[Перевод] Система автоматической оценки возраста по изображениям лиц
АннотацияЛюди — это самые важные объекты слежения в системах видеонаблюдения. Тем не менее, слежение за человеком само по себе не дает достаточной информации об его мотивах, намерениях, желаниях и т.п. В этой работе мы представляем новую и надежную систему для автоматической оценки возраста с помощью технологий компьютерного зрения. Она использует глобальные особенности лица, полученные на основе комбинирования вейвлетов Габора и сохранение ортогональности локальных проекций Orthogonal Locality Preserving Projections, OLPP). Кроме того, система способна оценивать возраст по изображениям в реальном времени. Это означает, что предлагаемая система имеет больший потенциал по сравнению с другими полуавтоматическими системами. Результаты, полученные в процессе применения предлагаемого подхода, могут позволить получить более ясное понимание алгоритмов в области оценки возраста, необходимых для разработки приложений, актуальных для реального применения.Ключевые слова: вейвлеты Габора, изображение лица, оценка возраста, метод опорных векторов (Support Vector Machine, SVM).1. ВведениеИзображение человеческого лица содержит обильную информацию о персоне, включающую черты лица, эмоции, пол, возраст и др. В общем, изображение лица человека может быть рассмотрено как сложный сигнал, состоящий из множества свойств лица, таких как: цвет кожи, геометрические особенности черт лица. Эти атрибуты играют важную роль в реальных приложениях по анализу изображений лиц. В таких приложениях различные свойства (атрибуты) оцененные из захваченного изображения лица могут использоваться для дальнейшей реакции (действий) системы. Возраст, в особенности, является одним из наиболее важных атрибутов. Например, пользователям может требоваться зависимая от возраста интерактивная компьютерная система, или система, которая может оценивать возраст для обеспечения контроля доступа или система для сбора разведывательных данных. Автоматическая оценка возраста с использованием анализа изображений лиц подразумевает огромное число реальных приложений.Система автоматической оценки возраста состоит из двух частей: обнаружения лица на изображении и собственно оценка возраста. Довольно сложно обнаруживать лица на изображении, потому что результаты обнаружения сильно зависят от многих условий: окружающая среда, движение, освещение, ориентация лиц в пространстве, выражение эмоций. Эти факторы могут вести к искажениям в цвете, яркости, тенях и контурах изображений. По этой причине, Виола и Джонс предложили свою знаменитую систему для обнаружения лиц в 2004. Классификатор Виолы-Джонса использует алгоритм AdaBoost в каждом узле каскада классификатора для обучения высокой степени обнаружения лиц за счет понижения числа игнорируемых лиц всего каскада. Этот алгоритм имеет следующие особенности: 1) использует признаки Хаара — сравнение разностей сумм интенсивностей пикселей в двух прямоугольных областях с пороговыми значениями; 2) использование интегрального изображения для ускорения вычислений сумм пикселей в прямоугольной области или прямоугольной области повернутой на угол 45 градусов; 3) алгоритм AdaBoost использует статистический бустинг, чтобы создать двоичные (лицо — не лицо) узлы классификации, характеризуемые хорошей вероятностью обнаружения лиц и маленькой вероятностью пропуска лица; 4) узлы слабых классификаторов организуется в каскад с целью отсеивания изображений-не-лиц на начальной стадии работы алгоритма (т.е. первые уровни каскада допускают большее число ошибок неправильной классификации, но при этом работают быстрее, чем последующие уровни каскадного классификатора). Лицо классифицируется как лицо, только если оно проходит через все уровни каскадного классификатора.Хотя автоматическое обнаружение лиц на изображении является зрелой техникой включающей множество приложений, оценка возраста по изображению лица — по-прежнему сложная задача. Это потому, что процесс старения выражен по-разному не только среди разных рас, но так же и внутри расы. Этот процесс по большей части персональный. Кроме того, он также определяется воздействием внешних факторов: стилем жизни (правильное питание, спорт), местностью проживания, погодными условиями. Поэтому проблема устойчивой оценки возраста является открытой проблемой.В целом, имеется три категории методов извлечения особенностей для оценки возраста человека в литературе. Первая категория — это статистические подходы. Xin Geng и др. [2, 3] предложили AGing pattErn Subspace (AGES) — метод для автоматической оценки возраста. Идея этого подхода заключается в моделировании паттерна (шаблона) старения, который определяется последовательностью персональных изображений старения лица. Эта модель строится изучением подпространства подобному EM-алгоритму итеративного обучения метода главных компонент Principal Component Analysis, PCA). В других работах [4, 5], Guodong Guo и др. сравнивают три типичных метода уменьшения размерностей пространства признаков и разнообразные методы вложения такие как: PCA, локально линейное вложение (Locally Linear Embedding, LLE), сохранение ортогональности локальных проекций (Orthogonal Locality Preserving Projections, OLPP). Согласно распределению данных в OLPP-подпространстве, они предлагают метод локально настроенной устойчивой регрессии (Locally Adjusted Robust Regression, LARR) для обучения и предсказания возраста человека. LARR использует регрессию опорных векторов (Support Vector Regression, SVR) для грубого предсказания и определяют локальные настройки в пределах небольшого ограниченного диапазона возрастов, центрированного относительно полученного результата, с помощью метода опорных векторов (Support Vector Machine, SVM).Вторая категория методов включает в себя подход на основе модели активного внешнего вида (Active Appearance Model, AAM). Использование модели внешнего вида — это самый интуитивный метод среди всех методов анализа изображений лиц.Young H. Kwon и др. [6] использовали визуальные возрастные особенности для конструирования антропометрической модели. Первичные особенности — это глаза, нос, рот и подбородок. Отношения этих особенностей вычислялись для различения разных возрастных категорий. При анализе вторичных особенностей, использовалась карта морщин для управления детекцией и измерением морщин. Jun‐Da Txia и др. [7] предложили метод оценки возраста на основе active appearance model (AAM) для извлечения регионов возрастных особенностей. Каждое лицо требует вычисления 28 особых точек и разделяется на 10 регионов морщин. Shuicheng Yan и др. [8] использовали модель внешнего вида на основе пути, именуемую Patch-Kernel. Этот метод спроектирован для определения расстояния Кульбак-Лейблера между моделями, которые выведены из глобальной модели гауссовых смесей (GMM) с использованием максимальной апостериорной вероятности (Maximum a Posteriori, MAP) любых двух изображений. Способность классифицировать усиливалась затем использованием процесса слабого обучения, называемого синхронизацией интермодального сходства. Ядерная регрессия используется в конце для оценки возраста.Третья категория методов использует подход, основанный на частоте. В обработке изображений и распознавании образов, анализ частотной области является одним из самых популярных методов извлечения особенностей изображения. Guodong Guo и др. [9] исследовали «биологические» особенности изображения (biologically inspired features, BIF) для оценки возраста людей по изображению. В отличие от предыдущих работ [4, 5], Guo моделировал лицо человека с помощью фильтров Габора [10]. Фильтры Габора — это линейные фильтры, используемые в обработке изображений для выделения границ объектов внутри изображения. Частота и ориентация представлений фильтров Габора схожа с человеческим зрением и хорошо подходит для текстурного представления и решения задачи дискриминации.Предлагаемая нами система использует каскадный AdaBoost для обучения для обнаружения лиц, а оценку возраста получает путем применения вейвлетов Габора и OLPP. Эта статься состоит из следующих разделов. Первый включает описание системы обнаружения лиц: выравнивание гистограмм, выбор особенностей, каскадный классификатор, обученный AdaBoost и алгоритм кластеризации регионов изображения лица. Второй раздел: процесс оценки возраста включает извлечение особенностей с помощью вейвлетов Габора, отсеивание особенностей и выбор лучших, классификация возраста. В конце статьи приводятся результаты моделирования и делаются выводы.В этой статье предлагается полностью автоматическая система оценки возраста, использующая вейвлеты Габора для представления процесса старения. Система, которую мы предлагаем, имеет 4 главных модуля: 1) обнаружение лиц; 2) анализ на основе вейвлетов Габора; 3) OLPP редукция; 4) классификация методом опорных векторов. Входное изображение может приходить с камеры или считываться из файла. Изображение лица выбирается из исходного изображения с помощью детектора лиц, используя подход, обозначенный в [12]. Затем изображение масштабируется, чтобы иметь размер 64×64 пикселей. Далее, используя 40 ядер вейвлетов Габора, извлекаются особенности, и к ним применяется редукция OLPP. В конце, запускается оценка возраста с помощью обученного классификатора SVM.Оставшаяся часть статьи организована следующим образом: раздел 2 описывает подсистему обнаружения лиц с помощью AdaBoost. Раздел 3 описывает алгоритм оценки возраста и включает: текстурный анализ вейвлетами Габора, OLPP редукцию и SVM классификацию. В разделе 4 представлены экспериментальные результаты. В разделе 5 делаются выводы по предлагаемой системе. Рисунок 1. Обзор системы2. Обнаружение лицРисунок 1 показывает архитектуру системы автоматической оценки возраста, предлагаемой в нашей работе. Вся система состоит из подсистемы обнаружения лица, задача которой обнаружение областей лиц на изображении и подсистемы оценки возраста. Для поиска лиц на изображении применяются окна сканирования различного размера, т.к. объект при захвате изображения может находиться на разных расстояниях от камеры. Имеется в общей сложности 12 масштабных уровней сканирования, а размер изображения изменяется, начиная с 24×24 с масштабным множителем 1,25. В зависимости от условий освещенности, в которых происходит захват изображений, могут быть различные вариации в яркости изображений. Изображение может быть более точно распознано (точнее, лицо на изображении) после нормализации его яркости.
Рисунок 1. Обзор системы2. Обнаружение лицРисунок 1 показывает архитектуру системы автоматической оценки возраста, предлагаемой в нашей работе. Вся система состоит из подсистемы обнаружения лица, задача которой обнаружение областей лиц на изображении и подсистемы оценки возраста. Для поиска лиц на изображении применяются окна сканирования различного размера, т.к. объект при захвате изображения может находиться на разных расстояниях от камеры. Имеется в общей сложности 12 масштабных уровней сканирования, а размер изображения изменяется, начиная с 24×24 с масштабным множителем 1,25. В зависимости от условий освещенности, в которых происходит захват изображений, могут быть различные вариации в яркости изображений. Изображение может быть более точно распознано (точнее, лицо на изображении) после нормализации его яркости.
2.1. Нормализация освещенностиНормализация освещенности основана на методе выравнивания (подгонки) гистограмм. Первоочередная задача подгонки гистограмм — это преобразовать исходную гистограмму H (l) в целевую гистограмму G (l). Целевая гистограмма G (l) выбрана как гистограмма изображения, близкая к средней гистограмме для базы данных лиц. Выберем целевое изображение и гистограмму G (l) как это показано на Рисунке 2(а). Изображения до и после нормализации показаны на рисунках 2(b)-©. Рисунок 2. Нормализация освещенности. (а) Целевое изображение. (b) Входные изображения. © Нормализованные изображения
Рисунок 2. Нормализация освещенности. (а) Целевое изображение. (b) Входные изображения. © Нормализованные изображения
Входные изображения, которые слишком темные или слишком светлые нормализуются в соответствии с гистограммой целевого изображения. Гистограммы H (l) преобразуются в гистограммы G (l) следующим образом:  где
где и
и  — прямое и обратное отображения гистограмм H (l) и G (l) в гистограммы однородных (равномерных) распределений.
— прямое и обратное отображения гистограмм H (l) и G (l) в гистограммы однородных (равномерных) распределений.
2.2 Отбор особенностейМы выбрали четыре прямоугольных признака Хаара так, как это показано на рисунке 3 [13]. Рисунок 3. Четыре типа прямоугольных особенностей
Рисунок 3. Четыре типа прямоугольных особенностей
Допустимо использовать композицию прямоугольников разной яркости для представления светлых и темных регионов изображения. Особенности определяются следующим образом:  где (х, y) обозначает центр относительной системы координат прямоугольной особенности в сканирующем окне. Важность w и h обозначает относительную ширину и высоту прямоугольной особенности соответственно. Type — тип прямоугольной особенности,
где (х, y) обозначает центр относительной системы координат прямоугольной особенности в сканирующем окне. Важность w и h обозначает относительную ширину и высоту прямоугольной особенности соответственно. Type — тип прямоугольной особенности,  — разность сумм пикселей в светлой и темной областях.Прямоугольная особенность, которая может эффективно разделять лица и не лица, рассматривается как слабый классификатор:
— разность сумм пикселей в светлой и темной областях.Прямоугольная особенность, которая может эффективно разделять лица и не лица, рассматривается как слабый классификатор: 
 Слабый классификатор используется для определения, является ли текущая часть изображения лицом или не лицом на основе подсчета прямоугольной особенности, порога q и полярности (направления неравенства) p. Для каждого слабого классификатора оптимальный порог выбирается так, чтобы минимизировать ошибку неправильной классификации. Выбор порога осуществляется посредством обучения на выборке из 4000 изображений лиц и 59000 изображений не лиц. Рисунки 4(a)-(b) представляют собой примеры из баз лиц и не лиц. В этой процедуре, мы подсчитываем распределение каждой особенности
Слабый классификатор используется для определения, является ли текущая часть изображения лицом или не лицом на основе подсчета прямоугольной особенности, порога q и полярности (направления неравенства) p. Для каждого слабого классификатора оптимальный порог выбирается так, чтобы минимизировать ошибку неправильной классификации. Выбор порога осуществляется посредством обучения на выборке из 4000 изображений лиц и 59000 изображений не лиц. Рисунки 4(a)-(b) представляют собой примеры из баз лиц и не лиц. В этой процедуре, мы подсчитываем распределение каждой особенности  для каждого изображения в базе и выбираем порог, который обладает максимальной дискриминативной способностью (т.е. разбивает изображения на два класса лучше остальных).
для каждого изображения в базе и выбираем порог, который обладает максимальной дискриминативной способностью (т.е. разбивает изображения на два класса лучше остальных). Рисунок 4. База данных лиц (а) и не лиц (b)
Рисунок 4. База данных лиц (а) и не лиц (b)
Хотя каждая прямоугольная особенность вычисляется очень эффективно, вычисление всех комбинаций очень вычислительно дорого. Для примера, для самого маленького скользящего окна (24×24) полный набор особенностей составляет 160000.Алгоритм AdaBoost комбинирует набор слабых классификаторов, чтобы сформировать сильный классификатор. Хотя сильный классификатор эффективен для приложений обнаружения лиц, он достаточно долго работает по времени. Структура каскадных классификаторов, которая улучшает способность обнаружения и уменьшает время вычислений, была предложена Виолой и Джонсом [14]. Основываясь на этой идее, наш каскадный AdaBoost формирует сильный классификатор. В первом шаге, если изображение из скользящего окна классифицируется как лицо, тогда мы переходим к шагу 2, в другом случае — изображение отбрасывается. Аналогичный процесс выполняется для всех шагов. Количество шагов должно быть достаточным для достижения хорошей степени распознавания и в то же время, должно минимизировать время вычислений. Например, если на каждом шаге вероятность обнаружения лица 0,99, 10-шаговый классификатор достигнет вероятности 0,9 (так как 0,9 ~= 0,99^10). Хотя достижение такой вероятности может звучать как очень сложная задача, это можно сделать легко, так как каждый шаг должен иметь величину ошибки ложноположительного распознавания всего лишь около 30%.Процедура работы алгоритма AdaBoost может быть описана следующим образом: если m и l — числа лиц и не лиц соответственно, а j — сумма не лиц и лиц. Начальные веса w_(i, j) для i-го шага могут быть определены как  . Нормализованная взвешенная ошибка слабого классификатора может быть выражена следующим образом:
. Нормализованная взвешенная ошибка слабого классификатора может быть выражена следующим образом:  Веса обновляются по формуле (5) в каждой итерации. Если объект классифицирован корректно, тогда
Веса обновляются по формуле (5) в каждой итерации. Если объект классифицирован корректно, тогда  в остальных случаях ej=1.
в остальных случаях ej=1. Конечный классификатор для i-го шага определяется ниже:
Конечный классификатор для i-го шага определяется ниже:  где
где 
2.3 Кластеризация на основе областейДетектор лиц обычно находит более чем одно лицо, даже если на изображении оно одно (как это показано на рисунке 5). Рисунок 5. Результаты работы детектора лиц
Рисунок 5. Результаты работы детектора лиц
Поэтому кластеризация на основе области используется для решения этой проблемы. Предлагаемый метод состоит из двух уровней кластеризации — локальной и глобальной кластеризации. Локальная кластеризация используется, чтобы кластеризовать блоки в одном масштабе и сформировать простой фильтр для определения количества блоков изображений внутри кластеров. Если количество блоков в некотором кластере более одного, тогда этот кластер помечается как вероятно содержащий лицо, в противном случае — кластер отвергается. Метод локальной кластеризации также имеет следующее правило для принятия решения о пометки кластера:  В формуле (7) процент перекрытия (x, y) обозначает расстояние между двумя обнаруженными регионами-кандидатами лиц и равен расстоянию между центрами этих регионов. Равенство
В формуле (7) процент перекрытия (x, y) обозначает расстояние между двумя обнаруженными регионами-кандидатами лиц и равен расстоянию между центрами этих регионов. Равенство  означает, что x и y — в одном кластере и эти области почти полностью перекрываются друг другомРисунок 6 показывает несколько возможных случаев перекрытия областей.
означает, что x и y — в одном кластере и эти области почти полностью перекрываются друг другомРисунок 6 показывает несколько возможных случаев перекрытия областей. Рисунок 6. Диаграммы перекрытия регионов и расстояния центров блоков
Рисунок 6. Диаграммы перекрытия регионов и расстояния центров блоков
На рисунке 6(а) два блока попадают в один кластер. На рисунке 6(b) два блока попадают в разные кластеры, т.к. расстояние между их центрами больше порога. Для особых случаев, как показано на рисунке 6©, все блоки рассмотрены как кандидаты, но большинство из них ложные лица. Поэтому в этой работе для практических приложений мы выбираем только один блок, который удовлетворяет уравнению (7) нежели несколько блоков. В конце концов, глобальная кластеризация будет использовать блоки, полученные на этапе локальной кластеризации, а метка лицевого региона соответствует среднему размеру всех доступных блоков. Некоторые результаты всего процесса кластеризации на основе выбора регионов для локального и глобального уровней показаны на рисунке 7. Из правого изображения на рисунке 7, фактически, только один блок будет точно классифицирован как лицевой регион в результате применения локальной и глобальной кластеризации (даже если более 5 лицевых кандидатов получены для изображения, включающего только 5 лиц). Рисунок 7. Результаты кластеризации. (а) Результаты кластеризации на локальном уровне. (b) Результаты кластеризации на глобальном уровне
Рисунок 7. Результаты кластеризации. (а) Результаты кластеризации на локальном уровне. (b) Результаты кластеризации на глобальном уровне
3. Оценка возрастаИмеется три основных части нашей системы оценки возраста, представленные в этой работе: извлечение возрастных особенностей, уменьшения количества особенностей и классификация особенностей. Извлечение особенностей выполняется с помощью вейвлетов Габора, которые используются для анализа изображений из-за их биологической значимости и вычислительных свойств. Ядра вейвлетов Габора схожи 2D восприятию молочных бактерий и выражающих мощные способности пространственной ориентации и селективности, а также являющиеся локально-оптимальными в пространственной и частотной областях. Преобразование Габора, общеизвестно, особенно подходит для декомпозиции изображений и их представлении, когда целью является выбор локальных и отличительных особенностей. Более того, Donato и другие [15] показали экспериментально, что представление через вейвлеты Габора является эффективной для классификации лицевых особенностей. В этом разделе вводятся основы вейвлетов Габора для представления особенностей изображений и описывается уменьшение количества особенностей, их отбора в вектор, используемый для оценки возраста.
3.1 Извлечения особенностей с помощью вейвлетов ГабораВейвлет Габора  может быть определен следующим образом [16]:
может быть определен следующим образом [16]:  где
где  и
и  определяют ориентацию и масштаб ядра Габора,
определяют ориентацию и масштаб ядра Габора,  обозначает оператор вычисления нормы, а волновой вектор
обозначает оператор вычисления нормы, а волновой вектор  определяется так:
определяется так:  где
где  и
и  — максимальная частота, а f — пространственный множитель между ядрами в частотной области. В общем, ядра вейвлетов Габора в (8) являются самоподобными, так как они могут быть выведены из одного фильтра — материнского вейвлета, с помощью масштабирования и вращения с помощью волнового вектора
— максимальная частота, а f — пространственный множитель между ядрами в частотной области. В общем, ядра вейвлетов Габора в (8) являются самоподобными, так как они могут быть выведены из одного фильтра — материнского вейвлета, с помощью масштабирования и вращения с помощью волнового вектора  Каждое ядро — произведение Гауссовой свертки и комплексной волновой плоскости, тогда как первый терм в квадратных скобках в (9) определяет колебательную часть ядра, а второй терм компенсирует значение постоянного тока. Параметр сигма — стандартное отклонение ширины гауссовой свертки от длины волны.В большинстве случаев, исследователи используют вейвлеты Габора с пятью различными масштабами,
Каждое ядро — произведение Гауссовой свертки и комплексной волновой плоскости, тогда как первый терм в квадратных скобках в (9) определяет колебательную часть ядра, а второй терм компенсирует значение постоянного тока. Параметр сигма — стандартное отклонение ширины гауссовой свертки от длины волны.В большинстве случаев, исследователи используют вейвлеты Габора с пятью различными масштабами,  и восемью ориентациями,
и восемью ориентациями,  На рисунке 8 показана реальная часть ядер Габора на 5 масштабных уровнях и в 8 направлениях, а также их величины для следующих параметров:
На рисунке 8 показана реальная часть ядер Габора на 5 масштабных уровнях и в 8 направлениях, а также их величины для следующих параметров: 

 Рисунок 8. Представление вейвлетов Габора
Рисунок 8. Представление вейвлетов Габора
Представление вейвлетов Габора для изображения — это свертка изображения с семейством ядер Габора, используя уравнение (8). Пусть  — распределение уровней серого изображения. Результат конволюции изображения I и
— распределение уровней серого изображения. Результат конволюции изображения I и  определяется как:
определяется как:  где
где  и * обозначает оператор конволюции (свертки).Применяя теорему свертки, быстрое преобразование Фурье (БПФ) используется для получения результата операции свертки. Уравнения (11) и (12) — определение конволюции через БПФ.
и * обозначает оператор конволюции (свертки).Применяя теорему свертки, быстрое преобразование Фурье (БПФ) используется для получения результата операции свертки. Уравнения (11) и (12) — определение конволюции через БПФ. где
где 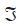 и
и  обозначают преобразование Фурье и обратное преобразование Фурье соответственно.
обозначают преобразование Фурье и обратное преобразование Фурье соответственно. Рисунок 9. Одно из изображений выборки и 40 выходов операции свертки
Рисунок 9. Одно из изображений выборки и 40 выходов операции свертки
Рисунок 9 показывает значения выходов операций свертки для изображения выборки. В соответствии с рисунком 9, выходные значения сверток проявляют способности пространственной ориентации и селективности. Такие характеристики производят устойчивые локальные особенности, которые подходят для визуального распознавания. В дальнейшем, мы обозначим  величину выходов операции свертки. 3.2 Уменьшение количества особенностей по схемеВ общем, МГК или другие алгоритмы работают с особенностями в виде вейвлетов Габора для уменьшения размерности преобразованных данных [19, 20]. Результаты конволюции, соответствующие все вейвлетам Габора, собираются вместе в единое целое, а чтобы улучшить вычислительную эффективность — применяется МГК для уменьшения размерности данных. Предлагаются 3 различные схемы: (а) схема параллельного уменьшения размерности (СПУР, Parallel Dimension Reduction Scheme, PDRS): особенности в виде вейвлетов Габора извлекаются из каждого изображения выборки как показано на рисунке 10. Обучается каждая проекционная матрица МГК для каждого канала, а объединение этих особенностей выполняется методом голосования. (b) Схема уменьшения размерности ансамбля (СУРА, Ensemble Dimension Reduction Scheme, EDRS): СУРА — наиболее распространенная схема, используемая для особенностей Габора. Как показано на рисунке 11, разница между СПУР и СУРА в том, что СУРА объединяет особенности Габора вместо параллельного их использования. © Схема многоканального уменьшения размерности (СМУР, Multi-channel Dimension Reduction, MDRS). Xiaodong Li и другие [21] предложили СМУР в 2009. Как показано на рисунке 12, основная идея СМУР состоит в обучении матрицы проекции МГК для одного канала с помощью различных изображений выборки. В [21] Xiaodong Li и др. уже доказали, что СМУР работает лучше, чем СУРА при использовании особенностей Габора.
величину выходов операции свертки. 3.2 Уменьшение количества особенностей по схемеВ общем, МГК или другие алгоритмы работают с особенностями в виде вейвлетов Габора для уменьшения размерности преобразованных данных [19, 20]. Результаты конволюции, соответствующие все вейвлетам Габора, собираются вместе в единое целое, а чтобы улучшить вычислительную эффективность — применяется МГК для уменьшения размерности данных. Предлагаются 3 различные схемы: (а) схема параллельного уменьшения размерности (СПУР, Parallel Dimension Reduction Scheme, PDRS): особенности в виде вейвлетов Габора извлекаются из каждого изображения выборки как показано на рисунке 10. Обучается каждая проекционная матрица МГК для каждого канала, а объединение этих особенностей выполняется методом голосования. (b) Схема уменьшения размерности ансамбля (СУРА, Ensemble Dimension Reduction Scheme, EDRS): СУРА — наиболее распространенная схема, используемая для особенностей Габора. Как показано на рисунке 11, разница между СПУР и СУРА в том, что СУРА объединяет особенности Габора вместо параллельного их использования. © Схема многоканального уменьшения размерности (СМУР, Multi-channel Dimension Reduction, MDRS). Xiaodong Li и другие [21] предложили СМУР в 2009. Как показано на рисунке 12, основная идея СМУР состоит в обучении матрицы проекции МГК для одного канала с помощью различных изображений выборки. В [21] Xiaodong Li и др. уже доказали, что СМУР работает лучше, чем СУРА при использовании особенностей Габора. Рисунок 10. Схема параллельного уменьшения размерности
Рисунок 10. Схема параллельного уменьшения размерности
 Рисунок 11. Схема уменьшения размерности ансамбля
Рисунок 11. Схема уменьшения размерности ансамбля
 Рисунок 12. Схема многоканального уменьшения размерности
Рисунок 12. Схема многоканального уменьшения размерности
Для сравнения работы СПУР и СМУР используется метод k-ближайших соседей (KNN). Для СПУР мы используем метод голосования, называемый «Гауссовское голосование», для объединения 40 каналов. Концепция Гауссовское голосования описывается как использование KNN классификатора для каждого канала для предсказания 40 возрастов. Каждый предсказанный возраст рассматривается как математическое ожидание нормального распределения и определяет гистограмму. Наивысший ее пик — это конечное предсказанное значение возраста. Для СМУР мы используем объединенные особенности напрямую. FG-NET база данных возрастов [22] адоптируется для экспериментов. База данных содержит 1002 изображения лиц людей (цветных и полутоновых) с большой вариацией в освещении, позах и выражениях эмоций. В этой базе 82 различных персон (разной расы) с возрастами от 0 до 69 лет. Мы использовали критерий на основе средней абсолютной ошибки (САО, mean absolute error, MAE) для оценки работы каждого способа оценки возраста. САО означает среднее значение абсолютной ошибки между оцененным и известным возрастами. Математическая функция САО имеет вид:  где
где  — известный возраст для тестируемого изображения k, а
— известный возраст для тестируемого изображения k, а  — оцененный возраст. N — общее число тестируемых изображений. В Таблице 1 показаны экспериментальные результаты для двух схем. СМУР оказалась лучше, чем СПУР.Таблица 1. Значения САО для СПУР и СМУР
— оцененный возраст. N — общее число тестируемых изображений. В Таблице 1 показаны экспериментальные результаты для двух схем. СМУР оказалась лучше, чем СПУР.Таблица 1. Значения САО для СПУР и СМУР
3.3 Отбор особенностейРазмерность пространства вейвлетов Габора чрезвычайно большое, даже несмотря на применение схемы уменьшение размерности. Поэтому важно выбрать наиболее существенные особенности и еще более сократить размерность пространства. Три типичных метода уменьшения размерности были предложены в последних исследованиях: (а) линейный дискриминантный анализ (ЛДА) схожий с МГК, но с той разницей, что ЛДА использует информацию о принадлежности к классу, чтобы улучшить себя [23]. (b) Сохранение локальных проекций (LPP) ищет подпространство, которое сохраняет необходимое разнообразие, измеряя расстояние до соседних точек [24]. © OLPP производит ортогональные базисные функции на основе LPP и сохраняет структуру метрики [25]. Для определения какой метод редукции из перечисленных выше наиболее подходящий для использования возрастных особенностей в виде вейвлетов Габора, мы использовали KNN классификатор и САО критерий для оценки эффективности. В эксперименте мы изменили вес близости LPP и OLPP для получения большей детальности. В таблице 2 показаны значения САО для каждого метода редукции. OLPP с косинусным весом расстояния наиболее эффективен в оценке возраста. Таблица 2. САО для разных методов уменьшения размерности
3.4 Классификация возрастаОсобенности в виде вейвлетов Габора используются в МОВ-классификаторе для определения возраста. МОВ имеет достаточный потенциал как классификатор разряженных обучающих данных. МОВ имеет схожие с нейронными сетями корни и также как они обладает способностью аппроксимировать любую функцию от многих переменных с любой желаемой точностью. Этот подход был изобретен Владимиром Вапником и др., используя статистическую теорию. [25–27]. Таблица 1 и рисунок 11 показывают результаты сравнения нашего условно основывающегося на энтропийном подходе к выбору особенностей с этими подходами к выбору особенностей и классификации. Все сравнения в этой статье используют одинаковую обучающую и тестовую базу данных. База данных содержит 1002 изображения лиц людей (цветных и полутоновых) с большой вариацией в освещении, позах и выражениях эмоций. В этой базе 82 различных персон (разной расы) с возрастами от 0 до 69 лет. Мы использовали размерность входа МОВ равную 43 в процессе сравнения (как показано в таблице 2). В дополнение, мы сравнили точность с теми же особенностями Габора и методом KNN.
4. Результаты экспериментовМы использовали адаптированную FG-NET базу изображений людей различного возраста [20]. Эта база доступна публично и содержит 1002 изображения лиц людей (цветных и полутоновых) с большой вариацией в освещении, позах и выражениях эмоций. В этой базе 82 различных персон (разной расы) с возрастами от 0 до 69 лет. На рисунке 13 показана серия изображений базы для одной из персон. Рисунок 13. Некоторые изображения персоны в FG-NET базе
Рисунок 13. Некоторые изображения персоны в FG-NET базе
Для оценки работы подсистемы оценки возраста, область лица на изображения была обозначена с помощью детектора лиц, описанного в разделе 2. Метод перекрестной проверки, в котором на каждом шаге проверки, только одна персона использовалась в качестве теста, а остальные использовались для обучения. Причем, поочередно в качестве тестовой персоны использовались все персоны выборки.Каждое изображение было обрезано и приведено к размеру 64×64 пикселей, а цветовая информация преобразована к 256 уровням серого. Мы использовали МОП с РБФ (Radial basis function kernel, RBF) ядром, в котором параметр c = 0,5 и гамма g = 0.0078125. Мы в основном сфокусировались на новых особенностях, полученных на основе вейвлетов Габора.Работа подсистемы оценки возраста может быть оценена с помощью двух мер: средней абсолютной ошибки (САО) и накопительной суммой (НС). САО определяется как средняя абсолютная ошибка между оцененным возрастом и известным. САО была использована в [2–10]. НС определяется так:  где
где  — количество тестируемых изображений, на которых оценка возраста имеет абсолютную ошибку не более чем j.Таблица 3 показывает результаты эксперимента. Мы сравниваем наши результаты с предыдущими методами, использующими на возрастную базу данных FG-NET. Метод Габора-OLSS, используемый в данной работе имеет САО равную 8.43 и 5.71 при использовании KNN и МОВ соответственно, которые явно меньше, чем большинство предыдущих результатов по аналогичным экспериментам. Наш метод предлагает приблизительно 16% САО в сравнении с результатами AGES [2]. В таблице 3, можно видеть, что LARR [4] метод и BIF [9] метод имеют более благоприятные значения САО: 5.07 и 4.77, чем наши. Талица 3. Значения САО для разных методов
— количество тестируемых изображений, на которых оценка возраста имеет абсолютную ошибку не более чем j.Таблица 3 показывает результаты эксперимента. Мы сравниваем наши результаты с предыдущими методами, использующими на возрастную базу данных FG-NET. Метод Габора-OLSS, используемый в данной работе имеет САО равную 8.43 и 5.71 при использовании KNN и МОВ соответственно, которые явно меньше, чем большинство предыдущих результатов по аналогичным экспериментам. Наш метод предлагает приблизительно 16% САО в сравнении с результатами AGES [2]. В таблице 3, можно видеть, что LARR [4] метод и BIF [9] метод имеют более благоприятные значения САО: 5.07 и 4.77, чем наши. Талица 3. Значения САО для разных методов
Как упоминалось ранее, наша цель — построить полностью автоматическую систему оценки возраста. LARR метод использует AAM особенности FG-NET напрямую и это означающие, что данный метод обычно нуждается в привлечении людей при выравнивании характерных точек. В нашем исследовании еще нет эффективного метода, который бы мог автоматически выравнивать точки быстро и корректно. Например, LARR метод может потребовать значительных усилий при выравнивании точек. САО у BIF явно эффективнее, чем у метода, предлагаемого нами. Чтобы верифицировать их результаты, мы попытались осуществить BIF метод. Результаты оказались гораздо хуже, с САО 10.32. Более того, метод BIF требует большое количество времени при извлечении черт старения. По сравнению с нашим методом, BIF требует в дважды больше времени. Наш метод увеличивает скорость обработки выделенных признаков до приблизительно 12–15 изображений за секунду.Сравнения НС проиллюстрированы на рисунке 14. Наш Gabor-OLPP метод выполняется быстрее, чем WAS и методы, использующие многослойные перцептроны. Метод AGES близок к GAbor-OLPP методу на низком уровне ошибки возраста, но ниже чем те Gabor-OLPP, где уровень ошибки больше пяти. Рисунок 14. Накопительная сумма для каждого метода
Рисунок 14. Накопительная сумма для каждого метода
5. ЗаключениеВ этой работе мы предложили новую систему для автоматической оценки возраста по изображению лица. Преобразование на основе вейвлетов Габора вводится, прежде всего, для оценки возраста с целью извлечения возрастных особенностей автоматически в режиме реального времени. Метод опорных векторов имеет хороший потенциал для классификации разряженных обучающих данных, а также обладает устойчивой способностью к обобщению.В самых последних исследованиях в этой области используется метод анализа главных компонент только для уменьшения размерности особенностей Габора. Но МГК имеет неадекватную эффективность, когда используются особенности Габора напрямую. Повышая эффективность за счет снижения точности классификации, предыдущие исследователи пытались выбирать определенные особенности, игнорируя все остальные. Поэтому, методы уменьшения размерности более
