Active/Passive PostgreSQL Cluster с использованием Pacemaker, Corosync
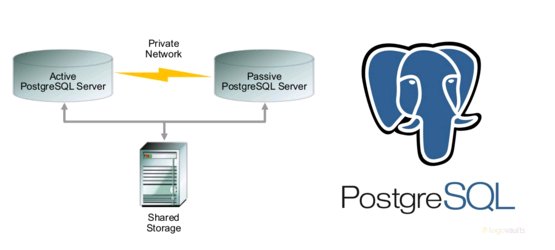 Описание
Описание
В данной статье рассматривается пример настройки Active/Passive кластера для PostgreSQL с использованием Pacemaker, Corosync. В качестве дисковой подсистемы рассматривается диск от системы хранения данных (CSV). Решение напоминает Windows Failover Cluster от Microsoft.
Технические подробности:
Версия операционной системы — CentOS 7.1
Версия пакета pacemaker — 1.1.13–10
Версия пакета pcs — 0.9.143
Версия PostgreSQL — 9.4.6
В качестве серверов (2шт) — железные сервера 2×12 CPU/ 94GB memory
В качестве CSV (Cluster Shared Volume) — массив класса Mid-Range Hitachi RAID 1+0
Подготовка узлов кластера
Правим /etc/hosts на обоих хостах и делаем видимость хостов друг друга по коротким именам, например:
[root@node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.66.23 node1.local.lan node1
10.1.66.24 node2.local.lan node2
Также делаем обмен между серверами через SSH-ключи и раскидываем ключи между хостами.
После этого надо убедиться, что оба сервера видят друг друга по коротким именам:
[root@node1 ~]# ping node2
PING node2.local.lan (10.1.66.24) 56(84) bytes of data.
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=1 ttl=64 time=0.204 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=2 ttl=64 time=0.221 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=3 ttl=64 time=0.202 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=4 ttl=64 time=0.207 ms
[root@node2 ~]# ping node1
PING node1.local.lan (10.1.66.23) 56(84) bytes of data.
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=1 ttl=64 time=0.202 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=2 ttl=64 time=0.218 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=3 ttl=64 time=0.186 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=4 ttl=64 time=0.193 ms
Установка пакетов для создания кластера
На обоих хостах ставим необходимые пакеты, чтобы затем собрать кластер:
yum install -y pacemaker pcs psmisc policycoreutils-python
Затем стартуем и включаем службу pcs:
systemctl start pcsd.service
systemctl enable pcsd.service
Для управление кластером нам потребуется специальный пользователь, создаем его на обоих хостах:
passwd hacluster
Changing password for user hacluster.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
Pacemaker|Corosync
Для проверки аутентификации, с первой ноды необходимо выполнить команду:
[root@node1 ~]# pcs cluster auth node1 node2
Username: hacluster
Password:
node1: Authorized
node2: Authorized
Далее, стартуем наш кластер и проверяем состояние запуска:
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
pcs cluster start --all
pcs status --all
Вывод о состоянии кластера должен быть примерно такой:
[root@node1 ~]# pcs status
Cluster name: cluster_web
WARNING: no stonith devices and stonith-enabled is not false
Last updated: Tue Mar 16 10:11:29 2016
Last change: Tue Mar 16 10:12:47 2016
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 Nodes configured
0 Resources configured
Online: [ node1 node2 ]
Full list of resources:
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Теперь переходим к настройке ресурсов в кластере.
Настройка CSV
Заходим на первый хост и настраиваем LVM:
pvcreate /dev/sdb
vgcreate shared_vg /dev/sdb
lvcreate -l 100%FREE -n ha_lv shared_vg
mkfs.ext4 /dev/shared_vg/ha_lv
Диск готов. Теперь нам необходимо сделать так, что было на диск не применялось правило автомонтирования для LVM. Делается это внесением изменений в файле /etc/lvm/lvm.conf (раздел activation) на обоих хостах:
activation {.....
#volume_list = [ "vg1", "vg2/lvol1", "@tag1", "@*" ]
volume_list = [ "centos", "@node1" ]
Обновляем initrams и перезагружаем ноды:
dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)
shutdown -h now
Добавление ресурсов в кластер
Теперь необходимо создать группу ресурсов в кластере — диск c файловой системой и IP.
pcs resource create virtual_ip IPaddr2 ip=10.1.66.25 cidr_netmask=24 --group PGCLUSTER
pcs resource create DATA ocf:heartbeat:LVM volgrpname=shared_vg exclusive=true --group PGCLUSTER
pcs resource create DATA_FS Filesystem device="/dev/shared_vg/ha_lv" directory="/data" fstype="ext4" force_unmount="true" fast_stop="1" --group PGCLUSTER
pcs resource create pgsql pgsql pgctl="/usr/pgsql-9.4/bin/pg_ctl" psql="/usr/pgsql-9.4/bin/psql" pgdata="/data" pgport="5432" pgdba="postgres" node_list="node1 node2" op start timeout="60s" interval="0s" on-fail="restart" op monitor timeout="60s" interval="4s" on-fail="restart" op promote timeout="60s" interval="0s" on-fail="restart" op demote timeout="60s" interval="0s" on-fail="stop" op stop timeout="60s" interval="0s" on-fail="block" op notify timeout="60s" interval="0s" --group PGCLUSTER
Обратите внимание, что у всех ресурсов одна группа.
Также надо не забыть поправить dafault -параметры кластера:
failure-timeout=60s
migration-threshold=1
В конечно итоге, Вы должны увидеть подобное:
[root@node1 ~]# pcs status
Cluster name: cluster_web
Last updated: Mon Apr 4 14:23:34 2016 Last change: Thu Mar 31 12:51:03 2016 by root via cibadmin on node2
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 nodes and 4 resources configured
Online: [ node1 node2 ]
Full list of resources:
Resource Group: PGCLUSTER
DATA (ocf::heartbeat:LVM): Started node2
DATA_FS (ocf::heartbeat:Filesystem): Started node2
virtual_ip (ocf::heartbeat:IPaddr2): Started node2
pgsql (ocf::heartbeat:pgsql): Started node2
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Проверяем статус службы PostgreSQL, на хосте, где ресурсная группа:
[root@node2~]# ps -ef | grep postgres
postgres 4183 1 0 Mar31 ? 00:00:51 /usr/pgsql-9.4/bin/postgres -D /data -c config_file=/data/postgresql.conf
postgres 4204 4183 0 Mar31 ? 00:00:00 postgres: logger process
postgres 4206 4183 0 Mar31 ? 00:00:00 postgres: checkpointer process
postgres 4207 4183 0 Mar31 ? 00:00:02 postgres: writer process
postgres 4208 4183 0 Mar31 ? 00:00:02 postgres: wal writer process
postgres 4209 4183 0 Mar31 ? 00:00:09 postgres: autovacuum launcher process
postgres 4210 4183 0 Mar31 ? 00:00:36 postgres: stats collector process
root 16926 30749 0 16:41 pts/0 00:00:00 grep --color=auto postgres
Проверяем работоспособность
Имитируем падение сервиса на ноде2 и смотрим, что происходит:
[root@node2 ~]# pcs resource debug-stop pgsql
Operation stop for pgsql (ocf:heartbeat:pgsql) returned 0
> stderr: ERROR: waiting for server to shut down....Terminated
> stderr: INFO: PostgreSQL is down
Проверяем статус на ноде1:
[root@node1 ~]# pcs status
Cluster name: cluster_web
Last updated: Mon Apr 4 16:51:59 2016 Last change: Thu Mar 31 12:51:03 2016 by root via cibadmin on node2
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 nodes and 4 resources configured
Online: [ node1 node2 ]
Full list of resources:
Resource Group: PGCLUSTER
DATA (ocf::heartbeat:LVM): Started node1
DATA_FS (ocf::heartbeat:Filesystem): Started node1
virtual_ip (ocf::heartbeat:IPaddr2): Started node1
pgsql (ocf::heartbeat:pgsql): Started node1
Failed Actions:
* pgsql_monitor_4000 on node2 'not running' (7): call=48, status=complete, exitreason='none',
last-rc-change='Mon Apr 4 16:51:11 2016', queued=0ms, exec=0ms
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Как мы видим сервис уже прекрасно себя чувствует на ноде1.
ToDO: сделать зависимости от ресурсов внутри группы…
Литература:
clusterlabs.org
