[Перевод] Время перезагрузки для «операционных систем»

За последние годы индустрия программного обеспечения ушла от статичных/ скомпилированных языков программирования и отдаёт предпочтение динамическим языкам — особенно в тех случаях, когда гибкость применения важнее чистого быстродействия. Однако, для этих языков характерны специфические проблемы (такие как проверка постепенной типизации), они требуют наличия дополнительной инфраструктуры и инструментария и отличаются большими объемами кодовых баз.
Ночной кошмар IT-наследия.
Дискуссия об использовании статичных или динамических языках не нова — она фактически началась в 1958 году, с созданием LISP. Однако многие CIO согласятся, что в последнее время распространение новых языков приводит к неконтролируемому росту технического долга. Каждый новый язык дает одну или две относительно полезные функции, но через несколько месяцев появляется следующий многообещающий язык. Кроме того, инструментарий динамического языка зачастую адаптируется исходя из потребностей рабочего процесса с использованием статичных «flat-файлов», и практически не поддерживается на корпоративном уровне.
Каждому достаточно сложному приложению / языку / инструменту придется либо использовать Lisp, либо изобретать его заново. — Десятое правило программирования Гринспуна.
Следом за «секретом на миллиард долларов» Goldman Sachs, после кризиса 2008 года, Нью-Йорк приступил к массовому распространению в Восточной Европе технологии «codebuilder», для устранения недостатков динамической языковой инфраструктуры.
Крошечная Эстония не могла участвовать в этом безумии, так как подобные мегапроекты трудоемки, но мы рассматриваем ситуацию в целом и видим, что NYC по существу создает специализированные решения проблем (таких, как дилемма языка программирования).
Поэтому можно поставить под сомнение роль базовой «операционной системы» — например, что она дала нам в последнее время? Еще в 1964 году в индустрии программного обеспечения понимали, что нельзя просто использовать динамические языки программирования, автоматизацию ИИ и так далее, без наличия минимального уровня «умной» инфраструктуры программирования. Это возвращает нас к оригинальному (и гораздо более широкому) видению, лёгшему в основу UNIX, и заставляет пересмотреть некоторые новаторские идеи, которые были забыты во время кризиса 1970-х годов. Знатоки истории поймут, что мы говорим о Multics.
Вниз в кроличью нору
Попытаемся объединить следующие понятия:
• Прикладная теория категорий.
• Контекст.
• Постоянная память.
• Одноуровневая память.

Прикладная теория категорий
Теория категорий — это направление в математике, посвящённое распознаванию закономерностей и унификации концепций. Однако ей свойственен некий парадокс — невозможность использования одних и тех же определений внутри и «вне» данной теории. Это приводит к алгебраической путанице даже при описании довольно простых вещей. В конце концов, читатель должен «выйти за пределы матрицы», чтобы разобраться в том, что происходит на самом деле.
Ключевым в теории категорий является понятие «лифт», которое означает, что мы поднимаем концепцию на более высокий уровень абстракции, где её можно объединить с другими, обычно не сочетаемыми друг с другом.
Контекст
Даже в чисто функциональной (без изменения состояния) программе разработчик должен поддерживать быстро растущее число параметров в дереве вызовов. Не имея формального способа управления этими данными, умные разработчики могут включить стек вызовов в экземпляры функций с помощью замыканий (closures) или каррирования, или же могут полагаться на «закулисную» передачу данных посредством некоторых встроенных монад. Огромный недостаток — это отсутствие надлежащей системной поддержки транзитных данных (transient data) (не говоря уже об обработке ошибок), потому что в языках программирования сложно отделить понятие области видимости от потока управления (control flow).
Контекст можно назвать Королём Монад. Представьте его «лифтом» оболочки Multics / UNIX, чтобы понять, как мы будем использовать его для отслеживания конфигурационных данных в разных строках кода.
Ниже показан контекст whitsunday, который напоминает терминальную сессию. Действительно, мы можем рассматривать браузер как модернизированный «терминал». Когда мы создаем объект foo, он выглядит как пустая папка, и после создания х мы можем применить команду «cd» (переходя по пути размещения объекта) и отобразить содержимое с помощью «list».
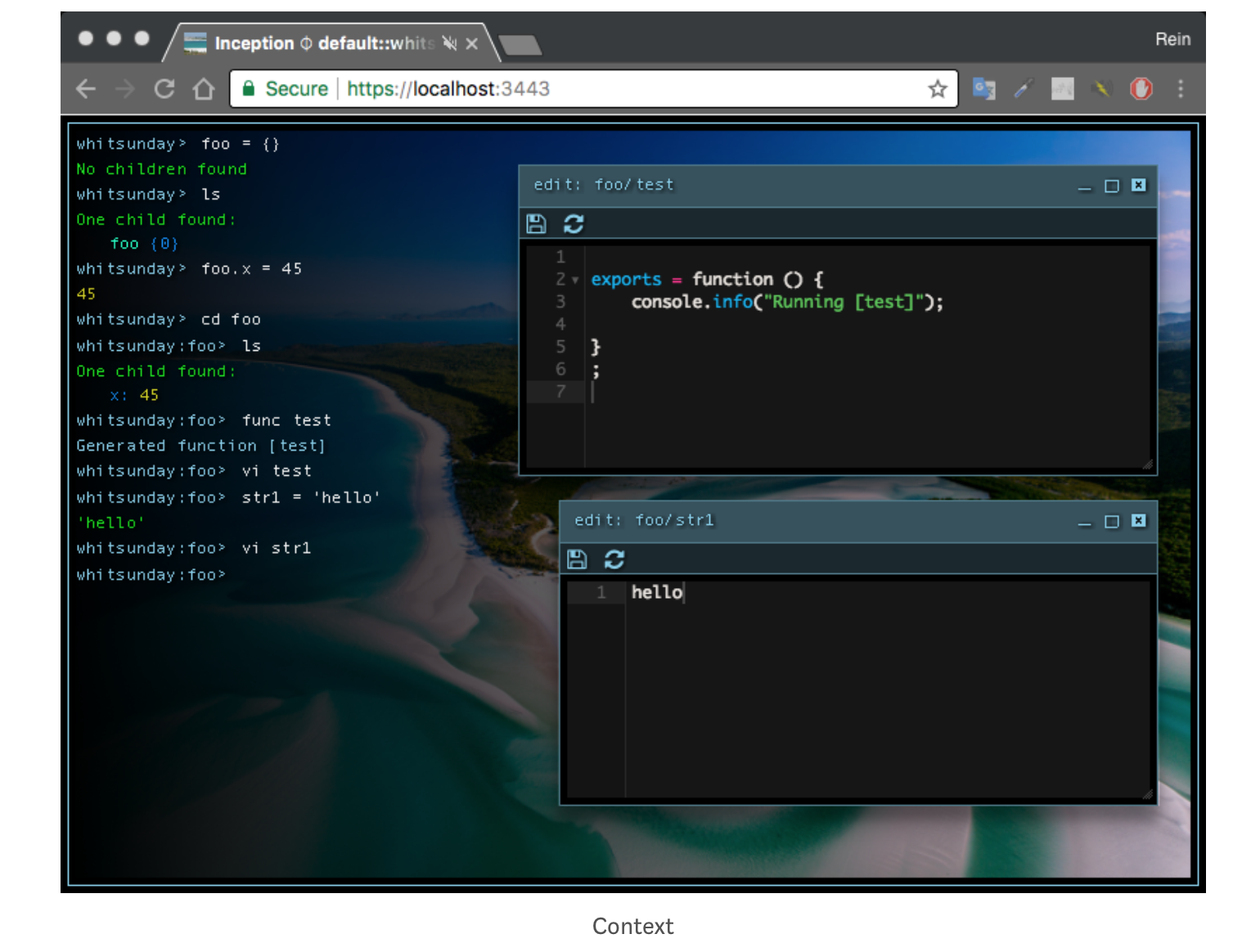
Воспользовавшись командой «vi», мы можем напрямую манипулировать функцией test или переменной str1. Это иллюстрирует более серьезные амбиции, стоящие за Multics, по сравнению с минимальной поддержкой процесса разработки в UNIX / Linux. Поскольку у нас есть контекст, существует понятие пространственного расположения (пути) этих раздробленных сущностей, не зависящих от потока управления (или исходного файла (ов)). Обратите внимание, что наш прототип оставляет эти объекты не только в традиционной файловой системе UNIX, а еще и в обычной программной памяти. Мы вернемся к контексту позже.
Постоянная память
Intel, HP, Micron и другие компании разрабатывают энергонезависимые (NVDIMM) чипы памяти и связанные с ними API, чтобы упростить программирование постоянной памяти. На интуитивном уровне мы понимаем, что постоянная память ведет себя так же, как ноутбук, который «засыпает», когда вы закрываете крышку. Теоретически, если заранее должным образом подготовить объекты, вы могли бы относиться к своей маленькой программе как к базе данных в оперативной памяти, а значит могли бы на лету обновлять код и так далее. Некоторое время по этому пути шли торговые системы NYC, работающие в оперативной памяти, хотя они зачастую рассматривают постоянную память просто как другой тип устройства для хранения данных, или как «распределенную постоянную память», например, блокчейн.
Настоящая «постоянная память» не имеет большого значения для среднестатистического программиста, работающего со статичными языками. Низкоуровневые программы полны нестабильных, расположенных в памяти «ссылок» на невесть что, и попытка сохранять их все на месте, приводит к проблемам при загрузке. Более того, сложные runtime-объекты, вроде HTTP-сервера, обычно собираются как одноразовые побочные эффекты запуска машины фон Неймана поверх списка сборочных инструкций —, а адреса памяти никогда не предназначались для использования в качестве первичных ключей. С другой стороны, динамические языки используют стабильные, динамически связываемые (late-binding) именные ссылки (name references), которые (по задумке) должны быть более надежными.
Ниже приведен простой пример постоянной памяти. Команда lv (отображение статуса сохранения) показывает две переменные зелеными/новыми (y выводится первым, потому что я создал его позже), пока x не будет сохранена. Позже x отображается красным цветом, чтобы предупредить нас о не сохраненных изменениях.
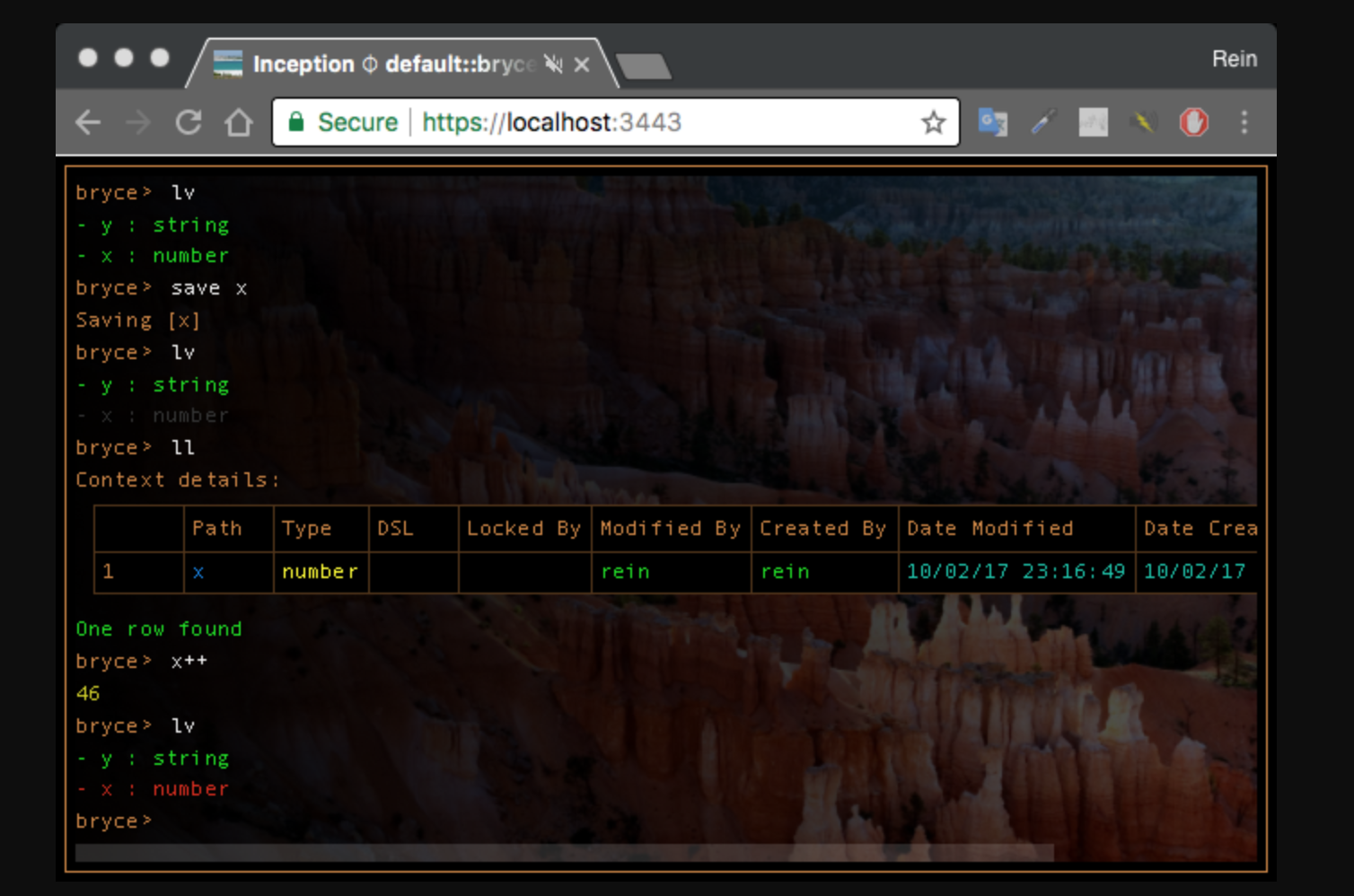
Команда ll подтверждает, что x действительно сохранен. Обратите внимание, что контекст играет жизненно важную роль «корня» для определения путей в постоянной памяти. В этой конкретной реализации также отслеживается метаинформация и блокировки (Multics поддерживает списки прав доступа к чему угодно). Функциональный программист может считать постоянную память (её побочные эффекты) анафемой, и отсюда проистекает отделение функционального кода от конфигурации (ведь простая загрузка программы в память — это изменение состояния, а возможность отката — это одна из негласных целей функционального программирования). Таким образом, дискуссия сводится к тому, что лучше использовать для постоянного хранения: DSL вроде SQL или язык, полный по Тьюрингу. Конечно, чаще всего просто сохраняются сделанные в функциях изменения (аналогично хранимым процедурам базы данных). Более интересным является случай, когда мы начинаем создавать переходные составные объекты (transient compound objects).
Одноуровневая память
До сих пор описанные возможности и идеи были сопоставимы с коммерческой СУБД с расширенной поддержкой различных языковых расширений. Но теперь давайте объединим несколько концепций с помощью теории категорий. Одноуровневая память (также называемая одноуровневым хранилищем) — это ещё одна инновационная концепция из Multics, позднее улучшенная IBM в 1970-х годах. Авторы концепции пытаются распространить одну модель программирования на различные устройства и возможности операционных систем.
Давайте расширим классическую концепцию одноуровневой памяти ради:
• Нейтральности к языку/DSL.
• Системной поддержки функционального программирования.
• Автоматической привязки памяти.
Эти концепции были проиллюстрированы ранее. По-существу языковая нейтральность означает, что ни один DSL не «подчинён» другому, то есть, не сводится к встроенным строкам. Ниже показано, как SQL и JavaScript исполняются совместно.
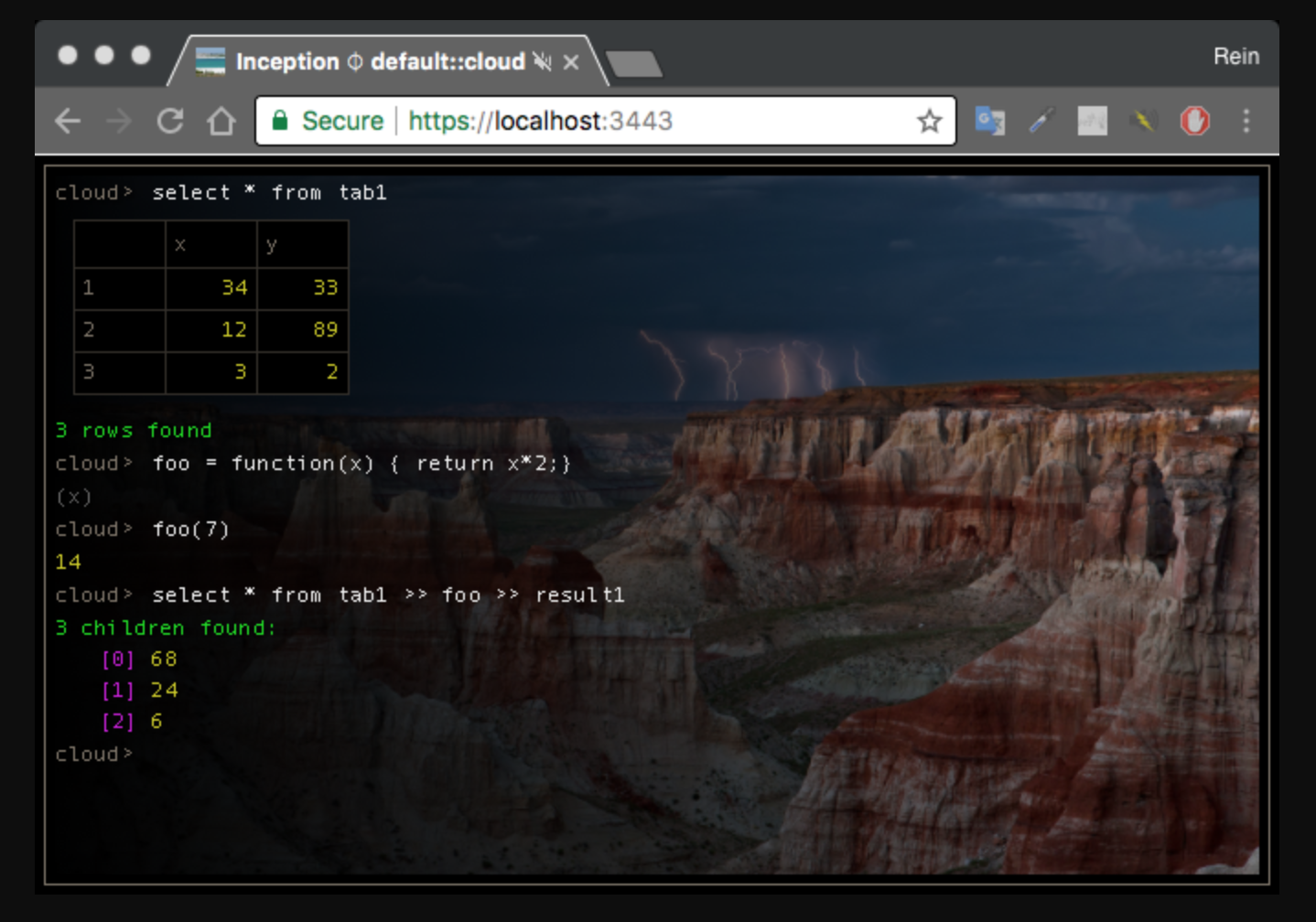
Объединение выражений, написанных на разных языках — это естественное применение теории категорий, когда нам нужно привязывать SQL-типы данных к JavaScript. Но в таком коде не было явной нужды, поскольку он не определяет, к какой базе данных мы обращаемся, как быть с функциональным программированием (множества и скаляры, синхронность и асинхронность, и так далее), должна ли функция foo явным образом циклически перебирать множество результатов. Это настройки конфигурации, которые лучше всего обрабатываются контекстом.
Обратите внимание, что foo может быть посредником для внедрения другого базового языка программирования (например, ради производительности или преемственности). Когда-то в торговых системах NYC было принято помещать «виртуальный» динамический уровень поверх статичного кода, это было частью более крупной корпоративной архитектуры разделения функционального кода и конфигурации. Можно предположить, что этот подход станет более востребованным при использовании виртуальных машин вроде WebAssembly (по иронии судьбы, это возвращает нас к LISP).
В приведенном выше примере одноуровневая память обрабатывает привязку функций foo и result1 в формате виртуальной файловой системы, что не мешает манипулировать ими в обычном редакторе. Хотя это выглядит как обычная файловая система, но на самом деле это привязка к памяти. Как мы видим ниже, контекст сloud выглядит для Atom как обычная папка, а сущности автоматически привязываются к файлам.
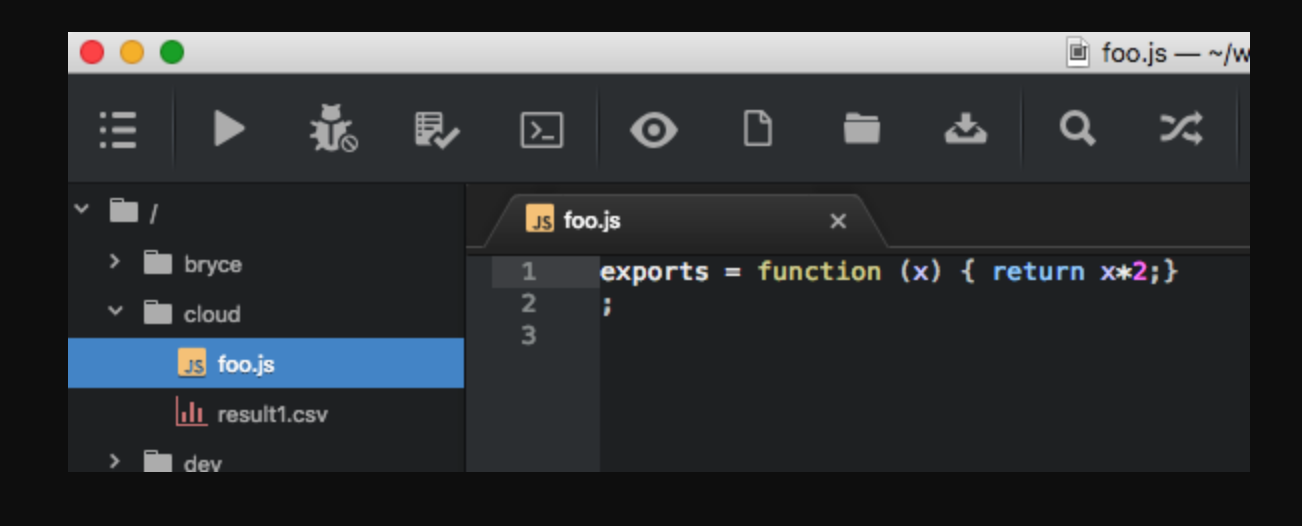
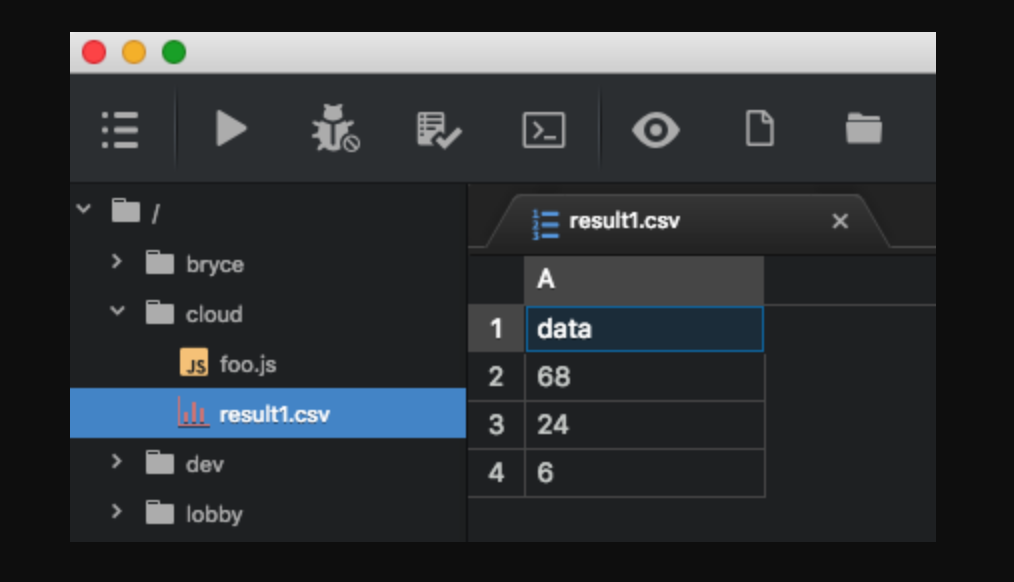
Самое интересное в том, что редактирование может быть двунаправленным, например, «сохранение» в Atom будет в горячем режиме немедленно загружено в runtime-среду, позволяя глубже погрузиться в REPL-разработку. Ещё интересно отметить, что Google, Facebook и другие рассматривают технологию FUSE — файловую систему в пользовательском пространстве — как средство улучшения своих систем разработки. Переменная result1 автоматически представляется как CSV-файл.
Интереснее обстоят дела с привязкой SLM к JSON, что может быть полезно для управления различными конфигурационными файлами.
Если глубже изучить функциональное программирование, то станет понятно, что при желании контекст может привязывать имена переменных к именам столбцов в входных данных.
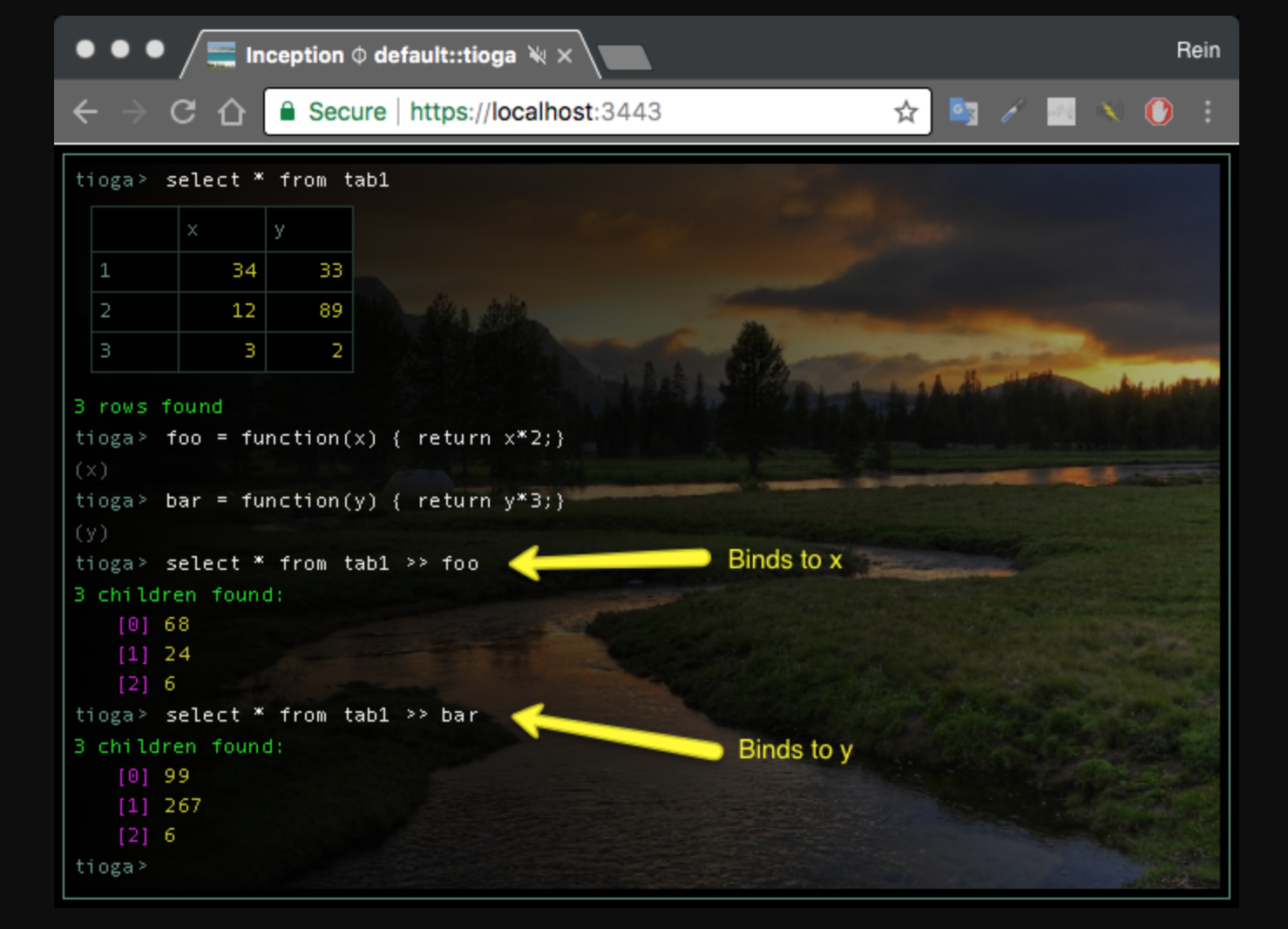
Все эти настройки похожи на то, как обрабатываются переменные среды в оболочке UNIX. Но смысл заключается в (1) устранении «шума» из кода, чтобы легче было понять намерения разработчика, и (2) попытке быть более декларативным даже в традиционном императивном языке.
Следует также отметить, что в контекстах также есть интересные свойства совместной работы, берущие своё начало в Multics.
Итог
Надеюсь, мне удалось вам показать, как несколько загадочных концепций, таких как теория категорий, постоянная память и прочие, могут сложиться в нечто более осязаемое, помогающее понять, как будет выглядеть программирование в будущем. UNIX на протяжении десятилетий влияла на архитектуру операционных систем, но мы полагаем, что пришло время выдвинуть на передний план более величественные концепции.
