[Перевод] Оценка ThunderX2 от Cavium: сбылась мечта об Arm сервере (часть 2)
Первая часть «Оценка ThunderX2 от Cavium: сбылась мечта об Arm сервере» — здесь
Конфигурация и методология тестирования
Для обзора ThunderX2 все наши испытания проводились на Ubuntu Server 17.10, ядро Linux 4.13 64 бит. Обычно мы используем версию LTS, но поскольку Cavium поставляется именно с этой версией Ubuntu, мы не стали рисковать, меняя ОС. Дистрибутив Ubuntu включает компилятор GCC 7.2.

Вы заметите, что обьем DRAM варьируется в наших конфигурациях сервера. Причина проста: система Intel имеет 6 каналов памяти, а в ThunderX2 от Cavium — 8 каналов памяти.
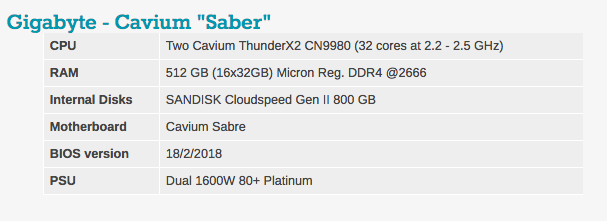
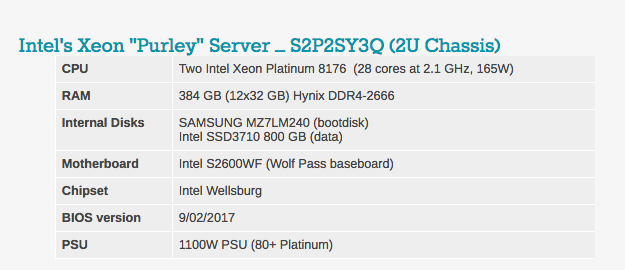
Типичные настройки BIOS можно увидеть ниже. Стоит отметить, что hyperthreading и технология виртуализации Intel включены.
Другие примечания
На оба сервера подается питание по европейскому стандарту — 230 В (максимум 16 ампер). Температура воздуха в помещении контролируется и поддерживается на уровне 23 ° C нашими приборами Airwell CRAC.
Потребление энергии
Стоит упомянуть, что система Gigabyte «Saber» потребляла 500 Вт, если просто работала под управлением Linux (то есть в основном бездействовала). Однако при нагрузке система потребляет около 800 Вт, что впринципе соответствовало нашим ожиданиям, поскольку у нас есть два 180 Вт TDP-чипа внутри. Как это обычно бывает для ранних тестовых систем, мы не можем проводить точные сравнения мощности.
Фактически, Cavium утверждает, что актуальные системы от HP, Gigabyte и других будут намного эффективнее. Система тестирования «Sabre», которая использовалась, имела несколько проблем с управлением питания: неправильное управление прошивкой вентилятора, ошибка BMC и блок питания слишком большой мощности (1600 Вт).
Подсистема памяти: пропускная способность
Измерить полный потенциал пропускной способности системы с использованием теста John McCalpin’s Stream bandwidth benchmark на последних процессорах становится все труднее, поскольку количество каналов ядра и памяти растет. Как видно из приведенных ниже результатов, оценить пропускную способность непросто. Результат сильно зависит от выбранных настроек.

Теоретически, ThunderX2 имеет на 33% большую пропускную способность, чем Intel Xeon, поскольку SoC располагает 8 каналами памяти по сравнению с шестью каналами Intel. Эти цифры высокой пропускной способности достигаются только в очень специфических условиях, и требуют некоторого тюнинга, чтобы избежать использования удаленной памяти. В частности, мы должны гарантировать, что потоки не переносятся из одного сокета в другой.
Для начала мы попытались достичь наилучших результатов на обеих архитектурах. В случае Intel компилятор ICC всегда выдавал лучшие результаты с некоторыми оптимизациями низкого уровня внутри потоковых циклов. В случае Cavium мы следовали инструкциям Cavium. Грубо говоря, полученная картина — представление о том, какую пропускную способность эти процессоры могут достичь на пиках. Чтобы быть честным с Intel, с идеальными настройками (AVX-512) вы сможете достичь 200 ГБ / с.
Тем не менее очевидно, что система ThunderX2 может обеспечить от 15 до 28% большей пропускной способности своим ядрам процессора. Результат составляет 235 ГБ / с, или около 120 ГБ / с на разъем. Это, в свою очередь, примерно в 3 раза больше, чем у оригинального ThunderX.
Подсистема памяти: задержка
Хотя измерения полосы пропускания относятся только к небольшой части рынка серверов, почти каждое приложение сильно зависит от латентности подсистемы памяти. В попытках измерить латентность кэша и памяти мы использовали LMBench. Данные, которые мы хотим видеть в итоге — «Задержка при случайной нагрузке, шаг = 16 байтов». Обратите внимание, что мы выражаем латентность L3 и временную задержку DRAM в наносекундах, поскольку у нас нет точных значений часов L3-кэша.
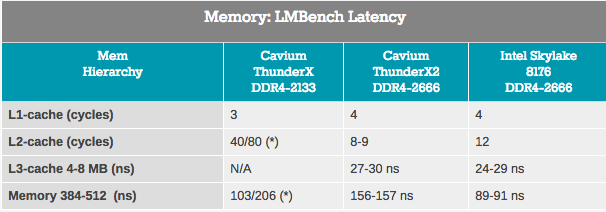
Доступ к L2-кэшу ThunderX2 осуществляется с очень малой задержкой, а при использовании одного потока L3-кэш выглядит конкурентом комплексному кэшу L3 от Intel. Однако, когда мы добрались до DRAM, Intel продемонстрировал значительно меньшую задержку.
Подсистема памяти: TinyMemBench
Чтобы получить более глубокое понимание соответствующих архитектур, был использован опен-сорс тест TinyMemBench. Исходный код был скомпилирован с помощью GCC 7.2, а уровень оптимизации был установлен на »-O3». Стратегия тестирования хорошо описана в руководстве бенчмарка:
Среднее время измеряется для случайных обращений к памяти в буферах разных размеров. Чем больше буфер, тем значительнее относительный вклад промахов кэша TLB, L1 / L2 и обращений к DRAM. Все числа представляют дополнительное время, которое необходимо добавить в латентность кэша L1 (4 цикла).
Мы тестировали с одним и двумя случайными чтениями (без огромных страниц), так как хотелось видеть, как система памяти справилась с несколькими запросами на чтение.
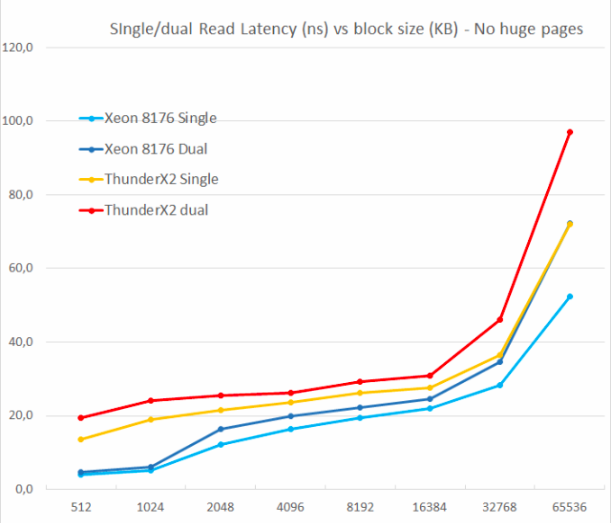
Одним из основных недостатков оригинального ThunderX была невозможность поддержки multiple outstanding misses. Параллелизм уровня памяти является важной особенностью для любого высокопроизводительного современного ядра процессора: с его помощью он избегает промахов в кэше, которые могут вызвать «голод» бэк-энда. Таким образом, неблокирующий кэш является ключевой функцией для больших ядер.
ThunderX2 не страдает от этой проблемы вообще, благодаря неблокирующему кэшу. Так же, как и у ядра Skylake в Xeon 8176, второе чтение увеличивает общее время ожидания только на 15–30%, а не на 100%. Согласно TinyMemBench, ядро Skylake имеет ощутимо лучшие показатели задержки. Точку отсчета в 512 Кбайт легко объяснить: ядро Skylake все еще извлекает из своего быстрого L2, а ядро ThunderX2 должно получить доступ к L3. Но цифры в 1 и 2 МБ показывают, что префетчеры Intel обеспечивают серьезное преимущество, поскольку время ожидания — это среднее значение для L2 и L3-кэша. Показатели задержки похожи в диапазоне 8 до 16 Мбайт, но как только мы выходим за пределы L3 (64 МБ), Skylake от Intel предлагает более низкие латенси памяти.
Однопоточная производительность: SPEC CPU2006
Приступая к измерению фактической вычислительной производительности, мы начнем с пакета SPEC CPU2006. Знающие читатели укажут, что SPEC CPU2006 устарел тогда, когда появился SPEC CPU2017. Но из-за ограниченного времени тестирования и того факта, что мы не смогли повторно протестировать ThunderX, мы решили придерживаться CPU2006.
Учитывая, что SPEC практически настолько же бенчмарк компилятора, как и аппаратной части, мы считаем, что будет уместно сформулировать нашу философию тестирования. Нужно оценить реальные показатели, а не раздуть результаты теста. Поэтому важно создать, насколько это возможно, условия «как в реальном мире» со следующими настройками (конструктивная критика по этому вопросу приветствуется):
- 64 bit gcc: наиболее используемый компилятор в Linux, хороший компилятор, который не пытается «прервать» тесты (libquantum …)
- -Ofast: оптимизация компилятора, которую могут использовать многие разработчики
- -fno-strict-aliasing: необходим для компиляции некоторых подтестов
- base run: каждый подтест компилируется одинаково
Во-первых, нужно измерить производительность в приложениях, в которых по некоторым причинам из-за «недружественной многопоточной среде» задачи возникает задержка. Во-вторых, необходимо понять, насколько хорошо архитектура ThunderX LLC работает с одним потоком по сравнению с архитектурой Skylake от Intel. Обратите внимание, что в той конкретной модели Skylake можно разогнать частоту до 3,8 ГГц. Чип будет работать на частоте 2,8 ГГц практически во всех ситуациях (28 потоков активны) и будет поддерживать 3,4 ГГц с 14 активными потоками.
В целом, Cavium позиционирует ThunderX2 CN9980 ($ 1795) как «лучший, чем 6148» ($ 3072), процессор, работающий на частоте 2,6 ГГц (20 потоков) и достигающий 3,3 ГГц без особых проблем (до 16 потоков активно). С другой стороны, у Intel-SKU будет значительное 30-процентное преимущество в тактовой частоте во многих ситуациях (3,3 ГГц против 2,5 ГГц).
Cavium решил компенсировать возникший дефицит частоты количеством ядер, предлагая 32 ядра — что на 60% больше, чем у Xeon 6148 (20 ядер). Стоить отметить, что большее количество ядер приведет к уменьшению отдачи во многих приложениях (например, Amdahl). Поэтому, если Cavium хочет пошатнуть доминирующее положение Intel с помощью ThunderX2, каждое ядро должно, по крайней мере, предлагать конкурентоспособную производительность в реальном использовании. Или в этом случае ThunderX2 должен обеспечить как минимум 66% (2,5 против 3,8) однопотоковой производительности Skylake.
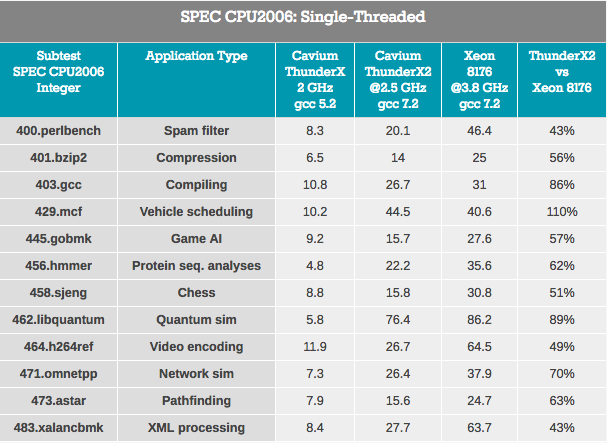
Резуьтаты размыты, поскольку ThunderX2 работает с кодом ARMv8 (AArch64), а Xeon использует код x86–64.
Тесты на отслеживание указателей — обработка XML (также большие буферы OoO) и поиск путей, которые обычно зависят от большого L3-кэша, чтобы снизить влияние латентности доступа, являются наихудшими для ThunderX2. Можно предположить, что более высокая латентность системы DRAM ухудшает производительность.
Рабочие нагрузки, в которых влияние прогноза ветвления выше (по крайней мере, на x86–64: более высокий процент выбора ошибочной ветви) — gobmk, sjeng, hmmer — не являются лучшими нагрузками для на ThunderX2.
Также стоит отметить, что perlbench, gobmk, hmmer и инструкции h264ref, как известно, извлекают выгоду из большего L2-кэша (512 КБ) Skylake. Мы показываем вам всего несколько кусочков головоломки, но вместе они могут помочь собрать картину воедино.
С положительной стороны, ThunderX2 хорошо зарекомендовал себя на gcc, который работает в основном внутри L1 и L2-кэша (таким образом, полагаясь на низкую задержку L2), и влияние производительности предсказателя ветвления минимально. В целом лучший подтест для TunderX2 — mcf (распределение транспортных средств в общественном транспорте), который, как известно, почти полностью пропускает кэш данных L1, полагаясь на L2-кэш, а это сильная сторона ThunderX2. Mcf также требователен к пропускной способности памяти. Libquantum — тест, у кого наибольшая потребность в пропускной способности памяти. Тот факт, что Skylake предлагает довольно посредственную однопоточную полосу пропускания, вероятно, также является причиной того, что ThunderX2 настолько хорошо показал себя на libquantum и mcf.
SPEC CPU2006 Cont: производительность на основе ядра с SMT
Выходя за рамки однопоточной производительности, многопоточная производительность в пределах одного ядра так же должна быть рассмотрена. Архитектура процессора Vulcan была изначально разработана для использования SMT4, чтобы поддерживать свои ядра нагруженными и повысить общую пропускную способность, и об этом мы сейчас и поговорим.
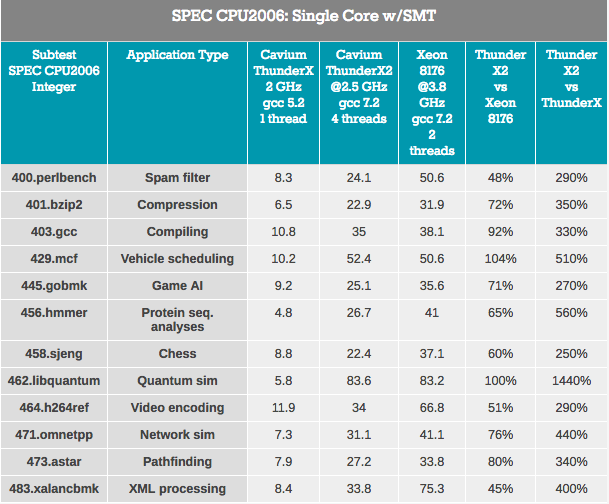
Прежде всего, ядро ThunderX2 «претерпело» много значительных улучшений по сравнению с первым ядром ThunderX. Даже с учетом libquantum — этот тест может легко работать в 3 раза быстрее на старшем ядре ThunderX после некоторых улучшений и оптимизации компилятора. Что же, новый ThunderX2 не менее чем в 3,7 раза быстрее, чем его старший брат. Такое превосходство IPC нивелирует любые преимущества предыдущего ThunderX.
Рассматривая влияние SMT, в среднем мы видим, что 4-сторонняя SMT улучшает производительность ThunderX2 на 32%. Это составляет от 8% для кодирования видео до 74% для Pathfinding. Intel тем временем получает прирост на 18% от своего 2-way SMT, от 4% до 37% в тех же самых сценариях.
В целом, повышение производительности ThunderX2 составляет 32%, что очень неплохо. Но тут возникает очевидный вопрос: чем он отличается от других архитектур SMT4? Например IBM POWER8, который также поддерживает SMT4, показывает 76% -ный прирост в том же сценарии.
Однако это не совсем сравнение подобного с подобным, поскольку чип IBM имеет гораздо более широкий бек-энд: он может обрабатывать 10 инструкций, в то время как ядро ThunderX2 ограничено 6 инструкциями за цикл. Ядро POWER8 более прожорливо: процессор мог вместить только 10 из этих «ультрашироких» ядер в бюджет мощности 190 Вт при 22 нм процессе. Вероятнее всего дальнейшее увеличение производительности от использования SMT4 потребует еще более крупных ядер и, что в свою очередь серьезно повлияет и на количество ядер, доступных внутри ThunderX2. Тем не менее интересно посмотреть на этот 32% прирост в перспективе.
В седующей (3) части:
- Производительность Java
- Производительность Java: огромные страницы
- Apache Spark 2.x Бенчмаркинг
- Итог
Спасибо, что остаетесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5–2650v4 128GB DDR4 6×480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
