[Перевод] Стратегии по ускорению кода на R, часть 1
Цикл for в R может быть очень медленным, если он применяется в чистом виде, без оптимизации, особенно когда приходится иметь дело с большими наборами данных. Есть ряд способов сделать ваш код быстрее, и вы, вероятно, будете удивлены, узнав насколько.
Эта статья описывает несколько подходов, в том числе простые изменения в логике, параллельную обработку и Rcpp, увеличивая скорость на несколько порядков, так что можно будет нормально обрабатывать 100 миллионов строк данных или даже больше.
Давайте попробуем ускорить код с циклом for и условным оператором (if-else) для создания колонки, которая добавляется к набору данных (data frame, df). Код ниже создает этот начальный набор данных.
# Создание набора данных
col1 <- runif (12^5, 0, 2)
col2 <- rnorm (12^5, 0, 2)
col3 <- rpois (12^5, 3)
col4 <- rchisq (12^5, 2)
df <- data.frame (col1, col2, col3, col4)
В этой части: векторизация, только истинные условия, ifelse.
В следующей части: which, apply, побайтовая компиляция, Rcpp, data.table.
Логика, которую мы собираемся оптимизировать
Для каждой строки в этом наборе данных (df) проверить, превышает ли сумма значений 4. Если да, новая пятая переменная получает значение «greater_than_4», в противном случае — «lesser_than_4».
# Исходный код на R: Перед векторизацией и предварительным выделением
system.time({
for (i in 1:nrow(df)) { # for every row
if ((df[i, 'col1'] + df[i, 'col2'] + df[i, 'col3'] + df[i, 'col4']) > 4) { # check if > 4
df[i, 5] <- "greater_than_4" # присвоить значение в 5-й колонке
} else {
df[i, 5] <- "lesser_than_4" # присвоить значение в 5-й колонке
}
}
})
Все последующие вычисления времени обработки были проведены на MAC OS X с процессором 2.6 ГГц и 8ГБ оперативной памяти.
Векторизируйте и выделяйте структуры данных заранее
Всегда инициализируйте ваши структуры данных и выходные переменные, задавая требуемые длину и тип данных до того, как запустить цикл вычислений. Постарайтесь не увеличивать объем ваших данных пошагово внутри цикла. Давайте сравним, как векторизация улучшает скорость на разных размерах данных от 1000 до 100 000 строк.
# после векторизации и предварительного выделения
output <- character (nrow(df)) # инициализируем выходной вектор
system.time({
for (i in 1:nrow(df)) {
if ((df[i, 'col1'] + df[i, 'col2'] + df[i, 'col3'] + df[i, 'col4']) > 4) {
output[i] <- "greater_than_4"
} else {
output[i] <- "lesser_than_4"
}
}
df$output})
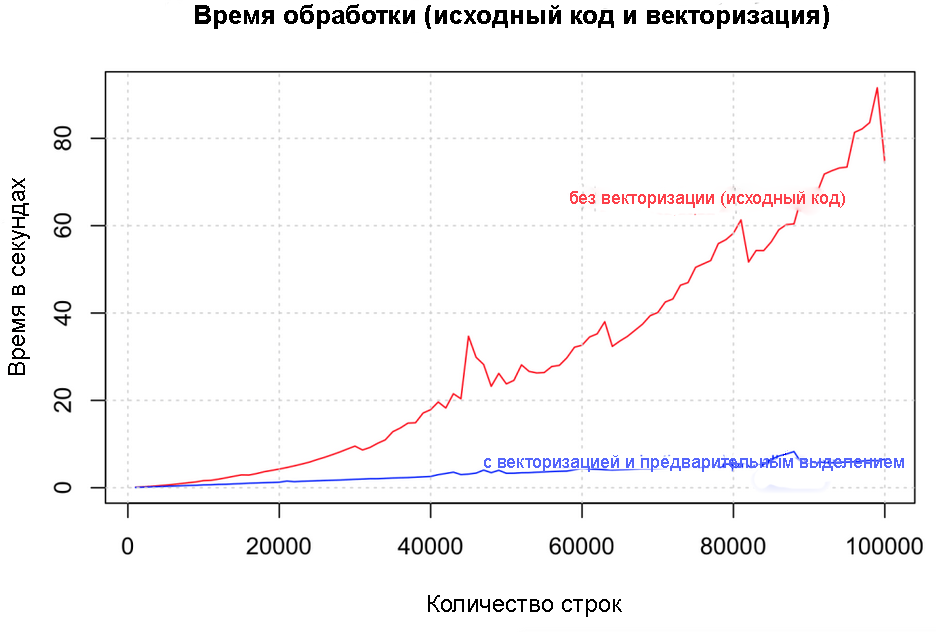
Исходный код и код с векторизацией
Уберите за границы цикла условные операторы
Вынесение за границы цикла условных проверок сравнимо по выигрышу с векторизацией самой по себе. Тесты проводились на диапазонах от 100 000 до 1 000 000 строк. Выигрыш в скорости снова колоссален.
# после векторизации и предварительного выделения, вынесения условного оператора за границы цикла
output <- character (nrow(df))
condition <- (df$col1 + df$col2 + df$col3 + df$col4) > 4 # проверка условия вне цикла
system.time({
for (i in 1:nrow(df)) {
if (condition[i]) {
output[i] <- "greater_than_4"
} else {
output[i] <- "lesser_than_4"
}
}
df$output <- output
})
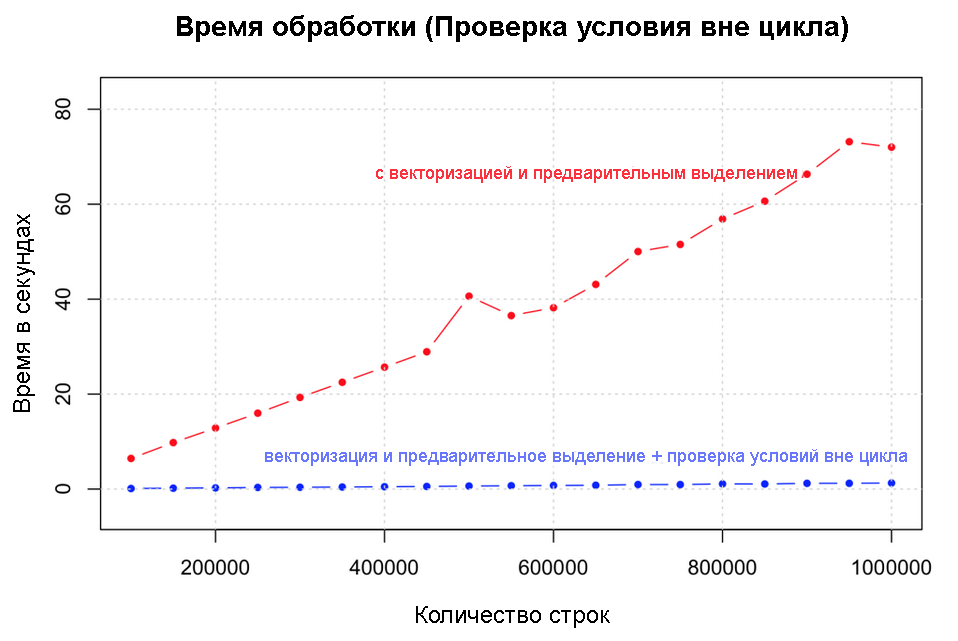
Проверка условия вне цикла
Выполнить цикл только для истинных условий
Еще одна оптимизация, которую тут можно использовать — запустить цикл только по истинным условиям, предварительно проинициализировав выходной вектор значениями False. Ускорение здесь сильно зависит от количества случаев с True в ваших данных.
В тестах сравнивается производительность этого и предыдущего улучшения на данных от 1 000 000 до 10 000 000 строк. Обратите внимание на увеличение количества нулей здесь. Как и ожидалось, есть вполне определенное заметное улучшение.
output <- character(nrow(df))
condition <- (df$col1 + df$col2 + df$col3 + df$col4) > 4
system.time({
for (i in (1:nrow(df))[condition]) { # запуск цикла только по истинным условиям
if (condition[i]) {
output[i] <- "greater_than_4"
} else {
output[i] <- "lesser_than_4"
}
}
df$output })
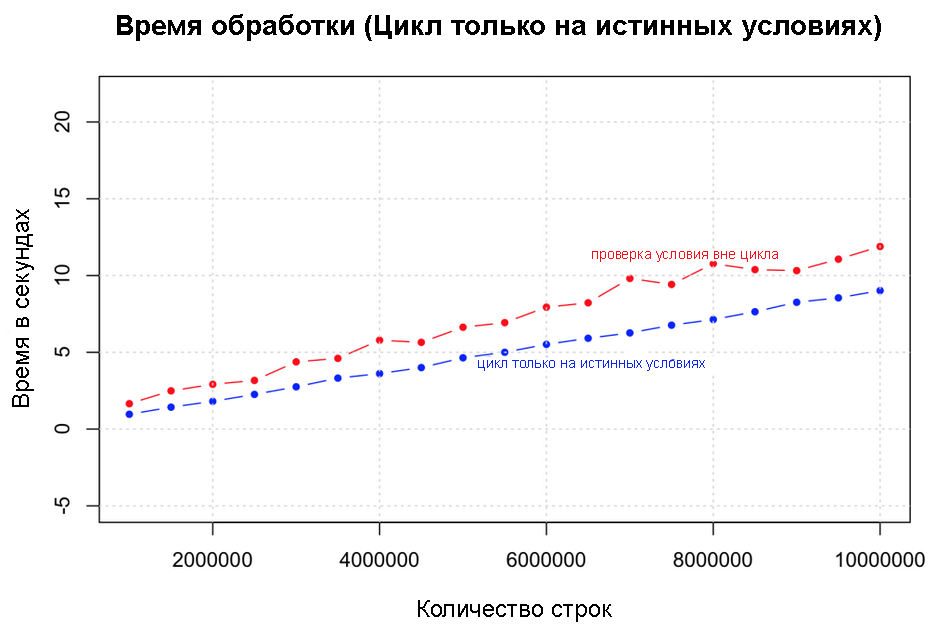
Запуск цикла только по истинным условиям
Используйте ifelse (), где это возможно
Эту логику можно сделать гораздо быстрее и проще с помощью ifelse(). Синтаксис аналогичен функции if в MS Excel, но ускорение феноменальное, особенно с учетом того, что здесь нет предварительного выделения, и условие проверяется каждый раз. Похоже, что это очень выгодный способ ускорить выполнение простых циклов.
system.time({
output <- ifelse ((df$col1 + df$col2 + df$col3 + df$col4) > 4, "greater_than_4", "lesser_than_4")
df$output <- output
})

Только истинные условия и ifelse
