5 типичных ошибок при использовании Apache Kafka

Даже если у вас большой опыт работы с Apache Kafka, время от времени наверняка случается зайти в тупик. Например, когда вы конфигурируете и изучаете клиенты или настраиваете и отслеживаете брокеры. Попробуй за всем уследить, когда в конвейере Kafka столько компонентов. В этой статье описано пять частых ошибок и советы по тому, как их избежать на всех этапах — от конфигурирования клиентов и брокеров до планирования и мониторинга. Эти рекомендации сэкономят вам время и силы.
Какие ошибки мы совершаем
Со стороны клиента:
1. Устанавливаем слишком маленькое значение request.timeout.ms.
2. Неправильно понимаем повторные попытки продюсера и исключения, допускающие повторные попытки.
Со стороны брокера:
3. Не отслеживаем ключевые метрики брокера.
4. Создаём слишком много партиций.
5. Устанавливаем слишком маленькое значение segment.ms.
Сначала рассмотрим типичные ошибки на стороне клиента.
1. Устанавливаем слишком маленькое значение request.timeout.ms
request.timeout.ms — это конфигурация на стороне клиента, которая определяет, как долго клиент (продюсер и консьюмер) будет ждать ответа от брокера. По умолчанию — 30 секунд.
Если за это время ответ не пришёл, случится одно из двух: клиент снова отправит запрос (если повторные попытки включены и не закончились, см. ниже) или произойдёт сбой.
Иногда возникает искушение установить очень маленькое значение для request.timeout.ms, чтобы клиенты реагировали быстрее, даже если речь о сбое. На самом деле, это не лучшая идея. Тут нужно действовать очень осторожно, иначе можно только усугубить проблемы на стороне брокера и ухудшить производительность приложения.
Например, если брокер медленно обрабатывает входящие запросы и мы установим маленькое значение request.timeout.ms, нагрузка на брокер только возрастёт из-за повторных попыток в очереди. Производительность и без того была невысокой, а сейчас совсем упадёт.
Лучше оставить для request.timeout.ms 30 секунд, как по умолчанию. Если уменьшить это значение, по факту время обработки запросов на стороне сервера может только возрасти. Если таймауты возникают часто, может быть, стоит даже наоборот увеличить request.timeout.ms.
2. Неправильно понимаем повторные попытки продюсера и исключения, допускающие повторные попытки.
Мы надеемся, что при выполнении producer.send () записи успешно сохранятся в топике. В реальности по той или иной причине может произойти сбой запроса. Иногда этот сбой временный, пройдёт сам и можно делать повторные попытки, а иногда постоянный и нужно что-то исправить, прежде чем отправлять запросы снова.
Например, при постепенном обновлении кластера могут возникать исключения, которые пройдут сами:
Если не настроить повторные попытки правильно, все эти исключения будут считаться ошибками и могут привести к нарушению работы и потере сообщений.
Существует несколько конфигураций продюсера, связанных с повторными попытками:
retries. Как видно по названию, это количество повторных попыток. Значение по умолчанию для продюсера — INT_MAX, самое большое целое значение в вашем языке, но можно установить любое число от 0 до INT_MAX. Значение может быть очень большим, но это вовсе не значит, что клиент будет пытаться до бесконечности. На самом деле повторные попытки будут ограничены значением delivery.timeout.ms.
delivery.timeout.ms и linger.ms. Продюсеры могут записывать сообщения в одну партицию пакетами, чтобы оптимизировать этот процесс. Значение linger.ms показывает, сколько времени продюсер будет медлить (linger) в ожидании сообщений для пакета. delivery.timeout.ms — это максимальное время, за которое продюсер должен доставить запись (по умолчанию — две минуты). Оно не должно быть меньше, чем linger.ms плюс request.timeout.ms.
retry.backoff.ms. При повторной попытке продюсер подождёт, прежде чем отправить запрос повторно. Если задать для этого параметра слишком маленькое значение, временное исключение не успеет устраниться и произойдёт сбой.
request.timeout.ms. Мы уже объясняли, почему лучше оставить для request.timeout.ms 30 секунд, как по умолчанию.
max.in.flight.requests.per.connection и enable.idempotence: max.in.flight.requests.per.connection определяет общее число неподтверждённых запросов для одного клиента при сохранении гарантированной очерёдности. Если для enable.idempotence задано значение true, только одна копия сообщения будет записана в топик; если false, сообщения могут повторяться.
Почему эти параметры важны? Если вкратце, они могут влиять на порядок сообщений в топике, особенно когда включены повторные попытки, max.in.flight.requests.per.connection больше 1, а enable.idempotence=false. Представим, что продюсер отправляет два запроса с сообщениями для одной партиции в брокере. Первый пакет доставить не удалось и продюсер пытается отправить его заново, а второй пакет успешно дошёл. В итоге второй пакет с сообщениями опередит первый. Если вам важен порядок сообщений, но при этом вы хотите использовать повторные попытки, не задавайте для max.in.flight.requests.per.connection значение больше 1, а для enable.idempotence=false.
acks. Если вы хотите полностью отключить повторные попытки, задайте для этого параметра значение 0. В этом случае продюсер отправит запрос и не будет волноваться о том, дошёл он или нет. (Больше о гарантиях доставки см. в статье о пяти вещах, которые должен знать любой, кто работает с Kafka.) Если повторные попытки нужны, у acks не должно быть значения 0.
Определитесь с этим решением, прежде чем настраивать параметры конфигурации продюсера. Если вам нужны повторные попытки, установите для параметра retries значение больше 1, а для параметра acks — 1 или all. Вы хотите, чтобы продюсер не тратил время на повторную отправку и выдавал исключение в случае любых проблем? Отключите повторные попытки, установив retries=0. (В этом случае вы всё равно сможете сами обрабатывать исключения в коде клиента.)
До сих пор мы говорили о проблемах при взаимодействии клиента с кластером, а что же сам кластер? Какие проблемы могут возникать с брокерами и как решать эти проблемы?
3. Не отслеживаем ключевые метрики брокера
Брокеры Kafka предоставляют очень полезные метрики JMX для оценки общей работоспособности кластера. К сожалению, иногда администраторы кластера упускают эту ценную информацию.
Одни метрики очевидны и понятны, с другими не все так просто. Если вы пока не знаете с чего начать, вот вам пять самых полезных метрик:
kafka.server: type=ReplicaManager, name=UnderReplicatedPartitions. У каждой партиции есть реплики, которые хранятся на разных брокерах в кластере. Данные записываются на ведущий брокер и реплицируются по фолловерам. Эта метрика считает партиции, для которых ещё не создано нужное число реплик. Любое значение этой метрики указывает на сбой работоспособности, потому что данные реплицируются не так, как нам хотелось бы.
kafka.network: type=SocketServer, name=NetworkProcessorAvgIdlePercent. Эта метрика показывает процент свободных сетевых потоков, которые выполняют обработку. Все запросы Kafka проходят через сетевые потоки, так что это важная метрика. 0 — все ресурсы недоступны, а 1 — все ресурсы доступны. Нормальным будет значение выше 30%, чтобы ресурсы кластера не находились на пределе постоянно.
kafka.server: type=KafkaRequestHandlerPool, name=RequestHandlerAvgIdlePercent. Обработчик запроса берет запрос из очереди, обрабатывает его и выводит ответ в очередь ответов. Эта метрика показывает процент свободных потоков для обработки запросов в брокерах. 0 — потоки обработки запросов полностью недоступны, 1 — все доступны. Это значение тоже должно быть выше 30%.
kafka.network: type=RequestChannel, name=RequestQueueSize. Общее количество запросов в очереди. Чем больше это число, тем длиннее очередь, так что мы надеемся на небольшое значение. Эте метрику можно использовать вместе с NetworkProcessorAvgIdlePercent и RequestHandlerAvgIdlePercent, чтобы получить хорошее представление о загруженности всего конвейера запросов Kafka.
kafka.network: type=RequestMetrics, name=TotalTimeMs, request={Produce|FetchConsumer|FetchFollower}. Сколько времени уходит на определённый тип запроса (включая время на отправку). Это серия метрик для каждого типа запросов: produce, fetchConsumer и fetchFollower. Хорошая метрика для оценки задержки в системе. Чем ниже значение, тем здоровее кластер.
Задержка запросов в брокере (как быстро брокер обрабатывает запросы) многое говорит о работоспособности кластера. Можно, конечно, отслеживать работоспособность запросов с помощью логов запросов, но они слишком подробные и сильно влияют на производительность. Метрики в этом плане гораздо лучше. Нельзя просто взять и проигнорировать их. Будут последствия — например, замедлится обработка запросов.
Если вы не знали о метриках JMX или не уделяли им должного внимания, самое время взяться за них. Если вы знаете, что они существуют, — это уже полдела. Теперь начните принимать меры и повышать работоспособность и отказоустойчивость кластера. Приведённые здесь метрики — лишь верхушка айсберга. Рекомендуем изучить дополнительные ресурсы:
Полный список метрик для брокера
Стеки мониторинга JMX для Confluent Platform
Мониторинг потоков событий: интеграция Confluent с Prometheus и Grafana
Обзор наблюдаемости и настройка Confluent Cloud
Вы, наверное, думаете: «Зачем мне метрики брокера, если какой-нибудь неавторизованный клиент будет нарушать работу кластера, а я этого даже не увижу!» Это и правда важно, поэтому существует KIP 714, чтобы улучшить наблюдаемость клиента в брокере. Здорово же?
Вас пугает мысль о мониторинге всех этих метрик? Confluent Cloud, полностью управляемый сервис Kafka, сделает всё за вас. Метрики задержки, использования и загрузки предоставляются по умолчанию для выделенных кластеров.
4. Создаём слишком много партиций
Партиции в Kafka отвечают за параллелизм — конечно, с учётом пропускной способности клиентов и других факторов. Чтобы увеличить общую пропускную способность, нужно создать побольше партиций. Логично? Не совсем. Много партиций тоже не всегда хорошо:
Больше обработчиков файлов, чем поддерживается операционной системой. Когда в топик поступает сообщение, оно сохраняется в партиции. По сути, данные добавляются в файл сегмента лога (подробности ниже), а соответствующий файл индексов обновляется. Обработчик файла есть и у файла с данными, и у файла индексов. Допустим, у нас есть 10 топиков, в каждом по 50 партиций. Всего получается 2000 обработчиков файлов. Linux, например, разрешает не больше 1024 дескрипторов на процесс.
Больше рисков, что партиции будут недоступны при сбое брокера. В идеальном отказоустойчивом кластере каждая партиция несколько раз реплицируется по брокерам в кластере. Один брокер хранит ведущую реплику, остальные реплики считаются фолловерами. В случае сбоя брокера хранящиеся на нем партиции с ведущими репликами будут какое-то время недоступны, пока контроллер (ещё один брокер в кластере) не выберет новые ведущие реплики из фолловеров.
Сценариев может быть три: запланированная остановка, незапланированный сбой и сбой контроллера. В случае запланированной остановки новый ведущий брокер можно выбрать заранее и простой будет коротким. При незапланированном сбое все партиции с ведущим репликами на отвалившемся брокере будут недоступны, пока контроллер выбирает ведущие реплики. Если сбой произошёл на контроллере, всё становится ещё хуже — нужно ждать, пока новый контроллер будет выбран и инициализирован, а для этого он должен считать метаданные для каждой партиции в ZooKeeper. В двух последних сценариях время, которое партиции будут недоступны, напрямую зависит от количества партиций в кластере. Чем больше партиций, тем дольше простой.
Увеличение общей задержки. Сообщения в топике доступны консьюмерам только после фиксации на всех синхронизированных репликах. Чем больше партиций, тем больше пропускной способности требуется для их репликации. Из-за лишних задержек на этом шаге увеличивается время между моментом, когда продюсер записывает сообщение, и моментом, когда консьюмер сможет его прочитать.ы
Кроме того, если вы используете Kafka с ZooKeeper, там есть лимит на партиции — примерно 4000 на брокер и 200 000 на кластер. С отказом от ZooKeeper (в результате реализации KIP-500) нас ждут большие изменения. Кластер больше не будет хранить метаданные партиций и брокеров в ZooKeeper, так что масштабируемость серьёзно возрастёт. Как показывают тесты, с новым контроллером метаданных на основе кворума партиций может быть хоть 2 миллиона.
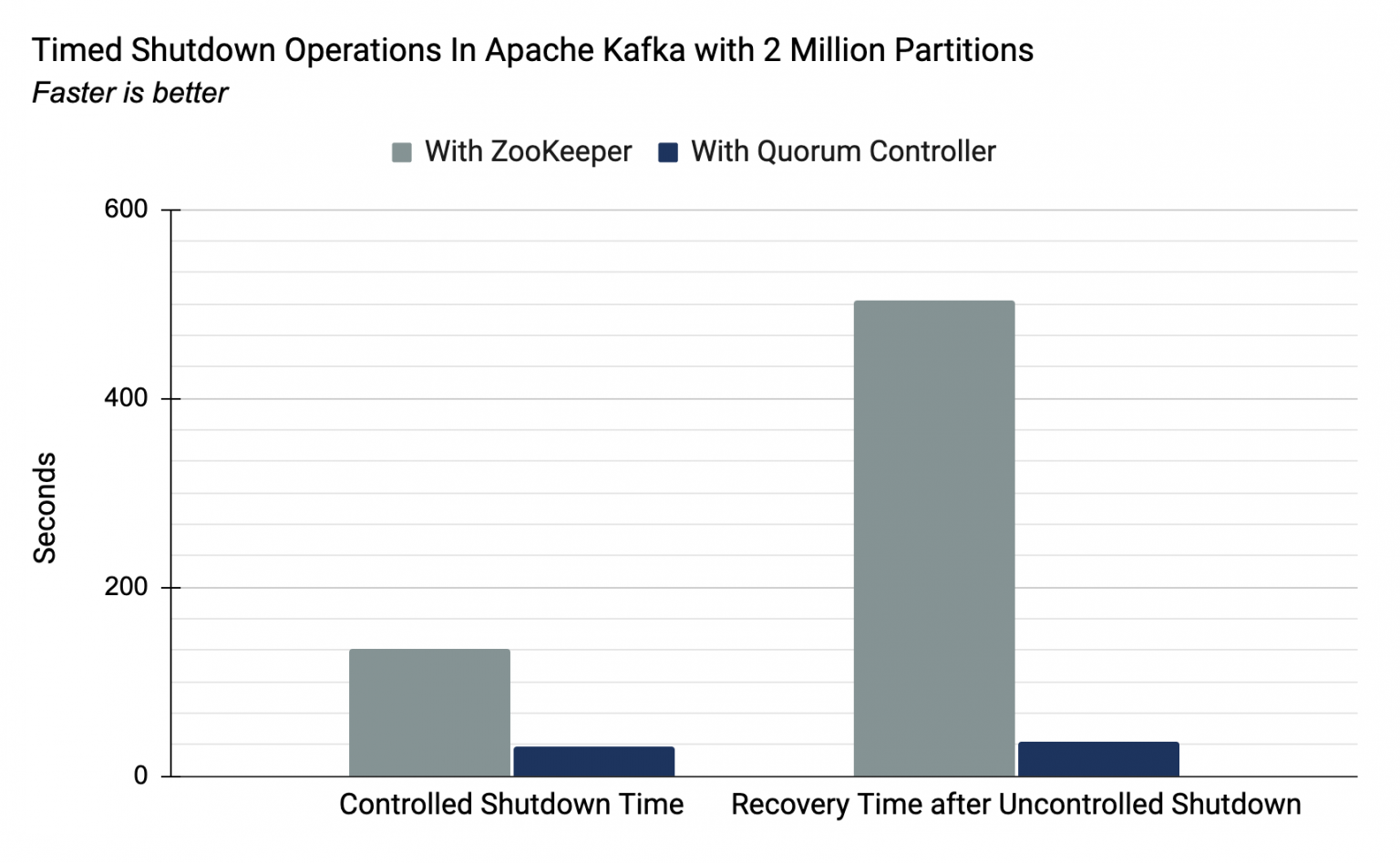
Как избежать всех этих проблем? Тщательно всё обдумайте и найдите баланс, чтобы партиций было достаточно для поддержания хорошей пропускной способности, но при этом не слишком много. Количество партиций в топике можно менять, но обычно это нежелательно, потому что изменится порядок сообщений.
Сколько партиций должно быть в топике?
Для расчёта есть отличная формула. Создавая топик в кластере Kafka, нужно первым делом оценить желаемую пропускную способность (t) в МБ/с. Затем прикиньте возможную пропускную способность для одной партиции (p). На неё влияет конфигурация продюсера, но обычно это где-то десятки МБ/с. Наконец, определите пропускную способность консьюмера ©. Она зависит от приложения и её придётся измерить самостоятельно. Партиций в топике должно быть как минимум max (t/p, t/c). Если, допустим, вы стремитесь к пропускной способности 250 МБ/с, а пропускная способность продюсера и консьюмера — 50 и 25 МБ/с соответственно, в топике должно быть не меньше max (250/50, 250/25) = max (5, 10) = 10.
5. Устанавливаем слишком маленькое значение segment.ms
Мы записываем сообщения в партиции, но если говорить о хранении фактических байтов на диске, Kafka разделяет каждую партицию на сегменты. Сегмент представляет собой файл с данными на диске. Нужно понимать, как работают и настраиваются сегменты, чтобы поддерживать оптимальную работу брокеров.
Когда сообщения записывают в топик, данные просто добавляются в последний открытый файл сегмента лога в партиции, куда направлено сообщение. Пока файл сегмента открыт, он не рассматривается как кандидат на удаление или сжатие. По умолчанию файлы сегментов лога остаются открытыми до заполнения (1 ГБ). Это значение указывается параметром конфигурации segment.bytes на уровне топика. Можно указать на уровне топика значение segment.ms, чтобы сегменты принудительно закрывались через этот период времени.
Иногда пользователи задают для segment.ms очень маленькое значение, чтобы чаще запускать сжатие или удаление и тем самым экономить память. Если период segment.ms будет слишком коротким (по умолчанию — 7 дней), в кластере будет создаваться очень много маленьких файлов сегмента. В результате будет возникать исключение, связанное с нехваткой памяти или слишком большим количеством открытых файлов. Много маленьких или пустых файлов сегмента повлияют на производительность консьюмеров топика. При запросе fetch консьюмеры получают данные максимум из одного сегмента партиции. Если сегменты очень маленькие, консьюмеры получат мало данных за раз, а значит придётся сделать больше запросов к брокеру.
Чтобы избежать этой проблемы, нужно как следует продумать конфигурацию при создании и администрировании топиков в кластере. Если для параметра segment.ms вы задали маленькое значение, нужно как можно скорее вернуть значение по умолчанию. Изменения не повлияют на уже созданные сегменты.
Заключение
Советы по предотвращению типичных ошибок:
Не задавайте слишком маленькое значение для параметра request.timeout.ms.
Просмотрите настройки повторных попыток и исключения. допускающие повторные попытки, когда будете в следующий раз писать клиент продюсера.
Отслеживайте метрики брокера и работоспособность кластера.
Следите за количеством партиций, особенно при создании новых топиков.
Не задавайте слишком маленькое значение для параметра segment.ms.
Используйте полностью управляемое решение (например, Confluent Cloud), чтобы уберечься от ошибок, связанных с брокерами. Сосредоточитесь на написании клиентских приложений, а не обслуживании брокеров.
Как еще предотвратить ошибки в Kafka
Приглашаем вас на курсы Слёрма по Apache Kafka, которые основаны на опыте спикеров, их кейсах и ошибках.
— Курс «Apache Kafka База»: познакомимся с технологией, научимся настраивать распределённый отказоустойчивый кластер, отслеживать метрики, равномерно распределять нагрузку.
— Видеокурс «Apache Kafka для разработчиков». Это углублённый интенсив с практикой на Java или Golang и платформой Spring+Docker+Postgres. Интенсив даёт понимание, как организовать работу микросервисов и повысить общую надежность системы.
Ждем вас!
