[Перевод] «Сладкое» программирование, или Как выделить этикетку с банки варенья в Mathematica?

Перевод дискуссии «How to peel the labels from marmalade jars using Mathematica?» с сайта Mathematica at StackExchange.
Код, приведенный в статье, можно скачать здесь (~31 МБ).
Выражаю огромную благодарность Кириллу Гузенко KirillGuzenko за помощь в переводе и подготовке публикации
Как можно выделить содержимое этикетки с указанной ниже банки (точка съёмки кадра, геометрия банки, её содержимое — всё это нам неизвестно),

чтобы получить нечто подобное — ту же самую этикетку в том виде, в каком она была до того, как оказалась на банке?

Основная идея заключается в следующем:
- Находим этикетку.
- Находим границы этикетки.
- Находим отображение координат пикселей изображения на цилиндрические координаты.
- Трансформируем изображение с использованием найденного отображения.
Предлагаемый нами алгоритм работает только для изображений, в которых:
- Этикетка ярче фона (это нужно для обнаружения этикетки).
- Этикетка прямоугольная (это нужно для того, чтобы оценить качество отображения).
- Банка должна занимать вертикальное положение (это нужно для того, чтобы сохранить простую форму функции отображения).
- Банка должна быть цилиндрической (это нужно для того, чтобы сохранить простую форму функции отображения).
Следует заметить, что алгоритм модульный. То есть вы можете дописать свой алгоритм обнаружения этикетки, который не будет требовать тёмного фона, или можете написать свою функцию оценки качества отображения, которая позволит работать с овальными или многоугольными этикетками.
Получившийся в конечном итоге алгоритм работает полностью автоматически (однако есть опция ручного задания границ банки), то есть берёт исходное изображение, после чего выдаёт изображение с сеткой и этикетку.
Вот моё «быстрое» решение. Оно немного похоже на решение пользователя azdahak, однако вместо цилиндрических координат оно использует приближенное отображение. С другой стороны, параметры управления нельзя задать вручную — все коэффициенты отображения определяется автоматически:
Этикетка ярко выделяется на тёмном фоне, так что я могу легко найти ее с помощью бинаризации:



Я просто выбираю самый большой элемент и считаю, что это и есть этикетка:


В следующем шаге необходимо выделить все границы этой области с помощью свёртки (ImageConvolve) полученной маски этикетки:


Небольшая вспомогательная функция, показанная ниже, позволяет найти все белые пиксели в одном из этих четырех изображений и преобразовать их индексы в координаты (Position возвращает индексы, а индексы есть пары чисел вида {у, х}, которые при у=1 задают полосу изображения толщиной в 1 пиксель сверху изображения. Но все функции обработки изображений принимают координаты в виде пар {х, у}, которые при у=0 задают полосу изображения толщиной в 1 пиксель снизу изображения. Это приводит к необходимости конвертации индексов, выдаваемых Position, в, по сути, обычные декартовы координаты для дальнейшего использования):
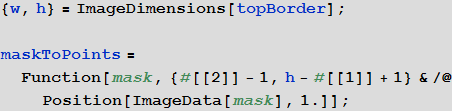
Теперь у меня есть четыре отдельных списка координат для верхней, нижней, левой и правой границ этикетки. Определим теперь отображение координат изображения в цилиндрические координаты:
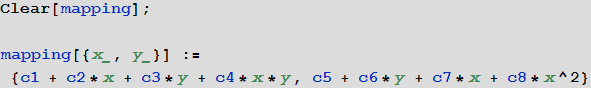
Это отображение, очевидно, является грубым приближением к цилиндрическим координатам. Однако, найти оптимальные значения коэффициентов c1, с2, …, c8 оказывается очень просто с помощью функции NMinimize:


Таким образом мы находим функцию, которая производит оптимальное отображение нашей этикетки на прямоугольник — точки на левой границе отображаются в {0, [что-то]}, а точки на верхней границе отображаются в {[что-то], 1} и так далее.
Отображение будет выглядеть следующим образом:


Теперь можно передать это отображение непосредственно функции ImageForwardTransformation:


Артефакты на изображении достались нам от исходного изображения. Версия изображения в более высоком разрешении дала бы лучший результат. Искажения в левой части возникли из-за недостаточно качественной функции отображения. Это можно исправить ее улучшением, о чем будет рассказано ниже.
Работа алгоритма с изображениями большего размера
Я попытался применить тот же алгоритм к изображению с более высоким разрешением и результат выглядит так:


Полученный результат говорит о том, что стоит немного подправить часть, отвечающую за обнаружение этикетки (сперва DeleteBorderComponents, а затем и FillingTransform), и ещё добавить дополнительные условия в формуле отображения с учётом перспективы (для изображений низкого разрешения изменения будут практически незаметны). Вы можете заметить, что ближе к границам изображения построенная функция отображения второго порядка работает с некоторыми незначительными искажениями.
Улучшение функции отображения
Проведя ряд исследований и экспериментов, удалось найти отображение, которое устраняет цилиндрические искажения (большую их часть, по крайней мере):

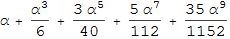
Это цилиндрическое отображение, которое использует ряд Тейлора для аппроксимации арксинуса, так как прямое использование функции арксинус делает символьную и численную оптимизацию довольно затруднительной. Функция Clip служит для предотвращения появление комплексных чисел в процессе оптимизации. Использование функции NMinimize для решения этой нелинейной задачи оптимизации не даст быстрых по скорости работы результатов, так как эта функция ищет глобальный минимум функционала с помощью гибридных символьно-численных методов, поэтому было решено вместо неё использовать функцию FindMinimium, которая прекрасно ищет с помощью сугубо численных методов минимум.


Вот что получаем в результате отображения:

Полученное изображение этикетки:

Полученные границы достаточно хорошо описывают контур этикетки. Символы по размеру выглядят одинаковыми, а значит искажения оказывают небольшое влияние. Решение для оптимизации так же можно проверить напрямую: посредством оптимизации попытаемся оценить радиус цилиндра R и координату X центра цилиндра, и полученные значения лишь на несколько пикселей будут отстоять от их реальных положений на изображении.
Проверка работы алгоритма на реальных данных
В Google были найдены похожие картинки, на которых был апробирован разработанный алгоритм. Ниже показаны результаты работы алгоритма в полностью автоматическом режиме, но некоторые изображение предварительно немного обрезались. Результаты выглядят весьма многообещающе:








Как и ожидалось, обнаружение этикетки — наименее устойчивый шаг алгоритма, потому и требовалась обрезка изображений в некоторых случаях. Если отметить точки на этикетке и вне её, то сегментация, основанная на границах, должна будет дать лучший результат.
Дополнительные улучшения алгоритма
Пользователь Szabolcs предложил интерактивный вариант кода, который позволяет улучшить результат.
Со своей стороны я предлагаю улучшить предложенный интерактивный интерфейс функцией ручного выбора левой и правой границ изображения, к примеру, с помощью локаторов:


Тогда будет возможность получить параметры r и cx в явном виде, а не через оптимизацию:
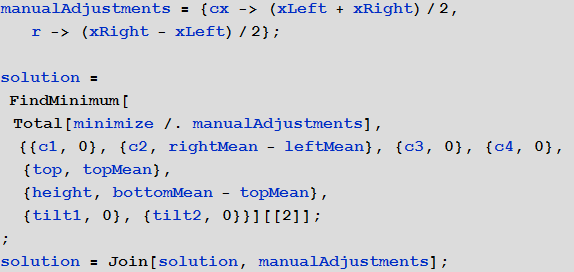
С использованием этого решения результат получается практически без искажений:


