10 причин [не] использовать k8s
Сегодня мы поговорим про Kubernetes, про грабли, которые можно собрать при его практическом использовании, и про наработки, которые помогли автору и которые должны помочь и вам. Постараемся доказать, что без k8s в современном мире никуда. Противникам k8s также предоставим отличные причины, почему не стоит на него переходить. То есть в рассказе мы будем не только защищать Kubernetes, но и ругать его. Отсюда в названии появилось это [не].
Эта статья основана на докладе Ивана Глушкова на конференции DevOops 2017. Последние два места работы Ивана так или иначе были связаны с Kubernetes: и в Postmates, и в Machine Zone он работал в инфракомандах, и Kubernetes они затрагивают очень плотно. Плюс, Иван ведет подкаст DevZen. Дальнейшее изложение будет вестись от лица Ивана.

Сперва я пробегусь вкратце по области, почему это полезно и важно для многих, почему этот хайп возникает. Потом расскажу про наш опыт использования технологии. Ну и потом выводы.
В этой статье все слайды вставлены как картинки, но иногда хочется что-нибудь скопировать. Например, там будут примеры с конфигами. Слайды в PDF можно скачать по ссылке.
Я не буду строго всем говорить: обязательно используйте Kubernetes. Есть и плюсы, и минусы, поэтому, если вы пришли искать минусы, вы их найдете. Перед вами выбор, смотреть только на плюсы, только на минусы или в целом смотреть на все вместе. Плюсы мне будет помогать показывать Simon Cat, и черная кошка будет перебегать дорогу, когда есть минус.

Итак, почему вообще произошел этот хайп, почему технология Х лучше, чем Y. Kubernetes — это точно такая же система, и существует их гораздо больше, чем одна штука. Есть Puppet, Chef, Ansible, Bash+SSH, Terraform. Мой любимый SSH помогает мне сейчас, зачем мне переходить куда-то. Я считаю, что критериев много, но я выделил самые важные.
Время от коммита до релиза — очень хорошая оценка, и ребята из Express 42 — большие эксперты в этом. Автоматизация сборки, автоматизация всего pipeline — это очень хорошая вещь, нельзя её перехвалить, она на самом деле помогает. Continuous Integration, Continuous Deployment. И, конечно же, сколько усилий вы потратите на то, чтобы все сделать. Все можно написать на Ассемблере, как я говорю, систему деплоймента тоже, но удобства это не добавит.

Короткую вводную в Kubernetes я рассказывать не буду, вы знаете, что это такое. Я немного коснусь этих областей дальше.

Почему всё это так важно для разработчиков? Для них важна повторяемость, то есть если они написали какое-то приложение, запустили тест, оно будет работать и у вас, и у соседа, и в продакшне.
Второе — стандартизированное окружение: если вы изучили Kubernetes и пойдете соседнюю компанию, где есть Kubernetes, там будет всё то же самое. Упрощение процедуры тестирования и Continuous Integration — это не прямое следствие использования Kubernetes, но всё равно это упрощает задачу, поэтому всё становится удобнее.

Для релиз-разработчиков гораздо больше плюсов. Во-первых, это иммутабельная инфраструктура.
Во-вторых, инфраструктура как код, который где-то хранится. В-третьих, идемпотентность, возможность добавить релиз одной кнопкой. Откаты релизов происходят достаточно быстро, и интроспекция системы достаточно удобная. Конечно, все это можно сделать и в вашей системе, написанной на коленке, но вы не всегда можете это сделать правильно, а в Kubernetes это уже реализовано.
Чем Kubernetes не является, и что он не позволяет делать? Есть много заблуждений на этот счет. Начнем с контейнеров. Kubernetes работает поверх них. Контейнеры — не легковесные виртуальные машины, а совсем другая сущность. Их легко объяснить с помощью этого понятия, но на самом деле это неправильно. Концепция совершенно другая, её надо понять и принять.
Во-вторых, Kubernetes не делает приложение более защищенным. Он не делает его автоматически скалируемым.
Нужно сильно постараться, чтобы запустить Kubernetes, не будет так, что «нажал кнопку, и все автоматически заработало». Будет больно.

Наш опыт. Мы хотим, чтобы вы и все остальные ничего не ломали. Для этого нужно больше смотреть по сторонам — и вот наша сторона.

Во-первых, Kubernetes не ходит в одиночку. Когда вы строите структуру, которая будет полностью управлять релизами и деплоями, вы должны понимать, что Kubernetes — один кубик, а таких кубиков должно быть 100. Чтобы все это построить, нужно все это сильно изучить. Новички, которые будут приходить в вашу систему, тоже будут изучать этот стек, огромный объем информации.
Kubernetes — не единственный важный кубик, есть много других важных кубиков вокруг, без которых система работать не будет. То есть нужно очень сильно беспокоиться об отказоустойчивости.

Из-за этого Kubernetes’у минус. Система сложная, нужно много о чем заботиться.

Но есть и плюсы. Если человек изучил Kubernetes в одной компании, в другой у него не встанут волосы дыбом из-за системы релизов. С течением времени, когда Kubernetes захватит большее пространство, переход людей и обучение будет более простым. И за это — плюс.


Мы используем Helm. Это система, которая строится поверх Kubernetes, напоминает пакетный менеджер. Вы можете нажать кнопку, сказать, что хотите установить *Wine* в свою систему. Можно устанавливать и в Kubernetes. Оно работает, автоматически скачает, запустит, и все будет работать. Он позволяет работать с плагинами, клиент-серверная архитектура. Если вы будете с ним работать, рекомендуем запускать один Tiller на namespace. Это изолирует namespace друг от друга, и поломка одного не приведет к поломке другого.

На самом деле система очень сложная. Система, которая должна быть абстракцией более высокого уровня и более простой и понятной, на самом деле не делает понятнее нисколечко. За это минус.

Давайте сравним конфиги. Скорее всего, у вас тоже есть какие-то конфиги, если вы запускаете в продакшне вашу систему. У нас есть своя система, которая называется BOOMer. Я не знаю, почему мы ее так назвали. Она состоит из Puppet, Chef, Ansible, Terraform и всего остального, там большой флакон.

Давайте посмотрим, как оно работает. Вот пример реальной конфигурации, которая сейчас работает в продакшне. Что мы здесь видим?
Во-первых, мы видим, где запускать приложение, во-вторых, что надо запускать, и, в-третьих, как это надо подготовить к запуску. В одном флаконе уже смешаны концепции.

Если мы посмотрим дальше, из-за того, что мы добавили наследование, чтобы сделать более сложные конфиги, мы должны посмотреть на то, что находится в конфиге common, на который ссылаемся. Плюс, мы добавляем настройку сетей, прав доступа, планирование нагрузки. Все это в одном конфиге, который нам нужен для того, чтобы запустить реальное приложение в продакшне, мы смешиваем кучу концепций в одном месте.
Это очень сложно, это очень неправильно, и в этом огромный плюс Kubernetes, потому что в нем вы просто определяете, что запустить. Настройка сети была выполнена при установке Kubernetes, настройка всего provisioning решается с помощью докера — у вас произошла инкапсуляция, все проблемы каким-то образом разделились, и в данном случае в конфиге есть только ваше приложение, и за это плюс.

Давайте посмотрим внимательнее. Здесь у нас есть только одно приложение. Чтобы заработал деплоймент, нужно, чтобы работала еще куча всего. Во-первых, нужно определить сервисы. Каким образом к нам поступают секреты, ConfigMap, доступ к Load Balancer.

Не стоит забывать, что у вас есть несколько окружений. Есть Stage/Prod/Dev. Это все вместе составляет не маленький кусочек, который я показал, а огромный набор конфигов, что на самом деле сложно. За это минус.

Helm-шаблон для сравнения. Он полностью повторяет шаблоны Kubernetes, если есть какой-то файл в Kubernetes с определением деплоймента, то же самое будет в Helm. Вместо конкретных значений для окружения у вас есть шаблоны, которые подставляются из values.
У вас есть отдельно шаблон, отдельно значения, которые должны подставиться в этот шаблон.
Конечно, нужно дополнительно определить различную инфраструктуру самого Helm, притом что у вас в Kubernetes масса конфигурационных файлов, которые нужно перетащить в Helm. Это все очень непросто, за что минус.
Система, которая должна упрощать, на самом деле усложняет. Для меня это явный минус. Либо нужно надстраивать что-то еще, либо не использовать
Давайте пойдем поглубже, мы недостаточно глубоко.

Во-первых, как мы работаем с кластерами. Я прочитал статью Гугла «Borg, Omega и Kubernetes», в ней очень сильно защищают концепцию, что нужно иметь один большой кластер. Я тоже был за эту идею, но, в конце концов, мы от неё ушли. В результате наших споров, используем четыре разных кластера.
Первый кластер e2e, для тестирования самого Kubernetes и тестирования скриптов, разворачивающих окружение, плагины и так далее. Второй, конечно же, prod и stage. Это стандартные концепции. В-третьих, это admin, в котором сгрузилось все остальное — в частности, у нас там CI, и, похоже, из-за него этот кластер будет самым большим всегда.
Тестирований очень много: по коммиту, по merge, все делают кучу коммитов, поэтому кластеры просто громадные.

Мы пытались посмотреть на CoreOS, но не стали ее использовать. У них внутри TF или CloudFormation, и то и другое очень плохо позволяет понимать, что находится внутри state. Из-за этого возникают проблемы при обновлении. Когда вы хотите обновить настройки вашего Kubernetes, к примеру, его версию, можно столкнуться с тем, что обновление происходит не таким образом, не в той последовательности. Это большая проблема стабильности. Это минус.

Во-вторых, когда вы используете Kubernetes, нужно откуда-то скачивать образы. Это может быть внутренний источник, репозиторий, или внешний. Если внутренний, есть свои проблемы. Я рекомендую использовать Docker Distribution, потому что она стабильная, её сделал Docker. Но цена поддержки все равно высокая. Чтобы она работала, нужно сделать ее отказоустойчивой, потому что это единственное место, откуда ваши приложения получают данные для работы.

Представьте, что в самый ответственный момент, когда вы нашли баг на продакшне, у вас репозиторий упал — приложение обновить вы не сможете. Вы должны сделать его отказоустойчивым, причем от всех возможных проблем, которые только могут быть.
Во-вторых, если масса команд, у каждой свой образ, их накапливается очень много и очень быстро. Можно убить свой Docker Distribution. Нужно делать чистку, удалять образы, выносить информацию для пользователей, когда и что вы будете чистить.
В-третьих, при больших образах, скажем, если у вас есть монолит, размер образа будет очень большим. Представьте, что нужно зарелизить на 30 нод. 2 гигабайта на 30 нод — посчитайте, какой поток, как быстро он скачается на все ноды. Хотелось бы, чтобы нажал кнопку, и тут же зарелизилось. Но нет, нужно сначала дождаться, пока закачается. Надо как-то ускорять эту закачку, а все это работает с одной точки.

При внешних репозиториях есть те же проблемы с garbage collector, но чаще всего это делается автоматически. Мы используем Quay. В случае с внешними репозиториями — это сторонние сервисы, в которых большинство образов публичные. Чтобы не было публичных образов, нужно обеспечивать доступ. Нужны секреты, права доступа к образам, все это специально настраивать. Конечно, это можно автоматизировать, но в случае локального запуска Куба на своей системе вам все равно его придется настраивать.

Для установки Kubernetes мы используем kops. Это очень хорошая система, мы ранние пользователи с тех времен, когда они еще в блоге не писали. Она не до конца поддерживает CoreOS, хорошо работает с Debian, умеет автоматически конфигурировать мастер-ноды Kubernetes, работает с аддонами, есть способность делать нулевое время простоя во время обновления Kubernetes.
Все эти возможности из коробки, за что большой и жирный плюс. Отличная система!


По ссылкам можно найти много вариантов для настройки сети в Kubernetes. Их реально много, у всех свои достоинства и недостатки. Kops поддерживает только часть из этих вариантов. Можно, конечно, донастроить, чтобы работал через CNI, но лучше использовать самые популярные и стандартные. Они тестируются сообществом, и, скорее всего, стабильны.

Мы решили использовать Calico. Он заработал хорошо с нуля, без большого количества проблем, использует BGP, быстрее инкапсуляции, поддерживает IP-in-IP, позволяет работать с мультиклаудами, для нас это большой плюс.
Хорошая интеграция с Kubernetes, с помощью меток разграничивает трафик. За это — плюс.
Я не ожидал, что Calico дойдет до состояния, когда включил, и все работает без проблем.

High Availability, как я говорил, мы делаем через kops, можно использовать 5–7–9 нод, мы используем три. Сидим на etcd v2, из-за бага не обновлялись на v3. Теоретически, это позволит ускорить какие-то процессы. Я не знаю, сомневаюсь.

Хитрый момент, у нас есть специальный кластер для экспериментов со скриптами, автоматическая накатка через CI. Мы считаем, что у нас есть защита от совершенно неправильных действий, но для каких-то специальных и сложных релизов мы на всякий случаем делаем снапшоты всех дисков, мы не делаем бэкапов каждый день.


Авторизация — вечный вопрос. Мы в Kubernetes используем RBAC — доступ, основанный на ролях. Он намного лучше ABAC, и если вы его настраивали, то понимаете, о чем я. Посмотрите на конфиги — удивитесь.
Мы используем Dex, провайдер OpenID, который из какого-то источника данных выкачивает всю информацию.
А для того, чтобы залогиниться в Kubernetes, есть два пути. Нужно как-то прописать в .kube/config, куда идти и что он может делать. Нужно этот конфиг как-то получить. Либо пользователь идет в UI, где он логинится, получает конфиги, копипастит их в /config и работает. Это не очень удобно. Мы постепенно перешли к тому, что человек заходит в консоль, нажимает на кнопку, логинится, у него автоматически генерируются конфиги и складываются в нужное место. Так гораздо удобнее, мы решили действовать таким образом.

В качестве источника данных мы используем Active Directory. Kubernetes позволяет через всю структуру авторизации протащить информацию о группе, которая транслируется в namespace и роли. Таким образом сразу разграничиваем, куда человек может заходить, куда не имеет права заходить и что он может релизить.

Чаще всего людям нужен доступ к AWS. Если у вас нет Kubernetes, есть машина с запущенным приложением. Казалось бы, все что нужно — получать логи, смотри их и все. Это удобно, когда человек может зайти на свою машину и посмотреть, как работает приложение. С точки зрения Kubernetes все работает в контейнерах. Есть команда `kubectl exec` — залезть в контейнер в приложение и посмотреть, что там происходит. Поэтому на AWS-инстансы нет необходимости ходить. Мы запретили доступ для всех, кроме инфракоманды.
Более того, мы запретили долгоиграющие админские ключи, вход через роли. Если есть возможность использовать роль админа — я админ. Плюс мы добавили ротацию ключей. Это удобно конфигурировать через команду awsudo, это проект на гитхабе, очень рекомендую, позволяет работать, как с sudo-командой.



Квоты. Очень хорошая штука в Kubernetes, работает прямо из коробки. Вы ограничиваете какие-то namespace, скажем, по количеству объектов, памяти или CPU, которое можете потреблять. Я считаю, что это важно и полезно всем. Мы пока не дошли до памяти и CPU, используем только по количеству объектов, но это все добавим.
Большой и жирный плюс, позволяет сделать много хитрых вещей.


Масштабирование. Нельзя смешивать масштабирование внутри Kubernetes и снаружи Kubernetes. Внутри Kubernetes делает масштабирование сам. Он может увеличивать pod’ы автоматически, когда идет большая нагрузка.
Здесь я говорю про масштабирование самих инстансов Kubernetes. Это можно делать с помощью AWS Autoscaler, это проект на гитхабе. Когда вы добавляете новый pod и он не может стартовать, потому что ему не хватает ресурсов на всех инстансах, AWS Autoscaler автоматически может добавить ноды. Позволяет работать на Spot-инстансах, мы пока это не добавляли, но будем, позволяет сильно экономить.


Когда у вас очень много пользователей и приложений у пользователей, нужно как-то за ними следить. Обычно это телеметрия, логи, какие-то красивые графики.

У нас по историческим причинам был Sensu, он не очень подошел для Kubernetes. Нужен было более метрикоориентированный проект. Мы посмотрели на весь TICK стек, особенно InfluxDB. Хороший UI, SQL-подобный язык, но не хватило немножко фич. Мы перешли на Prometheus.
Он хорош. Хороший язык запросов, хорошие алерты, и все из коробки.

Чтобы посылать телеметрию, мы использовали Cernan. Это наш собственный проект, написанный на Rust. Это единственный проект на Rust, который уже год работает в нашем продакшне. У него есть несколько концепций: есть концепция источника данных, вы конфигурируете несколько источников. Вы конфигурируете, куда данные будете сливать. У нас есть конфигурация фильтров, то есть перетекающие данные можно каким-то образом перерабатывать. Вы можете преобразовывать логи в метрики, метрики в логи, все, что хотите.
При том, что у вас несколько входов, несколько выводов, и вы показываете, что куда идет, там что-то вроде большой системы графов, получается довольно удобно.

Мы сейчас плавно переходим с текущего стека Statsd/Cernan/Wavefront на Kubernetes. Теоретически, Prometheus хочет сам забирать данные из приложений, поэтому во все приложения нужно добавлять endpoint, из которого он будет забирать метрики. Cernan является передаточным звеном, должен работать везде. Тут две возможности: запускать на каждом инстансе Kubernetes, можно с помощью Sidecar-концепции, когда в вашем поле данных работает еще один контейнер, который посылает данные. Мы делаем и так, и так.

У нас прямо сейчас все логи шлются в stdout/stderr. Все приложения рассчитаны на это, поэтому одно из критических требований, чтобы мы не уходили от этой системы. Cernan посылает данные в ElasticSearch, события всей системы Kubernetes посылают туда же с помощью Heapster. Это очень хорошая система, рекомендую.
После этого все логи вы можете посмотреть в одном месте, к примеру, в консоли. Мы используем Kibana. Есть замечательный продукт Stern, как раз для логов. Он позволяет смотреть, раскрашивает в разные цвета разные поды, умеет видеть, когда один под умер, а другой рестартовал. Автоматически подхватывает все логи. Идеальный проект, очень его рекомендую, это жирный плюс Kubernetes, здесь все хорошо.


Секреты. Мы используем S3 и KMS. Думаем о переходе на Vault или секреты в самом Kubernetes. Они были в 1.7 в состоянии альфы, но что-то делать с этим надо.

Мы добрались до интересного. Разработка в Kubernetes вообще мало рассматривается. В основном говорится: «Kubernetes — идеальная система, в ней все хорошо, давайте, переходите».
Но на самом деле бесплатный сыр только в мышеловке, а для разработчиков в Kubernetes — ад.

Не с той точки зрения, что все плохо, а с той, что надо немножко по-другому взглянуть на вещи. Я разработку в Kubernetes сравниваю с функциональным программированием: пока ты его не коснулся, ты думаешь в своем императивном стиле, все хорошо. Для того, чтобы разрабатывать в функциональщине, надо немножко повернуть голову другим боком — здесь то же самое.
Разрабатывать можно, можно хорошо, но нужно смотреть на это иначе. Во-первых, разобраться с концепцией Docker Way. Это не то чтобы сложно, но до конца ее понять довольно проблематично. Большинство разработчиков привыкло, что они заходят на свою локальную, удаленную или виртуальную машину по SSH, говорят: «Давай я тут кое-что подправлю, подшаманю».
Ты говоришь ему, что в Kubernetes так не будет, потому что у тебя read only инфраструра. Когда ты хочешь обновить приложение, пожалуйста, сделай новый образ, который будет работать, а старый, пожалуйста, не трогай, он просто умрет. Я лично работал над внедрением Kubernetes в разные команды и вижу ужас в глазах людей, когда они понимают, что все старые привычки придется полностью отбросить, придумать новые, новую систему какую-то, а это очень сложно.
Плюс придется много делать выборов: скажем, когда делаешь какие-то изменения, если разработка локальная, нужно как-то коммитить в репозиторий, затем репозиторий по pipeline прогоняет тесты, а потом говорит: «Ой, тут опечатка в одном слове», нужно все делать локально. Монтировать каким-то образом папку, заходить туда, обновлять систему, хотя бы компилировать. Если тесты запускать локально неудобно, то может коммитить в CI хотя бы, чтобы проверять какие-то локальные действия, а затем уже отправлять их в CI на проверку. Эти выборы достаточно сложные.
Особенно сложно, когда у вас развесистое приложение, состоящее из ста сервисов, а чтобы работал один из них, нужно обеспечить работу всех остальных рядышком. Нужно либо эмулировать окружение, либо как-то запускать локально. Весь этот выбор нетривиальный, разработчику об этом нужно сильно думать. Из-за этого возникает негативное отношение к Kubernetes. Он, конечно, хорош —, но он плох, потому что нужно много думать и изменять свои привычки.
Поэтому здесь три жирных кошки перебежали через дорогу.


Когда мы смотрели на Kubernetes, старались понять, может, есть какие-то удобные системы для разработки. В частности, есть такая вещь, как Deis, наверняка вы все про нее слышали. Она очень проста в использовании, и мы проверили, на самом деле, все простые проекты очень легко переходят на Deis. Но проблема в том, что более сложные проекты могут на Deis не перейти.
Как я уже рассказал, мы перешли на Helm Charts. Но единственная проблема, которую мы сейчас видим — нужно очень много хорошей документации. Нужны какие-то How-to, какие-то FAQ, чтобы человеку быстро стартовать, скопировать текущие конфиги, вставить свои, поменять названия для того, чтобы все было правильно. Это тоже важно понимать заранее, и нужно это все делать. У меня здесь перечислены общие наборы инструментов для разработки, всего этого не коснусь, кроме миникуба.

Minikube — очень хорошая система, в том смысле, что хорошо, что она есть, но плохо, что в таком виде. Она позволяет запускать Kubernetes локально, позволяет видеть все на вашем лэптопе, не надо никуда ходить по SSH и так далее.
Я работаю на MacOS, у меня Mac, соответственно, чтобы запускать локальный апп, мне нужно запускать локально докер. Это сделать никак нельзя. В итоге нужно либо запускать virtualbox, либо xhyve. Обе вещи, фактически, эмуляции поверх моей операционной системы. Мы используем xhyve, но рекомендуем использовать VirtualBox, поскольку очень много багов, их приходится обходить.
Но сама идея, что есть виртуализации, а внутри виртуализации запускается еще один уровень абстракции для виртуализации, какая-то нелепая, бредовая. В целом, хорошо, что он как-то работает, но лучше бы его еще доделали.


CI не относится напрямую к Kubernetes, но это очень важная система, особенно, если у вас есть Kubernetes, если ее интегрировать, можно получать очень хорошие результаты. Мы использовали Concourse для CI, очень богатая функциональность, можно строить страшные графы, что, откуда, как запускается, от чего зависит. Но разработчики Concourse очень странно относятся к своему продукту. Скажем, при переходе от одной версии на другую они поломали обратную совместимость и большинство плагинов не переписали. Более того, документацию не дописали, и, когда мы попытались что-то сделать, вообще ничего не заработало.
Документации мало вообще во всех CI, приходится читать код, и, в общем, мы отказались от Concourse. Перешли на Drone.io — он маленький, очень легкий, юркий, функциональности намного меньше, но чаще всего ее хватает. Да, большие и увесистые графы зависимости — было бы удобно иметь, но и на маленьких тоже можно работать. Тоже мало документации, читаем код, но это ок.
Каждая стадия pipeline работает в своем докер-контейнере, это позволяет сильно упростить переход на Kubernetes. Если есть приложение, которое работает на реальной машине, для того, чтобы добавить в CI, используете докер-контейнер, а после него перейти в Kubernetes проще простого.
У нас настроен автоматический релиз admin/stage-кластера, в продакшн-кластер пока боимся добавлять настройку. Плюс есть система плагинов.
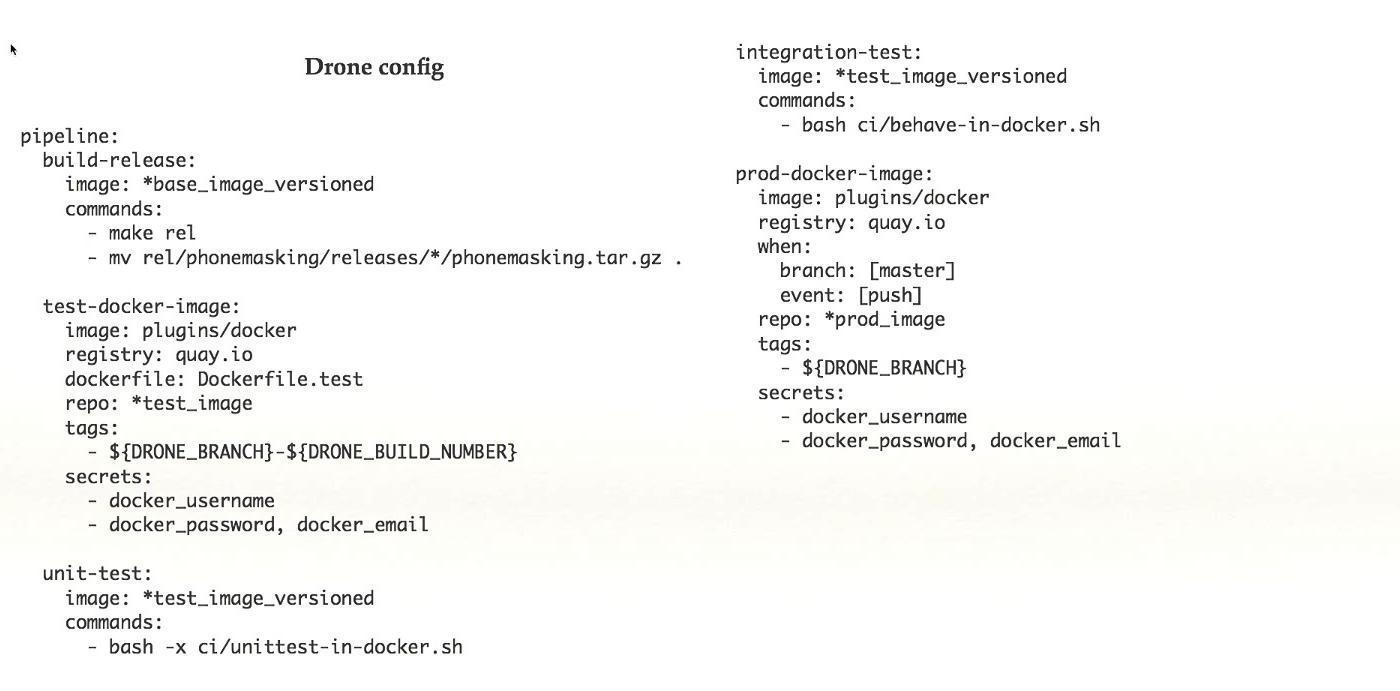
Это пример простого Drone-конфига. Взято из готовой рабочей системы, в данном случае есть пять шагов в pipeline, каждый шаг что-то делает: собирает, тестирует и так далее. При том наборе фич, что есть в Drone, я считаю, что это хорошая штука.

Мы много спорили о том, сколько иметь кластеров: один или несколько. Когда мы пришли к идее с несколькими кластерами, начали дальше работать в этом направлении, создали какие-то скрипты, понаставили кучу других кубиков к нашему Kubernetes. После этого пришли к Google и попросили консультации, все ли сделали так, может, нужно что-то исправить.
Google согласился, что идея одного кластера неприменима в Kubernetes. Есть много недоделок, в частности, работа с геолокациями. Получается, что идея верна, но говорить о ней пока рано. Возможно, попозже. Пока может помочь Service Mesh.

В целом, если хотите посмотреть, как работает наша система, обратите внимание на Geodesic. Это продукт, похожий на тот, что делаем мы. Он с открытыми исходниками, очень похожий выбор концепции дизайна. Мы думаем о том, чтобы объединиться и, возможно, использовать их.

Да, в нашей практике работы с Kubernetes тоже есть проблемы.
Есть боль с локальными именами, с сертификатами. Есть проблема с загрузками больших образов и их работой, возможно, связанная с файловой системой, мы туда еще не копали. Есть уже три разных способа устанавливать расширения Kubernetes. Мы меньше года работаем над этим проектом, и у нас уже три разных способа, годовые кольца растут.

Давайте подобьем все минусы.
Итак, я считаю, что один из главных минусов — большой объем информации на изучение, причем не только новых технологий, но и новых концепций и привычек. Это как новый язык выучить: в принципе, несложно, но сложно немного повернуть голову всем пользователям. Если раньше не работали с подобными концепциями — перейти на Kubernetes тяжело.
Kubernetes будет лишь небольшой частью вашей системы. Все думают, что установят Kubernetes, и всё сразу заработает. Нет, это маленький кубик, и таких кубиков будет много.
Некоторые приложения в принципе сложно запускать на Kubernetes — и лучше не запускать. Также очень тяжелые и большие конфигурационные файлы, и в концепциях поверх Kubernetes они ещё сложнее. Все текущие решения — сырые.
Все эти минусы, конечно, отвратительные.
Компромиссы и сложный переход создают негативный образ Kubernetes, и как с этим бороться — я не знаю. Мы не смогли сильно побороть, есть люди, которые ненавидят все это движение, не хотят и не понимают его плюсы.
Для того, чтобы запустить Minikube, вашу систему, чтобы все работало, придется сильно постараться. Как вы видите, минусов немало, и те, кто не хочет работать с Kubernetes имеют свои причины. Если не хотите слышать про плюсы — закройте глаза и уши, потому что дальше пойдут они.

Первый плюс — с течением времени придется все меньше учить новичков. Часто бывает так, что, придя в систему, новичок начинает вырывать все волосы, потому что первые 1–2 месяца он пытается разобраться, как это все зарелизить, если система большая и живет долго, наросло много годовых колец. В Kubernetes все будет проще.
Во-вторых, Kubernetes не сам делает, но позволяет сделать, короткий цикл релиза. Коммит создал CI, CI создал образ, автоматически подкачался, ты нажал кнопку, и все ушло в продакшн. Это сильно сокращает время релиза.
Следующее — разделение кода. Наша система и большинство ваших систем в одном месте собирают конфиги разных уровней, то есть у вас инфраструктурный код, бизнес код, все логики смешаны в одном месте. В Kubernetes такого не будет из коробки, выбор правильной концепции помогает этого избежать заранее.
Большое и очень активное сообщество, а значит, большое количество изменений. Большинство из того, о чем я упоминал, за последние два года стало настолько стабильным, что их можно выпускать в продакшн. Возможно, часть из них появилась пораньше, но была не очень стабильной.
Я считаю большим плюсом, что в одном месте можно видеть как логи приложения, так и логи работы Kubernetes с вашим приложением, что неоценимо. И нет доступа на ноды. Когда мы убрали у пользователей доступы на ноды, это сразу срезало большой класс проблем.

Вторая часть плюсов немного более концептуальна. Большая часть сообщества Kubernetes видят технологическую часть. Но мы увидели концептуальную менеджмент-часть. После того, как вы перейдете на Kubernetes, и если это все правильно настроить, инфракоманда (или бэкенд — я не знаю, как у вас это называется правильно) больше не нужна для того
