[Перевод] Трюки с SQL от DBA. Не банальные советы для разработчиков БД

Когда я начинал свою карьеру разработчика, моей первой работой стала DBA (администратор базы данных, АБД). В те годы, ещё до AWS RDS, Azure, Google Cloud и других облачных сервисов, существовало два типа АБД:
- АБД инфраструктуры отвечали за настройку базы данных, конфигурирование хранилища и заботу о резервных копиях и репликации. После настройки БД инфраструктурный администратор время от времени «настраивал экземпляры», например, уточнял размеры кэшей.
- АБД приложения получал от АБД инфраструктуры чистую базу и отвечал за её архитектуру: создание таблиц, индексов, ограничений и настройку SQL. АБД приложения также реализовывал ETL-процессы и миграцию данных. Если команды использовали хранимые процедуры, то АБД приложения поддерживал и их.
АБД приложений обычно были частью команд разработки. Они обладали глубокими познаниями по конкретной теме, поэтому обычно работали только над одним-двумя проектами. Инфраструктурные администраторы баз данных обычно входили в ИТ-команду и могли одновременно могли работать над несколькими проектами.
Я админ базы данных приложения
У меня никогда не было желания возиться с бэкапами или настраивать хранилище (уверен, это увлекательно!). По сей день мне нравится говорить, что я админ БД, который знает, как разрабатывать приложения, а не разработчик, который разбирается в базах данных.
В этой статье я поделюсь хитростями о разработке баз данных, которые узнал за свою карьеру.
Содержание:
Обновляйте лишь то, что нужно обновить
Операция UPDATE потребляет довольно много ресурсов. Для её ускорения лучше всего обновлять только то, что нужно обновить.
Вот пример запроса на нормализацию колонки email:
db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
Выглядит невинно, да? Запрос обновляет адреса почты для 1 010 000 пользователей. Но нужно ли обновлять все строки?
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
Нужно было обновить всего 10 000 строк. Уменьшив количество обрабатываемых данных, мы снизили длительность исполнения с 1,5 секунд до менее чем 300 мс. Это также сэкономит нам в дальнейшем силы на сопровождение базы данных.
Обновляйте лишь то, что нужно обновить.
Такой тип больших обновлений очень часто встречается в скриптах миграции данных. Когда в следующий раз будете писать подобный скрипт, убедитесь, что обновляете лишь необходимое.
При больших загрузках отключайте ограничения и индексы
Ограничения — важная часть реляционных баз данных: они сохраняют консистентность и надёжность данных. Но у всего своя цена, и чаще всего расплачиваться приходится при загрузке или обновлении большого количества строк.
Давайте зададим схему небольшого хранилища:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
Здесь определяются разные типы ограничений, таких как «not null», а также уникальные ограничения…
Чтобы задать исходную точку, начнём добавлять в таблицу sale внешние ключи
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
После определения ограничений и индексов загрузка в таблицу миллиона строк заняла около 15,4 с.
Теперь сначала загрузим данные в таблицу, и только потом добавим ограничения и индексы:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
Загрузка прошла гораздо быстрее, 2,27 с. вместо 15,4. Индексы и ограничения создавались после загрузки данных заметно дольше, но весь процесс оказался намного быстрее: 3,1 с. вместо 15,4.
К сожалению, в PostgreSQL с индексами так же поступить не получится, можно лишь выбрасывать и пересоздавать их. В других базах, например, Oracle, можно отключать и включать индексы без пересоздания.
Для промежуточных данных используйте UNLOGGED-таблицы
Когда вы меняете данные в PostgreSQL, изменения записываются в журнал с упреждающей записью (write ahead log (WAL)). Он используется для поддержания целостности, быстрой переиндексации в ходе восстановления и поддержки репликации.
Запись в WAL нужна часто, но есть некоторые обстоятельства, при которых вы можете отказаться от WAL ради ускорения процессов. Например, в случае с промежуточными таблицами.
Промежуточными называют одноразовые таблицы, в которых хранятся временные данные, используемые для реализации каких-то процессов. К примеру, в ETL-процессах очень часто загружают данные из CSV-файлов в промежуточные таблицы, очищают информацию, а затем грузят её в целевую таблицу. В таком сценарии промежуточная таблица является одноразовой и не используется в резервных копиях или репликах.
UNLOGGED-таблица.
Промежуточные таблицы, которые не нужно восстанавливать в случае сбоя и которые не нужны в репликах, можно задать как UNLOGGED:
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
Внимание: прежде чем использовать UNLOGGED, убедитесь, что полностью понимаете все последствия.
Реализуйте процессы целиком с помощью WITH и RETURNING
Допустим, у вас таблица пользователей, и вы обнаружили, что в ней есть дублирующиеся данные:
Table setup
db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
Пользователь haki benita зарегистрирован дважды, с почтой ME@hakibenita.com и me@hakibenita.com. Поскольку мы не нормализуем адреса почты при внесении в таблицу, теперь придётся разобраться с дублями.
Нам нужно:
- Определить дубли по адресам, написанным строчными буквами, и связать дублирующихся пользователей друг с другом.
- Обновить заказы, чтобы они ссылались только на один из дублей.
- Убрать дубли из таблицы.
Связать дублирующихся пользователей можно с помощью промежуточной таблицы:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
В промежуточной таблице содержатся связи между дублями. Если пользователь с нормализованным адресом почты появляется более одного раза, мы присваиваем ему минимальный ID пользователя, в которого свёрнём все дубли. Остальные пользователи хранятся в array column и все ссылки на них будут обновлены.
С помощью промежуточной таблицы обновим ссылки на дубли в таблице orders:
db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
Теперь можно безопасно удалить дубли из users:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
Обратите внимание, что для «преобразования» массива мы использовали функцию unnest, которая превращает каждый элемент в строку.
Результат:
db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
Отлично, все экземпляры пользователя 3 (ME@hakibenita.com) преобразованы в пользователя 2 (me@hakibenita.com).
Можем также проверить, что дубли удалены из таблицы users:
db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
Теперь можно избавиться от промежуточной таблицы:
db=# DROP TABLE duplicate_users;
DROP TABLE
Всё хорошо, но слишком долго и нужна очистка! Есть ли способ получше?
Обобщённые табличные выражения (CTE)
С помощью обобщённых табличных выражений, также известных как выражение WITH, мы можем выполнить всю процедуру с помощью единственного SQL-выражения:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
Вместо промежуточной таблицы мы создали обобщённое табличное выражение и многократно его использовали.
Возврат результатов из CTE
Одно из преимуществ исполнения DML внутри выражения WITH заключается в том, что вы можете вернуть из него данные с помощью ключевого слова RETURNING. Допустим, нам нужен отчёт о количестве обновлённых и удалённых строк:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
Результат:
orders_updated | users_deleted
----------------+---------------
2 | 1
Привлекательность подхода в том, что весь процесс выполняется одной командой, поэтому нет необходимости управлять транзакциями или беспокоиться об очистке промежуточной таблицы в случае сбоя процесса.
Внимание: Читатель Reddit указал мне на возможное непредсказуемое поведение исполнения DML в обобщённых табличных выражениях:
Подвыражения вWITHисполняются конкурентно друг с другом и с основным запросом. Поэтому при использовании вWITHмодифицирующих данные выражений фактический порядок обновлений будет непредсказуемым
Это означает, что вы не можете полагаться на порядок исполнения независимых подвыражений. Получается, что если между ними есть зависимость, как в примере выше, вы можете полагаться на исполнение зависимых подвыражение до их использования.
В колонках с низкой избирательностью избегайте индексов
Допустим, у вас есть процесс регистрации, при котором пользователь входит по адресу почты. Чтобы активировать аккаунт, нужно верифицировать почту. Таблица может выглядеть так:
db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLE
Большинство ваших пользователей — граждане сознательные, они регистрируются с корректным почтовым адресом и немедленно активируют аккаунт. Давайте заполним таблицу пользовательскими данными, и будем считать, что 90% пользователей активировано:
db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUM
Чтобы запросить количество активированных и неактивированных пользователей, можно создать индекс по колонке activated:
db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEX
И если вы запросите количество неактивированных пользователей, база воспользуется индексом:
db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
База решила, что фильтр выдаст 102 567 позиций, примерно 10% таблицы. Это согласуется с загруженными нами данными, так что таблица хорошо справилась.
Однако если мы запросим количество активированных пользователей, то обнаружим, что база решила не использовать индекс:
db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activated
Многих разработчиков сбивает с толку, когда база данных не использует индекс. Объяснить, почему она так делает, можно следующим образом: если бы вам нужно было прочитать всю таблицу, вы воспользовались бы индексом?
Вероятно, нет, зачем это нужно? Чтение с диска — операция дорогая, поэтому вы захотите читать как можно меньше. Например, если таблица размером 10 Мб, а индекс размером 1 Мб, то для считывания всей таблица придётся считать с диска 10 Мб. А если добавить индекс, то получится 11 Мб. Это расточительно.
Давайте теперь посмотрим на статистику, которую PostgreSQL собрал по нашей таблице:
db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}
Когда PostgreSQL проанализировал таблицу, он выяснил, что в колонке activated есть два разных значения. Значение t в колонке most_common_vals соответствует частоте 0.89743334 в колонке most_common_freqs, а значение f соответствует частоте 0.10256667. После анализа таблицы база данных определила, что 89,74% записей — это активированные пользователи, а остальные 10,26% — неактивированные.
На основе этой статистики PostgreSQL решил, что лучше сканировать всю таблицу, чем предполагать, что 90% строк удовлетворят условию. Порог, после которого база может решать, использовать ли ей индекс, зависит от многих факторов, и никакого эмпирического правила тут нет.
Индекс для колонок с низкой и высокой избирательностью.
Используйте частичные индексы
В предыдущей главе мы создали индекс для колонки с булевыми значениями, в которой около 90% записей были true (активированные пользователи).
Когда мы запросили количество активных пользователей, база не использовала индекс. А когда запросили количество неактивированных, база использовала индекс.
Возникает вопрос: если база не собирается пользоваться индексом для отфильтровывания активных пользователей, зачем нам индексировать их в первую очередь?
Прежде чем ответить на это вопрос, давайте посмотрим на вес полного индекса по колонке activated:
db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MB
Индекс весит 21 Мб. Просто для справки: таблица с пользователями занимает 65 Мб. То есть вес индекса ~32% веса базы. При этом мы знаем, что ~90% содержимого индекса вряд ли будет использоваться.
В PostgreSQL можно создавать индекс только для части таблицы — так называемый частичный индекс:
db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEX
С помощью выражения WHERE мы ограничиваем охватываемые индексом строки. Давайте проверим, сработает ли:
db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)
Отлично, база оказалась достаточно умной и поняла, что использованный нами в запросе логическое выражение может подойти для частичного индекса.
У такого подхода есть ещё одно преимущество:
db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kB
Полный индекс по колонке весит 21 Мб, а частичный — всего 2,2 Мб. То есть 10%, что соответствует доле неактивированных пользователей в таблице.
Всегда загружайте отсортированные данные
Это один из самых частых моих комментариев при разборе кода. Совет не столь интуитивный, как остальные, и может оказать огромное влияние на производительность.
Допустим, у вас есть огромная таблица с конкретными продажами:
db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLE
Каждую ночь в ходе ETL-процесса вы загружаете данные в таблицу:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Чтобы сымитировать загрузку, используем случайные данные. Вставили 100 тыс. строк со случайными именами, а даты продаж за период с 1 января 2020 и на два года вперёд.
По большей части таблица используется для итоговых отчётов о продажах. Чаще всего фильтруют по дате, чтобы посмотреть продажи за определённый период. Чтобы ускорить сканирование диапазона, создадим индекс по sold_at:
db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEX
Взглянем на план исполнения запроса на извлечение всех продаж в июне 2020:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 ms
Прогнав запрос несколько раз, чтобы прогреть кэш, длительность исполнения стабилизировалась на уровне 6 мс.
Сканирование по битовой карте (Bitmap Scan)
В плане исполнения мы видим, что база использовала сканирование по битовой карте. Оно проходит в два этапа:
Построение битовой карты (Bitmap Index Scan): база проходит по всему индексуsale_fact_sold_at_ixи находит все страницы таблицы, содержащие релевантные строки.Сканирование по битовой карте (Bitmap Heap Scan): база считывает страницы, содержащие релевантные строки, и находит те из них, что удовлетворяют условию.
Страницы могут содержать много строк. На первом этапе индекс используется для поиска страниц. На втором этапе ищутся строки в страницах, отсюда следует операция Recheck Cond в плане исполнения.
На этом моменте многие администраторы баз данных и разработчики закруглятся и перейдут к следующему запросу. Но есть способ улучшить этот запрос.
Индексное сканирование (Index Scan)
Внесём небольшое изменение в загрузку данных.
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
На этот раз мы загрузили данные, отсортированные по sold_at.
Теперь план исполнения того же запроса выглядит так:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 ms
После нескольких прогонов длительность исполнения стабилизировалась на уровне 2,3 мс. Мы получили устойчивую экономию примерно в 60%.
Также мы видим, что в этот раз база не стала использовать сканирование по битовой карте, а применила «обычное» индексное сканирование. Почему?
Корреляция
Когда база анализирует таблицу, она собирает всю возможную статистику. Одним из параметров является корреляция:
Статистическая корреляция между физическим порядком строк и логическим порядком значений в колонках. Если значение около -1 или +1, индексное сканирование по колонке считается выгоднее, чем когда значение корреляции около 0, поскольку снижается количество случайных обращений к диску.
Как объясняется в официальной документации, корреляция является мерой того, как «отсортированы» значения в конкретной колонке на диске.
Корреляция = 1.
Если корреляция равна 1 или около того, это означает, что страницы хранятся на диске примерно в том же порядке, что и строки в таблице. Такое встречается очень часто. Например, у автоинкрементирующихся ID корреляция обычно близка к 1. У колонок с датами и временными метками, которые показывают, когда были созданы строки, корреляция тоже близка к 1.
Если корреляция равна -1, страницы отсортированы в обратном порядке относительно колонок.
Корреляция ~ 0.
Если корреляция близка к 0, это означает, что значения в колонке не коррелируют или почти не коррелируют с порядком страниц в таблице.
Вернёмся к sale_fact. Когда мы загрузили данные в таблицу без предварительной сортировки, корреляции были такими:
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783
У автоматически сгенерированного ID колонки корреляция равна 1. У колонки sold_at корреляция очень низкая: последовательные значения разбросаны по всей таблице.
Когда мы загрузили отсортированные данные в таблицу, она вычислила корреляции:
tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1
Теперь корреляция sold_at равна 1.
Так почему база использовала сканирование по битовой карте, когда корреляция была низкой, а при высокой корреляции применила индексное сканирование?
- Когда корреляция была равна 1, база определила, что строки запрошенного диапазона, вероятно, будут в последовательных страницах. Тогда для чтения нескольких страниц лучше использовать индексное сканирование.
- Когда корреляция была близка к 0, база определила, что строки запрошенного диапазона, вероятно, будут разбросаны по всей таблице. Тогда целесообразно использовать сканирование по битовой карте тех страниц, в которых есть нужные строки, и только потом извлекать их с применением условия.
Когда в следующий раз будете загружать данные в таблицу, подумайте о том, сколько информации будет запрашиваться, и отсортируйте так, чтобы индексы могли быстро сканировать диапазоны.
Команда CLUSTER
Другой способ «сортировки таблицы на диске» по конкретному индексу заключается в использовании команды CLUSTER.
Например:
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822
Мы загрузили данные в таблицу в случайном порядке, поэтому корреляция sold_at близка к нулю.
Чтобы «перекомпоновать» таблицу по sold_at, используем команду CLUSTER для сортировки таблицы на диске в соответствии с индексом sale_fact_sold_at_ix:
db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298
После кластеризации таблицы корреляция sold_at стала равна 1.
Команда CLUSTER.
Что нужно отметить:
- Кластеризация таблицы по конкретной колонке может повлиять на корреляцию другой колонки. Например, взгляните на корреляцию ID после кластеризации по
sold_at. CLUSTER— тяжёлая и блокирующая операция, поэтому не применяйте её к живой таблице.
По этим причинам лучше вставлять уже отсортированные данные и не полагаться на CLUSTER.
Колонки с высокой корреляцией индексируйте с помощью BRIN
Когда речь заходит об индексах, многие разработчики думают о В-деревьях. Но PostgreSQL предлагает и другие типы индексов, например, BRIN:
BRIN спроектирован для работы с очень большими таблицами, в которых некоторые колонки обладают естественной корреляцией со своим физическим местоположением внутри таблицы
BRIN означает Block Range Index. Согласно документации, BRIN лучше всего работает с колонками, имеющими высокую корреляцию. Как мы уже видели в предыдущих главах, автоинкрементирующиеся ID и временные метки естественным образом коррелируют с физической структурой таблицы, поэтому для них выгоднее использовать BRIN.
При определённых условиях BRIN может обеспечить лучшее «соотношение цены и качества» с точки зрения размера и производительности по сравнению с аналогичным индексом типа B-дерево.
BRIN.
BRIN диапазон значений в пределах нескольких соседних страниц в таблице. Допустим, у нас в колонке есть такие значения, каждое в отдельной странице:
1, 2, 3, 4, 5, 6, 7, 8, 9
BRIN работает с диапазонами соседних страниц. Если задать три смежные страницы, индекс разделит таблицу на диапазоны:
[1,2,3], [4,5,6], [7,8,9]
Для каждого диапазона BRIN хранит минимальное и максимальное значение:
[1–3], [4–6], [7–9]
Давайте с помощью этого индекса поищем значение 5:
- [1–3] — здесь его точно нет.
- [4–6] — может быть здесь.
- [7–9] — здесь его точно нет.
С помощью BRIN мы ограничили зону поиска блоком 4–6.
Возьмём другой пример. Пусть значения в колонке будут иметь корреляцию близкой к нулю, то есть они не отсортированы:
[2,9,5], [1,4,7], [3,8,6]
Индексирование трёх соседних блоков даст нам такие диапазоны:
[2–9], [1–7], [3–8]
Поищем значение 5:
- [2–9] — может быть здесь.
- [1–7] — может быть здесь.
- [3–8] — может быть здесь.
В этом случае индекс вообще не сужает область поиска, поэтому он бесполезен.
Разбираемся с pages_per_range
Количество смежных страниц определяется параметром pages_per_range. Количество страниц в диапазоне влияет на размер и точность BRIN:
- Большое значение
pages_per_rangeдаст маленький и менее точный индекс. - Маленькое значение
pages_per_rangeдаст большой и более точный индекс.
По умолчанию значение pages_per_range равно 128.
BRIN с более низким значением pages_per_range.
Для иллюстрации создадим BRIN с диапазонами по две страницы и поищем значение 5:
- [1–2] — здесь его точно нет.
- [3–4] — здесь его точно нет.
- [5–6] — может быть здесь.
- [7–8] — здесь его точно нет.
- [9] — здесь его точно нет.
При двухстраничном диапазоне мы можем ограничить зону поиска блоками 5 и 6. Если диапазон будет трёхстраничным, индекс ограничит зону поиска блоками 4, 5 и 6.
Другим различием между двумя индексами является то, что когда диапазон равнялся трём страницам, нам нужно было хранить три диапазона, а при двух страницах в диапазоне мы получаем уже пять диапазонов и индекс увеличивается.
Создаём BRIN
Возьмём таблицу sales_fact и создадим BRIN по колонке sold_at:
db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEX
По умолчанию значение pages_per_range = 128.
Теперь запросим период дат продаж:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 ms
База с помощью BRIN получила период дат, но в этом ничего интересного…
Оптимизируем pages_per_range
Согласно плану исполнения, база убрала из страниц 23 130 строк, которые нашла с помощью индекса. Это может говорить о том, что заданный нами для индекса диапазон слишком велик для этого запроса. Создадим индекс с вдвое меньшим количеством страниц в диапазоне:
db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 ms
При 64 страницах в диапазоне база удалила меньше строк, найденных с помощью индекса — 9 434. Значит, ей пришлось делать меньше операций ввода-вывода, а запрос выполнился чуть быстрее, за ~5,5 мс вместо ~8,9.
Протестируем индекс с разными значениями pages_per_range:
При уменьшении pages_per_range индекс становится точнее, а из найденных с его помощью страниц удаляется меньше строк.
Обратите внимание, что мы оптимизировали совершенно конкретный запрос. Для иллюстрации годится, но в реальной жизни лучше использовать значения, которые соответствуют потребностям большинства запросов.
Оценка размера индекса
Другим важным преимуществом BRIN является его размер. В предыдущих главах мы для поля sold_at создали индекс на основе В-дерева. Его размер был 2 224 Кб. А размер BRIN с параметром pages_per_range=128 всего 48 Кб: в 46 раз меньше.
Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
На размер BRIN также влияет pages_per_range. К примеру, BRIN с pages_per_range=2 весит 56 Кб, чуть больше 48 Кб.
Делайте индексы «невидимыми»
В PostgreSQL есть классная фича transactional DDL. За годы работы с Oracle я привык в конце транзакций использовать такие DDL-команды, как CREATE, DROP и ALTER. Но в PostgreSQL выполнять DDL-команды можно внутри транзакции, а изменения будут применены только после коммита транзакции.
Недавно я обнаружил, что использование транзакционного DDL может сделать индексы невидимыми! Это полезно, когда хочется увидеть план исполнения без индексов.
Например, в таблице sale_fact мы создали индекс по колонке sold_at. План исполнения запроса на извлечение июльских продаж выглядит так:
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))P
Чтобы увидеть, как выглядел бы план, если бы индекса sale_fact_sold_at_ix не было, можно поместить индекс внутрь транзакции и немедленно откатиться:
db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACK
Сначала начнём транзакцию с помощью BEGIN. Затем дропнем индекс и сгенерируем план исполнения. Обратите внимание, что план теперь использует полностье сканирование таблицы, словно индекса не существует. В этот момент транзакция всё ещё выполняется, поэтому индекс пока не дропнут. Для завершения транзакции без дропа индекса откатим её с помощью команды ROLLBACK.
Проверим, что индекс ещё существует:
db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
Другие базы, которые не поддерживают транзакционный DDL, позволяют достичь цели иначе. Например, Oracle позволяет вам пометить индекс как невидимый, и тогда оптимизатор будет его игнорировать.
Внимание: если дропнуть индекс внутри транзакции, это приведёт к блокировке конкурентных операций SELECT, INSERT, UPDATE и DELETE в таблице, пока транзакция будет активна. Осторожно применяйте в тестовых средах и избегайте применения в эксплуатационных базах.
Не планируйте начало длительных процессов на начало любого часа
Инвесторы знают, что могут происходить странные события, когда цена акций достигает красивых круглых значений, например, 10$, 100$, 1000$. Вот что об этом пишут:
[…] цена активов может непредсказуемо меняться, пересекая круглые значения вроде $50 или $100 за акцию. Многие неопытные трейдеры любят покупать или продавать активы, когда цена достигает круглых чисел, потому что им кажется, что это справедливые цены.
С этой точки зрения разработчики не слишком отличаются от инвесторов. Когда им нужно запланировать длительный процесс, они обычно выбирают какой-то час.
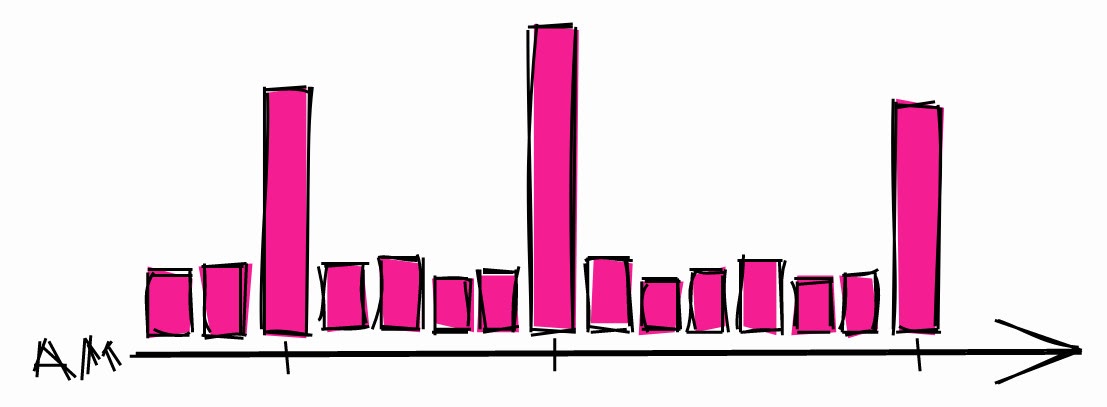
Типичная ночная нагрузка на систему.
Это может привести к всплескам нагрузки в эти часы. Так что если вам нужно запланировать длительный процесс, то больше шансов, что в другое время система будет простаивать.
Также рекомендуется применять в расписаниях случайные задержки, чтобы не запускаться каждый раз в одно и то же время. То
