3-е место в отборочном этапе DataScienceGame 2018

Недавно закончился отборочный этап DataScienceGame2018, который проходил в формате kaggle InClass. DataScienceGame — это международное студенческое соревнование, которое проводится на ежегодной основе. Нашей команде удалось оказаться на 3 м месте среди более чем 100 команд и при этом НЕ пройти в финальный этап.
Командное взаимодействие
 На больших соревнованиях на kaggle команды обычно формируются по ходу из людей с близким скором по лидерборду (типичный пример команды), а поэтому представляют разные города и, зачастую, разные страны. Тут же по условиям соревнования каждая команда должна была состоять из 4х человек из одного учебного заведения (мы представляли МФТИ). А, значит, у большинства участников, как мне кажется, все обсуждения проходили в оффлайне. У нас, например, вся команда жила на одном этаже общежития, поэтому мы просто собирались по вечерам у кого-нибудь в комнате.
На больших соревнованиях на kaggle команды обычно формируются по ходу из людей с близким скором по лидерборду (типичный пример команды), а поэтому представляют разные города и, зачастую, разные страны. Тут же по условиям соревнования каждая команда должна была состоять из 4х человек из одного учебного заведения (мы представляли МФТИ). А, значит, у большинства участников, как мне кажется, все обсуждения проходили в оффлайне. У нас, например, вся команда жила на одном этаже общежития, поэтому мы просто собирались по вечерам у кого-нибудь в комнате.
Никакого разделения задач, планирования или тимбилдинга у нас не было. В начале соревнования мы просто садились в кружок, обсуждали, что можно сделать в будущем и не делали. Код при этом писал один человек, а остальные в это время просто смотрели и давали советы. Я не очень люблю писать код, поэтому мне такое взаимодействие нравилось, несмотря на то, что оно, очевидно, было не самым оптимальным. Но так как отборочный этап попадал ровно на сессию в университете, часть команды не могла уделять достаточно много времени и код мне все же пришлось писать самому.
Описание задачи
По данным из истории, предоставленным банком BNP, нужно было предсказать, заинтересуется ли пользователь некоторой ценной бумагой (Isin) на следующей неделе или нет. При этом «заинтересованность» определялась колонкой TradeStatus, которая описывала статус сделки и имела следующие уникальные значения:
- Сделка была совершена (то есть пользователь купил/продал бумагу)
- Пользователь посмотрел бумагу, но не совершил сделки
- Пользователь отложил бумагу для покупки/продажи в будущем
- Сделка не была совершена по техническим причинам
- Холдинг
Итак, если TradeStatus принимает значение 1)-4), то считается, что пользователь заинтересовался данной бумагой и не заинтересовался во всех остальных случаях. При этом пункт 4) обозначал, что строчка с данной сделкой фиктивная, и сделана для удобной отчетности. А именно, в конце каждого месяца проводилось сравнение состояния портфеля каждого пользователя с его состоянием месяц назад, и, если, например, у пользователя каким-то образом в портфеле количество определенной ценной бумаги увеличилось на 10к, то заводилась эта самая строчка с пометкой «покупка» и номиналом 10к. Строки с пометкой «холдинг» имели целевую переменную 0(пользователь не заинтересовался).
Если задуматься, то можно понять, что датасет собирался следующим образом: пользователи проявляли активность на сайте банка — просматривали/покупали бумаги, и все эти действия записывались в базу данных. Например, пользователь с id=15 решил отложить для покупки в будущем бумагу, имеющую id=7. Тут же в базе данных появлялась соответствующая строчка с таргетом 1(пользователь заинтересовался)
| Id пользователя | Id ценной бумаги | Тип сделки | Статус сделки | Дополнительные поля | Таргет |
|---|---|---|---|---|---|
| 15 | 7 | Покупка | Отложено на будущее | … | 1 |
Плюс к этому добавлялись ежемесячные записи со статусом холдинг и таргетом 0. Например, у пользователя 15 по каким-то причинам увеличилось количество акции 93(возможно, он купил ее на другом сайте), при этом сам он с данной бумагой на сайте BNP никак не взаимодействовал (не интересовался).
| Id пользователя | Id ценной бумаги | Тип сделки | Статус сделки | Дополнительные поля | Таргет |
|---|---|---|---|---|---|
| 15 | 93 | Покупка | Холдинг | … | 0 |
Но, очевидно, банку BNP, нет никакого смысла предсказывать эти самые холдинги, ведь их можно однозначно восстановить из базы. Значит существует другой тип ноликов, которых нет в тренировочной таблице, а именно — любые тройки «пользователь — бумага — тип сделки», которые не попали в базу данных. То есть пользователь НЕ заинтересовался некоторой акцией, значит никак не провзаимодействовал с ней в системе BNP, значит соответствующая строка не появилась в базе данных, а значит она должна иметь таргет 0. А это говорит о том, что подобные строки для тренировки нужно сгенерировать самим (см. раздел «Составление тренировочной выборки»). Все это могло навести некоторую путаницу, ведь многие участники, наверняка, подумали — есть датасет, есть нолики и единички — можно предсказывать. Но не так все просто.
Итак, в трейне есть таблица с историей сделок (то есть интеракции «пользователь — бумага — тип сделки» и некоторая дополнительная информация по ним) и куча других табличек с характеристиками пользователя, акции, глобального состояния рынка. В тесте есть только тройки «пользователь — бумага — тип сделки» и для каждой такой тройки нужно предсказать, появится ли она на следующей неделе. Например, нужно предсказать, заинтересуется ли пользователь id=8 акцией id=46 с типом сделки «продажа»?
| Id пользователя | Id ценной бумаги | Тип сделки | Таргет |
|---|---|---|---|
| 8 | 46 | Продажа | ? |
Особенности построения датасета
Поскольку, как я уже сказал, в реальной базе данных BNP не было строчек с «не-холдинговыми» ноликами, то подобные строки для теста организаторы как-то сгенерировали сами. А там, где есть искусственная генерация данных, зачастую бывают лики и другиая неявная информация, которая могжет существенно улучшить результат без изменения моделей/признаков. В этом разделе описываются некоторые особенности построения датасета, которые нам удалсь понять, но которые, к сожалению, никак нам не помогли.
 Если посмотреть на тройки «пользователь — бумага — тип сделки» из тестовой таблицы, то легко заметить, что количество сделок с типом «покупка» и «продажа» в точности совпадает, причем таблица строго отсортирована по этому признаку: сначала все покупки, потом все продажи. Очевидно, что это не случайность и возникает вопрос: как такое могло получиться? Например, так: организаторы взяли все реальные записи из своей базы данных за неделю, на которую нам нужно сделать предсказание (такие строки имеют таргет 1), каким-то образом сгенерировали новые строки (таргет у них 0), не совпадающими с описанными выше. Так получилась таблица, в который типы сделок (покупка/продажа) расположены в произвольном порядке:
Если посмотреть на тройки «пользователь — бумага — тип сделки» из тестовой таблицы, то легко заметить, что количество сделок с типом «покупка» и «продажа» в точности совпадает, причем таблица строго отсортирована по этому признаку: сначала все покупки, потом все продажи. Очевидно, что это не случайность и возникает вопрос: как такое могло получиться? Например, так: организаторы взяли все реальные записи из своей базы данных за неделю, на которую нам нужно сделать предсказание (такие строки имеют таргет 1), каким-то образом сгенерировали новые строки (таргет у них 0), не совпадающими с описанными выше. Так получилась таблица, в который типы сделок (покупка/продажа) расположены в произвольном порядке:
| Id пользователя | Id ценной бумаги | Тип сделки | Таргет |
|---|---|---|---|
| 8 | 46 | Продажа | 1 |
| 2 | 6 | Покупка | 1 |
| 158 | 73 | Покупка | 1 |
| 3 | 29 | Продажа | 0 |
| 67 | 9 | Покупка | 0 |
| 17 | 465 | Продажа | 0 |
Теперь можно всем строкам с типом сделки «продажа» поставить тип «покупка», при этом если таргет был единичка, то он станет ноликом (в большинстве случаев пользователь интересовался некоторой бумагой только с одним статусом: либо покупка, либо продажа). Получится следующая таблица:
| Id пользователя | Id ценной бумаги | Тип сделки | Таргет |
|---|---|---|---|
| 8 | 46 | Покупка | 0 |
| 2 | 6 | Покупка | 1 |
| 158 | 73 | Покупка | 1 |
| 3 | 29 | Покупка | 0 |
| 67 | 9 | Покупка | 0 |
| 17 | 465 | Покупка | 0 |
Остается последний шаг: сделать то же самое, но заменяя «покупку на продажу» и расставить правильные таргеты:
| Id пользователя | Id ценной бумаги | Тип сделки | Таргет |
|---|---|---|---|
| 8 | 46 | Продажа | 1 |
| 2 | 6 | Продажа | 0 |
| 158 | 73 | Продажа | 0 |
| 3 | 29 | Продажа | 0 |
| 67 | 9 | Продажа | 0 |
| 17 | 465 | Продажа | 0 |
Конкатенируя таблицу с «покупками» и таблицу с «продажами» получаем (если бы мы были организаторами) таблицу как дана нам в тесте. Легко понять, что первая и вторая половины построенной таким образом таблицы имеют тот же порядок пар «пользователь — бумага», что в тестовой таблице действительно оказалось так.
Еще одной особенностью, было то, что в тренировочном датасете много строчек, в которых индекс пользователя повторялся несколько раз подряд, несмотря на то, что датасет не был отсортирован ни по одному из признаков:
| Id пользователя | Id ценной бумаги | Тип сделки | Таргет |
|---|---|---|---|
| 8 | 46 | Продажа | ? |
| 8 | 152 | Продажа | ? |
| 8 | 73 | Покупка | ? |
Сокомандник посчитал, что это нормально, и изначально был отсортированный по id пользователей датасет, а организаторы просто плохо его пошафлили (например, если бы шафл был устроен на случайных перестановках и таких перестановок было совершено недостаточно много). Пытаясь убедиться в этом, он перебрал четыре шафла из разных библиотек, но нигде таких частых повторений не возникло. Тест тоже имел такую особенность. Появилась мысль, что нолики организаторы не сгенерировали, а просто взяли старые пары из трейна. Чтобы проверить, я решил сделать следующее: каждой паре «пользователь — бумага» из теста сопоставить номер строки из трейна, когда данная пара первый раз встретилась и сделать plot от этого. То есть, например, мы смотрим на первую строчку в тесте, пусть она имеет id пользователя = 8 и id = бумаги = 15. Теперь проходимся по тренировочной таблице сверху вниз и ищем, когда данная пара первй раз появилась, пусть это будет, например, 51-я строчка. Мы получили сопоставление: 1я строчка в тесте была в трейне 51-й, значит наносим на график точку с координатами (1, 51). Делаем так для всего теста и получаем следующий график: 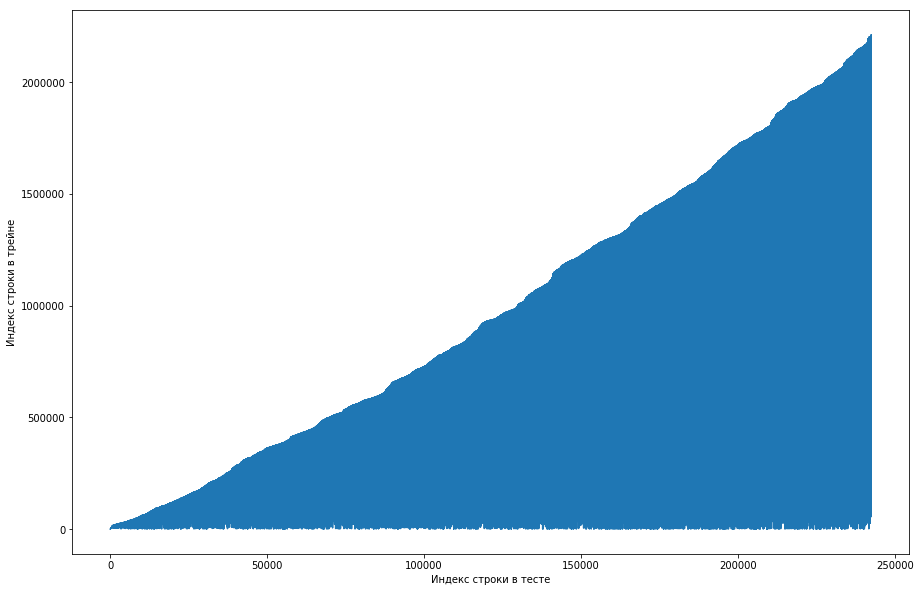
Отсюда видно, что, в основном, если пара раньше встретилась в трейне, то и в таблице теста ее позиция будет выше. Но при этом встречаются некоторые выбросы вниз на графике (их на самом деле не так много, но из-за разрешения экранов кажется, что тут сплошной треугольник). Причем количество выбросов примерно совпадало с ожидаемым количеством единичек в тесте. Конечно, мы попробовали пометить единичками выбросы и заслать это на лидерборд, но, к сожалению, это ничего не дало. Но мне все равно казалось, что тут может быть какой-то лик (), и, как капитан команды, я предложил потратить больше времени на то, чтобы понять, как такое вообще могло произойти, а натренировать модели и сгенерировать признаки мы еще успеем. Дисклеймер: мы потратили на это кучу времени, но за неделю до конца соревнования организаторы написали на форуме, что в тестовый датасет брались только тройки за последние 6 месяцев, а не все. Ну и если проделать описанные выше операции, но для последних 6 месяцев, а не всего датасета, то получится ровненькая монотонная кривая: 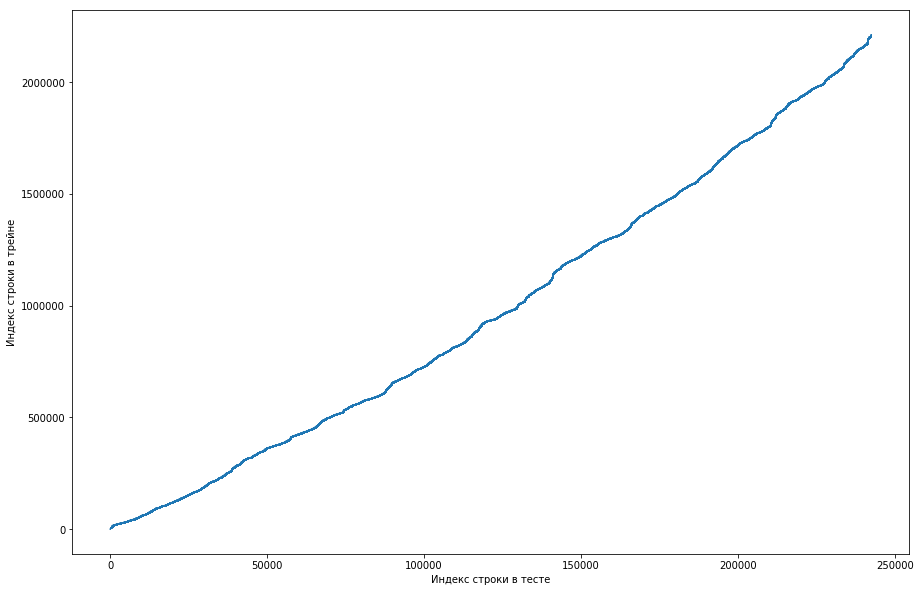
А это значит, что никакого лика здесь нет и быть не может.
Составление тренировочной выборки
Так как в тесте нужно сделать предсказание для троек на одну неделю, то разобьем тренировочный датасет на недели (при этом на каждой неделе встречается в среднем 20к троек «пользователь — бумага — тип сделки»). Теперь для любой тройки мы можем сказать, встретилась ли она на конкретной неделе или нет. При этом положительные тройки у нас уже есть (это все записи с данной недели в таблице трэйна), а отрицательные нужно как-то сгенерировать. Есть много вариантов как это сделать. Например, можно перебрать абсолютно все тройки, которых не было на определенной неделе в тренировочном датасете. Понятно, что тогда выборка будет сильно несбалансированной, и это плохо. Можно сначала сгенерировать пользователей пропорционально частоте их встречаемости в датасете, а потом как-то добавлять к ним в соответствие акции. Но при таком подходе будет куча строчек, для которых нельзя посчитать разумные статистики, что тоже плохо. Как сделали мы: взяли всевозможные тройки, которые ранее встречались в трейне, скопировали, заменив buy/sell на противоположный и сконкатенировали эти две таблицы. Понятно, что так могли возникнуть дупликаты (например, если пользователь когда-либо и покупал, и продавал акцию), но их было немного, и после удаления получалась таблица на 500к уникальных троек. Ну и все, теперь на каждую неделю для каждой такой тройки можно сказать, встретилась она или нет (и сколько раз?).
Поскольку по сути мы имеем дело с временными рядами — пользователь в каждую неделю просматривает конкретное объявление сколько-то раз, то таблицу для обучения классификатора будем строить классическим для временных рядов способом. А именно, возьмем последнюю доступную неделю из трейна, посмотрим, встречалась ли на этой неделе каждая тройка «customer — isin — buy or sell». Это будет таргет. А в качестве фичей посчитаем различные статистики, например, за последние 6 недель (подробнее про статистики в разделе «Признаки»). Теперь забудем про существование последней недели и сделаем все то же самое, но для предпоследней недели и сконкатенируем полученные таблицы. Так можно сделать несколько раз, тем самым увеличивая «по высоте» трейн, но при этом интервал, по которому мы считаем статистики, естественно, уменьшается. Мы повторяли такую операцию 10 раз, потому что если сделать больше, то в таргет бы попал праздник новый год и связанные с ним проблемы, которые ухудшили бы итоговое качество модели. Поясняющая картинка: 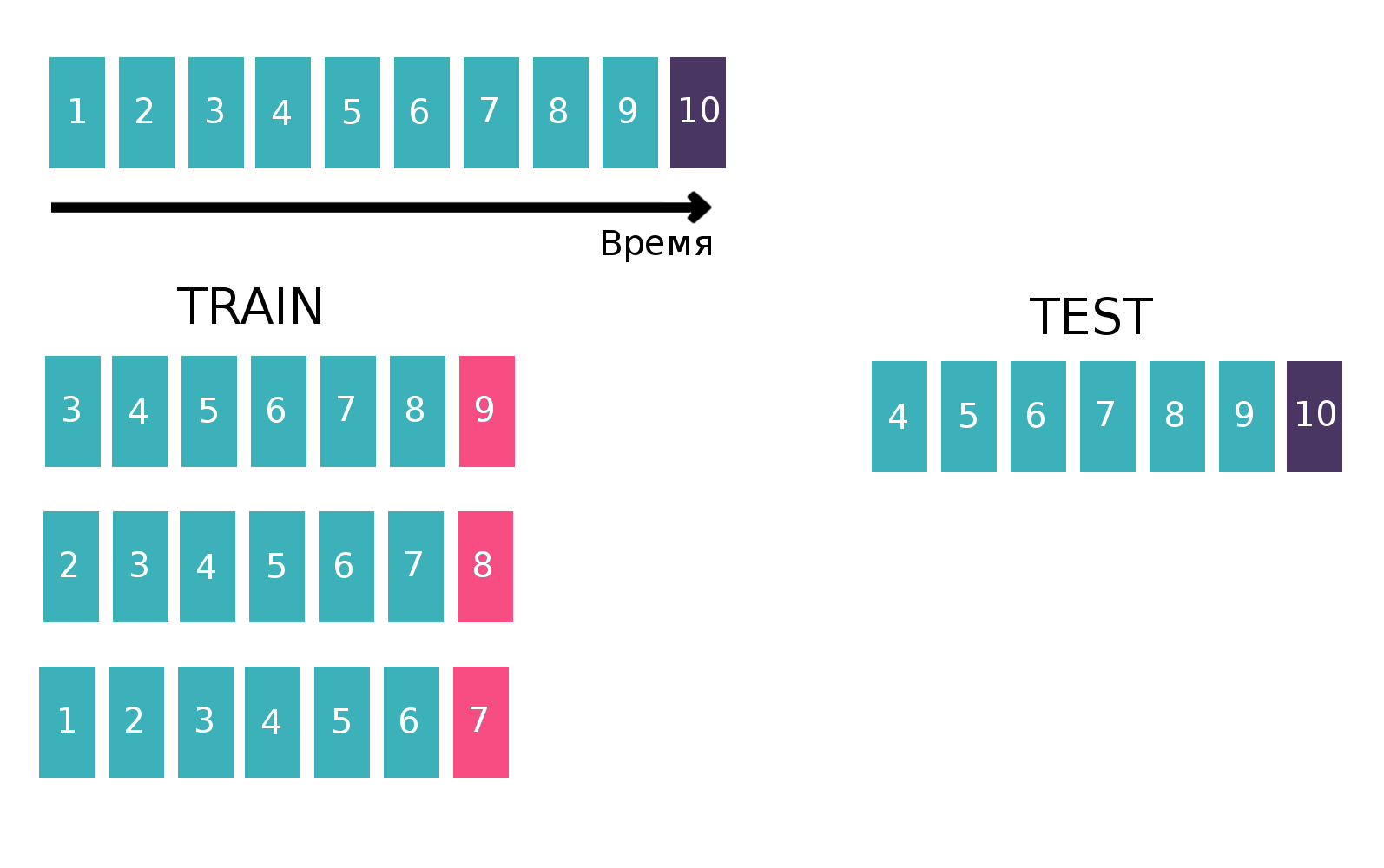
Подробнее про временные ряды и валидацию на временных рядах можно почитать тут.
Признаки
Как я уже говорил, было много таблиц, как-то характеризующих пользователя, акцию или глобальное состояние рынка (курсы главных валют и некоторые индикаторы). Но все они почти не улучшали качество, а главными признаками были статистики, посчитанные для пар «customer — isin», и троек «customer — isin — buy or sell», например, такие:
- Как часто встречалась пара/тройка за последние 1, 2, 5, 20, 100 недель?
- Статистики по временным промежуткам между встречаниями пары/тройки в датасете (mean, std, max, min)
- Расстояние во времени до первого/последнего раза, когда встретилась пара/тройка
- Доля каждого значения TradeStatus у пары/тройки
- Статистики по тому, сколько раз за неделю пара/тройка встречается (mean, std, max, min)
Кроме того, в последний день соревнования я прочитал на формуе, что для того, чтобы продать акцию, ее надо сначала купить. Это знание позволяет придумать еще много полезных признаков, но, почему-то, для меня это не было очевидно.
В коде это все выражалось функцией длиной в 200 строк, которая генерировала подобные признаки для каждого из десяти кусков трейна (для той части, где таргет, например, 7я неделя мы не должны использовать информацию за 8ю и 9ю). С учетом дополнительных таблиц набиралось около 300 признаков. Как я уже говорил, мы сгенерировали 500к уникальных троек и в качестве таргетов брали последние 10 недель, следовательно «в высоту» тренировочная таблица была 500к*10 = 5кк строк.
Еще некоторые признкаи были описаны в решении второго места. Ребята построили таблицу пользователь/бумага, где в каждой ячейке стояла единица, если пользователь когда-либо интересовался данной бумагой и ноль иначе. Посчитав косинусное расстояние между пользователями в данной таблице, можно получить схождеть пользователей между собой. Если применить PCA к полученной таблице схождестей, то получится набор признаков, которые некоторым образом характеризуют пользователя.
Модели или боремся за тысячные
Стоит отметить, что почти три недели никто не мог побить baseline от BNP, который имел скор 0.794(ROC AUC) на лидерборде и это при том, что решение «просто посчитать количество раз, которое пара встречалась ранее» давало на лидерборде 0.71, а некоторые участники получали и все 0.74 без применения машинного обучения.
Но мы машинное обучение применяли, более того, в последний день соревнования (который по счастливой случайности совпал с концом сессии) мы решили упороться if you know what i mean и сделать большой блендинг из разных моделей, обученных на разных подмножествах признаков с разным количеством недель в трейне. Как я уже сказал, наша тренировочная выборка состояла из 1.5кк строк, причем таргетов-единичек среди них примерно 150к. Размер теста был 400к, в то время как предполагаемое число единичек было 20к (в среднем на деле встречается такое количество уникальных троек). То есть доля единичек в тесте была значительно выше, чем в трейне. Поэтому во всех своих моделях мы регулировали параметр scale_pos_weight, который расставляет веса классам. Подробнее про этот параметр можно посмотреть на разборе лучшего решения одного из прошлогодних DataScienceGame. Матрица корреляций предсказаний наших моделей показана на рисунке: 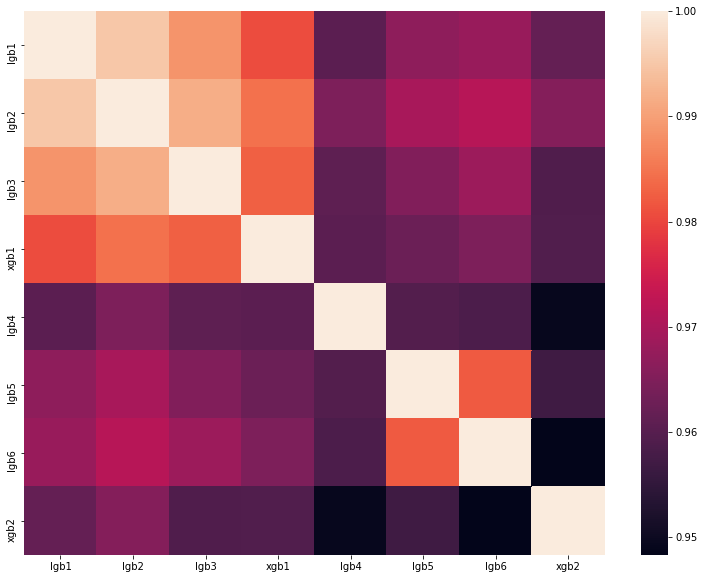
Как видно, у нас было много довольно разных моделей, что позволило получить на лидерборде скор 0.80204.
Почему мы не поедем во Францию на финальный этап
В результате мы показали неплохой результат и на прайвет лидерборде заняли третье место. Но организаторы установили следующие правила для отбора финалистов:
- Не более 20 лучших команд
- Не более 5 лучших команд из страны
- Не более 1 команды из учебного заведения
И все бы хорошо, если бы на втором месте не оказалась другая команда из МФТИ со скором 0.80272. То есть мы отстали всего на 0.00068. Обидно, но тут уж ничего не поделаешь. Скорее всего, организаторы сделали такие правила чтобы люди из одного университета никаким образом не помогали друг другу, но в нашем случае, мы ничего не знали о соседней команде и никак с ней не контактировали.
Итоги
В этом году в сентябре в Париже будут бороться за первое место 5 команд из России, одна из Украины и две команды из Германии и Финляндии, состоящие из русскоговорящих студентов. Итого 8 команд ру-комьюнити, что в очередной раз доказывает доминацию ру-сегмента датасаенса. А я перевожусь в шарагу тренируюсь и работаю над собой, чтобы в следующем году все-таки побороть отборочный этап.
