[Перевод] В {n} раз быстрее Си

Иногда человек может обнаружить такие возможности оптимизации, которые не видит компилятор. В этой статье мы начнём с цикла, сгенерированного из кода Си с помощью clang, и скорректируем его разными способами, попутно измеряя прирост в скорости.
Эта статья публиковалась на главной странице HackerNews, и к её обсуждению вы можете присоединиться здесь.
Дисклеймер: я не эксперт по оптимизациям. По факту мой опыт касается высокоуровневых, чисто функциональных языков, где программист обычно не думает о том, как программа выполняется.
Листинги кода из этой статьи можно найти на GitHub.
Часть I
▍ Функция
Мы начнём с функции, которая перебирает строку и в зависимости от встречаемых символов инкрементирует либо декрементирует число.
int run_switches(char *input) {
int res = 0;
while (true) {
char c = *input++;
switch (c) {
case '\0':
return res;
case 's':
res += 1;
break;
case 'p':
res -= 1;
break;
default:
break;
}
}
}
Инкрементирование происходит при встрече s (successor, следующий элемент), а декрементирование при встрече p (predecessor, предыдущий элемент).
Это достаточно небольшая функция, которую gcc и clang должны неплохо оптимизировать. Может, даже оптимально? Изначально я написал её, чтобы увидеть, создаст gcc таблицу переходов или же поиск.
Вот, что выдал clang (заполняющие no-op удалены и комментарии добавлены вручную):
# llvm-objdump -d --symbolize-operands --no-addresses --x86-asm-syntax=intel --no-show-raw-insn loop-1-clang.c.o
run_switches:
xor eax, eax # res = 0
loop: # while (true) {
movsx ecx, byte ptr [rdi] # c = *input
test ecx, ecx # if (c == '\0')
je ret # return
add rdi, 1 # input++
cmp ecx, 'p' # if (c == 'p')
je p # goto p
cmp ecx, 's' # if (c == 's')
jne loop # continue
add eax, 1 # res++
jmp loop # continue
p: add eax, -1 # res--
jmp loop # }
ret: ret# objdump -Mintel -d --no-addresses --no-show-raw-insn --visualize-jumps loop-1-clang.c.o
run_switches:
xor eax, eax
loop:
╭────➤ movsx ecx, byte ptr [rdi]
│ test ecx, ecx
│ ╭─── je ret
│ │ add rdi, 1
│ │ cmp ecx, 'p'
│ │ ╭─ je p
│ │ │ cmp ecx, 's'
├─│─│─ jne loop
│ │ │ add eax, 1
├─│─│─ jmp loop
p: │ │ ╰➤ add eax, -1
╰─│─── jmp loop
ret: ╰──➤ ret- Время выполнения: 3.23 s
- Скорость: 295.26 MiB/s
Gcc выдал немного больше кода, который выполнился чуть быстрее.
Этот код довольно прост — в нём есть три условных инструкции ветвления (je, je, jne), ведущие к четырём возможным блокам: \0, s, p, а также блок для всех других символов.
▍ Перестройка ветвлений
Тем не менее об этом цикле мы кое-что знаем. Нам известно, что выход из него происходит только при достижении нуль-терминатора (\0). Генерируемый clang код сначала выполняет проверку наличия нуль-терминатора, но в этом нет смысла. Максимальное число нуль-терминированных строк, с которыми встретится эта функция, равно 1. Поэтому нам следует оптимизировать функцию так, чтобы сначала выполнялась проверка присутствия p или s и других символов, а не нуль-терминатора.
Немного перестроим наш цикл.
run_switches:
xor eax, eax
loop: ╭─────➤ movsx ecx, byte ptr [rdi]
│ inc rdi
│ cmp ecx, 'p'
│ ╭──── je p
│ │ cmp ecx, 's'
│ │ ╭── je s
│ │ │ test ecx, ecx
├─│─│── jne loop
│ │ │ ret
p: │ ╰─│─➤ dec eax
├───│── jmp loop
s: │ ╰─➤ inc eax
╰────── jmp loop
run_switches:
xor eax, eax
loop: movsx ecx, byte ptr [rdi]
inc rdi
cmp ecx, 'p'
je p
cmp ecx, 's'
je s
test ecx, ecx
jne loop
ret
p: dec eax
jmp loop
s: inc eax
jmp loop
Отлично! Теперь мы выполняем ветвление раньше — при встрече p или s, а не редкого \0.
- Время выполнения: 3.10 s
- Прирост скорости: 1.04x
- Скорость: 307.64 MiB/s
▍ Перестановка блоков
Итак, оба типичных случая (p и s) переместились в начало цикла, так почему бы нам не удалить одну из этих ветвей, поместив её целевой блок (или BasicBlock™, для специалистов по компиляторам) в начало цикла?
run_switches:
xor eax, eax
╭───── jmp loop
s: │ ╭──➤ inc eax
loop: ├─│──➤ movsx ecx, byte ptr [rdi]
│ │ inc rdi
│ │ cmp ecx, 'p'
│ │ ╭─ je p
│ │ │ cmp ecx, 's'
│ ╰─│─ je s
│ │ test ecx, ecx
├───│─ jne loop
│ │ ret
p: │ ╰➤ dec eax
╰───── jmp loop
run_switches:
xor eax, eax
jmp loop # This is new
s: inc eax # This is up here now
loop: movsx ecx, byte ptr [rdi]
inc rdi
cmp ecx, 'p'
je p
cmp ecx, 's'
je s
test ecx, ecx
jne loop
ret
p: dec eax
jmp loop
Прекрасно! Теперь наш блок s перескакивает (fall through) в цикл без ветвления. Неплохо.
Вы заметите, что теперь нам нужно переходить в цикл из начала функции, чтобы избежать выполнения блока s. Хотя это довольно хороший компромисс — переход в цикл из функции происходит один раз в то время, как символов s мы встречаем множество.
Но насколько быстрым окажется этот вариант?
- Время выполнения: 2.98 s
- Общее ускорение: 1.08x
- Скорость: 320.02 MiB/s
▍ Замена переходов арифметикой
Условные переходы нежелательны, но как насчёт стандартного безусловного jmp? Что, если попробовать убрать возвращение в цикл p:?
Декремент равнозначен двум декрементам и одному инкременту, правильно? Значит, давайте используем его для перескакивания в s:.
run_switches:
xor eax, eax
╭────── jmp loop
p: │ ╭─➤ sub eax, 2
s: │ ╭─│─➤ inc eax
loop: ├─│─│─➤ movsx ecx, byte ptr [rdi]
│ │ │ inc rdi
│ │ │ cmp ecx, 'p'
│ │ ╰── je p
│ │ cmp ecx, 's'
│ ╰──── je s
│ test ecx, ecx
╰────── jne loop
retrun_switches:
xor eax, eax
jmp loop
p: sub eax, 2
s: inc eax
loop: movsx ecx, byte ptr [rdi]
inc rdi
cmp ecx, 'p'
je p
cmp ecx, 's'
je s
test ecx, ecx
jne loop
ret
Вот мы и избавились от ещё одной инструкции ветвления, используя простую арифметику. Хорошо. Но будет ли этот код быстрее?
- Время выполнения: 2.87 s
- Общее ускорение: 1.12x
- Скорость: 332.29 MiB/s
Забавный факт. Всё это время мы сравнивали производительность с выводом clang 16, но gcc 12 на деле выдавал более быстрый (хотя и более громоздкий) код. Его версия выполняется также за 2,87 с, так что мы только её догнали. Но при этом наша программа состоит из 13 инструкций, а программа gcc — из 19.
Похоже, что код gcc развернул цикл и до определённой степени повторно использует блоки кейсов.
▍ Без ветвления
Хорошо, но эти условные ветви являются реальной проблемой, не так ли? Как ускорить их прогнозирование? Я не знаю, поэтому давайте просто не будем его использовать.
# rdi: char *input
# eax: ouput
# r8: 1
# edx: -1
# ecx: char c
# esi: n
run_switches:
xor eax, eax
mov r8d, 1
mov edx, -1
loop:
╭──➤ movsx ecx, byte ptr [rdi]
│ test ecx, ecx
│ ╭─ je ret
│ │ inc rdi
│ │ mov esi, 0
│ │ cmp ecx, 'p'
│ │ cmove esi, edx
│ │ cmp ecx, 's'
│ │ cmove esi, r8d
│ │ add eax, esi
╰─│─ jmp loop
ret: ╰➤ ret# rdi: char *input
# eax: ouput
# r8: 1
# edx: -1
# ecx: char c
# esi: n
run_switches:
xor eax, eax # res = 0
mov r8d, 1 # need 1 in a register later
mov edx, -1 # need -1 in a register later
loop: # while (true) {
movsx ecx, byte ptr [rdi] # char c = *input
test ecx, ecx # if (c == '\0')
je ret # return
inc rdi # input++
mov esi, 0 # n = 0
cmp ecx, 'p' # if (c == 'p')
cmove esi, edx # n = -1
cmp ecx, 's' # if (c == 's')
cmove esi, r8d # n = 1
add eax, esi # res += n
jmp loop # }
ret: ret
Вау, мы удалили из графа потока управления множество стрелок…
Вместо условного ветвления/переходов мы, в зависимости от текущего символа, используем для сложения разные значения. Это мы делаем с помощью cmove или «условного перехода согласно равенству».
Правила таковы: по умолчанию использовать ноль, при встрече s использовать 1, а при встрече p использовать -1. При этом всегда выполнять сложение.
Неплохой поворот, но будет ли так быстрее?
- Время выполнения: 0.48 s
- Общее ускорение: 6.73x
- Скорость: 1.94 GiB/s
Да уж, получилось чертовски быстро.
▍ Освобождение регистра
В x86_64 есть ещё один способ условной установки регистра (1 байта) на 0 или 1. Он называется sete. Давайте используем его и избавимся от нашего r8d.
run_switches:
xor eax, eax
mov edx, -1
loop:
╭──➤ movsx ecx, byte ptr [rdi]
│ test ecx, ecx
│ ╭─ je ret
│ │ inc rdi
│ │ mov esi, 0
│ │ cmp ecx, 's'
│ │ sete sil
│ │ cmp ecx, 'p'
│ │ cmove esi, edx
│ │ add eax, esi
╰─│─ jmp loop
ret: ╰➤ retrun_switches:
xor eax, eax # res = 0
mov edx, -1 # need -1 in a register later
loop: # while (true) {
movsx ecx, byte ptr [rdi] # char c = *input
test ecx, ecx # if (c == '\0')
je ret # return
inc rdi # input++
mov esi, 0 # n = 0
cmp ecx, 's' # c == 's'?
sete sil # n = 0|1
cmp ecx, 'p' # if (c == 'p')
cmove esi, edx # n = -1
add eax, esi # res += n
jmp loop # }
ret: ret
Но обеспечит ли это ускорение?
- Время выполнения: 0.51 s
- Общее ускорение: 6.33x
- Скорость: 1.83 GiB/s
Что ж, получилось медленнее, чем при использовании cmov. Думаю, нет смысла задействовать меньше регистров или использовать 8-битные операции вместо 32-битных.
▍ Другие попытки
Я попытался развернуть цикл нашей лучшей версии кода. В результате код замедлился.
Тогда я решил выровнять начало цикла по 16-байтовой границе (профессиональный совет: вы можете добавить .align перед меткой, и GNU Assembler вставит инструкции nop за вас). Это тоже замедлило код.
▍ Настройка бенчмарка
$ uname -sr
Linux 6.1.33
$ lscpu
...
Model name: AMD Ryzen 5 5625U with Radeon Graphics
CPU family: 25
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
$ clang --version
clang version 16.0.1
$ gcc --version
gcc (GCC) 12.2.0
Версии Си были скомпилированы с использованием -march=native, сообщая компилятору, что нужно создать код, который будет выполняться быстро на конкретно моём процессоре, а не каком-то среднем x86_64.
Этот бенчмарк тысячу раз прогоняет функцию для списка из миллиона символов (со случайными вхождениями p и s).
Для каждой версии я выполнил этот тест несколько раз, выбрав лучшие результаты.
▍ Выводы
Порой можно добиться 6-кратного ускорения путём ручной правки сжатого цикла Си в ассемблере и оптимизации с помощью техник, которые в компиляторы, похоже, ещё не встроили.
Но это ещё не конец, и далее вас ждёт вторая часть моего эксперимента.
Часть II
В первой части мы написали небольшую программу на Си, скомпилировали её, дизассемблировали, а затем скорректировали, добившись шестикратного ускорения. Теперь же мы этот результат улучшим.
Листинги из этой части также лежат на GitHub.
Первая версия нашей программы могла обрабатывать 295.26 MiB/s, а её лучший вариант — 1.94 GiB/s.
Итак, начнём с первой версии:
int run_switches(char *input) {
int res = 0;
while (true) {
char c = *input++;
switch (c) {
case '\0':
return res;
case 's':
res += 1;
break;
case 'p':
res -= 1;
break;
default:
break;
}
}
}# llvm-objdump -d --symbolize-operands --no-addresses --x86-asm-syntax=intel --no-show-raw-insn loop-1-gcc.c.o
run_switches:
xor eax, eax # res = 0
loop: # while (true) {
movsx ecx, byte ptr [rdi] # c = *input
test ecx, ecx # if (c == '\0')
je ret # return
add rdi, 1 # input++
cmp ecx, 'p' # if (c == 'p')
je p # goto p
cmp ecx, 's' # if (c == 's')
jne loop # continue
add eax, 1 # res++
jmp loop # continue
p: add eax, -1 # res--
jmp loop # }
ret: ret# objdump -Mintel -d --no-addresses --no-show-raw-insn --visualize-jumps loop-2-gcc.c.o
run_switches:
xor eax, eax
loop:
╭────➤ movsx ecx, byte ptr [rdi]
│ test ecx, ecx
│ ╭─── je ret
│ │ add rdi, 1
│ │ cmp ecx, 'p'
│ │ ╭─ je p
│ │ │ cmp ecx, 's'
├─│─│─ jne loop
│ │ │ add eax, 1
├─│─│─ jmp loop
p: │ │ ╰➤ add eax, -1
╰─│─── jmp loop
ret: ╰──➤ ret- Время выполнения: 3.23 s
- Скорость: 295.26 MiB/s
▍ Отбрасывание кейсов
Мы выразили задачу логическим образом сверху вниз. В ней мы перебираем входные данные по одному символу и выполняем анализ кейсов для возможных вариантов (иными словами, переключаем символы).
В зависимости от результатов анализа кейсов мы выполняем разный код.
Чтобы этого избежать, мы объединим пути кода, имеющие общую структуру. Оба кейса — p и s — добавляют в аккумулятор число. Может, тогда вместо выполнения анализа кейсов для перехода к следующему пути кода, мы будем с помощью того же анализа получать число для прибавления?
Это число можно искать в массиве:
#include
static
int to_add[256] = {
['s'] = 1,
['p'] = -1,
};
int run_switches(const char *input) {
int res = 0;
while (true) {
char c = *input++;
if (c == '\0') {
return res;
} else {
res += to_add[(int) c];
}
}
} # objdump -Mintel -d --no-addresses --no-show-raw-insn --visualize-jumps loop-2-gcc.c.o
run_switches:
movsx rax, byte ptr [rdi]
lea rdx, [rdi+1]
xor ecx, ecx
lea rsi, [rip+0] #
test al, al
╭─── je ret
│ nop dword ptr [rax]
loop: │ ╭➤ add rdx, 0x1
│ │ add ecx, dword ptr [rsi+rax*4]
│ │ movsx rax, byte ptr [rdx-1]
│ │ test al, al
│ ╰─ jne loop
ret: ╰──➤ mov eax, ecx
ret # objdump -Mintel -d --no-addresses --no-show-raw-insn --visualize-jumps loop-2-clang.c.o
run_switches:
mov cl, byte ptr [rdi]
test cl, cl
╭─── je ret
│ add rdi, 0x1
│ xor eax, eax
│ lea rdx, [rip+0x0] #
│ cs nop word ptr [rax+rax*1+0x0]
│ nop dword ptr [rax]
loop: │ ╭➤ movsx rcx, cl
│ │ add eax, dword ptr [rdx+rcx*4]
│ │ movzx ecx, byte ptr [rdi]
│ │ add rdi, 0x1
│ │ test cl, cl
│ ╰─ jne loop
│ ret
ret: ╰──➤ xor eax, eax
ret - Время выполнения GCC: 0.47 s
- Скорость GCC: 1.98 GiB/s
- Время выполнения Clang: 0.25 s
- Скорость Clang: 3.72 GiB/s
Неплохо. В случае gcc мы достигли скорости нашей лучшей (cmov) версии из предыдущей части, но вывод clang почти вдвое её опередил.
Между gcc и clang присутствует какое-то реально странное отличие. Насколько сильной может быть разница в быстродействии между этими строками:
movzx ecx, byte ptr [rdi]
movsx rax, byte ptr [rdx-1]
Думаю, что смогу заставить gcc cгенерировать версию с movzx (перемещение и дополнение нулями) вместо movsx (перемещение и дополнение символами), используя в качестве инструкции беззнаковый целочисленный тип, то есть uint8_t или unsigned char вместо char.
Попробуем:
#include
#include
static
int to_add[256] = {
['s'] = 1,
['p'] = -1,
};
int run_switches(const uint8_t *input) {
int res = 0;
while (true) {
uint8_t c = *input++;
if (c == '\0') {
return res;
} else {
res += to_add[(int) c];
}
}
} # objdump -Mintel -d --no-addresses --no-show-raw-insn --visualize-jumps loop-3-gcc.c.o
run_switches:
movzx eax, byte ptr [rdi]
lea rdx, [rdi+0x1]
xor ecx, ecx
lea rsi, [rip+0x0]
test al, al
╭───── je ret
│ nop dword ptr [rax+0x0]
loop: │ ╭─➤ movzx eax, al
│ │ add rdx, 1
│ │ add ecx, dword ptr [rsi+rax*4]
│ │ movzx eax, byte ptr [rdx-1]
│ │ test al, al
│ ╰── jne loop
ret: ╰────➤ mov eax,ecx
ret# objdump -Mintel -d --no-addresses --no-show-raw-insn --visualize-jumps loop-3-clang.c.o
run_switches:
mov cl, byte ptr [rdi]
test cl, cl
╭───── je ret
│ add rdi, 1
│ xor eax, eax
│ lea rdx, [rip+0x0]
│ cs nop word ptr [rax+rax*1+0x0]
│ nop dword ptr [rax]
loop: │ ╭─➤ movzx ecx, cl
│ │ add eax, dword ptr [rdx+rcx*4]
│ │ movzx ecx, byte ptr [rdi]
│ │ add rdi, 1
│ │ test cl, cl
│ ╰── jne loop
│ ret
ret: ╰────➤ xor eax,eax
ret
Сработало, но окажется ли этот код быстрее?
- Время выполнения GCC: 0.47 s
- Скорость GCC: 1.98 GiB/s
- Время выполнения Clang: 0.25 s
- Скорость Clang: 3.72 GiB/s
Нет. Всё в точности, как и прежде. Хорошо, тогда в чём отличие между этими вариантами:
loop: ╭─➤ movzx eax, al
│ add rdx, 1
│ add ecx, dword ptr [rsi+rax*4]
│ movzx eax, byte ptr [rdx-1]
│ test al, al
╰── jne looploop: ╭─➤ movzx ecx, cl
│ add eax, dword ptr [rdx+rcx*4]
│ movzx ecx, byte ptr [rdi]
│ add rdi, 1
│ test cl, cl
╰── jne loop
Отличия три:
- порядок;
[rdi]вместо[rdx - 1];- выбор регистров.
▍ Пропуск дополнения
Оба компилятора выдали инструкцию movzx для преобразования входного символа в целое число.
Я не думаю, что эта инструкция необходима в каком-либо из этих компиляторов, поскольку 32-битные операции на x86_64 внутренне выполняют дополнение нулями, и я не вижу ни одного пути кода, где старшие биты были бы установлены.
Тем не менее некоторое чутьё подсказывает мне, что можно избавиться от этих инструкций на стороне Си, заменив:
uint8_t c = *input++;
На
uint64_t c = *input++;
Таким образом мы удаляем всю идентификацию этого значения как 8-битного, требующего дополнения нулями.
loop: /-> add rdx, 1
| add ecx, dword ptr [rsi+rax*4]
| movzx eax, byte ptr [rdx-1]
| test rax, rax
\-- jne looploop: /-> movzx ecx,cl
| add eax,dword ptr [rdx+rcx*4]
| movzx ecx,byte ptr [rdi]
| add rdi,0x1
| test cl,cl
\-- jne
Что ж, для gcc сработало.
На одну инструкцию меньше без разбирания кода до уровня ассемблера. Весьма неплохо.
- Время выполнения gcc 0.47 s
- Скорость gcc: 1.98 GiB/s
Но…никакого эффекта.
▍ Переписывание asm
Давайте перепишем этот код в ассемблере — это позволит понять, что именно происходит.
Нет, нельзя надёжно пересобрать дизассемблированный код… Потребуется по меньшей мере скорректировать вывод. В данном случае я написал массив, из которого выполняется считывание посредством директив ассемблера gcc, и добавил метки перехода, чтобы сделать его читаемым.
.text
run_switches:
xor eax, eax # res = 0
loop: # while (true) {
/----> movsx rcx, byte ptr [rdi] # char c = *input
| test rcx, rcx # if (c == '\0')
| /-- je ret # return
| | add eax, dword ptr [arr+rcx*4] # res += arr[c]
| | inc rdi # input++
\--|-- jmp loop # }
ret: \-> ret
.data
arr:
.fill 'p', 4, 0
.long -1, 0, 0, 1
.fill (256 - 's'), 4, 0
Это моё первое выполнение, и тут мы видим буквальный перевод версии Си. Здесь у нас на критическом пути даже два перехода (один дополнительный безусловный) в сравнении с выводом gcc и clang. Как же это скажется на скорости?
- Время выполнения: 0.24 s
- Скорость: 3.88 GiB/s
Что ж, этот вариант с первой попытки превзошёл gcc и clang. Я ожидал, что будет труднее написать более быстрый код, чем создают современные компиляторы со множеством оптимизаций…
▍ Разбираем кодирование
Вывод gcc загружает адрес массива в регистр и использует его для обращения к этому массиву на критическом пути:
lea rsi, [add_arr]
...
add ecx, dword ptr [rsi+rax*4]
Это кажется излишним, так что мы наверняка можем избавиться от лишней инструкции lea, используя адрес массива напрямую.
add ecx, dword ptr [arr+rax*4]
Мы удалили одну инструкцию (lea) из не критического пути, так? Да, но если сопоставить кодировки инструкций, то мы увидим, что увеличили количество байтов, требуемых для кодирования add, а add является инструкцией на критическом пути.
48 8d 34 25 00 00 00 lea rsi,ds:0x0
...
03 0c 86 add ecx,DWORD PTR [rsi+rax*4]...
03 0c 85 00 00 00 00 add ecx,DWORD PTR [rax*4+0]
Думаю, что загрузка адреса первого элемента массива в rsi является хорошей оптимизацией, если у вас есть свободные регистры. Пока проигнорируем этот момент.
▍ Исправление кода gcc
В действительности мы хотим знать, почему внутренний цикл gcc почти вдвое медленнее clang несмотря на то, что они так похожи. Чтобы это выяснить, я скопировал код gcc в программу ассемблера здесь и внёс изменения, необходимые для того, чтобы он заработал.
Если мы выполним бенчмарк для дизассемблированной версии, то он должен занять столько же времени, что и версия gcc, то есть 0,47 секунды.
Ноооо, он занял 0,26 с, оказавшись почти вдвое быстрее. Думаю, я допустил ошибку? Давайте поищем отличия в выводе.
9: 48 8d 35 00 00 00 00 lea rsi,[rip+0]
10: 48 85 c0 test rax,rax
13: 74 13 je 28 ret 9: 48 8d 34 25 00 00 00 lea rsi,ds:0
10: 00
11: 48 85 c0 test rax,rax
14: 74 13 je 29 ret
Ага! Здесь у нас несколько иная кодировка lea.
Я не совсем уверен, что послужило причиной, так как в обеих версиях массив, похоже, сохраняется в разделе .rodata бинарника. Если кто-то понимает разницу между этими двумя кодировками, отпишите в комментариях или мне на почту.
Итак, поскольку единственное ощутимое отличие находится перед критическим путём, я предполагаю, что на производительность влияет разница в выравнивании.
Безусловно, если добавить перед нашим сжатым циклом пять невинных no-op, то мы вернёмся к быстродействию gcc.
Но мы сделаем лучше и построим график, который отразит связь добавления заполняющих no-op и времени выполнения.

Итак, начиная с пяти no-op (по одному байту каждая), мы получаем 2-кратное замедление, которое сохраняется вплоть до 20 no-op, после чего происходит ускорение. Это повторяющийся паттерн?
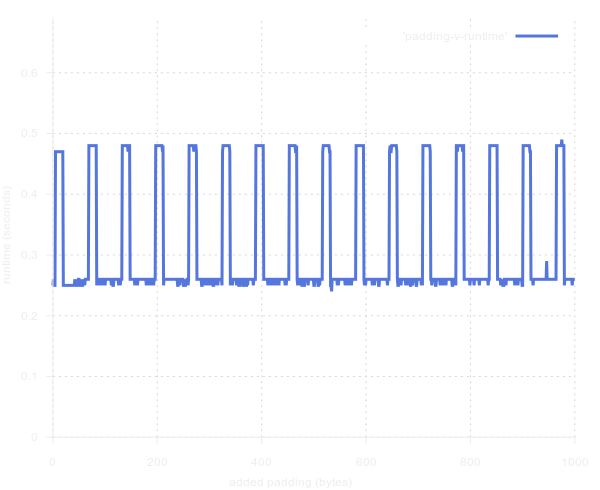
Да, он определённо повторяется. С какой периодичностью? Надеюсь, что это удобная степень двойки…
… Это 64 — очень хорошо.
В течение 15 байт заполнения выполнение происходит медленно, после чего в течение 49 оно происходит быстро.
Мой внутренний цикл измеряет ровно 16 байт. Значит, этот повторяющийся паттерн из 15 медленных версий должен быть связан с моментом, когда внутренний цикл gcc распределяется вдоль границы двух кэш-линий. А каков размер кэш-линии на моем процессоре? 64 байта.
Хорошие новости! Мы выяснили причину отличия в скорости.
Итак, как нам убедить gcc выровнять цикл более удачно?
Я попробовал CFLAGS=-falign-jumps= при различных значениях n, но ничего не произошло.

Причина, похоже, в том, что верхний сегмент нашего цикла, являясь целью ветвления, также выступает местом, куда происходит переход из кода выше.
Фрагмент из документации gcc:Цели ветвления, которые могут быть достигнуты только путём перехода, следует выравнивать по величине, равной степени двойки.
К счастью, CFLAGS=-falign-loops=16 работает!
В документации сказано, что -falign-loops активна по умолчанию с оптимизациями, установленными на >= -O2. Но в ней также говорится: «Если n не указано или равно нулю, используйте значение по умолчанию, определяемое машиной». Думаю, что на моей машине это значение меньше 16:/
Также кажется излишним применять эту опцию для всей компилируемой единицы. В идеале это выравнивание желательно устанавливать вручную только для внутреннего цикла. Gcc предоставляет атрибуты выравнивания, например, __attribute__((aligned(16))), но они не применимы к меткам/инструкциям — только к функциям.
Вся наша функция фактически вписывается в одну кэш-линию и, действительно, установка __attribute__((aligned(64))) для run_switches работает. Думаю, что это самый тонкий контроль, который вы можете получить, не разбирая код до уровня ассемблера. Хотя, возможно, кто-то знает способ получше?
Заключение
- Пожалуй, нет смысла оптимизировать не критические пути.
- Сжатые, выровненные циклы, вписывающиеся в кэш-линию, выполняются молниеносно.
- Сжатые циклы, распределённые по двум кэш-линиям, могут выполняться в 2 раза медленнее своих выровненных альтернатив.
- Похоже, gcc по умолчанию выравнивает код не слишком строго.
- При написании кода GNU Assembler вашим другом окажется
.align.
Выиграй телескоп и другие призы в космическом квизе от RUVDS. Поехали?
