[Перевод] В условиях параллелизма обнуление памяти замедляется
Взявшись исследовать некоторые непонятки с производительностью в Chrome, я обнаружил, что Microsoft распараллелили обнуление памяти, и иногда работа из-за этого сильно замедляется. В Windows 11 такое замедление можно частично побороть, но в последних версиях Windows Server — где этот фактор наиболее важен — баг цветет и пахнет.
Но есть и хорошие новости — по-видимому, проблема актуальна только на тех машинах, где много процессоров. Под «много» я понимаю »96 или более». Поэтому вашего ноутбука проблема не касается. И даже 96-процессорные машины могут сталкиваться с ней не так часто. Но я нашел и другие факторы, из-за которых может быть спровоцирована такая неэффективность, если сложится подходящая ситуация — и обомлел. Вы бы посмотрели, как разбазаривается мощность CPU.
Окей — давайте перейдем к деталям.
Я, как обычно, занимался своим делом. Поступило сообщение о баге, позволявшее предположить, что на скорости загрузки в Chrome (например, на измеряемые при помощи speedtest.net) влияет какой-то антивирусный софт. Казалось, что такое действительно возможно. Загрузки проходят через кэш, кэш сохраняется на диск, а операции сохранения на диск замедляются под влиянием (некого) антивирусного софта. Дело закрыто. Но я кое-что заприметил…
Я проводил тесты в датацентре на виртуальной машине, к которой у меня был доступ, строго потому, что у этой машины было соединение с Интернетом, и скорость этого соединения превышала 2 Гбит/c. Прогнав разок speedtest, показавший более 2 Гбит/c (скачивание и закачка), я сам себе доказал, что Chrome по сути своей не ограничивает скорость скачивания. Но я также записал трассировку ETW, чтобы понять, на что именно тратится процессорное время во вспомогательном процессе Network Service, и тогда заметил, что часть времени расходуется в ntoskrnl.exe!KiPageFault:

Эта функция вызывается, когда машина впервые притрагивается к свежевыделенной памяти — память сбрасывается по требованию (следовательно, если она остается нетронутой, то никакой физической памяти не потребляется). Если случаются мягкие немногочисленные обращения к отсутствующим страницам памяти, то это еще нормально, но я заметил, что поток CacheThread_BlockFile в этом процессе растрачивает 16% ресурсов ядра (на него приходится 2,422 мс из 15,1 с) именно на такие обращения к несуществующим страницам. Может быть, это и неизбежно при скачивании данных на такой скорости, но таких расходов можно избежать, если переиспользовать блоки памяти.
Такие обращения к несуществующим страницам — которые часто именуются «обнуляемыми по требованию страницами памяти» — всего лишь один из симптомов, позволяющих судить о скрытых издержках выделения памяти от ОС (VirtualAlloc, а не мелкие выделения malloc). Кстати, тема знакомая, так как об этих скрытых издержках я уже писал. Поэтому я углубился в архивы собственной мудрости и нашел следующую табличку, в которой обобщены скрытые затраты на выделение памяти:
Спасибо тебе, мой бывший альтер-эго. Что бы я сейчас делал, если бы ты тогда не записал все эти полезные факты и приемы, которые я так часто забываю? Просто числа, но именно те, что мне были нужны. Самое лучшее в ведении блога — это когда гуглишь и пролистываешь в выдаче свои былые исследования. Но что-то я отвлекся…
Из этой таблицы следовало, что, если я трачу 16% мощности ядра на отказы несуществующих страниц, то, вероятно, также трачу (и не вижу этих трат, так как они спрятаны в процессе System) еще примерно 13,7% ресурсов ядра на обнуление памяти.
Вот почему возникают эти лишние расходы: когда страницы высвобождаются обратно в ОС, Windows их обнуляет. Ситуация такова, что я могу передавать их другим процессам, и утечки информации при этом не возникают. В Windows 7 был выделенный поток для обнуления памяти, но где-то в Windows 10 задачу обнуления памяти сделали многопоточной.
Обнуление страниц: проверка в реальных условиях
Я быстро просмотрел данные трассировки, чтобы проверить, сколько процессорного времени потребляется в различных потоках MiZeroLargePageThread процесса System.
Примечание: это не имя потоков, поскольку ядро Windows по-прежнему не именует своих потоков, несмотря на то, что еще пять лет назад был добавлен API для этого. Это просто имя входной точки. Может быть, когда-нибудь…
Я был шокирован. Процесс System в среднем использовал чуть более 4 ядер в пересчете на процессорное время, чтобы обнулить высвобожденную память!
Оказывается, были и другие процессы, выполнявшие краткосрочные выделения VirtualAlloc, так что общий объем памяти, который требовалось обнулить, оказался примерно вдвое больше, чем я поначалу думал (да, в трассах UIforETW по умолчанию записываются все VirtualAllocs — удобно). Но. Все-таки. Процессорное время, которого хватило бы на четыре ядра тратится там, где я рассчитывал потратить примерно 0,28 ядра — кажется, многовато. Общее процессорное время составило около 60 процессорных секунд сверх 15 секунд фактического времени, и все это — чтобы обнулить всего примерно 8,6 ГБ памяти. Ледник и то ползет быстрее.
На чем основаны спин-очереди
Мне хватило нескольких секунд посмотреть на потоки MiZeroLargePageThread — и проблема прояснилась. Оказывается, они проводили за обнулением памяти совсем немного времени. Львиная доля их времени тратилась на ntoskrnl.exe!ExpWaitForSpinLockExclusiveAndAcquire. Системный процесс использовал 92,445 с процессорного времени, причем, 60,287 с из них — в MiZeroLargePageThread, а 51,967 с из этого времени стоял и ждал в спин-очереди, пока ему достанется блокировка.
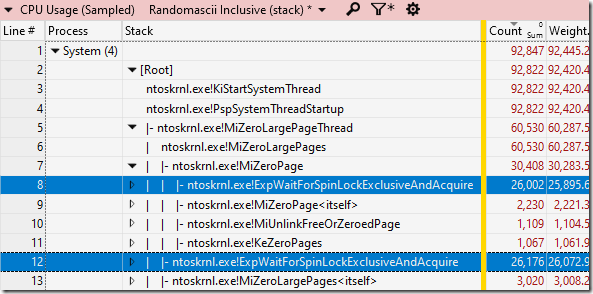
Конечно, я не разработчик ядра, но я совершенно уверен: если большую часть времени вы проводите в функции, в имени которой присутствует WaitForSpinLock, то произошло что-то очень скверное. Как сказал однажды один мудрец, спин-очереди впустую растрачивают энергию и процессорную мощность, поэтому их следует избегать.
Немного переупорядочив сводные таблицы (а с именованными потоками это было бы куда проще!), смог убедиться, что ОС моей 96-ядерной машины отряжает не менее 39 потоков на обнуление памяти. Беда в следующем: все выглядит так, будто эти потоки берут по одному куску работы в единицу времени, и каждый такой кусок памяти (подлежащий обнулению) составляет 4 КиБ памяти. Пропускная способность современных процессоров такова, что они могут обрабатывать по 50+ ГБ/с памяти, поэтому на обнуление 4 КиБ памяти могло бы уходить всего 76 нс.
Но, фактически, изначально операции обнуления кэшируются, поэтому на практике обнуление 4 КиБ памяти могло бы потребовать всего около десятка нс. Таким образом, та спин-блокировка, которая защищает тот список задач, оспаривается более чем 39 потоками, каждый из которых мог бы вернуться в спин-очередь примерно через 10 нс. Вполне можно предположить, что кэш-линия, содержащая спин-блокировку, тратит большую часть времени на перескакивание между ядрами процессора и пакетами.
Действует следующее грубое эмпирическое правило: если у вас N рабочих потоков, то я сказал бы, что вам потребуется, как минимум, в N раз больше времени на обработку рабочего пакета, чем на приобретение и удержание блокировки, защищающей рабочую очередь. Предположу, что при 39+ рабочих потоков на их обслуживание уходило бы 200–500 нс, но ситуация выглядит так, будто эти потоки такую работу не делают.
Насколько мы можем замедлиться?
Выше описано бесподобно патологическое поведение. Но можно ли его усугубить? Мне удалось случайно спровоцировать такое неэффективное поведение, просто воспользовавшись веб-страницей –, а что, если бы я преднамеренно попытался его получить?
Немного поэкспериментировав, я обнаружил, что два процесса, каждый из которых находится в спин-очереди в рамках цикла из 800 000 итераций (на каждой из итераций выделяется/обнуляется/высвобождается фрагмент памяти размером 4 КиБ, и это делается при помощи VirtualAlloc/VirtualFree) дают удовлетворительный результат (вот код):

Процессы zeropage_test.exe (коричневато-красные) выделяют, обнуляют и высвобождают память. Процесс System (оливкового цвета) не делает ничего сверх обнуления той же самой памяти. Процесс System выполняет меньше работы, зато потребляет на нее практически вдесятеро больше процессорного времени. Системный процесс ухитряется употребить 29 процессоров (!!!) просто на обнуление нескольких гигабайт памяти. Это прекрасно до жути.
Я обратился за помощью в твиттере, и мне прислали трассировку с машины, оборудованной 128 логическими процессорами, результаты на которой оказались примерно такими же. Я, продолжая работать на моей машине, стал внимательнее следить за ее поведением и изыскивать, как бы мне спровоцировать такую проблему. Этот баг сработал под действием Python-скрипта для измерения производительности диска, за выделением и высвобождением блоков памяти по 2 ГиБ каждый. Непосредственным триггером стала программка Empty Standby List из memmap — и опустошение списка ожидания значительно замедлилось, по-видимому, именно по этой причине. Выполняя сборку Chrome, я заметил, что использование процессора в процессе System взлетало на целых 25% — можно предположить, что до 24 логических процессоров активно пытались обнулить память, высвобожденную нашими многочисленными сборочными процессами.
Я попробовал посчитать по-разному и, по моей оценке, параллельный алгоритм для обнуления страниц памяти в Windows 10 может потреблять в 150 (!!!) раз больше процессорного времени, чем старый последовательный алгоритм. Поскольку он использует 39 потоков, это означает, что он более затратный как на уровне процессорной мощности, так и по фактическому времени, требуемому на выполнение задачи. Мощности датацентров ограничиваются и, пожалуй, никто сейчас не оснащает их 96-ядерными процессорами, поскольку многие ядра такой машины будут заняты непродуктивной работой. В одном из наихудших случаев процесс System использовал свыше 162 с of CPU процессорного времени, чтобы обнулить 6,13 ГиБ оперативной памяти, что позволило добиться скорости записи всего 0,038 ГБ в процессорную секунду!
Итак, что же делать разработчикам операционных систем?
Что делать
Конечно, я не знаю внутреннего устройства ядра, поэтому могу советовать невпопад, но вот некоторые идеи:
Использовать меньше потоков. Один поток — это, на самом деле, очень хорошо. Начинайте с малого и, может быть, дойдите до двух потоков. Честно говоря, если программа высвобождает память настолько быстро, что пара потоков не поспевает за ее обнулением, то, может быть, стоит исправить саму программу. А если обнуляющие потоки немного запаздывают, это даже хорошо — ведь тогда страницы можно обнулять именно после того, как к ним обратится процесс и получит отказ. Windows всегда это поддерживала. Обратите внимание: если кто-нибудь, вооружившись отладчиком ядра, смог бы приостановить большинство обнуляющих потоков в процессе System и посмотреть, решает ли это проблему — думаю, решило бы.
Пусть потоки берут больше работы. В некоторых статьях предлагается делать так: когда поток приобретает блокировку рабочей очереди, он должен взять на себя половину всей оставшейся работы. В альтернативном случае, если у вас N потоков, соперничающих за одну и ту же блокировку, то размер задания у вас должен быть пропорционально больше, чтобы избежать патологической конкуренции за ресурсы. Поэтому, возможно, пусть каждый рабочий поток захватывает N (или 2*N) страниц за раз.
Не пользуйтесь спин-блокировками. Я думаю, спин-блокировки — просто зло. Ходит народная мудрость, что спин-локам не место в пользовательском пространстве, но, возможно, уже пора ее уточнить, поскольку спин-блокировками также злоупотребляют разработчики ядра. KeAcquireInStackQueuedSpinLock — вот функция, которая не крутится и определенно пригодится вам в пространстве ядра.
Сделайте все вышеперечисленное. Если у вас будет четыре рабочих потока, и каждый последующий возьмет больше работы, чем предыдущий, а блокировки будут организованы без спин-очередей, то в самом деле может получиться красиво.
Windows 11
В итоге мне удалось получить некоторые тестовые результаты на Windows 11 (спасибо!) на машине со 128 логическими процессорами — и результаты воодушевляют. По-видимому, Microsoft многое поправила. Вот как обнуляется память на этой машине, если провести все тот же стресс-тест zeropage_test.exe:

В рамках этого теста обнуляющий поток использует процессор гораздо скромнее. По-видимому, теперь ОС оперирует всего 12 потоками (но это не точно) и использует ntoskrnl.exe!KeAcquireInStackQueuedSpinLock, чтобы сократить число спин-блокировок. Не могу сказать, захватывают ли рабочие потоки большие куски данных на обработку.
Но сделано еще не все. По-видимому, код для обнуления памяти по-прежнему
тратит около 80% процессорного времени, и при этот стоит в спин-блокировках. Поскольку
функции KeAcquireInStackQueuedSpinLock и ExpWaitForSpinLockExclusiveAndAcquire нельзя использовать с одной и той же блокировкой, делаем вывод, что здесь
в работу было вовлечено две (или более) блокировок, и Microsoft просто заменила одну из них на вариант с очередью. Как сказано в их же документации:
Спин-блокировки с очередью– это разновидность спин-блокировок, более эффективная в случаях с высокой конкуренцией за блокировку на многопроцессорных машинах. При использовании спин-блокировок с очередями на многопроцессорных машинах гарантируется, что процессоры будут приобретать спин-блокировку по принципу «первым пришел — первым обслужен». Драйверы для Windows XP и позднейших версий Windows должны использовать именно спин-блокировки с очередями, а не обычные спин-блокировки.
Ну, допустим. Может быть, ОС должна начинать следовать этому совету, либо нужно обновить документацию и объяснить, почему этого не делается.
С серверными версиями все должно .snm нормально…
Затем я провел последний тест. Воспользовался Google Compute Engine (не смог заставить Azure работать), чтобы создать машину из 128 логических процессоров, на которой у меня работала Windows Server 2022 DataCenter. Можно подумать, что, если занимаешься высокопроизводительными вычислениями под Windows, то нужно полагать, что именно этой операционной системой мы воспользуемся — так что меня весьма позабавило, что в ней ничего не исправлено под Windows 11 (пруф). Тут работы на $3,08. Вот трассировка из новейшей серверной ОС Microsoft (эти данные можно скачать отсюда):

Из этой трассировки мне стала очевидна одна вещь, которую я ранее не замечал: потоки MiZeroLargePageThread просыпаются каждые две секунды, чтобы посмотреть, нет ли работы. Это не меняет ни одного из моих выводов, но означает, что все эти потоки некоторое время сидят без дела, а затем одновременно отчаянно сцепляются за шанс поработать — приходится поторапливаться и ждать.
Спасибо всем тем твиттерянам, которые откликнулись на мой невнятный клич о помощи. Это было чудесно, когда столько людей предложили мне логические машины на 128 процессоров, и нашелся даже человек, предложивший машину 68×4 Xeon Phi — я и подумать не мог, что существуют машины на 272 логических процессора!
Дискуссия на Reddit здесь
Дискуссия на Hacker news здесь
Дискуссия на Twitter здесь и здесь
