2 года, 7 попыток, 0 распознанных бордюров: как мы учились детектить ДТП в реалтайм без датасета
Привет, Хабр! Это команда дата-сайентистов Magnus Tech. В этом посте мы расскажем, как работали над одним общественно полезным проектом — алгоритмом, который распознает ДТП по видео с дорожных камер. Кейс будет интересен широкому кругу разработчиков, которые занимаются технологиями машинного зрения и обучения. В нем — наш долгий путь из множества попыток сделать точный алгоритм, несмотря на его настойчивые попытки быть неточным.
За два года мы наступили на все возможные грабли, протестировали уйму гипотез и подходов к задаче. В итоге пришли к рабочему алгоритму, который, наконец-то, научился отличать машины от бордюров. В этом посте мы поделимся инсайтами, расскажем о неудачных гипотезах, распишем архитектуру последней версии нашего алгоритма и объясним, почему для выхода на прод нам все-же понадобится датасет.

Параметр в левом верхнем углу (уверенность) отвечает за предсказание ДТП
Больше, чем профессиональный вызов
Сразу скажем, что проект и сейчас в активной разработке, и мы уже тестируем новую версию на улицах. Администрации российских городов активно внедряют элементы умного города, если точнее, системы видеоаналитики, работающие с транспортными потоками. В перспективе они должны повысить пропускную способность и безопасность дорог, уменьшить количество ДТП, снизить расход топлива и вредные выбросы.
Сложность проекта заключалась в том, что таким мы раньше не занимались, а заказчик серьезный. К тому же оказалось, что здесь нет готовых рабочих решений, нет репозиториев и предобученных моделей, которые справлялись бы с задачей детекции ДТП. Не каждый день выпадает шанс набить шишек и придумать решение с нуля. Чутка поволновавшись, мы решили перестать это делать и приступить к работе (звучит героическая музыка).

Платформа уже умела считать машины и распознавать марки, цвета, номера. Нашей задачей стала разработка алгоритма, который мог бы консистентно детектить ДТП по видеопотоку.
С нашей помощью система видеоаналитики должна была научиться в:
Последний пункт вдохновлял сильнее всего, ведь служба мониторинга может вызвать скорую помощь быстрее, чем участники ДТП, которые могут находиться в состоянии шока, быть обездвижены, без сознания или без средств связи. А в перспективе собранные данные могут помочь повысить безопасность, например, обнаружить перекрестки, которые требуют реконструкции.
Что ж, мы справимся. Наберем данных для обучения и справимся…
Нет данных. У нас почти нет данных! На чем мы будем обучать модель?
Это, конечно, не было истерикой, но затылки мы чесали активно. Поначалу думали, что можем положиться на:
репозитории с предобученными моделями;
стандартный софт, которые можно быстро настроить под наши задачи;
большой датасет для обучения нейросети.
На деле не оказалось ни того, ни другого, ни третьего.
Существуют готовые датасеты, которые можно использовать для решения задачи распознавания машин, можно запросить данные с прода (мы их разметим и что-то точно получим), но для задач детекции ДТП такого объема и разнообразия данных попросту нет.
Открытые датасеты маленькие и бедные. Как выяснилось, собрать достаточный объем примеров ДТП с продакшена мы тоже не можем — аварии сравнительно редко попадают в поле зрения видеокамер.

Более того, ДТП сильно отличаются друг от друга: одно дело поцарапать бампер, и совсем другое — столкнуться на скорости. Причем последний вариант имеет множество подвариантов: удар «лоб в лоб», в бок кузова, о дорожные ограждения и т. д. А ведь есть еще и мотоциклисты, велосипедисты, трамваи и пешеходы — разнообразие возможных ситуаций требует еще больше данных для обучения нейронки, которая могла бы покрыть всю вариативность.
5 (кругов ада) попыток задетектить ДТП без датасета
Мы решили, что попробуем обойти эту проблему и начали тестировать гипотезы. Первые попытки оказались настолько «креативными», что занимают призовые места в топе «Не надо так делать». Потом дело пошло лучше.
Первая попытка
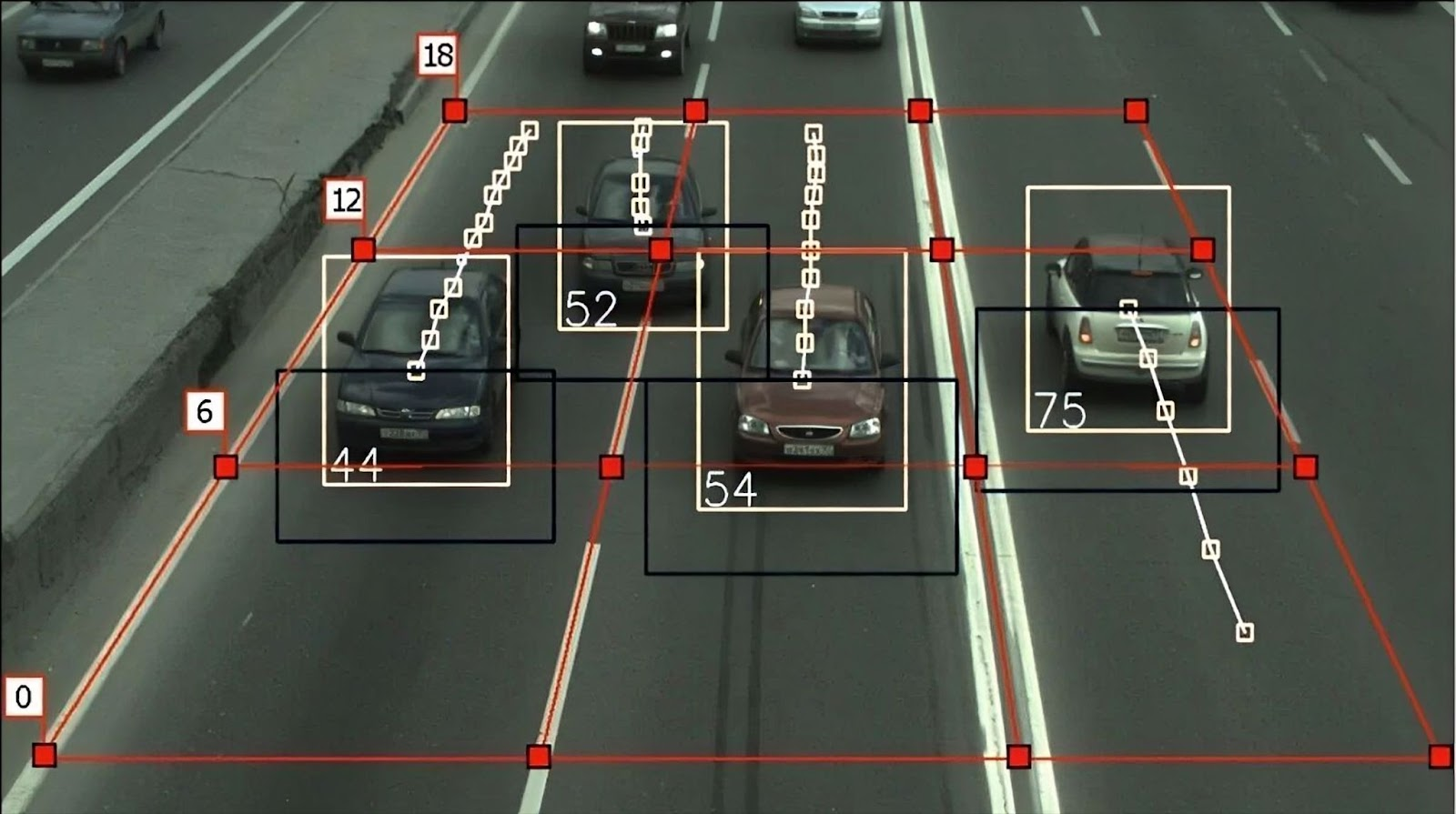
Мы пытались использовать данные из другого компонента системы — трекера, который генерировал «карту» на основе векторов движения автомобилей. Размышляли так: если произойдет ДТП, то «точка» должна резко дернуться, а вектор направления движения сильно изменится. Мы смотрели результаты трекера, в надежде увидеть сильную разницу в скорости или направлении, чтобы заключить: это произошло ДТП.
Гипотеза не подтвердилась, так как трекер работал нестабильно. Например, когда транспортное средство передвигалось медленно, почти стояло, вектор дергало и колбасило в непредсказуемых направлениях.
Вторая попытка
Мы пытались компенсировать недостаточную стабильность алгоритма ограничением диапазона возможного изменения, «сказав», что если происходит слишком резкая смена направления, то такие данные учитывать не надо. Сработало на первой пятерке тестовых видео, но скоро стало ясно, что это тоже не вариант.
Например, если машины слегка сталкивались и останавливались (относительно частая ситуация), алгоритм не срабатывал. Или были моменты, когда одна машина загораживала другую, и трек пропадал. Была даже пара случаев, когда машина сильно разбивалась и переставала детектиться вовсе. Похоже, алгоритм считал, что эта груда металла — не ТС.
Третья попытка
Появилась идея сделать другую эвристику. Размышляли так: в момент ДТП люди обычно выходят из машины и начинают вокруг нее передвигаться, матерясь и жестикулируя. Нет, мы не считывали мат по губам (впрочем, эта идея приходила в голову), а решили попробовать детектить суетящихся поблизости людей.
Задачу «решали» три модуля:
маска дороги (маскирование позволяет избежать ложных детекций);
детектор, который засекает транспортные средства, задержавшиеся на проезжей части дольше, чем на определенный срок;
детектор людей, который отслеживает проезжую часть и определяет, есть ли люди вокруг неподвижной машины.
Мы рисовали радиус вокруг BBox«ов (BBox, Bounding Boxes, ограничивающий параллелепипед — имеются в виду цветные прямоугольники вокруг объектов). Люди, которые консистентно определялись в этом радиусе и при этом находились на дороге, активировали оповещение о ДТП.
Пишем эти строчки и смеемся, но, по крайней мере, мы не побоялись применить метод «слабоумия и отваги» прежде чем наковырять данные для обучения более умного алгоритма.
К слову, этот вариант иногда даже работал и определял некоторые ДТП. И все же, чаще алгоритм ошибался, потому что людей не всегда видно — они могут находиться вдали от камеры или перекрываться автомобилями и другими объектами. Иногда спадал счетчик непрерывной детекции. Еще были ситуации, когда человек детектился на проезжей части, а на самом деле он стоял на тротуаре, просто большая часть его BBox«а попадала на дорогу. Иногда детектился тротуар.
Четвертая попытка
Все предыдущие итерации мы пытались реализовать алгоритм, исходя из наших представлений о том, как происходят ДТП. Проблема в том, что у нас не получалось покрыть все разнообразие дорожных аварий нашими эвристиками. Но отчаиваться рано. Мы еще не пробовали обучать алгоритм на фотографиях разбитых машин!

Собрали датасет из нескольких тысяч изображений разбитых ТС, настроили детекцию по ним и получили кучу ложных срабатываний. Теперь любое мятое крыло или поцарапанный бампер воспринимались как ДТП. Почему-то, алгоритму особенно полюбились помятые радиаторы.
Несмотря на неудачу, мы повторили эксперимент, но на картинках с авариями, которые нарезали из видеозаписей с городских камер. И это тоже не дало результата: алгоритм запоминал конкретные улицы и выдавал предсказания просто по фону. Стало ясно, что обучение на фотографиях нам не подходит. Забегая вперед, детекция фрагментам дольше 5–10 секунд тоже срабатывает не всегда, поэтому мы пришли к компромиссу: начали разбивать видеопоток на клипы по 2–3 секунды.
Пятая попытка
Возможно, вы удивитесь, но есть профессиональные соревнования по ДТП-детекции в рамках NVIDIA AI CITY Challenge. Мы решили попробовать метод вычитания фона, описанный в статье об алгоритме-победителе 2021 года — Good Practices and A Strong Baseline for Traffic Anomaly Detection.
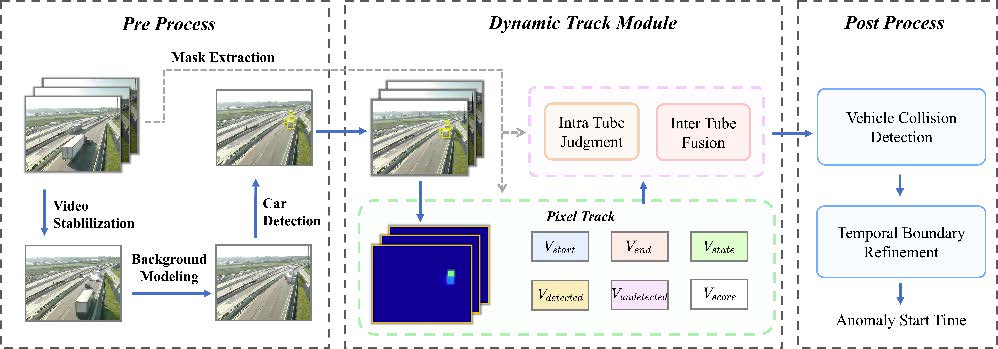
Рецепт: берешь данные с дорожной видеокамеры и направляешь в генератор фона, который реалтайм высчитывает некий «средний кадр» с обездвиженными объектами (он обновляется, когда приходит новый кадр) — так получаешь консистентное изображение того, что происходит в этой части дороги.
Генерацию производит MOG2 из библиотеки алгоритмов компьютерного зрения OpenCV на основе n изображений. Вначале, опасаясь тормозов, мы сделали n=30 сек, потом увеличили до 300 сек. Пробовали и при большем количестве изображений, но тогда функция работает медленней.
На полученном фоне движущиеся машины выглядят «размазано» и напоминают фантомы (наверное, так и рождаются городские легенды про машины-призраки). ТС, попавшие в ДТП, останавливаются, и тогда прорисовываются более четко, потому что кадры стоящей на месте машины наслаиваются друг на друга.

Отделить машину, попавшую в аварию, от просто остановившихся ТС позволяют константы, определяющие, что ТС находится в неизменном положении не меньше некоторого времени.
Итак, генератор фона дает «среднее изображение». На нем детектор объектов YOLO ищет машины. Затем фон вместе с детекцией и маской для каждой камеры (определяет ту часть дороги, снимаемой видеокамерой, где проводится детекция), попадают в трекер пикселей. Pixel-трекер с учетом маски считает для каждого пикселя количество детекций, прерываемых не более, чем на константу, тоже заданную эвристически. Константы влияют на точность детекции.
Дальше детекции, попавшие в трекер пикселей (например, метрика пересечения с полем пикселей + маска не меньше константы 0,5), отправляются в BBox-трекер. Там начинается работа с так называемыми трубками — подробнее о них ниже. Здесь только разъясним, что трубка — это то, насколько меняется BBox у машины со временем, ее создает передвинувшийся BBox сместившегося ТС.
По крайней мере, так оно должно работать в теории. Мы проверили, и оказалось, что код, который опубликовали исследователи, работает не так, как заявлено. Точнее не работает в реальном времени. Пришлось сильно все переписать и заодно оптимизировать для реалтайм-работы. Например, для некоторых функций, которые считались на CPU, мы подобрали аналоги, которые реализованы на видеокартах. Но в итоге, похоже, мы справились. Давайте разложим все по полочкам.
Из чего состоит и как работает шестая версия алгоритма
Наш первый рабочий алгоритм детекции ДТП представляет собой комплексный набор эвристик, способный более-менее консистентно фиксировать длительную остановку ТС на проезжей части.
Для выполнения этой задачи нейронной сети необходимо, как минимум, уметь разделять различные ТС друг от друга (проводить некоторое подобие трекинга) и стабильно фиксировать отслеживаемое остановившееся ТС. Сложность состоит в том, что проезжающие мимо автомобили иногда загораживают место ДТП. Кроме того, необходимо различать остановки в предусмотренных на то местах и остановки на проезжей части в обычных ситуациях: в пробке, на светофорах, при заглохшем двигателе. Если не учитывать эти нюансы, то работа алгоритма будет нестабильной. Значит, его нельзя будет использовать по назначению.
Перейдем к описанию работы алгоритма и его составных частей.
Компоненты алгоритма
Алгоритм ДТП-детекции можно разделить на четыре компонента. Кроме того, есть вспомогательные подсистемы, которые обрабатывают и связывают результаты работы этих модулей, но их описание только все запутает.
Генератор фона

Генератор фона получает на вход изображения с камеры. Каждую итерацию он составляет на их основе некоторое «среднее изображение» при помощи алгоритма MOG2. Вот пример гифки, составленной из таких изображений.

Генератор фона также снабжен буфером, который обновляется при каждом новом сгенерированном фоне.
Детектор автомобилей
Работает на YoloV5s — усовершенствованной пятой версии детектора объектов YOLO, реализованной на PyTorch. Модель производит детекцию автомобилей на изображениях, которые создает генератор фона. Стоит заметить, что все детекции фильтруются относительно некоторой маски, которая обозначает проезжую часть. Вне проезжей части (например, на стоянках) объекты не учитываются.

Для понимания принципов работы этого модуля важно различать процессы Object Detection и Object Tracking. Object Detection — это определение объектов на картинке или в кадре, но не определение их движения — этим как раз занимается Object Tracking. То есть, алгоритм или нейронная сеть работают только с одним кадром: определяют объект и записывают его позицию вместе с BBox.
YoloV5s относится к архитектуре One-Stage detector. Она позволяет предсказывать координаты определенного количества bounding box’ов с результатами классификации и вероятности нахождения объекта.
Мы опасались, что детектор не сможет различать грязные автомобили на фоне серых улиц, но снижение точности оказалось незначительным.
Pixel-трекер

Дальше детекции в виде изображений вместе с BBox«ами попадают в Pixel-трекер. Его задачи:
найти область изображения, на которой консистентно находятся автомобили и непрерывно происходит детекция;
отфильтровать точно ложные детекции.
С ложными детекциями было весело. Во время тестирования алгоритма оказалось, что на некоторых видео YoloV5s распознает в качестве ТС края дороги — бордюры и другие элементы дорожного полотна. Мы решили использовать достаточно простой метод фильтрации заведомо ложных детекций такого рода: при детекции некоторого BBox«а изображение в нем сравнивается с предыдущими кадрами. Это как раз та ситуация, когда используется буфер генератора фона.
Алгоритм нахождения области изображения, в которой находятся автомобили, тоже достаточно прост: матрица размером с изображение учитывает соответствующие части BBox«ов, которые находятся на проезжей части (с точки зрения маски). Детектор ДТП при этом срабатывает при одновременной активации двух трекеров.
BBox-трекер

Этот трекер работает с BBox«ами, которые прошли первичную фильтрацию в pixel-трекере. Треки каждого ТС представляются в виде трубок — наборов BBox«ов в каждый момент времени, характеризующих позицию ТС на сгенерированном фоновом изображении.
BBox-трекер становится активированным, когда трубка становится достаточно большой.
Итоговое решение

Если конечный BBox активированной трубки содержит в себе активированные пиксели Pixel-трекера в достаточном количестве (другими словами: последний бокс активированной трубки покрывает достаточно большую активированную область, относительно собственной площади), то мы делаем вывод о том, что случилось ДТП и выдаем alert.
Попытка номер семь или от зрения к обучению
Мы опробовали получившееся решение на проде, и оно обеспечило стабильную детекцию ДТП, но все же показало и весомые недостатки.
Основной проблемой стало то, что этот алгоритм не справляется с важной задачей: оперативно реагировать на аварии и помогать пострадавшим. Так происходит потому, что он работает с задержкой в 1–3 минуты — это слишком медленно. Так что после всех экспериментов с машинным зрением мы все же решили вернуться к нейросетям.
За основу взяли модель распознавания объектов, разработанную в Facebook в 2020 году. Она работает на базе трехмерных сверточных слоев: по ширине, по высоте и по времени. Мы попробовали обучить ее с нуля на небольшом датасете: всего 150 клипов от заказчика, 16 пятиминутных видео с разных камер, 5 часов записей без аварий и 500 примеров из открытых источников. Этого достаточно для тестирования машинного зрения, но, как выяснилось, мало для машинного обучения.
Чтобы хотя бы немного разнообразить набор, применили аугментацию данных, то есть, внесли множество различных изменений в каждый кадр: цветовых, геометрических, пространственных (повороты и растягивание). Так, из одного кадра получается несколько «ракурсов». Выяснилось, что такие модификации датасета заметно улучшают распознавание, особенно для видео со сложными погодными условиями.

Параметр в левом верхнем углу (уверенность) отвечает за предсказание ДТП
Сработало неплохо, но есть куда стремиться — модель от Facebook выдавала 20% ложных срабатываний в реалтайме.
Убедившись, что у этого подхода есть потенциал, мы заказали сбор и разметку датасета у сторонней компании. Чтобы сократить число ложных срабатываний до разумных значений потребовалось еще больше 2 тыс. уникальных примеров. Количество ложных срабатываний типа «бордюр — это машина» снизилось почти до нуля. С этим можно было работать дальше.
О том, что получилось и на какие еще грабли мы наступили, расскажем в следующий раз, а пока, в качестве затравки покажем запись из актуальной версии нашей системы детекции ДТП.
Это результат работы сразу нескольких алгоритмов. Одна нейронка распознает транспортные средства, другая — людей, отдельный алгоритм тречит ТС по ходу движения и еще одна подсистема отвечает за преобразование картинки с камеры на «вид сверху» при помощи матрицы поворота.
Надеемся наш опыт вам пригодится. Задавайте, пожалуйста, вопросы в комментариях.
