3D Pose Estimation объектов фиксированной геометрии для складских роботов

«Позабыты хлопоты, остановлен бег. Вкалывают роботы, а не человек» — соблазн автоматизировать физический труд знаком нам ещё с «Приключений Электроника». И точно актуален на складах, особенно в период пиковой сезонности. И тогда на помощь приходят роботы, забирая на себя большую часть задач.
Привет, меня зовут Александр Тимофеев-Каракозов, я Senior ML/CV Engineer в Яндекс Роботикс. Я разрабатываю архитектуру ML-решений, обучаю нейросети для роботов и настраиваю MLOps, чтобы модели быстро адаптировались к новым складам и задачам. В этой статье я расскажу вам про нейросетевую жизнь складских роботов Яндекса и покажу, как один из них решает задачу 3D-локализации объектов в фиксированной геометрии.
Какие роботы есть на наших складах
Давайте начнём с того, что посмотрим на жизненный цикл товара на складе:

Наш робопарк насчитывает несколько видов складских роботов:
АМР (автономный мобильный робот) — робот-извозчик, на который кладут товары, и он их возит.
Spectro — робот-инвентаризатор, который гоняет по складу и проводит инвентаризацию.
Dilectus — робот-тотоносец (тоты — наше название коробок), который занимается перемещением товаров по всему складу.

А ещё у нас есть роборука с искусственным интеллектом — Пикер. Она собирает и упаковывает товары. О ней мы рассказывали в отдельной статье. И ещё есть роборука побольше — Депаллетайзер.
Для сегодняшней темы возьмём в качестве примера робота Dilectus. Операции, которые он выполняет на складе, в среднем составляют от 30 до 35% от общего количества операций, поэтому робот является важной частью автоматизации процессов.
Dilectus работает по концепции «товар к человеку». Товары размещаются в коробках, робот находит тоты с нужными товарами, берёт их со стеллажей в зоне хранения, перевозит в зону комплектации. Затем пустой тот при необходимости возвращается на стеллаж.
Dilectus может работать внутри склада автономно, то есть без людей. Он оснащён 3D-лидаром, который позволяет позиционироваться на складе, а также предотвращать столкновения. Также у робота есть механизм захвата — граббер, который позволяет снимать с полок не только ближайшие коробки, но и те, что лежат за ними. Поэтому на складе удастся разместить больше товаров без беспокойства, что робот дотянется не до всех коробок. А ещё он может перевозить тоты в себе — для этого в нём есть 5 слотов. Длина Dilectus — 2,4 м, ширина — 1,2 м, а высота — 4,1 м.

Робот управляется с помощью ПО, которое получает задания из единой умной системы управления роботами (Robot Management System, или RMS). Робот при знакомстве со складом запоминает, где и какой тот находится — он считывает коробки по специальным QR-кодам.
Затем он начинает с ними работать: система направляет ему задание, какой тот нужно взять и куда отвезти. Первый пайплайн детектирует с помощью сегментации, наклеенной на полку дата-матрицы, положение робота относительно полки и калибрует его для дальнейших действий. Второй пайплайн помогает взять коробку с полки. Он определяет 3D-положение коробки и отдаёт эти данные, чтобы процессы могли определить, как её захватить. А теперь давайте разберёмся, как ставить роботу подобные задачи.
Формулируем задачу и ищем решение
Для начала сформулируем задачу: у нас есть картинки, и мы должны найти 3D-положение тота в системе координат камеры в виде восьми трёхмерных точек. Звучит как стандартная задача 3D-локализации (её ещё называют 6D Pose Estimation). Но, как обычно, есть условия:
Ошибка не должна превышать 1 см. Общий запас надёжности захвата коробок латчами (лапками робота) — около 2 см, и по каждой стороне мы можем ошибиться не более чем на 1 см.
Скорость обработки на Nvidia Jetson: 10 FPS. Такое значение выбрано с целью уложиться в скоростные ограничения всем пайплайном, а это не только нейросеть, но и обработка потоков данных с робота, локализация и т. д.
Single-view. Опция Multi-view для нас, к сожалению, недоступна. То есть мы можем «посмотреть на коробку» один раз, а не как при Multi-view рассмотреть её с разных ракурсов, чтобы точнее определить локализацию.
Но перед тем как решать нашу задачу, давайте поймём, как оценивать наше решение. У нас стандартные метрики:
Средняя квадратичная ошибка — возведённая в квадрат усреднённая разница между предсказанными и истинными значениями. Это стандартная метрика, которая показывает, насколько сильно ошибается модель. Чем меньше значение — тем лучше. Так как она квадратичная, все выбросы (очень большие ошибки) будут учитываться в квадрате, то есть делать очень большой вклад в ошибку, и мы увидим это по метрике.
Аналог accuracy в терминах максимального отклонения. Другими словами, это доля предсказаний, у которых максимальное отклонение каждой из точек не больше определённого порога. Чем больше доля — тем лучше, то есть если метрика равна 1.0 (100% точности), это значит, что все предсказания укладываются в диапазон 1 см.

Всё это мы считаем по трёхмерным координатам XYZ в системе координат камеры.
Условия есть, метрики тоже — пора решить нашу задачу! Для начала мы уходим по таргетам в 2D. Таргет — это то, что мы хотим предсказать с помощью модели, и сначала мы хотели предсказывать в 3D (XYZ). Но оказалось, что в 2D (XY) значительно проще — разметка в 3D делается на ограниченном множестве данных и она очень трудозатратная. К тому же мы используем краудсорсинг, чтобы размечать большое количество данных, а его в 3D сделать нельзя.
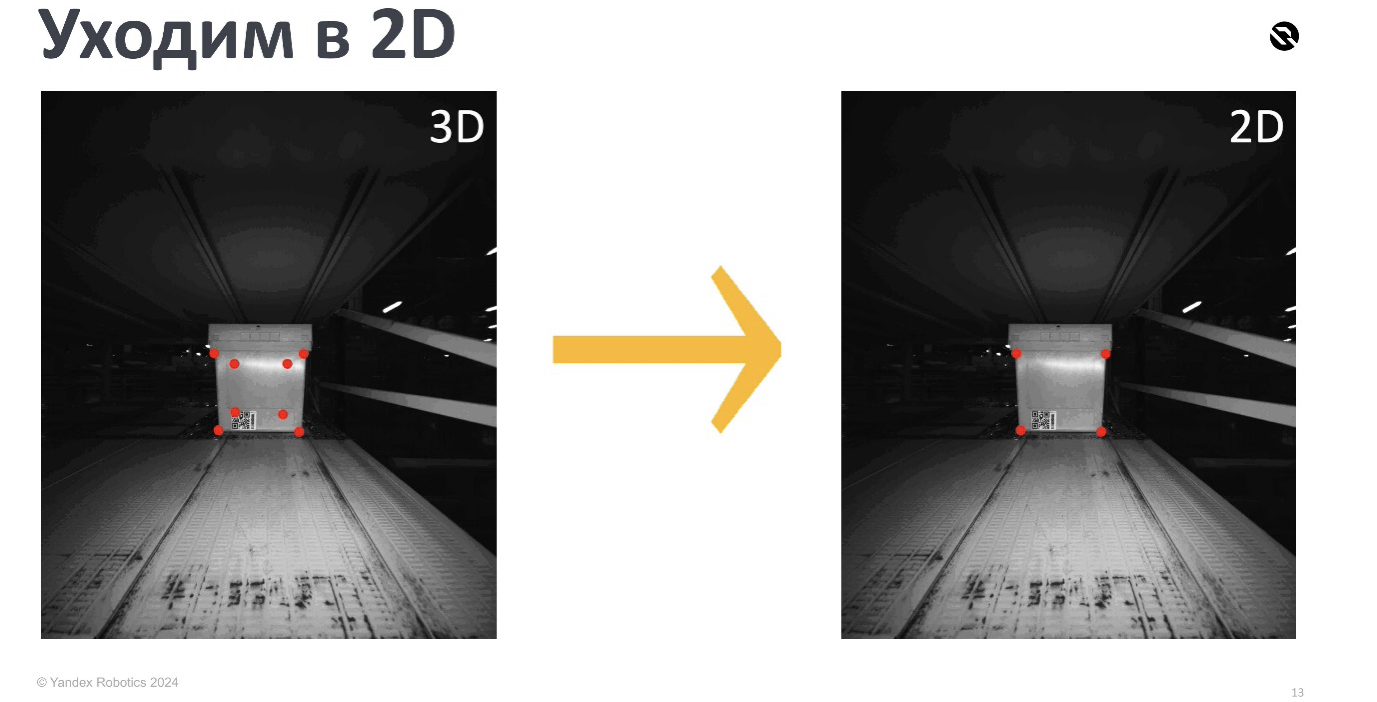
Возьмём переднюю грань нашей коробочки. Так как коробка в целевом кейсе всегда стоит лицом к камере, то это оправдано. Тут возникает вопрос — в 2D перешли, а как вернуться обратно? Как, зная четыре двухмерные координаты, получить восемь трёхмерных в системе координат камеры?
Методы, на самом деле, есть, но для них потребуется немного математики — нужно решить оптимизационную задачу. Нам известны двухмерные координаты точек, а также эти точки в какой-то трёхмерной системе координат и параметры камеры. Надо найти поворот и смещение проекции.

На самом деле, это задача Perspective-n-Point, которая неплохо решается как раз, когда есть хотя бы четыре точки.

Но самое главное, что, зная параметры проекции, мы можем использовать их, чтобы преобразовать систему координат коробки в систему координат камеры. Таким образом, для заранее полученных точек, которые можно просто снять в двухмерной системе координат, мы можем найти их проекции в трёхмерной системе координат камеры. А это значит, что мы решили задачу и проблему перехода из 2D в 3D.
С учётом всего сказанного, наш пайплайн будет выглядеть достаточно просто:

Сначала находим двухмерные точки передней грани, потом с помощью Perspective-n-Point находим итоговые трёхмерные точки. На всякий случай, тоже сформулируем задачу в 2D.

Для каждой коробки надо найти четыре угловые координаты передней грани, сделать это быстро и, самое главное, точно. Мы пробовали четыре разных подхода:

Мы начинали с самого простого — с метода двух моделей. Сначала детектировали наши коробки, потом каждую прогоняли через Keypoints Estimator и получали искомые точки. Потом пробовали решить в лоб одной моделью (E2E-подход). Далее вообще переосмыслили таргеты — решили предсказывать не точки, а линии. А в конце свернули в сегментацию.
Расставляем все точки над тотом: нейросетевые подходы
Путь двух моделей
Мы начинали с двух моделей: YOLOX — детектор объектов и TransPose — детектор ключевых точек.

Простейший подход — берём детектор, находим передние грани коробки, каждую из них прогоняем через Keypoints Estimator и находим четыре нужные точки. Keypoints Estimator мы брали в виде TransPose — это небольшой трансформер с энкодером в виде ResNet-18.
Плюсы:
Высокое разрешение для вычисления ключевых точек. Количество информации на пиксель больше, чем при Е2Е-подходах.
Single task для ключевых точек. Мы сначала нашли область, где наша коробка. И эту область подаём на вычисление точек, а алгоритм, который их вычисляет, занимается только одной задачей — непосредственно вычислением точек.
Декомпозиция ошибки. Мы можем отдельно улучшать как детекцию коробок, так и локализацию точек.
Самое главное, что тут Keypoints Estimator смотрит не на всю картинку, а только на ту область, где присутствует наша коробка. Именно поэтому количество информации на пиксель здесь больше, чем в остальных методах. Приятно то, что задача декомпозируется, но это ведёт и к минусам.
Минусы:
Детектор ошибается сильнее, чем при E2E-решении. На практике мы заметили, что детектор без дополнительных задач в виде определения ключевых точек чаще предсказывает фантомные коробки, которых нет на фотке. И на этих фантомных коробках локализатор точек находит какие-то точки. Такое предсказание — плохое предсказание, ведь коробки-то нет :)
Сложнее поддерживать. В этом методе используются две модели, а это в 2 раза больше работы.
Не E2E. А нам бы хотелось решать задачу только одной моделью.
Чувствительность к нечёткой разметке. Если люди разметили точки с ошибками, то модели будет тяжелее обучаться.
Мы решили попробовать другие подходы, и заодно сравнить Е2Е-решения с текущим, так как хотели избавиться от его минусов.
Путь E2E
Потом мы попробовали решить задачу одной моделью YOLOX-Pose — так начался путь E2E.

YOLOX-Pose отличается от YOLOX только в реализации головной части, которая выполняет основную задачу — локализацию объектов:

YOLOX — это anchor-free детектор, а значит, якорем мы можем считать каждую точку на фича-мапе. У YOLOX три головы: классификация предсказывает классы для каждой якорной точки, регрессия предсказывает смещение bounding box и его размеры, а объектность предсказывает, что вообще какой-то объект есть.
В YOLOX-Pose фичи отводятся ещё на решение задачи Pose Estimation. Одна голова предсказывает регрессию, а вторая — объектность. Она говорит, что точка существует (ключевая точка позы), а регрессия предсказывает смещение x и y для каждой якорной точки в сторону соответствующих ключевых точек позы.
Также мы добавили Refinement-модуль, который уточняет предсказания наших keypoints.

Refinement-модуль работает с более высокоразмерной фича-мапой и такую же отдаёт. То есть у неё чаще расставлены якорные точки, и она предсказывает смещение до ближайших таргетов точек. То есть суть в том, что головы делают первое приближённое предсказание, а Refinement-модуль доуточняет его, чтобы предсказание получилось лучше.
Еще Refinement-модуль предсказывает смещение до обезличенных точек. То есть он не отличает левую и верхнюю от правой и нижней, например — простой трюк, чтобы просто уточнить наше предсказание. Выглядит это так:

В YOLOX мы выбираем якорные точки так, чтобы их было просто регрессировать в центр объекта. В YOLOX-Pose мы также выбираем якорную точку так, чтобы было проще регрессировать в центр объекта, а также в ключевые отметки поз. Если посмотреть на нашу геометрию, то опять мы выбираем якорные точки ближе к центру. Получается, что мы в центр будем регрессировать легко, потому что просто ближе находимся, а в ключевые точки регрессировать сложнее. Refinement-модуль как раз решает эту проблему.

Мы берём предсказание от YOLOX-Pose для ключевых точек и якорные точки из Refinement-модуля. Они также предсказывают смещение до ближайшей ключевой точки.
Плюсы:
E2E. То есть у нас одна модель, и это хорошо.
Легко поддерживать, так как одна модель = только одна головная боль.
Минусы:
Малое разрешение для вычисления ключевых точек. Теперь мы смотрим на картинку и сразу делаем предсказания, предварительно изменив размер картинки, чтобы скормить её нейросети. Поэтому мы уменьшаем количество информации на пиксель в несколько раз, и в итоге появляется гарантированное отклонение.
Multitask сложнее обучать, так как одна модель делает сразу много всего.
Чувствителен к нечёткой разметке, то есть всё ещё зависит от ошибок в разметке, сделанных людьми.
По метрикам получается так:

Даже с Refinement-модулем E2E-подход отстаёт от подхода с двумя моделями, но это, наверное, логично. Однако если применить хак в виде Test-Time Augmentation, то метрики мы пробиваем и при этом даже укладываемся в наши скоростные ограничения (на Jetson, напомню).
Test-Time Augmentation — это метод, который используется для улучшения производительности и стабильности моделей машинного обучения. Он включает применение случайных преобразований к входным данным во время этапа тестирования или оценки модели, что позволяет получить несколько разных представлений одного и того же объекта.
Результаты, полученные из каждого преобразованного изображения, объединяются для формирования окончательного результата прогнозирования: например, с помощью усреднения ответов моделей или голосования моделей за то или иное предсказание. Это помогает обобщить модель и уменьшить переобучение по тренировочному набору данных. В свою очередь, это может улучшить производительность на новых невидимых данных.
Дальше мы попробовали переосмыслить таргет: то есть не тюнить архитектуру, а просто посмотреть на топ проблем, которые вообще у нас есть. Оказалось, что самая большая из них — это проблема окклюзии точек, когда какие-то точки не видно, какие-то сильно засвечены.

Если не видно двух точек, итоговую геометрию с помощью Perspective-n-Point мы найти, скорее всего, не сможем. А если не видно одной точки, то позу оценить можно. На самом деле Perspective-n-Point умеет решать задачу, даже если три точки известны. Однако получается сильно неустойчивое к шуму решение, и нам не очень это приятно.
Путь линий
Немного поразмыслив, мы решили предсказывать линии, которые пересекаются в необходимых нам точках. Для этого мы немножко модернизировали YOLOX (я обозначил его как YOLOX-Lines).

Когда мы находим четыре линии для каждой нашей коробки, мы находим и их четыре угловые координаты в виде их пересечения. От классического YOLOX это отличается только головой детектора.

Мы отводим фичи, чтобы предсказывать четыре линии нашей коробки. Важно сказать, что линии можно параметризовать по-разному. Мы их представляем как точку на прямой и угол.
На самом деле даже угол можно параметризовать по-разному, поэтому вы видите здесь параметр Angle dim. Скажем, можно предсказывать градусы или представить угол как вектор, например, решая задачу классификации на сглаженных классах. В нашем случае Angle dim равен 180 градусам. В итоге получается так:

Мы также предсказываем смещение в центр объекта и в центральные точки на видимых частях каждой из граней из четырёх линий.
Вы можете заметить, что тут нет Refinement-модуля. Но это не потому, что он здесь не сработает, а потому что мы просто не успели его добавить, так как у нас был дедлайн на эксперименты, а мы уже нашли решение, которое в перспективе сработает лучше.
Плюсы:
Почти E2E. То есть нужно, как и в предыдущем методе, просто найти ещё пересечения точек по прямым, что очень просто.
Легко поддерживать, так как это одна модель.
Работает, даже если видно хотя бы две точки.
Минусы:
Малое разрешение для вычисления ключевых точек. Вся информация подаётся на пиксель меньше, чем в первом методе.
Одна шумная линия → две шумные точки. Если мы предсказали линию плохо, то две точки тоже будут предсказаны плохо.
Нужно много всего предсказывать. Этот multitask ещё сложнее, чем в предыдущем подходе, и его надо оптимизировать.
По метрикам получается негусто:

Но, как ни странно, выбросов в виде кривых поз стало меньше, потому что кривые позы очень часто соответствовали окклюзии точек и квадратичная ошибка у нас уменьшилась.
Путь сегментации
Тут вообще всё просто. С помощью инстанс-сегментатора мы находим маски для каждой передней грани коробки, а потом каждую маску постпроцессим в точке.

Модель инстанс-сегментации на базе YOLOX выглядит так.

Опять берутся свитчи с более высокоразмерной фича-мапой, утягиваются в подсеть ProtoNet, которая состоит из свёрточных слоёв и одного апскейла. Эта штука предсказывает прототипы — результат предсказания масок и кандидаты для матчинга с результатами детекции.
На самом деле все эти YOLO-подобные инстанс-сегментаторы (YOLOv8, YOLOv5 и пр.) выглядят примерно одинаково. Для каждой передней грани предсказываются только маски, и потом они постпроцессятся в точки. Возникает вопрос:, а как постпроцессить маски обратно в точки?

Один из простых подходов: берём маску и какой-нибудь алгоритм Edge Detection, то есть детектируем граничные точки нашей маски. Например, можно взять алгоритм Canny из OpenCV. Далее по этим граничным точкам с помощью алгоритма Lines Detection предсказываем линии. Например, с помощью алгоритма Huff из OpenCV, который называется Hough Line. Потом мы кластеризуем эти линии, например, применяя K-means. Теперь мы понимаем, где какая линия, фитим наши лучи, опять получаем, как в предыдущем подходе, таргеты, линии. Их пересечение даёт нам искомые точки.
Мы используем следующий простой, но ёмкий подход:
Берём маску ровно одной грани (то есть одного тота).
Применяем какой-нибудь алгоритм Edge Detection. Например, сейчас мы используем обычный алгоритм Canny из OpenCV. В итоге мы получаем граничные точки нашей маски.
Далее, когда у нас есть граничные точки, мы можем их «выровнять» путем применения алгоритма детекции линий. Например, мы используем алгоритм Хаффа — Hough Line из той же OpenCV. Тут мы получаем линии, которые аппроксимируют наши граничные точки, что помогает отфильтровать выбросы в точках в виде кривых участков границ.
Полученное множество линий мы можем кластеризовать по углу и их соответствующим центрам (центрам линий). Это даст нам понимание, какие линии относятся, например, к левой границе грани, а какие — к правой, нижней или верхней. Кстати, кластеризацию мы проводим с помощью KMeans с небольшими эвристиками.
В итоге для каждого кластера линий мы можем зафитить прямые. Это позволяют сделать FitLines из OpenCV, которые аппроксимируют наше множество линий. И для каждой грани нашей маски мы находим прямые, которые далее обрабатываем по аналогии с подходом из «пути двух линий».

Плюсы:
Легко поддерживать. Этот метод состоит всего из одной модели — не нужно сильно вкладываться в ресурсы.
Сегментация наименее чувствительна к нечёткой разметке по сравнению с остальными методами. Если, допустим, мы ошиблись на 1 см в разметке — это критично, а для маски не так фатально — это просто сделает её чуть хуже, но пересекаться с правильной она будет всё равно по большей площади.
Минусы:
Сегментация делает модель тяжелее остальных решений.
Сложный постпроцессинг. В алгоритме перевода маски в точки много шагов, на практике он выглядит тяжело.
Не совсем Е2Е, так как мы предсказываем не сразу точки, а маску. Потом нужно ещё многое сделать, чтобы перейти в точки. Но при этом всё делает одна модель.
И снова предлагаю посмотреть на замеры. В FPS вписались, квадратичная ошибка упала, а самое главное — доля ошибок до 1 см у нас выросла почти на 3% — это отлично.

Само собой, мы выбрали этот путь. Наш итоговый пайплайн выглядит так: сначала с помощью instance segmentation модели YOLOX-Seg мы находим маски для каждой коробки, потом из масок делаем 2D-точки, а дальше с помощью решения задачи PnP из 2D-точек делаем 3D и таким образом решаем нашу задачу.

Этап Active Learning
Мы разобрались, как обучать модель и как получать итоговые 3D-координаты наших объектов. Но что делать с данными?
В самом начале наша выборка для обучения насчитывала не больше 2000 изображений — этого было мало и хотелось как-то исправить. Ведь данные, на которых мы учимся, — это один из самых главных факторов успеха всей нашей модели.
Мы задались вопросами:
Где найти данные для последующего обучения?
Какие данные отобрать из всего потока?
Как все эти действия вообще автоматизировать?
На эти вопросы нам помогает ответить активное обучение (Active Learning, или AL). Вкратце — это метод постоянного дообучения моделей с помощью майнинга сложных примеров. Благодаря AL мы можем собирать данные так, чтобы получить максимальный профит в последующем обучении.
Active Learning хорошо ложится на кейс, когда у вас много моделей, которые нужно поддерживать и дообучать. Однако есть нюанс: пайплайн AL, как правило, автоматический, поэтому вряд ли получится добиться качества лучше, чем если бы мы исследовали модель руками, акцентируя внимание на неявные фичи.

У нас катается много роботов, и они сыпят логи, в которых есть какие-то предсказания для каждой из моделей. По этим предсказаниям мы отбираем подозрительные семплы (изображения и предсказания модели), которые можно описать как примеры, где модель неуверенно себя чувствует. Всё это летит в базу данных или облачное хранилище.
В кейсе робототехники нам приходится сильно подчищать данные, так как наша среда статична. Каждый день мы видим практически одно и то же и работаем с дубликатами и очень похожими изображениями. Мы чистим наши датасеты с помощью автоэнкодера, который может опознать сильно похожие друг на друга изображения. Фильтровать дубликаты очень важно, чтобы не просто как-то условно разбить выборку, но и при этом не разбить ваш Train Test Split (особенно, когда всё это автоматизировано).
Далее формируется батч, который отправляется на разметку. После этого мы смотрим в Sampler 1, у которого уже есть не только предсказание модели, но и разметка от наших асессоров. Sampler 1 работает в облаке, поэтому сюда можно подключать более тяжёлые алгоритмы, например использовать большие модели.
В итоге самые интересные данные попадают в датасет обучения. Мы готовим датасеты, выборки, параметры и начинаем обучать. Во время обучения мы тоже перебираем гиперпараметры, выбираем модели. Лучшая модель отправляется на CI/CD-пайплайн. Она проходит синхронное, асинхронное тестирование, считается онлайн, офлайн, отсматривается по интеграционным метрикам. В общем, проходит через все круги ада перед тем, как попасть в релиз :)
Но самое главное здесь — для чего мы это всё делали — это данные, которые мы отсюда получаем. Вся магия происходит в этих сэмплерах. Кстати, именно они отличают нашу модель 3D-локализации от остальных моделей в контексте процесса активного обучения.
Рассмотрим примеры сэмплеров для нашей задачи.
Сэмплинг на углах. Мы можем посмотреть на углы, которые образуют предсказания с осью X, и оценить их разницу. Если она больше определённого порога, то пример считается неуверенным. Аналогично можно сделать и с задней поверхностью после 3D-локализации точек, использовать самые разные эвристики, чтобы по предсказаниям понять, что с примером что-то не так.

PnP-сэмплинг. После 2D Key Point Estimation мы используем решение задачи Perspective-n-Point, чтобы найти трёхмерные координаты целевых углов.

У нас есть предсказания от 2D Key Point Estimation и предсказания после решения задачи Perspective-n-Point. Мы можем посмотреть, насколько сильно поехали предсказания после решения этой задачи.

Если значения поехали больше обычного — с примером что-то не так.
TTA-сэмплеры. Этот сэмплер более общий. Мы навешиваем Test-Time Augmentation, смотрим, как сильно меняется предсказание, и если изменения больше определённого порога — с примером что-то не то.

Эти сэмплеры распределяются так:

Лёгкие сэмплеры делаются непосредственно на роботах для того, чтобы не сильно просадить их перф и не увеличивать сетевую нагрузку. Тяжёлые в виде Test-Time Augmentation сэмплера или больших языковых моделей (да и вообще любых моделей) делаются в облаке.
С такой конфигурацией получается следующее:

То есть пока мы были заняты другими делами, наша модель нарастила себе качество на 20%. Но самое главное, ради чего мы всё это делали — мы намайнили себе выборку, которая в 10 раз больше предыдущей и состоит из очень сложных и интересных примеров.
И если мы говорим о метриках — не стоит забывать про бизнес.

Мы смотрим на метрику Success Rate, которая означает долю успешных заданий робота в определённом временном интервале. С июня метрика стала практически стопроцентной, что говорит о том, что задачу мы в целом уже решили, при этом — фоново.
Также не стоит забывать про визуализацию наших пайплайнов.

Визуализация — не только красивые картинки, которые можно показать руководителю, но и способ успешно дебажить нетривиальные кейсы. В случае Яндекса, например во время дежурства, когда к вам из соседней команды приходят коллеги и говорят, что у вас что-то не работает, вы можете мгновенно проверить с помощью визуализации, в вас ли дело, и убедиться, что всё хорошо.
В заключении хочется сделать пару выводов:
Не всегда задачу 3D-локализации объектов фиксированной геометрии стоит решать в 3D. Можно упростить и решать задачи в знакомом 2D-домене, и, в случае нечёткой разметки, использовать методы, которые её не боятся. В 2D их не так мало. Например, у нас сработала сегментация, задачу мы на самом деле уже плюс-минус решили.
Активное обучение — отличный помощник для поддержки модели в проде, который позволяет в равной степени наращивать качество нейросети и приспосабливаться к частой смене домена. Например, для вышеописанной задачи активное обучение помогло намайнить полезных данных, вследствие чего Success Rate вырос до 100%. Более того, мы внедрили AL почти во всех роботов и теперь просто пьём чай можем заниматься и другими, не менее интересными задачами.
