ActiveRecord Schema Consistency — а если проверю?

Это ещё один текст по мотивам доклада на Ruby Russia 2022. Он посвящён консистентности схемы базы данных на примере библиотеки database_consistency. Автор — Евгений Демин, Principal Engineer и Ruby-разработчик Toptal.
Toptal, как и многие другие компании, сделала ставку на язык программирования Ruby и получила большой монолит. Каждый день, приходя на работу, я вижу очень много новых пул-запросов и новых коммитов от разных команд. Поскольку компания большая и большой монолит, у нас очень большая база данных и, соответственно, ActiveRecord. За пять лет работы над этим монолитом в компании Toptal случались разные ситуации.
Консистенции между ActiveRecord и базой данных
В 2018 году где-то в глубинах нашей ActiveRecord произошло падение со странной ошибкой.

Что происходит? Трудно понять, почему при обновлении одного поля у нас падает валидация по другому.

Оказывается, валидация была добавлена не так давно, то есть модель и таблица уже существовали. Почему упала валидация? Потому что в базе данных есть старые записи, которые забыли обновить.
Как можно было этого избежать? Одно из очевидных решений — при добавлении валидации убедиться, что все записи в нашей таблице готовы к этой валидации.
Как это сделать? С помощью null constraint.

К сожалению, любой может забыть добавить null constraint в процессе добавления валидации из-за большого объема работы. Поэтому мне стало интересно, как часто случаются такие ситуации, когда разработчик добавил валидацию, но не убедился, что в базе данных существует null constraint.

По результатам очень грубой оценки оказалось, что в нашем монолите их много. Это навело меня на мысль, что можно написать линтер, который автоматически искал бы похожие ситуации, и который в дальнейшем можно было бы расширять и добавлять в другие проекты. Такие ситуации я называю консистенциями между ActiveRecord схемой и базой данных.
v0.1.0 ColumnPresenceChecker
v0.1.0 ColumnPresenceChecker — это первая проверка, которая появилась в библиотеке.

Допустим, у нас есть таблица users, а также класс Userс валидацией над полем name. В данном случае библиотека покажет, что не хватает null constraint над полем nameнашей таблицы.

Соответственно, нужна следующая схема баз данных:

Сделать это можно с помощью простой миграции.

ПРИМЕЧАНИЕ. Эта миграция не подходит для тех, кто следует Zero Downtime Deployment Policy.
В нашем монолите оказалось более 500 кейсов, что много даже для нашей базы данных. Но, как это часто бывает в больших компаниях, эта хорошая идея пришла в голову не только мне. Проблему решил коллега из другой команды вручную с помощью небольшого скрипта. Однако я решил продолжить писать гем, чтобы в дальнейшем его можно было расширять и добавлять другие проверки, а также выложить в Open Source, чтобы им могли пользоваться другие компании и индивидуальные разработчики. Спустя несколько месяцев произошел релиз гема, и он стал дополняться новыми проверками.
v0.2.0 NullConstraintChecker
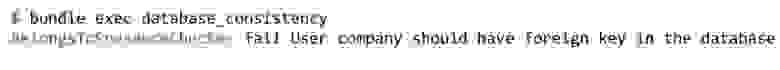
NullConstraintChecker — это вторая проверка после ColumnPresenceChecker, которая делает то же самое, но в обратную сторону. Предположим, у нас есть null constraint, но нет валидации на модели. Это проблема. Например, пользователь использует один из наших интерфейсов, API или страницу и пытается заполнить какую-то форму, но не заполняет определенные значения. Если бы у нас была валидация, выпала бы ошибка 422 Unprocessable Entity, и на фронтенде мы могли бы ее соответствующим образом обработать. Однако, если мы не добавляем валидацию, сервер будет падать с 500-ой ошибкой, что не очень хорошо.
v. 0.4.0 BelongsToPresenceChecker
BelongsToPresenceChecker отслеживает, чтобы все неполиморфные ассоциации BelongsTo имели соответствующие foreign key constraint в базе данных.

Это очень полезная проверка, чтобы гарантированно иметь данные, связанные с нашей таблицей в связанных таблицах, чего без foreign key constraint мы гарантировать не можем.
v. 0.5.0 MissingUniqueIndexChecker
Мы все знаем, что валидация на уникальность сама по себе уникальность не гарантирует. Во-первых, может быть Race Condition, во-вторых, данные могли быть сохранены с выключенной валидацией, в-третьих, что угодно могло пойти не так. Без соответствующего уникального индекса, который покрывает нашу валидацию, уникальность мы гарантировать не можем, и было бы хорошо иметь этот индекс в нашей таблице. Данная проверка смотрит, покрыта ли валидация на уникальность этими индексами.

В начале 2019 года я встретил конкурента. Сначала мне захотелось присоединиться к существующему гему, который на тот момент был уже достаточно популярен, и у него было уже несколько проверок. Однако коллеги, в том числе Михаил Папис, создатель RVM, подсказали, что здоровая конкуренция — это здорово, как и свое видение какой-то проблематики и создание своего продукта. Поэтому я решил продолжить разрабатывать собственный гем.
В этот момент в нашей компании произошла новая неочевидная проблема.
v0.6.0 MissingIndexChecker
Предположим, у нас есть простая таблица users, таблица accounts с user_id, модель Users с has_one :account и модель Accounts с belongs_to.

Казалось бы, ничего не предвещает беды. ActiveRecord работает как часы, для каждого пользователя возвращаются аккаунты.

Однако для конкретного пользователя, когда мы выполняем joins, почему-то отображается два аккаунта, то есть всего две записи.

Чего же не хватает? Это не очевидно, и не все знают об этой проблеме по умолчанию. Все очень просто. has_one не гарантирует, что будет 0 или 1 связь с нашей базой данных. Поэтому желательно иметь соответствующий уникальный индекс над нашим связующим вторичным ключом, что не сделано в первоначальной схеме.

Отсутствие индекса может привести к очень странным последствиям. Например, часть нашей программы может отлично работать, но в конкретных ситуациях все может посыпаться и потребовать усилий, чтобы все исправить.
Индекс в схеме должен быть уникальным.

Добиться этого можно простой миграцией.

Пролетел еще один год и вышли новые проверки.
v0.7.0 LengthConstraintChecker
Данная проверка смотрит, чтобы все наши типы данных, которые имеют определенные лимиты, например, varchar (128), в нашей базе данных, имели соответствующие валидации на длину в наших моделях.

v. 0.8.0 PrimaryKeyTypeChecker
Начиная с пятой версии Rails, выходит обновление, предусматривающее, что все первичные ключи по умолчанию имеют большой тип данных, например, BIGINT или BIG SERIAL. К сожалению, в каких-то проектах первичные ключи имеют меньший тип данных. Это нормально, поскольку не так-то просто переполнить 2 миллиарда первичных ключей. Однако это можно сделать, и после переполнения это приведет к неординарным проблемам.
В конце 2020 года Дэвид Хенсон, создатель Rails, больше известный, как DHH, рассказал, как все рассыпалось в Basecamp. Они столкнулись с переполнением типа для вторичного ключа, то есть первичный ключ имел больший тип данных, чем вторичный. Соответственно, когда были добавлены новые записи для таблицы, все было хорошо, но в связывающей таблице вторичный ключ переполнился. Связь была утеряна или же указывала на другую запись в первичной таблице (что, возможно, еще хуже).
Поэтому я решил написать валидатор для DHH, чтобы находить такие ситуации автоматически. Мы это сделали в рамках v0.8.5 ForeignKeyTypeChecker.
v0.8.5 ForeignKeyTypeChecker
Предположим, у нас есть таблица users, таблица account с полем user_id, модель User с ассоциацией с has_one :account и модель Accountsс belongs_to :user.

В данном случае ошибка библиотеки выдаст ошибку, что наш тип данных для вторичного ключа недостаточен для покрытия типа данных первичного ключа.

Исправить это можно примерно следующим образом:

Необходимо перейти от .integer к .bigint для user_id в таблице accounts. Сделать это можно следующий миграцией:

