101 способ приготовления RabbitMQ и немного о pipeline архитектуре
Павел Филонов (Positive Technologies)

В данном докладе я хочу поговорить о пересечении RabbitMQ и Pipeline архитектуры, и о том, как оно связанно с работой нашей компании.
Сначала немного в качестве пролога. Это приятная часть.

Сценка, разворачивающаяся в будний день в офисе, наводит нас на очень приятное размышление. Перед нами встает шикарная задача, новая система. Мало что так сильно будоражит ум инженера, как просьба разработать новую систему. Не починить что-то старое, не адаптировать что-то старое, а именно что-то создать, в каком-то смысле практически с нуля.
Вместе с такой задачей приходит и целая серия проблем.
Проблема №1. Продолжаем сценку.
Вам приносят вот это:

Вы смотрите, спрашиваете: «А где требования?».
Вам показывают: «Ну, вот же они!» (см. на слайде).
Это подчас и есть требования для новой системы. Почти всем приходилось работать с такими формулировками, вы понимаете проблему, которая с этим связана. Но подчас с этого надо начинать. Давайте попробуем начать.
Был замечательный доклад про NLP-обработку естественных языков, здесь она очень поможет нам, нам нужно из этого связного текста выделить самое зерно. Я попробую сделать это так:

Выделить что-то ключевое, что-то, что поможет сделать нам правильный выбор, и правильно построить ту систему, которую нас просят.
Первое, на что я хотел бы обратить особое внимание — это слово «события». Я в каком-то смысле хочу противопоставить их слову «запрос» — request, чтобы показать разницу. Когда мы говорим про request (запрос), с request’ом всегда связан кто-то, кто сидит на той стороне, тот, кто его отправил, очень нетерпеливый человек, робот, браузер, программа, он ждет от нас ответа. Он ждет от нас ответа быстро. Это его самое большое желание — получить ответ, получить его быстро. Это когда мы говорим о запросах.
Когда мы говорим об обработке событий, тут немножко другой шаблон подходит. Нет этого нетерпеливого робота, человека, который запрос отправил. Есть просто система, которая засылает в нас события, логи, метрики, статистики — достаточно большой объем, сетевой трафик… От нас не требуют мгновенного ответа на какой-то вопрос. От нас просят суметь много и быстро их обработать, обработать их по-разному. Это самое больное место — мы не можем подчас заранее предсказать, что от нас будут просить — что-то сагрегировать, подсчитать интенсивность, что-то просуммировать, скорее всего, в конечном счете, куда-то это сохранить. Но самое интересное — многие сталкивались с тем, что начали решать задачу, идет активная разработка, а потом прибегают в середине: «А еще, пожалуйста, добавьте вот это!».
Когда вас предупреждают сразу о том, что такое будет происходить, то желательно в архитектуру вашей системы это заложить как требование, чтоб она могла гибко меняться и актуализироваться под то, что вас будут просить сделать.
«Из разных источников» — это такой нюанс, что нам нужно будет уметь поддерживать разные протоколы на вход.
«Сделать прототип» — очень сейчас любят, очень любят, чтобы что-то быстро сделали и что-то быстро показали. Кто согласен с тем, что прототипы потом надо выкидывать? А кому приходилось потом их пускать в продакшн? Это тоже проблема, и к ней надо быть готовым. И если есть такая возможность, желательно заложить эту проблему сразу: вы сделаете прототип, потом вы начнете его выкидывать, но вы не сможете сделать это быстро — очень трудно что-то взять и все быстро переписать на что-то более основательное. Скорее всего, его придется заменять по частям — чуть было неживую систему, выдирать из нее одни куски и заменять их другими функционально полностью эквивалентными, но уже более основательными…
«Должно работать хорошо и всюду» — это я даже не выделяю, это понятно. По поводу «всюду» — сложный момент. Кто сталкивался с разработкой под разные операционные системы? Это большая проблема, она может очень сильно ограничить круг ваших решений и это нужно тоже учитывать сразу же при проектировании.
Мы попытались выделить зерно, и мы на него сейчас будем очень активно опираться. Потому что встает следующая проблема.

Ко мне часто прибегают и спрашивают: «Скажи, а как ты это придумал?». Я смотрю на вопрошающего и говорю: «Знаете, я вообще очень мало чего придумываю сам, практически на любую задачу, которую мне приносят, у меня возникает сразу целый ворох решений — 3, 5, 10 и больше. Самая моя главная проблема — это не придумать решение, а выбрать наиболее адекватное, наиболее подходящее данной задаче». Я обычно отвечаю такой шуткой, что все уже придумано за нас, нам как инженерам, на мой взгляд, современным инженерам, скорее нужно уметь делать правильный осознанный выбор, с которым мы сталкиваемся даже на самом первом шаге.
Мы хотим создать систему. У нее должна быть архитектура. Красивое слово. Обычно оно выражается в картинках, вот я здесь попробовал представить картинки некоторых самых стандартных шаблонов архитектур, из которых строятся разные системы.

Я думаю, каждый из вас сейчас отправит себя в какую-то из частей этой схемы. Кто-то скажет: мы находимся в левом верхнем углу, а мы работаем в правом верхнем углу, кто-то работает посерединке, каждый себя ассоциирует с той или иной картинкой.
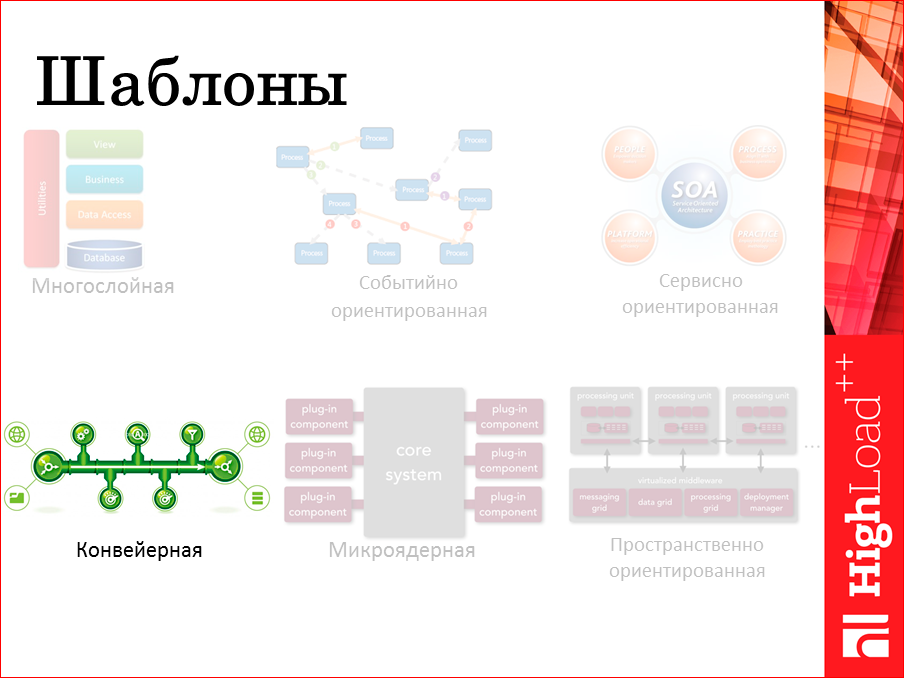
Конкретно в этом докладе я буду рассказывать про конвейерную архитектуру как интересный способ и подход именно к обработке событий. Когда нет этой другой стороны, жаждущей ответа на запрос, когда в каком-то очень абстрактном смысле, все что нам нужно взять — это прогнать наши данные через целую серию обработки и в итоге куда-то их сохранить. И желательно делать это как можно быстрее. Вот, «как можно быстрее» требует детального разбора.
Где мы обычно замедляемся? Где обычно наши узкие места? Есть два самых основных критерия — это процессор CPU-bound и вывод I/O-bound. Причем, на удивление, часто мы не упираемся в сеть, мы не упираемся иногда в гигабиты, иногда даже в 10 гигабит, мы упираемся просто в то, что нам нужно ждать. Особенно это хорошо прослеживается на архитектурах, построенных на основе «запрос-ответ» — мы отправили запрос, мы ждем ответ. В плохом случае — мы просто отдыхаем, в хорошем смысле — мы пытаемся как-то переключиться на другую задачу, позаниматься ей, потом вернуться назад. Вот, если не надо ждать, как было бы здорово — не надо даже переключаться на другую задачу, вы просто сделали кусок вашей работы и передали его дальше. Никаких ожиданий, никаких задержек, с этим связанных, стараясь максимально упереться фактически уже в процессор, просто превратить его в такую сковородку для готовки яичницы.
Если мы вспомним, откуда это пришло… Например, из автомобилестроения, где как раз такая же идея, чтобы как можно меньше кто-то кого-то ждал. Каждый участок выполняет свою роль и передает результат дальше. Допустим, вы сделали такой выбор, мы посчитали, что для решения нашей задачи, для построения нашей архитектуры, этот шаблон подходит лучше всего.
Вопрос №2: как мы будем эту архитектуру реализовывать? Какими средствами? Какое связующее ПО нам потребуется для того, чтобы разнородные обработчики связать вместе.

Здесь выбор зашкаливает. Это не все, что есть, это все, что влезло на слайд.
Я сейчас вряд ли успею рассказать про достоинства и недостатки каждой из этих систем и обосновать конкретно, почему выбор сделан именно в сторону RabbitMQ, частично это будет видно потом из доклада, на конкретных примерах. Рассмотрев разные варианты, даже самый забавный, самый верхний левый — взять и все написать вручную, просто на сокетах — тоже были такие эксперименты. Но в итоге, в ходе всех экспериментов, был сделан выбор именно в сторону этого брокера сообщений.

Мне очень понравился доклад Дмитрия, который сравнивал In-memory базы данных. Он говорил про правильный инженерный подход — меряйте, не верьте рекламе, обязательно нужно мерить. Он упомянул еще один немаловажный факт, перед тем как мерить, нужно изначально сузить и выбрать какие базы данных вы будете мерить между собой, вам нужно изначально сузить поиск. Обычно отталкиваются, исходя из функционала, кто что умеет.
Я хочу здесь еще одну проблему поднять и сказать, что на нее тоже стоит обратить внимание — это сколько эта технология проживет? Глядя на то, как развивается современный рынок технологий, мне становится немножко страшно, я боюсь, что однажды утром открою ленту новостей и увижу там статью »7 новых SQL баз данных, которые вы должны изучить за эту неделю». Если они так быстро появляются, то они начнут примерно с такой же скоростью умирать. Отсюда есть желание при выборе опереться на технологию, которая с какой-то вероятностью, с какой-то долей уверенности проживет чуть дольше. С этой точки зрения RabbitMQ интересен не как продукт, а как технология, которая опирается на протокол AMQP, более низлежащий слой, который уже нашел достаточно неплохое свое применение.

Вот с официального сайта протокола AMQP официальные пользователи. Очень интересно здесь видеть Microsoft Azure Service Bus и Google.
Google, вообще, выпускает официальный анонс, что он просто свой SQS-сервис баз строит на основе RabbitMQ.
Microsoft Azure просто реализует протокол AMQP, реализация у них явно, похоже, своя.
VMware — один из родоначальников протокола AMQP и системы RabbitMQ, очень активно использует его внутри своих решений.
Т.е. это такой рекламный слайдик. Знаете, когда он помогает? Представьте, что я так же стою на сцене, а вы stakeholder«ы, вы владельцы компаний, инвесторы, вы сейчас на это собираетесь давать деньги, и вас нужно убедить, на что вы будете давать деньги. Вот такие слайды очень помогают, они сразу видят знакомые названия и им нравится. Поэтому можно его использовать именно в рекламных целях.
Пара картинок, которые мне потребуются далее, как основные определения и терминология.
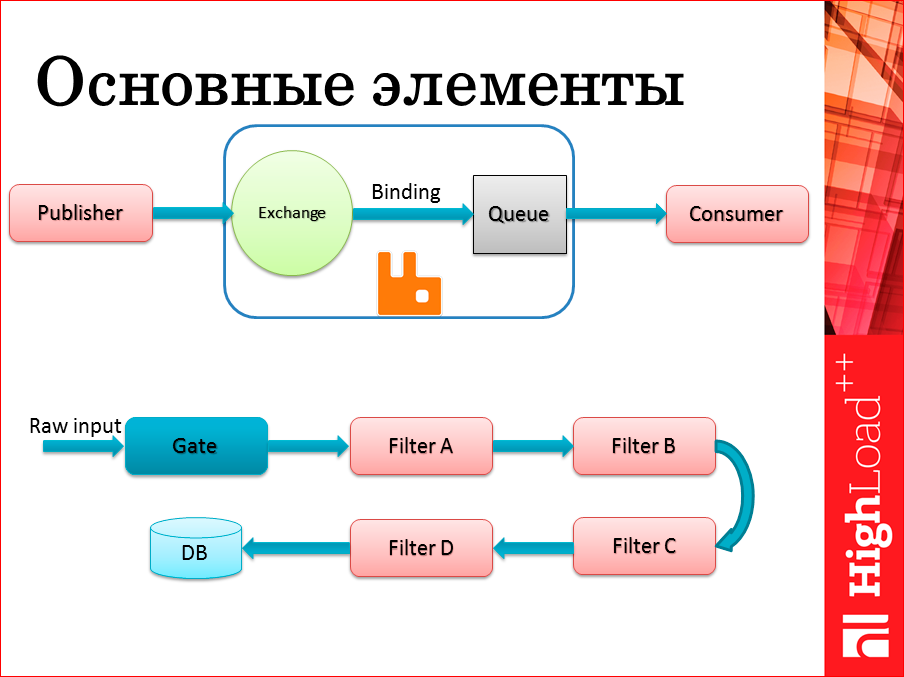
Первая картинка для тех, кто просто плохо знаком с основными сущностями внутри протокола AMQP и в системе RabbitMQ. Слева — Publisher — писатель — система, которая что-то пишет в этой очереди. Внутри самого RabbitMQ выделяются две отдельные сущности: первая — кружочек — обменник — Exchange — точка входа, обычно туда публикуются все сообщения систем. Второй немаловажный элемент — очередь, где эти сообщения потом хранятся и связка между ними — Binding, которые позволяют достаточно гибко и интересным способом маршрутизировать ваши сообщения между разными очередями.
В дальнейшем чуть подробнее поговорим о том, какие способы маршрутизации есть, и какие можно использовать в том или ином случае. Пока просто остановимся на том, что такая привязка есть. С этой точки зрения Publisher не всегда даже знает, в какую очередь он пишет, он знает: пишем в евенты, пишем в статистике, пишем в метрике, пишем в логе, сколько там реально стоит за этим очередей, ему не особо даже нужно знать. С точки зрения писателя — это очень удобно.
Читателю, с другой стороны, желательно знать, откуда он будет конкретно читать, поэтому он привязывается к той либо иной очереди.
И если мы будем использовать эти Q-очереди как буферы, которые связывают разные обработчики между собой, мы получаем картинку в нижней части слайда. Это очень простой способ изобразить Pipeline архитектуру, архитектуру типа «конвейер», когда есть поток сырых данных, который проходит разные обработчики, между каждым из обработчиков, фактически есть эта очередь, и они, выполняя каждый свой кусочек работы, прогоняют данные вплоть до, допустим, базы данных. К этой картинке и обозначениям на ней, я буду в дальнейшем возвращаться.
Давайте конспективно попробую пройтись. Что хорошего мы получаем:
- Асинхронную обработку — не надо ничего ожидать — сделали свою работу, отправили результат дальше — очень приятно.
- Простое добавление обработчиков, практически на лету. Да, на самом деле, на лету. Переконфигурировать систему на лету — очень просто. Необходимо вставить
в середину pipeline что-то новое. Вы делаете это даже без перезагрузки, более того, подчас ни писатели, ни читатели этого могут не заметить. Писатель может
заметить, что он начал писать в другое место. - Гибкая маршрутизация. Фактически, поскольку писатель не очень знает, куда он пишет, мы можем настроить, чтоб он писал в одну очередь, сразу в две, с
каким-то масштабированием, с какой-то стратегией шардинга между этими очередями. О некоторых стратегиях мы обязательно поговорим. - Удобная отладка — очень немаловажный фактор. Если вы архитектор, при этом пишущий код, то при проектировании системы вы попробуете учесть то, что потом
люди должны будут это программировать, значит, они должны будут это отлаживать, значит им нужно предоставить удобные готовые инструменты. Один из самых
удобных инструментов — то, что можно прямо на лету взять и скопировать все сообщения из очереди, просто взять себе копию. Это дает возможность очень легко
воспроизвести практически любую ситуацию, как пример удобной отладки. - Масштабируемость читателей и писателей — из очереди может читать несколько, писать в очередь может несколько, добавлять практически всегда можно на лету.
Очень приятный и немаловажный факт, особенно для нагруженных систем. - Не стоит забывать, что кроме полезной работы, теперь появляется некоторая дополнительная нагрузка — нужно перекачивать данные между разными обработчиками
и можно упереться в то, что сам брокер очередей начнет не справляться с нагрузкой. Немаловажным фактором является то, чтобы он сам хотя бы по себе мог
масштабироваться, а это RabbitMQ предоставляет очень хорошо. - Еще приятный момент — устойчивость к перезагрузкам и отказам. Поскольку есть режим записи всего содержимого очередей на диск с некоторым периодом, то
можно себя обезопасить от такой неприятной ситуации, например, что нода случайно перезагрузилась, или у вас очень много данных в системе, а вас просят ее
перезагрузить из соображений какого-то мэнтейнса. То, что вы данные при этом не теряете, является очень приятным моментом.
Если бы вы были stakeholder«ами, скорее всего это был бы конец моего доклада. Я все рассказал, я сказал, что мы будем делать, дальше я хочу попросить несколько человеко-лет, неограниченное количество кофе, печеньки, и мы вам ее сделаем. Но здесь все-таки конференция немножко другого типа. Здесь в первую очередь, собрались инженеры, и те слова, которые я говорил до этого, вы внимательно слушаете и думаете: «Так, а где подвох? Где проблемы? Не может быть без проблем».
Если это высоконагруженные системы, которые реально функционируют у пользователей, там должны быть проблемы, поэтому я готов перейти ко второй части своего доклада.
Что делать, когда к вам прибегут с проблемами: «Шеф, ничего не работает! То, что мы придумали — ерунда!»?
Во-первых, не стоит паниковать. Если вы сделали ваш выбор, он изначально был осознан, держитесь его до конца. Надо взглянуть взглядом инженера, оторвавшись от чашечки вашего любимого кофе, и приступить к решению проблем.

По некоторым проблемам, не по всем конечно, я хочу пройтись, рассказать какие конкретно решения мы выбрали.
Первая проблема — пропускная способность. Оказывается, пропускная способность системы зависит от ее настройки. Типы exchange«ей, которые предоставляют разную маршрутизацию:

Какие-то позволяют просто делать publish subscribe — раскидывать по всем очередям. Какие-то позволяют, в зависимости от ключей маршрутизации, просто строк, говорить: «Так, красная — в эту очередь, зеленая — в эту очередь, debug логи — в эту очередь, warning логи — в эту очередь» и т.д. Это, например, Direct.
Topic — более гибкая маршрутизация, более сложная, она позволяет маршрутизировать по маскам, например, звездочки, решеточки использовать. Очень хорошо работает с точки зрения функционала. Не очень хорошо работает с точки зрения пропускной способности. Там просто более сложная структура данных внутри.
Есть интересная статья создателей RabbitMQ, как они долго выбирали префиксные деревья, либо недетерминированные конечные автоматы. Они выбрали то, что посчитали лучшим, все равно оказывается, что, ориентируясь на такую гибкую маршрутизацию, мы можем не дотянуть до тех характеристик, которые нам необходимы, поэтому это стоит обязательно учитывать.
Четвертый exchange — это Consistent-Hash. Он ведет себя даже лучше, чем остальные. Хотя он, казалось бы, сложнее. Какая-то явно будет сегментация, шардирование, сложный алгоритм выбора очередей… Преимущество в том, что он работает с числами. Первые три работают со строками как ключами маршрутизации, а последний работает с числами. Это позволяет ему некоторые дополнительные такты выигрывать.
Эти замеры я провел… я бы посчитал, что это средняя машина, я ничего не настраивал дополнительно, это после apt-get install вот так работает. Вообще говоря, не очень хорошо. 35 тысяч messages per second (сообщений в секунду), ну как-то хотелось бы немножко быстрее.
С чем могут быть связаны такие низкие цифры? На самом деле, с приемом, которые многие знают, но почему-то мало кто применяет. Пакетная обработка.

Когда вы знаете, что вам нужно сделать примерно одну и ту же работу много раз, почему бы вам не обрабатывать не по одному событию, а целыми пакетами, целыми блоками, целыми пачками? Например, как делает Kafka из ZeroMQ. За это им смайлик. Они молодцы, они незаметно для клиентов делают пакетную обработку. Вы считаете, что вы публикуете сообщения по одному, а если вы посмотрите, как они летят по шине данных — они летят уже пачками. Поэтому прямо сходу мы получаем достаточно хороший критерий пропускной способности.
Смайлик в обратную сторону, потому что не наш выбор. За них мы рады, но нам это ничего не дает.
Давайте сделаем ее самостоятельно — это не очень сложно, это раз. А второе, сделав реализацию пакетов самостоятельно, мы начинаем лучше ею управлять — сколько мы хотим сообщений в пакете, как долго мы хотим, чтобы они набирались. Если в случае Kafka из ZeroMQ это находится глубоко в драйвере и туда не всегда можно залезть, то, имея собственную реализацию, мы можем управлять достаточно гибко и хорошо.
И сильно негативный смайлик — мы увеличиваем наши задержки. Мы начинаем собирать пакеты, не отправляем дальше сообщения, которые уже готовы, значит, мы увеличиваем их задержку.
Как я уже говорил, может для системы обработки событий это не очень критично, мы все-таки говорим о задержках порядка десятков миллисекунд. Для системы типа request response это critical, но если у нас потом на отчеты по событиям смотрят раз в 10 минут, либо раз в час, то задержка в пару десятков миллисекунд, наверное, для нашей системы может быть терпимой.
Вот небольшой замер, результат — что будет происходить, если мы начнем увеличивать размеры, здесь — просто байтов в каждом сообщении, которые мы отправляем в шину.

Синий график — это пропускная способность в сообщениях в секунду, она падает. Начинаем мы с 35 и потихонечку уходим ниже, когда уже начинаем отправлять такие здоровые сообщения, по одному Мбайту. Но если мы посмотрим на график пропускной способности в байтах в секунду, их легко пересчитать в сообщения в секунду. Допустим, у вас сообщение в среднем 256 байт, либо 1 Кбайт, оно начинает расти. Расти начинает очень хорошо.
Я здесь отмасштабировал красный график, он поделен на 30 тысяч, чтобы они как-то вместе смотрелись. Давайте я вам помогу с калькуляцией: если сейчас все это назад умножить, то это в пике достигает 10-ти Гбит в секунду. Это loopback-интерфейс, это не реальная сеть, чуть-чуть здесь пример искусственный в этом плане. Один писатель, один читатель — тоже искусственно. Но вот так система работает из коробки. Т.е. уже на интерфейсе обратной петли можно вот так сходу добиться пропускной способности в 10 Гбит. Не производя какого-то особо детального тюнинга, разве что, оперируя размерами пакетов, которые мы будем обрабатывать. Шикарное решение, очень советую помнить, что если система не делает это сама, мы можем сделать это за нее.
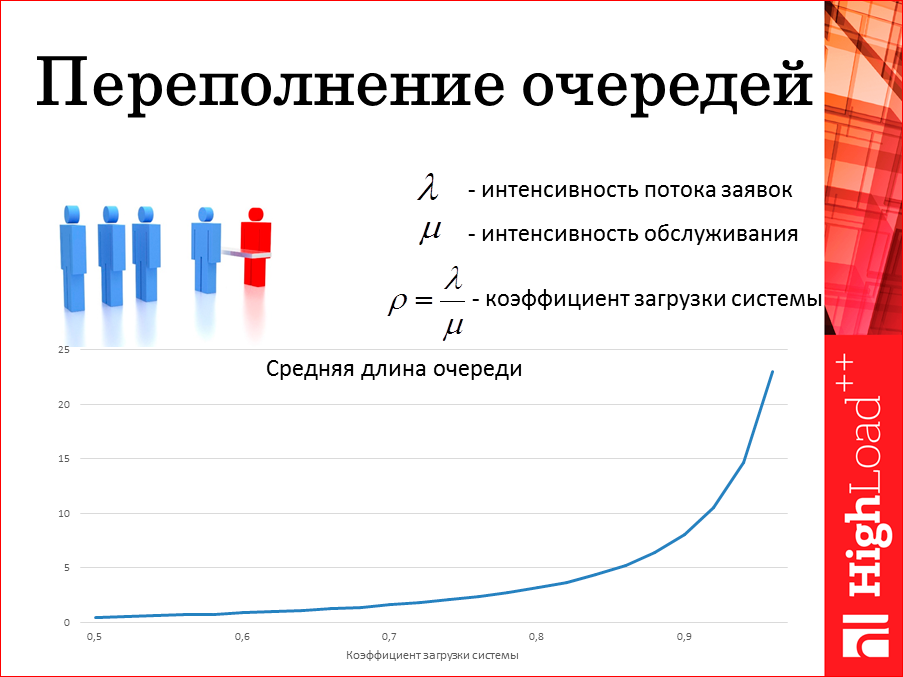
Следующая проблема. Она возникает обычно именно в системах с очередями. К ней надо быть просто готовым. Надо знать, что вы будете делать, и признаваться себе в этом. Когда очередь начнет переполняться? Ну, все помните эти очереди в магазинах, большие не выдерживают. Здесь я нарисовал график теоретический. Теория говорит нам о том, что если у вас есть интенсивность обслуживания, сколько вы успеваете обработать за секунду, если у вас есть интенсивность потока заявок сообщений? Сколько вы пишете в секунду? У вас есть коэффициент загрузки системы. Когда он единица — это очень плохо. Очень интересный факт, который дает теория. Когда он даже не единица, когда он даже очень маленький, очередь ненулевая. Там всегда что-то будет. Этого не надо бояться. Там, скорее всего, будет что-то в среднем не очень большое, туда будет дописываться, оттуда будет вычитываться, считать, что эти очереди между системой должны быть всегда по нулям, т.е. сообщения должны пролетать через них мгновенно — они бы тогда не были нужны как буферы. Единственно, что надо стараться — не дойти до правой границы.
Правда, мы не можем предсказывать будущее… Что, если начнется момент, когда в нас вольют неожиданно невероятное количество данных, т.е. система не готова к таким пиковым нагрузкам, как она себя поведет в этом случае? Т.е. мы не успеваем доставлять сервера и запускать новые ноды.

Есть несколько путей, в зависимости от вашей конкретной задачи вы можете выбрать тот либо иной:
- Первый — сбрасывать сообщения из памяти на диск. Ну, приятно, правда, пока диск не закончится.
- Второй момент — вы начинаете блокировать писателей. Это очень хорошо, вы стараетесь чуть меньше писать, дать возможность читателям выполнить свою работу.
- Малоприятный момент — как только мы подключаем диск ко всей этой системе, активную работу с диском, все очень замедляется и большой пропускной
способности мы, скорее всего, не достигнем. - Но приятный момент — никто не падает. Один раз за много лет эксплуатации нам удалось завалить всю эту систему. Закончилась оперативка, закончился потом
диск. Она не упала, мы ее выключили, она не смогла подняться. Потребовалось очистить данные с жесткого диска и все, она взлетела и поехала дальше. Данные,
к сожалению, во время эксперимента были потеряны.

Интересная стратегия — как этого не допускать?
- Первое: кто может себе это позволить? Да просто ограничьте размер очередей. Что произойдет с теми, кто не влезает? Если эти данные для вас не очень
важны, допустим, какие-то служебные метрики, которые пишутся раз в секунду… Если вы пару этих метрик пропустите, это на общей картине не скажется, тогда вы
можете просто их выкидывать. Это хорошо, если вы такое можете себе позволить. Мы не можем. - Второй момент. Вы можете ограничить время жизни сообщений. Если они очень долго сидят в очереди, их оттуда все еще не вычитали, может, они уже стали
просто бесполезными. Что, если вы пытаетесь строить систему, которая отслеживает тренды в реальном времени? Если какой-то элемент этого тренда уже запоздал
на 2 минуты, он просто неинтересен, его просто можно выкинуть тогда, тоже не рассматривать. - Третий способ самый сложный. Есть встроенный механизм RabbitMQ flow control. Можно пойти этим путем, пытаться немного демпфировать наших очень активных
писателей. Я это называю стратегией «Горшочек, не вари!».

В начале времени, когда у нас все хорошо, есть один писатель Filter A. Он пишет в очередь. Есть читатель из этой очереди, очередь небольшая, допустим 10000 сообщений.
Ситуация меняется, очередь растет-растет-растет. 10 млн — уже не очень маленькая, уже как-то что-то хочется с этим сделать. На пальцах стратегия RabbitMQ flow control следующая. Давайте его придержим. Реализация, если я правильно понимаю, очень простая, система начинает вставлять случайное ожидание, специальным образом подобранное при чтении сокета от паблишера, в каком-то смысле уменьшая уже даже на сетевом уровне интенсивность приходящих от него сетевых пакетов.
Я попытался здесь изобразить, что лямбда стала мала. Она начинает просто медленнее писать. Мы даем возможность читателю немного перевести дух, быстро ее разгрести. Как только очередь возвращается в свои рамки, этот стоп-сигнал убирается, писатель начинает работать в прежнюю силу. Если это было что-то пиковое, временное, вот на эту временную траекторию, это нас спасет. Если нет, и эта ситуация постоянна, мы ее откладываем до самой границы системы — до точки входа. Там уже зависит от того, кто нам пишет. Если к нам идет поток UDP, там просто нечего контролировать — все мимо. Если идет поток TCP, можно предпринять свои стратегии. То, что внутри системы эта балансировка происходит автоматически между читателями и писателями — это очень приятный момент.
К следующей проблеме. Масштабирование.

Тут есть 2 аспекта. Первый — то, что называется Stateless filters. Filters — они же обработчики или обработчики без состояний, что-то очень простое. Ему на вход А, он на выход Б, без памяти, шикарная штука. Самый удобный примитив, с которым только можно работать — масштабируется на ура. Вы просто их добавляете, прям на лету, сколько хотите, сколько вам нужно в пределах одного процесса по потокам. В пределах разных процессов на одной машине, в пределах разных процессов на разных машинах, главное конфиг им соответствующего уровня подать, чтоб они пошли с ним работать. Это моя любимая часть — масштабирование.
Вторая часть моя самая нелюбимая, когда появляются обработчики с состояниями — Stateful filters, сумматоры, разного рода агрегаторы.
Пример из нашей практики расскажу. Считаем неуспешные попытки входа в систему для Васи и для Маши. Для Васи один счетчик, для Маши — другой счетчик. Нас интересуют ситуации, когда в течение двух минут произойдет больше ста неудачных попыток под одним и тем же пользователем. Выбирать стратегию типа Round-robin«а — мы просто раскидываем по любым обработчикам — здесь нельзя. Мы должны каким-то образом гарантировать, что все события, связанные с Машей, пойдут в одну систему, в один счетчик, все события, связанные с Васей, — пойдут в другую. Тогда нам необходимо чуть-чуть верхнюю картинку переусложнить, ради такой благой цели. Во-первых, появляется у каждого обработчика своя собственная очередь. Допустим, очередь А1 — это логины Васи, очередь А2 — это логины Маши. И должен быть какой-то маршрутизатор — Router, который умеет между ними раскидывать. Можно построить свой. У него вот проблема, он должен будет знать тогда о количестве очередей, которые там возникают. Можно использовать встроенный. В exchange«ах RabbitMQ есть как раз такой обменник, который реализует стратегию консистентного хэширования, который сам будет выполнять роль этого маршрутизатора.

Про Statefull filters. Почему они мне не нравятся.
Во-первых, нужно писать много кода, больше кода, чем для обработчиков без состояний. Потому что это состояние в этом обработчике нужно будет где-то уметь сохранять. Что-то необходимо будет как-то реализовывать. В этот момент сегментация, она же шардинг. Нужно будет эту картинку усложнять, вводить каждому свою очередь, как-то по этим очередям раскидывать, как-то это планировать, продумывать. Если эту работу не нужно было делать, вообще, желательно ее не делать.
Если вы столкнулись с такой ситуацией, что вы не можете сделать обработчик без состояния, придется с этой проблемой иметь место. Одна из самых моих главных мыслей во всем докладе — если вы можете без них обойтись, постарайтесь это сделать. Иначе вы столкнетесь с дополнительным ворохом проблем, которые можно избежать. Если вы не можете без этого обойтись, вы не можете переложить эту проблему на базу данных. Если нам потребовались сетевые локи, сетевые блокировки — это очень дорого. А с большой скоростью при сетевых блокировках обрабатывать данные — мы не смогли придумать такой архитектуры. Мы смогли придумать стандартный путь, когда у каждого обработчика свое состояние, оно прямо у него в памяти, оно эксклюзивное, он им владеет, никто ему не мешает, он полностью его обрабатывает.

Если мы пришли к тому, что нужно делать сегментацию (шардинг), то какими путями мы можем пойти?
Кстати, вообще, проблема эта очень хорошо описана в докладе прошлого года у Алексея Рыбака и Константина Осипова, там более детальное описание, а я про некоторые моменты расскажу.
Первый способ такого шардинга очень простой — берем ключик m, вычисляем hash-функцию, берем остаток от деления N –количество наших обработчиков. Все, мы знаем его номер, поехали. Для одних и тех же ключей поедут в один и тот же обработчик. Почему смайлик вниз? Когда N меняется — все становится очень плохо. Все эти счетчики просто сбиваются. События отправляются в совершенно рандомном порядке, и контролировать как-то этот процесс мы совершенно не можем. Много раз говорили, я не буду повторяться, что это такое, просто на пальцах — это тоже похоже на hash-функцию, но она старается решить проблему первой hash-функции. Как только у вас изменится количество обработчиков, что-то поедет не туда, куда ехало раньше, но не такой большой размер, будет стараться этот алгоритм эту миграцию данных делать гораздо меньше.
Можно использовать свой, но можно использовать готовый. В RabbitMQ есть целых 2 Sharding plugin«а. Один позволяет сказать какой из обработчиков с какой областью готов работать — этому давай больше, этому давай меньше. К сожалению, этот плагин приходится ставить отдельно, это не всегда удобно, потому что нужно компилировать эрланговский код, на продакшн системе это не всегда удобно делать.
Что приятно, четвертый способ — consistent-hash-exchange — идет прямо в дефолтной инсталляции, он реализует фактически этот алгоритм консистентного хэширования, позволяя динамически при изменении количества обработчиков, а следовательно и количества очередей, правильно выбирать, кому из обработчиков данные отправить. Но когда их количество динамически меняется, старается делать так, чтобы решардинг прошел как можно более мягко.
Таким образом, я подхожу к заключению доклада. 2 основные мысли, которые, надеюсь, я донес:

Не надо ничего придумывать, практически все уже придумано, нужно выбирать, но не надо считать, что выбирать просто. Выбирать очень сложно. По-моему, выбирать сложнее, чем придумывать, это нужно делать с большой осторожностью.
И когда вы сделали свой выбор, проблемы будут. Мой опыт показывает, проблемы будут. Но не бойтесь их, будьте уверены в своем решении и старайтесь с вашим решением все эти проблемы превозмочь.
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. Сейчас мы активно готовим конференцию 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.Павел Филонов подал в этом году целых две заявки, что из них выбрать, Программный комитет пока не знает:
- «Выбираем СУБД для хранения временных рядов»;
- «Нейронные сети на страже индустриальной кибербезопасности».
Нейронные сети, это, конечно, горячая тема, но хороший обзор СУБД для хранения временных рядов — это очень и очень ценно!
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!

