[Перевод] Введение в архитектуру Greenplum
В этой статье поговорим о Greenplum — СУБД, основанной на PostgreSQL. Разберём её общую архитектуру, способы хранения данных, а также перечислим проблемы, с которыми можно столкнуться в ходе эксплуатации.

Общая архитектура Greenplum
Greenplum — распределённая база данных с открытым исходным кодом. Представляет собой несколько взаимосвязанных экземпляров PostgreSQL, объединённых в кластер по массивно-параллельной архитектуре (MPP).
Кластер Greenplum состоит из:
master node («мастер-ноды» или «главного узла») — конечные пользователи подключаются к нему для выполнения запроса;
standby node («резервного узла») — он обеспечивает поддержку доступности для мастера;
segment nodes («узлов сегментов») — являются рабочими узлами, где находятся данные.
Мастер-нода получает запрос, инициированный пользователем, выполняет его компиляцию и оптимизацию, генерирует план параллельного запроса и распределяет его по узлу сегмента. После выполнения данные отправляются обратно на главный узел и, наконец, передаются пользователю.
Организация данных в Greenplum основывается на следующих стратегиях:
Сначала данные равномерно распространяются по каждому сегменту — эта операция называется распределение данных.
Затем данные каждого узла разбивают на более мелкие подмножества — эта операция называется разделение данных.
Рассмотрим процесс обслуживания Greenplum. Слева находится главный узел, а справа — два узла сегмента:
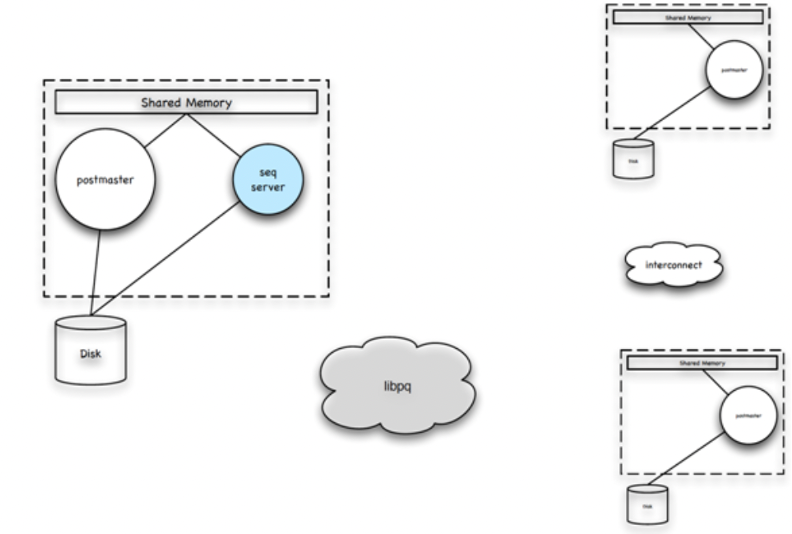
С точки зрения топологии, Greenplum — это кластер баз данных, состоящий из автономных PostgreSQL. Когда у клиента появляется запрос, он связывается с главным узлом Greenplum через протокол libpq. После того, как процесс postmaster на главном сервере прослушивает запрос на подключение, он создаёт подпроцесс (QD) для обработки всех запросов клиента. QD и исходный мастер обмениваются данными через общую память.
Далее возникает связь между QD и отдельными сегментами. QD можно рассматривать как клиент каждого сегмента — он отправляет запросы на подключение ко всем узлам сегмента и устанавливает запросы на подключение через протокол libpq. Процесс postmaster при прослушивании запроса на подключение QD также создаёт подпроцесс (QE) для обработки последующих запросов.
QD — диспетчер запросов, который является распространителем.
QE — исполнитель, который обрабатывает запросы.
Процессы QD и QE работают вместе для выполнения запроса, отправленного клиентом. QD обрабатывает запрос, отправленный клиентом, и передаёт его процессу QE по протоколу libpq. Протокол libpq в основном используется для управления возвратом команд и результатов, в то время как interconnect используется для внутренней передачи данных.
QE выполняет назначенные ему подзадачи запроса и возвращает результаты QD. Затем QD обобщает собранные результаты запроса и возвращает их клиенту через libpq.
Чтобы улучшить загрузку процессора, Greenplum реализует распараллеливание запросов между операторами в сегменте. Пользовательские запросы могут содержать несколько ключей в одном сегменте, и QE взаимодействуют друг с другом через interconnect.

«DWH на основе GreenPlum»
Управление хранилищем
Greenplum использует общую буферную область (Shared buffer) в качестве промежуточного буфера памяти. Backend-процесс взаимодействует со средним уровнем. Буфер в общей памяти заменяется файлом на диске (Disk file).

Что происходит в общем буфере? Greenplum собирает данные в блоки:

Таблица сопоставления (mapping table) находит блок, соответствующий блоку общего буфера (Shared buffer). Если содержимое признаётся недействительным, данные загружаются в блок общего буфера с помощью операции с нижним файлом (lower file operation). Если действительным — читается напрямую.
В Greenplum чтение и запись могут выполняться одновременно. Чтобы разрешить одновременное чтение и запись, Greenplum предоставляет механизм управления несколькими версиями MVCC для улучшения параллелизма. При вставке данных сохраняются два скрытых поля: xmin и xmax, которые представляют собой номера транзакции вставки и транзакции удаления соответственно.
Индекс
Хотя в большинстве традиционных баз данных индексы могут значительно сократить время доступа к данным, в Greenplum их следует использовать более экономно. Поскольку данные Greenplum распределены по сегментам, каждый сегмент сканирует меньшую часть общих данных, чтобы получить результат. При разбиении таблицы на разделы общий объём сканируемых данных может быть ещё меньше. Так как рабочие нагрузки запросов бизнес-аналитики (BI) обычно возвращают большие наборы данных, использование индексов неэффективно.
Однако индексы могут повышать производительность рабочих нагрузок OLTP, где запрос возвращает одну запись или небольшое подмножество данных. Индексы также могут повышать производительность сжатых таблиц, оптимизированных для запросов, поскольку оптимизатор может использовать метод доступа к индексу, а не полное сканирование таблицы, когда это необходимо. Для сжатых данных метод доступа к индексу означает, что распаковываются только необходимые строки.
Выполнение запроса
Чтобы предоставить пользователями более мощные и полезные функции, в Greenplum предусмотрен механизм выполнения (execution engine). При выполнении запроса оператор SQL проходит через анализатор, и строковый оператор SQL превращается в структурированное дерево.

В Greenplum экзекьютор выполняет план запроса через итераторы — сверху вниз, по одному кортежу за раз. Каждая экзекьютор-нода (executor node) передаёт один кортеж наверх и получает другой кортеж снизу. Может быть несколько планов выполнения запросов, например, последовательное сканирование и сканирование индекса. Задача оптимизатора — выбрать наименее затратный план выполнения.
Если используется сканирование индекса, одна из проблем заключается в том, что кортежи, выполняемые индексом, находятся в файле, что приводит к произвольному доступу к диску.

Одно из решений — Greenplum Cluster operation. Операция кластера переупорядочивает кортежи в файле в соответствии с порядком индекса, за счёт чего доступ к диску осуществляется последовательным образом.
Ещё одно решение (актуально при наличии нескольких условий) — сканирование на основе битовых изображений (bitmaps). Bitmap записывает, какие кортежи соответствуют условиям запроса, и позволяет получить последовательный доступ к файлам.

JOIN operations
Существует три основных типа операций объединения (JOIN operations) для кортежей в Greenplum. Первый — объединение вложенных циклов, аналогичное файловому хранилищу, когда два цикла накладываются друг на друга, чтобы сопоставить сканы внутри и снаружи, и возвращается результат. Возможный вариант здесь заключается в том, что внутренний цикл может использовать индексы вместо последовательных сканирований, чтобы сделать выполнение более эффективным.
Второй — объединение слиянием, состоящее из двух этапов. Первый этап предполагает сортировку кортежей, подлежащих подключению. На втором этапе выполняется операция слияния на основе отсортированных кортежей.
Третий способ — хэш-соединение. При хэш-соединении одна таблица обычно используется в качестве таблицы поиска, а другая — в качестве хэш-таблицы. Идея хеширования состоит в том, что функция хеширования равномерно распределяет значения по ограниченному числу корзин хеш-таблицы. В таком случае разные значения будут попадать в разные корзины. Если равномерности не будет, в одну корзину может попасть много значений. В таком случае они выстраиваются в список, и по мере увеличения длины списка эффективность поиска по хеш-таблице будет падать.
Вместо заключения
Greenplum требует к себе немного другого подхода, чем остальные enterprise-решения. Однако при достаточно низком пороге вхождения и большой унифицированности с PostgreSQL он является сильным игроком на поле Data Warehouse DB.
«DWH на основе GreenPlum»
