[Перевод] Сложение векторов со скоростью 154 Гб/с на WebAssembly
Автор ускорил сложение векторов до ~12 000 000 сложений 1024-мерных векторов в секунду. Делимся подробностями и представляем генератор WASM из С++ от автора статьи к старту курса по Fullstack-разработке на Python.
Код запускался на M1 MacBook Air с node.js 17, весь код здесь.
Начинаем с чистого JavaScript
let a = new Array(N).fill(0);
let b = new Array(N).fill(0);
let c = new Array(N).fill(0);
function add() {
for (let i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
}Это медленно. Попробуем размеры 4, 64, 1024:
benchmarking vec add of size 4
pure javascript: 6.43 GB/s (133952036.48 iters/sec)
benchmarking vec add of size 64
pure javascript: 13.71 GB/s (17850781.69 iters/sec)
benchmarking vec add of size 1024
pure javascript: 14.96 GB/s (1217559.02 iters/sec)Это будет базовое значение (~15 Гб/с).
Типизированные массивы
Вместо скучного Array используем Float32Array. Типизированная версия покажет V8 в деле. Кроме того, Array использует double, float — в два раза меньше. Надо только поменять вызовы инициализации:
let a = new Float32Array(N);
let b = new Float32Array(N);
let c = new Float32Array(N);Получим:
benchmarking vec add of size 4
pure javascript: 6.54 GB/s (136224559.41 iters/sec)
typed arrays: 5.73 GB/s (119443844.4 iters/sec)
benchmarking vec add of size 64
pure javascript: 13.86 GB/s (18053198.87 iters/sec)
typed arrays: 10.81 GB/s (14080397.49 iters/sec)
benchmarking vec add of size 1024
pure javascript: 14.96 GB/s (1217559.02 iters/sec)
typed arrays: 10.88 GB/s (885410.91 iters/sec)Ух… Вызовы типизированных массивов быстрее, чем 11 Гб/с, даже на больших размерах:
benchmarking vec add of size 4096
pure javascript: 15.08 GB/s (306770.86 iters/sec)
typed arrays: 11.03 GB/s (224453.88 iters/sec)Похоже, JIT хорошо работает с массивами JavaScript. Это видно по отключению прогрева в тесте:
benchmarking vec add of size 4 [no warmup]
pure javascript: 0.04 GB/s (782572.09 iters/sec)
typed arrays: 0.13 GB/s (2701225.26 iters/sec)
benchmarking vec add of size 64 [no warmup]
pure javascript: 0.12 GB/s (154383.82 iters/sec)
typed arrays: 0.14 GB/s (180306.89 iters/sec)
benchmarking vec add of size 1024 [no warmup]
pure javascript: 9.15 GB/s (744839.13 iters/sec)
typed arrays: 6.66 GB/s (542320.53 iters/sec)Как это делается, написано в посте блога команды V8. Агрегированный тип Array отслеживается, т. е. подсказка типа от типизированных массивов не даёт большого преимущества, а float — меньше по размеру, так что причина происходящего непонятна.
Решение предложил Matheus28 на HackerNews: сложение выполняется с двойной точностью и с преобразованиями на каждом этапе. Float64Array даёт ускорение, позволяя догнать чистый JavaScript. В Firefox движок JavaScript не такой, как в node.js и Chromium, отсюда типизированные массивы быстрее. Это заметил viraptor на lobste.rs. Спасибо!
Emscripten
Emscripten — это фреймворк, который сразу компилирует C и C++ в WebAssembly и берёт на себя тяжёлую работу, для совместимости оборачивает системные вызовы и вызовы стандартной библиотеки C.
WebAssembly — это простой набор инструкций, производительность которых близка к нативной. Вот спецификация его ядра.
Передача памяти
WebAssembly не только прост, но и безопасен, что немного затрудняет работу с большими объёмами памяти: у каждого экземпляра WebAssembly своя линейная память. Единственная функция «из коробки» здесь (Memory.grow) похожа на mmap и, уже не настолько, на malloc:
const instance = new WebAssembly.Instance(...);
let mem = instance.exports.memory; // this needs to be manually exported
mem.grow(1); // grow by a single page (64KiB)На самом деле в Emscripten malloc реализован, но памятью владеет экземпляр WebAssembly, в котором нужно складывать вектора. Вот типичная функция Emscripten:
function emscripten_array(len) {
var ptr = Module._malloc(len * 4);
return [new Float32Array(Module.HEAPF32.buffer, ptr, len), ptr];
}Код выше использует malloc в Emscripten заставляет JavaScript интерпретировать этот указатель как смещение в кучу Emscripten. Это даёт две переменные, которые ссылаются на одну и ту же память: последнюю можно передать вызовам Emscripten, а первую — использовать как типизированный массив.
let [a, a_] = emscripten_array(N);
let [b, b_] = emscripten_array(N);
let [c, c_] = emscripten_array(N);
const add = Module._add;
// initialize a, b
for (let i = 0; i < N; ++i) {
a[i] = Math.random();
b[i] = Math.random();
}
add(a_, b_, c_);
// results are now in cЗапустим только что написанный модуль Emscripten с флагом оптимизации -O3:
// emcc add.cc -O3 -s EXPORTED_FUNCTIONS="['_add']"
extern "C" {
void add(const float* a, const float* b, float* c, int len) {
for (auto i = 0; i < len; ++i) {
c[i] = a[i] + b[i];
}
}
}На малых размерах скорость по-прежнему невысокая, но у размера 1024 заметно ускорение:
benchmarking vec add of size 4
pure javascript: 6.83 GB/s (142214376.78 iters/sec)
typed arrays: 5.71 GB/s (119016249.72 iters/sec)
emscripten: 1.33 GB/s (27608487.76 iters/sec)
benchmarking vec add of size 64
pure javascript: 13.46 GB/s (17524173.64 iters/sec)
typed arrays: 10.64 GB/s (13853318.79 iters/sec)
emscripten: 11.91 GB/s (15505845.36 iters/sec)
benchmarking vec add of size 1024
pure javascript: 15.06 GB/s (1225731.4 iters/sec)
typed arrays: 10.92 GB/s (888576.43 iters/sec)
emscripten: 22.81 GB/s (1856272.37 iters/sec)SIMD
Одна инструкция одновременного процессора обрабатывает несколько элементов. WebAssembly отчасти поддерживает такие инструкции — SIMD. Чтобы воспользоваться SIMD, скомпилируем код с флагом -msimd128; хорошее ускорение:
benchmarking vec add of size 4
pure javascript: 6.62 GB/s (137877529.08 iters/sec)
typed arrays: 5.76 GB/s (120071457.96 iters/sec)
emscripten (simd): 1.33 GB/s (27729893.7 iters/sec)
benchmarking vec add of size 64
pure javascript: 13.3 GB/s (17319586.98 iters/sec)
typed arrays: 10.59 GB/s (13795225.43 iters/sec)
emscripten (simd): 18.31 GB/s (23845788.63 iters/sec)
benchmarking vec add of size 1024
pure javascript: 15.07 GB/s (1226252.88 iters/sec)
typed arrays: 10.96 GB/s (892301.4 iters/sec)
emscripten (simd): 75.14 GB/s (6114821.99 iters/sec)75 Гб/с! Но ещё есть где прибавить. Например, при запуске функции, работающей с вектором любого размера. Можно ли оптимизировать что-то ещё, если при тестировании ограничить функцию размером вектора?
wasmblr
Работать на C++ с Emscripten — это круто, и в 99% случаев этот рабочий процесс незаменим, но именно здесь пойдём дальше: генерируем код динамически. К сожалению, на компиляцию в Emscripten часто уходят секунды, а в крупных проектах — минуты, поэтому я написал заголовочный файл, генерирующий чистый WebAssembly прямо из C++ — это wasmblr.
Большинство вызовов занимает 1,5 микросекунды, потому что представлена спецификация с семантикой C++. Чтобы инстанцировать модуль WebAssembly, нужно 125 микросекунд, поэтому у нас около 8000 перекомпиляций в секунду, что намного быстрее Emscripten.
Развёртка цикла
Зная размер цикла, можно развернуть его. Развёртывание часто используется, чтобы убрать инструкции для циклов и арифметику указателей. В wasmblr все вызовы cg.* создают сборку, а значит, для загрузки, добавления и хранения каждого элемента в векторах можно использовать циклы C++, это нечто вроде метапрограммирования.
std::vector gen_add_unroll(int len) {
assert(len % 4 == 0);
wasmblr::CodeGenerator cg;
auto pages = (len * 3 * 4) / (1 << 16) + 1;
cg.memory(pages).export_("mem");
auto add_func = cg.function({cg.i32, cg.i32, cg.i32}, {}, [&]() {
// no loop emitted at all,
// C++ is generating len / 4 groups of instructions
for (auto i = 0; i < len / 4; ++i) {
cg.local.get(2);
cg.local.get(0);
cg.v128.load(0, i * 16);
cg.local.get(1);
cg.v128.load(0, i * 16);
cg.v128.f32x4_add();
cg.v128.store(0, i * 16);
}
});
cg.export_(add_func, "add");
return cg.emit();
} Поясню кое-что в коде.
1. Переменная pages. В wasmblr нет вызываемой из JavaScript реализации malloc. Поэтому пришлось поработать с предварительным распределением полного размера ввода и вывода (2 ввода, 1 вывод, 4 байта с плавающей точкой, все длины len, размер страницы 1<<16).
2. Что делает cg.local.get (2) наверху? cg.local.get (X) ссылается на аргументы, это — ссылка на третий аргумент, то есть наш вывод. Вызываем его наверху, потому что он нужен для пути cg.v128.store внизу как аргумент в стеке. WebAssembly — это скорее набор инструкций стека, чем регистра, поэтому читать его странно.
3. load и store принимают непосредственные аргументы. Это часть спецификации WebAssembly. В load/store можно жёстко задать смещение, и оно будет добавлено к указателю в стеке. Вместо того чтобы жёстко задать 0 и добавлять указатели на память, можно просто оставить указатели и поместить смещения в сам код. В Emscripten это было бы невозможно, ведь сгенерированный код должен обрабатывать все типы длин.
Для выбранных размеров результаты хорошие: в 2 раза больше, чем в Emscripten. В последнем тесте скорость уже 154 Гб/с!
benchmarking vec add of size 4
pure javascript: 6.47 GB/s (134745835.5 iters/sec)
typed arrays: 5.94 GB/s (123764397.54 iters/sec)
emscripten (simd): 1.34 GB/s (27821574.95 iters/sec)
wasmblr: 2.73 GB/s (56838383.47 iters/sec)
benchmarking vec add of size 64
pure javascript: 13.82 GB/s (17996280.78 iters/sec)
typed arrays: 10.79 GB/s (14052220.48 iters/sec)
emscripten (simd): 18.26 GB/s (23773963.85 iters/sec)
wasmblr: 37.41 GB/s (48715916.95 iters/sec)
benchmarking vec add of size 1024
pure javascript: 15.04 GB/s (1223936.07 iters/sec)
typed arrays: 10.91 GB/s (887874.77 iters/sec)
emscripten (simd): 75.07 GB/s (6109401.71 iters/sec)
wasmblr: 154.89 GB/s (12605111.46 iters/sec)А как насчёт размеров больше?
benchmarking vec add of size 16384
pure javascript: 15.02 GB/s (76393.04 iters/sec)
typed arrays: 10.89 GB/s (55389.2 iters/sec)
emscripten (simd): 90.96 GB/s (462658.42 iters/sec)
wasmblr: 88.09 GB/s (448069.81 iters/sec)Должно быть, мы выпали из кеша инструкций. У развёртки есть пределы, и мы зашли слишком далеко, выпустив для простого цикла for программу размером ~100 Кб. Придётся идти непростым путём и следить за указателями:
std::vector gen_add_mix(int len, int unroll) {
assert(len % (unroll * 4) == 0);
wasmblr::CodeGenerator cg;
auto pages = (len * 3 * 4) / (1 << 16) + 1;
cg.memory(pages).export_("mem");
auto add_func = cg.function({cg.i32, cg.i32, cg.i32}, {}, [&]() {
// keep track of the iteration with this variable
auto iter = cg.local(cg.i32);
cg.i32.const_(0);
cg.local.set(iter);
cg.loop(cg.void_);
// same as above, but now locals are mutated
for (auto i = 0; i < unroll; ++i) {
cg.local.get(2);
cg.local.get(0);
cg.v128.load(0, i * 16);
cg.local.get(1);
cg.v128.load(0, i * 16);
cg.v128.f32x4_add();
cg.v128.store(0, i * 16);
}
// pointer/iterator math below
cg.local.get(0);
cg.i32.const_(unroll * 16);
cg.i32.add();
cg.local.set(0);
cg.local.get(1);
cg.i32.const_(unroll * 16);
cg.i32.add();
cg.local.set(1);
cg.local.get(2);
cg.i32.const_(unroll * 16);
cg.i32.add();
cg.local.set(2);
cg.local.get(iter);
cg.i32.const_(unroll * 16);
cg.i32.add();
cg.local.set(iter);
// condition to exit the loop
cg.i32.const_(len * 4); // bytes
cg.local.get(iter);
cg.i32.ge_s();
cg.br_if(0);
cg.end(); // need to end the loop! this is important to remember
});
cg.export_(add_func, "add");
return cg.emit();
} Теперь выполним развёртку с коэффициентом разумнее — 16:
benchmarking vec add of size 4
pure javascript: 6.32 GB/s (131599401.31 iters/sec)
typed arrays: 5.88 GB/s (122460888.5 iters/sec)
emscripten (simd): 1.33 GB/s (27803398.21 iters/sec)
wasmblr: 2.73 GB/s (56812962.22 iters/sec)
benchmarking vec add of size 64
pure javascript: 13.82 GB/s (18000013.97 iters/sec)
typed arrays: 10.8 GB/s (14057150.76 iters/sec)
emscripten (simd): 18.24 GB/s (23755889.12 iters/sec)
wasmblr: 36.98 GB/s (48154136.31 iters/sec)
benchmarking vec add of size 1024
pure javascript: 15.04 GB/s (1224069.46 iters/sec)
typed arrays: 10.85 GB/s (882788.85 iters/sec)
emscripten (simd): 73.71 GB/s (5998175.91 iters/sec)
wasmblr: 138.9 GB/s (11303927.39 iters/sec)
benchmarking vec add of size 16384
pure javascript: 15.27 GB/s (77662.85 iters/sec)
typed arrays: 11.09 GB/s (56398.08 iters/sec)
emscripten (simd): 90.31 GB/s (459346.92 iters/sec)
wasmblr: 86.71 GB/s (441049.92 iters/sec)Похоже, работа бесполезная: производительность для размера 1024 упала! Мы наверняка увеличим её, подобрав коэффициент развёртки.
Настройка коэффициента
Но зачем делать это вручную, когда на перекомпиляцию и перезагрузку кода wasmblr нужно 1/8000 секунды? Лучше просто сравнить коэффициенты и сохранить лучший:
let best = 0;
let best_time = 1e9;
for (let i = 0; Math.pow(2, i) < Math.min(1024, N / 4 + 2); ++i) {
let [fn, w_a, w_b, w_c] = gen_wasmblr(N, Math.pow(2, i));
for (let _ = 0; _ < 100; ++_) {
fn();
}
const t = performance.now();
for (let _ = 0; _ < 1000; ++_) {
fn();
}
const diff = performance.now() - t;
if (diff < best_time) {
best = i;
best_time = diff;
}
}Добавим ещё один тест. Чем больше размерность векторов, тем меньше оперативной памяти и больше возможностей у инструкций, поэтому стоит ожидать выравнивания:
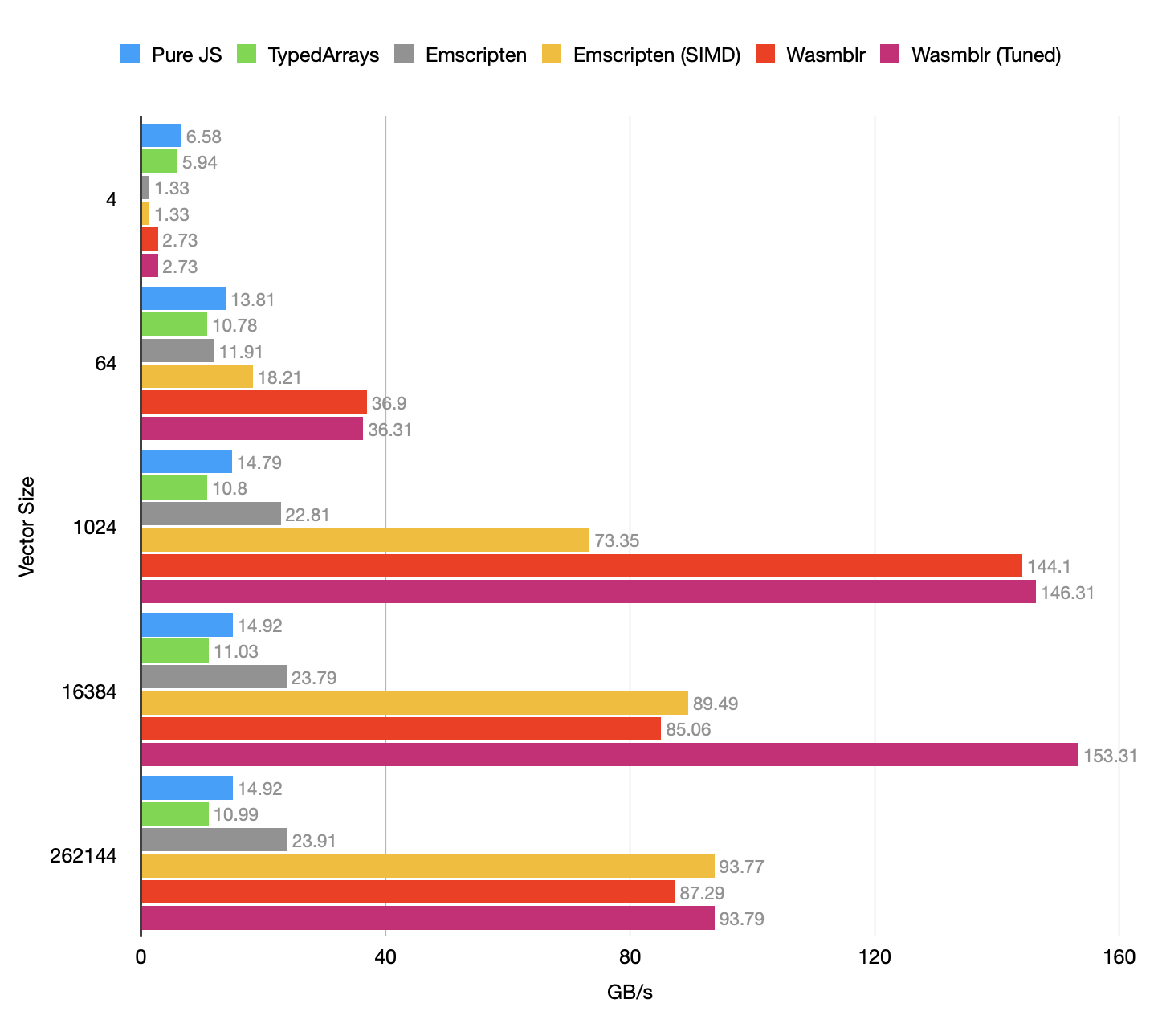
benchmarking vec add of size 4
pure javascript: 6.58 GB/s (137027121.14 iters/sec)
typed arrays: 5.94 GB/s (123815568.64 iters/sec)
emscripten (simd): 1.33 GB/s (27750315.65 iters/sec)
wasmblr: 2.73 GB/s (56932301.96 iters/sec)
wasmblr (tuned 2): 2.73 GB/s (56956492.7 iters/sec)
benchmarking vec add of size 64
pure javascript: 13.81 GB/s (17975517.63 iters/sec)
typed arrays: 10.78 GB/s (14037142.11 iters/sec)
emscripten (simd): 18.21 GB/s (23713778.4 iters/sec)
wasmblr: 36.9 GB/s (48052212.55 iters/sec)
wasmblr (tuned 4): 36.31 GB/s (47284842.5 iters/sec)
benchmarking vec add of size 1024
pure javascript: 14.79 GB/s (1203713.72 iters/sec)
typed arrays: 10.8 GB/s (878615.27 iters/sec)
emscripten (simd): 73.35 GB/s (5969393.52 iters/sec)
wasmblr: 144.1 GB/s (11727035.06 iters/sec)
wasmblr (tuned 16): 144.05 GB/s (11722845.16 iters/sec)
benchmarking vec add of size 16384
pure javascript: 14.92 GB/s (75866.72 iters/sec)
typed arrays: 11.03 GB/s (56121.47 iters/sec)
emscripten (simd): 89.49 GB/s (455146.48 iters/sec)
wasmblr: 85.06 GB/s (432642.22 iters/sec)
wasmblr (tuned 4): 153.31 GB/s (779787.52 iters/sec)
benchmarking vec add of size 262144
pure javascript: 14.92 GB/s (4744.22 iters/sec)
typed arrays: 10.99 GB/s (3493.11 iters/sec)
emscripten (simd): 93.77 GB/s (29809.79 iters/sec)
wasmblr: 87.29 GB/s (27748.19 iters/sec)
wasmblr (tuned 2): 93.79 GB/s (29814.89 iters/sec)Благодаря настройке удалось восстановить идеальные показатели для размера 16 384, а на определённых размерах даже улучшить их и не выпасть из кеша. На размере 262 144 действия уже не слишком важны: векторы так велики, что мы просто ждём в памяти почти всё время.
Заключение
Для небольших векторов подойдёт чистый JavaScript. Если же векторы больше кеша, отлично справится Emscripten. А когда размер очень специфический и у вас много времени, воспользуйтесь wasmblr. Спасибо за внимание!
А мы поможем вам прокачать навыки или освоить профессию, востребованную в любое время:
Выбрать другую востребованную профессию.
 Краткий каталог курсов и профессий
Краткий каталог курсов и профессий
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также
