[Перевод] Ввод-вывод — уже не узкое место
На собеседованиях с программистами я часто прошу их написать простую программу, посчитывающую частотность слов в текстовом файле. Это хорошая задача, проверяющая множество навыков, а уточняющие вопросы позволяют зайти на удивление глубоко.
Один из моих уточняющих вопросов такой: «Что является узким местом производительности вашей программы?» Многие отвечают что-то типа «считывание из входящего файла».
На самом деле, написать эту статью меня вдохновил ответ на чей-то вопрос в Gopher Slack: «Я заметил, что много дополнительной работы приходится на разделение строки и тому подобное, но обычно всё это намного быстрее ввода-вывода, поэтому нас это не волнует».
Я не стал спорить… и пока не проанализировал производительность задачи с подсчётом слов, думал так же. Ведь всех нас этому учили, правда? «Ввод-вывод — это медленно».
Но это больше не так! Дисковый ввод-вывод мог быть медленным 10–20 лет назад, но 2022 году последовательное считывание файла с диска выполняется очень быстро.
Насколько же быстро? Я протестировал скорость чтения и записи моего ноутбука при помощи этой методики, но с параметром count=4096, то есть с чтением и записью 4 ГБ. Вот результаты, полученные на моём Dell XPS 13 Plus 2022 года с накопителем Samsung PM9A1 NVMe и Ubuntu 22.04:
Разумеется, системные вызовы относительно медленны, но при последовательном чтении или записи один syscall нужно выполнять через каждые 4 КБ или 64 КБ (или другую величину, в зависимости от размера буфера). А ввод-вывод по сети по-прежнему медленный, особенно в нелокальной сети.
Так что же является узким местом в программе, считающей частотность слов? Это обработка или парсинг входящих данных, а также соответствующее распределение памяти: разбиение входящих данных на слова, преобразование в нижний регистр и подсчёт частотностей при помощи таблицы хэшей.
Я модифицировал свои программы подсчёта слов на Python и Go так, чтобы фиксировать время разных этапов процесса: считывания входящих данных, обработки (медленная часть), сортировки по самым частым и вывода. Потом выполнил проверку на текстовом файле размером 413 МБ, то есть на приличном объёме входящих данных (100 конкатенированных копий текста Библии короля Якова).
Ниже показаны усреднённые результаты трёх лучших прогонов в секундах:
Сортировка и вывод занимают пренебрежимо мало времени: так как входящие данные состоят из 100 копий, количество уникальных слов относительно невелико. Примечание: это приводит к ещё одному уточняющему вопросу на собеседовании. Некоторые кандидаты говорят, что узким местом будет сортировка, потому что её сложность O (N log N), а не обработка входящих данных, сложность которой O (N). Однако здесь легко забыть, что мы имеем дело с двумя разными N: общим количеством слов в файле и количеством уникальных слов.
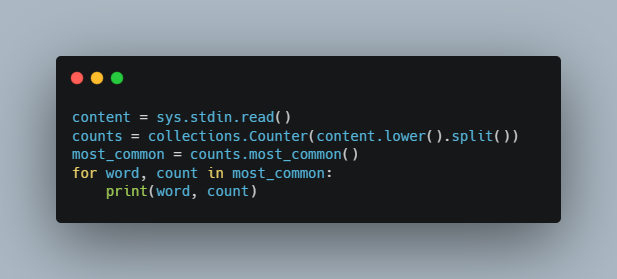
Внутренняя работа версии на Python сводится к нескольким строкам кода:
content = sys.stdin.read()
counts = collections.Counter(content.lower().split())
most_common = counts.most_common()
for word, count in most_common:
print(word, count)
На Python запросто можно выполнять построчное чтение, однако это немного медленнее, поэтому здесь я просто считываю весь файл в память и обрабатываю его за раз.
В простой версии на Go используется тот же подход, однако стандартная библиотека Go не содержит collections.Counter, поэтому выполнять сортировку «самых частых» нам нужно самостоятельно.
Оптимизированная версия на Go существенно быстрее, однако и гораздо сложнее. Мы избегаем большинства распределений памяти, выполняя преобразования в нижний регистр и разделяя текст на слова с замещением. Это хорошее эмпирическое правило для оптимизации кода с интенсивными вычислениями: снижайте количество распределений памяти. Информацию о том, как это профилировать, читайте в моей статье об оптимизации подсчёта количества слов.
Я не показал оптимизированную версию на Python, потому что сложно оптимизировать Python ещё сильнее! (Время снизилось с 8,4 до 7,5 секунды). Код уже и так быстр, потому что базовые операции выполняются в коде на C; именно поэтому часто не важно, что «Python медленный».
Как видите, дисковый ввод-вывод в простой версии на Go занимает всего 14% от времени выполнения. В оптимизированной версии мы ускорили и чтение, и обработку, и дисковый ввод-вывод занимает всего 7% от общего времени.
Какой же я делаю вывод? Если вы обрабатываете «big data», то дисковый ввод-вывод, вероятно, не будет узким местом. Даже поверхностные измерения дадут понять, что основное время тратится на парсинг и распределение памяти.
