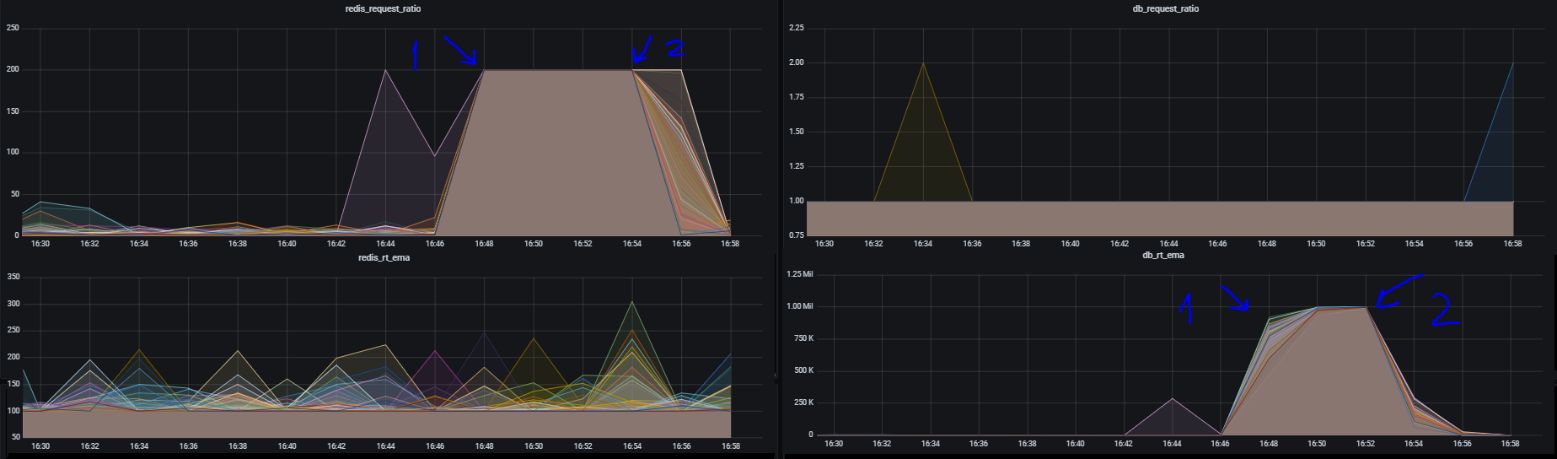
На графике стрелкой 1 отмечен момент отключения базы данных (переименовываем таблицу, из которой читает сервис). Отключение было примерно в 16:44 (балансировщик отдает метрики, но с небольшим отставанием, чтобы уменьшить накладные расходы). Видно, что примерно за две минуты база данных была полностью отсечена от запросов, на неё падали эти 0.5% трафика с fallback на Redis. Cтрелка 2 — обратно вернул таблицу на место.
Давайте посмотрим, как это повлияло на характеристики сервиса.
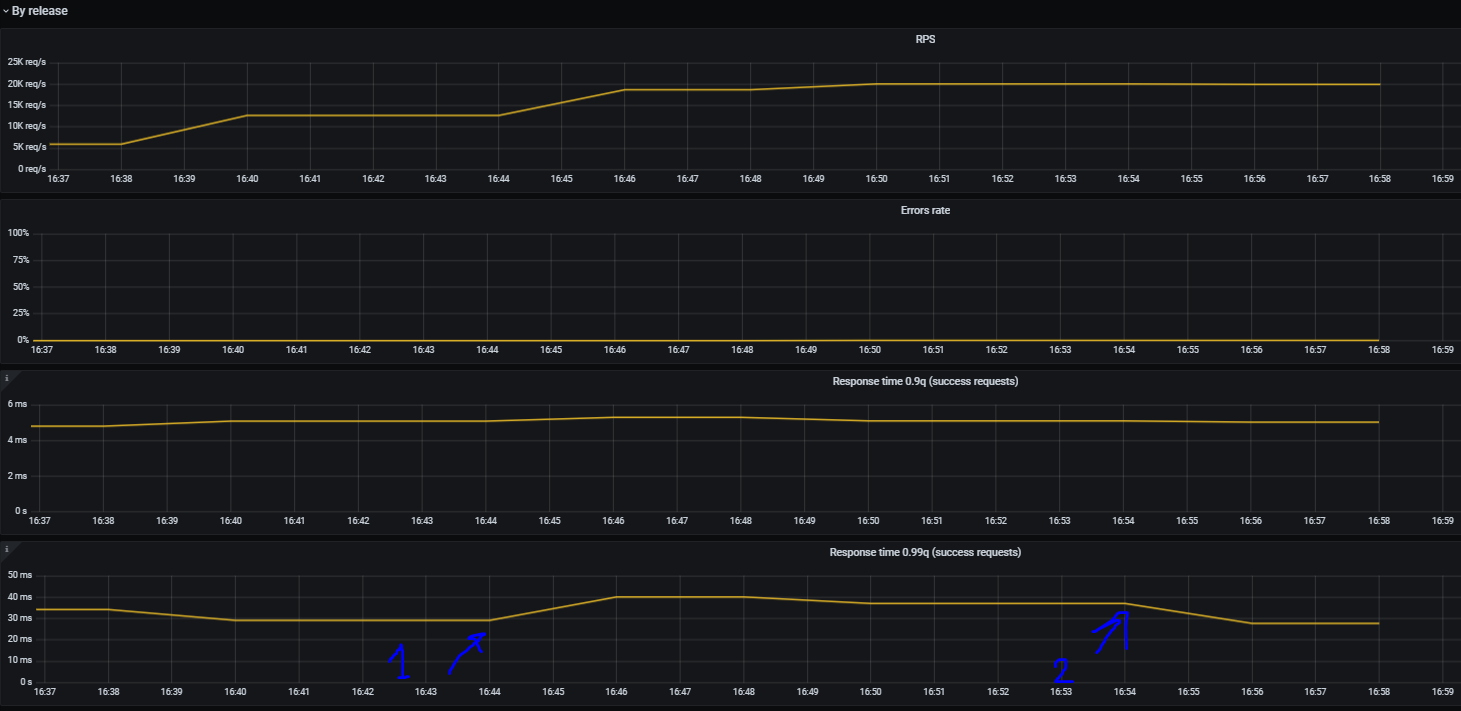
Error rate остался на прежнем уровне и немного увеличился response time — поскольку всё-таки часть трафика попала на отказавший postgres, и только потом происходил fallback на Redis. PostgreSQL очень быстро кидал exception (таблицы же нет, чего ждать), поэтому response time не сильно увеличился. Но, что самое главное, приложение «выжило» и не упало!
И обратная картина. Убиваем Redis (командой DEBUG SEGFAULT).
К сожалению, данных балансировки по этому тесту нет. Но есть данные по работе приложения.
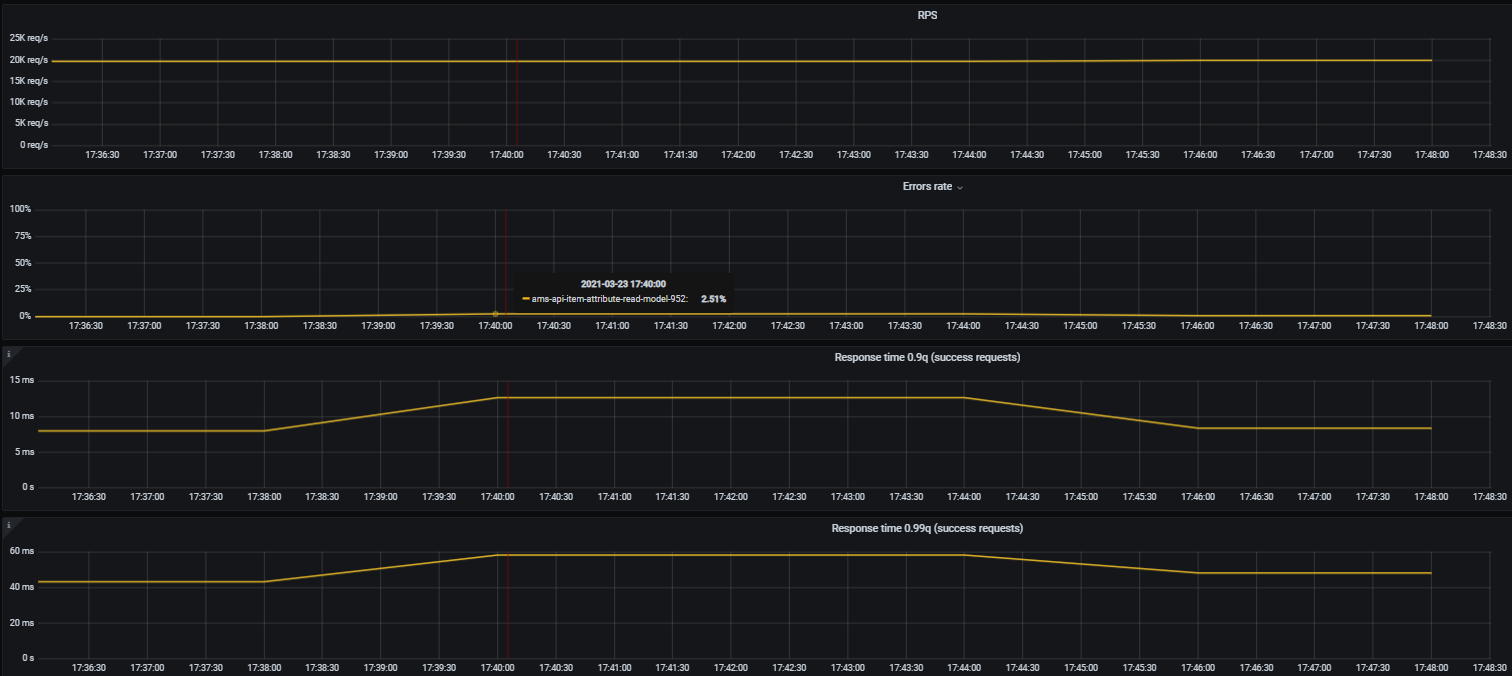
На скрине плохо видно, но error rate увеличился до 2.51% (в нормальном режиме работы — 0.009%). Подрос response time в 90 и 99 квантилях. Но в целом, катастрофы не случилось.
Это были стресс-тесты.
А что на «проде»?
Там вот так убивать базу или Redis страшно (хотя очень бы хотелось).
Но есть момент выкатки релиза, когда не хватает соединений к PostgreSQL и постоянно возникает exception.
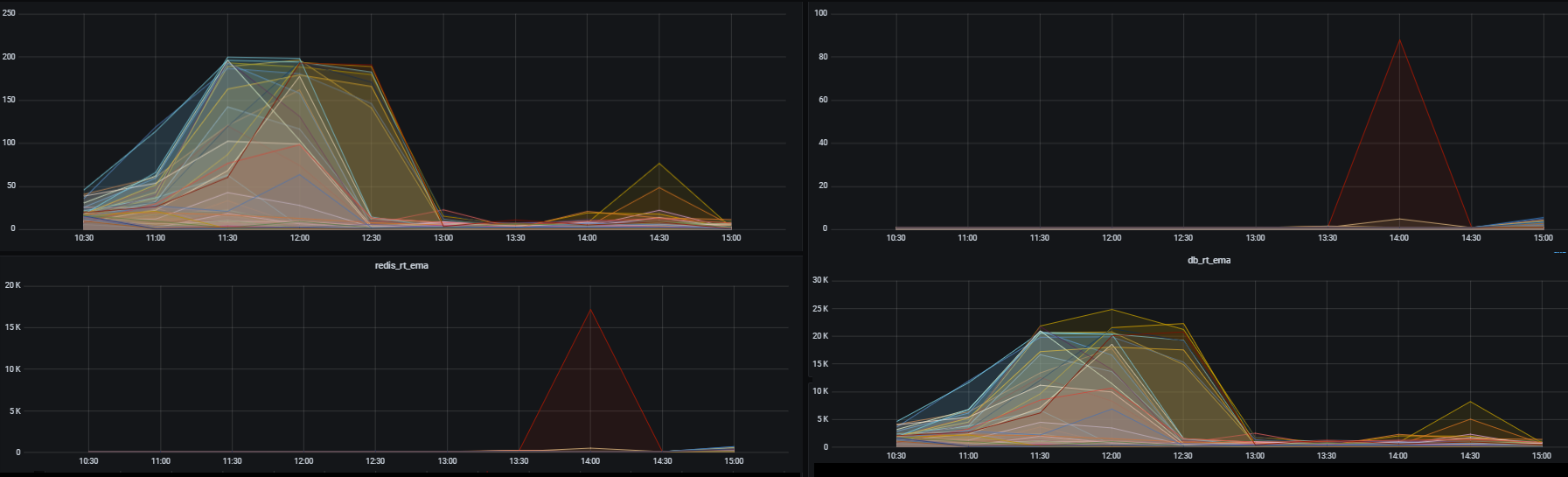
Вот этот «холмик» — как раз и есть момент отсечения PostgreSQL.

Нехватка соединений в целом никак не повлияла на сервис, лишь немного деградировал ответ в 99 квантиле. На графике это период с 11:30 до 12:30.
А вот несколькими неделями ранее, до релиза балансировки — был бы полный отказ приложения.
Не серебряная, но пуля
Мы написали адаптивный балансировщик, который приспосабливается к изменяющимся условиям, умеет отсекать нагрузку и автоматически восстанавливаться. При этом весьма простой и с небольшими накладными расходами.
Понятно, что это не серебряная пуля, и всех проблем мы не решили. Но в какой-то степени мы добились улучшения показателей высокой доступности и отказоустойчивости сервиса.
На этом у меня всё.
Буду рад комментариям, замечаниям, пожеланиям!
