[Перевод] Высококачественная, легковесная и адаптируемая технология Text-to-Speech с использованием LPCNet

Последние достижения в области глубокого обучения привносят существенные улучшения в развитие систем синтеза речи (далее — TTS). Это происходит благодаря применению более эффективных и быстрых методов изучения голоса и стиля говорящих, а также благодаря синтезу более естественной и качественной речи.
Однако, чтобы этого достичь, большинство систем TTS должны использовать большие и сложные модели нейронных сетей, которые трудно обучить и которые не позволяют синтезировать речь в реальном времени, даже при помощи графических процессоров.
Чтобы решить эти проблемы, наша команда IBM Research AI разработала новый метод нейросетевого синтеза, основанный на модульной архитектуре. Данный метод объединяет три глубокие нейронные сети (deep neural network, далее — DNN) с промежуточной обработкой их выходных сигналов. Мы представили эту работу в нашей статье «Высококачественная, легковесная и адаптируемая TTS технология с использованием LPCNet» на Interspeech 2019. Архитектура TTS легка и может синтезировать высококачественную речь в режиме реального времени. Каждая сеть специализируется на различных аспектах голоса говорящего, что позволяет эффективно обучать любой из компонентов независимо от других.
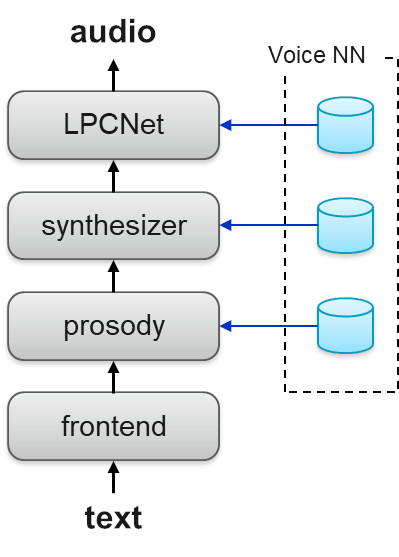
Схема 1. Системная архитектура TTS
Другое преимущество нашего подхода заключается в том, что после обучения базовых сетей их можно легко адаптировать к новому стилю речи или голосу даже на небольших объемах обучающих данных, например, в целях брендинга и кастомизации.
В процессе синтеза используется интерфейсный модуль для конкретного языка, который преобразует входной текст в последовательность лингвистических признаков. Затем применяются следующие DNN одна за другой:
1. Предсказание просодии
Просодические признаки речи представлены в виде четырехмерного вектора на единицу TTS (примерно одна треть состояний звука по СММ (скрытая марковская модель)), включающего в себя log-duration, начальный и конечный log-pitch, а также log-energy. Эти признаки определяются в процессе обучения, поэтому их можно предсказать по особенностям текста, полученного интерфейсом во время синтеза. Просодия чрезвычайно важна не только для того, чтобы речь звучала естественно и живо, но и для того, чтобы в данных, предназначенных для обучения или адаптации, имелось наиболее полное отражение стиля речи говорящего. Адаптация просодии к голосу диктора основана на вариационном автоэнкодере (Variational Auto Encoder, VAE).
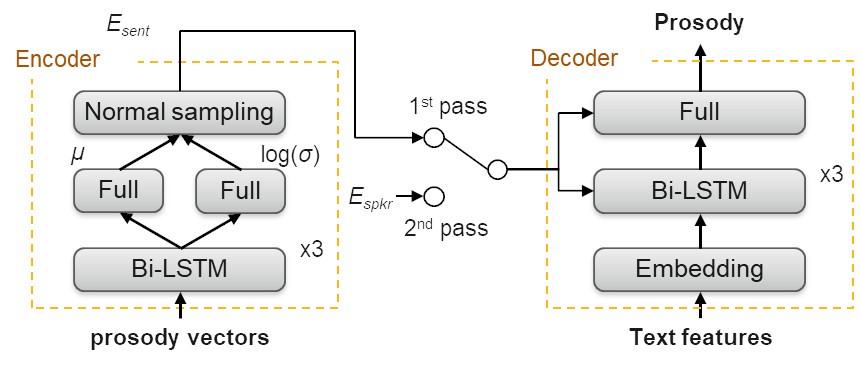
Схема 2. Обучение и переобучение генератора просодии
2. Прогнозирование акустических признаков
Векторы акустических признаков обеспечивают спектральное представление речи в коротких 10-миллисекундных кадрах, из которых может быть сгенерирован фактический звук. Акустические особенности определяются в процессе обучения, и их можно предсказать по фонетическим меткам и просодии во время синтеза.
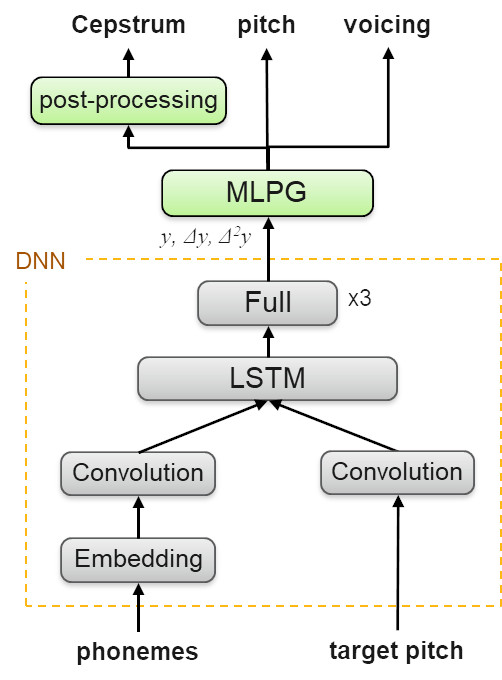
Схема 3. Сеть-синтезатор
Созданная модель DNN представляет собой аудиоданные (голос диктора), необходимые для обучения или адаптации. Архитектура модели состоит из сверточных и рекуррентных слоев, предназначенных для извлечения локального контекста и временных зависимостей в последовательности звуков и структуре тона. DNN предсказывает акустические признаки по их первой и второй производной. Затем следует метод максимального правдоподобия и применяются формантные фильтры, которые помогают генерировать речь лучшего звучания.
3. Нейронный вокодер
Нейронный вокодер отвечает за генерацию речи из акустических признаков. Он обучается на образцах естественной речи говорящего, учитывая их соответствующие особенности. Технически мы были первыми, кто использовал новый, легкий, высококачественный нейронный вокодер под названием LPCNet в полностью коммерциализированной системе TTS.
Новизна этого вокодера заключается в том, что он не пытается предсказать сложный речевой сигнал непосредственно с помощью DNN. Вместо этого DNN только прогнозирует менее сложный остаточный сигнал голосового тракта, а затем использует фильтры LPC (Linear Predictive Coding) для преобразования его в окончательный речевой сигнал.
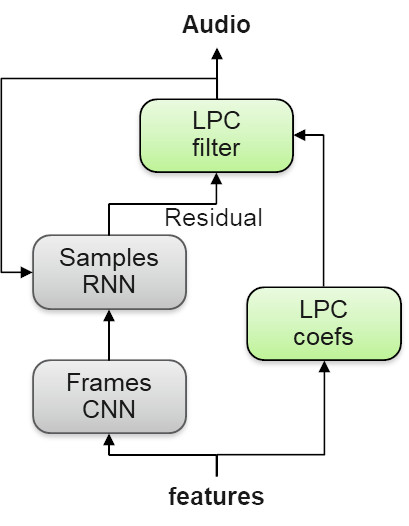
Схема 4. Нейронный вокодер LPCNet
Голосовая адаптация
Адаптация к голосу легко достигается путем переобучения трех сетей на основе небольшого количества аудиоданных целевого диктора. В нашей статье мы представляем результаты адаптационных экспериментов с точки зрения качества речи и ее сходства с истинной речью диктора. На этой странице также приведены примеры адаптации к восьми различным дикторам VCTK (Voice Cloning Toolkit), из которых 4 являются мужчинами и 4 — женщинами.
Результаты прослушивания
На рисунке ниже представлены результаты тестов прослушивания синтезированных и естественных образцов речи дикторов VCTK. Значения средней экспертной оценки (Mean Opinion Score, MOS) основываются на анализе слушателями качества речи по шкале от 1 до 5. Сходство между парами образцов оценено слушателями по шкале от 1 до 4.
Мы измерили качество синтезированной речи, а также ее сходство с речью «живых» дикторов, сравнив женские и мужские адаптированные голоса длительностью 5, 10 и 20 минут с естественной речью дикторов.
Результаты испытаний показывают, что мы можем поддерживать как высокое качество, так и высокое сходство с оригиналом даже для голосов, которые были обучены на пятиминутных примерах.
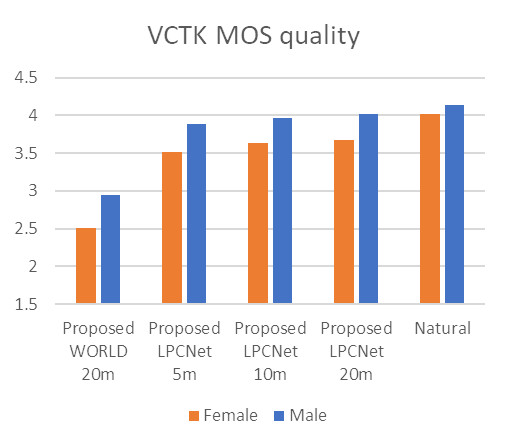
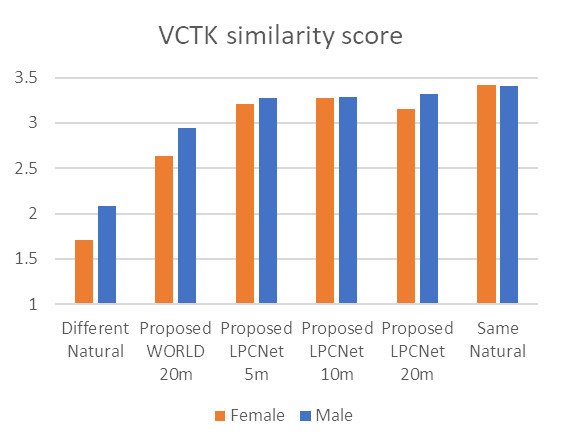
Схема 5. Результаты тестов на качество и сходство
Эта работа была проведена IBM Watson и послужила основой для нового выпуска сервиса IBM Watson TTS с улучшенным качеством голоса (см. голоса »*V3» в демонстрационной версии IBM Watson TTS).
